Author:放翁(文初)
Email:fangweng@taobao.com
Mblog:
weibo.com/fangweng
Blog: http://blog.csdn.net/cenwenchu79/
重要:全文內容都是參照這個源碼地址內容所寫,因此兩邊對著看會更清晰明了:https://github.com/cenwenchu/beatles
這篇小記主要處于兩方面考慮:首先�����,希望打破一提到海量數據分析�,就只有hadoop基礎上的一系列工具����,更多的時候很多企業需要的是更輕量的設計(辦喜酒殺豬殺雞未必都要用一把刀),因此將開放平臺基礎分析組件重構版本beatles的設計寫出來���,給出更多的思考空間。其次����,也是希望推廣一種思想���,所有的系統����,框架設計簡化(可擴展),小部件精致化�����,這樣才能讓很多項目能夠整體靈活�,細節給力。
這篇小記一共分成4部分�,概述���,整體設計���,局部設計�����,待續���。如果你只想了解個背景����,那么看完概述即可,如果對于流式分析的大框架設計感興趣(看看省略了分布式計算集群的什么����?核心設計是怎么樣的)�,請仔細看完整體設計��。如果還對代碼優化有興趣���,那請看局部設計(細到代碼功能級別)��。最后留下的待續,將會增加后續的一些擴展����,及同學看完后提出問題的解答(比較通用的一些問題���,例如容災啊�,啥啥啥很多被認為很重要的東西)
07年底開始做開放平臺���,當時每天訪問量在4kw左右�����,考慮到開放平臺的數據透明化需求����,開始考慮如何做統計分析�,當時需求是一天出一次結果即可�����,因此自己摸索搭建Hadoop迷你集群���,開始了分析之路�����。09年公司調整加入淘寶開放平臺,當時每天服務調用量2億,數據分析要求比較散,從服務的系統數據統計到業務趨勢統計都有涉及,而且統計需求變化較多���,因此開始籌備自己寫簡單的統計抽象模型來規避MapReduce類,提高適應變化的能力,同時出于簡化系統設計維護的要求��,直接將每日分析數據放置到集中服務器上����,每日拉取,切割���,分析(統計分析引擎抽象完成)���。2010年開放平臺基礎體系開始建立�����,對于服務質量,應用行為����,用戶安全都提到了較高的要求上來����,分析結果從原來的統計分析���,擴展到了監控告警�����,每日分析轉變為增量分析(頻度1小時左右),簡化的任務調度模型抽象出來,同時服務調用量增漲到了9億�����。2011年平臺數據統計分析及時性要求更高�����,同時開始開放統計數據給外部開發者(系統可用性和效率要求更高)���,整體框架和局部設計不斷優化和改進�����,截至今年11月,單日最大服務調用量19億,增量統計實時性要求在2分鐘內(包含數據分析和數據產出����,低峰期1分鐘���,高峰期1分半)�,系統可用性要求高于99.6%���,而投入的服務器比起動則幾十臺甚至上百上千的Hadoop系統來說���,就是一個迷你集群(一臺Master實體機(16核���,16g內存)���,12臺虛擬機(虛后5核�,8g內存���,實際為4臺實體機))��,每天負責600g增量數據分析�����,產出1.5g數據。
很多時候很多開發人員會問到說在業務和代碼結構優化沖突的時候怎么辦����,老板要結果���,而程序員要的是看起來不惡心的代碼���,但很多時候���,我們就是在摸索中做事�。上面描述的背景就好比開始買的是件夏天穿的短袖,然后天氣不斷變冷��,開始給短袖加袖子��,然后在身上貼補丁���,但最后真的要到冬天的時候,應該怎么辦����,在秋天和冬天之間���,作為核心代碼負責人�����,就應該保證系統可用性的情況下做好另一手準備(簡單來說,時間不是別人給的�����,而是自己給的�����,天晴補漏�����,雨天不愁)。因此年末的兩周將2年中斷斷續續走過的路�����,重新整理了一遍���,取名為beatles(甲殼蟲)��,因為甲殼蟲雖小,但聚集起來能夠吃掉一大片葉子(業務系統各種需要分析的數據),因此這個框架首先是個很小的內核(希望有更多擴展和參與者)����,其次不是一個從頭開始的項目�����,而是一個兩年多斷斷續續演進產品的積累。
Beatles不是一個萬能的技術產品����,它出生和發展就為它適合的場景做了定義��,因此使用和擴展的時候需要明確的了解是否合適,避免勿用,下面兩個圖會大志說一下它的特點和適用場景���。
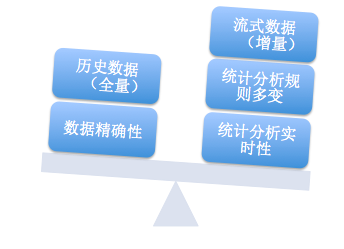
上面這張圖左邊部分是Beatles可以局部犧牲的,右邊部分是場景要求的。由于是對流式數據的增量分析,因此對于歷史數據的全量挖掘無能為例(這部分完全可以用Hadoop這種離線分析系統來做)���。數據精確性要求所有數據在分析的任何一個環節都要做好保護(數據輸入,分析過程,數據輸出)���,而這種強完整性要求勢必會使得系統的效率和可用性降低(和右邊實時性矛盾),因此會被放低一些要求(類似于計費結算等就直接一天走一次分析即可)。在左面所看重的三個部分大致分布的場景為:監控告警(業務,系統�,用戶�����,平臺透明化),業務即時分析對比(ABtest),系統灰度發布對比,用戶實時統計展示(非金額等數據一致性要求較高的內容展示)�。
要滿足上面所說的場景���,實時流式數據分析需要做哪些功能�����?
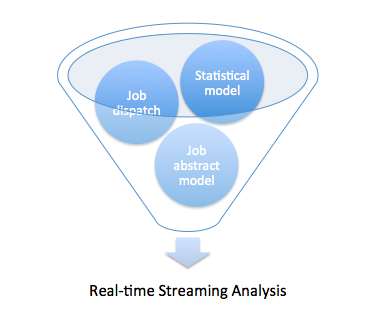
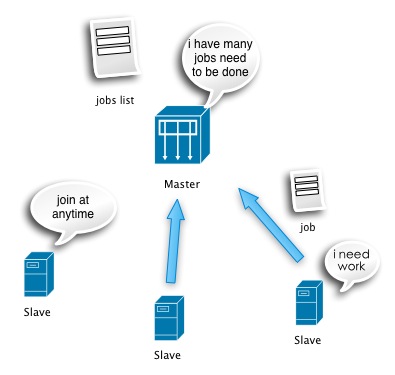
Beatles的任務調度十分簡單��,遵循兩個原則:1.按需分配(Slave的多少及Slave自身執行任務的快慢自然促成的分配方式)2.任務粒度細化�����,粗暴簡單的任務重置(通過透明化監控任務可能出現的問題�����,避免集群陷入一個任務的糾結中)。優勢:簡單,高效�����,易擴展(Slave隨時來���,隨時走)�。劣勢:對于任務執行可控度較弱(通過任務細粒度和粗暴重置狀態的方式來降低風險,增加的只是節點重復計算的浪費可能性)。
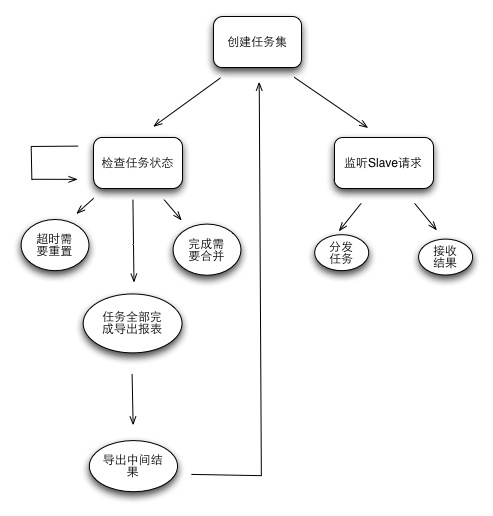
master處理流程
可以看到Master整體就兩部分工作���,對內部任務的管理維護,對外部slave請求的處理(請求獲取任務,返回處理后的結果(Slave也可以不返回結果,根據Job定義來判斷,防止Master變重))����。Master單點并不可怕����,只要遵循兩個原則:現場可快速恢復���,分析流程可追趕��。因此做到Master所有狀態定期外移和實時監控����,即可滿足這種簡單的Master可用性需求�����。
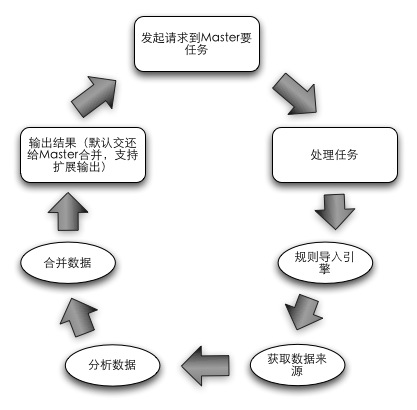
slave處理流程
Slave更為單純,整個生命周期就是獲取任務��,分析任務����,返回任務結果的一個環,內置一個分析引擎和交互組件�,根據任務的定義來無差別化的處理各種分析工作(Job定義了數據的輸入來源��,輸出目標地址,分析規則)���。Slave的設計主要考慮如何做到無業務規則侵入和數據來源限制,滿足了這些需求的情況下才能夠實現節點處理無差別性�����,各種分析任務可以跑在一個集群上(實現計算節點可復用)����。
任務抽象設計比較簡單,主要結合任務調度設計���,實現計算節點的無差別化。
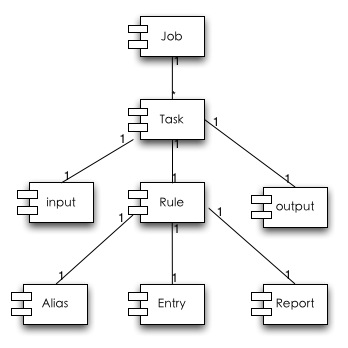
Job是一類分析的定義(例如對gc的日志分析�����,對服務調用日志分析可以定義為兩個Job)��,Job中的Task表示對于這一類數據分析再次拆分任務����,來分解海量數據處理�����,Task中繼承了Job中的輸入和輸出����,支持多種模式的數據來源和數據輸出�。Rule就是分析統計模型抽象部分主要分成:Alias(對于分析數據的列別名定義),Entry的MapReduce的定義�,Report是Entry整合成用戶可接受的Report的定義��。
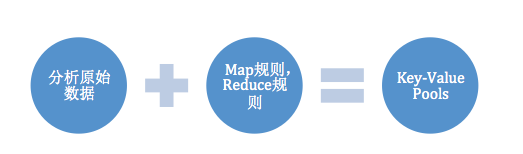
統計模型抽象主要分為兩部分:統計模型抽象和統計流程抽象。統計模型抽象就是將MapReduce的Key-Value統計�����,轉化成為傳統意義上的報表結構���。
分析的輸入:(弱業務含義的大表)
c1,c2,c3,c4,c5,c6
c1,c2,c3,c4
c1,c2,c3,c4,c5,c6,c7
……
MapReduce可以處理的:
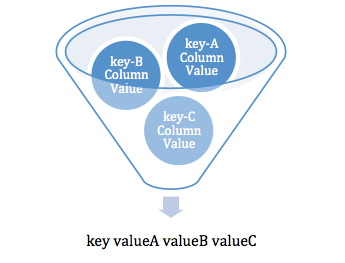
如下圖�,傳統報表的一行可以看作是多個相同key但不同統計字段組合的結果。
例如:輸入的數據結構如下:
服務名稱�,服務類型�,服務上行數據流量��,服務處理結果(錯誤碼)����,服務耗時
真實日志如下:(分隔符可在分析時指定���,這里用逗號作演示)
taobao.user.get,read,100,0,20
taobao.product.add,write,1000,0,50
……
那么定制如下MapReduce組合:
Key:服務名稱�,Value:服務上行數據流量總和。
Key:服務名稱��,Value:服務耗時總和�。
Key:服務名稱�,Value:服務平均耗時。
Key:服務名稱,Value:服務最大耗時。
Key:服務名稱���,Value:服務最小耗時。
那么將這些MapReduce處理后的Key-value在組合一次就可以得到:
Key:服務名稱,Value:服務上行數據流量總和�����,服務耗時總和���,服務平均耗時�,服務最大耗時,服務最小耗時。
簡單來說其實就是類似于SQL中的Groupby的方式�����,將一堆<key�����,value> groupby key��。
分析流程抽象如下:
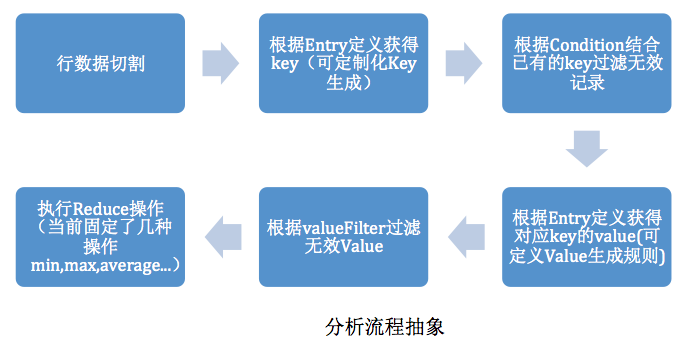
分析流程抽象
流程中可以擴展的在第三步和第四步,第三步影響了Key的生成(當簡單的列組合成字符串無法滿足生成key的情況下可擴展)��,第四步影響value的生成���。(當map的value生成以及Reduce無法滿足需求的情況下可擴展)��,要使用min�,max…以外的reduce���,可以直接在ReduceClass中作處理���,然后使用plain輸出實現�。
這種流程比傳統的MapReduce的寫法好處在于可以對輸入只讀取一次(海量的日志文件為了多種條件分析����,反復讀取本身就是最大的損耗)?��?梢钥吹皆谖募?/span>IO操作上,不會隨著分析模型配置的增多而增長�,中間數據也不會隨著報表組合的不同而過快膨脹(只要報表復用Entry足夠多)����。
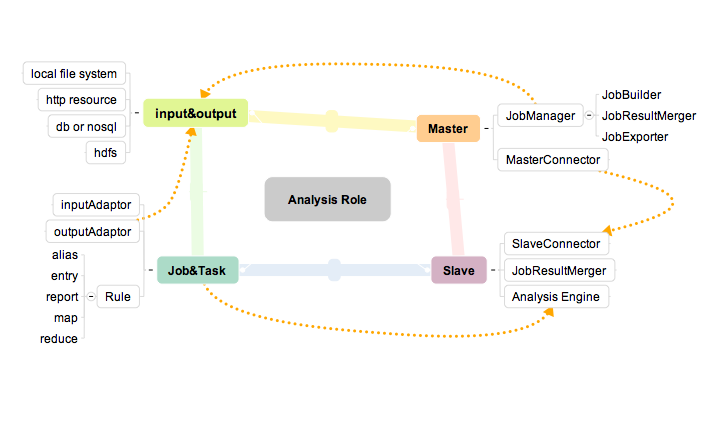
角色定義
Beatles內部業務組件如上圖。
Master包含兩個子組件����,JobManager用于管理任務���,MasterConnector用于與Slave通信�����。
Slave包含三個組件,SlaveConnector用于與服務端通信���,Analysis
Engine用于數據分析,JobResultMerger可選,用于在客戶端分擔服務端匯總結果的壓力,同時讓Slave可以多線程并行執行任務�。(當然單機可以跑多個Slave的實例)�����。
Job&Task已經提到過用于任務抽象,支持Slave的Analysis Engine的分析無差別性。
Input&output用于擴展整個框架的各種數據來源,例如job構建的來源,job的輸入和輸出等。

整體流程
1.
Master利用jobManager通過JobBuilder來構建服務端的任務集合。
2.
Slave向Master發起要任務的請求�。
3.
通過Master和Slave的Connector來做交互�����。
4.
MasterConnector向MasterNode內部的事件處理模塊提交事件�����。
5.
JobManager檢查內部任務狀態后返回未完成且符合條件的任務返回給Slave���。
6.
SlaveNode收到任務后調用內部分析引擎并行執行任務分析���。
7.
分析引擎獲得任務的數據來源�����,開始分析數據。
8.
如果是多個任務并行執行�,合并同一個Job的多個Task的結果��。
9.
導出分析后的結果
10. 如果是需要匯總到Master的話,利用SlaveConnector返回給Master�����。
11. MasterConnector獲得返回的分析結果數據���。
12. MasterNode類似走事件流程����,然后調度到合并組件合并結果。
13. 當Job任務全部完成就調用JobExporter導出數據����。
代碼結構體系:sourcecode:(https://github.com/cenwenchu/beatles)

整體包結構
整個項目內容不多����,根據包名的前綴可以發現主要分成兩塊:node���,Statistics�。前者是任務調度及任務抽象�����,后者是統計分析模型抽象����。
Config中是多個角色各自的config定義�����,同時這些config會在一個實體里傳播����,例如MasterConfig就在MasterNode中傳播到jobManager和MasterConnector組件中,SlaveConfig就在SlaveNode傳播到分析引擎組件和SlaveConnector中����。
Node中的結構如下:
Component:對Node的各個組件接口的實現���。
Connect:Master與Slave交互的接口定義和實現。
Io:對于Job的輸入輸出來源的接口定義和默認幾個實現�����。
Event:定義了Master和Slave這樣的Node中需要處理的事件��。
Job:任務抽象定義�����。
Map�����,Reduce:支持當分析引擎無法滿足的Map����,Reduce的情況�����。(足夠通用的情況下可以被抽象到主框架中)
Operation:定義了Node結構中需要異步處理事件�。(因為當前Node的Event是單線程處理的�,因此事件執行如果比較消耗,則需要異步后臺執行,或者并行執行)
Util包是一些工具類和定義類���。
Staitistics是分析引擎接口和實現,其中Data中是分析規則的抽象。
至此為止,整體的結構設計就如上所述了,整體上結構比較簡單直接�����,可擴展性為了支持分析規則擴展�����,不同計算場景擴展���,效率和可靠性擴展��。下一個部分將會細化到具體的模塊代碼設計上來談優化和代碼技巧。
@import url(http://www.tkk7.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);