今天看了“Database Sharding at Netlog, with MySQL and PHP”一文,和去年我們討論擴展的思路很類似(不過這種分布式擴展,計算,存儲的思路都很類似),但是這片文章的作者是在日益爆炸式增長的用戶數據下實踐的分享,因此這里將文中的一些思想記錄下來分享一下。
Netlog擁有4000萬活躍用戶,每個月有超過5000萬的獨立用戶訪問網站,每個月有5億多的PV。數據量應該算是比較大的。作者是Jurriaan Persyn,他從一個開發者角度而非DBA或者SA角度來談Netlog是如何通過數據切分來提高網站性能,橫向擴展數據層的。原文在:http://www.jurriaanpersyn.com/archives/2009/02/12/database-sharding-at-netlog-with-mysql-and-php/
首先,還是先談到關于數據庫在數據日益龐大的情況下一個演變過程。
第一階段:讀寫同在一臺數據庫服務器

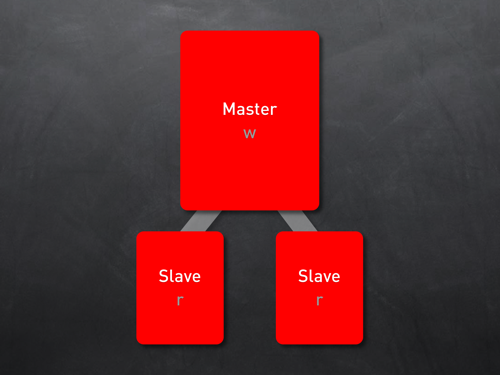
第二階段:讀寫分離(可以解決讀寫比例均衡或者讀居多的情況,但是帶入了數據復制同步的問題)
第三階段:部分數據獨立部署結合讀寫分離。(部分數據根據其業務獨立性情況,可以將所有的數據獨立存儲到數據庫服務器,分擔數據讀寫壓力,前提是要求數據具有較高的業務獨立性)
第四階段:數據分拆結合讀寫分離(三階段的增強)

第五階段:問題出現,分拆也無法解決數據爆炸性增長,同時讀寫處于同等比例。

解決問題兩種方式:DB Scale up ,DB Scale out。前者投入以及后期擴展有限,因此需要進行數據切分。

上圖就是將photo的數據切分到了10臺數據庫服務器上。
切分數據的兩個關鍵點:
1. 如何根據存儲的數據內容判斷數據的存儲歸屬,也就是什么是內容的分區主鍵。
2. 采用什么算法可以根據不同的主鍵將內容存儲到不同的分區中。
分區主鍵的選擇還是要根據自身的業務場景來決定,Netblog選擇的是用戶ID。
采用什么方式將分區主鍵映射到對應的分區可以通過以下四種方式:
1. 根據數據表來切分。(前提就是數據獨立性較強,和前面提到的三階段類似)
2. 基于內容區間范圍的分區。(就好比前1000個用戶的信息存儲在A服務器,1000-2000存儲在B服務器)
3. 采用Hash算法結合虛擬節點的方式。(這類在memcached等等分布式場景中最常見,其實也是一個難點),缺點就是在于動態增加存儲節點會導致數據部分或者全部失效。
4. 目錄式的分區。最簡單也是最直接的方式,key和分區的對應關系被保存,通過查找目錄可以得到分區信息。適合擴展,就是增加查詢損耗。
如何將數據分布的盡量均勻,如何平衡各個服務器之間的負載,如何在新增存儲機器和刪除存儲機器的時候不影響原有數據,同時能夠將數據均攤,都是算法的關鍵。在分布式系統中DHT(Distribute Hash Table)被很多人研究,并且有很多的論文是關于它的。
數據的橫向切分給應用帶來的問題:
1. 跨區的數據查詢變得很困難。(對于復雜的關聯性數據查詢無法在一個請求中完成)
2. 數據一致性和引用完整性較難保證。(多物理存儲的情況下很難保證兼顧效率、可用性、一致性)
3. 數據分區之間的負載均衡問題。(數據本身的不均衡性,訪問和讀寫的不均衡性都會給數據分區的負載均衡帶來困難)
4. 網絡配置的復雜性。(需要保證服務器之間的大數據量頻繁的交互和同步)
5. 數據備份策略將會變得十分復雜。
解決這些問題當前已經有的一些開源項目:
1. MySql Cluster,解決讀寫分離問題已經十分成熟。
2. MySql Partitioning,可以將一個大表拆分為很多小表,提高訪問速度,但是限制與這些小表必須在同一臺服務器上。
3. HSCALE和Spock Proxy都是建立與MySql Proxy基礎上的開源項目,MySql Proxy采用LUA腳本來進行數據分區。
4. HiveDB是MySql分區框架的java實現。
5. 另外還有HyperTable,HBase,BigTable等等。
Netblog幾個需求:
1. 需要靈活的可擴展性。對于存儲增加減少需要能夠動態的及時實施,因為數據量增長很快,如果策略會導致數據失效或者部署需要重新啟動,則就不能滿足需求。
2. 不想引入全新的數據層和與原有系統不匹配的抽象層,因為并不是所有數據都需要切分,僅僅在需要的情況下通過API的方式來透明切分數據。
3. 分區的主鍵需要可配置。
4. 需要封裝API,對開發人員透明數據切分的工作。
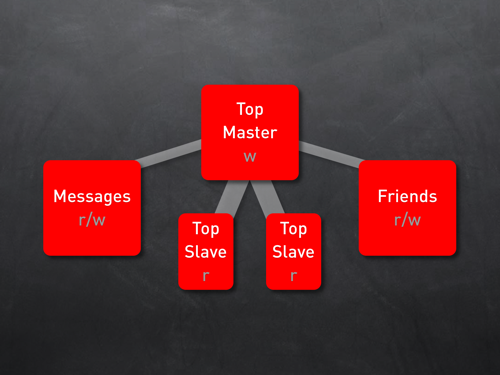
Netblog Sharding的實現

上圖就是Netblog的Sharding的結構圖,主要分成了三部分:Shard,Sharddb,Sharddbhost。Shard就是一個表,里面存放了部分用戶數據。Sharddb是一個表的組合就像一個虛擬的DB。Sharddbhost是具體的存儲分區。Shard,Sharddb可以根據負載的情況被移動到不同的host中去。
對于Shard的管理,Netblog采用的是目錄查詢的管理方式。目錄信息也存儲在MySql中,同時會通過互備,Memcache,集群來確保安全性和高效性。
Shard Table API采用了多一層的映射模式來適合各種不同屬性的查詢情況。數據和記錄在數據庫中存儲除了UserID以外還有對應的ItemID,ItemID的作用就是定義了具體獲取數據的字段信息,例如關聯照片表時,ItemID就是PhotoId,關聯視頻表時,ItemID就是videoID。
一個獲取用戶id為26博客信息的范例:
1.Where is user 26?
User 26 is on shard 5.
2.On shard 5; Give me all the $blogIDs ($itemIDs) of user 26.
That user's $blogIDs are: array(10,12,30);
3.On shard 5; Give me all details about the items array(10,12,30) of user 26.
Those items are: array(array('title' => "foo", 'message' => "bar"), array('title' => "milk", 'message' => "cow"));
對于Shard的管理Netblog采取的措施主要有這些:
1. 服務器之間的負載均衡根據用戶數,數據庫文件大小,讀寫次數,cpu load等等作為參數來監控和維護。根據最后的結果來遷移數據和分流數據。
2. 移動數據時會監控用戶是否在操作數據,防止不一致性。
3. 對于數據庫的可用性,采用集群,master-master,master-slave復制等手段。
最后通過三種技術來解決三個問題:
1. Memcached解決shard多次查詢的效率問題。
根據上面的范例可以看到,一次查詢現在被分割成為了三部分:shard查詢,item查詢,最終結果查詢。通過memcached可以緩存三部分內容,由前到后數據的穩定性以及命中率逐漸降低,同時通過結合有效期(內容存儲時效)和修改更新機制(add,update,delete觸發緩存更新),可以極大地解決效率問題。甚至通過緩存足夠信息減少大量的數據庫交互。
2. 并行計算處理。
由于數據的分拆,有時候需要得到對于多Shard數據處理的結果匯總,因此就會將一個請求分拆為多個請求,分別交由多個服務器處理,最后將結果匯總。(類似于Map-reduce)
3. 采用Sphinx全文搜索引擎解決多數據分區數據匯總查詢,例如察看網站用戶的最新更新情況或者最熱門日至。這個采用單獨系統部署,通過建立全局信息索引,來查詢數據情況。
以上是技術上的全部內容,作者在最后的幾個觀點十分值得學習,同時也不僅僅限于數據切分,任何框架設計都可以參考。
“Don't do it, if you don't need to!" (37signals.com)
"Shard early and often!" (startuplessonslearned.blogspot.com)
看起來矛盾的兩句話,卻是說出了對于數據切分的一些考慮。
首先在沒有必要的情況下就不要考慮數據切分,切分帶來的復雜性直接影響可用性,可維護性和一致性。在能夠采用Scale up的情況下,可以選擇Scale up降低框架復雜度。
另一方面,如果發現了業務增長情況出現必須要擴展的趨勢,那么就要盡早著手去實施和規劃擴展的工作,并且在切分和擴展過程中要不斷地去優化和重構。
后話:
其實任何架構設計首要就是簡單直接,不過度設計,不濫竽充數。其實就是要平衡好:可用性、高效性、一致性、可擴展性這四者之間的關系。良性循環、應時應事作出取舍和折中。用的好要比學會用更重要,更關鍵。