轉自:http://www.keyusoft.cn/Contentview.aspx?year=2005&month=$10&day=$6&postid=123
通過一周左右的研究,對規則引擎有了一定的了解。現在寫點東西跟大家一起交流,本文主要針對RETE算法進行描述。我的文筆不太好,如果有什么沒講明白的或是說錯的地方,請給我留言。
首先申明,我的帖子借鑒了網上很流行的一篇帖子,好像是來自CSDN;還有一點,我不想做太多的名詞解釋,因為我也不是個研究很深的人,定義的不好怕被笑話。
好現在我們開始。
首先介紹一些網上對于規則引擎比較好的帖子。
1、 來自JAVA視頻網
2、? RETE算法的最原始的描述,我不知道在哪里找到的,想要的人可以留下E-mail
?
接著統一一下術語,很多資料里的術語都非常混亂。
1、? facts 事實,我們實現的時候,會有一個事實庫。用F表示。
2、? patterns 模板,事實的一個模型,所有事實庫中的事實都必須滿足模板中的一個。用P表示。
3、
? conditions
條件,規則的組成部分。也必須滿足模板庫中的一條模板。用C表示。我們可以這樣理解facts、patterns、conditions之間的關系。
Patterns是一個接口,conditions則是實現這個接口的類,而facts是這個類的實例。
4、? rules 規則,由一到多個條件構成。一般用and或or連接conditions。用R表示。
5、? actions 動作,激活一條rule執行的動作。我們這里不作討論。
6、? 還有一些術語,如:working-memory、production-memory,跟這里的概念大同小異。
7、? 還有一些,如:alpha-network、beta-network、join-node,我們下面會用到,先放一下,一會討論。
?
引用一下網上很流行的例子,我覺得沒講明白,我在用我的想法解釋一下。
?
假設在規則記憶中有下列三條規則
?
if A(x) and B(x) and C(y) then add D(x)
if A(x) and B(y) and D(x) then add E(x)
if A(x) and B(x) and E(x) then delete A(x)
?
RETE算法會先將規則編譯成下列的樹狀架構排序網絡

而工作記憶內容及順序為{A(1),A(2),B(2),B(3),B(4),C(5)},當工作記憶依序進入網絡后,會依序儲存在符合條件的節點中,直到完全符合條件的推論規則推出推論。以上述例子而言, 最后推得D(2)。
?
讓我們來分析這個例子。
?
模板庫:(這個例子中只有一個模板,算法原描述中有不同的例子, 一般我們會用tuple,元組的形式來定義facts,patterns,condition)
P: (?A , ?x)? 其中的A可能代表一定的操作,如例子中的A,B,C,D,E ; x代表操作的參數。看看這個模板是不是已經可以描述所有的事實。
?
條件庫:(這里元組的第一項代表實際的操作,第二項代表形參)
C1: (A , <x>)
C2: (B , <x>)
C3: (C , <y>)
C4: (D , <x>)
C5: (E , <x>)
C6: (B , <y>)
?
事實庫:(第二項代表實參)
F1: (A,1)
F2: (A,2)
F3: (B,2)
F4: (B,3)
F5: (B,4)
F6: (C,5)
?
?????? 規則庫:
?????? ? R1: c1^c2^c3
?????? ? R2: c1^c2^c4
?????? ? R3: c1^c2^c5
?
??????
?????? 有人可能會質疑R1: c1^c2^c3,沒有描述出,原式中:
if A(x) and B(x) and C(y) then add D(x),A=B的關系。但請仔細看一下,這一點已經在條件庫中定義出來了。
?
?????? 下面我來描述一下,規則引擎中RETE算法的實現。
?????? 首先,我們要定一些規則,根據這些規則,我們的引擎可以編譯出一個樹狀結構,上面的那張圖中是一種簡易的表現,其實在實現的時候不是這個樣子的。
?????? 這就是beta-network出場的時候了,根據rules我們就可以確定beta-network,下面,我就畫出本例中的beta-network,為了描述方便,我把alpha-network也畫出來了。
??????
?
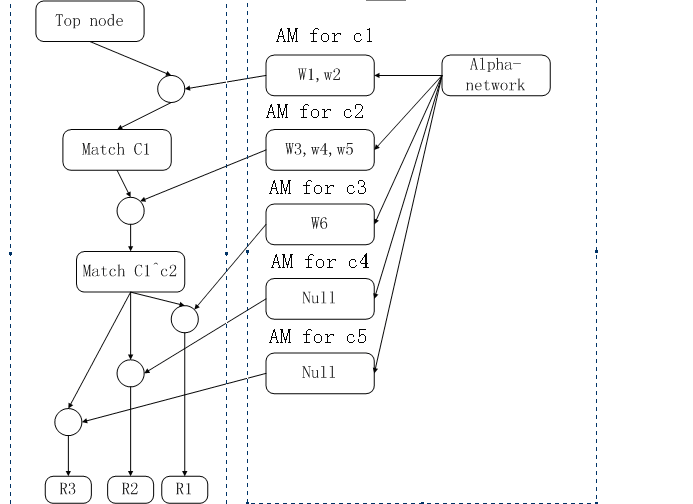
上圖中,左邊的部分就是beta-network,右邊是alpha-network,圓圈是join-node.
從上圖中,我們可以驗證,在beta-network中,表現出了rules的內容,其中r1,r2,r3共享了許多BM和join-node,這是由于這些規則中有共同的部分,這樣能加快match的速度。
右
邊的alpha-network是根據事實庫構建的,其中除alpha-network節點的節點都是根據每一條condition,從事實庫中
match過來的,這一過程是靜態的,即在編譯構建網絡的過程中已經建立的。只要事實庫是穩定的,即沒有大幅度的變化,RETE算法的執行效率應該是非常
高的,其原因就是已經通過靜態的編譯,構建了alpha-network。我們可以驗證一下,滿足c1的事實確實是w1,w2。
下
面我們就看一下,這個算法是怎么來運行的,即怎么來確定被激活的rules的。從top-node往下遍歷,到一個join-node,與AM for
c1的節點匯合,運行到match c1節點。此時,match c1節點的內容就是:w1,w2。繼續往下,與AM for
c2匯合(所有可能的組合應該是w1^w3,w1^w4,w1^w5,w2^w3,w2^w4,w2^w5),因為c1^c2要求參數相同,因此,
match
c1^c2的內容是:w2^w3。再繼續,這里有一個扇出(fan-out),其中只有一個join-node可以被激活,因為旁邊的AM只有一個非空。
因此,也只有R1被激活了。
解決扇出帶來的效率降低的問題,我們可以使用hashtable來解決這個問題。
RETE算法還有一些問題,如:facts庫變化,我們怎么才能高效的重建alpha-network,同理包括rules的變化對beta-network的影響。這一部分我還沒細看,到時候再貼出來吧。
posted on 2006-05-30 15:30
混沌中立 閱讀(1048)
評論(2) 編輯 收藏 所屬分類:
非技術