譯者:原始文章有點性能測試工具軟文的感覺,畢竟文章來源于某工具官方博客。高手請略過。
對于我這種新手,此文還是給我帶來一些驚喜,從上到下地,從表象到根源地,定位他們遇到性能問題-響應時間過長-的根本原因,有具體的步驟,思考和判斷依據,這就是一個比較不錯性能測試分析實例。可以更清楚看到性能測試如何分析定位,可以學習其思路。故分享之。
原文連接:http://apmblog.compuware.com/2013/06/04/how-to-accurately-identify-impact-of-system-issues-on-end-user-response-time/
以下為正文
我們希望檢測下我們社區網站的負載能力,所以我們開發團隊進行了一個任務,驗證生產環境的系統是否能在現有的硬件基礎上處理10倍于目前的負載。為了將網站在高負載下可能的崩潰影響降到最低,我們決定在周日下午進行第一輪測試。在運行測試之前,我們給運維團隊提了一個醒:他們可能在這次兩小時的期間觀察到明顯的負載變化,從而可能影響到運行在同一環境下的其他應用程序。
在測試過程中,運維團隊和開發團隊一起監控實時性能數據,當達到一定的負載水平后,我們看到最終用戶的響應時間和耗盡資源。在本次測試中非常有趣的是,開發團隊和運維團隊都看著相同的數據,但是卻從不同的角度去審視這些結果。然而,他們都是依賴于最近才公布的Compuware的PureStack技術,這是——整合dynaTrace和PurePath——的第一個解決方案,顯示出在高負載下生產環境的硬件是如何影響到關鍵業務應用程序的性能。
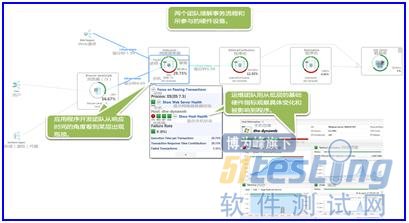
上下文為運維團隊和開發團隊的數據之間架起橋梁:這張圖片顯示"橫向"事務以及"縱向"層面的熱點區域(BridgingtheGapbetweenOpsandAppsDatabyaddingContext:OnepicturethatshowstheHotspotsof"Horizontal"Transactionaswellasthe"Vertical"Stack.)。
在我們的場景中表現不佳的根本原因-一個運行著Web和應用程序服務的主服務器的CPU被耗盡-從而導致達不到我們的負載目標。事實證明,這個問題是跟硬件設備和應用程序都有關系(ThisturnedouttobebothanITprovisioningandanapplicationproblem)。讓我解釋一下團隊的步驟以及他們是如何得出他們的行動項列表,以便改善目前的系統性能,以便在第二輪測試中得到更好的結果。
第1步:監控和識別硬件健康狀況
運維團隊希望能夠看著他們的服務器列表,而所有關鍵指標(CPU,內存,網絡,磁盤等)都能很快地呈現出綠色狀態(OperationsTeamslikehavingtheabilitytolookattheirlistofserversandquicklyseethatallcriticalindicators(CPU,Memory,Network,Disk,etc)aregreen)。但是,當我們的負載測試達到了頂峰時,他們看向服務器的狀態時,顯示出來卻是,他們有2臺機器正出現了異常:
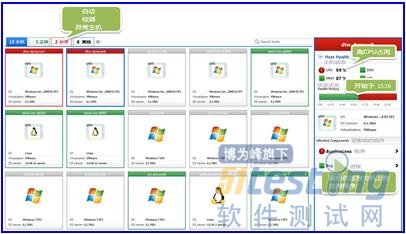
我們的社區網站核心服務器出現CPU相關的問題,并影響到另一運行在這臺服務器上的應用程序。
步驟2:哪些運行中的應用程序被真正影響到了?
單擊受影響的程序選項卡,它會顯示受影響的機器上所有運行的應用程序,以及目前受影響的應用程序:

增加的負載不僅影響到社區網站,而且也影響到我們支持網站
這次負載測試已經讓我們明白:如果我們希望未來的社區網站能夠承擔更高的負載,那我們可能需要移動支持網站到其他的機器,以避免不必要的影響。
當兩個團隊孤立檢查,運維導向的監測是不會有這個的結論(Whenexaminedindependently,operations-orientedmonitoringwouldnotbethattelling.)。但是,當它被放到具體的上下文中,并涉及到關聯的數據(最終用戶響應時間,用戶體驗,...),這對開發團隊來說是非常重要的,兩個團隊將獲得更多的靈感和視角。這是一個良好的開端,但仍然還有很多需要了解的。
步驟3:哪些關鍵事務被真正影響到了?
點擊社區應用程序的鏈接,它會顯示實際受硬件狀態影響的事務和頁面,但仍然存在著兩個關鍵的卻又懸而未決的問題:
這些事務,是否是我們成功運行的關鍵?
這些事務和個人用戶受性能問題影響后,有多嚴重的后果?
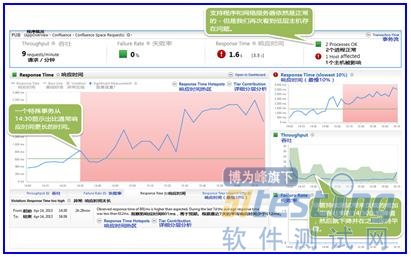
自動基線告訴我們,社區網站主要頁面的響應時間受到明顯的的性能影響。也包括我們的首頁,這是我們最有價值的一個頁面。
步驟4:可視化受硬件問題影響的事務流
事務流圖表是一個令人滿意的方式,能使得運維團隊和開發團隊達到一個基本的共識,并根據其完整的上下文查看關鍵的數據。它能顯示涉及到的應用層,正在運行的物理機器和虛擬機器,以及哪里是熱點區域。

運維團隊和開發團隊有相同的概要圖表,告訴他們無論是在"橫向"事務和"縱向"層面的熱點區域。
我們知道,我們的網頁內容非常"豐富"(圖像,JavaScript和CSS),高達80%的事務時間花費在瀏覽器上。看到熱點區域這樣的表現,現在整體頁面加載時間下降到50%,我們馬上就知道更多的事務時間已經轉移到新的熱點區域:服務器端。好消息是,數據庫是沒有問題的(只用了1%的響應時間),整個性能熱點區域似乎轉到Web和應用程序服務器,它們都運行在同一臺機器上-即那臺存在CPU問題的機器。
第5步:精確定位存在問題的機器的健康問題
點擊主機健康圖表(HostHealthDashboard),它會顯示了那個特定的服務器出了什么問題:
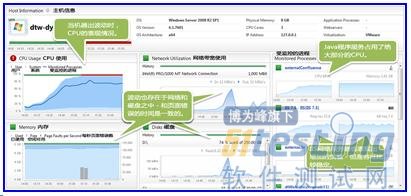
運維團隊立即看到了CPU的消耗主要來自于一個Java應用服務器。網絡,磁盤和頁面錯誤在一些某些特定的時間也都存在不尋常的波動。
第6步:進程健康圖表顯示應用程序服務器上響應緩慢
我們可以看到,這臺機器上的兩個主要進程是IIS(Web服務器)和Tomcat(應用程序服務器)。再進一步看看,隨著時間的推移,他們具體的表現情況:
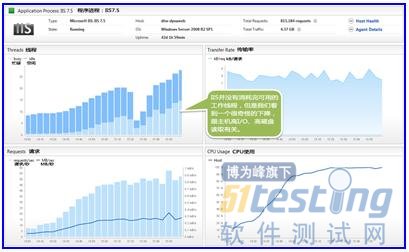
我們并不是沒有足夠的工作線程。傳輸速率是相當平緩。這就說明,Web服務器正在等待應用服務器的響應。

它表明應用程序服務器的CPU被耗盡。負載測試工具發送的持續請求在排隊等待,因為服務器無法及時處理掉這些請求。實際上已處理的事務數量在下降。
第7步:精確定位CPU的大量消耗
現在我們開發團隊非常有興趣搞清楚到底是什么在消耗著CPU,以及是否我們可以在應用程序代碼里面修復,或者是否只是我們需要更多的CPU:

熱點區域顯示應用程序的兩層都消耗CPU比較多。讓我們進一步深入。
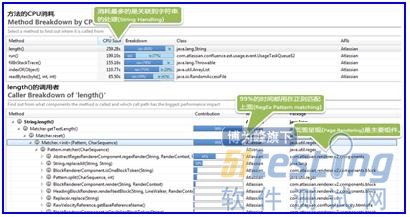
我們有些相當復雜的頁面(包含大量Confluencemacros)導致大量的CPU占用。
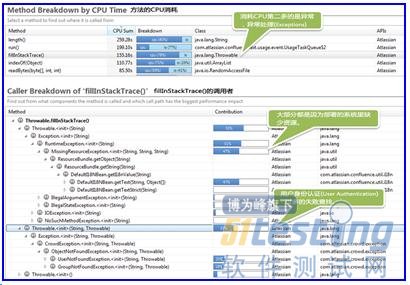
缺少資源和身份驗證問題導致了這些異常。
運維和開發團隊現在可以輕松地劃分處理硬件和應用程序問題的優先級
所以如前所述,上下文是關鍵。但這些數據不是輕而易舉就能獲得的-上下文依賴于智能關聯的能力,使所有相關的數據組成一個連貫的故事。當"橫向"的事務數據(最終用戶響應時間的分析)關聯到"縱向"的硬件層面信息,這就很容易讓兩個團隊達到一個共識,并規劃影響最小的修復的優先級。
這次實驗使我們能夠確定以下幾個行動項:
當應用程序對其他程序造成負面影響時,部署我們的關鍵應用程序到其他的機器上。
優化我們的頁面生成方式,以便降低CPU使用率。
為虛擬機分配更多的CPU,以便能夠處理更多的負載。
版權聲明:本文出自 在劫錄 的51Testing軟件測試博客: http://www.51testing.com/?166582
原創作品,轉載時請務必以超鏈接形式標明本文原始出處、作者信息和本聲明,否則將追究法律責任。