Author:放翁(文初)
Date: 2010/11/23
Email:fangweng@taobao.com
mblog: http://t.sina.com.cn/fangweng
blog: http://blog.csdn.net/cenwenchu79/
這篇文章將會從問題,技術背景,設計實現,代碼范例這些角度去談基于管道化和事件驅動模型的Web請求處理,其中的一些描述和例子也許不是很恰當,也希望得到更多的反饋。
業務架構設計:
基于上述問題,通過兩步走來解決。首先采用支持打破傳統http request生命周期管理的Web容器(很多人說可以自己寫,其實Web容器寫起來并不是最麻煩的,如何做好兼容和照顧好每一個細節才是漫長發展的道路)。其次在容器新的線程生命周期管理基礎上封裝業務框架,為開發者屏蔽底層異步化和事件驅動模式帶來的復雜流程管理內容。

Pipe Service Framework:
基礎管道體系:
很多時候設計和實現都會有很多細節上的差異,而這些差異往往是在事實驗證后對體系的一種修訂,也許修訂后的結構不如修訂前的清晰和優雅,但是確實在性能和結構上找到了平衡點,下面就看看兩個基礎管道體系的設計,后一個是前一個的演進。
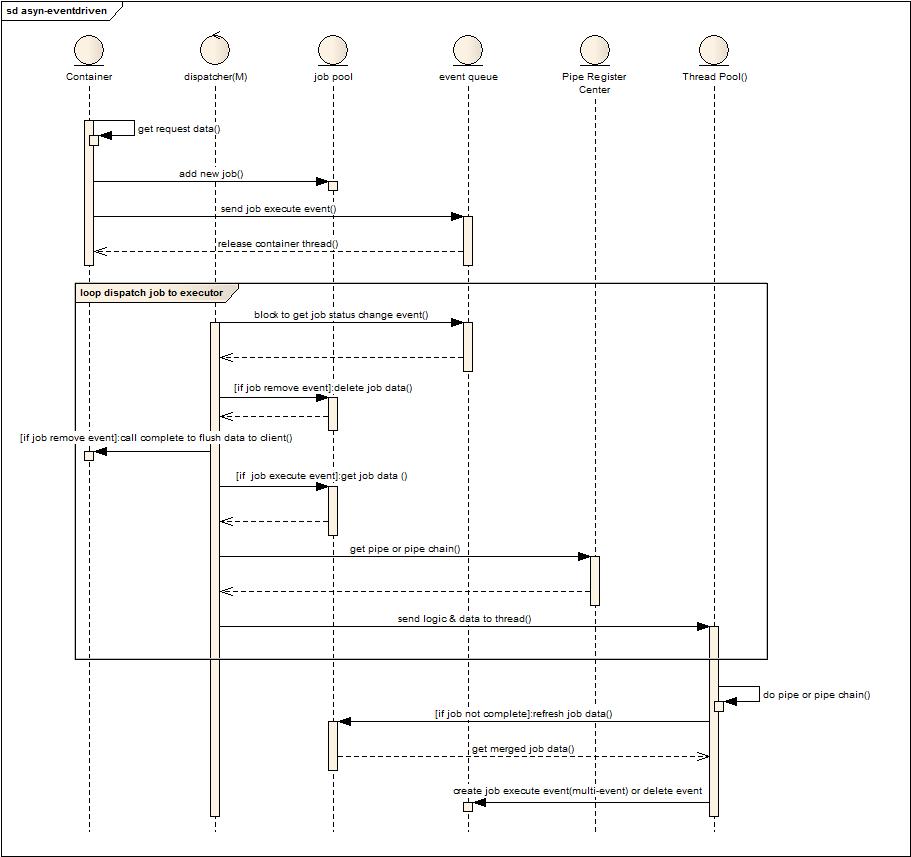
流程與角色說明:
角色分成:Container(傳統的容器),dispatcher(任務派發線程數量根據性能要求可以是1-m個),job pool(存儲任務數據的本地緩存),event queue(任務狀態發生變化的事件存儲隊列),pipe register center(管道鏈注冊中心,根據job的自描述信息給出相關處理的單個管道或者管道鏈),thread pool(用于處理業務請求的線程池)
流程描述如下:
1. 容器解析請求數據。
2. 創建任務并存儲到job pool。
3. 發送job執行消息到消息隊列。
4. 釋放容器線程,掛起請求資源。
5. Dispatcher阻塞方式的從event queue獲取事件消息。
6. 如果是刪除任務事件消息,則將剩余未發送數據flush到客戶端,結束本次Http會話。(刪除任務消息是在任務走完所有管道或者任務執行超時或者任務執行失敗產生)
7. 如果是執行任務消息事件,則從job pool獲取任務數據。
8. 根據任務信息去pipe register center獲取pipe或者pipe chain。
9. 將任務數據和管道信息發送給線程池。
10. 線程池分配線程執行任務,如果當前pipe chain執行后并沒有完成job,則將job信息存儲到job pool。(這塊后面可以參看一下job 執行邏輯圖)
11. 如果沒有執行完畢,則可以創建一個或者多個執行事件激發下一次的處理,如果執行完畢,則創建一個刪除任務消息激發任務結束處理。
問題:
1. 規范化帶來的消息事件過多,線程切換消耗的問題。
2. Dispatcher自身任務是否繁重導致處理速度變慢。同時兩套線程池管理麻煩(如果Dispatcher的個數為M也就可以看作另一個線程池)。
細節:
1. 利用容器本身支持請求掛起的方式,將容器線程池和業務線程池分割開來。
2. 如果所有子任務都是串行化且沒有一個子任務是由外部系統來實施狀態遷移,則可以在一個線程中完成所有子任務,減少線程切換和事件分發帶來的消耗。最極端是退化到任務交由容器線程一并完成。
3. 當允許并行多個子任務執行時,只需要在并行子任務執行前的那個任務完成后,分發多個任務執行事件,并且任務執行事件指定要求處理的Pipe,就可以讓分發器將當前任務分發給多個線程并行執行子任務,后續詳細介紹子任務并行處理的過程。
4. Job會被多線程訪問,因此必要的屬性需要做成線程安全的。另一種模式就是抓取job的數據是個快照(clone),在結果產生后再鎖住合并。
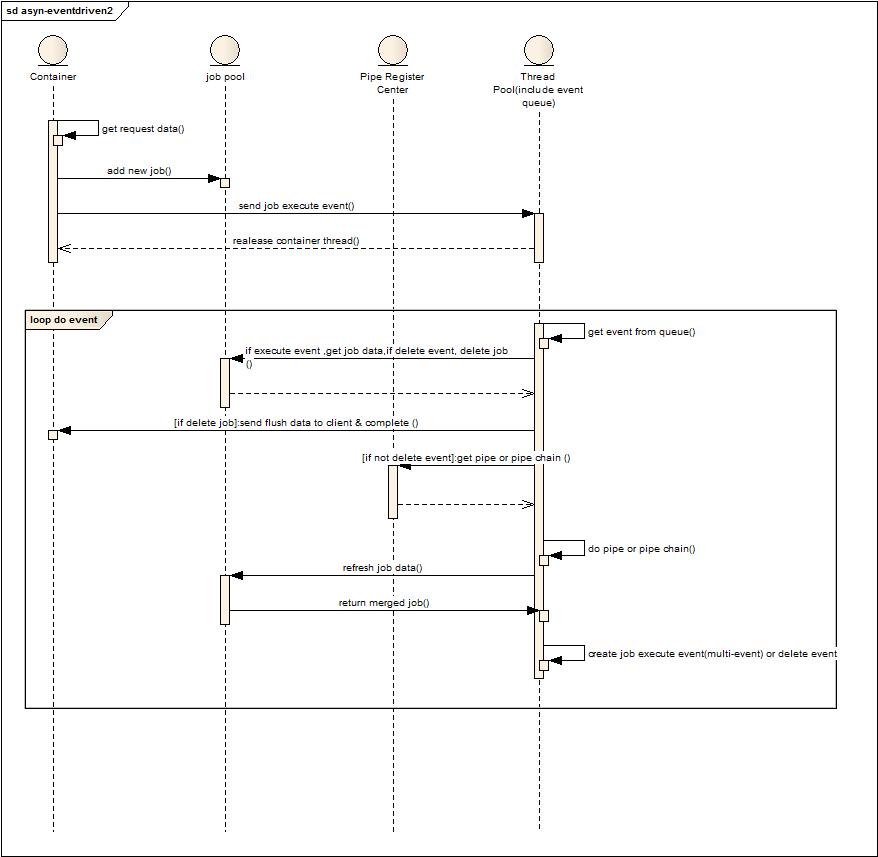
角色和流程說明:
上圖角色將線程池和消息隊列做了合并,去掉了dispatcher,event queue合并到了 Thread Pool中。
1. 容器解析請求參數。
2. 創建任務并放置到任務緩存中。
3. 發送執行任務事件到線程池。
4. 釋放容器線程資源。
5. 線程池從自身事件隊列中獲取事件。
6. 如果是刪除事件,則直接刪除任務,并發送數據到客戶端,結束本地會話。
7. 如果是執行事件,則從pipe register center獲取pipe或者pipe chain。
8. 本地執行pipe或者pipe chain。
9. 更新job 數據到緩存。
10. 創建執行或者刪除消息事件到本地線程池隊列或者直接連續執行。
差異:
1. 將分發器的功能散落到各個實際業務操作線程上,提升處理效率。(增加了對于消息隊列的競爭,不過這個代價不是很大)
2. 線程可以連續執行子任務,減少任務事件數量,減少線程切換代價。(類似于自旋鎖的方式,自己可以盡量的完成可以完成的任務,帶來的問題就是對于不同任務多階段并行執行的策略有所減弱)
細節:
和第一種模式一樣,可以退化這個模型到傳統的一個web容器線程處理所有的子任務,減少線程切換代價。
四種方式的子任務執行說明:

傳統的串行化任務執行模式,這種模式下可以交由單個線程全部執行,減少線程切換代價,另一方面假如3這個環節將會等待外部系統來更新狀態并繼續執行,那么到2執行完畢可以將job放入緩沖區,不產生事件消息,等外部操作完成后,創建執行事件消息,激發后續管道執行任務。(這種方式可以直接利用容器的掛起,來釋放容器線程,而后續操作交由后臺業務線程池執行)
這里有點說明一下,也是很多朋友問起的,關于上下文,原來的模式中上下文一種方式是通過方法參數不斷傳遞,另一種方式保存在ThreadLocal中,而現在因為要切換線程可能就需要做拷貝或者線程之間傳遞。在后面幾種模式中都建議直接將狀態存儲在本地緩存中共享,帶來的問題就是多線程安全,一種方式是都獲取此對象,然后操作時候做鎖,一種是獲得對象快照,然后合并結果時鎖定。(這還是取決于多個線程之間處理是否需要看到對方的數據變化)
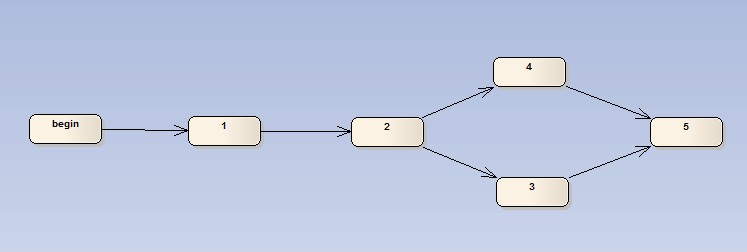
3,4兩個任務可以并行完成,同時任何一個完成即可進入5,此時在2完成后,將會產生兩個執行任務消息,并且自描述后續的Pipe,此時兩個線程可以分別執行3,4,任何一個完畢后創建執行消息,激發任務處理進入到5流程中。(當發現已經進入5狀態時,則忽略某個過期任務消息)
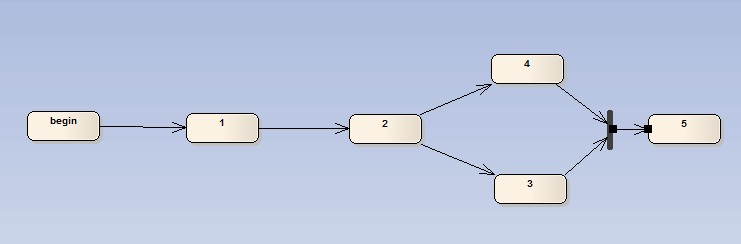
與上一個圖的區別就是,3,4將不再是二選一,而是必須全執行完畢后才可以進入下一個階段,因此job在執行后會先判斷是否被并行的另一個任務執行過,確定全部都Ready,則發起創建執行消息。(在完成3或者4后都會判斷當前合并結果是否符合進入下一環節的要求,符合再發起新的執行任務消息)
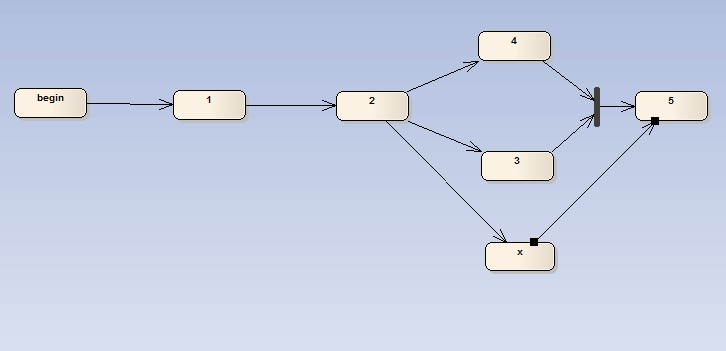
此圖是2,3兩種方案的結合,因此參照3的做法完成。
支持異步化請求處理模型:
上面的管道模型是較為通用的模型,但考慮到TOP現有業務狀況和資源消耗在上述框架下定制了簡單的異步支持模型:
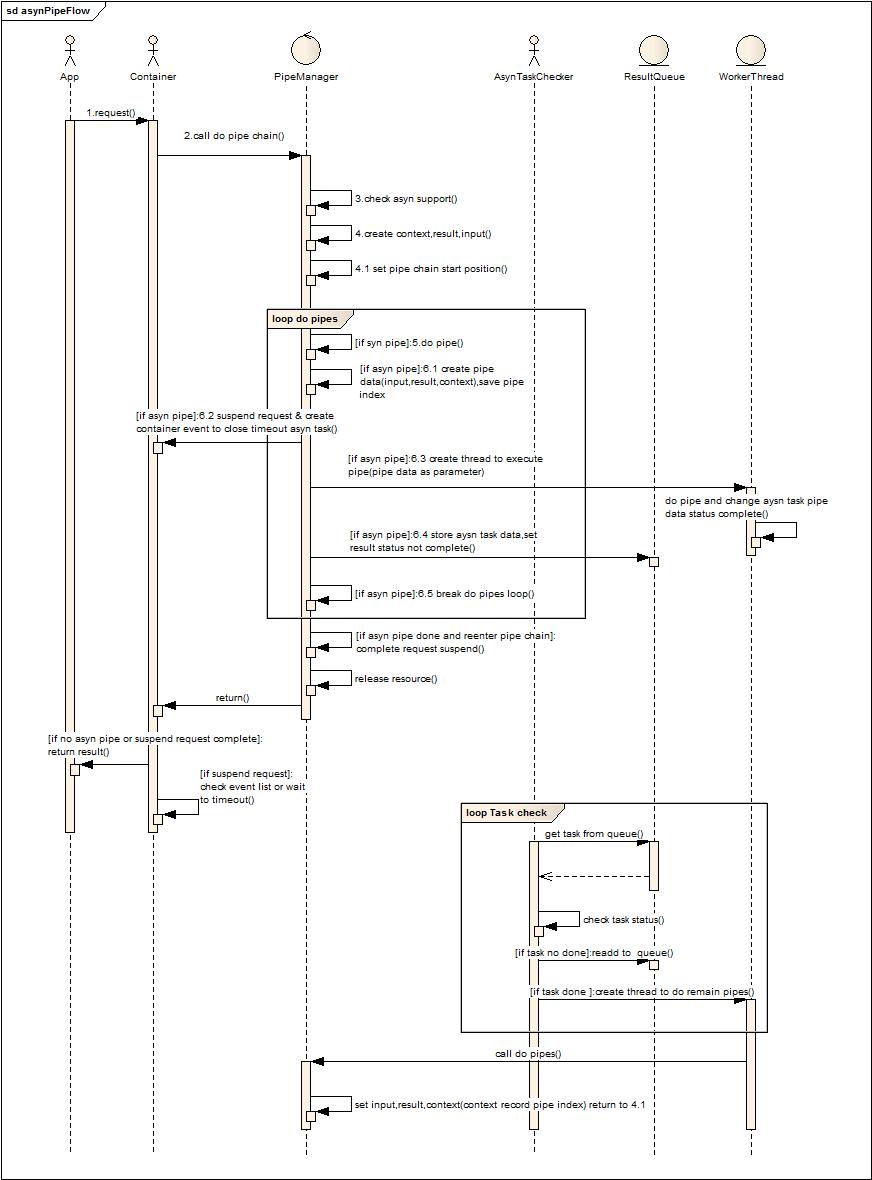
角色及流程說明:
App第三方ISV軟件,Container Web容器,PipeManager管道注冊管理者(區別于通用的管道注冊中心在于他對于所有請求都只管理一套Pipe Chain,由他將請求數據傳入,并管理整個子任務的執行和分發),AsynTaskChecker是異步執行任務狀態變更事件的檢查者(類似于前面的事件分發器角色),ResultQueue保存事件及事件所帶的上下文,workerThead是工作線程池。
1. 應用發起服務請求。
2. 容器調用管道管理器去執行任務管道鏈。(解析參數通過Lazy方式解析字節流被離散放到了各個管道環節中)
3. 檢查容器是否對異步支持。(便于多容器兼容)
4. 創建上下文和輸入輸出對象(輸入輸出是管道基本傳遞參數,后面給出類圖結構可知,上下文則是放置在ThreadLocal的數據,在多個管道邏輯中共享)。
5. 設置管道鏈執行的起始點(為了異步化后再次進入管道鏈無需重新執行前面執行過的管道作處理)。
6. 循環執行管道鏈。
如有異步管道在管道鏈中:
a) 復制管道上下文,保存當前執行的管道位置。
b) 掛起請求,釋放容器線程資源。
c) 創建線程執行異步化管道。
d) 保存任務到隊列,等待外部處理結束改變任務狀態。
e) 推出循環執行后續管道
7. 判斷是否是異步執行后的重入,如果是則提交異步結束事件,讓容器在這次管道鏈執行后自動提交數據到客戶端,結束本地Http請求會話。
8. 釋放上下文等線程本地資源。
9. 返回容器,容器判斷是否有掛起請求,如果請求結束則返回結果到客戶端。
10. 容器自檢查從掛起到當前是否處于執行超時(每次掛起請求就會產生一個超時事件,容器循環的校驗這些事件)
11. AsynTaskChecker循環的檢查隊列中的任務是否已經完成,如果狀態變更為完成,則提交到給線程池繼續執行后續的管道鏈。(處于性能考慮,可以將未完成的對象先不放入隊列,等到后端服務處理完畢再放入,這樣AsynTaskChecker消耗會大大降低,任務超時完全交給容器來處理,不由業務方來處理)
細節:
主要目的是將容器和業務線程池分開,這樣業務線程池可以采用后面提到的權重線程池,通過對權重線程池的權重模型設置來滿足根據業務或者根據服務健康狀況來不均衡的分配線程執行不同的業務請求。
后端系統的NIO異步方式能夠利用操作系統的中斷來激發改變對象狀態,節省前端業務線程等待消耗。(如果后端是非異步化的操作,那么執行線程只是從容器線程變為了業務線程,當然可以讓業務線程更加輕量)
系統中盡量減少線程切換(能夠一個線程干完的,盡量一個線程執行多個子任務),盡量減少內存拷貝復用對象(當然復用的代價就是同步問題,因此取決于數據操作沖突的概率選擇使用快照還是引用)。
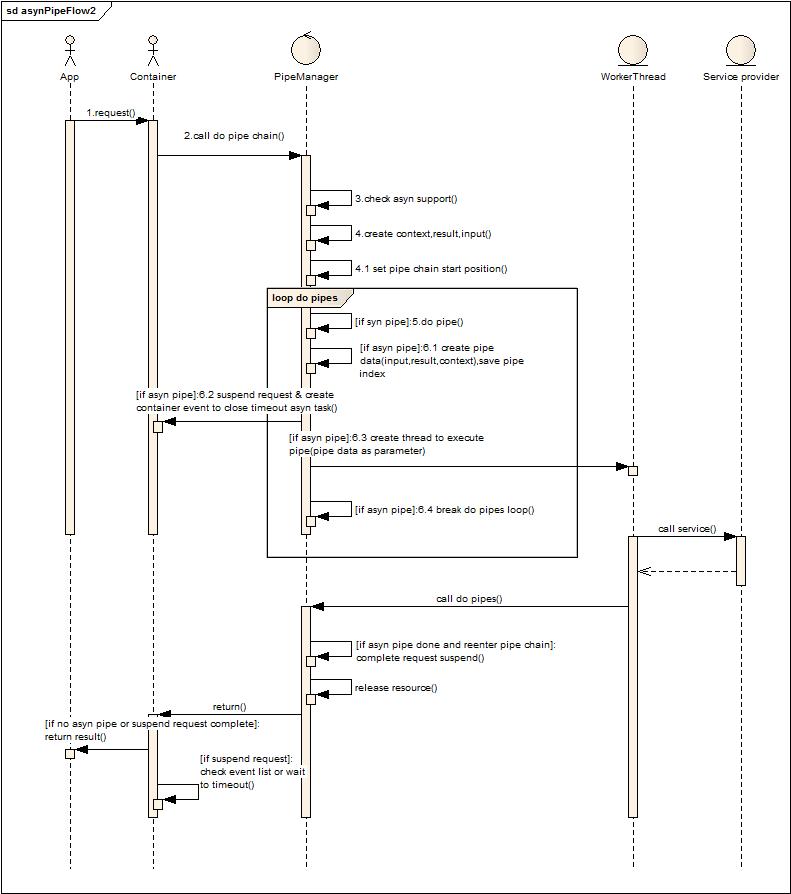
上圖的設計省略了隊列和檢查者,直接交由業務線程阻塞方式等待返回,并直接執行后續的管道,其實也就是對第一種場景的簡化,在后端服務非異步方式的情況下,推薦這種方式。
總的來說,任務切割執行在設計上會覺得很清晰,但是還是要看整體處理時間的分布,如果整個事務處理消耗的時間很短,那么切割帶來的復雜度和內部消耗就會得不償失,采用簡單的方式來實現可以滿足業務上的需求(分離容器和業務線程,根據業務需求和系統動態性能決定線程資源分配),也能保證性能。
權重線程池:
將請求全程處理從容器線程池分離到業務線程池后,可以使用帶權重的線程池來動態調整請求線程資源分配,下面是一個簡單的權重線程池的實現。
目標:執行的任務實現接口getkey來用于判斷是否有空余線程可以執行請求處理任務。資源被分成兩種:默認全局可使用資源,給特定請求預留資源。配置分成兩種,限制最大使用線程數,預留特定請求的線程數。
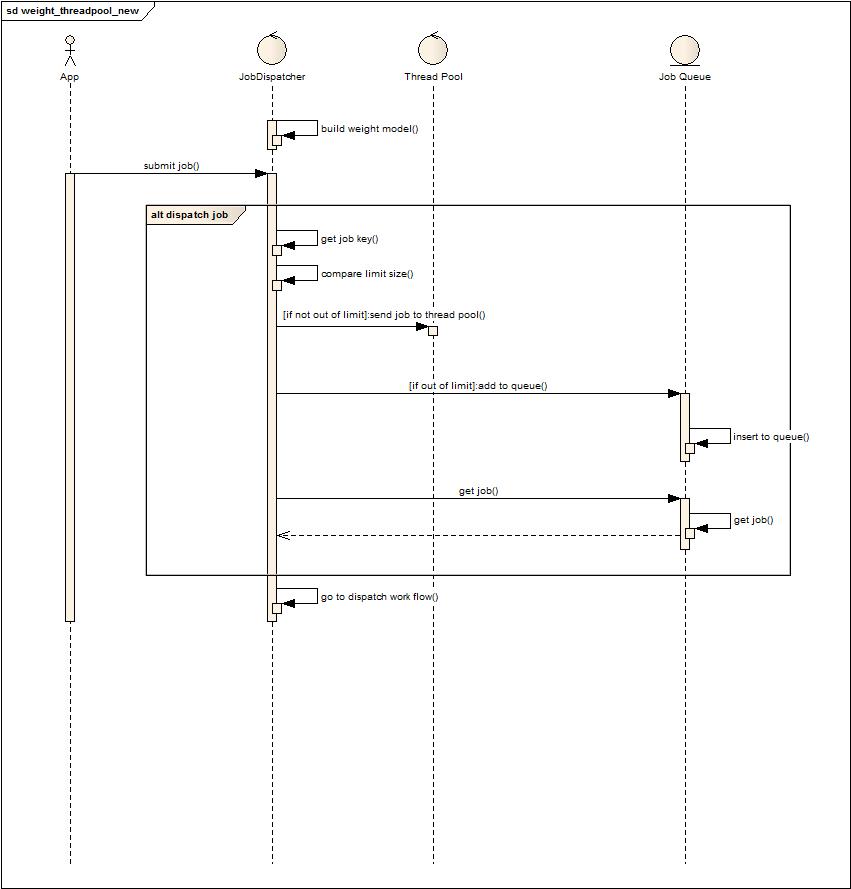
上圖是簡單的請求任務執行流程圖,不多解釋了。下圖是狀態轉換圖:
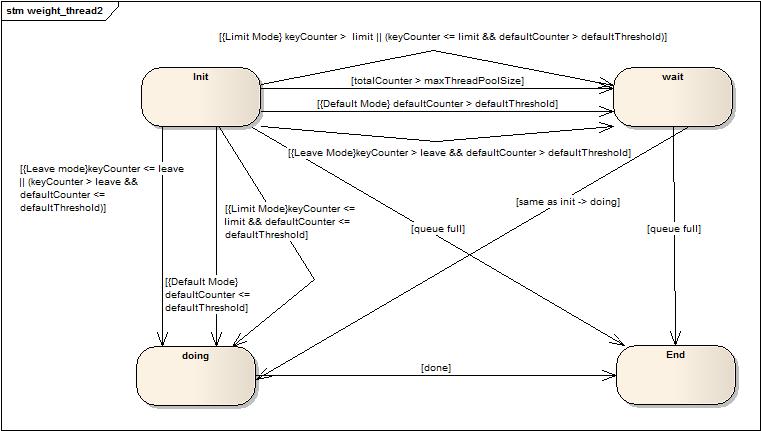
Wait到doing的轉換和init到doing的轉換一樣,就沒有重復畫了。內部的一些標識解釋(totalCounter全局的計數器,maxThreadPoolSize線程池最大線程數,defaultCounter是沒有設置預留或者限制的請求的計數器,defaultThreshold是maxThreadPoolSize – sum(預留線程),keyCounter表示設置了預留或者限制的請求自身標識(自身標識通過getkey接口獲得)計數器,leave表示某一類請求設置的預留的數值,limit表示某一類請求設置的限制的數值)
上圖中大括號中的是場景描述,例如:{Limit Mode}keyCounter <= limit && defaultCounter <= defaultThreshold表示在設置了限制模式的場景下符合當前請求類型計數器(當前請求類型通過請求實現getkey接口返回數據來區別)小于限制且默認計數器小于默認閥值時狀態轉變。
一點小技巧:在存儲預留和限制的閥值時,因為存儲在一個map中,通過將閥值設置為負數來區分開,這樣節省了區分閥值類型的工作。(這點可以在很多場景中考慮,比如說有多個類型的數據配置需要存儲,可以通過數據區間的劃分來判斷是什么類型的,提高判斷效率)
Comet Push Framework:
服務端實現:這期做了很簡單的服務端實現,也是為了驗證原型,標準的REST實現。
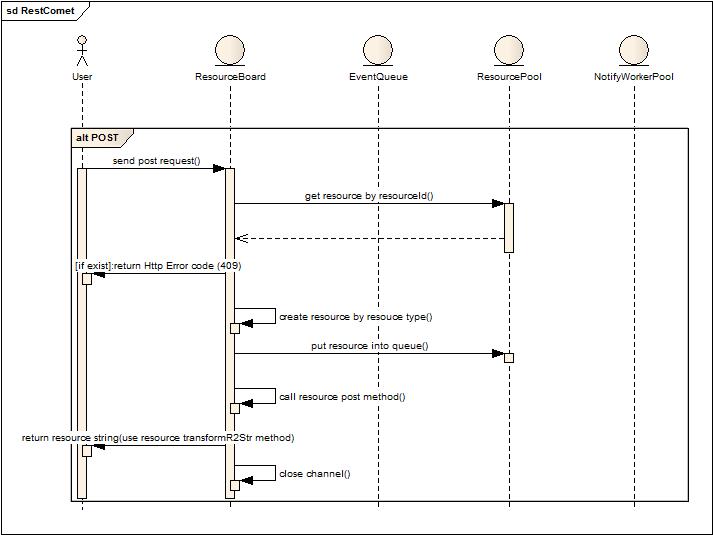
POST操作,用于新增資源,操作后得到資源返回,會話非長連接。
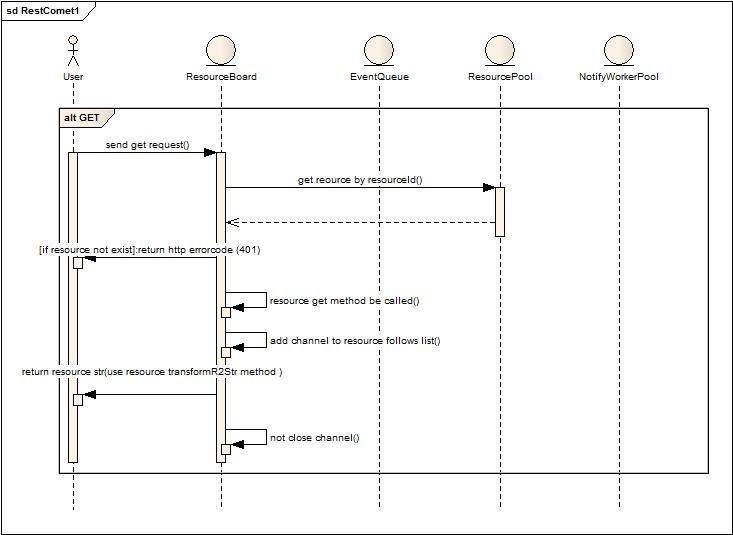
GET操作,獲得當前請求的資源,會被加入到資源關注者列表中,保持長連接,用于資源變更后推送變更后的資源對象。
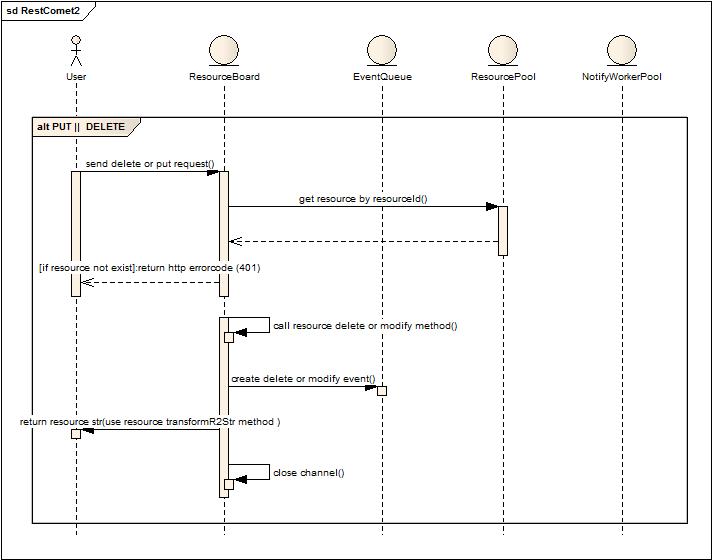
PUT或者Delete操作,短鏈接,同時產生變化事件,交由后臺線程執行通知動作。
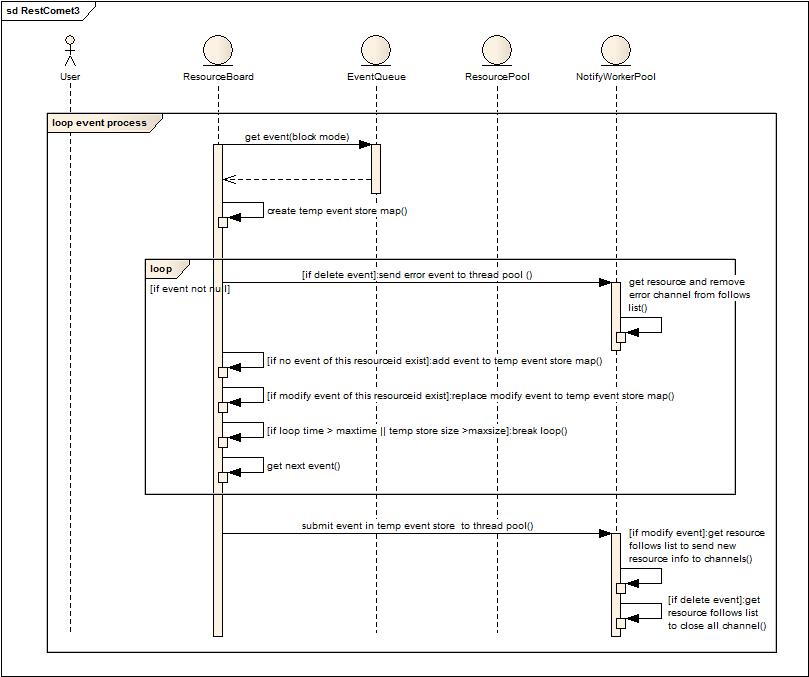
批量執行通知消息。
1. ResourceBoard阻塞式的從隊列中獲取事件通知。
2. 創建臨時事件存儲Map。
3. 如果存在通知事件,判斷是否屬于刪除事件(此類事件發生在異常發生或者正常結束),如果是刪除事件,立刻提交給后臺線程池執行刪除動作。(刪除動作就是獲取刪除資源的follow列表,然后關閉所有follow的長連接)
4. 如果屬于修改事件,判斷當前資源的刪除事件是否已經保存在臨時存儲Map中,如果有就不再加入修改事件直接忽略,否則就放入Map。
5. 判斷當前循環累積事件是否超過一定時間或者存儲的消息量已經超過一定值,如果是就跳出循環,如果否,則繼續從隊列中獲取數據循環判斷,直到隊列為空。
6. 批量執行臨時存儲中的事件消息,如果是修改,則獲取資源的follows來推送變更后的數據。
細節:
內部對于follow的有效性管理是在發送數據時判斷的,如果出錯就會產生刪除事件。
對于消息批量處理主要是針對數據不斷被修改,合并這些無用消息而作,但是某些場景也許就需要所有的修改痕跡,那就不能簡單合并,因此資源需要提供類似合并的接口實現來保證獲取的正確性。
問題:
海量長連接的支持。
采用簡單的Http InnerFrame + js實現客戶端增量展現會使得頁面數據越來越多,到一定程度需要放棄連接重新建立follow,減輕客戶端和服務端雙重壓力。XHR的方式在各種瀏覽器中支持的不一致。
代碼實現,Demo及測試效果
待續….