轉(zhuǎn)自:http://hi.baidu.com/webcell/blog/item/f179ac0f0ab6f3e7aa645749.html
最近關(guān)注Hadoop����,因此也順便關(guān)注了一下Hadoop相關(guān)的項(xiàng)目。HBASE就是基于Hadoop的一個開源項(xiàng)目����,也是對Google的BigTable的一種實(shí)現(xiàn)��。
BigTable是什么?Google的Paper對其作了充分的說明。字面上看就是一張大表��,其實(shí)和我們想象的傳統(tǒng)數(shù)據(jù)庫的表還是有些差別的�����。松散數(shù)據(jù)可以說是介于Map Entry(key & value)和DB Row之間的一種數(shù)據(jù)。在我使用Memcache的時候����,有時候的需求是需要存儲的不僅僅是簡單的一個key對應(yīng)一個value��,可能我需要類似于數(shù)據(jù)庫表結(jié)構(gòu)中多屬性的存儲,但是又不會有傳統(tǒng)數(shù)據(jù)庫表結(jié)構(gòu)中那么多關(guān)聯(lián)關(guān)系的需求,其實(shí)這類數(shù)據(jù)就是所謂的松散數(shù)據(jù)����。BigTable最淺顯來看就是一張很大的表��,表的屬性可以根據(jù)需求去動態(tài)增加,但是又沒有表與表之間關(guān)聯(lián)查詢的需求。
互聯(lián)網(wǎng)應(yīng)用有一個最大的特點(diǎn),就是速度�����,功能再強(qiáng)大�����,速度慢����,還是會被舍棄����。因此在大訪問量的網(wǎng)站都采取前后的緩存來提升性能和響應(yīng)時間。對于Map Entry類型的數(shù)據(jù)����,集中式分布式Cache都有很多選擇��,對于傳統(tǒng)的關(guān)系型數(shù)據(jù)�����,從MySQL到Oracle都給了很好的支持����,唯有松散數(shù)據(jù)這類數(shù)據(jù)�����,采用前后兩種解決方案都不能最大化它的處理能力����。因此BigTable才有了它用武之地。
HBASE作為Apache的開源項(xiàng)目����,也是出于起步階段��,因?yàn)槠鋵?shí)它所依賴的Hadoop也不能說已經(jīng)到了成熟階段,所以都有很大的發(fā)展空間�����,這也為我們這些開源愛好者提供了更多空間去貢獻(xiàn)�����。這里主要會談到HBASE的框架設(shè)計方面的知識和它的一些特點(diǎn)����,不論是否采用HBASE去解決工作中的問題�����,一種好的流程設(shè)計總會給開發(fā)者和架構(gòu)設(shè)計者帶來一些思想上的火花。
HBASE設(shè)計介紹
數(shù)據(jù)模型
HBASE中的每一張表����,就是所謂的BigTable��。BigTable會存儲一系列的行記錄,行記錄有三個基本類型的定義:Row Key,Time Stamp,Column����。Row Key是行在BigTable中的唯一標(biāo)識����,Time Stamp是每次數(shù)據(jù)操作對應(yīng)關(guān)聯(lián)的時間戳��,可以看作類似于SVN的版本�����,Column定義為:<family>:<label>,通過這兩部分可以唯一的指定一個數(shù)據(jù)的存儲列��,family的定義和修改需要對HBASE作類似于DB的DDL操作����,而對于label的使用,則不需要定義直接可以使用����,這也為動態(tài)定制列提供了一種手段��。family另一個作用其實(shí)在于物理存儲優(yōu)化讀寫操作,同family的數(shù)據(jù)物理上保存的會比較臨近,因此在業(yè)務(wù)設(shè)計的過程中可以利用這個特性�����。
看一下邏輯數(shù)據(jù)模型:
|
Row Key
|
Time Stamp
|
Column "contents:"
|
Column "anchor:"
|
Column "mime:"
|
|
"com.cnn.www"
|
t9
|
|
"anchor:cnnsi.com"
|
"CNN"
|
|
|
t8
|
|
"anchor:my.look.ca"
|
"CNN.com"
|
|
|
t6
|
"<html>..."
|
|
|
"text/html"
|
|
t5
|
"<html>..."
|
|
|
|
|
t3
|
"<html>..."
|
|
|
|
上表中有一列��,列的唯一標(biāo)識為com.cnn.www,每一次邏輯修改都有一個timestamp關(guān)聯(lián)對應(yīng),一共有四個列定義:<contents:>,<anchor:cnnsi.com>,<anchor:my.look.ca>,<mime:>。如果用傳統(tǒng)的概念來將BigTable作解釋����,那么BigTable可以看作一個DB Schema����,每一個Row就是一個表����,Row key就是表名,這個表根據(jù)列的不同可以劃分為多個版本,同時每個版本的操作都會有時間戳關(guān)聯(lián)到操作的行。
再看一下HBASE的物理數(shù)據(jù)模型:
|
Row Key
|
Time Stamp
|
Column "contents:"
|
|
"com.cnn.www"
|
t6
|
"<html>..."
|
|
t5
|
"<html>..."
|
|
t3
|
"<html>..."
|
|
Row Key
|
Time Stamp
|
Column "anchor:"
|
|
"com.cnn.www"
|
t9
|
"anchor:cnnsi.com"
|
"CNN"
|
|
t8
|
"anchor:my.look.ca"
|
"CNN.com"
|
|
Row Key
|
Time Stamp
|
Column "mime:"
|
|
"com.cnn.www"
|
t6
|
"text/html"
|
物理數(shù)據(jù)模型其實(shí)就是將邏輯模型中的一個Row分割成為根據(jù)Column family存儲的物理模型����。
對于BigTable的數(shù)據(jù)模型操作的時候��,會鎖定Row,并保證Row的原子操作��。
框架結(jié)構(gòu)及流程

圖1 框架結(jié)構(gòu)圖
HBASE依托于Hadoop的HDFS作為存儲基礎(chǔ),因此結(jié)構(gòu)也很類似于Hadoop的Master-Slave模式,Hbase Master Server 負(fù)責(zé)管理所有的HRegion Server����,但Hbase Master Server本身并不存儲HBASE中的任何數(shù)據(jù)��。HBASE邏輯上的Table被定義成為一個Region存儲在某一臺HRegion Server上,HRegion Server與Region的對應(yīng)關(guān)系是一對多的關(guān)系。每一個HRegion在物理上會被分為三個部分:Hmemcache、Hlog�����、HStore�����,分別代表了緩存,日志,持久層����。通過一次更新流程來看一下這三部分的作用:
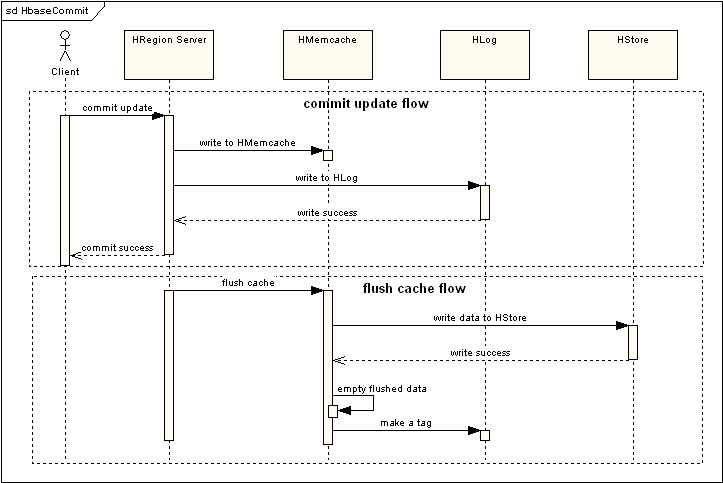
圖2 提交更新以及刷新Cache流程
由流程可以看出��,提交更新操作將會寫入到兩部分實(shí)體中,HMemcache和Hlog中,HMemcache就是為了提高效率在內(nèi)存中建立緩存��,保證了部分最近操作過的數(shù)據(jù)能夠快速的被讀取和修改�����,Hlog是作為同步Hmemcache和Hstore的事務(wù)日志��,在HRegion Server周期性的發(fā)起Flush Cache命令的時候,就會將Hmemcache中的數(shù)據(jù)持久化到Hstore中����,同時會清空Hmemecache中的數(shù)據(jù)�����,這里采用的是比較簡單的策略來做數(shù)據(jù)緩存和同步,復(fù)雜一些其實(shí)可以參照java的垃圾收集機(jī)制來做��。
在讀取Region信息的時候�����,優(yōu)先讀取HMemcache中的內(nèi)容��,如果未取到再去讀取Hstore中的數(shù)據(jù)。
幾個細(xì)節(jié):
1. 由于每一次Flash Cache,就會產(chǎn)生一個Hstore File�����,在Hstore中存儲的文件會越來越多��,對性能也會產(chǎn)生一定影響,因此達(dá)到設(shè)置文件數(shù)量閥值的時候就會Merge這些文件為一個大文件�����。
2. Cache大小的設(shè)置以及flush的時間間隔設(shè)置需要考慮內(nèi)存消耗以及對性能的影響�����。
3. HRegion Server每次重新啟動的時候會將Hlog中沒有被Flush到Hstore中的數(shù)據(jù)再次載入到Hmemcache����,因此Hmemcache過大對于啟動的速度也有直接影響�����。
4. Hstore File中存儲數(shù)據(jù)采用B-tree的算法����,因此也支持了前面提到對于Column同Family數(shù)據(jù)操作的快速定位獲取����。
5. HRegion可以Merge也可以被Split,根據(jù)HRegion的大小決定�����。不過在做這些操作的時候HRegion都會被鎖定不可使用。
6. Hbase Master Server通過Meta-info Table來獲取HRegion Server的信息以及Region的信息��,Meta最頂部的一個Region是虛擬的一個叫做Root Region��,通過Root Region可以找到下面各個實(shí)際的Region。
7. 客戶端通過Hbase Master Server獲得了Region所在的Region Server�����,然后就直接和Region Server進(jìn)行交互�����,而對于Region Server相互之間不通信�����,只和Hbase Master Server交互,受到Master Server的監(jiān)控和管理��。
后話
對HBase還沒有怎么使用��,僅僅只是看了wiki去了解了一下結(jié)構(gòu)和作用�����,暫時還沒有需要使用的場景,不過對于各種開源項(xiàng)目的設(shè)計有所了解�����,對自己的框架結(jié)構(gòu)設(shè)計也會有很多幫助��,因此分享一下����。