性能測試新手誤區(qū)(一):找不到測試點,不知為何而測
性能測試新手誤區(qū)(二):為什么我模擬的百萬測試數(shù)據(jù)是無效的?
同樣的項目、同樣的性能需求,讓不同的測試人員來測,會是相同的結(jié)果么?
假設(shè)有這樣一個小論壇,性能測試人員得到的需求是“支持并發(fā)50人,響應(yīng)時間要在3秒以內(nèi)”,性能測試人員A和B同時開始進行性能測試(各做各的)。
只考慮發(fā)帖這個操作,A設(shè)計的測試場景是50人并發(fā)發(fā)帖,得到的測試結(jié)果是平均完成時間是5秒。于是他提出了這個問題,認為系統(tǒng)沒有達到性能期望,需要開發(fā)人員進行優(yōu)化。
B設(shè)計的測試場景是,50個人在線,并且在5分鐘內(nèi)每人發(fā)一個帖子,也就是1分鐘內(nèi)有10個人發(fā)帖子,最后得到的測試結(jié)果是平均完成時間2秒。于是他的結(jié)論是系統(tǒng)通過性能測試,可以滿足上線的壓力。
兩個人得到了不同的測試結(jié)果,完全相反的測試結(jié)論,誰做錯了?
或許這個例子太極端,絕對并發(fā)和平均分布的訪問壓力當然是截然不同的,那我們再來看個更真實的例子。
還是一個小論壇,需求是“100人在線時,頁面響應(yīng)時間要小于3秒”。A和B又同時開工了,這時他們都成長了,經(jīng)驗更加豐富了,也知道了要設(shè)計出更符合實際的測試場景。假設(shè)他們都確認了用戶的操作流程為“登錄-進入子論壇-(瀏覽列表-瀏覽帖子)×10-發(fā)帖”,即每個用戶看10個帖子、發(fā)一個帖子。于是他們都錄制出了同樣的測試腳本。
A認為,每個用戶的操作,一般間隔30s比較合適,于是他在腳本中的每兩個事務(wù)之間加上了30秒的等待(思考時間)。
B想了想自己看論壇時的情景,好像平均每次鼠標點擊要間隔1分鐘,于是他在腳本中的每兩個事務(wù)之間加上了1分鐘的等待。
他們都認為自己的測試場景比較接近實際情況,可惜測試結(jié)果又是不同的,很顯然A場景的壓力是B的兩倍。那誰錯了呢?或者有人說是需求不明確導致的,那么你需要什么樣的需求呢?
看看我隨手在網(wǎng)上(51testing)找的提問吧,和上面的內(nèi)容如出一轍。一定有很多的性能測試人員每天接到的就是這種需求,又這樣就開展了測試,結(jié)果可想而知。
這里我想問幾個問題,希望各位看完了上面的小例子后想一想:
如果有另一個人和你測同樣的系統(tǒng),你們的測試結(jié)果會一致么?
如果不一致,那么誰是正確的?
如何證明測試結(jié)果是有效的?
如果你有了一些疑惑,對之前的測試結(jié)果少了一些自信,那么請繼續(xù)。
服務(wù)器視角 vs. 用戶視角
性能測試中非常重要的一塊內(nèi)容就是模擬預期的壓力,測試系統(tǒng)運行在此壓力下,用戶的體驗是什么樣的。
那么壓力是什么?壓力是服務(wù)器在不斷的處理事情、甚至是同時處理很多事情。壓力是服務(wù)器直接處理的“事情”,而不是遠在網(wǎng)絡(luò)另一端的用戶。
下圖中,每一個顏色的線段代表一種操作。在任意一個時刻,服務(wù)器都知道它有10個事務(wù)需要處理,這10個事務(wù)也是有10個用戶產(chǎn)生的。但它不知道的是,整個時間段內(nèi)的所有事務(wù),是由多少個用戶與系統(tǒng)交互而產(chǎn)生的。
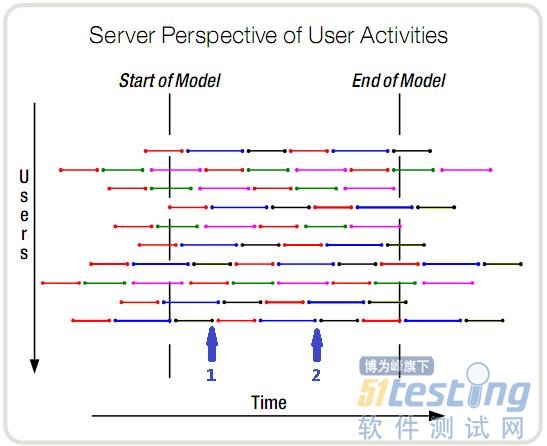
這句話好像有點繞,我再試著更形象的解釋一下。時刻1,10個當前事務(wù)是由10個用戶發(fā)起的。時刻2,依然是10個正在進行的事務(wù),但可能是完全不同的10個人發(fā)起的。在這段時間內(nèi),服務(wù)器每一個時刻都在處理10個事務(wù),但是參與了這個交互過程(對服務(wù)器產(chǎn)生壓力)的人可能會達到上百個,也可能只有最開始的10個。
那么,對于服務(wù)器來說,壓力是什么呢?顯然只是每時刻這10個同時處理的事務(wù),而到底是有10個人還是1000個人,區(qū)別不大(暫不考慮session等問題)。
下面再從用戶的視角來看看。實際的情況中,不可能出現(xiàn)很多用戶同一時刻開始進行操作的場景,而是有一定的時間順序的。正如下圖所示,在這個時間段內(nèi),一共有23個用戶進行了操作。
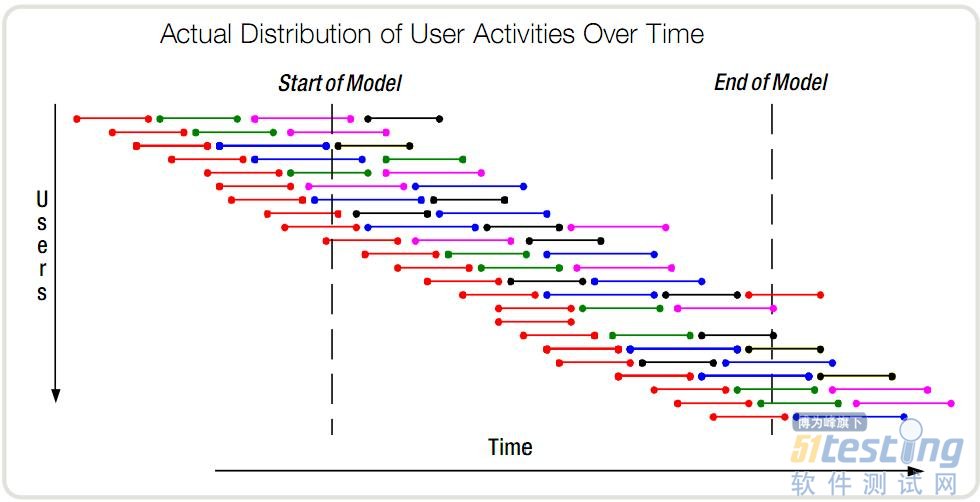
但是服務(wù)器能看到這些用戶么?它知道的只是某一個時間點上,有多少個正在執(zhí)行的事務(wù)。大家可以數(shù)一下,此圖中任意時刻的并發(fā)事務(wù)依然是10個。
其實這兩個圖描述的本來就是同一個場景,只不過觀察者的視角不同罷了。
那么大家想想,在性能需求中最常見到的“并發(fā)用戶”到底是指的什么呢? 并發(fā)用戶
很多使用“并發(fā)用戶”這個詞的人,并沒有從服務(wù)器視角進行考慮。他們想的是坐在電腦前使用這個系統(tǒng)、對系統(tǒng)產(chǎn)生壓力的人的個數(shù)。基于這個原因,我很少使用這個容易讓人誤解的詞匯,而是進行了更細的劃分。主要有這么幾個:系統(tǒng)用戶數(shù)(注冊用戶數(shù))、在線用戶數(shù)(相對并發(fā)用戶數(shù))、絕對并發(fā)用戶數(shù)。
上面幾個例子中所說的“并發(fā)用戶”,實際就是在線用戶數(shù)。其實我更喜歡叫做相對并發(fā)用戶數(shù),因為這個詞更容易讓人感受到“壓力”。相對并發(fā)用戶數(shù)指的是,在一個時間段內(nèi),與服務(wù)器進行了交互、對服務(wù)器產(chǎn)生了壓力的用戶的數(shù)量。這個時間段,可以是一天,也可以是一個小時。而需求人員必須要描述的,也正是這個內(nèi)容。
而絕對并發(fā)用戶,主要是針對某一個操作進行測試,即多個用戶同一時刻發(fā)起相同請求。可以用來驗證是否存在并發(fā)邏輯上的處理問題,如線程不安全、死鎖等問題;也可提供一些性能上的參考信息,比如1個用戶需要1秒,而10個用戶并發(fā)卻需要30秒,那很可能就會有問題,需要進行關(guān)注,因為10個用戶請求排隊處理也應(yīng)該只需要10秒啊。但這種絕對并發(fā)的測試,同實際壓力下的用戶體驗關(guān)系不大。
再回到相對并發(fā)這個概念上來,它與服務(wù)器的壓力到底是什么關(guān)系呢?如果你理解了前面的所有內(nèi)容,那么就會知道這兩者其實沒有直接聯(lián)系(當然了,同一個測試用例中,肯定是用戶數(shù)越多壓力越大)。也就是說,你得到的這種性能需求,是無法知道服務(wù)器到底要承受多大壓力的。
那么如何開展性能測試?
如何模擬壓力
既然我們知道了所謂的壓力其實是從服務(wù)器視角來講的,服務(wù)器要處理的事務(wù)才是壓力,那么我們就從這出發(fā),來探尋一下性能測試需要的信息。依然用之前的小論壇為例,我們需要測試活躍用戶為500人時,系統(tǒng)的性能是否能還能提供良好的用戶感受。
假設(shè)現(xiàn)在的活躍用戶有50個人(或者通過另一個類似的系統(tǒng)來推算也行),平均每天總的發(fā)帖量是50條、瀏覽帖子500次,也就是每人每天發(fā)一個帖子、瀏覽十個帖子(為了方便講解,假設(shè)論壇只有這兩個基本功能)。那么我們就可以推算,活躍用戶達到500時,每天的業(yè)務(wù)量也會成比例的增長,也就是平均每天會產(chǎn)生500個新帖子、瀏覽帖子5000次。
進一步分析數(shù)據(jù),又發(fā)現(xiàn)。用戶使用論壇的時間段非常集中,基本集中在中午11點到1點和晚上18點到20點。也就是說每天的這些業(yè)務(wù),實際是分布在4個小時中完成的。
那我們的測試場景,就是要用500個用戶在4小時內(nèi)完成“每人發(fā)一個帖子、瀏覽十個帖子”的工作量。
注意上面的兩處,“平均每天……”、“分布在4個小時……”。敏感的測試人員應(yīng)該能發(fā)現(xiàn),這個場景測的是平均壓力,也就是一個系統(tǒng)最平常一天的使用壓力,我喜歡稱之為日常壓力。
顯然,除了日常壓力,系統(tǒng)還會有壓力更大的使用場景,比如某天發(fā)生了一件重要的事情,那么用戶就會更加熱烈的進行討論。這個壓力,我習慣叫做高峰期壓力,需要專門設(shè)計一個測試場景。
這個場景,需要哪些數(shù)據(jù)呢,我們依然可以從現(xiàn)有的數(shù)據(jù)進行分析。比如上面提到的是“平均每天總的發(fā)帖量……”,那么這次我們就要查到過去最高一日的業(yè)務(wù)量。“分布在4個小時”也需要進行相應(yīng)的修改,比如查查歷史分布圖是否有更為集中的分布,或者用更簡單通用的80-20原則,80%的工作在20%的時間內(nèi)完成。根據(jù)這些數(shù)據(jù)可以再做適當?shù)恼{(diào)整,設(shè)計出高峰期的測試場景。
實際工作中可能還需要更多的測試場景,比如峰值壓力場景。什么是峰值壓力呢,比如一個銀行網(wǎng)站,可能會由于發(fā)布一條重磅消息使訪問量驟增,這個突發(fā)的壓力也是性能測試人員需要考慮的。
需要注意高峰期壓力和峰值壓力的區(qū)別,高峰期壓力是指系統(tǒng)正常的、預期內(nèi)壓力的一個高峰。而峰值壓力是指那些不在正常預期內(nèi)的壓力,可能幾年才出現(xiàn)一次。
這里只是舉了個最簡單的例子,實際工作遠比這復雜的多。需要哪些數(shù)據(jù)、如何獲取,很可能要取得這些數(shù)據(jù)就要花費很大的功夫。這其實就涉及到了一個很重要的內(nèi)容,用戶模型和壓力模型的建立,以后會有專門的文章進行講述。
為什么要花這么大的精力來收集這些信息呢?是因為只有通過這些有效的數(shù)據(jù),才能準確的去模擬用戶場景,準確的模擬壓力,獲取到更加真實的用戶體驗。只有這樣,“不同的測試人員,測出相同的結(jié)果”才會有可能實現(xiàn),而且結(jié)果都是準確有效的。
要點回顧
● 最后通過幾個小問題來總結(jié)回顧一下:
● 你真的理解“并發(fā)用戶”的意義么?
● 什么是用戶視角和服務(wù)器視角?
● 什么是壓力?
● 如何模擬預期壓力?
相關(guān)鏈接:
性能測試新手誤區(qū)(一):找不到測試點,不知為何而測
性能測試新手誤區(qū)(二):為什么我模擬的百萬測試數(shù)據(jù)是無效的?