PhraseQuery使用位置信息來進行相關查詢,比如TermQuery使用“我們”和“祖國”進行查詢,那么文檔中含有這兩個詞的所有記錄都會被查詢出來。但是有一種情況,我們可能需要查詢“我們”和“中國”之間只隔一個字和兩個字或者兩個字等,而不是它們之間字距相差十萬八千里,就可以使用PhraseQuery。比如下面的情況:
doc.add(Field.Text("field", "the quick brown fox jumped over the lazy dog"));
那么:
String[] phrase = new String[] {"quick", "fox"};
assertFalse("exact phrase not found", matched(phrase, 0));
assertTrue("close enough", matched(phrase, 1));
multi-terms:
assertFalse("not close enough", matched(new String[] {"quick", "jumped", "lazy"}, 3));
assertTrue("just enough", matched(new String[] {"quick", "jumped", "lazy"}, 4));
assertFalse("almost but not quite", matched(new String[] {"lazy", "jumped", "quick"}, 7));
assertTrue("bingo", matched(new String[] {"lazy", "jumped", "quick"}, 8));
數字表示slop,通過如下方式設置,表示按照順序從第一個字段到第二個字段之間間隔的term個數。
query.setSlop(slop);
順序很重要:
String[] phrase = new String[] {"fox", "quick"};
assertFalse("hop flop", matched(phrase, 2));
assertTrue("hop hop slop", matched(phrase, 3));
原理如下圖所示:
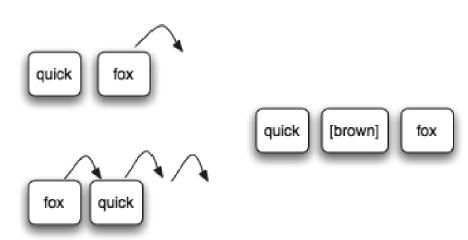
對于查詢關鍵字quick和fox,只需要fox移動一個位置即可匹配quick brown fox。而對于fox和quick這兩個關鍵字
需要將fox移動三個位置。移動的距離越大,那么這項記錄的score就越小,被查詢出來的可能行就越小了。
SpanQuery利用位置信息查詢更有意思的查詢:
SpanQuery type Description
SpanTermQuery Used in conjunction with the other span query types. On its own, it’s
functionally equivalent to TermQuery.
SpanFirstQuery Matches spans that occur within the first part of a field.
SpanNearQuery Matches spans that occur near one another.
SpanNotQuery Matches spans that don’t overlap one another.
SpanOrQuery Aggregates matches of span queries.
SpanFirstQuery:To query for spans that occur within the first n positions of a field, use Span-FirstQuery.

quick = new SpanTermQuery(new Term("f", "quick"));
brown = new SpanTermQuery(new Term("f", "brown"));
red = new SpanTermQuery(new Term("f", "red"));
fox = new SpanTermQuery(new Term("f", "fox"));
lazy = new SpanTermQuery(new Term("f", "lazy"));
sleepy = new SpanTermQuery(new Term("f", "sleepy"));
dog = new SpanTermQuery(new Term("f", "dog"));
cat = new SpanTermQuery(new Term("f", "cat"));
SpanFirstQuery sfq = new SpanFirstQuery(brown, 2);
assertNoMatches(sfq);
sfq = new SpanFirstQuery(brown, 3);
assertOnlyBrownFox(sfq);
SpanNearQuery:
彼此相鄰的跨度
首先,強調一下PhraseQuery對象,這個對象不屬于跨度查詢類,但能完成跨度查詢功能。
匹配到的文檔所包含的項通常是彼此相鄰的,考慮到原文檔中在查詢項之間可能有一些中間項,或為了能查詢倒排的項,PhraseQuery設置了slop因子,但是這個slop因子指2個項允許最大間隔距離,不是傳統意義上的距離,是按順序組成給定的短語,所需要移動位置的次數,這表示PhraseQuery是必須按照項在文檔中出現的順序計算跨度的,如quick brown fox為文檔,則quick fox2個項的slop為1,quick向后移動一次.而fox quick需要quick向后移動3次,所以slop為3
其次,來看一下SpanQuery的子類SpanTermQuery。
它能跨度查詢,并且不一定非要按項在文檔中出現的順序,可以用一個獨立的標記表示查詢對象必須按順序,或允許按倒過來的順序完成匹配。匹配的跨度也不是指移動位置的次數,是指從第一個跨度的起始位置到最后一個跨度的結束位置。
在SpanNearQuery中將SpanTermQuery對象作為SpanQuery對象使用的效果,與使用PharseQuery的效果非常相似。在SpanNearQuery的構造函數中的第三個參數為inOrder標志,設置這個標志,表示按項在文檔中出現的順序倒過來的順序。
如:the quick brown fox jumps over the lazy dog這個文檔
public void testSpanNearQuery() throws Exception{
SpanQuery[] quick_brown_dog=new SpanQuery[]{quick,brown,dog};
SpanNearQuery snq=new SpanNearQuery(quick_brown_dog,0,true);//按正常順序,跨度為0,對三個項進行查詢
assertNoMatches(snq);//無法匹配
SpanNearQuery snq=new SpanNearQuery(quick_brown_dog,4,true);//按正常順序,跨度為4,對三個項進行查詢
assertNoMatches(snq);//無法匹配
SpanNearQuery snq=new SpanNearQuery(quick_brown_dog,4,true);//按正常順序,跨度為5,對三個項進行查詢
assertOnlyBrownFox(snq);//匹配成功
SpanNearQuery snq=new SpanNearQuery(new SpanQuery[]{lazy,fox},3,false);//按相反順序,跨度為3,對三個項進行查詢
assertOnlyBrownFox(snq);//匹配成功
//下面使用PhraseQuery進行查詢,因為是按順序,所以lazy和fox必須要跨度為5
PhraseQuery pq=new PhraseQuery();
pq.add(new Term("f","lazy"));
pq.add(new Term("f","lazy"));
pq.setslop(4);
assertNoMatches(pq);//跨度4無法匹配
//PharseQuery,slop因子為5
pq.setSlop(5);
assertOnlyBrownFox(pq);
}
3.PhrasePrefixQuery 主要用來進行同義詞查詢的:
IndexWriter writer = new IndexWriter(directory, new WhitespaceAnalyzer(), true);
Document doc1 = new Document();
doc1.add(Field.Text("field", "the quick brown fox jumped over the lazy dog"));
writer.addDocument(doc1);
Document doc2 = new Document();
doc2.add(Field.Text("field","the fast fox hopped over the hound"));
writer.addDocument(doc2);
PhrasePrefixQuery query = new PhrasePrefixQuery();
query.add(new Term[] {new Term("field", "quick"), new Term("field", "fast")});
query.add(new Term("field", "fox"));
Hits hits = searcher.search(query);
assertEquals("fast fox match", 1, hits.length());
query.setSlop(1);
hits = searcher.search(query);
assertEquals("both match", 2, hits.length());