一. 應用場景
在大型分布式應用中,我們經常碰到在多數據庫之間的數據同步問題,比如說一款游戲,在玩家注冊后,可以馬上登陸進入服務器,即數據在一個IDC更新,其它IDC立即可見。為了簡化思路,我們這里稱玩家注冊的數據庫(數據來源庫)為中心庫,同步目的地的數據庫為分站庫。
在分布式領域有個CAP理論,是說Consistency(一致性), Availability(可用性), Partition tolerance(分區和容錯) 三部分在系統實現只可同時滿足二點,無法三者兼顧。
能做的
· 數據快速搬運到指定的IDC節點
· 數據傳遞過程中失敗時,重新傳遞
· 監控數據傳遞流程
· 故障轉移
· 數據版本控制
· 分配全局唯一的ID
不能做的
· 不參與業務行為,業務操作只能通過注冊的方式集成
· 不保存業務數據,不提供傳遞的業務的查詢
二.系統要求
1.數據快速同步:除去網絡原因,正常情況下從來源庫同步到接收庫的時間不超過300m2.高并發:單個應用每秒同步2000條記錄
3.可伸縮性,在資源達到上限時能通過增加應用分散處理后期增長的壓力
4.數據完整性要求,在數據同步過程中保證數據不丟失和數據安全
5.故障轉移和數據恢復功能
三.設計思路
系統優化,最常用的就是進行業務切割,將總任務切割為許多子任務,分區塊分析系統中可能存在的性能瓶頸并有針對性地進行優化,在本系統中,主要業務包含以下內容:
1.Syncer:外部接口,接收同步數據請求,初始化同步系統的一些必要數據
2.Delivery:將同步數據按照業務或優先級進行分發,并記錄分發結果
3.Batch:分站庫收到同步數據后,根據不同的業務類型調用相應的業務邏輯處理數據
基于以上三塊業務功能,我們可以把整個數據同步流程切割為3個應用,具體如下圖顯示。在Syncer端應用中,我們需要將原始同步數據和分發的分站進行存儲,以備失敗恢復,此時如果采用數據庫進行存儲,勢必會受限于數據庫性能影響,因此我們采用了高效的key-value風格存儲的redis服務來記錄數據,同時在不同應用之間采用隊列(Httpsqs服務)的方式來進行通訊,同時也保證的數據通訊的順序性,為之后的順序同步做好基礎。
Httpsqs提供了http風格的數據操作模式,業務編碼非常簡單,同時也提供了web形式的隊列處理情況查詢,這是選擇它做隊列服務很大一部分原因:方便業務操作和性能監控。
四.數據流轉
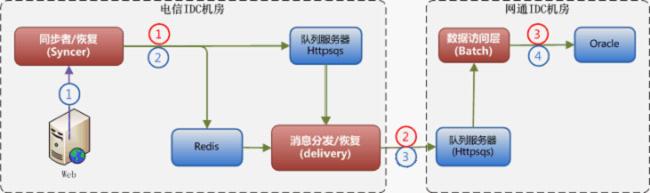
綠色-正常流程、紅色-異常流程
隊列處理
根據業務劃分隊列名稱,每個隊列再劃分為三個關聯隊列:正常隊列(Normal)、重試隊列(Retry)、死亡隊列(Death),處理流程為:
1 【進程A】把數據先放入正常隊列,如果放置失敗寫恢復日志
2 【進程B】監聽正常隊列,獲取隊列數據并進行業務處理,處理失敗放入重試隊列
3 【進程C】監聽重試隊列,過幾秒獲取隊列數據并重新進行業務處理,處理失敗放入死亡隊列
4 【進程D】監聽死亡隊列,獲取隊列數據并重新進行業務處理,處理失敗重新放入死亡隊列尾部,等待下一次輪回
業務處理失敗如果無法再次放入隊列,記錄恢復日志
數據同步流程
1發送數據,支持Http POST:curl -d "經過URL編碼的文本消息",如"http://host:port/sync_all/register"
或者Http GET:curl "http://host:port/sync_all/register?data=經過URL編碼的文本消息"
5 sync-syncer接收到同步數據請求,創建sid并分解出需要同步的節點個數,把原始數據和子任務寫入redis中,sid寫入httpsqs中
6 sync-delivery監聽中心httpsqs隊列,根據sid從redis獲取到原始數據和需要同步的節點地址,往其他節點發送數據,流程如按"隊列處理流程"進行
7 sync-batch監聽分節點的httpsqs隊列,調用已經注冊的處理器處理隊列數據,流程如按"隊列處理流程"進行
三. 恢復和監控
恢復數據源
· httpsqs中的死亡隊列 - 業務處理暫時處理不了的數據
· recovery日志文件 - 其它異常情況下的數據,例如網絡無法連接、內部服務不可用
數據恢復
獨立的應用來處理正常流程中沒有完成的任務,主要功能有:
· 監聽死亡隊列,進行業務重做,再次執行失敗時將執行次數+1,最大執行次數為5(默認),超出上限則記錄到恢復日志中
· 讀取恢復日志,重新放入死亡隊列
應用監控
· 使用scribe日志框架服務業務日志的采集和監控
· 收集重要的業務操作日志
· 動態的開啟/關閉某類業務日志
· 對redis進行監控
· 對httpsps,監控隊列個數,每個隊列的狀態
四. 數據結構
{"sid":111,"type":"reg","v":1,"data":"hello world","ctime":65711321800,"exec":1}
· sid(sync id) - 全局唯一id
· v(version) - 版本號
· data - 業務數據
· ctime(create time) - 創建時間(毫秒)
· exec - 可選,執行次數
|
類別
|
key格式
|
value格式
|
備注
|
|
redis原始數據
|
sync:<業務類型>:<sid>
|
{"ctime":65711321800,"v":1,"data":"hello world"}
|
分站沒有此項
|
|
redis業務附加任務
|
sync:<業務類型>:<sid>:sub
|
set類型,保存需要同步的節點id,例如[1,3,5]
|
分發確認Set數據結構
|
|
httpsqs隊列
|
sync:<業務類型>
sync:<業務類型>:retry
sync:<業務類型>:death
|
{"sid":111,"type":"pp_register","exec":1}
|
中心隊列內容,key中<業務類型>是可選項
|
|
httpsqs隊列
|
sync:<業務類型>
sync:<業務類型>:retry
sync:<業務類型>:death
|
{"sid":111,"v":1,"data":"hello world","ctime":65711321800,"exec":1}
|
分站隊列內容,包含業務數據
|
所有的key都小寫,以 ':' 作為分隔符
五.編碼及測試結果
經過編碼和測試,在內網環境下,在無數據庫限制的情況下,單應用可以傳遞1500條/秒,基本滿足業務需求。如果需進一步擴展,采用集群式布署可使得吞吐量成倍的增長。