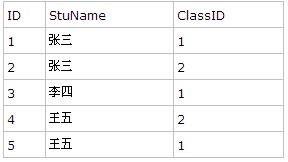
在項目中我們經常能遇到數據庫有“一對多”的關系,比如下面兩張表:
Student:
Class:
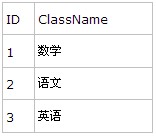
Class-Student就這樣構成了一個簡單的一對多關系。當然在實際的項目中,也可以再建立一張Relation表來保存他們之間的關系,在這里為了簡單,就不做Relation表了。
現在在項目中,我需要將Class表中的數據list顯示,當然也想顯示選擇了這門課的Student的StuName。也可以說是將一對多關系轉換為一對一關系。我所期望的顯示格式是這樣的:
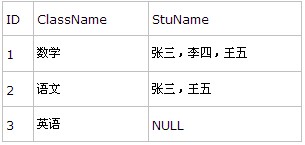
要做到這一點并不難,大體有兩種思路:
1、在數據庫中寫一個函數
2、在程序中獲取表Class與表Student所有數據,然后對比ClassID
那么,那種方法效率比較高呢?于是我寫了下面的代碼來進行一個簡單的測試
View Code
class Program
{
static void Main(string[] args)
{
Sql sql = new Sql();
Stopwatch time1 = new Stopwatch();
Stopwatch time2 = new Stopwatch();
for (int j = 0; j < 10; j++)
{
time2.Start();
for (int i = 0; i < 1000; i++)
{
string sql1 = "select ID,[StuName],[ClassID] FROM [Student]";
string sql2 = " SELECT ID,ClassName from Class";
List<string> item = new List<string>();
string bl="";
DataTable dt1 = sql.getData(sql1);
DataTable dt2 = sql.getData(sql2);
foreach (DataRow dtRow2 in dt2.Rows)
{
foreach (DataRow dtRow1 in dt1.Rows)
{
if (dtRow1["ClassID"].ToString() == dtRow2["ID"].ToString())
{
bl+=dtRow1["StuName"].ToString()+",";
}
}
item.Add(bl);
bl = "";
}
}
time2.Stop();
Console.WriteLine(time2.Elapsed.ToString());
time1.Start();
for (int i = 0; i < 1000; i++)
{
string sql3 = "SELECT C.ID, C.ClassName, dbo.f_getStuNamesByClassID(C.ID)as stuName FROM Class C";
DataTable dt = sql.getData(sql3);
}
time1.Stop();
Console.WriteLine(time1.Elapsed.ToString());
float index = (float)time1.Elapsed.Ticks / (float)time2.Elapsed.Ticks;
Console.WriteLine("效率比" + index.ToString());
Console.WriteLine("=============================");
}
Console.ReadLine();
}
} |
View Code
class Sql
{
public DataTable getData(string sql)
{
SqlConnection conn = new SqlConnection();
conn.ConnectionString = "Data Source=.\\SQLEXPRESS;Initial Catalog=Test;User Id=sa;Password=1;";
SqlCommand comm = new SqlCommand(sql, conn);
conn.Open();
SqlDataAdapter da = new SqlDataAdapter(comm);
DataSet ds = new DataSet();
da.Fill(ds, "ds");
conn.Close();
return ds.Tables[0];
}
}
|
View Code --根據課程ID,返回選此課程的學生的名字,以逗號隔開
ALTER function [dbo].[f_getStuNamesByClassID] (@ID int)
RETURNS nvarchar(50)
begin
declare @Result nvarchar(50);
declare @stuName nvarchar(50);
Set @Result=''; declare cur cursor for
(
SELECT S.StuName FROM Class C
LEFT JOIN Student S ON C.ID=S.ClassID
WHERE C.ID=@ID
)
open cur;
fetch next from cur into @stuName;
while(@@fetch_status=0)
begin
set @Result=@Result+@stuName+',';
fetch next from cur into @stuName;
end;
--去除最后多余的一個逗號
IF @Result <> ''
SET @Result=SUBSTRING(@Result, 1, LEN(@Result)-1);
ELSE
SET @Result=NULL;
return @Result;
en |
測試結果如下:
00:00:00.5466790
00:00:00.7753704
效率比1.418329
=============================
00:00:01.0251996
00:00:01.5594629
效率比1.521131
=============================
00:00:01.5124349
00:00:02.3286227
效率比1.539652
=============================
00:00:01.9882458
00:00:03.1007960
效率比1.559564
=============================
00:00:02.4476305
00:00:03.8717636
效率比1.581842
=============================
00:00:02.9129007
00:00:04.6332828
效率比1.590608
=============================
00:00:03.4006140
00:00:05.3971930
效率比1.587123
=============================
00:00:03.8655281
00:00:06.2574500
效率比1.618783
=============================
00:00:04.4532249
00:00:07.0674710
效率比1.587046
=============================
00:00:04.9540083
00:00:07.8596999
效率比1.586533
=============================
分析一下測試結果,不難發現每一個一千次所用的時間基本符合一個等差數列。當然第一個一千次由于要初始化,所以顯得慢一些。
總體來說,在程序中用處理一對多關系,比在數據庫中用函數處理效率要高35%這樣。
那么如果我們在Student表中再添加一行這樣的數據:

測試結果如下:
00:00:00.5519228
00:00:00.8206084
效率比1.486817
=============================
00:00:01.0263686
00:00:01.5813210
效率比1.540695
=============================
00:00:01.4886327
00:00:02.3516000
效率比1.579705
=============================
00:00:01.9807901
00:00:03.1495472
效率比1.590046
=============================
00:00:02.4613411
00:00:03.9278171
效率比1.595804
=============================
00:00:02.9246678
00:00:04.6961790
效率比1.605714
=============================
00:00:03.3911521
00:00:05.5018374
效率比1.62241
=============================
00:00:03.8737490
00:00:06.2716150
效率比1.619004
=============================
00:00:04.4047347
00:00:07.1796579
效率比1.629986
=============================
00:00:04.8688508
00:00:07.9477787
效率比1.632372
=============================
發現添加數據之后,效率比進一步加大
環境:vs2008,sql 2005
總結:根據測試結果來說,對于大規模高并發的數據庫操作(在這里是10次循環,每次1000次讀取數據),我們應該盡可能的避免使用數據庫函數,而應該將數據全部取出來,在程序中進行處理
寫在最后的話:對于我的程序、代碼、思路等等一切的一切有不同見解者,歡迎留言討論。這是我的第一篇博客,希望大家多多支持,如有不足望海涵。