這篇文章摘自網(wǎng)絡(luò)�����,已經(jīng)找不到原文出處了�����,寫的不錯(cuò),學(xué)習(xí)一下。
數(shù)據(jù)庫的索引
1. 如果不建立索引�����,那么查詢都需要全表掃描�����;如果建立了索引�����,則數(shù)據(jù)庫會(huì)保存一個(gè)索引文件通常是特殊的結(jié)構(gòu)比如B樹�����,這樣查詢起來不需要全表掃描,一下子能夠找到滿足要求的記錄。
2. 一般是對Where之后的條件建立索引�����,數(shù)據(jù)庫中的主鍵是已經(jīng)建立了索引的�����。數(shù)據(jù)庫中可以建立多個(gè)索引。
3. 可以對不同類型的列建立索引�����。
對于Text類型等�����,可以使用MySQL的全文檢索功能建立全文索引�����。它利用了自然語言的方法去在文本中檢索關(guān)鍵詞。
舉個(gè)例子:如果使用=號(hào)的話可能需要使用like以及%等去匹配�����。而使用MySQL的全文檢索可以使用Match函數(shù)即可檢索出包含關(guān)鍵詞的列�����。
詳細(xì)情況參看MySQL參考手冊關(guān)于全文檢索的部分�����。
4.1使用索引
我們首先討論索引,因?yàn)樗羌涌觳樵兊淖钪匾墓ぞ?����。還有其他加快查詢的技術(shù)�����,但是最有效的莫過于恰當(dāng)?shù)厥褂盟饕恕T?/span>MySQL的郵件清單上�����,人們通常詢問關(guān)于使查詢更快的問題�����。在大量的案例中�����,都是因?yàn)楸砩蠜]有索引,一般只要加上索引就可以立即解決問題�����。但這樣也并非總是有效�����,因?yàn)閮?yōu)化并非總是那樣簡單�����。然而�����,如果不使用索引�����,在許多情形下�����,用其他手段改善性能只會(huì)是浪費(fèi)時(shí)間。應(yīng)該首先考慮使用索引取得最大的性能改善�����,然后再尋求其他可能有幫助的技術(shù)�����。
本節(jié)介紹索引是什么�����、它怎樣改善查詢性能、索引在什么情況下可能會(huì)降低性能,以及怎樣為表選擇索引�����。下一節(jié)�����,我們將討論MySQL的查詢優(yōu)化程序�����。除了知道怎樣創(chuàng)建索引外�����,了解一些優(yōu)化程序的知識(shí)也是有好處的�����,因?yàn)檫@樣可以更好地利用所創(chuàng)建的索引。某些編寫查詢的方法實(shí)際上會(huì)妨礙索引的效果�����,應(yīng)該避免這種情況出現(xiàn)�����。(雖然并非總會(huì)這樣�����。有時(shí)也會(huì)希望忽略優(yōu)化程序的作用。我們也將介紹這些情況�����。)
4.1.1索引的益處
讓我們從一個(gè)無索引的表著手來考察索引是怎樣起作用的�����。無索引的表就是一個(gè)無序的行集。例如�����,圖4 - 1給出了我們在第1章“MySQL與SQL 介紹” 中首先看到的ad 表。這個(gè)表上沒有索引�����,因此如果我們查找某個(gè)特定公司的行時(shí)�����,必須查看表中的每一行�����,看它是否與所需的值匹配。這是一個(gè)全表掃描�����,很慢�����,如果表中只有少數(shù)幾個(gè)記錄與搜索條件相匹配�����,則其效率是相當(dāng)?shù)偷摹?/span>
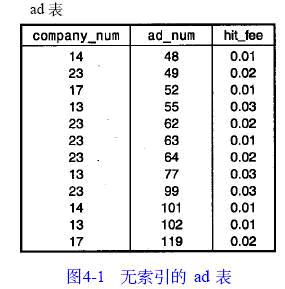
圖4 - 2給出了相同的表,但在表的company_num 列上增加了一個(gè)索引�����。此索引包含表中每行的一項(xiàng)�����,但此索引是在company_num 上排序的。現(xiàn)在�����,不需要逐行搜索全表查找匹配的條款�����,而是可以利用索引進(jìn)行查找�����。假如我們要查找公司13的所有行,那么可以掃描索引,結(jié)果得出3行�����。然后到達(dá)公司14的行�����,這是一個(gè)比我們正在查找的要大的號(hào)碼�����。索引值是排序的,因此在讀到包含14的記錄時(shí)�����,我們知道不會(huì)再有匹配的記錄�����,可以退出了。如果查找一個(gè)值�����,它在索引表中某個(gè)中間點(diǎn)以前不會(huì)出現(xiàn),那么也有找到其第一個(gè)匹配索引項(xiàng)的定位算法,而不用進(jìn)行表的順序掃描(如二分查找法)�����。這樣�����,可以快速定位到第一個(gè)匹配的值�����,以節(jié)省大量搜索時(shí)間。數(shù)據(jù)庫利用了各種各樣的快速定位索引值的技術(shù)�����,這些技術(shù)是什么并不重要�����,重要的是它們工作正常�����,索引技術(shù)是個(gè)好東西�����。
有人會(huì)問�����,為什么不只對數(shù)據(jù)文件進(jìn)行排序,省掉索引文件�����?這樣不也在搜索時(shí)產(chǎn)生相同的效果嗎�����?問得好�����,如果只有單個(gè)索引時(shí),
是這樣的�����。不過有可能會(huì)用到第二個(gè)索引�����,但同時(shí)以兩種不同的方法對同一個(gè)數(shù)據(jù)文件進(jìn)行排序是不可能的。(如�����,想要一個(gè)顧客名的索
引�����,同時(shí)又要一個(gè)顧客ID 號(hào)或電話號(hào)碼的索引。)將索引文件作為一個(gè)與數(shù)據(jù)文件獨(dú)立的實(shí)體就解決了這個(gè)問題�����,而且允許創(chuàng)建多個(gè)索
引�����。此外�����,索引中的行一般要比數(shù)據(jù)文件中的行短�����。在插入或刪除值時(shí),為保持排序順序而移動(dòng)較短的索引值與移動(dòng)較長的數(shù)據(jù)行相比更
為容易�����。
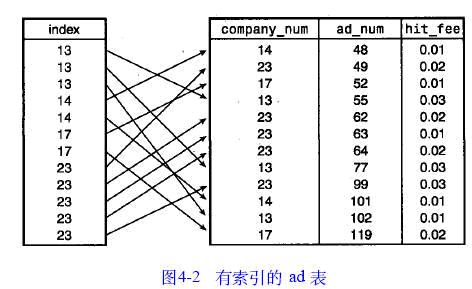
這個(gè)例子與MySQL索引表的方法相符�����。表的數(shù)據(jù)行保存在數(shù)據(jù)文件中�����,而索引值保存在索引文件中�����。一個(gè)表上可有不止一個(gè)索引�����;如果確實(shí)有不止一個(gè)索引,它們都保存在同一個(gè)索引文件中�����。索引文件中的每個(gè)索引由排過序的用來快速訪問數(shù)據(jù)文件的鍵記錄數(shù)組構(gòu)成�����。
前面的討論描述了單表查詢中索引的好處�����,其中使用索引消除了全表掃描,極大地加快了搜索的速度�����。在執(zhí)行涉及多個(gè)表的連接查詢時(shí)�����,索引甚至?xí)袃r(jià)值�����。在單個(gè)表的查詢中�����,每列需要查看的值的數(shù)目就是表中行的數(shù)目�����。而在多個(gè)表的查詢中,可能的組合數(shù)目極大,因?yàn)檫@個(gè)數(shù)目為各表中行數(shù)之積�����。
假如有三個(gè)未索引的表t 1�����、t 2�����、t 3�����,分別只包含列c 1、c 2、c 3�����,每個(gè)表分別由含有數(shù)值1到1000 的1000 行組成�����。查找對應(yīng)值相等的表行組合的查詢?nèi)缦滤荆?/span>
SELECT c1,c2,c3
FROM t1,t2,t3
WHERE c1=c2 AND c1=c3
此查詢的結(jié)果應(yīng)該為1000 行,每個(gè)組合包含3 個(gè)相等的值。如果我們在無索引的情況下處理此查詢,則不可能知道哪些行包含那些值�����。因此�����,必須尋找出所有組合以便得出與WHERE 子句相配的那些組合�����。可能的組合數(shù)目為10 0 0??0 0 0??0 0 0(十億)�����,比匹配數(shù)目多一百萬倍�����。很多工作都浪費(fèi)了�����,并且這個(gè)查詢將會(huì)非常慢,即使在如像MySQL這樣快的數(shù)據(jù)庫中執(zhí)行也會(huì)很慢�����。而這還是每個(gè)表中只有1000 行的情形�����。如果每個(gè)表中有一百萬行時(shí),將會(huì)怎樣�����?很顯然�����,這樣將會(huì)產(chǎn)生性能極為低下的結(jié)果�����。如果對每個(gè)表進(jìn)行索引,就能極大地加速查詢進(jìn)程�����,因?yàn)槔盟饕牟樵兲幚砣缦拢?/span>
1) 如下從表t1中選擇第一行�����,查看此行所包含的值�����。
2) 使用表t2 上的索引�����,直接跳到t2 中與來自t1的值匹配的行�����。類似�����,利用表t3 上的索引,直接跳到t3 中與來自t1的值匹配的行�����。
3) 進(jìn)到表t1的下一行并重復(fù)前面的過程直到t1中所有的行已經(jīng)查過�����。在此情形下�����,我們?nèi)匀粚Ρ?/span>t1執(zhí)行了一個(gè)完全掃描,但能夠在表t2 和t3 上進(jìn)行索引查找直接取出這些表中的行。從道理上說�����,這時(shí)的查詢比未用索引時(shí)要快一百萬倍�����。如上所述�����,MySQL利用索引加速了WHERE 子句中與條件相配的行的搜索�����,或者說在執(zhí)行連接時(shí)加快了與其他表中的行匹配的行的搜索�����。它也利用索引來改進(jìn)其他操作的性能:
■ 在使用MIN( ) 和MAX( ) 函數(shù)時(shí),能夠快速找到索引列的最小或最大值�����。
■ MySQL常常能夠利用索引來完成ORDER BY 子句的排序操作�����。
■ 有時(shí)�����,MySQL可避免對整個(gè)數(shù)據(jù)文件的讀取。假如從一個(gè)索引數(shù)值列中選擇值�����,而且不選擇表中其他列�����。這時(shí)�����,通過對索引值的讀取,就已經(jīng)得到了讀取數(shù)據(jù)文件所要得到的值�����。沒有對相同的值進(jìn)行兩次讀取的必要�����,因此�����,甚至無需涉及數(shù)據(jù)文件。
4.1.2 索引的弊端
一般情況下�����,如果MySQL能夠知道怎樣用索引來更快地處理查詢�����,它就會(huì)這樣做�����。這表示,在大多數(shù)情況下�����,如果您不對表進(jìn)行索引�����,則損害的是您自己的利益?����?梢钥闯?����,作者描繪了索引的諸多好處�����。但有不利之處嗎?是的,有�����。實(shí)際上�����,這些缺點(diǎn)被優(yōu)點(diǎn)所掩蓋了�����,
但應(yīng)該對它們有所了解。
首先�����,索引文件要占磁盤空間�����。如果有大量的索引�����,索引文件可能會(huì)比數(shù)據(jù)文件更快地達(dá)到最大的文件尺寸。其次,索引文件加快了檢索�����,但增加了插入和刪除�����,以及更新索引列中的值的時(shí)間(即�����,降低了大多數(shù)涉及寫入的操作的時(shí)間),因?yàn)閷懖僮鞑粌H涉及數(shù)據(jù)行�����,而且還常常涉及索引�����。一個(gè)表擁有的索引越多�����,則寫操作的平均性能下降就越大�����。在4 . 4節(jié)“有效地裝載數(shù)據(jù)”中�����,我們將更為詳細(xì)地介紹這些性能問題,并討論怎樣解決�����。
4.1.3 選擇索引
創(chuàng)建索引的語法已經(jīng)在3 . 4 . 3節(jié)“創(chuàng)建和刪除索引”中進(jìn)行了介紹�����。這里�����,我們假定您已經(jīng)閱讀過該節(jié)。但是知道語法并不能幫助確定表怎樣進(jìn)行索引�����。要決定表怎樣進(jìn)行索引需要考慮表的使用方式�����。本節(jié)介紹一些關(guān)于怎樣確定和挑選索引列的準(zhǔn)則:
■ 搜索的索引列�����,不一定是所要選擇的列�����。換句話說�����,最適合索引的列是出現(xiàn)在WHERE 子句中的列�����,或連接子句中指定的列,而不是出現(xiàn)在SELECT 關(guān)鍵字后的選擇列表中的列:
當(dāng)然�����,所選擇的列和用于WHERE 子句的列也可能是相同的�����。關(guān)鍵是�����,列出現(xiàn)在選擇列表中不是該列應(yīng)該索引的標(biāo)志。出現(xiàn)在連接子句中的列或出現(xiàn)在形如col1= col2 的表達(dá)式中的列是很適合索引的列�����。查詢中的col_b 和col_c 就是這樣的例子�����。如果MySQL能利用連接列來優(yōu)化一個(gè)查詢,表示它通過消除全表掃描相當(dāng)可觀地減少了表行的組合。
■ 使用惟一索引�����?����?紤]某列中值的分布�����。對于惟一值的列,索引的效果最好�����,而具有多個(gè)重復(fù)值的列�����,其索引效果最差�����。例如,存放年齡的列具有不同值,很容易區(qū)分各行�����。而用來記錄性別的列�����,只含有“ M”和“F”,則對此列進(jìn)行索引沒有多大用處(不管搜索哪個(gè)值�����,都會(huì)得出大約一半的行)�����。
■ 使用短索引�����。如果對串列進(jìn)行索引�����,應(yīng)該指定一個(gè)前綴長度,只要有可能就應(yīng)該這樣做。例如,如果有一個(gè)CHAR(200) 列,如果在前10 個(gè)或20 個(gè)字符內(nèi),多數(shù)值是惟一的,那么就不要對整個(gè)列進(jìn)行索引。對前10 個(gè)或20 個(gè)字符進(jìn)行索引能夠節(jié)省大量索引空間�����,也可能會(huì)使查詢更快�����。較小的索引涉及的磁盤I/O 較少�����,較短的值比較起來更快。更為重要的是,對于較短的鍵值�����,索引高速緩存中的塊能容納更多的鍵值�����,因此,MySQL也可以在內(nèi)存中容納更多的值�����。這增加了找到行而不用讀取索引中較多塊的可能性�����。(當(dāng)然�����,應(yīng)該利用一些常識(shí)。如僅用列值的第一個(gè)字符進(jìn)行索引是不可能有多大好處的�����,因?yàn)檫@個(gè)索引中不會(huì)有許多不同的值�����。)
■ 利用最左前綴�����。在創(chuàng)建一個(gè)n 列的索引時(shí),實(shí)際是創(chuàng)建了MySQL可利用的n 個(gè)索引�����。多列索引可起幾個(gè)索引的作用�����,因?yàn)榭衫盟饕凶钭筮叺牧屑瘉砥ヅ湫小_@樣的列集稱為最左前綴�����。(這與索引一個(gè)列的前綴不同�����,索引一個(gè)列的前綴是利用該的前n 個(gè)字符作為索引值�����。)
假如一個(gè)表在分別名為s t a t e、city 和zip 的三個(gè)列上有一個(gè)索引。索引中的行是按state/city/zip 的次序存放的�����,因此,索引中的行也會(huì)自動(dòng)按state/city 的順序和state 的順序存放�����。這表示�����,即使在查詢中只指定state 值或只指定state 和city 的值,MySQL也可以利用索引�����。因此�����,此索引可用來搜索下列的列組合:
state,city,zip
state,city
sate
MySQL不能使用不涉及左前綴的搜索�����。例如,如果按city 或zip 進(jìn)行搜索,則不能使用該索引。如果要搜索某個(gè)州以及某個(gè)zip 代碼(索引中的列1和列3)�����,則此索引不能用于相應(yīng)值的組合�����。但是�����,可利用索引來尋找與該州相符的行,以減少搜索范圍�����。