A variable-length format for positive integers is
defined where the high-order bit of each byte indicates whether more
bytes remain to be read. The low-order seven bits are appended as
increasingly more significant bits in the resulting integer value.
Thus values from zero to 127 may be stored in a single byte, values
from 128 to 16,383 may be stored in two bytes, and so on.
εè·εè‰φ†ΦεΦèγö³φï¥εû΄ε°öδΙâοΦöφ€ÄιΪ‰δΫçηΓ®γΛΚφ‰·εêΠ‰q‰φ€âε≠½ηä²ηΠ¹η·Μεè•οΦ¨δΫéδΗÉδΫçεΑ±φ‰·εΑ±φ‰·εÖΖδΫ™γö³φ€âφïàδΫçοΦ¨φΖ’dä†εà?/p>
Ψl™φû€φïΑφç°δΗ≠ψIJφ·îεΠ?0000001 φ€ÄιΪ‰δΫçηΓ®γΛΚ0εQ¨ι²ΘδΙàη·¥φ‰éηΩôδΗΣφïΑû°±φ‰·δΗÄδΗΣε≠½ηä²ηΓ®ΫCΚοΦ¨φ€âφïàδΫçφ‰·εêéιùΔγö³δΗÉδΫ?000001εQ¨εÄιgΊ™(f®¥)1ψÄ?0000010 00000001 ΫW§δΗÄδΗΣε≠½ηä²φ€ÄιΪ‰δΫçδΗ?εQ¨ηΓ®ΫCΚεêéιùΔηΩ‰φ€âε≠½ηä²οΦ¨ΫW§δΚ¨δΫçφ€ÄιΪ‰δΫç0ηΓ®γΛΚεàΑφ≠ΛδΗΚφ≠ΔδΚÜοΦ¨εç¦_Α±φ‰·δΗΛδΗΣε≠½ηä²οΦ¨ι²ΘδΙàεÖΖδΫ™γö³εÄΦφ≥®φ³èοΦ¨φ‰·δΜéφ€ÄεêéδΗÄδΗΣε≠½ηä²γö³δΗÉδΫçφ€âφïàφïΑφîΨε€®φ€ÄεâçιùΔεQ¨δΨù΄ΤΓφîΨΨ|°οΦ¨φ€Äεêéφ‰·ΫW§δΗÄδΗΣη΅ΣεΖόqö³δΗÉδΫçφ€âφïàδΫçοΦ¨φâÄδΜΞηΩôδΗΣφïΑηΓ®γΛΚ 0000001 0000010εQ¨φçΔΫé½φàêφï¥φïΑû°±φ‰·130
VInt Encoding Example
|
Value |
First byte |
Second byte |
Third byte |
|
0 |
00000000 |
|
|
|
1 |
00000001 |
|
|
|
2 |
00000010 |
|
|
|
... |
|
|
|
|
127 |
01111111 |
|
|
|
128 |
10000000 |
00000001 |
|
|
129 |
10000001 |
00000001 |
|
|
130 |
10000010 |
00000001 |
|
|
... |
|
|
|
|
16,383 |
11111111 |
01111111 |
|
|
16,384 |
10000000 |
10000000 |
00000001 |
|
16,385 |
10000001 |
10000000 |
00000001 |
|
... |
|
|
|
LuceneφΚêδΜΘγ†¹δΗ≠‰q¦ηΓ¨ε≠‰ε²®ε£¨η·Μεè•φ‰·‰qôφ†Ζγö³ψIJOutputStreamφ‰·η¥üη¥ΘεÜôεQ?/p>
2 * five bytes. Smaller values take fewer bytes. Negative numbers are not
3 * supported.
4 * @see InputStream#readVInt()
5 */
6 public final void writeVInt(int i) throws IOException {
7 while ((i & ~0x7F) != 0) {
8 writeByte((byte)((i & 0x7f) | 0x80));
9 i >>>= 7;
10 }
11 writeByte((byte)i);
12 }
InputStreamη¥üη¥Θη·ΜοΦö
2 * five bytes. Smaller values take fewer bytes. Negative numbers are not
3 * supported.
4 * @see OutputStream#writeVInt(int)
5 */
6 public final int readVInt() throws IOException {
7 byte b = readByte();
8 int i = b & 0x7F;
9 for (int shift = 7; (b & 0x80) != 0; shift += 7) {
10 b = readByte();
11 i |= (b & 0x7F) << shift;
12 }
13 return i;
14 }
>>>ηΓ®γΛΚφ½†γ§ΠεèΖεè≥ΩU?br />
tomcat壨jdkιÉΫε°âηΘÖεΞΫεQ?/p>
δΚ¨οΦönutch-0.9.tar.gz
û°ÜδΗ΄ηΫΫεàΑγö³tar.gzε¨ÖοΦ¨ηßΘεé΄εà?optγ¦°εΫïδΗ΄εΤàφîΙεêçεQ?br />
#gunzip -xf nutch-0.9.tar.gz |tar xf
#mv nutch-0.9.tar.gz /usr/local/nutch
΄Ι΄η·ïγé·εΔÉφ‰·εêΠη°³ΓΫ°φàêεäüεQöηΩêηΓ¨οΦö/urs/local/nutch/bin/nutch〴δΗÄδΗ΄φ€âφ≤Γφ€âεëΫδΉoεè²φïΑηΨ™ε΅ΚεQ¨εΠ²φû€φ€âη·¥φ‰éφ≤Γι½°ιΔ‰ψÄ?/p>
φä™ε蕉q΅γ®΄εQ?cd /opt/nutch
#mkdir urls
#vi nutch.txt ηΨ™εÖΞwww.aicent.net
#vi conf/crawl-urlfilter.txt εä†εÖΞδΜΞδΗ΄δΩΓφ¹·εQöεà©γî®φ≠ΘεàôηΓ®ηΨë÷Φèε·ΙγΫëγΪôurlφä™εè•Ϋ{¦ιÄâψÄ?br />
/**** accept hosts in MY.DOMAIN.NAME******/
+^http://([a-z0-9]*\.)*aicent.net/
#vi nutch/nutch-site.xmlεQàγΜôη΅ΣεΖ±γö³η€‰η¦¦εè•δΗÄδΗΣεêçε≠½οΦâη°³ΓΫ°εΠ²δΗ΄εQ?br />
<configuration>
<property>
<name>http.agent.name</name>
<value>test/unique</value>
</property>
</configuration>
εΦÄεß΄φä™εè•οΦö#bin/nutch crawl urls -dir crawl -detpth 5 -thread 10 >& crawl.log
Ϋ{âεΨÖδΗÄδΦöοΦ¨φ½âô½¥δΨùφç°Ψ|ëγΪôγö³εΛßû°èο֨壨η°ΨΨ|°γö³φä™εè•φΖ±εΚΠψÄ?/p>
δΗâοΦöapache-tomcat
ε€®ηΩô顨οΦ¨εΫ™δۆ〴εàΑφ·èφ§Γ΄²Äγ¥Δγö³ôεΒιùΔδΗ?顨οΦ¨ι€ÄηΠ¹δΩ°φîΙδΗÄδΗ΄εè²φïéΆΦ¨ε¦†δΊ™(f®¥)tomcatδΗ≠γö³nutchγö³φΘÄγ¥ΔηΒ\εΨ³δΗçε·öwĆφàêγö³ψÄ?br />
#vi /usr/local/tomcat/webapps/ROOT/WEB-INF/classes/nutch-site.xml
<property>
<name>searcher.dir</name>
<value>/opt/nutch/crawl</value>φä™εè•Ψ|ëιΓΒφâÄε€®γö³ηΖ·εΨ³
<description>My path to nutch's searcher dir.</description>
</property>
#/opt/tomcat/bin/startup.sh
OK,φêûε°öψIJψIJψÄ?/p>
ι½°ιΔ‰φ±΅φÄΜοΦö
‰qêηΓ¨εQösh ./bin/nutch crawl urls -dir crawl -depth 3 -threads 60 -topN 100 >&./logs/nutch_log.log
1.Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.crawl.Injector.inject(Injector.java:162)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:115)
Ψ|ëδΗäφüΞφ€âη·¥φ‰·JDKγâàφ€§γö³ι½°ιΔ‰οΦ¨δΗçηÉΫγî®JDK1.6εQ¨δΚéφ‰·ε°âηΘ?.5ψIJδΫÜφ‰·ηΩ‰φ‰·εê¨φ†οL(f®Ξng)ö³ι½°ιΔ‰εQ¨εΞ΅φÄΣεïäψÄ?br />
δΚéφ‰·Ψlßγ°΄googleεQ¨εèëγéΑφ€âεΠ²δΗ΄γö³εè·ηÉΫοΦö
Injector: Converting injected urls to crawl db entries.
Exception in thread "main" java.io.IOException: Job failed!
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:604)
at org.apache.nutch.crawl.Injector.inject(Injector.java:162)
at org.apache.nutch.crawl.Crawl.main(Crawl.java:115)
η·¥φ‰éεQöδΗÄηà§δΊ™(f®¥)crawl-urlfilters.txtδΗ≠ιÖçΨ|°ι½°ιΔ‰οΦ¨φ·îεΠ²‰q΅φΉoφùΓδögεΚîδΊ™(f®¥)
+^http://www.ihooyo.com ,ηĨιÖçΨ|°φàêδΚ?http://www.ihooyo.com ‰qôφ†Ζγö³φÉÖεÜΒεΑ±εΦïη™vεΠ²δΗäιîôη··ψÄ?/p>
δΫÜφ‰·η΅ΣεΖ±γö³ιÖçΨ|°φ†Ιφ€§εΑ±φ≤Γφ€âι½°ιΔ‰εïäψÄ?br />
ε€®Logsγ¦°εΫïδΗ΄ιùΔιôΛδΚÜγîüφàênutch_log.log‰q‰η΅Σεä®γîüφàêδΗÄδΗΣlogφ•΅δögεQöhadoop.log
εèëγéΑφ€âιîôη··ε΅ΚγééΆΦö
2009-07-22 22:20:55,501 INFO crawl.Crawl - crawl started in: crawl
2009-07-22 22:20:55,501 INFO crawl.Crawl - rootUrlDir = urls
2009-07-22 22:20:55,502 INFO crawl.Crawl - threads = 60
2009-07-22 22:20:55,502 INFO crawl.Crawl - depth = 3
2009-07-22 22:20:55,502 INFO crawl.Crawl - topN = 100
2009-07-22 22:20:55,603 INFO crawl.Injector - Injector: starting
2009-07-22 22:20:55,604 INFO crawl.Injector - Injector: crawlDb: crawl/crawldb
2009-07-22 22:20:55,604 INFO crawl.Injector - Injector: urlDir: urls
2009-07-22 22:20:55,605 INFO crawl.Injector - Injector: Converting injected urls to crawl db entries.
2009-07-22 22:20:56,574 INFO plugin.PluginRepository - Plugins: looking in: /opt/nutch/plugins
2009-07-22 22:20:56,720 INFO plugin.PluginRepository - Plugin Auto-activation mode: [true]
2009-07-22 22:20:56,720 INFO plugin.PluginRepository - Registered Plugins:
2009-07-22 22:20:56,720 INFO plugin.PluginRepository - the nutch core extension points (nutch-extensionpoints)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Basic Query Filter (query-basic)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Basic URL Normalizer (urlnormalizer-basic)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Basic Indexing Filter (index-basic)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Html Parse Plug-in (parse-html)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Basic Summarizer Plug-in (summary-basic)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Site Query Filter (query-site)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - HTTP Framework (lib-http)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Text Parse Plug-in (parse-text)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Regex URL Filter (urlfilter-regex)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Pass-through URL Normalizer (urlnormalizer-pass)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Http Protocol Plug-in (protocol-http)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Regex URL Normalizer (urlnormalizer-regex)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - OPIC Scoring Plug-in (scoring-opic)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - CyberNeko HTML Parser (lib-nekohtml)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - JavaScript Parser (parse-js)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - URL Query Filter (query-url)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Regex URL Filter Framework (lib-regex-filter)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Registered Extension-Points:
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Nutch Summarizer (org.apache.nutch.searcher.Summarizer)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Nutch URL Normalizer (org.apache.nutch.net.URLNormalizer)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Nutch Protocol (org.apache.nutch.protocol.Protocol)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Nutch Analysis (org.apache.nutch.analysis.NutchAnalyzer)
2009-07-22 22:20:56,721 INFO plugin.PluginRepository - Nutch URL Filter (org.apache.nutch.net.URLFilter)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Nutch Indexing Filter (org.apache.nutch.indexer.IndexingFilter)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Nutch Online Search Results Clustering Plugin (org.apache.nutch.clustering.OnlineClusterer)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - HTML Parse Filter (org.apache.nutch.parse.HtmlParseFilter)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Nutch Content Parser (org.apache.nutch.parse.Parser)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Nutch Scoring (org.apache.nutch.scoring.ScoringFilter)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Nutch Query Filter (org.apache.nutch.searcher.QueryFilter)
2009-07-22 22:20:56,722 INFO plugin.PluginRepository - Ontology Model Loader (org.apache.nutch.ontology.Ontology)
2009-07-22 22:20:56,786 WARN regex.RegexURLNormalizer - can't find rules for scope 'inject', using default
2009-07-22 22:20:56,829 WARN mapred.LocalJobRunner - job_2319eh
java.lang.RuntimeException: java.net.UnknownHostException: jackliu: jackliu
at org.apache.hadoop.io.SequenceFile$Writer.<init>(SequenceFile.java:617)
at org.apache.hadoop.io.SequenceFile$Writer.<init>(SequenceFile.java:591)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:364)
at org.apache.hadoop.io.SequenceFile.createWriter(SequenceFile.java:390)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.startPartition(MapTask.java:294)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.sortAndSpillToDisk(MapTask.java:355)
at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.access$100(MapTask.java:231)
at org.apache.hadoop.mapred.MapTask.run(MapTask.java:180)
at org.apache.hadoop.mapred.LocalJobRunner$Job.run(LocalJobRunner.java:126)
Caused by: java.net.UnknownHostException: jackliu: jackliu
at java.net.InetAddress.getLocalHost(InetAddress.java:1353)
at org.apache.hadoop.io.SequenceFile$Writer.<init>(SequenceFile.java:614)
... 8 more
δΙüεΑ±φ‰·HostιÖçγΫ°ιîôη··εQ¨δΚéφ‰·οΦö
Add the following to your /etc/hosts file
127.0.0.1 jackliu
‰qôφ§ΓεÜçφ§Γ‰qêηΓ¨εQ¨γΜ™φû€φàêεäüοΦ¹
2:http://127.0.0.1:8080/nutch-0.9
ηΨ™εÖΞnutch‰q¦ηΓ¨φüΞη·ΔεQ¨γΜ™φû€φäΞιîôοΦö
HTTP Status 500 -
type Exception report
message
description The server encountered an internal error () that prevented it from fulfilling this request.
exception
org.apache.jasper.JasperException: /search.jsp(151,22) Attribute value language + "/include/header.html" is quoted with " which must be escaped when used within the value
org.apache.jasper.compiler.DefaultErrorHandler.jspError(DefaultErrorHandler.java:40)
org.apache.jasper.compiler.ErrorDispatcher.dispatch(ErrorDispatcher.java:407)
org.apache.jasper.compiler.ErrorDispatcher.jspError(ErrorDispatcher.java:198)
org.apache.jasper.compiler.Parser.parseQuoted(Parser.java:299)
org.apache.jasper.compiler.Parser.parseAttributeValue(Parser.java:249)
org.apache.jasper.compiler.Parser.parseAttribute(Parser.java:211)
org.apache.jasper.compiler.Parser.parseAttributes(Parser.java:154)
org.apache.jasper.compiler.Parser.parseInclude(Parser.java:867)
org.apache.jasper.compiler.Parser.parseStandardAction(Parser.java:1134)
org.apache.jasper.compiler.Parser.parseElements(Parser.java:1461)
org.apache.jasper.compiler.Parser.parse(Parser.java:137)
org.apache.jasper.compiler.ParserController.doParse(ParserController.java:255)
org.apache.jasper.compiler.ParserController.parse(ParserController.java:103)
org.apache.jasper.compiler.Compiler.generateJava(Compiler.java:170)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:332)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:312)
org.apache.jasper.compiler.Compiler.compile(Compiler.java:299)
org.apache.jasper.JspCompilationContext.compile(JspCompilationContext.java:586)
org.apache.jasper.servlet.JspServletWrapper.service(JspServletWrapper.java:317)
org.apache.jasper.servlet.JspServlet.serviceJspFile(JspServlet.java:342)
org.apache.jasper.servlet.JspServlet.service(JspServlet.java:267)
javax.servlet.http.HttpServlet.service(HttpServlet.java:717)
note The full stack trace of the root cause is available in the Apache Tomcat/6.0.20 logs.
εàÜφûêεQöφüΞ〴nutch WebεΚîγî®φ†Ιγ¦°εΫïδΗ΄γö³search.jspεè·γüΞεQ¨φ‰·εΦïεèΖε¨öwÖçγö³ι½°ιΔ‰ψÄ?/p>
<jsp:include page="<%= language + "/include/header.html"%>"/> //line 152 search.jsp
ΫW§δΗÄδΗΣεΦïεèΖ壨εêéιùΔΫW§δΗÄδΗΣε΅ΚγéΑγö³εΦïεèΖ‰q¦ηΓ¨ε¨öwÖçεQ¨ηĨδΗçφ‰·ε£¨‰qôδΗÄηΓ¨φ€ÄεêéδΗÄδΗΣεΦïεè·²Ω¦ηΓ¨ε¨ΙιÖçοΦ¨φâÄδΜΞι½°ιΔ‰εΑ±ε΅ΚγéΑδΚÜψÄ?/p>
ηßΘεÜ≥φ•“é(gu®©)≥ïεQ?/p>
û°Üη·ΞηΓ¨δΜΘγ†¹δΩ°φîΙδΊ™(f®¥)εQ?lt;jsp:include page="<%= language+urlsuffix %>"/>
‰qô顨φàëδΜ§ε°öδΗÄδΗΣε≠½ΫWΠδΗ≤urlsuffixεQ¨φàëδΜ§φääε°Éε°öδΙâε€®languageε≠½γ§ΠδΗ≤ε°öδΙâδΙ΄εêéοΦ¨
String language = // line 116 search.jsp
ResourceBundle.getBundle("org.nutch.jsp.search", request.getLocale())
.getLocale().getLanguage();
String urlsuffix="/include/header.html";
δΩ°φîΙε°¨φàêεêéοΦ¨δΗΚγΓ°δΩùδΩ°φî“é(gu®©)àêεäüοΦ¨ι΅çεê·δΗÄδΗ΄Tomcatφ€çεäΓεô®οΦ¨‰q¦ηΓ¨φê€γÉΠεQ¨δΗçεÜçφäΞιîôψÄ?/p>
3.φ½†φ≥ïφüΞη·ΔΨl™φû€εQ?br />
ε·“é(gu®©)·înutch_log.logγö³γΜ™φû€εèëγéΑ壨Ψ|ëδΗäφèèηΩΑγö³δΗçεê¨οΦ¨ηĨδΗîcrawl顨ιùΔεèΣφ€âδΗΛδΗΣφ•΅δögεΛΙsegments壨crawldbεQ¨εêéφùΞι΅çφ•Αγà§δΚÜδΗÄ΄Τ?br />
εèëγéΑ‰qôφ§Γφ‰·εΞΫγö³οΦ¨εΞ΅φÄΣδΗçγüΞι¹™δΗόZΜÄδΙàδΗä΄ΤΓγà§γö³εΛ±η¥ΞδΚÜψÄ?br />
4.cached.jsp explain.jspΫ{âιÉΫφ€âδΗäιù?γö³ιîôη··οΦ¨φ¦¥φ≠Θ‰q΅εéΜû°±O(ji®Γn)KδΚÜψÄ?/p>
5.δΜäεΛ©ηäΉÉΚÜδΗÄδΗäεçà壨εçäδΗΣδΗ΄εçàγö³φ½âô½¥ΨlàδΚéφêûε°öδΚÜnutchγö³ε°âηΘÖ壨ιÖçγΫ°δΚÜψIJφ‰éεΛ©γëτΨl≠ε≠ΠδΙ?f®Λn)ψÄ?/p>
ι²ΘδΙàεQ?br /> String[] phrase = new String[] {"quick", "fox"};
assertFalse("exact phrase not found", matched(phrase, 0));
assertTrue("close enough", matched(phrase, 1));
multi-terms:
assertFalse("not close enough", matched(new String[] {"quick", "jumped", "lazy"}, 3));
assertTrue("just enough", matched(new String[] {"quick", "jumped", "lazy"}, 4));
assertFalse("almost but not quite", matched(new String[] {"lazy", "jumped", "quick"}, 7));
assertTrue("bingo", matched(new String[] {"lazy", "jumped", "quick"}, 8));
φïΑε≠½ηΓ®γΛΚslopεQ¨ιÄöηΩ΅εΠ²δΗ΄φ•ΙεΦèη°³ΓΫ°εQ¨ηΓ®ΫCΚφ¨âγÖßιΓΚεΚèδΜéΫW§δΗÄδΗΣε≠½¨DΒεàΑΫW§δΚ¨δΗΣε≠½¨DΒδΙ΄ι½¥ι½¥ιöîγö³termδΗΣφïΑψÄ?br /> query.setSlop(slop);
ôεΚεΚèεΨàι΅çηΠ¹οΦö
String[] phrase = new String[] {"fox", "quick"};
assertFalse("hop flop", matched(phrase, 2));
assertTrue("hop hop slop", matched(phrase, 3));
εéüγêÜεΠ²δΗ΄ε¦ΨφâÄΫCΚοΦö
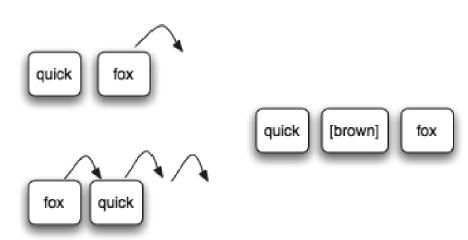
ε·ΙδΚéφüΞη·ΔεÖ≥ιî°ε≠½quick壨foxεQ¨εèΣι€ÄηΠ¹foxΩU’dä®δΗÄδΗΣδΫçΨ|°εç≥εè·ε¨ΙιÖçquick brown foxψIJηĨε·ΙδΚéfox壨quick‰qôδΗΛδΗΣεÖ≥ιî°ε≠½
ι€ÄηΠ¹εΑÜfoxΩU’dä®δΗâδΗΣδΫçγΫ°ψIJγßΜεä®γö³ηΖùγΠΜ≠ëäεΛßεQ¨ι²ΘδΙàηΩôôεΙη°ΑεΫïγö³scoreû°όpΕäû°èοΦ¨ηΔΪφüΞη·Δε΅ΚφùΞγö³εè·ηÉΫηΓ¨εΑ±≠ëäεΑèδΚÜψÄ?br />
SpanQueryεà©γî®δΫçγΫ°δΩΓφ¹·φüΞη·Δφ¦¥φ€âφ³èφÄùγö³φüΞη·ΔεQ?br />
SpanQuery type Description
SpanTermQuery Used in conjunction with the other span query types. On its own, it’s
functionally equivalent to TermQuery.
SpanFirstQuery Matches spans that occur within the first part of a field.
SpanNearQuery Matches spans that occur near one another.
SpanNotQuery Matches spans that don’t overlap one another.
SpanOrQuery Aggregates matches of span queries.
SpanFirstQueryεQöTo query for spans that occur within the first n positions of a field, use Span-FirstQuery.

quick = new SpanTermQuery(new Term("f", "quick"));
brown = new SpanTermQuery(new Term("f", "brown"));
red = new SpanTermQuery(new Term("f", "red"));
fox = new SpanTermQuery(new Term("f", "fox"));
lazy = new SpanTermQuery(new Term("f", "lazy"));
sleepy = new SpanTermQuery(new Term("f", "sleepy"));
dog = new SpanTermQuery(new Term("f", "dog"));
cat = new SpanTermQuery(new Term("f", "cat"));
SpanFirstQuery sfq = new SpanFirstQuery(brown, 2);
assertNoMatches(sfq);
sfq = new SpanFirstQuery(brown, 3);
assertOnlyBrownFox(sfq);
SpanNearQueryεQ?br />
εΫΦφ≠Λγ¦îR²Μγö³ηΖ®εΚ?
3.PhrasePrefixQuery δΗΜηΠ¹γî®φùΞ‰q¦ηΓ¨εê¨δΙâη·çφüΞη·Δγö³εQ?br />
IndexWriter writer = new IndexWriter(directory, new WhitespaceAnalyzer(), true);
Document doc1 = new Document();
doc1.add(Field.Text("field", "the quick brown fox jumped over the lazy dog"));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(Field.Text("field","the fast fox hopped over the hound"));
writer.addDocument(doc2);
PhrasePrefixQuery query = new PhrasePrefixQuery();
query.add(new Term[] {new Term("field", "quick"), new Term("field", "fast")});
query.add(new Term("field", "fox"));
Hits hits = searcher.search(query);
assertEquals("fast fox match", 1, hits.length());
query.setSlop(1);
hits = searcher.search(query);
assertEquals("both match", 2, hits.length());
2ψĹηΩëδΙâη·çφüΞη·ΔψÄ?SynonymAnalyzer壨PhrasePrefixQueryιÉΫηÉΫηßΘεÜ≥‰qôδΗΣι½°ιΔ‰ψÄ?
WhitespaceAnalyzer Splits tokens at whitespace
SimpleAnalyzer Divides text at nonletter characters and lowercases
StopAnalyzer Divides text at nonletter characters, lowercases, and removes stop words
StandardAnalyzer Tokenizes based on a sophisticated grammar that recognizes
e-mail addresses, acronyms, Chinese- Japanese-Korean characters,
alphanumericsεQ?and more; lowercases;and removes stop words
εÄ£φé£γ¥ΔεΦïεQöInverted index
Luceneφ‰·δΗÄδΗΣιΪ‰φÄßηÉΫγö³javaεÖ®φ•΅΄²Äγ¥ΔεΖΞεÖΖε¨ÖεQ¨ε°ÉδΫΩγî®γö³φ‰·εÄ£φé£φ•΅δögγ¥ΔεΦïΨl™φû³ψIJη·ΞΨl™φû³εèäγ¦ΗεΚîγö³γîüφàêΫé½φ≥ïεΠ²δΗ΄εQ?br />
0εQâη°Ψφ€âδΗΛΫ΄΅φ•΅γΪ?ε£?
φ•΅γΪ†1γö³εÜÖε°ΙδΊ™(f®¥)εQöTom lives in Guangzhou,I live in Guangzhou too.
φ•΅γΪ†2γö³εÜÖε°ΙδΊ™(f®¥)εQöHe once lived in Shanghai.
1)γîΉÉΚéluceneφ‰·εüΚδΚéεÖ≥ιî°η·çγ¥ΔεΦï壨φüΞη·Δγö³εQ¨ιΠ•εÖàφàëδΜ§ηΠ¹εè•εΨ½‰qôδΗΛΫ΄΅φ•΅γΪ†γö³εÖ≥ιî°η·çοΦ¨ιÄöεΗΗφàëδΜ§ι€ÄηΠ¹εΠ²δΗ΄εΛ³γêÜφéΣφ•?br /> a.φàëδΜ§γéΑε€®φ€âγö³φ‰·φ•΅γΪ†εÜÖε°ΙοΦ¨εç≥δΗÄδΗΣε≠½ΫWΠδΗ≤εQ¨φàëδΜ§εÖàηΠ¹φâΨε΅Κε≠½ΫWΠδΗ≤δΗ≠γö³φâÄφ€âεçïη·çοΦ¨εç¦_àÜη·çψÄ²η΄±φ•΅εçïη·çγî±δΚéγî®ΫIΚφ†ΦεàÜιöîεQ¨φ·îηΨÉεΞΫεΛ³γêÜψIJδΗ≠φ•΅εçïη·çι½¥φ‰·ηΩûε€®δΗÄηΒοL(f®Ξng)ö³ι€ÄηΠ¹γâΙ¨Däγö³εàÜη·çεΛ³γêÜψÄ?br /> b.φ•΅γΪ†δΗ≠γö³”in”, “once” “too”Ϋ{âη·çφ≤Γφ€âδΜÄδΙàε°ûιôÖφ³èδΙâοΦ¨δΗ≠φ•΅δΗ≠γö³“γö?#8221;“φ‰?#8221;Ϋ{âε≠½ιÄöεΗΗδΙüφ½†εÖΖδΫ™εêΪδΙâεQ¨ηΩôδΚ¦δΗçδΜΘηΓ®φΠ²εΩΒγö³η·çεè·δΜΞ‰q΅φΉoφé?br /> c.γî®φàΖιÄöεΗΗεΗ¨φ€¦φü?#8220;He”φ½ΕηÉΫφääεêΪ“he”εQ?#8220;HE”γö³φ•΅γΪ†δΙüφâë÷΅ΚφùΞοΦ¨φâÄδΜΞφâÄφ€âεçïη·çι€ÄηΠ¹γΜüδΗÄεΛßεΑèεÜôψÄ?br /> d.γî®φàΖιÄöεΗΗεΗ¨φ€¦φü?#8220;live”φ½ΕηÉΫφääεêΪ“lives”εQ?#8220;lived”γö³φ•΅γΪ†δΙüφâë÷΅ΚφùΞοΦ¨φâÄδΜΞι€ÄηΠ¹φää“lives”εQ?#8220;lived”‰q‰εéüφà?#8220;live”
e.φ•΅γΪ†δΗ≠γö³φ†΅γ²ΙΫWΠεèΖιÄöεΗΗδΗçηΓ®ΫCΚφüêΩUçφΠ²εΩΒοΦ¨δΙüεè·δΜΞηΩ΅φΜΛφéâ
ε€®luceneδΗ≠δΜΞδΗäφéΣφ•Ϋγî±AnalyzerΨc’d°¨φà?br />
ΨlèηΩ΅δΗäιùΔεΛ³γêÜεê?br /> φ•΅γΪ†1γö³φâÄφ€âεÖ≥ιî°η·çδΗΚοΦö[tom] [live] [guangzhou] [i] [live] [guangzhou]
φ•΅γΪ†2γö³φâÄφ€âεÖ≥ιî°η·çδΗΚοΦö[he] [live] [shanghai]
2) φ€âδΚÜεÖ≥ιî°η·çεêéεQ¨φàëδΜ§εΑ±εè·δΜΞεΜΚγΪ΄εÄ£φé£γ¥ΔεΦïδΚÜψIJδΗäιùΔγö³ε·ΙεΚîεÖ≥γ≥Μφ‰·οΦö“φ•΅γΪ†εè?#8221;ε·?#8220;φ•΅γΪ†δΗ≠φâÄφ€âεÖ≥ιî°η·ç”ψIJεÄ£φé£γ¥ΔεΦïφääηΩôδΗΣεÖ≥Ψp’dÄ£ηΩ΅φùΞοΦ¨εè‰φàêεQ?#8220;εÖ≥ιî°η·?#8221;ε·?#8220;φ΄Ξφ€âη·ΞεÖ≥ιî°η·çγö³φâÄφ€âφ•΅γΪ†εèΖ”ψIJφ•΅γΪ?εQ?ΨlèηΩ΅εÄ£φé£εêéεè‰φà?br /> εÖ≥ιî°η·?nbsp; φ•΅γΪ†εè?br /> guangzhou 1
he 2
i 1
live 1,2
shanghai 2
tom 1
ιÄöεΗΗδΜÖγüΞι¹™εÖ≥ιî°η·çε€®ε™ΣδΚ¦φ•΅γΪ†δΗ≠ε΅ΚγéΑ‰q‰δΗçεΛüοΦ¨φàëδΜ§‰q‰ι€ÄηΠ¹γüΞι¹™εÖ≥ιî°η·çε€®φ•΅γΪ†δΗ≠ε΅ΚγéΑ΄ΤΓφïΑ壨ε΅ΚγéΑγö³δΫçγΫ°εQ¨ιÄöεΗΗφ€âδΗΛΩUçδΫçΨ|°οΦöa)ε≠½γ§ΠδΫçγΫ°εQ¨εç≥η°ΑεΫïη·Ξη·çφ‰·φ•΅γΪ†δΗ≠ΫW§ε΅†δΗΣε≠½ΫWΠοΦàδΦ‰γ²Ιφ‰·εÖ≥ιî°η·çδΚ°φ‰Ψφ½Εε°öδΫçεΩΪεQâοΦ¦b)εÖ≥ιî°η·çδΫçΨ|°οΦ¨εç¨ô°ΑεΫïη·Ξη·çφ‰·φ•΅γΪ†δΗ≠㧧塆δΗΣεÖ≥ιî°η·çοΦàδΦ‰γ²Ιφ‰·ηä²ΨUΠγÉΠεΦïγ©Κι½¥ψĹη·çΨl³οΦàphaseεQâφüΞη·ΔεΩΪεQâοΦ¨luceneδΗ≠η°ΑεΫïγö³û°±φ‰·‰qôγßçδΫçγΫ°ψÄ?br />
εä†δΗä“ε΅ΚγéΑιΔëγé΅”ε£?#8220;ε΅ΚγéΑδΫçγΫ°”δΩΓφ¹·εêéοΦ¨φàëδΜ§γö³γÉΠεΦïγΜ™φû³εè‰δΗΚοΦö
εÖ≥ιî°η·?nbsp; φ•΅γΪ†εèΖ[ε΅ΚγéΑιΔëγé΅] ε΅ΚγéΑδΫçγΫ°
guangzhou 1[2] 3εQ?
he 2[1] 1
i 1[1] 4
live 1[2],2[1] 2εQ?εQ?
shanghai 2[1] 3
tom 1[1] 1
δΜΞlive‰qôηΓ¨δΗόZΨ΄φàëδΜ§η·¥φ‰éδΗÄδΗ΄η·ΞΨl™φû³εQöliveε€®φ•΅γΪ?δΗ≠ε΅ΚγéνCΚÜ2΄ΤΓοΦ¨φ•΅γΪ†2δΗ≠ε΅ΚγéνCΚÜδΗÄ΄ΤΓοΦ¨ε°Éγö³ε΅ΚγéΑδΫçγΫ°δΗ?#8220;2,5,2”‰qôηΓ®ΫCόZΜÄδΙàεëΔεQüφàëδΜ§ι€ÄηΠ¹γΜ™εêàφ•΅γΪ†εèΖ壨ε΅ΚγéΑιΔëγé΅φùΞεàÜφûêεQ¨φ•΅γΪ?δΗ≠ε΅ΚγéνCΚÜ2΄ΤΓοΦ¨ι²ΘδΙà“2,5”û°όpΓ®ΫCΚliveε€®φ•΅γΪ?δΗ≠ε΅ΚγéΑγö³δΗΛδΗΣδΫçγΫ°εQ¨φ•΅γΪ?δΗ≠ε΅ΚγéνCΚÜδΗÄ΄ΤΓοΦ¨εâ©δΗ΄γö?#8220;2”û°όpΓ®ΫCΚliveφ‰·φ•΅γΪ?δΗ≠㧧2δΗΣεÖ≥ιî°ε≠½ψÄ?br />
δΜΞδΗäû°±φ‰·luceneγ¥ΔεΦïΨl™φû³δΗ≠φ€Äφ†ΗεΩÉγö³ιÉ®εàÜψIJφàëδΜ§φ≥®φ³èεàΑεÖ≥ιî°ε≠½φ‰·φ¨âε≠½ΫWΠιΓΚεΚèφé£εà½γö³εQàluceneφ≤Γφ€âδΫΩγî®Bφ†?w®®i)γΜ™φû³οΦâεQ¨ε¦†φ≠Λluceneεè·δΜΞγî®δΚ¨εÖÉφê€γ¥Δγ°½φ≥ïεΩΪιÄüε°öδΫçεÖ≥ιî°η·çψÄ?br />
ε°ûγéΑφ½?nbsp;luceneû°ÜδΗäιùΔδΗâεà½εàÜεàΪδΫ€δΗχô·çεÖΗφ•΅δΜ”ûΦàTerm DictionaryεQâψĹιΔëγé΅φ•΅δΜ?frequencies)ψĹδΫçΨ|°φ•΅δΜ?positions)δΩùε≠‰ψIJεÖΕδΗ≠η·çεÖΗφ•΅δΜΕδΗçδΜÖδΩùε≠‰φ€âφ·èδΗΣεÖ≥ιî°η·çοΦ¨‰q‰δΩùγïôδΚÜφ¨΅εêëιΔëγé΅φ•΅δög壨δΫçΨ|°φ•΅δΜΕγö³φ¨΅ι£àεQ¨ιÄöηΩ΅φ¨΅ι£àεè·δΜΞφâë÷àΑη·ΞεÖ≥ιî°ε≠½γö³ιΔëγé΅δΩΓφ¹·ε£¨δΫçγΫ°δΩΓφ¹·ψÄ?br />
LuceneδΗ≠δ΄…γî®δΚÜfieldγö³φΠ²εΩΒοΦ¨γî®δΚéηΓ®ηΨΨδΩΓφ¹·φâÄε€®δΫçΨ|°οΦàεΠ²φ†΅ιΔ‰δΗ≠εQ¨φ•΅γΪ†δΗ≠εQ¨urlδΗ≠οΦâεQ¨ε€®εΜΚγÉΠεΦïδΗ≠εQ¨η·ΞfieldδΩΓφ¹·δΙüη°ΑεΫïε€®η·çεÖΗφ•΅δögδΗ≠οΦ¨φ·èδΗΣεÖ≥ιî°η·çιÉΫφ€âδΗÄδΗΣfieldδΩΓφ¹·(妆亙(f®¥)φ·èδΗΣεÖ≥ιî°ε≠½δΗÄε°öε±ûδΚéδΗÄδΗΣφà•εΛöδΗΣfield)ψÄ?br />
δΗόZΚÜε΅èεΑèγ¥ΔεΦïφ•΅δögγö³εΛßû°èοΦ¨Luceneε·ΙγÉΠεΦïηΩ‰δΫΩγî®δΚÜεé΄Ψ~©φäÄφ€·ψIJιΠ•εÖàοΦ¨ε·Ιη·çεÖΗφ•΅δΜΕδΗ≠γö³εÖ≥ιî°η·ç‰q¦ηΓ¨δΚÜεé΄Ψ~©οΦ¨εÖ≥ιî°η·çεé΄Ψ~©δΊ™(f®¥)<εâçγΦÄιïΩεΚΠεQ¨εêéΨ~Ä>εQ¨δΨ΄εΠ²οΦöεΫ™εâçη·çδΊ™(f®¥)“ι‰Ωφ΄âδΦ·η·≠”εQ¨δΗäδΗÄδΗΣη·çδΗ?#8220;ι‰Ωφ΄âδΦ?#8221;εQ¨ι²ΘδΙ?#8220;ι‰Ωφ΄âδΦ·η·≠”εé΄γΨÉδΗ?lt;3εQ¨η·≠>ψIJεÖΕ΄ΤΓεΛßι΅èγî®εàΑγö³φ‰·ε·ΙφïΑε≠½γö³εé΄Ψ~©οΦ¨φïΑε≠½εèΣδΩùε≠‰δΗéδΗäδΗÄδΗΣεÄΦγö³εΖ°εÄϊ|Φà‰qôφ†Ζεè·δΜΞε΅èεΑèφïΑε≠½γö³ιïΩεΚΠοΦ¨‰q¦ηĨε΅èû°ëδΩùε≠‰η·ΞφïΑε≠½ι€ÄηΠ¹γö³ε≠½ηä²φïéΆΦâψIJδΨ΄εΠ²εΫ™εâçφ•΅γΪ†εèΖφ‰?6389εQàδΗçεé΄γΨÉηΠ¹γî®3δΗΣε≠½ηä²δΩùε≠‰οΦâεQ¨δΗäδΗÄφ•΅γΪ†εèδh‰·16382εQ¨εé΄Ψ~©εêéδΩùε≠‰7εQàεèΣγî®δΗÄδΗΣε≠½ηä²οΦâψÄ?br />
δΗ΄ιùΔφàëδΜ§εè·δΜΞιÄöηΩ΅ε·Ιη·Ξγ¥ΔεΦïγö³φüΞη·ΔφùΞηßΘι΅äδΗÄδΗ΄δΊ™(f®¥)δΜÄδΙàηΠ¹εΜΚγΪ΄γ¥ΔεΦïψÄ?br /> ε¹΅η°ΨηΠ¹φüΞη·Δεçïη·?nbsp;“live”εQ¨luceneεÖàε·Ιη·çεÖΗδΚ¨εÖÉφüΞφâΨψĹφâΨεàΑη·Ξη·çοΦ¨ιÄöηΩ΅φ¨΅εêëιΔëγé΅φ•΅δögγö³φ¨΅ι£àη·Με΅ΚφâÄφ€âφ•΅γΪ†εèΖεQ¨γ³ΕεêéηΩîε¦ûγΜ™φû€ψIJη·çεÖîRÄöεΗΗιùûεΗΗû°èο֨妆ηĨοΦ¨φï¥δΗΣ‰q΅γ®΄γö³φ½Ει½¥φ‰·φ·ΪγߣΨUßγö³ψÄ?br /> ηĨγî®φô°ιÄöγö³ôεΚεΚèε¨öwÖçΫé½φ≥ïεQ¨δΗçεΜΚγÉΠεΦïοΦ¨ηĨφ‰·ε·“é(gu®©)âÄφ€âφ•΅γΪ†γö³εÜÖε°Ι‰q¦ηΓ¨ε≠½γ§ΠδΗ≤ε¨ΙιÖçοΦ¨‰qôδΗΣ‰q΅γ®΄û°ÜδΦöγ¦ΗεΫ™Ψ~™φÖΔεQ¨εΫ™φ•΅γΪ†φïΑγ¦°εΨàεΛßφ½”ûΦ¨φ½âô½¥εΨÄεΨÄφ‰·φ½†φ≥ïεΩçεè½γö³ψÄ?br />
η΅Σφàëη·³η°ΚεQ?br /> ‰q‰εè·δΜΞεè²ηÄÉhttp://zh.wikipedia.org/wiki/%E5%80%92%E6%8E%92%E7%B4%A2%E5%BC%95
δΚ¨εÖÉφê€γÉΠΫé½φ≥ï
ε€®φé£εΞΫεΚèγö³φïΑΨl³δΗ≠φâë÷àΑγâΙε°öγö³εÖÉ㥆ψÄ?br /> ιΠ•εÖà, φ·îηΨÉφïΑγΜ³δΗ≠ι½¥γö³εÖÉ㥆οΦ¨εΠ²φû€γ¦Ηεê¨εQ¨εàô‰qîε¦ûφ≠ΛεÖÉ㥆γö³φ¨΅ι£àεQ¨ηΓ®ΫCΚφâΨεàνCΚÜψÄ?εΠ²φû€δΗçγ¦Ηεê¨οΦ¨ φ≠Λε΅ΫφïΑεΑ±δΦöγëτΨl≠φê€γ¥ΔεÖΕδΗ≠εΛßû°èγ¦ΗΫWΠγö³δΗÄεçäοΦ¨γ³ΕεêéΨlßγ°΄δΗ΄εéΜψIJεΠ²φû€εâ©δΗ΄γö³φïΑγΜ³ιïΩεΚΠδΗ?εQ¨εàôηΓ®γΛΚφâΨδΗçεàéΆΦ¨ι²ΘδΙàε΅ΫφïΑû°ΉÉΦöΨl™φùüψÄ?br /> φ≠Λγ°½φ≥ïε΅ΫφïΑεΠ²δΗ΄οΦö
int *binarySearch(int val, int array[], int n)
{
int m = n/2;
if(n <= 0) return NULL;
if(val == array[m]) return array + m;
if(val < array[m]) return binarySearch(val, array, m);
else return binarySearch(val, array+m+1, n-m-1);
}
ε·ΙδΚéφ€ânδΗΣεÖÉ㥆γö³φïΑγΜ³φùΞη·¥εQ¨δΚ¨εÖÉφê€γ¥Δγ°½φ≥ïηΩ¦ηΓ¨φ€ÄεΛ?+log2(n)΄ΤΓφ·îηΨÉψÄ?εΠ²φû€φ€âδΗÄγôΨδΗ΅εÖÉ㥆εQ¨εΛßφΠ²φ·îηΨ?0΄ΤΓοΦ¨δΙüεΑ±φ‰·φ€ÄεΛ?0΄ΤΓιÄ£εΫ£φâßηΓ¨binarySearch()ε΅ΫφïΑψÄ?/p>
protected String[] unindexed = {"Netherlands", "Italy"};
protected String[] unstored = {"Amsterdam has lots of bridges", "Venice has lots of canals"};
protected String[] text = {"Amsterdam", "Venice"};
Directory dir = FSDirectory.getDirectory(indexDir, true);
IndexWriter writer = new IndexWriter(dir, new SimpleAnalyzer(), true);
writer.setUseCompoundFile(true);
for (int i = 0; i < keywords.length; i++) {
Document doc = new Document();
doc.add(Field.Keyword("id", keywords[i]));
doc.add(Field.UnIndexed("country", unindexed[i]));
doc.add(Field.UnStored("contents", unstored[i]));
doc.add(Field.Text("city", text[i]));
writer.addDocument(doc);
}
writer.optimize();
writer.close();
2.Removing Documents from an indexεQ?br /> IndexReader reader = IndexReader.open(dir);
reader.delete(1);
δΗäιùΔγö³φ•ΙεΦèδΗÄ΄ΤΓεèΣηÉΫεà†ιôΛδΗÄδΗΣdocumentεQ¨δΗ΄ιùΔγö³φ•“é(gu®©)≥ïεè·δΜΞεà†ιôΛεΛöδΗΣφΜΓηÉωφùΓδögγö³document
IndexReader reader = IndexReader.open(dir);
reader.delete(new Term("city", "Amsterdam"));
reader.close();
3.Index dates
Document doc = new Document();
doc.add(Field.Keyword("indexDate", new Date()));
4.Tuning indexing performance
IndexWriter System property Default value Description
--------------------------------------------------------------------------------------------------
mergeFactor org.apache.lucene.mergeFactor 10 Controls segment merge frequency and size
maxMergeDocs org.apache.lucene.maxMergeDocs Integar.MAX_VALUE Limits the number of documents per segement
minMergeDocs org.apache.lucene.minMergeDocs 10 Controls the amount of RAM used when indexing
mergeFactorφéßεàΕεÜôεÖΞΦ΄§γ¦‰εâçεÜÖε≠‰δΗ≠Ψ~™ε≠‰γö³documentφïΑι΅èεQ¨εê¨φ½ΕφéßεàΕmerge index segmentsγö³ιΔëγé΅ψIJεÖΕιΜ‰η°ΛεÄΦφ‰·10εQ¨εç≥ε≠‰φΜΓ10δΗ?br />
documentsεêéεΑ±εΩÖιΓΜεÜôεÖΞΦ΄§γ¦‰εQ¨ηĨδΗîεΠ²φû€segmentγö³φïΑι΅èηΨΨεà?0γö³γώîφïΑγö³φ½ΕεÄôδΦömergeφàêδΗÄδΗΣsegmentεQ¨εΫ™γ³ΕmaxMergeDocsιôêεàΕδΚÜφ·èδΗ?br />
segmentφ€ÄεΛßηÉΫεΛüδΩùε≠‰γö³documentφïΑι΅èψIJmergeFactor≠ëäεΛßγö³η·ùû°όpΕäηÉΫεà©γî®RAMεQ¨φèêιΪ‰indexγö³φïàγé΅οΦ¨δΫÜφ‰·mergeFactor≠ëäιΪ‰δΙüεΑ±φ³èεë≥γùÄ
mergeγö³ιΔëγé΅εΑ±≠ëäδΫéεQ¨δΦöεè·ηÉΫε·ΤD΅¥segmentsγö³φïΑι΅èεΨàεΛßοΦà妆亙(f®¥)φ≤Γφ€âmergeεQâοΦ¨‰qôφ†Ζsearchγö³φ½ΕεÄôεΑ±ι€ÄηΠ¹φâ™εΦÄφ¦¥εΛöγö³segmentφ•΅δögεQ¨δΙüû°?br />
ιôçδΫéδΚÜsearchγö³φïàγé΅ψIJminMergeDocs is another IndexWriter instance variable that affects indexing performance. Its
value controls how many Documents have to be buffered before they’re merged to a segment.δΙüεç≥φ‰·η·¥minMergeDocsδΙüεÖΖφ€?br />
mergeFactorφéßεàΕΨ~™ε≠‰documentφïΑι΅èγö³εäüηÉΫψÄ?/p>
5.RAMDirectoryεΗ°εä©εà©γî®RAMεQ¨δΙüεè·δΜΞι΅΅γî®ι¦ÜγΨΛφà•ηÄÖεΛöΨUΩγ®΄γö³φ•ΙεΦèεÖÖεàÜεà©γî®γΓ§δΜΕ壨ηΫ·δögηΒ³φΚêεQ¨φèêιΪ‰indexγö³φïàγé΅ψÄ?/p>
6.φ€âφ½ΕεÄôε·ΙδΚéφ·èδΗΣfieldεè·ηÉΫεΗ¨φ€¦φéßεàΕεÖΕεΛßû°èοΦ¨φ·îεΠ²εèΣε·Ιεâ?000δΗΣtermε¹öindexεQ¨ηΩôδΗΣφ½ΕεÄôεΑ±ι€ÄηΠ¹δ΄…γî®maxFieldLengthφùΞφéßεàΕψÄ?/p>
7.IndexWriter’s optimize()φ•“é(gu®©)≥ïû°±φ‰·û°Üsegments‰q¦ηΓ¨mergeεQ¨ιôçδΫésegmentsγö³φïΑι΅èδΜéηĨε΅èû°ësearchγö³φ½ΕεÄôη·Μεè•indexγö³φ½Ει½¥ψÄ?/p>
8.φ≥®φ³èεΛöγΚΩΫE΄γé·εΔÉδΗ΄γö³εΖΞδΫ€οΦöan index-modifying IndexReader operation can’t be executed
while an index-modifying IndexWriter operation is in progress.δΗόZΚÜι‰≤φ≠Δη··γî®εQ¨Luceneε€®δ΄…γî®φüêδΚ¦APIφ½ΕδΦöΨl?br />
indexδΗäιî¹ψÄ?/p>
Searcher searcher = new IndexSearcher(dbpath);
Query query = QueryParser.parse(searchkey, searchfield,
new StandardAnalyzer());
Hits hits = searcher.search(query);
δΗ΄ιùΔφ‰·Queryγö³εê³ΩUçε≠êφüΞη·ΔεQ¨δΜ•δΜ§φ•½ι±ΦQueryParserιÉΫφ€âε·ΙεΚîεÖ≥γ≥ΜψÄ?/p>
1.TermQueryεΗΗγî®εQ¨ε·ΙδΗÄδΗΣTermεQàφ€Äû°èγö³γ¥ΔεΦïεù½οΦ¨ε¨ÖεêΪδΗÄδΗΣfieldεêçε≠½ε£¨εÄϊ|Φâ‰q¦ηΓ¨γ¥ΔεΦïφüΞη·ΔψÄ?br /> Term㦥φéΞδΗéQueryParser.parse顨ιùΔγö³key壨field㦥φéΞε·ΙεΚîψÄ?/p>
IndexSearcher searcher = new IndexSearcher(directory);
Term t = new Term("isbn", "1930110995");
Query query = new TermQuery(t);
Hits hits = searcher.search(query);
2.RangeQueryγî®δΚéε¨Κι½¥φüΞη·Δ,RangeQueryγö³γ§§δΗâδΗΣεè²φïΑηΓ®γΛΚφ‰·εΦÄε¨Κι½¥‰q‰φ‰·ι½≠ε¨Κι½¥ψÄ?br /> QueryParserδΦöφû³εΜόZΜébeginεàΑendδΙ΄ι½¥γö³NδΗΣφüΞη·ΔηΩ¦ηΓ¨φüΞη·ΔψÄ?/p>
Term begin, end;
Searcher searcher = new IndexSearcher(dbpath);
begin = new Term("pubmonth","199801");
end = new Term("pubmonth","199810");
RangeQuery query = new RangeQuery(begin, end, true);
RangeQueryφ€§η¥®φ‰·φ·îηΨÉεΛßû°èψIJφâÄδΜΞεΠ²δΗ΄φüΞη·ΔδΙüφ‰·εè·δΜΞγö³εQ¨δΫÜφ‰·φ³èδΙâεΑ±δΚéδΗäιùΔδΗçεΛßδΗÄφ†ΖδΚÜεQ¨φÄ÷MΙ΄φ‰·εΛßû°èγö³φ·îηΨÉ
η°ë÷°öδΚÜδΗÄδΗΣε¨Κι½Ώ_Φ¨ε€®ε¨Κι½¥εÜÖγö³ιÉΫηÉΫεΛüφê€γÉΠε΅ΚφùΞεQ¨ηΩô顨εΑ±ε≠‰ε€®δΗÄδΗΣφ·îηΨÉεΛßû°èγö³εéüεàôεQ¨φ·îεΠ²ε≠½ΫWΠδΗ≤δΦöιΠ•εÖàφ·îηΨÉ㧧δΗÄδΗΣε≠½ΫWΠοΦ¨‰qôφ†ΖδΗéε≠½ΫWΠιïΩεΚΠφ≤Γφ€âεÖ≥ΨpÖRÄ?br />
begin = new Term("pubmonth","19");
end = new Term("pubmonth","20");
RangeQuery query = new RangeQuery(begin, end, true);
3.PrefixQuery.ε·ΙδΚéTermQueryεQ¨εΩÖôε’d°¨εÖ®ε¨ΙιÖçοΦàγî®Field.Keywordγîüφàêγö³ε≠½¨DΒοΦâφâçηÉΫεΛüφüΞη·Δε΅ΚφùΞψÄ?br />
‰qôεΑ±εàΕγΚΠδΚÜφüΞη·Δγö³γ¹â|¥ΜφÄßοΦ¨PrefixQueryεèΣι€ÄηΠ¹ε¨ΙιÖçvalueγö³εâçιùΔδ™QδΫïε≠½¨DΒεç≥εè·ψIJεΠ²FieldδΗΚnameεQ¨η°ΑεΫ?br />
δΗ≠ι²ΘδΙàφ€âjackliu,jackwu,jackli,ι²ΘδΙàδΫΩγî®jackû°±εè·δΜΞφüΞη·Δε΅ΚφâÄφ€âγö³η°ΑεΫïψIJQueryParser creates a PrefixQuery
for a term when it ends with an asterisk (*) in query expressions.
IndexSearcher searcher = new IndexSearcher(directory);
Term term = new Term("category", "/technology/computers/programming");
PrefixQuery query = new PrefixQuery(term);
Hits hits = searcher.search(query);
4.BooleanQuery.δΗäιùΔφâÄφ€âγö³φüΞη·ΔιÉΫφ‰·εüόZΚéεçïδΗΣfieldγö³φüΞη·ΔοΦ¨εΛöδΗΣfieldφÄéδΙàφüΞη·ΔεëΔοΦ¨BooleanQuery
û°±φ‰·ηßΘεÜ≥εΛöδΗΣφüΞη·Δγö³ι½°ιΔ‰ψIJιÄöηΩ΅add(Query query, boolean required, boolean prohibited)εä†εÖΞ
εΛöδΗΣφüΞη·Δ.ιÄöηΩ΅BooleanQueryγö³εΒ¨εΞ½εè·δΜΞγΜ³εêàιùûεΗΗεΛçφù²γö³φüΞη·ΔψÄ?br />
IndexSearcher searcher = new IndexSearcher(directory);
TermQuery searchingBooks =
new TermQuery(new Term("subject","search"));
RangeQuery currentBooks =
new RangeQuery(new Term("pubmonth","200401"),
new Term("pubmonth","200412"),true);
BooleanQuery currentSearchingBooks = new BooleanQuery();
currentSearchingBooks.add(searchingBook s, true, false);
currentSearchingBooks.add(currentBooks, true, false);
Hits hits = searcher.search(currentSearchingBooks);
BooleanQueryγö³addφ•“é(gu®©)≥ïφ€âδΗΛδΗΣbooleanεè²φïΑεQ?br />
trueεQÜfalseεQöηΓ®φ‰éεΫ™εâçεä†εÖΞγö³ε≠êεèΞφ‰·εΩÖôεΜηΠ¹φΜΓηÉωγö³οΦ¦
falseεQÜtrueεQöηΓ®φ‰éεΫ™εâçεä†εÖΞγö³ε≠êεèΞφ‰·δΗçεè·δΜΞηΔΪφΜΓ≠ë≥γö³εQ?br />
falseεQÜfalseεQöηΓ®φ‰éεΫ™εâçεä†εÖΞγö³ε≠êεèΞφ‰·εè·ιÄâγö³εQ?br />
trueεQÜtrueεQöιîôη··γö³φÉÖεÜΒψÄ?/p>
QueryParser handily constructs BooleanQuerys when multiple terms are specified.
Grouping is done with parentheses, and the prohibited and required flags are
set when the –, +, AND, OR, and NOT operators are specified.
5.PhraseQuery‰q¦ηΓ¨φ¦¥δΊ™(f®¥)Ψ_³ΓΓ°γö³φüΞφâΨψIJε°ÉηÉΫεΛüε·ΙγÉΠεΦïφ•΅φ€§δΗ≠γö³δΗΛδΗΣφà•φ¦¥εΛöγö³εÖ≥ιî°η·çγö³δΫçΨ|°ηΩ¦ηΓ?br />
ιôêε°öψIJεΠ²φê€φüΞε¨ÖεêΪA壨BρqΕδΗîAψĹBδΙ΄ι½¥‰q‰φ€âδΗÄδΗΣφ•΅ε≠½ψIJTerms surrounded by double quotes in
QueryParser parsed expressions are translated into a PhraseQuery.
The slop factor defaults to zero, but you can adjust the slop factor
by adding a tilde (~) followed by an integer.
For example, the expression "quick fox"~3
6.WildcardQuery.WildcardQueryφ·îPrefixQueryφèêδΨ¦δΚÜφ¦¥ΨlÜγö³φéßεàΕ壨φ¦¥εΛßγö³γ¹â|¥ΜφÄßοΦ¨‰qôδΗΣφ€Äε°“é(gu®©)‰™
γêÜηßΘ壨䴅γî®ψÄ?/p>
7.FuzzyQuery.‰qôδΗΣQueryφ·îηΨÉγâΙεàΪεQ¨ε°ÉδΦöφüΞη·ΔδΗéεÖ≥ιî°ε≠½ιïΩεΨ½εΨàεÉèγö³εÖΕδΜ•η°ΑεΫïψIJQueryParser
supports FuzzyQuery by suffixing a term with a tilde (~),for exmaple wuzza~.
public void testFuzzy() throws Exception {
indexSingleFieldDocs(new Field[] {
Field.Text("contents", "fuzzy"),
Field.Text("contents", "wuzzy")
});
IndexSearcher searcher = new IndexSearcher(directory);
Query query = new FuzzyQuery(new Term("contents", "wuzza"));
Hits hits = searcher.search(query);
assertEquals("both close enough", 2, hits.length());
assertTrue("wuzzy closer than fuzzy",
hits.score(0) != hits.score(1));
assertEquals("wuzza bear","wuzzy", hits.doc(0).get("contents"));
}
ε€®εÖ®φ•΅φΘÄγ¥ΔδΗ≠εQ¨εè·δΜΞ壨φïΑφç°εΚ™ηΩ¦ηΓ¨δΗÄδΗΣγ°Äεçïγö³ε·“é(gu®©)·î
εÖ®φ•΅΄²Äγ¥Δφ≤Γφ€âηΓ®γö³φΠ²εΩΒοΦ¨δΙüεΑ±φ≤Γφ€âε¦Κε°öγö³fieldsεQ¨δΫÜφ‰·φ€âη°ΑεΫïεQ¨φ·èδΗÄδΗΣη°ΑεΫïεΑ±φ‰·δΗÄδΗΣDocumentε·Ιη±Γ
φ·èδΗÄδΗΣdocumentιÉΫεè·δΜΞφ€âη΅ΣεΖ±δΗçεê¨γö³fieldsεQ¨εΠ²δΗ΄οΦö
Document doc = new Document();
doc.add(Field.Keyword("filename",file.getAbsolutePath()));
//δΜΞδΗ΄δΗΛεèΞεèΣηÉΫεè•δΗÄεè?εâçηÄÖφ‰·γ¥ΔεΦïδΗçε≠‰ε²?εêéηÄÖφ‰·γ¥ΔεΦïδΗîε≠‰ε²?
//doc.add(Field.Text("content",new FileReader(file)));
doc.add(Field.Text("content",this.chgFileToString(file)));
indexWriter.addDocument(doc);
ε€®φüΞη·Δγö³φ½ΕεÄôοΦ¨ι€ÄηΠ¹δΗâδΗΣι΅çηΠ¹γö³εè²φïΑ
ιΠ•εÖàφ‰·εΚ™ηΖ·εΨ³εQ¨εç≥ε€®ε™ΣδΗΣεʙ顨ιùΔ‰q¦ηΓ¨΄²Äγ¥ΔοΦàγ¦ΗεΫ™δΚédatabaseγö³ηΒ\εΨ³οΦâεQ?br />
Searcher searcher = new IndexSearcher(dbpath);
γ³Εεêéû°±φ‰·δΫ†δΜΞε™ΣδΗΣε≠½φ°ΒεQ¨φüΞη·ΔδΜÄδΙàεÖ≥ιî°η·çεQ¨ε¦†δΗΚφ†Ιφç°ε≠½¨DΒεΑ±εè·δΜΞεΨ½εàΑε≠½φ°Βε·ΙεΚîγö³εÜÖε°?br /> ε€®εΨ½εàΑγö³εÜÖε°ΙδΗ≠φΘÄγ¥ΔδΫ†γö³εÖ≥ιî°η·çεQ¨ηΩôδΗΣγ·èφ≠Μsqlη·≠εèΞεQ¨εèΣδΗçηΩ΅φ≤Γφ€âηΓ®γö³φΠ²εΩΒ
Query query
= QueryParser.parse(searchkey,searchfield,new StandardAnalyzer());
γ³ΕεêéεΦÄεß΄φüΞη·ΔοΦ¨φüΞη·Δγö³γΜ™φû€εΑ±φ‰·documentγö³ι¦ÜεêàοΦö
Hits hits = searcher.search(query);
ε·ΙεΨ½εàΑγö³ι¦Üεêà‰q¦ηΓ¨εΛ³γêÜεQ?br />
if(hits != null)
{
list = new ArrayList();
int temp_hitslength = hits.length();
Document doc = null;
for(int i = 0;i < temp_hitslength; i++){
doc = hits.doc(i);
//list.add(doc.get("filename"));
list.add(doc.get("content"));
}
}
ιô³εΗΗγî®FieldεQ?span style="font-size: 10pt; color: black; font-family: ε°΄δΫ™;">
εΗΗγî®γö?/span>Fieldφ•“é(gu®©)≥ïεΠ²δΗ΄εQ?/span>
|
φ•“é(gu®©)≥ï |
εà΅η·ç |
γ¥ΔεΦï |
ε≠‰ε²® |
γî®ιÄ?/span> |
|
Field.Text(String name, String value) |
Yes |
Yes |
Yes |
εà΅εàÜη·çγÉΠεΦïεΤàε≠‰ε²®εQ¨φ·îεΠ²οΦöφ†΅ιΔ‰εQ¨εÜÖε°Ιε≠½¨D?/span> |
|
Field.Text(String name, Reader value) |
Yes |
Yes |
No |
εà΅εàÜη·çγÉΠεΦïδΗçε≠‰ε²®εQ¨φ·îεΠ²οΦöMETAδΩΓφ¹·εQ?/span> δΗçγî®δΚéηΩîε¦ûφ‰ΨΫCΚοΦ¨δΫÜι€ÄηΠ¹ηΩ¦ηΓ¨φΘÄγ¥ΔεÜÖε°?/span> |
|
Field.Keyword(String name, String value) |
No |
Yes |
Yes |
δΗçεà΅εàÜγÉΠεΦïεΤàε≠‰ε²®εQ¨φ·îεΠ²οΦöφ½Ξφ€üε≠½φ°Β |
|
Field.UnIndexed(String name, String value) |
No |
No |
Yes |
δΗçγÉΠεΦïοΦ¨εèΣε≠‰ε²®οΦ¨φ·îεΠ²εQöφ•΅δΜΕηΒ\εΨ?/span> |
|
Field.UnStored(String name, String value) |
Yes |
Yes |
No |
εèΣεÖ®φ•΅γÉΠεΦïοΦ¨δΗçε≠‰ε²?/span> |
εà΅εàÜη·? û°±φ‰·φ¨΅ε·Ιφ•΅φ€§‰q¦ηΓ¨εà΅η·çεQ¨γî®δΚéηΩ¦ηΓ¨γÉΠεΦïοΦ¨δΗäιùΔεè·δΜΞ〴εàΑεà΅εàÜγö³ιÉΫδΦöηΩ¦ηΓ¨γÉΠεΦïοΦ¦γ¥ΔεΦïεç≥γî®δΚéιÄöηΩ΅φê€γÉΠη·çηΩ¦ηΓ¨φüΞη·ΔοΦ¦ε≠‰ε²®ηΓ®γΛΚφ‰·εêΠε≠‰ε²®εÜÖε°Ιφ€§ημnψIJδΗäιùΔγö³ Field.Keywordφ•“é(gu®©)≥ïû°ΉÉΗçεà΅εàÜδΫÜφ‰·εè·δΜΞγ¥ΔεΦïεQ¨φâÄδΜΞεè·δΜΞγqôδΗΣε≠½φ°Β‰q¦ηΓ¨φüΞη·ΔεQ¨ηĨField.UnIndexedû°ΉÉΗçηÉΫηΩ¦ηΓ¨φüΞη·ΔδΚÜψIJδΫÜφ‰·γî±δΚ? Field.KeywordδΗçεà΅εàÜοΦ¨φâÄδΜΞεΫ™δΫΩγî®new Term(searchkey,searchfield)‰q¦ηΓ¨φüΞη·Δφ½”ûΦ¨Ψlôε΅Κγö³searchkeyεΩÖιΓΜδΗévaueεè²φïΑεÄΦε°¨εÖ®δΗÄη΅¥φâçδΦöφüΞη·Δε΅ΚφùΞοΦ¨ηÄ? Field.Text壨Field.UnStoredεàôεΑ±δΗçδΗÄφ†?/span>ψÄ?br />
LuceneδΗ≠ε¦Ϋφ‰·δΗÄδΗΣιùûεΗΗεΞΫγö³γΫëγΪôοΦ¨ε·ΙLuceneεÜÖιÉ®Ψl™φû³‰q¦ηΓ¨δΚÜη·ΠΨlÜγö³εàÜφûêεQ¨εè·δΜΞεè²ηÄÉψÄ?br />