本文github地址
你可能沒意識到Java對函數式編程的重視程度,看看Java 8加入函數式編程擴充多少功能就清楚了。Java 8之所以費這么大功夫引入函數式編程,原因有二:
- 代碼簡潔,函數式編程寫出的代碼簡潔且意圖明確,使用stream接口讓你從此告別for循環。
- 多核友好,Java函數式編程使得編寫并行程序從未如此簡單,你需要的全部就是調用一下
parallel()方法。
這一節我們學習stream,也就是Java函數式編程的主角。對于Java 7來說stream完全是個陌生東西,stream并不是某種數據結構,它只是數據源的一種視圖。這里的數據源可以是一個數組,Java容器或I/O channel等。正因如此要得到一個stream通常不會手動創建,而是調用對應的工具方法,比如:
- 調用
Collection.stream()或者Collection.parallelStream()方法
- 調用
Arrays.stream(T[] array)方法
常見的stream接口繼承關系如圖:

圖中4種stream接口繼承自BaseStream,其中IntStream, LongStream, DoubleStream對應三種基本類型(int, long, double,注意不是包裝類型),Stream對應所有剩余類型的stream視圖。為不同數據類型設置不同stream接口,可以1.提高性能,2.增加特定接口函數。
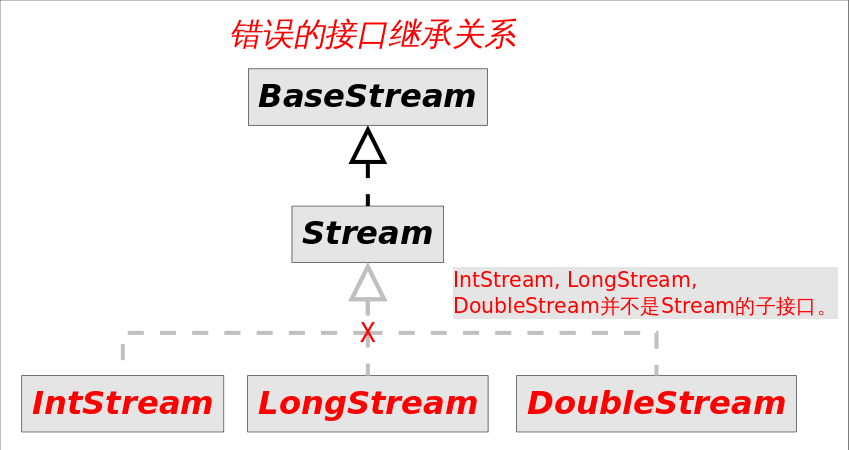
你可能會奇怪為什么不把IntStream等設計成Stream的子接口?畢竟這接口中的方法名大部分是一樣的。答案是這些方法的名字雖然相同,但是返回類型不同,如果設計成父子接口關系,這些方法將不能共存,因為Java不允許只有返回類型不同的方法重載。
雖然大部分情況下stream是容器調用Collection.stream()方法得到的,但stream和collections有以下不同:
- 無存儲。stream不是一種數據結構,它只是某種數據源的一個視圖,數據源可以是一個數組,Java容器或I/O channel等。
- 為函數式編程而生。對stream的任何修改都不會修改背后的數據源,比如對stream執行過濾操作并不會刪除被過濾的元素,而是會產生一個不包含被過濾元素的新stream。
- 惰式執行。stream上的操作并不會立即執行,只有等到用戶真正需要結果的時候才會執行。
- 可消費性。stream只能被“消費”一次,一旦遍歷過就會失效,就像容器的迭代器那樣,想要再次遍歷必須重新生成。
對stream的操作分為為兩類,中間操作(intermediate operations)和結束操作(terminal operations),二者特點是:
- 中間操作總是會惰式執行,調用中間操作只會生成一個標記了該操作的新stream,僅此而已。
- 結束操作會觸發實際計算,計算發生時會把所有中間操作積攢的操作以pipeline的方式執行,這樣可以減少迭代次數。計算完成之后stream就會失效。
如果你熟悉Apache Spark RDD,對stream的這個特點應該不陌生。
下表匯總了Stream接口的部分常見方法:
| 中間操作 |
concat() distinct() filter() flatMap() limit() map() peek()
skip() sorted() parallel() sequential() unordered() |
| 結束操作 |
allMatch() anyMatch() collect() count() findAny() findFirst()
forEach() forEachOrdered() max() min() noneMatch() reduce() toArray() |
區分中間操作和結束操作最簡單的方法,就是看方法的返回值,返回值為stream的大都是中間操作,否則是結束操作。
stream方法使用
stream跟函數接口關系非常緊密,沒有函數接口stream就無法工作。回顧一下:函數接口是指內部只有一個抽象方法的接口。通常函數接口出現的地方都可以使用Lambda表達式,所以不必記憶函數接口的名字。
forEach()
我們對forEach()方法并不陌生,在Collection中我們已經見過。方法簽名為void forEach(Consumer<? super E> action),作用是對容器中的每個元素執行action指定的動作,也就是對元素進行遍歷。
// 使用Stream.forEach()迭代
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.forEach(str -> System.out.println(str));
由于forEach()是結束方法,上述代碼會立即執行,輸出所有字符串。
filter()
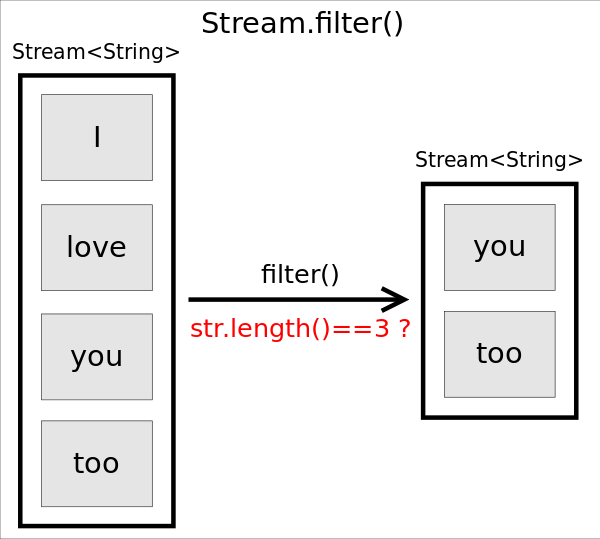
函數原型為Stream<T> filter(Predicate<? super T> predicate),作用是返回一個只包含滿足predicate條件元素的Stream。
// 保留長度等于3的字符串
Stream<String> stream= Stream.of("I", "love", "you", "too");
stream.filter(str -> str.length()==3)
.forEach(str -> System.out.println(str));
上述代碼將輸出為長度等于3的字符串you和too。注意,由于filter()是個中間操作,如果只調用filter()不會有實際計算,因此也不會輸出任何信息。
distinct()

函數原型為Stream<T> distinct(),作用是返回一個去除重復元素之后的Stream。
Stream<String> stream= Stream.of("I", "love", "you", "too", "too");
stream.distinct()
.forEach(str -> System.out.println(str));
上述代碼會輸出去掉一個too之后的其余字符串。
sorted()
排序函數有兩個,一個是用自然順序排序,一個是使用自定義比較器排序,函數原型分別為Stream<T> sorted()和Stream<T> sorted(Comparator<? super T> comparator)。
Stream<String> stream= Stream.of("I", "love", "you", "too");
stream.sorted((str1, str2) -> str1.length()-str2.length())
.forEach(str -> System.out.println(str));
上述代碼將輸出按照長度升序排序后的字符串,結果完全在預料之中。
map()
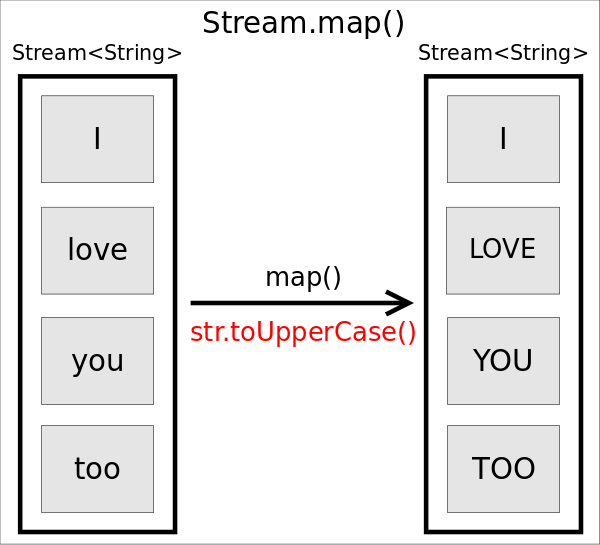
函數原型為<R> Stream<R> map(Function<? super T,? extends R> mapper),作用是返回一個對當前所有元素執行執行mapper之后的結果組成的Stream。直觀的說,就是對每個元素按照某種操作進行轉換,轉換前后Stream中元素的個數不會改變,但元素的類型取決于轉換之后的類型。
Stream<String> stream = Stream.of("I", "love", "you", "too");
stream.map(str -> str.toUpperCase())
.forEach(str -> System.out.println(str));
上述代碼將輸出原字符串的大寫形式。
flatMap()
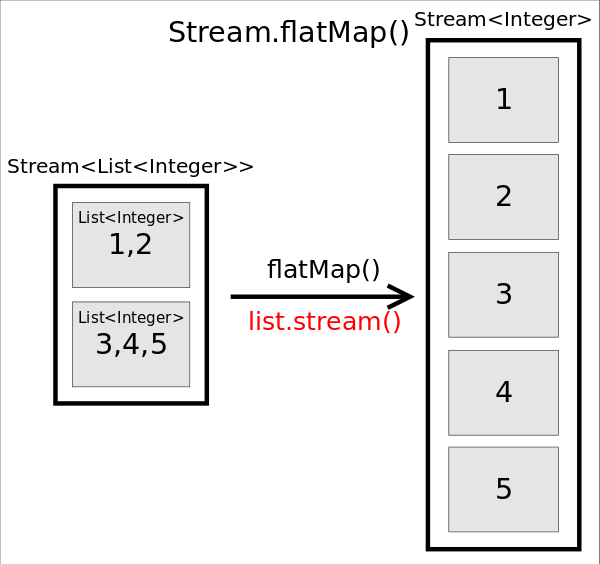
函數原型為<R> Stream<R> flatMap(Function<? super T,? extends Stream<? extends R>> mapper),作用是對每個元素執行mapper指定的操作,并用所有mapper返回的Stream中的元素組成一個新的Stream作為最終返回結果。說起來太拗口,通俗的講flatMap()的作用就相當于把原stream中的所有元素都"攤平"之后組成的Stream,轉換前后元素的個數和類型都可能會改變。
Stream<List<Integer>> stream = Stream.of(Arrays.asList(1,2), Arrays.asList(3, 4, 5));
stream.flatMap(list -> list.stream())
.forEach(i -> System.out.println(i));
上述代碼中,原來的stream中有兩個元素,分別是兩個List<Integer>,執行flatMap()之后,將每個List都“攤平”成了一個個的數字,所以會新產生一個由5個數字組成的Stream。所以最終將輸出1~5這5個數字。
結語
截止到目前我們感覺良好,已介紹StreamAPI理解起來并不費勁兒。如果你就此以為函數式編程不過如此,恐怕是高興地太早了。下一節對Stream規約操作的介紹將刷新你現在的認識。
本文github地址,歡迎關注。