沒(méi)有用的索引
正如在上一小節(jié)所的講的,創(chuàng)建一個(gè)索引是一個(gè)非常需要重視的問(wèn)題,需要考慮很多的方面,因?yàn)椋绻覀兘⒌乃饕龥](méi)有發(fā)揮作用,甚至說(shuō),查詢優(yōu)化器不采用我們的索引,那么就會(huì)帶來(lái)適得其反的效果。
索引的維護(hù)是需要成本,甚至使得數(shù)據(jù)庫(kù)的性能變得很低,特別實(shí)在數(shù)據(jù)更新的時(shí)候。當(dāng)在數(shù)據(jù)表上面進(jìn)行數(shù)據(jù)的更新,刪除,和插入的時(shí)候,都會(huì)導(dǎo)致索引頁(yè)發(fā)生重新的調(diào)整,導(dǎo)致索引頁(yè)中的數(shù)據(jù)重新的排序,從而導(dǎo)致數(shù)據(jù)表被鎖定。
所以,我們很有必要找出沒(méi)有發(fā)揮作用的索引,我們還是可以采用DMV來(lái)快速的查看:
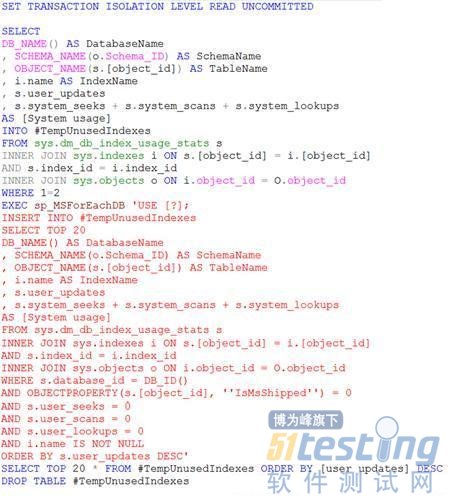
這里不否認(rèn),要完全明白上面的查詢的意思卻不是一件容易的事情,大家可以暫時(shí)不用懂,可以把這些腳本保存起來(lái),作為一個(gè)小的工具使用。
查詢結(jié)果如下:

因?yàn)槲疫@里采用的是一個(gè)示例數(shù)據(jù)庫(kù),所以看到的結(jié)果不是很多,但是可以發(fā)現(xiàn):這些索引一些在被不斷的更新(user_updates),但是沒(méi)有被用過(guò)(system usage)。
對(duì)無(wú)用索引的解決很簡(jiǎn)單:刪除索引就OK了。
關(guān)于腳本,請(qǐng)大家在附件中下載,可以保留起來(lái),并且大家還可以修改,查詢指定的數(shù)據(jù)庫(kù)的情況。
附件:
scripts.zip 我們通過(guò)減少查詢中的不必要的讀取操作從而使得查詢的性能得到提升。一個(gè)查詢?cè)?a href="" target="_self" style="word-break: break-all; text-decoration: none; line-height: normal !important; ">
數(shù)據(jù)庫(kù)中執(zhí)行的讀操作越多,那么就對(duì)磁盤,CPU,內(nèi)存的壓力越大。除非整個(gè)數(shù)據(jù)庫(kù)的數(shù)據(jù)全在在內(nèi)存中,否則每次的讀操作都會(huì)把數(shù)據(jù)從磁盤讀入到內(nèi)存中,然后返回。
一個(gè)查詢?cè)谧x取一個(gè)資源的時(shí)候,通過(guò)加鎖會(huì)阻止其他的查詢對(duì)這個(gè)資源進(jìn)行修改,此時(shí)其他要操作這個(gè)資源的查詢就需要等待,從而導(dǎo)致了延時(shí)。
誠(chéng)然,有些等待是必須的,讀取操作也是必須的,但是一些因?yàn)槲覀兇a或者設(shè)計(jì)導(dǎo)致的過(guò)度的讀取操作和等待,那就會(huì)嚴(yán)重影響性能,尤其是當(dāng)數(shù)據(jù)庫(kù)的訪問(wèn)量開(kāi)始變大的時(shí)候。
可以說(shuō)在SQL Server中,最高效的讀取數(shù)據(jù)方式就是通過(guò)索引去獲取數(shù)據(jù)。如果在數(shù)據(jù)表中存在缺失索引的問(wèn)題,結(jié)果可想而知。
在本篇中,我們將會(huì)討論下面幾個(gè)議題:
● 如何識(shí)別缺失索引性能問(wèn)題
● 識(shí)別沒(méi)有用的索引
● 如何解決上面的問(wèn)題
確實(shí)本篇講述的內(nèi)容涉及到了一些與數(shù)據(jù)庫(kù)性能調(diào)優(yōu)的話題,對(duì)于調(diào)優(yōu)而言,難點(diǎn)很多時(shí)候在于如何正確的找出性能問(wèn)題。
下面,我們首先來(lái)看看缺失索引。
缺失索引
SQL Server可以在表字段上面建立索引,從而使得Where和Join這樣的語(yǔ)句執(zhí)行的更快。當(dāng)查詢優(yōu)化器在優(yōu)化一個(gè)查詢的時(shí)候,它會(huì)保存一些來(lái)暗示哪些列上可能建立索引之后可能性能會(huì)更快的信息。我們可以通過(guò)動(dòng)態(tài)管理視圖sys.dm_db_missing_index_details來(lái)查看,運(yùn)行如下查詢

查詢的結(jié)果如下:
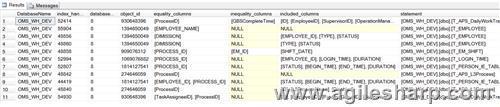
下面,我們就來(lái)稍微的解釋一下結(jié)果中主要字段的含義:
字段名字 | 說(shuō)明 |
DatabaseName | 告訴我們是哪一個(gè)數(shù)據(jù)庫(kù)上面存在缺失索引的問(wèn)題 |
equality_columns | 如果在某個(gè)字段上面進(jìn)行了相等的操作,例如Name=’Agilesharp’,在Name字段上面進(jìn)行了判等的操作,如果查詢優(yōu)化器認(rèn)為這個(gè)Name上面缺失索引,那么這個(gè)Name就會(huì)出現(xiàn)在上述查詢的結(jié)果中。 多個(gè)字段,用逗號(hào)分割 |
inquality_columns | 在某個(gè)字段上進(jìn)行了不等的操作,例如ID>1等,如果ID上面存在缺失索引,那么ID就會(huì)出現(xiàn)在這里 |
Included_columns | 告訴我們那些數(shù)據(jù)列可以作為索引包含列放在索引中,從而減少書簽查找的開(kāi)銷 |
Statement | 告訴哪一個(gè)表上面存在缺失索引的問(wèn)題 |
當(dāng)然,上面的DMV查詢所得到的結(jié)果只是推薦結(jié)果,至于是否要去在相應(yīng)的列上面建立索引,還需要進(jìn)行綜合的分析,不能單靠一方面來(lái)判斷,例如,我們可以在去制定一些計(jì)劃去運(yùn)行SQL Profiler去跟蹤數(shù)據(jù)庫(kù),然后分析跟蹤的數(shù)據(jù),并且分析這個(gè)列的數(shù)據(jù)的分布情況,分析數(shù)據(jù)的密度和差異性,而且還可以進(jìn)一步的分析列的統(tǒng)計(jì)信息,然后決定是否要加索引。
注:我也正在寫SQL Server Profiler的文章,還沒(méi)有發(fā)布,請(qǐng)大家耐心等待。另外SQL Server的調(diào)優(yōu)是個(gè)非常深的話題,大家可以通過(guò)我這里的一些問(wèn)題在掌握一些所謂的小技巧,起到一個(gè)拋磚引玉的作用!
說(shuō)了這么多,可能大家感覺(jué)像是沒(méi)有說(shuō),感覺(jué)有點(diǎn)虛。確實(shí),我也感覺(jué)這樣,因?yàn)榫瓦@分析缺失索引的問(wèn)題要考慮的問(wèn)題就N多。agilesharp的其他系列文章也在討論SQL Server的性能問(wèn)題,這里,我們就不多說(shuō),也不把問(wèn)題搞復(fù)雜了。我再送朋友一段分析的代碼,可以更好的幫助我們找到缺失索引的問(wèn)題:

上面的查詢比較不錯(cuò),按照成本進(jìn)行了分析,成本越大,就說(shuō)明加了索引之后,收益就越大,可以看到如下的結(jié)果:

然后大家加了索引之后,可以多多的測(cè)試,可以查看執(zhí)行計(jì)劃,也可以查看查詢的數(shù)據(jù)頁(yè)的讀取情況,I/O的情況:
