SIP的第四期結束了,因為控制策略的豐富�,早先的的壓力測試結果已經無法反映在高并發和高壓力下SIP的運行狀況���,因此需要重新作壓力測試����。跟在測試人員后面做了快一周的壓力測試,壓力測試的報告也正式出爐����,本來也就算是告一段落���,但第二天測試人員說要修改報告,由于這次作壓力測試的同學是第一次作����,有一個指標沒有注意����,因此需要修改幾個測試結果�。那個沒有注意的指標就是load average,他和我一樣開始只是注意了CPU����,內存的使用狀況���,而沒有太注意這個指標�,這個指標與他們通常的限制(10左右)有差別���。重新測試的結果由于這個指標被要求壓低����,最后的報告顯然不如原來的好看。自己也沒有深入過壓力測試�,但是覺得不搞明白對將來機器配置和擴容都會有影響���,因此去問了DBA和SA���,得到的結果相差很大�,看來不得不自己去找找問題的根本所在了。
通過下面的幾個部分的了解,可以一步一步的找出Load Average在壓力測試中真正的作用�。
CPU時間片
為了提高程序執行效率���,大家在很多應用中都采用了多線程模式����,這樣可以將原來的序列化執行變為并行執行�,任務的分解以及并行執行能夠極大地提高程序的運行效率���。但這都是代碼級別的表現����,而硬件是如何支持的呢?那就要靠CPU的時間片模式來說明這一切����。程序的任何指令的執行往往都會要競爭CPU這個最寶貴的資源�,不論你的程序分成了多少個線程去執行不同的任務�,他們都必須排隊等待獲取這個資源來計算和處理命令。先看看單CPU的情況����。下面兩圖描述了時間片模式和非時間片模式下的線程執行的情況:
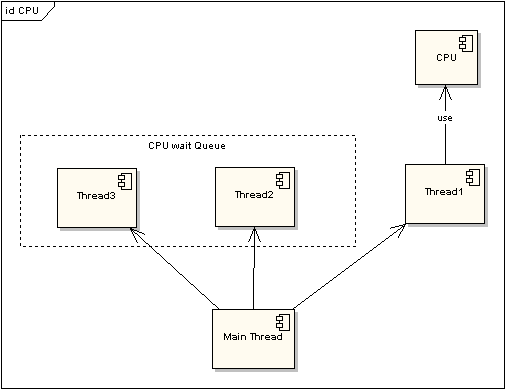
圖 1 非時間片線程執行情況
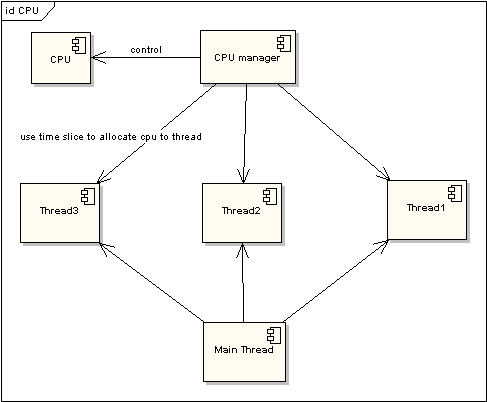
圖 2 非時間片線程執行情況
在圖一中可以看到����,任何線程如果都排隊等待CPU資源的獲取����,那么所謂的多線程就沒有任何實際意義。圖二中的CPU Manager只是我虛擬的一個角色����,由它來分配和管理CPU的使用狀況�,此時多線程將會在運行過程中都有機會得到CPU資源���,也真正實現了在單CPU的情況下實現多線程并行處理���。
多CPU的情況只是單CPU的擴展�,當所有的CPU都滿負荷運作的時候�,就會對每一個CPU采用時間片的方式來提高效率。
在Linux的內核處理過程中����,每一個進程默認會有一個固定的時間片來執行命令(默認為1/100秒)����,這段時間內進程被分配到CPU���,然后獨占使用����。如果使用完,同時未到時間片的規定時間,那么就主動放棄CPU的占用����,如果到時間片尚未完成工作����,那么CPU的使用權也會被收回���,進程將會被中斷掛起等待下一個時間片�。
CPU利用率和Load Average的區別
壓力測試不僅需要對業務場景的并發用戶等壓力參數作模擬,同時也需要在壓力測試過程中隨時關注機器的性能情況�,來確保壓力測試的有效性�。當服務器長期處于一種超負荷的情況下運行�,所能接收的壓力并不是我們所認為的可接受的壓力。就好比項目經理在給一個人估工作量的時候����,每天都讓這個人工作12個小時���,那么所制定的項目計劃就不是一個合理的計劃���,那個人遲早會垮掉���,而影響整體的項目進度�。
CPU利用率在過去常常被我們這些外行認為是判斷機器是否已經到了滿負荷的一個標準����,看到50%-60%的使用率就認為機器就已經壓到了臨界了。CPU利用率,顧名思義就是對于CPU的使用狀況����,這是對一個時間段內CPU使用狀況的統計���,通過這個指標可以看出在某一個時間段內CPU被占用的情況����,如果被占用時間很高���,那么就需要考慮CPU是否已經處于超負荷運作���,長期超負荷運作對于機器本身來說是一種損害���,因此必須將CPU的利用率控制在一定的比例下����,以保證機器的正常運作。
Load Average是CPU的Load,它所包含的信息不是CPU的使用率狀況,而是在一段時間內CPU正在處理以及等待CPU處理的進程數之和的統計信息,也就是CPU使用隊列的長度的統計信息。為什么要統計這個信息����,這個信息的對于壓力測試的影響究竟是怎么樣的����,那就通過一個類比來解釋CPU利用率和Load Average的區別以及對于壓力測試的指導意義����。
我們將CPU就類比為電話亭����,每一個進程都是一個需要打電話的人。現在一共有4個電話亭(就好比我們的機器有4核)���,有10個人需要打電話。現在使用電話的規則是管理員會按照順序給每一個人輪流分配1分鐘的使用電話時間���,如果使用者在1分鐘內使用完畢,那么可以立刻將電話使用權返還給管理員����,如果到了1分鐘電話使用者還沒有使用完畢�,那么需要重新排隊���,等待再次分配使用����。

圖 3 電話使用場景
上圖中對于使用電話的用戶又作了一次分類,1min的代表這些使用者占用電話時間小于等于1min�,2min表示使用者占用電話時間小于等于2min����,以此類推���。根據電話使用規則����,1min的用戶只需要得到一次分配即可完成通話�,而其他兩類用戶需要排隊兩次到三次。
電話的利用率 = sum (active use cpu time)/period
每一個分配到電話的使用者使用電話時間的總和去除以統計的時間段。這里需要注意的是是使用電話的時間總和(sum(active use cpu time))���,這與占用時間的總和(sum(occupy cpu time))是有區別的����。(例如一個用戶得到了一分鐘的使用權���,在10秒鐘內打了電話���,然后去查詢號碼本花了20秒鐘���,再用剩下的30秒打了另一個電話���,那么占用了電話1分鐘�,實際只是使用了40秒)
電話的Average Load體現的是在某一統計時間段內,所有使用電話的人加上等待電話分配的人一個平均統計���。
電話利用率的統計能夠反映的是電話被使用的情況,當電話長期處于被使用而沒有的到足夠的時間休息間歇���,那么對于電話硬件來說是一種超負荷的運作,需要調整使用頻度�。而電話Average Load卻從另一個角度來展現對于電話使用狀態的描述���,Average Load越高說明對于電話資源的競爭越激烈����,電話資源比較短缺����。對于資源的申請和維護其實也是需要很大的成本���,所以在這種高Average Load的情況下電話資源的長期“熱競爭”也是對于硬件的一種損害�。
低利用率的情況下是否會有高Load Average的情況產生呢?理解占有時間和使用時間就可以知道���,當分配時間片以后,是否使用完全取決于使用者����,因此完全可能出現低利用率高Load Average的情況���。由此來看���,僅僅從CPU的使用率來判斷CPU是否處于一種超負荷的工作狀態還是不夠的���,必須結合Load Average來全局的看CPU的使用情況和申請情況���。
所以回過頭來再看測試部對于Load Average的要求����,在我們機器為8個CPU的情況下�,控制在10 Load左右,也就是每一個CPU正在處理一個請求,同時還有2個在等待處理�?��?戳丝淳W上很多人的介紹一般來說Load簡單的計算就是2* CPU個數減去1-2左右(這個只是網上看來的���,未必是一個標準)����。
補充幾點:
1.對于CPU利用率和CPU Load Average的結果來判斷性能問題���。首先低CPU利用率不表明CPU不是瓶頸���,競爭CPU的隊列長期保持較長也是CPU超負荷的一種表現���。對于應用來說可能會去花時間在I/O,Socket等方面����,那么可以考慮是否后這些硬件的速度影響了整體的效率。
這里最好的樣板范例就是我在測試中發現的一個現象:SIP當前在處理過程中,為了提高處理效率����,將控制策略以及計數信息都放置在Memcached Cache里面�,當我將Memcached Cache配置擴容一倍以后����,CPU的利用率以及Load都有所下降,其實也就是在處理任務的過程中,等待Socket的返回對于CPU的競爭也產生了影響�。
2.未來多CPU編程的重要性?��,F在服務器的CPU都是多CPU了���,我們的服務器處理能力已經不再按照摩爾定律來發展���。就我上面提到的電話亭場景來看�,對于三種不同時間需求的用戶來說���,采用不同的分配順序�,我們可看到的Load Average就會有不同。假設我們統計Load的時間段為2分鐘,如果將電話分配的順序按照:1min的用戶,2min的用戶�,3min的用戶來分配���,那么我們的Load Average將會最低���,采用其他順序將會有不同的結果�。所以未來的多CPU編程可以更好的提高CPU的利用率,讓程序跑的更快�。
以上所提到的內容未必都是很準確或者正確���,如果有任何的偏差也請大家指出,可以糾正一些不清楚的概念�。