摘要: 商業智能(BI,Business Intelligence)。商業智能的概念最早在1996年提出。當時將商業智能定義為一類由數據倉庫(或數據集市)、查詢報表、數據分析、數據挖掘、數據備份和恢復等部分組成的、以幫助企業決策為目的技術及其應用。目前,商業智能通常被理解為將企業中現有的數據轉化為知識,幫助企業做出明智的業務經營決策的工具。商務智能系統中的數據來自企業其他業務系統。例如商貿型企業,其商務智...
閱讀全文
現在是一個Google的時代,而對于開發者,開源已成為最重要的參考書。對于某課題,不管你是深入研究還是初窺門徑。估且google一把,勾一勾同行的成就,你必會獲益良多。
說到ETL開源項目,Kettle當屬翹首,因此,偶決定花點時間了解一下。
項目名稱很有意思,水壺。按項目負責人Matt的說法:把各種數據放到一個壺里,然后呢,以一種你希望的格式流出。呵呵,外國人都很有聯想力。
看了提供的文檔,然后對發布程序的簡單試用后,可以很清楚得看到Kettle的四大塊:
Chef——工作(job)設計工具 (GUI方式)
Kitchen——工作(job)執行器 (命令行方式)
Spoon——轉換(transform)設計工具 (GUI方式)
Span——轉換(trasform)執行器 (命令行方式)
嗯,廚師已經在廚房里,勺子和盤子一應俱全,且看能做出如何的大餐?
一:Chef——工作(job)設計器
這是一個GUI工具,操作方式主要通過拖拖拉拉,勿庸多言,一看就會。
何謂工作? 多個作業項,按特定的工作流串聯起來,開成一項工作。正如:我的工作是軟件開發。我的作業項是:設計、編碼、測試!先設計,如果成功,則編碼,否則繼續設計,編碼完成則開始設計,周而復始,作業完成。
來,看看Chef中的作業項:
1.1: 轉換:指定更細的轉換任務,通過Spoon生成。通過Field來輸入參數。
1.2: SQL:sql語句執行,
1.3: FTP:下載ftp文件。
1.4: 郵件:發送郵件。
1.5: 檢查表是否存在,
1.6: 檢查文件是否存在,
1.7: 執行shell腳本。如:dos命令。
1.8: 批處理。(注意:windows批處理不能有輸出到控制臺)。
1.9: Job包。作為嵌套作業使用。
1.10:JavaScript執行。這個比較有意思,我看了一下源碼,如果你有自已的Script引擎,可以很方便的替換成自定義Script,來擴充其功能。
1.11:SFTP:安全的Ftp協議傳輸。
1.12:HTTP方式的上/下傳。
好了,看看工作流:
如上文所述,工作流是作業項的連接方式。分為三種:無條件,成功,失敗。這個沒啥好說的,從名字就能知道它的意圖。
嗯,為了方便工作流使用,提供了幾個輔助結點單元(你也可將其作為簡單的作業項):
1:Start單元,任務必須由此開始。設計作業時,以此為起點。
2:OK單元:可以編制做為中間任務單元,且進行腳本編制,用來控制流程。
3:ERROR單元:用途同上。
4:DUMMY單元:啥都不做,主要是用來支持多分支的情況。文檔中有例子,不再多說。
存儲方式:
支持XML存儲,或存儲到指定數據庫中。
一些默認的配置(如數據庫存儲位置……),在系統的用戶目錄下,單獨建立了一個.Kettle目錄,用來保存用戶的這些設置。
LogView:可查看執行日志。
二:Kitchen——作業執行器
是一個作業執行引擎,用來執行作業。這是一個命令行執行工具,沒啥可講的,就把它的參數說明列一下。
-rep : Repository name 任務包所在存儲名
-user : Repository username 執行人
-pass : Repository password 執行人密碼
-job : The name of the job to launch 任務包名稱
-dir : The directory (don't forget the leading / or /)
-file : The filename (Job XML) to launch
-level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志級別
-log : The logging file to write to 指定日志文件
-listdir : List the directories in the repository 列出指定存儲中的目錄結構。
-listjobs : List the jobs in the specified directory 列出指定目錄下的所有任務
-listrep : List the defined repositories 列出所有的存儲
-norep : Don't log into the repository 不寫日志
嗯,居然不支持調度。看了一下文檔,建議使用操作系統提供的調度器來實現調度,比如:Windows可以使用它的任務計劃工具。
三:Spoon——轉換過程設計器
GUI工作,用來設計數據轉換過程,創建的轉換可以由Pan來執行,也可以被Chef所包含,作為作業中的一個作業項。
下面簡單列舉一下所有的轉換過程。(簡單描述,詳細的可見Spoon文檔)
3.1:Input-Steps:輸入步驟
3.1.1:Text file input:文本文件輸入,
可以支持多文件合并,有不少參數,基本一看參數名就能明白其意圖。
3.1.2:Table input:數據表輸入
實際上是視圖方式輸入,因為輸入的是sql語句。當然,需要指定數據源(數據源的定制方式在后面講一下)
3.1.3:Get system info:取系統信息
就是取一些固定的系統環境值,如本月最后一天的時間,本機的IP地址之類。
3.1.4:Generate Rows:生成多行。
這個需要匹配使用,主要用于生成多行的數據輸入,比如配合Add sequence可以生成一個指定序號的數據列。
3.1.5:XBase Input:
3.1.6:Excel Input:
3.1.7:XML Input:
這三個沒啥可講的,看看參數就明了。
3.2:Output-Steps: 輸出步聚
3.2.1:Text file output:文本文件輸出。
這個用來作測試蠻好,呵呵。很方便的看到轉換的輸出。
3.2.2:Table output:輸出到目的表。
3.2.3:Insert/Update:目的表和輸入數據行進行比較,然后有選擇的執行增加,更新操作。
3.2.4:Update:同上,只是不支持增加操作。
3.2.5:XML Output:
3.3:Look-up:查找操作
DataBase:
Stream:
Procedure:
Database join:
很簡單,看看參數就明白了。
3.4:Transform 轉換 (嗯,重點)
3.4.1:Select values: 對輸入的行記錄數據 的字段進行更改 (更改數據類型,更改字段名或刪除)
數據類型變更時,數據的轉換有固定規則,可簡單定制參數。可用來進行數據表的改裝。
3.4.2: Filter rows: 對輸入的行記錄進行 指定復雜條件 的過濾。
用途可擴充sql語句現有的過濾功能。但現有提供邏輯功能超出標準sql的不多。
3.4.3:Sort rows:對指定的列以升序或降序排序,當排序的行數超過5000時需要臨時表。
3.4.4:Add sequence:為數據流增加一個序列,
這個配合其它Step(Generate rows, rows join),可以生成序列表,如日期維度表(年、月、日)。
3.4.5:Dummy:不做任何處理,主要用來作為分支節點。
3.4.6:Join Rows:對所有輸入流做笛卡兒乘積。
3.4.7:Aggregate:聚合,分組處理
3.4.8:Group by:分組
用途可擴充sql語句現有的分組,聚合函數。但我想可能會有其它方式的sql語句能實現。
3.4.9:Java Script value:使用mozilla的rhino作為腳本語言,并提供了很多函數,用戶可以在腳本中使用這些函數。
3.4.10. Row Normaliser:該步驟可以從透視表中還原數據到事實表,
通過指定維度字段及其分類值,度量字段,最終還原出事實表數據。
3.4.11. Unique rows:去掉輸入流中的重復行
在使用該節點前要先排序,否則只能刪除連續的重復行。
3.4.12. Calculator:提供了一組函數對列值進行運算,
所介紹,使用該方式比用戶自定義JAVA SCRIPT腳本速度更快。
3.4.13. Merge Rows:用于比較兩組輸入數據,一般用于更新后的數據重新導入到數據倉庫中。
3.4.14. Add constants:增加常量值。
這個我沒弄明白它的用法???
3.4.15. Row denormaliser:同Normaliser過程相反。
3.4.16. Row flattener:表扁平化處理
指定需處理的字段和扃平化后的新字段,將其它字段做為組合Key進行扃平化處理。
3.5:Extra:除了上述基本節點類型外還定義了擴展節點類型
3.5.1:SPLIT FIELDS, 按指定分隔符拆分字段
3.5.2:EXECUTE SQL SCRIPT,執行SQL語句
3.5.3:CUBE INPUT,
3.5.4:CUBE OUTPUT等。
這兩個沒明白是啥意思。
3.6:其它
存儲方式: 與Chef相同。
數據源(Connection);見后。
Hops:setp連接起來,形成Hops。
Plugin step types等節點:這個沒仔細看,不知如何制作Plugin step。
LogView:可查看執行日志。
四:Pan——轉換的執行工具
命令行執行方式,可以執行由Spoon生成的轉換任務。
同樣,不支持調度。
參數與Kitchen類似,可參見Pan的文檔。
五:其它
Connection:
可以配置多個數據源,在Job或是Trans中使用,這意味著可以實現跨數據庫的任務。
支持大多數市面上流行的數據庫。
個人感覺:(本人不成熟的看法)
1:轉換功能全,使用簡潔。作業項豐富,流程合理。但缺少調度。
2:java代碼,支持的數據源范圍廣,所以,跨平臺性較好。
3:從實際項目的角度看,和其它開源項目類似,主要還是程序員的思維,缺少與實際應用項目(專業領域)的更多接軌,當然,項目實施者的專注點可能在于一個平臺框架,而非實際應用(實際應用需要二次開發)。
4:看過了大多數源碼,發現源碼的可重用性不是太好(缺少大粒度封裝),有些關鍵部分好象有Bug。
比如:個別class過于臃腫,線程實現的同步有問題。
5:提供的工具有些小錯,如參數的容錯處理。
好,對Kettle有了淺淺的了解,其它的容后再說。
對于數據倉庫以及ETL的知識,我基本上是個門外漢。一切都得從頭開始,記個筆記,方便自已了解學習進度。
首先,我們來了解最基本的定義:
嗯,也有人將ETL簡單稱為數據抽取。至少在未學習之前,領導告訴我的是,你需要做一個數據抽取的工具。
其實呢,抽取是ETL中的關鍵環節,顧名思義,也就將數據從不同的數據源中抓取(復制)出來。
太簡單了!
上面的解釋無首無尾,有點象能讓你吃飽的第七個燒餅,
仔細一想,抽取是不可能單獨存在,我們需要將與之關聯的一些其它環節拿出來。
于是,得到ETL的定義:
將數據抽取(Extract)、轉換(Transform)、清洗(Cleansing)、裝載(Load)的過程。
好的,既然到了這一個層次,我們完全會進一步展開聯想,引出上面這個抽象事件的前因后果,
抽取的源在哪里?
裝載的目的又是什么呢?
抽取源:大多數情況下,可以認為是關系數據庫,專業一點,就是事務處理系統(OLTP)。當然,廣義一點,可能會是其它數據庫或者是文件系統。
目的地:OK,我們希望是數據倉庫。數據倉庫是啥?在學習之前,它對我來說是個抽象的怪物,看過一些簡單的資料之后,才了解這個怪物一點都不怪。堆積用來分析的數據的倉庫。是了,是用來分析的,于是,它區別于OLTP中的數據存儲。
然后,我們來看看為什么要ETL?
在我看來,有兩個原因。
一:性能 將需要分析的數據從OLTP中抽離出來,使分析和事務處理不沖突。咦?這不是數據倉庫的效果嗎?是了,
數據倉庫,大多數情況下,也就是通過ETL工具來生成地。
二:控制 用戶可以完全控制從OLTP中抽離出來的數據,擁有了數據,也就擁有了一切。
嗯,OLAP分析,數據挖掘等等等……。
最后,總結一下,
從資料上看,ETL是一門大學問,對于大學問,實在有些怕怕,所以,我覺得應該停下來想一想,下一步我該干點啥?
嗯,時不我待,我沒有辦法一切從頭開始,
是了,從應用出發,看看現在工作中,最急需的是什么?
鴨子要變成一盤菜,并不是舉手將之置于油鍋之勞。
OK,要將生米變為熟飯,鴨子放上大盤,一堆廢話之后,我得先看看廚房里都有了一些啥?
ETL為數據倉庫服務,數據倉庫用于數據分析,數據分析屬于BI系統的要干的事兒。
一般中/小型ERP系統都會有不成熟的BI系統,為啥叫做不成熟?
因為它們或者有報表分析功能,但不具有OLAP(在線分析),或者有OLAP,但卻沒有數據挖掘和深度分析。或者干脆,來個大集成,直接利用第三方工具來達到相應的目的。
為什么會這樣,究其原因,很多情況是因為沒有自主的數據倉庫,沒有數據倉庫,其它的做起來也就有些四不象了。而要建立數據倉庫,首要的是:ETL。
于是,需求就應運而生了。
對了,BI是什么?OLAP是啥?什么又是數據挖掘?鑒于我只能解釋其表面含義,我就不多說了。各位不妨找本數據倉庫的書,翻翻前幾頁,一般就明白了。或者Google一把。
我們撿當下最流行的BI應用:OLAP來說說它與ETL的關系。
了解OLAP的人都知道,它的分析模型由事實表和維表組成。但往往OLTP系統中的數據庫是為事務而建,而并不為分析而建,而為了BI去改動OLTP數據庫是不現實,并且,很多情況下也基本上是不可能的(當然,有些公司把不可能的任務變成可能的,但這顯然是一種很僵硬的做法)。
這時候,ETL的作用就顯出來了,它可以為OLAP服務,按業務主題提取分析模型進行數據抽取。
聯機分析處理(OLAP)
:聯機事務處理OLTP(On-Line Transaction Processing)、聯機分析處理OLAP(On-Line Analytical Processing)。
OLTP是傳統的關系型數據庫的主要應用,主要是基本的、日常的事務處理,例如銀行交易。OLAP是數據倉庫系統的主要應用,支持復雜的分析操作,側重決策支持,并且提供直觀易懂的查詢結果。 OLAP是使分析人員、管理人員或執行人員能夠從多角度對信息進行快速、一致、交互地存取,從而獲得對數據的更深入了解的一類軟件技術。OLAP的目標是滿足決策支持或者滿足在多維環境下特定的查詢和報表需求,它的技術核心是"維"這個概念。 (OLAP分析需要什么樣的數據支持?可以參看一下OLAP的星型模型)。
{
天面試有一個問題是:星型模型與雪花模型的比較,何時用星型模型,何時需要用雪花模型 星型模式:是一種使用關系數據庫實現多維分析空間的模式,用星型模型可以通過關系數據庫來模擬OLAP模式。 使用關系數據庫+星型模型能夠優化存儲并且保持數據結構的靈活性。
OLAP多維數據模型對數據做預先計算,建成多維數據立方體,它需要很大的內存以存儲所有事實。無論是稠密緯合適稀疏維,無論數據塊否包含事實,都必須要預留單元。星型模式的基本思想就是保持立方體的多維功能,同時也增加了小規模數據存儲的靈活性。
雪花模式
有時候,需要對星型模式的維度需要進行規范化,這時,星型模式就演進為雪花模式。
原因是基本的星型模式并不能滿足數據挖掘的所有需要。
(1)我們需要更復雜的維度,例如時間。分析員希望根據周、月、季度等識別模式。
(2)維度必須進行規范化。我們不需要冗余的維度表,這只會使數據切片變得更加復雜。這種過程中我們得到的模式被稱為雪花模式。
(3)另外一個原因需要把星型模型變成雪花模型:就是當存在多對多的關聯時,無法在關系數據庫中實現,需要使用雪花模式。雪花模式中可以存在切片,切塊。
}
再說說數據挖掘:
這個課題實在太大,相關的書藉有很多很多,我還得花時間慢慢去學習。簡單的說,這涉及ERP業務和統計學的知識。現在我暫時還沒開始相關學習,但它與ETL的關系卻很明顯。因為數據挖掘所要求的數據大都是高聚合的已處理的數據,所以,不管從獲取難度和效率上來說,都不適合直接從OLTP中獲取。
同樣,需要ETL來幫忙。
因此,按本人粗淺的理解:
ETL實在是: BI系統 設計開發,項目實施 之必備良藥!
有句名言講得好:成為巨人不如站在巨人的肩膀上。
如果想對ETL有詳盡的了解,不妨先了解一下現有流行的ETL工具。
對于MS SQL-Server的DTS,在使用MS SQL-Server2000時,有最基本的接觸,但僅限時簡單的數據導入/導出。當開始了解ETL時,才發現DTS原來就是ETL的應用之一。
先不談論DTS的好壞,但它至少MS產品的特點,易學,易用。所以,要了解ETL的應用,從DTS開始,在我看來,是個不錯的選擇。我只是學習,所以我沒有能耐去評價它,下面,只能講DTS的功能一一列舉出來,可能這些與SQL-Server的聯機幫助有些重復,但對我來說,是一個加深記憶的方法。
一:概念
自完全不同源的數據析取、轉換并合并到單個或多個目的。主要應用于企業數據倉庫的數據抽取過程,完成從源數據庫/文件到數據倉庫的抽取和轉換過程。
看看,這不就是ETL要做的事兒。
二:特征
2.1:基于OLE DB,很方便從不同的數據源復制和轉換數據。
是了,MS總是首要支持自已的其它產品,所以,它選擇了最通用的Windows的標準。
2.2:有圖形化設計器,也可通過編程二次開發。
這也是MS的長項,并且能把其它的東西一股腦兒的集成進來。
2.3:執行效率高于普通ADO(SQL)操作
據說是這樣地,我做過簡單的比較,確實不是一個數量級,原理呢?估計可能有較多特殊處理,比如批量插入bcp,傳輸前的數據壓縮等技術……,當然,這只是我的猜測。
2.4:可調度。
這對于Windows系統,那很容易了,可以利用現成的系統級調度。
三:詳細
來說點詳細的東東,當然,這里的詳細并不指全部,實際上,我也只能挑出比較有代表性的功能點列舉一下,要是全部,那還不如抄襲聯機幫助了。
3.1:包——最小的可調度單元
包是基本任務,由工作流連接而成。包可以嵌套(包中的單個任務可以是執行另一個已存在的包)。
包是調度的直接管理對象,嵌套包保證包任務的重用。
3.2:任務——最小的工作流連接單元
分為以下幾種任務:
導出和導入數據任務、轉換任務、復制數據庫對象、郵件/消息發送、Transact-SQL 語句或 Microsoft ActiveX® 腳本執行包、采用COM自定義任務。
其中,最常用的應該是普通轉換任務。這等同于ETL中的T。
3.3: 數據連接——定義數據源和目的地
分為以下幾種:
標準數據庫(如 Microsoft SQL Server 2000、Microsoft Access 2000、Oracle、dBase、Paradox);與 ODBC 數據源的 OLE DB 連接;Microsoft Excel 2000 電子表格數據;HTML 源;以及其它 OLE DB 提供程序
文件連接數據鏈接連接(比較特殊)
注意:SQL-Server作為Windows應用產品,DTS自然也不支持Java。
對于標準數據庫是最基本的應用,易于實現。文件連接涉及格式定義,還不算復雜。
3.4:轉換——數據轉換
數據轉換,指列進行,有多種方式:
3.4.1:簡單復制方式。
3.4.2:簡單轉換(如,數據格式化,取字符串子串等……)
3.4.3:ActiveX腳本(實際上是vbScript和JavaScript)
3.4.4:調用自定的COM對象進行轉換。
通常會采用一二方式。如果要將DTS集成到你的應用中,可以第三種方式。
3.5:工作流
工作流包括成功,失敗,完成。工作流支持腳本控制。可編程控制。
工作流方式對于純數據抽取意義不大,但是考慮到任務包含收發郵件,信息,上/下傳文件,那就有必要了。當然,你也可以將這些任務單獨提出到應用端執行,而不采用DTS中的任務。
3.6:元數據
元數據方式更多的留備擴展,最基礎的應用是用來預定義數據表。
3.7:數據驅動的查詢任務——(一種特珠的轉換方式)
一種很特殊的轉換方式,支持參數。這里,單獨把它提出來,因為它不是那么容易理解,我花了一些時間,才將其弄明白。
3.7.1:根據源數據的特征決定之后的查詢方式(指增,刪,改,查詢操作)。
3.7.2:支持參數,參數通過定義綁定表來關聯,通過定義轉換腳本,可以計算出綁定列參數。
3.7.3:轉換時可以定義批量處理。
3.7.4:轉換支持多階段抽取,可以定義階段代碼,階段分為:行轉換,轉換失敗,插入成功,插入失敗,批處理完成,抽取完成。
此種應用異常復雜,應屬高級應用。簡單的看,當轉換任務需要根據數據源來確定動作,這是非常有用的。比如你的應用存在多表存儲,就可能根據表內的時間來確定之后的動作,達到數據分多表存儲的目的。
3.8: 查找查詢
作為轉換數據任務和數據驅動的查詢任務的一種功能。
查找查詢使您得以對源和目的之外的其它連接運行查詢和存儲過程。例如,通過使用查找查詢,可以在查詢過程中進行單獨的連接,并在目的表中包括來自連接的數據。
作為一種擴充功能,實現更復雜的查詢操作。
3.9: 多任務支持事務處理
除了順序執行,可以進行并行執行步驟,且支持檢查點回滾。
當然,任務的事務仍然依賴于數據源所在所據庫是否支持事務。一般情況下,順序執行已經可以滿足抽取需求。
好了,不管對錯,還是說說我的看法:
首先:DTS中抽取流程定義比較清晰,數據轉換功能豐富,可視的設計工具強大,有一定的可擴展性(COM定制,腳本支持)。
但是:但學習下來,隱隱約約覺得它有MS產品的通病,就是大而全,如果進行小型應用的集成,它是很方便和夠用的,但如果要在大型項目中集成DTS,它提供的二次開發方式,就顯得有些散亂,缺少一個總體的框架指導。當然,這可能與它的定位有關。
對了,我看的SQL-Sever2000的DTS,對于2005,我不知有哪些方面的改進。
前幾天看到一篇“SQL ServerDBA三十問”,很不錯,比較中肯。這些題目還是需要一定操作經驗的才能答得上來,其中的很多題目都可以通過books online查到,有些題目我也非常感興趣,因為也處理過類似的問題,所以印象深刻,現在把我的答案寫出來,希望可以幫到有緣人,如果有更好的方案,當然我也很樂意學學。
題目:7在線系統,一個表有五千萬記錄,現在要你將其中的兩千萬條記錄導入到另一臺服務器的某個表中,導完后,需要將這兩千萬數據刪 除,你預備如何處理,優缺點是什么;
我的答案:(先說明一下我的環境是sqlserver 2000,并且假設他有主鍵id)
第1步:先做一個表,t_update_log,記錄更新過的記錄的主鍵id,記錄修改和刪除的記錄,這步驟的具體作用看下面的步驟;
第2步:導出2000萬的數據到另一個庫另一表,我起名為 t_2000w ,我是用dts來處理的,效率很好,如果沒有大字段,2000萬大概3個小時可以導完,如果有大字段,比如很大的varchar,text,ntext 等,那需要的時間久會比較長,具體時間還要看數據的大小。
第3步:刪除當前庫導出的2000萬,我把當前庫起名為 t_5000w, 我是這樣來處理的,首先建一個和源數據表相同結構的表,起名t_3000w,導入剩下的3000萬條數據,然后用sp_rename 分別修改兩個表,把t_5000w改成t_5000w_bak,把t_3000w改成t_5000w(即源表), 大概就是這樣,很easy吧。
別急,第一步的準備工作還沒用上呢,而且還有很多細節的問題。
Q1:如何保證數據的準確性,如果你在導入的同時有人對數據進行了更新怎么辦?
Q2:盡量減少對用戶的影響,如果在sp_rename修改表名稱需要的時間比較長,而且剛好有數據需要insert怎么辦?
我的解決方案:
A1:剛好用到了第1步的表t_update_log,把有更新的記錄再重新導入到新表t_2000w,從此記錄表中t_update_log找出被刪除的id,從t_2000w中刪除;
A2:修改對表t_5000w的insert操作接口,可以再建一個結構和t_5000w一樣的新表,取名t_6000w,如果有自增id,把自增id的當前值設置為6000w,然后新增的數據都insert到t_6000w中,如果你的數據庫操作都是通過存儲過程統一操作,那很幸運,你只需要修改存儲過程,不需要修改你的。net程序,你甚至可以不停止服務就可以順利升級,在這里存儲過程的優越性得到了充分體現,如果你不是通過存儲過程,而是sql語句,而且調用的地方很多,那我建議,升級期間你還是暫停服務吧。
當然以上操作都是需要再測試環境下演練一遍,記錄下每一部需要的時間,并且做好失敗時能及時恢復到之前狀態。當然升級期間還是建議暫停服務,因為大部分人可以接受暫停服務,但不能接受數據丟失。
摘要: 由于平臺服務器是通過接口來與客戶端交互數據提供各種服務,因此服務器測試工作首先需要進行的是接口測試工作。測試人員需要通過服務器接口功能測試來確保接口功能實現正確,那么其他測試人員進行客戶端與服務器結合的系統測試過程中,就能夠排除由于服務器接口缺陷所導致的客戶端問題,便于開發人員定位問題。以下便是個人的平臺服務器接口功能測試經驗總結: 一、接口測試范圍 根據服務器的測試需求,接口測試范圍主要分為...
閱讀全文
關于光大驗收測試的現狀
51Testing:很多人對于金融證券行業不是很熟悉,能給我們簡單介紹一下嗎?
許崢:證券業指從事證券發行和交易服務的專門行業,是證券市場的基本組成要素之一,主要經營活動是溝通證券需求者和供給者直接的聯系,并為雙方證券交易提供服務,促使證券發行與流通高效地進行,并維持證券市場的運轉秩序。主要由證券交易所、證券公司、證券協會及金融機構組成。
當前證券企業幾乎100%通過借助集中式的信息技術平臺,通過金融電子交易技術幫助企業實現從分散化經營到集約化、規模化經營的戰略轉移。將交易類、經營管理類、統計分析類等各類軟件系統集成,通過公司級的數據集中、應用集中和管理集中形成集中式證券交易系統。只有持續的IT服務保障才能提供持續運營的服務創新能力。
51Testing:能否介紹您在光大證券驗收測試工作中所承擔的角色?
許崢:光大證券信息技術部的測試團隊主要由以下角色組成:質量經理、業務專家、自動化測試工程師、性能及安全測試專家。我主要承擔的角色是“質量經理”和項目經理。具體工作主要有:負責制定“測試計劃”和“測試方案”;根據測試需要協調相關業務專家加入測試團隊;保證“測試用例”質量;測試全流程監控;通過評測或驗收測試評價軟件質量和上線風險。
51Testing:軟件開發廠商在研發階段已經開展了測試工作,那么光大的驗收測試與研發廠商的測試差異在哪里?如果不做驗收測試,是否會有bug遺留到上線的系統中?
許崢:廠家的測試主要注重白盒測試,我們的驗收測試主要是黑盒測試。其次,廠家希望提供的通用的產品,因此在系統測試中測試數據選擇上主要選擇通用的測試數據,而我們做驗收測試中是使用生產環境的真實數據進行測試,因此能充分體現券商和客戶的個性化特點。另外,廠家注重功能性測試,而我們更注重業務場景的測試。因此從整體上看我們的驗收測試體系和廠家的測試形成了很好的互補作用,確保了測試的全面性。從質量管理的角度,廠家保證其研發過程質量、軟件的質量和應用系統的質量,我們除了對廠家這幾個環節的質量管控之外,還需保證最終用戶的使用質量。
51Testing:如何做好金融證券行業的驗收測試?主要保障哪些問題?你們團隊又是如何做的?分享下您的經驗。
許崢:證券業是個比較特殊的行業,對于證券IT系統,特別是交易系統對于業務連續性、安全性、穩定性通常有非常高的要求。由于券商在證券領域的角色定位,因此券商更多地把資源投入到系統的安全運維中,對軟件開發的投入以及軟件測試資源的投入相對較小。因大多交易類系統通過外包方式獲得,所以驗收測試是券商對接受產品最主要的質量控制環節。要做好驗收測試就必須在當前行業現狀下,通過一套適合的驗收體系、方法和流程來對驗收測試的過程進行控制,確保測試目標明確、測試過程可控、測試結果評估。為此我們組建了以業務專家為核心的測試團隊,通過對驗收測試標準的制定,驗收測試全面性以及測試用例質量進行控制,從而實現對驗收對象的客觀評估。
51Testing:以前的驗收測試工作中,存在哪些主要的困難?(可從人員/技術/流程幾方面談)
許崢:以往我們的驗收測試主要依靠運維人員來完成,沒有專門的測試團隊支持,測試用例更多依賴開發商提供的測試用例。因此測試中我們無法確認測試用例質量好壞,測試過程主要依賴運維人員的個人能力,測試結果往往不能客觀評價,測試全面性存在不足。
51Testing:目前光大證券的驗收測試技術團隊的構成是什么樣的?如何構建測試團隊規范/體系?
許崢:由于券商在證券領域角色定位,通常券商的專職測試人員相對較少。同時,我們考慮到證券業務的復雜度較高,驗收測試和開發商測試的互補性,我們組建了以“業務專家”為核心的測試團隊。“業務專家”通過對測試用例質量的控制來進行驗收測試質量保證。
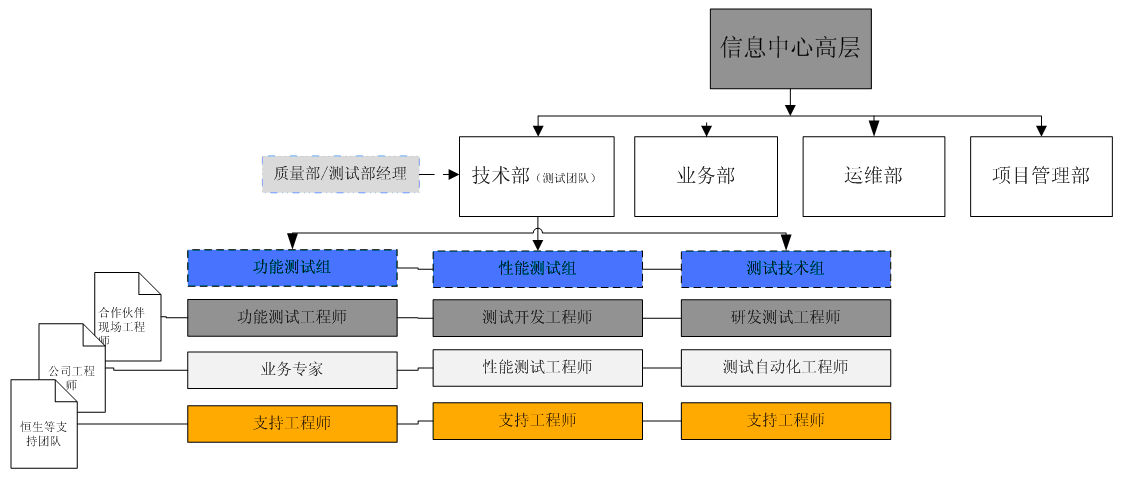
51Testing:對于金融證券行業的測試,尤其需要注意的是測試風險,談談你們團隊是如何控制測試風險的?
許崢:其實在測試過程的每個環節都存在一定的風險,但風險影響程度是隨著測試工作逐步推進而逐漸減少的。因此我們在風險控制上注重以下原則:
● 在測試的準備和計劃階段引入專家評審機制,對開發商交付件的可測試性進行評審;對測試方案和計劃進行評審。好的測試方案和計劃可避免未來測試過程中絕大多數的風險發生,是測試工作有序進行的重要保證。
● 在測試每個階段中引入質量保證機制,對每階段的工作輸出通過和基線的比較來動態調整,確保整個測試過程可控。
關于快速驗收測試體系
51Testing:據說,光大已經構建了一套快速驗收測試體系,可否簡要介紹此體系?
許崢:我們的快速驗收測試體系主要是針對產品驗收環節所制定的,目的是通過可量化評估的測試過程客觀評價測試對象,從而保證上線產品的質量。為此我們把驗收測試體系劃分了六個階段:
任務準備階段:該階段負責收集和驗收測試相關的各種材料,并對相關材料所描述內容的可測試性進行評審。
計劃和方案階段:該階段負責明確測試范圍,定義和優化目標,以及為實現上述目標而制定行動方案。
設計和實現階段:該階段負責完成測試計劃和方案中確定的工作以實現項目目標的過程。
執行階段:該階段負責具體落實測試工作。包括測試環境的準備以及測試用例的執行。
結果分析階段:該階段負責對測試結果進行分析,關注測試對象的質量是否符合驗收質量要求。
回歸測試階段:該階段負責對新發布的版本進行回歸測試,用以驗證之前的缺陷是否修復,是否還引入新的缺陷等。
51Testing:能具體給我們談談此體系中具體的測試流程嗎?
許崢:以下是具體流程圖:
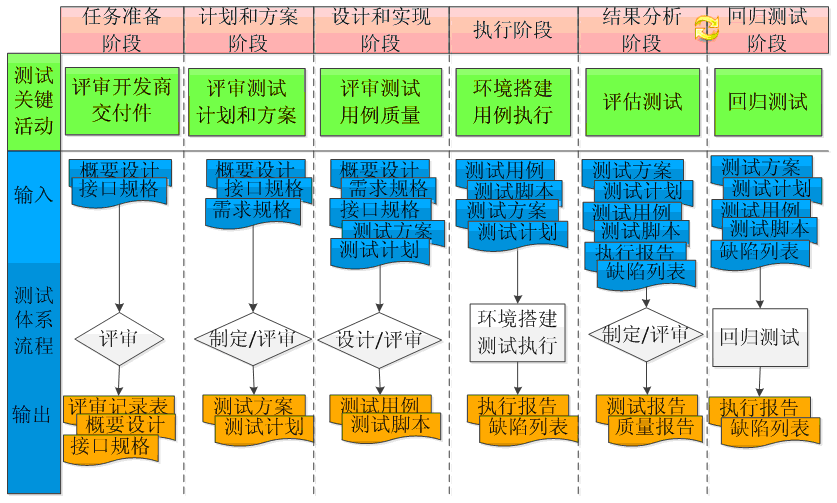
51Testing:快速驗收測試的評估點有哪些?
許崢:在驗收測試中的評估點是根據階段不同而有所不同。在任務準備階段主要是對開發商交付件的可測試性規范進行評估;在計劃和方案階段主要是對測試方案和計劃進行評估;在設計和實現階段主要是對測試用例質量進行評估;在執行階段主要是對測試執行報告進行評估;在結果分析階段主要是對測試報告進行評估;在回歸測試階段主要是對缺陷的修復情況進行評估。
概括地講,驗收測試重點評估業務場景的功能、系統的性能和上線運營的用戶測試。
51Testing:光大證券使用了哪些測試工具?帶來了什么效果?
許崢:我們的驗收測試體系中主要選擇了基于測試用例分析及管理的TestPlatform工具來構建我們核心的測試用例庫,并依靠它實現測試項目管理、需求管理、測試需求分析、測試用例設計、缺陷管理、缺陷分析等。同時我們根據證券業軟件的特點,使用了面向接口的集成測試自動化工具Integration Test Platform工具,通過該工具實現測試用例自動化執行,極大提高了測試效率及回歸測試效率。
51Testing:快速驗收測試體系在光大的實施效果如何?是否有量化的數據加以說明?
許崢:首先是測試用例質量的大幅度提高,之前我們的測試用例多依賴供應商提供,難免會有疏漏。建立起該體系后我們通過TP/ITP工具能夠快速設計出高質量且覆蓋面全的測試用例,從而避免了測試疏漏。其次,測試速度大幅提高,之前的測試大多是依靠人工執行,500條用例最少需要2~4人天才能完成,而使用ITP測試工具后僅僅需要20分鐘即可輸出測試結果。另外,測試用例的資產化轉變是測試體系中的核心,隨著測試用例資產的逐步積累,測試用例復用度提高,測試從準備到執行的效率都因此而提升。
51Testing:對希望進入金融證券行業測試的新人,您有什么樣的建議?快速驗收測試對項目的整體解決方案有何作用?將來有怎樣的推廣價值?
許崢:其實不管是金融行業還是其他行業,要想做好測試首先是要對業務熟悉。因為只有懂業務的人設計的測試用例才能是高質量的。只有當你的測試技術和業務知識充分結合才能做好測試工作。
這套測試體系的建立是在我們長期工作中摸索總結出的經驗,它的作用主要體現在:“規劃質量”、“快速執行”和“統計度量”幾個方面,它的實施保障了整個項目在可控環境下的高效有序的進行。
金融行業是個比較特殊的行業,有著鮮明的行業特點,因此我們這個驗收測試體系在整個行業內均有借鑒意義,希望這個體系的建立在行業中起到拋磚引玉的作用,促進提高行業中驗收測試的質量管理。