html_1 = urllib2.urlopen(cityURL,timeout=120).read() mychar = chardet.detect(html_1) bianma = mychar['encoding'] if bianma == 'utf-8' or bianma == 'UTF-8': html = html_1 else : html = html_1.decode('gb2312','ignore').encode('utf-8') |
chapter_soup = BeautifulSoup(html) city = chapter_soup.find('div',class_ = 'row-fluid').find('h1').get_text() province = chapter_soup.find('a',class_ = 'province').get_text() pmNum = chapter_soup.find('div',class_ = 'row-fluid').find('span').get_text() suggest = chapter_soup.find('div',class_ = 'row-fluid').find('h2').get_text() rand = chapter_soup.find('div',class_ = 'row-fluid').find('h2').find_next_sibling('h2').get_text() face = chapter_soup.find('div',class_ = 'span4 pmemoji').find('h1').get_text() conclusion = chapter_soup.find('h1',class_ = 'review').get_text() print city.encode('utf-8') cur.execute('insert into t_pm values(\''+city.encode('utf-8') +'\',\''+province.encode('utf-8') +'\',\''+pmNum.encode('utf-8') +'\',\''+suggest.encode('utf-8') +'\',\''+rand.encode('utf-8') +'\',\''+conclusion.encode('utf-8')+'\')') |
做了簡(jiǎn)單的封裝后,我們可以實(shí)現(xiàn)如下的自動(dòng)化測(cè)試代碼。請(qǐng)注意,這些代碼是可以正確運(yùn)行并作為正式的自動(dòng)化測(cè)試用例的。這樣一來(lái),自動(dòng)化測(cè)試腳本跟手工測(cè)試用例就非常相似了,大言不慚的說(shuō)相似程度可以達(dá)到60%。
這樣做有什么好處呢?
■ 手工測(cè)試用例更加容易“翻譯”正自動(dòng)化測(cè)試用例:
| 測(cè)試瀏覽器 = Watir::Browser.new :firefox 測(cè)試瀏覽器.轉(zhuǎn)到 'www.google.com' 在(測(cè)試瀏覽器.的.text_field(:name, "q")).中.輸入 "qq" 點(diǎn)擊 測(cè)試瀏覽器.的.button(:name, "btnG") 等待(測(cè)試瀏覽器.的.div(:id, "resultStats")) 斷言 '測(cè)試通過(guò)' if 測(cè)試瀏覽器.的.text.包含('騰訊QQ') 關(guān)閉 測(cè)試瀏覽器 |
由于加入了符合自然語(yǔ)義的”的”及“在”函數(shù),整個(gè)測(cè)試用例的自然度得到大大提升,基本可以做到不熟悉自動(dòng)化代碼的人員可以大致猜測(cè)到用例的真實(shí)用例。讓用例自己說(shuō)話,這比反復(fù)釋疑和解惑要好上一些;
■ 手工測(cè)試人員編寫(xiě)用例的門(mén)檻相對(duì)降低:
由于代碼的靈活度及兼容性相對(duì)較大(ruby語(yǔ)言的特性)及測(cè)試api相對(duì)簡(jiǎn)單(watir的特性),手工測(cè)試人員應(yīng)該可以更加方便的理解和編寫(xiě)代碼,這樣用例編寫(xiě)的門(mén)檻降低;
■ 用例維護(hù)成本降低:
中文化的用例代碼可以很容易的進(jìn)行review。大家應(yīng)該有這樣的經(jīng)驗(yàn),在有些代碼中會(huì)出現(xiàn)一些隨意的ab, zb之類難以理解的變量或方法名。糾其原因無(wú)非是不好的編程習(xí)慣或詞窮的英文積淀。用上中文之后這些情況會(huì)有很大好轉(zhuǎn)。代碼本地化這項(xiàng)工作日本這些年一直在做,而且成果豐碩。我們完全可以通過(guò)ruby借鑒這一點(diǎn);
■ webdriver的強(qiáng)大特性
上面的測(cè)試代碼是基于watir-webdriver編寫(xiě)的。由于webdriver支持多種瀏覽器,如ff,chrome,safiri,ie等,代碼的擴(kuò)展性非常強(qiáng)。在配置合理及框架支撐的前提下,基本可以做到一套腳本多瀏覽器運(yùn)行,這對(duì)回歸測(cè)試來(lái)說(shuō)應(yīng)該是一個(gè)利好消息;
當(dāng)然,測(cè)試腳本中文化,自然化口語(yǔ)化也會(huì)帶來(lái)一些列的問(wèn)題,這點(diǎn)我們也必須清楚認(rèn)識(shí)到。
1.用例編寫(xiě)會(huì)相對(duì)費(fèi)時(shí)一些;中英文結(jié)合編碼在輸入速度上確實(shí)不如純英文;
2.對(duì)程序員來(lái)說(shuō)上面的代碼會(huì)有些怪異或者是令人難以忍受的;對(duì)于完美主義者來(lái)說(shuō),上面的代碼是“不純粹”且有些難看的;
總結(jié)一下,個(gè)人的觀點(diǎn)如下:
對(duì)于產(chǎn)品代碼來(lái)說(shuō),中英文混編的風(fēng)格目前來(lái)說(shuō)應(yīng)該是不合時(shí)宜的。但對(duì)于測(cè)試腳本來(lái)說(shuō),中文越多,用例可讀性越高,自動(dòng)化測(cè)試代碼越接近手動(dòng)用例,這反而應(yīng)該是一件不錯(cuò)的事情。這在里先拋磚引玉,希望有志同道合者可以一起研究,讓自動(dòng)化腳本更加的人性、自然、可讀、可維護(hù)。也許在不遠(yuǎn)的將來(lái),手動(dòng)用例可以直接拿來(lái)當(dāng)自動(dòng)化用例執(zhí)行也未嘗不可能。
下面是用例的完整代碼,由于只是演示興致,因此只是隨意在Module層進(jìn)行了簡(jiǎn)單的可視化封裝,過(guò)于簡(jiǎn)陋和demo,還望磚家手下留情。
# encoding: utf-8 測(cè)試瀏覽器 = Watir::Browser.new :firefox |

目的:
和普通性能自動(dòng)化測(cè)試工具相似,創(chuàng)建給定數(shù)量的請(qǐng)求代理,對(duì)鏈接列表中的鏈接不斷發(fā)送請(qǐng)求,并收集請(qǐng)求時(shí)間和其他響應(yīng)信息,最終返回結(jié)果數(shù)據(jù)。
事實(shí)上,由于開(kāi)源測(cè)試項(xiàng)目pylot的思路和這個(gè)項(xiàng)目有些相似,大部分示例代碼使用pylot源碼,一些會(huì)有稍微改動(dòng)。
設(shè)計(jì)思路:
如設(shè)計(jì)圖所示,總體上分為5個(gè)主要部分:
1、Test.xml處理部分:
通過(guò)用戶的制作的testcase.xml文件,獲取總體的屬性值作為參數(shù),并讀取所有test case所包含的信息,獲取所有測(cè)試連接列表和其他配置數(shù)據(jù),testcase.xml的格式如下,這個(gè)testcase.xml可以專門(mén)寫(xiě)一個(gè)xml寫(xiě) 作的工具,供QA人員以界面方式進(jìn)行編寫(xiě),提高效率并減小錯(cuò)誤率:
<testcases><project>
<name>Test</name>
<description>Only Test</description>
<executor>zhangyi</executor>
<!-- 如果需要結(jié)果進(jìn)入數(shù)據(jù)庫(kù),配置下面數(shù)據(jù)庫(kù)鏈接參數(shù) ->
<DB
<host></host>
<port></port>
<user></user>
<pwd></pwd>
<db></db>
<debug>true</debug>
</DB>
<type>Example</type>
</project>
<property>
<old_version></old_verstion>
<old_version></old_verstion>
<wel_url>r'http://www.baidu.cn/'</wel_url>
</property>
<!-- run before all testcase -->
<beforesetup>
</beforesetup>
<!-- run after all testcase -->
<afterteardown>
</afterteardown>
<!-- run before each testcase. if fail, not continue run testcase-->
<setup>
</setup>
<!-- run after each testcase. ignore testcase fail. -->
<teardown>
</teardown>
<!-- SAMPLE TEST CASE -->
<case repeat=3>
<url>http://www.example.com</url>
</case>
<case repeat=3>
<url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url>
<method>POST</method>
<body><![CDATA[appid=YahooDemo&query=pylot]]></body>
<add_header>Content-type: application/x-www-form-urlencoded</add_header>
</case>
<case repeat=2>
<url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url>
<method>POST</method>
<body><![CDATA[appid=YahooDemo&query=pylot]]></body>
<add_header>Content-type: application/x-www-form-urlencoded</add_header>
</case repeat=3>
<case>
<url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url>
<method>POST</method>
<body><![CDATA[appid=YahooDemo&query=pylot]]></body>
<add_header>Content-type: application/x-www-form-urlencoded</add_header>
</case>
<case>
<url>http://www.example.com</url>
</case>
<case repeat=10>
<url>http://www.example.com</url>
</case>
<!-- SAMPLE TEST CASE -->
<!--
<case>
<url>http://search.yahooapis.com/WebSearchService/V1/webSearch</url>
<method>POST</method>
<body><![CDATA[appid=YahooDemo&query=pylot]]></body>
<add_header>Content-type: application/x-www-form-urlencoded</add_header>
</case>
-->
</testcases>
重要代碼:
| def load_xml_cases_dom(dom): cases = [] param_map = {} for child in dom.getiterator(): if child.tag != dom.getroot().tag and child.tag == 'param': name = child.attrib.get('name') value = child.attrib.get('value') param_map[name] = value if child.tag != dom.getroot().tag and child.tag == 'case': req = Request() repeat = child.attrib.get('repeat') if repeat: req.repeat = int(repeat) else: req.repeat = 1 for element in child: if element.tag.lower() == 'url': req.url = element.text if element.tag.lower() == 'method': req.method = element.text if element.tag.lower() == 'body': file_payload = element.attrib.get('file') if file_payload: req.body = open(file_payload, 'rb').read() else: req.body = element.text if element.tag.lower() == 'verify': req.verify = element.text if element.tag.lower() == 'verify_negative': req.verify_negative = element.text if element.tag.lower() == 'timer_group': req.timer_group = element.text if element.tag.lower() == 'add_header': splat = element.text.split(':') x = splat[0].strip() del splat[0] req.add_header(x, ''.join(splat).strip()) req = resolve_parameters(req, param_map) # substitute vars cases.append(req) return case |
2、Request請(qǐng)求代理部分:
請(qǐng)求代理會(huì)根據(jù)分配給自己的testcase.xml進(jìn)行初始化,獲取所有配置參數(shù)和case列表,當(dāng)接收到agent manager發(fā)給的執(zhí)行消息后,會(huì)開(kāi)啟一個(gè)線程對(duì)case列表中的每一個(gè)case進(jìn)行處理;初始化agent時(shí),agent manager會(huì)傳進(jìn)來(lái)全局的幾個(gè)隊(duì)列,包括result queue,msg queue,error queue;這些queue中的信息最終會(huì)由agent manager統(tǒng)一處理;
重要代碼:
def run(self):
agent_start_time = time.strftime('%H:%M:%S', time.localtime())
total_latency = 0
total_connect_latency = 0
total_bytes = 0
while self.running:
self.cookie_jar = cookielib.CookieJar()
for req in self.msg_queue:
for repeat in range(req.repeat):
if self.running:
request=Request(req)
# send the request message
resp, content, req_start_time, req_end_time, connect_end_time = request.send(req)
# get times for logging and error display
tmp_time = time.localtime()
cur_date = time.strftime('%d %b %Y', tmp_time)
cur_time = time.strftime('%H:%M:%S', tmp_time)
# check verifications and status code for errors
is_error = False
if resp.code >= 400 or resp.code == 0:
is_error = True
if not req.verify == '':
if not re.search(req.verify, content, re.DOTALL):
is_error = True
if not req.verify_negative == '':
if re.search(req.verify_negative, content, re.DOTALL):
is_error = True
if is_error:
self.error_count += 1
error_string = 'Agent %s: %s - %d %s, url: %s' % (self.id + 1, cur_time, resp.code, resp.msg, req.url)
self.error_queue.append(error_string)
log_tuple = (self.id + 1, cur_date, cur_time, req_end_time, req.url.replace(',', ''), resp.code, resp.msg.replace(',', ''))
self.log_error('%s,%s,%s,%s,%s,%s,%s' % log_tuple) # write as csv
resp_bytes = len(content)
latency = (req_end_time - req_start_time)
connect_latency = (connect_end_time - req_start_time)
self.count += 1
total_bytes += resp_bytes
total_latency += latency
total_connect_latency += connect_latency
# update shared stats dictionary
self.runtime_stats[self.id] = StatCollection(resp.code, resp.msg, latency, self.count, self.error_count, total_latency, total_connect_latency, total_bytes)
self.runtime_stats[self.id].agent_start_time = agent_start_time
# put response stats/info on queue for reading by the consumer (ResultWriter) thread
q_tuple = (self.id + 1, cur_date, cur_time, req_end_time, req.url.replace(',', ''), resp.code, resp.msg.replace(',', ''), resp_bytes, latency, connect_latency, req.timer_group)
self.results_queue.put(q_tuple)
expire_time = (self.interval - latency)
if expire_time > 0:
time.sleep(expire_time) # sleep remainder of interval so we keep even pacing
else: # don't go through entire range if stop has been called
break
對(duì)每一個(gè)case初始化為一個(gè)request類實(shí)例,包含這case的測(cè)試數(shù)據(jù),測(cè)試方法和測(cè)試結(jié)果,agent會(huì)實(shí)例化對(duì)立中的每個(gè)case,并在主線程中執(zhí)行測(cè)試方法,獲取相應(yīng)的測(cè)試數(shù)據(jù);
重要代碼,這部分代碼本來(lái)是pylot中的源碼,個(gè)人更傾向于將它放在request中,需要少許更改:
def send(self, req):
# req is our own Request object
if HTTP_DEBUG:
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie_jar), urllib2.HTTPHandler(debuglevel=1))
elif COOKIES_ENABLED:
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie_jar))
else:
opener = urllib2.build_opener()
if req.method.upper() == 'POST':
request = urllib2.Request(req.url, req.body, req.headers)
else:
request = urllib2.Request(req.url, None, req.headers) # urllib2 assumes a GET if no data is supplied. PUT and DELETE are not supported
# timed message send+receive (TTLB)
req_start_time = self.default_timer()
try:
resp = opener.open(request) # this sends the HTTP request and returns as soon as it is done connecting and sending
connect_end_time = self.default_timer()
content = resp.read()
req_end_time = self.default_timer()
except httplib.HTTPException, e: # this can happen on an incomplete read, just catch all HTTPException
connect_end_time = self.default_timer()
resp = ErrorResponse()
resp.code = 0
resp.msg = str(e)
resp.headers = {}
content = ''
except urllib2.HTTPError, e: # http responses with status >= 400
connect_end_time = self.default_timer()
resp = ErrorResponse()
resp.code = e.code
resp.msg = httplib.responses[e.code] # constant dict of http error codes/reasons
resp.headers = dict(e.info())
content = ''
except urllib2.URLError, e: # this also catches socket errors
connect_end_time = self.default_timer()
resp = ErrorResponse()
resp.code = 0
resp.msg = str(e.reason)
resp.headers = {} # headers are not available in the exception
content = ''
req_end_time = self.default_timer()
if self.trace_logging:
# log request/response messages
self.log_http_msgs(req, request, resp, content)
return (resp, content, req_start_time, req_end_time, connect_end_time)
代理管理的主要任務(wù)是創(chuàng)建幾個(gè)重要數(shù)據(jù)的隊(duì)列,實(shí)例化每個(gè)agent并為其創(chuàng)建新的線程。代理管理會(huì)管理這個(gè)線程池,并在這些中重要的隊(duì)列中獲取到測(cè)試的結(jié)果;
重要代碼:
def run(self):
self.running = True
self.agents_started = False
try:
os.makedirs(self.output_dir, 0755)
except OSError:
self.output_dir = self.output_dir + time.strftime('/results_%Y.%m.%d_%H.%M.%S', time.localtime())
try:
os.makedirs(self.output_dir, 0755)
except OSError:
sys.stderr.write('ERROR: Can not create output directory\n')
sys.exit(1)
# start thread for reading and writing queued results
self.results_writer = ResultWriter(self.results_queue, self.output_dir)
self.results_writer.setDaemon(True)
self.results_writer.start()
for i in range(self.num_agents):
spacing = float(self.rampup) / float(self.num_agents)
if i > 0: # first agent starts right away
time.sleep(spacing)
if self.running: # in case stop() was called before all agents are started
agent = LoadAgent(i, self.interval, self.log_msgs, self.output_dir, self.runtime_stats, self.error_queue, self.msg_queue, self.results_queue)
agent.start()
self.agent_refs.append(agent)
agent_started_line = 'Started agent ' + str(i + 1)
if sys.platform.startswith('win'):
sys.stdout.write(chr(0x08) * len(agent_started_line)) # move cursor back so we update the same line again
sys.stdout.write(agent_started_line)
else:
esc = chr(27) # escape key
sys.stdout.write(esc + '[G' )
sys.stdout.write(esc + '[A' )
sys.stdout.write(agent_started_line + '\n')
if sys.platform.startswith('win'):
sys.stdout.write('\n')
print '\nAll agents running...\n\n'
self.agents_started = True
def stop(self):
self.running = False
for agent in self.agent_refs:
agent.stop()
if WAITFOR_AGENT_FINISH:
keep_running = True
while keep_running:
keep_running = False
for agent in self.agent_refs:
if agent.isAlive():
keep_running = True
time.sleep(0.1)
self.results_writer.stop()
代理中獲取的數(shù)據(jù)最終寫(xiě)到一個(gè)csv文件中,在代理部分的執(zhí)行函數(shù)完成后,讀取這個(gè)文件的內(nèi)容,生成相關(guān)的結(jié)果數(shù)據(jù)和圖片(圖片在python中傾向于使用matlibplot包)。最終將其寫(xiě)成html的結(jié)果報(bào)告形式:
重要代碼:
| def generate_results(dir, test_name): print '\nGenerating Results...' try: merged_log = open(dir + '/agent_stats.csv', 'rb').readlines() # this log contains commingled results from all agents except IOError: sys.stderr.write('ERROR: Can not find your results log file\n') merged_error_log = merge_error_files(dir) if len(merged_log) == 0: fh = open(dir + '/results.html', 'w') fh.write(r'<html><body><p>None of the agents finished successfully. There is no data to report.</p></body></html>\n') fh.close() sys.stdout.write('ERROR: None of the agents finished successfully. There is no data to report.\n') return timings = list_timings(merged_log) best_times, worst_times = best_and_worst_requests(merged_log) timer_group_stats = get_timer_groups(merged_log) timing_secs = [int(x[0]) for x in timings] # grab just the secs (rounded-down) throughputs = calc_throughputs(timing_secs) # dict of secs and throughputs throughput_stats = corestats.Stats(throughputs.values()) resp_data_set = [x[1] for x in timings] # grab just the timings response_stats = corestats.Stats(resp_data_set) # calc the stats and load up a dictionary with the results stats_dict = get_stats(response_stats, throughput_stats) # get the pickled stats dictionaries we saved runtime_stats_dict, workload_dict = load_dat_detail(dir) # get the summary stats and load up a dictionary with the results summary_dict = {} summary_dict['cur_time'] = time.strftime('%m/%d/%Y %H:%M:%S', time.localtime()) summary_dict['duration'] = int(timings[-1][0] - timings[0][0]) + 1 # add 1 to round up summary_dict['num_agents'] = workload_dict['num_agents'] summary_dict['req_count'] = len(timing_secs) summary_dict['err_count'] = len(merged_error_log) summary_dict['bytes_received'] = calc_bytes(merged_log) # write html report fh = open(dir + '/results.html', 'w') reportwriter.write_head_html(fh) reportwriter.write_starting_content(fh, test_name) reportwriter.write_summary_results(fh, summary_dict, workload_dict) reportwriter.write_stats_tables(fh, stats_dict) reportwriter.write_images(fh) reportwriter.write_timer_group_stats(fh, timer_group_stats) reportwriter.write_agent_detail_table(fh, runtime_stats_dict) reportwriter.write_best_worst_requests(fh, best_times, worst_times) reportwriter.write_closing_html(fh) fh.close() # response time graph def resp_graph(nested_resp_list, dir='./'): fig = figure(figsize=(8, 3)) # image dimensions ax = fig.add_subplot(111) ax.set_xlabel('Elapsed Time In Test (secs)', size='x-small') ax.set_ylabel('Response Time (secs)' , size='x-small') ax.grid(True, color='#666666') xticks(size='x-small') yticks(size='x-small') axis(xmin=0) x_seq = [item[0] for item in nested_resp_list] y_seq = [item[1] for item in nested_resp_list] ax.plot(x_seq, y_seq, color='blue', linestyle='-', linewidth=1.0, marker='o', markeredgecolor='blue', markerfacecolor='yellow', markersize=2.0) savefig(dir + 'response_time_graph.png') # throughput graph def tp_graph(throughputs_dict, dir='./'): fig = figure(figsize=(8, 3)) # image dimensions ax = fig.add_subplot(111) ax.set_xlabel('Elapsed Time In Test (secs)', size='x-small') ax.set_ylabel('Requests Per Second (count)' , size='x-small') ax.grid(True, color='#666666') xticks(size='x-small') yticks(size='x-small') axis(xmin=0) keys = throughputs_dict.keys() keys.sort() values = [] for key in keys: values.append(throughputs_dict[key]) x_seq = keys y_seq = values ax.plot(x_seq, y_seq, color='red', linestyle='-', linewidth=1.0, marker='o', markeredgecolor='red', markerfacecolor='yellow', markersize=2.0) savefig(dir + 'throughput_graph.png') try: # graphing only works on systems with Matplotlib installed print 'Generating Graphs...' import graph graph.resp_graph(timings, dir=dir+'/') graph.tp_graph(throughputs, dir=dir+'/') except: sys.stderr.write('ERROR: Unable to generate graphs with Matplotlib\n') print '\nDone generating results. You can view your test at:' print '%s/results.html\n' % dir |
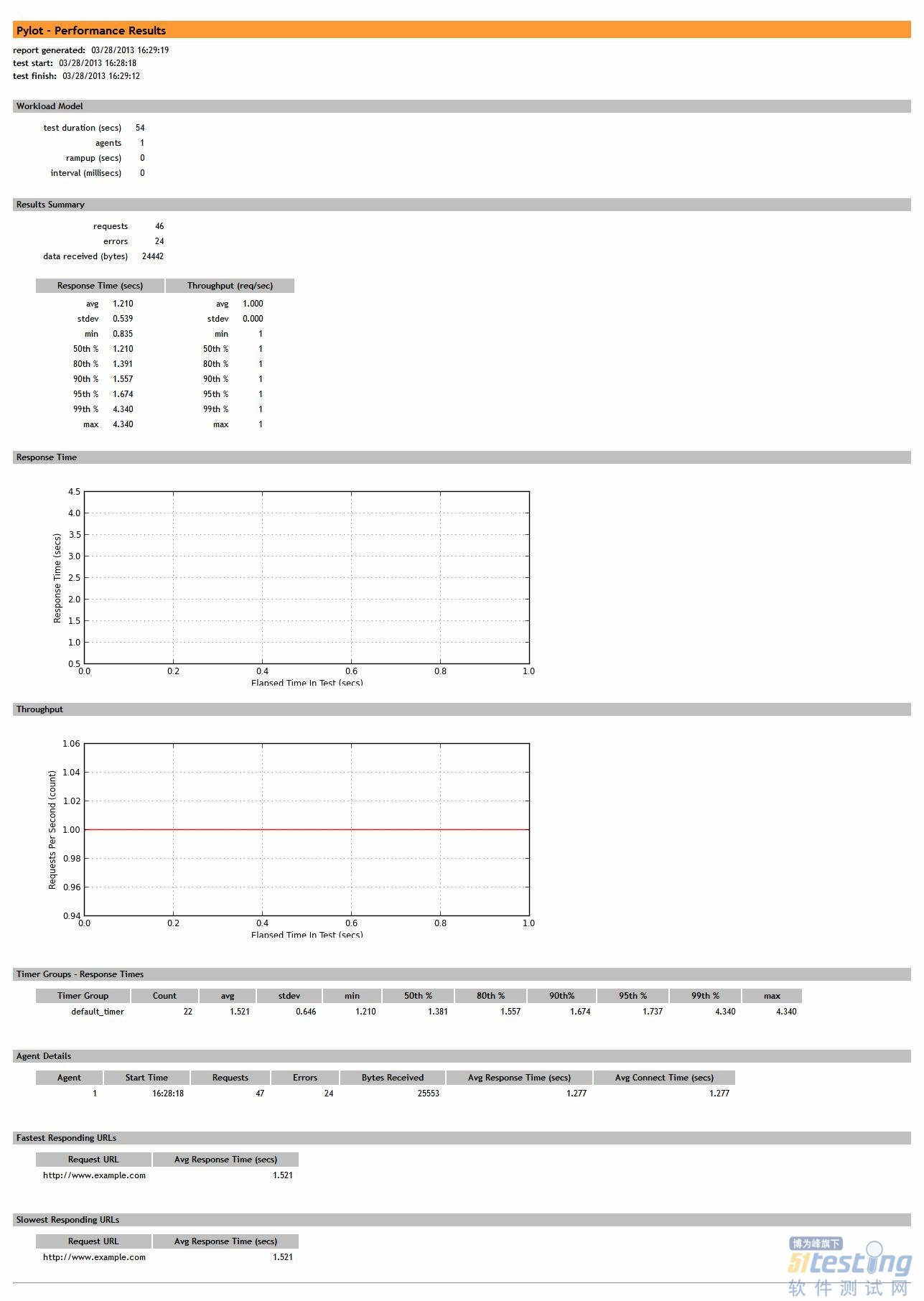
對(duì)于項(xiàng)目的運(yùn)行,既可以采取控制臺(tái)方式,也可以提供給QA人員GUI的方式。Pylot中提供了很好的GUI支持,可以作為示例使用。實(shí)際上不 建議使用GUI的方式,另外pylot中沒(méi)有用戶指定策略的支持,這個(gè)需要自己專門(mén)進(jìn)行開(kāi)發(fā);另外就是pylot中的類封裝結(jié)構(gòu)還不是很好,對(duì)以后的擴(kuò)展 來(lái)說(shuō)還需要一定的更改。但是作為一般使用已經(jīng)足夠了,下面是pylot的最終報(bào)告結(jié)果(只做實(shí)例使用)。