
2006年5月30日
在一個(gè)項(xiàng)目里面有這么一個(gè)技術(shù)需求:
1.集合中元素個(gè)數(shù),10M
2.根據(jù)上限和下限從一個(gè)Set中過(guò)濾出滿(mǎn)足要求的元素集合.
實(shí)際這個(gè)是個(gè)很典型的技術(shù)要求, 之前的項(xiàng)目也遇見(jiàn)過(guò),但是因?yàn)楫?dāng)時(shí)的類(lèi)庫(kù)不多, 都是直接手寫(xiě)實(shí)現(xiàn)的. 方式基本等同于第一個(gè)方式.
在這個(gè)過(guò)程中, 我寫(xiě)了四個(gè)方式, 基本記錄到下面.
第一個(gè)方式:對(duì)Set進(jìn)行迭代器遍歷, 判斷每個(gè)元素是否都在上限和下限范圍中.如果滿(mǎn)足則添加到結(jié)果集合中, 最后返回結(jié)果集合.
測(cè)試效果:集合大小100K, 運(yùn)算時(shí)間 3000ms+
過(guò)濾部分的邏輯如下:
1 void filerSet(Set<BigDecimal> targetSet, String lower, String higher) {
2 BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
3 BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
4
5 Set<BigDecimal> returnSet = new HashSet<BigDecimal>();
6 for (BigDecimal object : targetSet) {
7 if (isInRange(object, bdLower, bdHigher)) {
8 returnSet.add(object);
9 }
10 }
11 }
12
13 private boolean isInRange(BigDecimal object, BigDecimal bdLower,
14 BigDecimal bdHigher) {
15 return object.compareTo(bdLower) >= 0
16 && object.compareTo(bdHigher) <= 0;
17 }
第二個(gè)方式: 借助TreeSet, 原始集合進(jìn)行排序, 然后直接subset.
測(cè)試效果: 集合大小10M, 運(yùn)算時(shí)間: 12000ms+(獲得TreeSet) , 200ms(獲得結(jié)果)
過(guò)濾部分的邏輯如下(非常繁瑣):
1 Set<BigDecimal> getSubSet(TreeSet<BigDecimal> targetSet, String lower,
2 String higher) {
3
4 BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
5 BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
6
7 if ((bdHigher.compareTo(targetSet.first()) == -1)
8 || (bdLower.compareTo(targetSet.last()) == 1)) {
9 return null;
10 }
11
12 boolean hasLower = targetSet.contains(bdLower);
13 boolean hasHigher = targetSet.contains(bdHigher);
14 if (hasLower) {
15 if (hasHigher) {
16 System.out.println("get start:" + bdLower);
17 System.out.println("get end:" + bdHigher);
18 return targetSet.subSet(bdLower, true, bdHigher, true);
19 } else {
20 BigDecimal newEnd = null;
21 System.out.println("get start:" + bdLower);
22 SortedSet<BigDecimal> returnSet = null;
23 if (bdHigher.compareTo(targetSet.last()) != -1) {
24 newEnd = targetSet.last();
25 } else {
26 SortedSet<BigDecimal> newTargetSet = targetSet
27 .tailSet(bdLower);
28 for (BigDecimal object : newTargetSet) {
29 if (object.compareTo(bdHigher) == 1) {
30 newEnd = object;
31 break;
32 } else if (object.compareTo(bdHigher) == 0) {
33 newEnd = object;
34 break;
35 }
36 }
37 }
38 returnSet = targetSet.subSet(bdLower, true, newEnd, true);
39 if (newEnd.compareTo(bdHigher) == 1) {
40 returnSet.remove(newEnd);
41 }
42 return returnSet;
43 }
44
45 } else {
46 if (hasHigher) {
47 System.out.println("get end:" + bdHigher);
48 TreeSet<BigDecimal> newTargetSet = (TreeSet<BigDecimal>) targetSet
49 .headSet(bdHigher, true);
50 BigDecimal newStart = null;
51 SortedSet<BigDecimal> returnSet = null;
52
53 if (bdLower.compareTo(targetSet.first()) == -1) {
54 newStart = targetSet.first();
55 } else {
56 for (BigDecimal object : newTargetSet) {
57 if (object.compareTo(bdLower) != -1) {
58 newStart = object;
59 break;
60 }
61 }
62 }
63 returnSet = targetSet.subSet(newStart, true, bdHigher, true);
64
65 return returnSet;
66 } else {
67 System.out.println("Not get start:" + bdLower);
68 System.out.println("Not get end:" + bdHigher);
69 BigDecimal newStart = null;
70 BigDecimal newEnd = null;
71 if (bdHigher.compareTo(targetSet.last()) != -1) {
72 newEnd = targetSet.last();
73 }
74 if (bdLower.compareTo(targetSet.first()) == -1) {
75 newStart = targetSet.first();
76 }
77 for (BigDecimal object : targetSet) {
78 if (newStart == null) {
79 if (object.compareTo(bdLower) != -1) {
80 newStart = object;
81 if (newEnd != null) {
82 break;
83 }
84 }
85 }
86
87 if (newEnd == null) {
88 if (object.compareTo(bdHigher) != -1) {
89 newEnd = object;
90 if (newStart != null) {
91 break;
92 }
93 }
94 }
95 }
96
97 if (newStart == null) {
98 if (newEnd == null) {
99 if ((bdHigher.compareTo(targetSet.first()) == -1)
100 || (bdLower.compareTo(targetSet.last()) == 1)) {
101 return null;
102 }
103 return targetSet;
104 } else {
105 SortedSet<BigDecimal> newTargetSet = targetSet.headSet(
106 newEnd, true);
107 if (newEnd.compareTo(bdHigher) == 1) {
108 newTargetSet.remove(newEnd);
109 }
110 return newTargetSet;
111 }
112 } else {
113 if (newEnd == null) {
114 SortedSet<BigDecimal> newTargetSet = targetSet.tailSet(
115 newStart, true);
116 return newTargetSet;
117 } else {
118 SortedSet<BigDecimal> newTargetSet = targetSet.subSet(
119 newStart, true, newEnd, true);
120 if (newEnd.compareTo(bdHigher) == 1) {
121 newTargetSet.remove(newEnd);
122 }
123 return newTargetSet;
124 }
125 }
126 }
127 }
128 }
第三種方式: 使用Apache Commons Collections, 直接對(duì)于原始Set進(jìn)行filter.
測(cè)試效果:集合大小10M,過(guò)濾結(jié)果1M, 運(yùn)算時(shí)間: 1000ms+
過(guò)濾部分的代碼如下:
1 //過(guò)濾的主體邏輯
2 void filterSet(Set<BigDecimal> targetSet, String lower, String higher) {
3 final BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
4 final BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
5
6 Predicate predicate = new Predicate() {
7 public boolean evaluate(Object object) {
8 BigDecimal bDObject = (BigDecimal) object;
9 return bDObject.compareTo(bdLower) >= 0
10 && bDObject.compareTo(bdHigher) <= 0;
11 }
12 };
13
14 CollectionUtils.filter(targetSet, predicate);
15 }
第四種方式:使用Guava(google Collections), 直接對(duì)于原始Set進(jìn)行Filter
測(cè)試效果:集合大小10M,過(guò)濾結(jié)果1M, 運(yùn)算時(shí)間: 100ms-
過(guò)濾部分的代碼如下:
1 //guava filter
2
3 Set<BigDecimal> filterSet(Set<BigDecimal> targetSet, String lower,
4 String higher) {
5 final BigDecimal bdLower = new BigDecimal(Double.parseDouble(lower));
6 final BigDecimal bdHigher = new BigDecimal(Double.parseDouble(higher));
7
8 Set<BigDecimal> filterCollection = Sets.filter(targetSet,
9 new Predicate<BigDecimal>() {
10 @Override
11 public boolean apply(BigDecimal input) {
12 BigDecimal bDObject = (BigDecimal) input;
13 return bDObject.compareTo(bdLower) >= 0
14 && bDObject.compareTo(bdHigher) <= 0;
15 }
16 });
17
18 return filterCollection;
19 }
四種方式對(duì)比如下:
第一種方式: 僅依賴(lài)于JAVA原生類(lèi)庫(kù) 遍歷時(shí)間最慢, 代碼量很小
第二種方式: 僅依賴(lài)于JAVA原生類(lèi)庫(kù) 遍歷時(shí)間比較慢(主要慢在生成有序Set), 代碼量最多
第三種方式: 依賴(lài)于Apache Commons Collections, 遍歷時(shí)間比較快, 代碼量很少
第四種方式: 依賴(lài)于Guava, 遍歷時(shí)間最快, 代碼量很少
基于目前個(gè)人的技術(shù)水平和視野, 第四種方式可能是最佳選擇.
記錄一下, 以后可能還會(huì)有更好的方案.
在幾年之前,在大學(xué)里面的時(shí)候,認(rèn)為系統(tǒng)的架構(gòu)設(shè)計(jì),就像建筑設(shè)計(jì)一樣,會(huì)把骨架搭成,然后有具體人員進(jìn)行詳細(xì)的開(kāi)發(fā).
在后來(lái),工作中,慢慢有了一些變化,因?yàn)樵鹊南敕ú惶泻蠈?shí)際,系統(tǒng)就是在變化之中的,如果固定了骨架,那就很難的敏捷面對(duì)變化.
所以,系統(tǒng)的架構(gòu)設(shè)計(jì),應(yīng)該是面向接口的設(shè)計(jì),確定各個(gè)部分之間的數(shù)據(jù)接口和方法接口.這樣,即使有了變化,只要遵循接口的定義,就還是可以面對(duì)變化.
最近,又有了想法的變化.架構(gòu)的設(shè)計(jì),應(yīng)該就是規(guī)則和規(guī)約的設(shè)計(jì).設(shè)計(jì)出一系列,統(tǒng)一的,和諧的規(guī)則,在這些規(guī)則之前圈住的部分,實(shí)際就是系統(tǒng)的全貌.
接口的設(shè)計(jì),實(shí)際只是規(guī)則和規(guī)約設(shè)計(jì)的一個(gè)部分.
架構(gòu)的設(shè)計(jì),不應(yīng)該只是程序方面的事情,同時(shí)也包含了心理學(xué)方面和社會(huì)學(xué)方面的一些規(guī)則.例如:團(tuán)隊(duì)在面對(duì)變化時(shí)候,需要采用的規(guī)則和流程.
只有包含了這些非程序上的規(guī)則之后,才能保證架構(gòu)風(fēng)格的統(tǒng)一協(xié)調(diào).
以上,是我對(duì)系統(tǒng)設(shè)計(jì)的想法的轉(zhuǎn)變過(guò)程.記錄于此,以供回溯.
面對(duì)著滿(mǎn)屏幕的程序
是三年前,項(xiàng)目剛剛啟動(dòng)的時(shí)候,同事寫(xiě)的代碼.
三年過(guò)去了,項(xiàng)目由第一期變成了第七期.
這段代碼還是在這里,有個(gè)屬性是list,其中每個(gè)cell都是一個(gè)長(zhǎng)度18的String數(shù)組.
數(shù)組里面放置了所需要導(dǎo)出到頁(yè)面table的內(nèi)容.
現(xiàn)在要開(kāi)始修改了,需要向頁(yè)面的table中增加4列.
繁瑣的讓人要命的工作,需要跟蹤這個(gè)循環(huán),判斷每個(gè)pattern下面,這個(gè)長(zhǎng)度18的數(shù)組里面放了哪些內(nèi)容.
好吧,對(duì)象化維護(hù)從數(shù)組開(kāi)始,把數(shù)組對(duì)折,因?yàn)檫@個(gè)數(shù)組時(shí)一個(gè)比較數(shù)組,前面9個(gè)元素是之前的情況,后面9個(gè)事之后的情況.
用一個(gè)bean,放入兩次就可以了.但是bean中,需要一個(gè)標(biāo)志,標(biāo)識(shí)是之前的情況還是之后的情況.
同時(shí)需要一個(gè)transform方法,把之前從幾個(gè)來(lái)源過(guò)來(lái)的情況,變成bean的屬性.
接下來(lái)需要一個(gè)values方法,把bean里面的屬性直接按順序轉(zhuǎn)化成數(shù)組.
本期新增的4個(gè)屬性,直接放入bean中就可以了.
這樣原來(lái)很復(fù)雜的數(shù)組,就可以簡(jiǎn)單的用對(duì)象來(lái)解決.外部的接口完全沒(méi)有變化.
維護(hù)程序,從把數(shù)組(特別是異型數(shù)組)對(duì)象化開(kāi)始.
這個(gè)小的project是前一個(gè)階段,待業(yè)在家的時(shí)候,迷戀sudoku的時(shí)候,自己寫(xiě)來(lái)玩的。
正好當(dāng)時(shí)在看Uncle Bob的《Agile Software Development: Principles, Patterns, and Practices》 (敏捷軟件開(kāi)發(fā):原則、模式與實(shí)踐),所以就按照自己對(duì)書(shū)中的一些概念和方法的理解,結(jié)合自己之前的開(kāi)發(fā)經(jīng)驗(yàn)寫(xiě)出來(lái)一段小的代碼。
代碼行數(shù): < 900
類(lèi)的個(gè)數(shù): 18
抽象類(lèi)的個(gè)數(shù):2
工廠類(lèi)的個(gè)數(shù):1
包的個(gè)數(shù):5
一些關(guān)于類(lèi)和包作用的說(shuō)明:
1.Cell:表示一個(gè)Cell,是一個(gè)游戲中的一個(gè)單元格。
? Cell主要由3個(gè)部分組成,Point,Value,Status.
2.Point:表示一個(gè)坐標(biāo),主要格式為:(2,3).
? !!!注意:由于個(gè)人比較懶,所以開(kāi)始的錯(cuò)誤被貫徹了下來(lái)。
? 這個(gè)錯(cuò)誤就是(2,3)表示的是由最左上的位置為坐標(biāo)原點(diǎn),第二行和第三列所確定的那個(gè)單元格。也就是縱坐標(biāo)在前,橫坐標(biāo)在后了。
3.Value:表示一個(gè)值
4.Status:表示Cell的狀態(tài),只有兩個(gè)狀態(tài),一個(gè)是NotSure,另一個(gè)是Sure.
5.AbstractCells:表示一些cell的集合,主要有三個(gè)子類(lèi)
???? BlockCells:表示一個(gè)由多個(gè)Cell組成的塊,例如一個(gè)2*2由4個(gè)Cell組成的塊,或者一個(gè)2*3由6個(gè)Cell組成的塊
???? HorizonCells:表示一個(gè)橫行,即:從(0,0)到(0,n)坐標(biāo)確定的所有Cell的集合。
???? VerticalCells:表示一個(gè)縱行,即:從(0,0)到(n,0)坐標(biāo)確定的所有Cell的集合。
6.AbstractPolicy:就是游戲的策略。
?? 這個(gè)主要表示的是:4*4的游戲,還是9*9的游戲。
?? 可以在以后對(duì)此類(lèi)進(jìn)行繼承和擴(kuò)展,例如16*16的游戲我就沒(méi)有實(shí)現(xiàn)。
?? 主要擴(kuò)展3個(gè)方法:
????????????????? 1)getValueRange,返回當(dāng)前policy的value的個(gè)數(shù)。4*4的游戲的getValueRange返回的就應(yīng)該是4。
??? ??? ? 2)getStep:表示當(dāng)前policy中相鄰的兩個(gè)BlockCells的坐標(biāo)差。
??? ??? ? 3)getIncrease:說(shuō)不明白了:)(只可意會(huì)不可言傳。)
7.Game:進(jìn)行Policy的場(chǎng)所(我一直想拋棄這個(gè)類(lèi))
8.TestGame:游戲運(yùn)行的地方,包括從PolicyFactory取得指定的Policy,設(shè)置輸入輸出文件的路徑。
9.PolicyFactory:取得Policy的工廠。
??? getPolicy(int x) :這個(gè)方法獲得的是正方形的sudoku的策略。例如:4*4的,9*9,16*16。
??? getPolicy(int x, int y):這個(gè)方法獲得的是長(zhǎng)方形的Sudoku的策略。例如:9*12的。
雖然是盡量避免bad code smell,但是由于能力有限,還是出現(xiàn)了一些不好的地方。
例如:之間的關(guān)聯(lián)關(guān)系還是很多,而且很強(qiáng);抽象的方法和抽象類(lèi)的個(gè)數(shù)偏少等等。
里面實(shí)現(xiàn)了三個(gè)解決sudoku的方法:
1.在一個(gè)Cell中出現(xiàn)的Value,不會(huì)在和這個(gè)Cell處在同一個(gè)AbstractCells中的所有Cell中出現(xiàn);
2.如果一個(gè)Cell中,所有可能出現(xiàn)的Value的個(gè)數(shù)為1,那么Cell的Value必然是這個(gè)最后的Value;
2.如果一個(gè)Value,如果在當(dāng)前AbstractCells的所有其他的Cell中都不可能出現(xiàn),那么它必然是最后一個(gè)Cell的Value。
附件1:src code
http://www.tkk7.com/Files/GandofYan/sudoku.rar
附件2:輸入輸出文件的example
http://www.tkk7.com/Files/GandofYan/temp.rar
如同Tom DeMacro說(shuō)的:無(wú)法控制的東西就不能管理,無(wú)法測(cè)量的東西就無(wú)法控制。
軟件的度量對(duì)于設(shè)計(jì)者和開(kāi)發(fā)者非常重要,之前只是對(duì)這些有一個(gè)簡(jiǎn)單的了解。今天看來(lái),了解的還遠(yuǎn)遠(yuǎn)不夠。
- Cyclomatic Complexity (圈復(fù)雜性)
- Response for Class (類(lèi)的響應(yīng))
- Weighted methods per class (每個(gè)類(lèi)重量方法)
一個(gè)系統(tǒng)中的所有類(lèi)的這三個(gè)度量能夠說(shuō)明這個(gè)系統(tǒng)的設(shè)計(jì)上的一些問(wèn)題(不是全部),這三個(gè)度量越大越不好。
如果一個(gè)類(lèi)這三個(gè)度量很高,證明了這個(gè)類(lèi)需要重構(gòu)了。
以第一個(gè)度量來(lái)說(shuō),有下面的一個(gè)表格:
CC Value | Risk |
1-10 | Low
risk program |
11-20 | Moderate
risk |
21-50 | High
risk |
>50 | Most
complex and highly unstable method |
CC數(shù)值高,可以通過(guò)減少if else(switch case也算)判斷來(lái)達(dá)到目的;
可以通過(guò)減少類(lèi)與其他類(lèi)的調(diào)用來(lái)減少RFC;
通過(guò)分割大方法和大類(lèi)來(lái)達(dá)到減少WMPC.
而Uncle Bob和Jdepend的度量標(biāo)準(zhǔn)應(yīng)該算是另一個(gè)度量系統(tǒng)。
用包中的每個(gè)類(lèi)平均的內(nèi)部關(guān)系數(shù)目作為包內(nèi)聚性的一種表示方式。用于表示包和它的所有類(lèi)之間的關(guān)系。
H=(R+1)/N
R:包內(nèi)類(lèi)的關(guān)系數(shù)目(與包外部的類(lèi)沒(méi)有關(guān)系)
N:包內(nèi)類(lèi)的數(shù)量
被分析package的具體和抽象類(lèi)(和接口)的數(shù)量,用于衡量package的可擴(kuò)展性。
依賴(lài)于被分析package的其他package的數(shù)量,用于衡量pacakge的職責(zé)。
被分析package的類(lèi)所依賴(lài)的其他package的數(shù)量,用于衡量package的獨(dú)立性。
被分析package中的抽象類(lèi)和接口與所在package所有類(lèi)數(shù)量的比例,取值范圍為0-1。
A=Cc/N
用于衡量package的不穩(wěn)定性,取值范圍為0-1。I=0表示最穩(wěn)定,I=1表示最不穩(wěn)定。
I=Ce/(Ce+Ca)
??? ??? ? 被分析package和理想曲線A+I(xiàn)=1的垂直距離,用于衡量package在穩(wěn)定性和抽象性之間的平衡。理想??? ??? ? 的package要么完全是抽象類(lèi)和穩(wěn)定(x=0,y=1),要么完全是具體類(lèi)和不穩(wěn)定(x=1,y=0)。
??? ??? ? 取值范圍為0-1,D=0表示完全符合理想標(biāo)準(zhǔn),D=1表示package最大程度地偏離了理想標(biāo)準(zhǔn)。
??? ?? ?? D = |A+I-1|/0.70710678
??? ?? ?? 注:0.70710678*0.70710678 =2,既為“根號(hào)2“
我認(rèn)為D是一個(gè)綜合的度量,架構(gòu)和設(shè)計(jì)的改善可以通過(guò)D數(shù)值的減少來(lái)體現(xiàn),反之就可以認(rèn)為是設(shè)計(jì)和架構(gòu)的退化。
讀過(guò)http://javaboutique.internet.com/tutorials/metrics/index.html之后的一些想法
另一篇中文的內(nèi)容相近的文章可以參考http://www.jdon.com/artichect/coupling.htm
不過(guò)第二篇的中文文章中間關(guān)于Cyclomatic Complexity,有一個(gè)情況遺漏了
public void findApplications(String id, String name){
if(id!=null && name!=null) {
//do something
}else{
//do something
}
}
這種情況的CC不是2+1,而是2+1+1,依據(jù)是公式(1)。公式(2)應(yīng)該是公式(1)的簡(jiǎn)化版。
Cyclomatic Complexity (CC) = no of decision points + no of logical operations +1 (1)
Cyclomatic Complexity (CC) = number of decision points +1 (2)
參考了JDepend的參數(shù)和Uncle Bob的《Agile Software Development: Principles, Patterns, and Practices》 (敏捷軟件開(kāi)發(fā):原則、模式與實(shí)踐)
轉(zhuǎn)自:http://www.keyusoft.cn/Contentview.aspx?year=2005&month=$10&day=$6&postid=123
通過(guò)一周左右的研究,對(duì)規(guī)則引擎有了一定的了解。現(xiàn)在寫(xiě)點(diǎn)東西跟大家一起交流,本文主要針對(duì)RETE算法進(jìn)行描述。我的文筆不太好,如果有什么沒(méi)講明白的或是說(shuō)錯(cuò)的地方,請(qǐng)給我留言。
首先申明,我的帖子借鑒了網(wǎng)上很流行的一篇帖子,好像是來(lái)自CSDN;還有一點(diǎn),我不想做太多的名詞解釋?zhuān)驗(yàn)槲乙膊皇莻€(gè)研究很深的人,定義的不好怕被笑話。
好現(xiàn)在我們開(kāi)始。
首先介紹一些網(wǎng)上對(duì)于規(guī)則引擎比較好的帖子。
1、 來(lái)自JAVA視頻網(wǎng)
2、? RETE算法的最原始的描述,我不知道在哪里找到的,想要的人可以留下E-mail
?
接著統(tǒng)一一下術(shù)語(yǔ),很多資料里的術(shù)語(yǔ)都非常混亂。
1、? facts 事實(shí),我們實(shí)現(xiàn)的時(shí)候,會(huì)有一個(gè)事實(shí)庫(kù)。用F表示。
2、? patterns 模板,事實(shí)的一個(gè)模型,所有事實(shí)庫(kù)中的事實(shí)都必須滿(mǎn)足模板中的一個(gè)。用P表示。
3、
? conditions
條件,規(guī)則的組成部分。也必須滿(mǎn)足模板庫(kù)中的一條模板。用C表示。我們可以這樣理解facts、patterns、conditions之間的關(guān)系。
Patterns是一個(gè)接口,conditions則是實(shí)現(xiàn)這個(gè)接口的類(lèi),而facts是這個(gè)類(lèi)的實(shí)例。
4、? rules 規(guī)則,由一到多個(gè)條件構(gòu)成。一般用and或or連接conditions。用R表示。
5、? actions 動(dòng)作,激活一條rule執(zhí)行的動(dòng)作。我們這里不作討論。
6、? 還有一些術(shù)語(yǔ),如:working-memory、production-memory,跟這里的概念大同小異。
7、? 還有一些,如:alpha-network、beta-network、join-node,我們下面會(huì)用到,先放一下,一會(huì)討論。
?
引用一下網(wǎng)上很流行的例子,我覺(jué)得沒(méi)講明白,我在用我的想法解釋一下。
?
假設(shè)在規(guī)則記憶中有下列三條規(guī)則
?
if A(x) and B(x) and C(y) then add D(x)
if A(x) and B(y) and D(x) then add E(x)
if A(x) and B(x) and E(x) then delete A(x)
?
RETE算法會(huì)先將規(guī)則編譯成下列的樹(shù)狀架構(gòu)排序網(wǎng)絡(luò)

而工作記憶內(nèi)容及順序?yàn)閧A(1),A(2),B(2),B(3),B(4),C(5)},當(dāng)工作記憶依序進(jìn)入網(wǎng)絡(luò)后,會(huì)依序儲(chǔ)存在符合條件的節(jié)點(diǎn)中,直到完全符合條件的推論規(guī)則推出推論。以上述例子而言, 最后推得D(2)。
?
讓我們來(lái)分析這個(gè)例子。
?
模板庫(kù):(這個(gè)例子中只有一個(gè)模板,算法原描述中有不同的例子, 一般我們會(huì)用tuple,元組的形式來(lái)定義facts,patterns,condition)
P: (?A , ?x)? 其中的A可能代表一定的操作,如例子中的A,B,C,D,E ; x代表操作的參數(shù)。看看這個(gè)模板是不是已經(jīng)可以描述所有的事實(shí)。
?
條件庫(kù):(這里元組的第一項(xiàng)代表實(shí)際的操作,第二項(xiàng)代表形參)
C1: (A , <x>)
C2: (B , <x>)
C3: (C , <y>)
C4: (D , <x>)
C5: (E , <x>)
C6: (B , <y>)
?
事實(shí)庫(kù):(第二項(xiàng)代表實(shí)參)
F1: (A,1)
F2: (A,2)
F3: (B,2)
F4: (B,3)
F5: (B,4)
F6: (C,5)
?
?????? 規(guī)則庫(kù):
?????? ? R1: c1^c2^c3
?????? ? R2: c1^c2^c4
?????? ? R3: c1^c2^c5
?
??????
?????? 有人可能會(huì)質(zhì)疑R1: c1^c2^c3,沒(méi)有描述出,原式中:
if A(x) and B(x) and C(y) then add D(x),A=B的關(guān)系。但請(qǐng)仔細(xì)看一下,這一點(diǎn)已經(jīng)在條件庫(kù)中定義出來(lái)了。
?
?????? 下面我來(lái)描述一下,規(guī)則引擎中RETE算法的實(shí)現(xiàn)。
?????? 首先,我們要定一些規(guī)則,根據(jù)這些規(guī)則,我們的引擎可以編譯出一個(gè)樹(shù)狀結(jié)構(gòu),上面的那張圖中是一種簡(jiǎn)易的表現(xiàn),其實(shí)在實(shí)現(xiàn)的時(shí)候不是這個(gè)樣子的。
?????? 這就是beta-network出場(chǎng)的時(shí)候了,根據(jù)rules我們就可以確定beta-network,下面,我就畫(huà)出本例中的beta-network,為了描述方便,我把a(bǔ)lpha-network也畫(huà)出來(lái)了。
??????
?
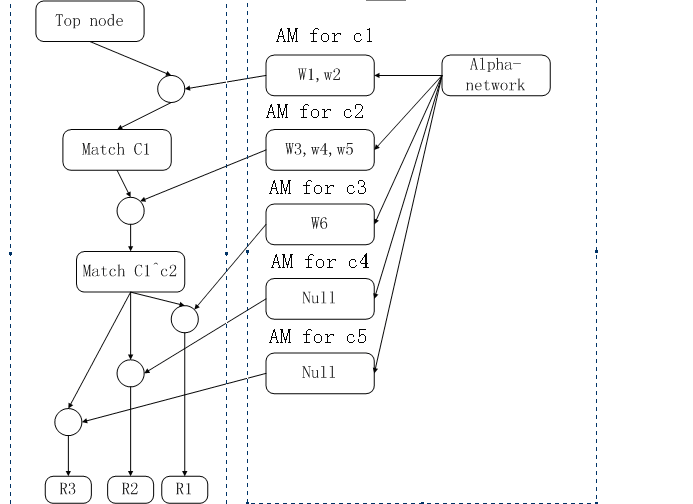
上圖中,左邊的部分就是beta-network,右邊是alpha-network,圓圈是join-node.
從上圖中,我們可以驗(yàn)證,在beta-network中,表現(xiàn)出了rules的內(nèi)容,其中r1,r2,r3共享了許多BM和join-node,這是由于這些規(guī)則中有共同的部分,這樣能加快match的速度。
右
邊的alpha-network是根據(jù)事實(shí)庫(kù)構(gòu)建的,其中除alpha-network節(jié)點(diǎn)的節(jié)點(diǎn)都是根據(jù)每一條condition,從事實(shí)庫(kù)中
match過(guò)來(lái)的,這一過(guò)程是靜態(tài)的,即在編譯構(gòu)建網(wǎng)絡(luò)的過(guò)程中已經(jīng)建立的。只要事實(shí)庫(kù)是穩(wěn)定的,即沒(méi)有大幅度的變化,RETE算法的執(zhí)行效率應(yīng)該是非常
高的,其原因就是已經(jīng)通過(guò)靜態(tài)的編譯,構(gòu)建了alpha-network。我們可以驗(yàn)證一下,滿(mǎn)足c1的事實(shí)確實(shí)是w1,w2。
下
面我們就看一下,這個(gè)算法是怎么來(lái)運(yùn)行的,即怎么來(lái)確定被激活的rules的。從top-node往下遍歷,到一個(gè)join-node,與AM for
c1的節(jié)點(diǎn)匯合,運(yùn)行到match c1節(jié)點(diǎn)。此時(shí),match c1節(jié)點(diǎn)的內(nèi)容就是:w1,w2。繼續(xù)往下,與AM for
c2匯合(所有可能的組合應(yīng)該是w1^w3,w1^w4,w1^w5,w2^w3,w2^w4,w2^w5),因?yàn)閏1^c2要求參數(shù)相同,因此,
match
c1^c2的內(nèi)容是:w2^w3。再繼續(xù),這里有一個(gè)扇出(fan-out),其中只有一個(gè)join-node可以被激活,因?yàn)榕赃叺腁M只有一個(gè)非空。
因此,也只有R1被激活了。
解決扇出帶來(lái)的效率降低的問(wèn)題,我們可以使用hashtable來(lái)解決這個(gè)問(wèn)題。
RETE算法還有一些問(wèn)題,如:facts庫(kù)變化,我們?cè)趺床拍芨咝У闹亟╝lpha-network,同理包括rules的變化對(duì)beta-network的影響。這一部分我還沒(méi)細(xì)看,到時(shí)候再貼出來(lái)吧。
最近插件又加多了,eclipse老是死掉
?
一怒之下,刪除重裝
?
以前因?yàn)閼?沒(méi)有把插件的目錄和主體的目錄分開(kāi),這次也給它分開(kāi)了
?
?
插件少了之后,eclipse確實(shí)快了不少
?
附eclipse啟動(dòng)參數(shù): -nl en_US vmargs -Xverify:none -Xms256M -Xmx1024M
-XX:PermSize=50M? -XX:+UseParallelGC
freemind一個(gè)比較不錯(cuò)free的
mind map 軟件,很多人建議使用這個(gè)來(lái)管理自己的思路.
?
mind manager另一個(gè)比較不錯(cuò)的mind
map的軟件,可以和office兼容.不過(guò)是商業(yè)的
?
visio,就不介紹了.office里面有的東西.做流程圖來(lái)說(shuō),確實(shí)是比較好的軟件.但是在思路不清楚的時(shí)候,很難畫(huà)出什么有用的東西來(lái).這點(diǎn)就比不上前面兩個(gè)東西了.不過(guò)對(duì)我來(lái)說(shuō)visio可能更順手,因?yàn)槲医?jīng)常畫(huà)的是軟件流程圖........
?
在最近的圍繞domain
object的討論中浮現(xiàn)出來(lái)了三種模型,(還有一些其他的旁枝,不一一分析了),經(jīng)過(guò)一番討論,各種問(wèn)題逐漸清晰起來(lái),在這里我試圖做一個(gè)總結(jié),便于大家了解和掌握。
第一種模型:只有g(shù)etter/setter方法的純數(shù)據(jù)類(lèi),所有的業(yè)務(wù)邏輯完全由business
object來(lái)完成(又稱(chēng)TransactionScript),這種模型下的domain object被Martin Fowler稱(chēng)之為“貧血的domain
object”。下面用舉一個(gè)具體的代碼來(lái)說(shuō)明,代碼來(lái)自Hibernate的caveatemptor,但經(jīng)過(guò)我的改寫(xiě):
一個(gè)實(shí)體類(lèi)叫做Item,指的是一個(gè)拍賣(mài)項(xiàng)目
一個(gè)DAO接口類(lèi)叫做ItemDao
一個(gè)DAO接口實(shí)現(xiàn)類(lèi)叫做ItemDaoHibernateImpl
一個(gè)業(yè)務(wù)邏輯類(lèi)叫做ItemManager(或者叫做ItemService)
|
java代碼:?
|
|
public
class Item implementsSerializable{
? ? privateLong id = null;
? ? privateint version;
? ?
privateString name;
? ? private User seller;
? ? privateString description;
? ? private MonetaryAmount
initialPrice;
? ? private MonetaryAmount
reservePrice;
? ? privateDate startDate;
? ? privateDate endDate;
? ? privateSet categorizedItems = newHashSet();
? ? privateCollection bids = newArrayList();
? ? private
Bid successfulBid;
? ? private ItemState state;
? ? private
User approvedBy;
? ? privateDate approvalDatetime;
? ? privateDate created = newDate();
? ? //?
getter/setter方法省略不寫(xiě),避免篇幅太長(zhǎng)
}
|
|
java代碼:?
|
|
public
interface ItemDao {
? ? public Item
getItemById(Long id);
? ? publicCollection findAll();
? ? publicvoid
updateItem(Item item);
}
|
ItemDao定義持久化操作的接口,用于隔離持久化代碼。
|
java代碼:?
|
|
public
class
ItemDaoHibernateImpl implements ItemDao extends
HibernateDaoSupport {
? ? public Item
getItemById(Long id){
? ? ? ? return(Item) getHibernateTemplate().load(Item.class, id);
? ? }
? ? publicCollection findAll(){
? ? ? ? return(List) getHibernateTemplate().find("from
Item");
? ? }
? ? publicvoid updateItem(Item item){
? ? ? ? getHibernateTemplate().update(item);
? ? }
}
|
ItemDaoHibernateImpl完成具體的持久化工作,請(qǐng)注意,數(shù)據(jù)庫(kù)資源的獲取和釋放是在ItemDaoHibernateImpl
里面處理的,每個(gè)DAO方法調(diào)用之前打開(kāi)Session,DAO方法調(diào)用之后,關(guān)閉Session。(Session放在ThreadLocal中,保證一次調(diào)用只打開(kāi)關(guān)閉一次)
|
java代碼:?
|
|
public
class ItemManager {
? ? private ItemDao itemDao;
? ? publicvoid
setItemDao(ItemDao itemDao){
this.itemDao = itemDao;}
? ? public Bid
loadItemById(Long id){
? ? ? ? itemDao.loadItemById(id);
? ? }
? ? publicCollection listAllItems(){
? ? ? ? return? itemDao.findAll();
? ? }
? ? public Bid placeBid(Item item, User bidder, MonetaryAmount
bidAmount,
? ? ? ? ? ? ? ? ? ? ? ? ? ? Bid currentMaxBid, Bid
currentMinBid)throws BusinessException
{
? ? ? ? ? ? if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
? ? ? ? ? ? throw new
BusinessException("Bid too low.");
? ? }
? ?
? ? // Auction is active
? ? if( !state.equals(ItemState.ACTIVE))
? ? ? ? ? ? throw new
BusinessException("Auction is not active yet.");
? ?
? ? // Auction still valid
? ? if( item.getEndDate().before(newDate()))
? ? ? ? ? ? throw new
BusinessException("Can't place new bid, auction already
ended.");
? ?
? ? // Create new Bid
? ? Bid newBid =
new Bid(bidAmount, item, bidder);
? ?
? ? // Place bid for this Item
? ?
item.getBids().add(newBid);
? ? itemDao.update(item);?
? ?//? 調(diào)用DAO完成持久化操作
? ? return newBid;
? ?
}
}
|
事務(wù)的管理是在ItemManger這一層完成的,ItemManager實(shí)現(xiàn)具體的業(yè)務(wù)邏輯。除了常見(jiàn)的和CRUD有關(guān)的簡(jiǎn)單邏輯之外,這里還有一個(gè)placeBid的邏輯,即項(xiàng)目的競(jìng)標(biāo)。
以上是一個(gè)完整的第一種模型的示例代碼。在這個(gè)示例中,placeBid,loadItemById,findAll等等業(yè)務(wù)邏輯統(tǒng)統(tǒng)放在ItemManager中實(shí)現(xiàn),而Item只有g(shù)etter/setter方法。
?
?
第二種模型,也就是Martin Fowler指的rich domain object是下面這樣子的:
一個(gè)帶有業(yè)務(wù)邏輯的實(shí)體類(lèi),即domain object是Item
一個(gè)DAO接口ItemDao
一個(gè)DAO實(shí)現(xiàn)ItemDaoHibernateImpl
一個(gè)業(yè)務(wù)邏輯對(duì)象ItemManager
|
java代碼:?
|
|
public
class Item implementsSerializable{
? ? //? 所有的屬性和getter/setter方法同上,省略
? ?
public Bid
placeBid(User bidder, MonetaryAmount
bidAmount,
? ? ? ? ? ? ? ? ? ? ? ? Bid currentMaxBid, Bid currentMinBid)
? ? ? ? ? ? throws BusinessException
{
? ?
? ? ? ? ? ? // Check highest bid (can also be a different
Strategy (pattern))
? ? ? ? ? ? if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
? ? ? ? ? ? ? ? ? ? throw new
BusinessException("Bid too low.");
? ? ? ? ? ? }
? ?
? ? ? ? ? ? // Auction is active
? ? ? ? ? ?
if( !state.equals(ItemState.ACTIVE))
? ? ? ? ? ? ? ? ? ? throw new
BusinessException("Auction is not active yet.");
? ?
? ? ? ? ? ? // Auction still valid
? ? ? ? ? ?
if( this.getEndDate().before(newDate()))
? ? ? ? ? ? ? ? ? ? throw new
BusinessException("Can't place new bid, auction already
ended.");
? ?
? ? ? ? ? ?
// Create new Bid
? ? ? ? ? ?
Bid newBid = new
Bid(bidAmount, this, bidder);
? ?
? ? ? ? ? ? // Place bid for this Item
? ? ? ? ?
? this.getBids.add(newBid);? //
請(qǐng)注意這一句,透明的進(jìn)行了持久化,但是不能在這里調(diào)用ItemDao,Item不能對(duì)ItemDao產(chǎn)生依賴(lài)!
? ?
? ? ? ?
? ? return newBid;
? ? }
}
|
競(jìng)標(biāo)這個(gè)業(yè)務(wù)邏輯被放入到Item中來(lái)。請(qǐng)注意this.getBids.add(newBid);
如果沒(méi)有Hibernate或者JDO這種O/R
Mapping的支持,我們是無(wú)法實(shí)現(xiàn)這種透明的持久化行為的。但是請(qǐng)注意,Item里面不能去調(diào)用ItemDAO,對(duì)ItemDAO產(chǎn)生依賴(lài)!
ItemDao和ItemDaoHibernateImpl的代碼同上,省略。
|
java代碼:?
|
|
public
class ItemManager {
? ? private ItemDao itemDao;
? ? publicvoid
setItemDao(ItemDao itemDao){
this.itemDao = itemDao;}
? ? public Bid
loadItemById(Long id){
? ? ? ? itemDao.loadItemById(id);
? ? }
? ? publicCollection listAllItems(){
? ? ? ? return? itemDao.findAll();
? ? }
? ? public Bid placeBid(Item item, User bidder, MonetaryAmount
bidAmount,
? ? ? ? ? ? ? ? ? ? ? ? ? ? Bid currentMaxBid, Bid
currentMinBid)throws BusinessException
{
? ? ? ? item.placeBid(bidder, bidAmount, currentMaxBid,
currentMinBid);
? ? ? ? itemDao.update(item);?
? // 必須顯式的調(diào)用DAO,保持持久化
? ? }
}
|
在第二種模型中,placeBid業(yè)務(wù)邏輯是放在Item中實(shí)現(xiàn)的,而loadItemById和findAll業(yè)務(wù)邏輯是放在
ItemManager中實(shí)現(xiàn)的。不過(guò)值得注意的是,即使placeBid業(yè)務(wù)邏輯放在Item中,你仍然需要在ItemManager中簡(jiǎn)單的封裝一層,以保證對(duì)placeBid業(yè)務(wù)邏輯進(jìn)行事務(wù)的管理和持久化的觸發(fā)。
這種模型是Martin Fowler所指的真正的domain
model。在這種模型中,有三個(gè)業(yè)務(wù)邏輯方法:placeBid,loadItemById和findAll,現(xiàn)在的問(wèn)題是哪個(gè)邏輯應(yīng)該放在Item
中,哪個(gè)邏輯應(yīng)該放在ItemManager中。在我們這個(gè)例子中,placeBid放在Item中(但是ItemManager也需要對(duì)它進(jìn)行簡(jiǎn)單的封裝),loadItemById和findAll是放在ItemManager中的。
切分的原則是什么呢? Rod Johnson提出原則是“case by case”,可重用度高的,和domain
object狀態(tài)密切關(guān)聯(lián)的放在Item中,可重用度低的,和domain object狀態(tài)沒(méi)有密切關(guān)聯(lián)的放在ItemManager中。
我提出的原則是:看業(yè)務(wù)方法是否顯式的依賴(lài)持久化。
Item的placeBid這個(gè)業(yè)務(wù)邏輯方法沒(méi)有顯式的對(duì)持久化ItemDao接口產(chǎn)生依賴(lài),所以要放在Item中。請(qǐng)注意,如果脫離了Hibernate這個(gè)持久化框架,Item這個(gè)domain
object是可以進(jìn)行單元測(cè)試的,他不依賴(lài)于Hibernate的持久化機(jī)制。它是一個(gè)獨(dú)立的,可移植的,完整的,自包含的域?qū)ο?/span>。
而loadItemById和findAll這兩個(gè)業(yè)務(wù)邏輯方法是必須顯式的對(duì)持久化ItemDao接口產(chǎn)生依賴(lài),否則這個(gè)業(yè)務(wù)邏輯就無(wú)法完成。如果你要把這兩個(gè)方法放在Item中,那么Item就無(wú)法脫離Hibernate框架,無(wú)法在Hibernate框架之外獨(dú)立存在。
?
?
第三種模型印象中好像是firebody或者是Archie提出的(也有可能不是,記不清楚了),簡(jiǎn)單的來(lái)說(shuō),這種模型就是把第二種模型的domain
object和business object合二為一了。所以ItemManager就不需要了,在這種模型下面,只有三個(gè)類(lèi),他們分別是:
Item:包含了實(shí)體類(lèi)信息,也包含了所有的業(yè)務(wù)邏輯
ItemDao:持久化DAO接口類(lèi)
ItemDaoHibernateImpl:DAO接口的實(shí)現(xiàn)類(lèi)
由于ItemDao和ItemDaoHibernateImpl和上面完全相同,就省略了。
|
java代碼:?
|
|
public
class Item implementsSerializable{
? ? //? 所有的屬性和getter/setter方法都省略
? ?privatestatic ItemDao itemDao;
? ? publicvoid
setItemDao(ItemDao itemDao){this.itemDao = itemDao;}
? ?
? ? publicstatic Item
loadItemById(Long id){
? ? ? ? return(Item) itemDao.loadItemById(id);
? ? }
? ? publicstaticCollection findAll(){
? ? ? ? return(List) itemDao.findAll();
? ? }
? ? public Bid placeBid(User bidder, MonetaryAmount bidAmount,
? ?
? ? ? ? ? ? ? ? Bid currentMaxBid, Bid currentMinBid)
? ? throws BusinessException
{
? ?
? ? ? ? // Check highest bid (can also be a different
Strategy (pattern))
? ? ? ? if(currentMaxBid != null &&
currentMaxBid.getAmount().compareTo(bidAmount) > 0){
? ? ? ? ? ? ? ? throw new
BusinessException("Bid too low.");
? ? ? ? }
? ? ? ?
? ? ? ? // Auction is active
? ? ? ? if( !state.equals(ItemState.ACTIVE))
? ? ? ? ? ? ? ? throw new
BusinessException("Auction is not active yet.");
? ? ? ?
? ? ? ? // Auction still valid
? ? ? ? if( this.getEndDate().before(newDate()))
? ? ? ? ? ? ? ? throw new
BusinessException("Can't place new bid, auction already
ended.");
? ? ? ?
? ? ? ?
// Create new Bid
? ? ? ? Bid
newBid = new
Bid(bidAmount, this, bidder);
? ? ? ?
? ? ? ? // Place bid for this Item
? ? ? ?
this.addBid(newBid);
? ? ? ? itemDao.update(this);?
? ? //? 調(diào)用DAO進(jìn)行顯式持久化
? ? ? ?
return newBid;
? ? }
}
|
在這種模型中,所有的業(yè)務(wù)邏輯全部都在Item中,事務(wù)管理也在Item中實(shí)現(xiàn)。
?
?
在上面三種模型之外,還有很多這三種模型的變種,例如partech的模型就是把第二種模型中的DAO和
Manager三個(gè)類(lèi)合并為一個(gè)類(lèi)后形成的模型;例如frain....(id很長(zhǎng)記不住)的模型就是把第三種模型的三個(gè)類(lèi)完全合并為一個(gè)單類(lèi)后形成的模型;例如Archie是把第三種模型的Item又分出來(lái)一些純數(shù)據(jù)類(lèi)(可能是,不確定)形成的一個(gè)模型。
但是不管怎么變,基本模型歸納起來(lái)就是上面的三種模型,下面分別簡(jiǎn)單評(píng)價(jià)一下:
第一種模型絕大多數(shù)人都反對(duì),因此反對(duì)理由我也不多講了。但遺憾的是,我觀察到的實(shí)際情形是,很多使用Hibernate的公司最后都是這種模型,這里面有很大的原因是很多公司的技術(shù)水平?jīng)]有達(dá)到這種層次,所以導(dǎo)致了這種貧血模型的出現(xiàn)。從這一點(diǎn)來(lái)說(shuō),Martin
Fowler的批評(píng)聲音不是太響了,而是太弱了,還需要再繼續(xù)吶喊。
第二種模型就是Martin
Fowler一直主張的模型,實(shí)際上也是我一直在實(shí)際項(xiàng)目中采用這種模型。我沒(méi)有看過(guò)Martin的POEAA,之所以能夠自己摸索到這種模型,也是因?yàn)閺?2年我已經(jīng)開(kāi)始思考這個(gè)問(wèn)題并且尋求解決方案了,但是當(dāng)時(shí)沒(méi)有看到Hibernate,那時(shí)候做的一個(gè)小型項(xiàng)目我已經(jīng)按照這種模型來(lái)做了,但是由于沒(méi)有O/R
Mapping的支持,寫(xiě)到后來(lái)又不得不全部改成貧血的domain
object,項(xiàng)目做完以后再繼續(xù)找,隨后就發(fā)現(xiàn)了Hibernate。當(dāng)然,現(xiàn)在很多人一開(kāi)始就是用Hibernate做項(xiàng)目,沒(méi)有經(jīng)歷過(guò)我經(jīng)歷的那個(gè)階段。
不過(guò)我覺(jué)得這種模型仍然不夠完美,因?yàn)槟氵€是需要一個(gè)業(yè)務(wù)邏輯層來(lái)封裝所有的domain
logic,這顯得非常羅嗦,并且業(yè)務(wù)邏輯對(duì)象的接口也不夠穩(wěn)定。如果不考慮業(yè)務(wù)邏輯對(duì)象的重用性的話(業(yè)務(wù)邏輯對(duì)象的可重用性也不可能好),很多人干脆就去掉了xxxManager這一層,在Web層的Action代碼直接調(diào)用xxxDao,同時(shí)容器事務(wù)管理配置到Action這一層上來(lái)。
Hibernate的caveatemptor就是這樣架構(gòu)的一個(gè)典型應(yīng)用。
第三種模型是我很反對(duì)的一種模型,這種模型下面,Domain
Object和DAO形成了雙向依賴(lài)關(guān)系,無(wú)法脫離框架測(cè)試,并且業(yè)務(wù)邏輯層的服務(wù)也和持久層對(duì)象的狀態(tài)耦合到了一起,會(huì)造成程序的高度的復(fù)雜性,很差的靈活性和糟糕的可維護(hù)性。也許將來(lái)技術(shù)進(jìn)步導(dǎo)致的O/R
Mapping管理下的domain object發(fā)展到足夠的動(dòng)態(tài)持久透明化的話,這種模型才會(huì)成為一個(gè)理想的選擇。就像O/R
Mapping的流行使得第二種模型成為了可能(O/R Mapping流行以前,我們只能用第一種模型,第二種模型那時(shí)候是不現(xiàn)實(shí)的)。
?
?
既然大家都統(tǒng)一了觀點(diǎn),那么就有了一個(gè)很好的討論問(wèn)題的基礎(chǔ)了。Martin Fowler的Domain
Model,或者說(shuō)我們的第二種模型難道是完美無(wú)缺的嗎?當(dāng)然不是,接下來(lái)我就要分析一下它的不足,以及可能的解決辦法,而這些都來(lái)源于我個(gè)人的實(shí)踐探索。
在第二種模型中,我們可以清楚的把這4個(gè)類(lèi)分為三層:
1、實(shí)體類(lèi)層,即Item,帶有domain logic的domain
object
2、DAO層,即ItemDao和ItemDaoHibernateImpl,抽象持久化操作的接口和實(shí)現(xiàn)類(lèi)
3、業(yè)務(wù)邏輯層,即ItemManager,接受容器事務(wù)控制,向Web層提供統(tǒng)一的服務(wù)調(diào)用
在這三層中我們大家可以看到,domain
object和DAO都是非常穩(wěn)定的層,其實(shí)原因也很簡(jiǎn)單,因?yàn)閐omain object是映射數(shù)據(jù)庫(kù)字段的,數(shù)據(jù)庫(kù)字段不會(huì)頻繁變動(dòng),所以domain
object也相對(duì)穩(wěn)定,而面向數(shù)據(jù)庫(kù)持久化編程的DAO層也不過(guò)就是CRUD而已,不會(huì)有更多的花樣,所以也很穩(wěn)定。
問(wèn)題就在于這個(gè)充當(dāng)business workflow facade的業(yè)務(wù)邏輯對(duì)象,它的變動(dòng)是相當(dāng)頻繁的。業(yè)務(wù)邏輯對(duì)象通常都是無(wú)狀態(tài)的、受事務(wù)控制的、Singleton類(lèi),我們可以考察一下業(yè)務(wù)邏輯對(duì)象都有哪幾類(lèi)業(yè)務(wù)邏輯方法:
第一類(lèi):DAO接口方法的代理,就是上面例子中的loadItemById方法和findAll方法。
ItemManager之所以要代理這種類(lèi),目的有兩個(gè):向Web層提供統(tǒng)一的服務(wù)調(diào)用入口點(diǎn)和給持久化方法增加事務(wù)控制功能。這兩點(diǎn)都很容易理解,你不能既給Web層程序員提供xxxManager,也給他提供xxxDao,所以你需要用xxxManager封裝xxxDao,在這里,充當(dāng)了一個(gè)簡(jiǎn)單代理功能;而事務(wù)控制也是持久化方法必須的,事務(wù)可能需要跨越多個(gè)DAO方法調(diào)用,所以必須放在業(yè)務(wù)邏輯層,而不能放在DAO層。
但是必須看到,對(duì)于一個(gè)典型的web應(yīng)用來(lái)說(shuō),絕大多數(shù)的業(yè)務(wù)邏輯都是簡(jiǎn)單的CRUD邏輯,所以這種情況下,針對(duì)每個(gè)DAO方法,xxxManager都需要提供一個(gè)對(duì)應(yīng)的封裝方法,這不但是非常枯燥的,也是令人感覺(jué)非常不好的。
第二類(lèi):domain
logic的方法代理。就是上面例子中placeBid方法。雖然Item已經(jīng)有了placeBid方法,但是ItemManager仍然需要封裝一下Item的placeBid,然后再提供一個(gè)簡(jiǎn)單封裝之后的代理方法。
這和第一種情況類(lèi)似,其原因也一樣,也是為了給Web層提供一個(gè)統(tǒng)一的服務(wù)調(diào)用入口點(diǎn)和給隱式的持久化動(dòng)作提供事務(wù)控制。
同樣,和第一種情況一樣,針對(duì)每個(gè)domain logic方法,xxxManager都需要提供一個(gè)對(duì)應(yīng)的封裝方法,同樣是枯燥的,令人不爽的。
第三類(lèi):需要多個(gè)domain object和DAO參與協(xié)作的business
workflow。這種情況是業(yè)務(wù)邏輯對(duì)象真正應(yīng)該完成的職責(zé)。
在這個(gè)簡(jiǎn)單的例子中,沒(méi)有涉及到這種情況,不過(guò)大家都可以想像的出來(lái)這種應(yīng)用場(chǎng)景,因此不必舉例說(shuō)明了。
通過(guò)上面的分析可以看出,只有第三類(lèi)業(yè)務(wù)邏輯方法才是業(yè)務(wù)邏輯對(duì)象真正應(yīng)該承擔(dān)的職責(zé),而前兩類(lèi)業(yè)務(wù)邏輯方法都是“無(wú)奈之舉”,不得不為之的事情,不但枯燥,而且令人沮喪。
分析完了業(yè)務(wù)邏輯對(duì)象,我們?cè)倩仡^看一下domain object,我們要仔細(xì)考察一下domain
logic的話,會(huì)發(fā)現(xiàn)domain logic也分為兩類(lèi):
第一類(lèi):需要持久層框架隱式的實(shí)現(xiàn)透明持久化的domain
logic,例如Item的placeBid方法中的這一句:
|
java代碼:?
|
|
this.getBids().add(newBid);
|
上面已經(jīng)著重提到,雖然這僅僅只是一個(gè)Java集合的添加新元素的操作,但是實(shí)際上通過(guò)事務(wù)的控制,會(huì)潛在的觸發(fā)兩條SQL:一條是insert一條記錄到bid表,一條是更新item表相應(yīng)的記錄。如果我們讓Item脫離Hibernate進(jìn)行單元測(cè)試,它就是一個(gè)單純的Java集合操作,如果我們把他加入到Hibernate框架中,他就會(huì)潛在的觸發(fā)兩條SQL,這就是隱式的依賴(lài)于持久化的domain logic。
特別請(qǐng)注意的一點(diǎn)是:在沒(méi)有Hibernate/JDO這類(lèi)可以實(shí)現(xiàn)“透明的持久化”工具出現(xiàn)之前,這類(lèi)domain logic是無(wú)法實(shí)現(xiàn)的。
對(duì)于這一類(lèi)domain logic,業(yè)務(wù)邏輯對(duì)象必須提供相應(yīng)的封裝方法,以實(shí)現(xiàn)事務(wù)控制。
第二類(lèi):完全不依賴(lài)持久化的domain logic,例如readonly例子中的Topic,如下:
|
java代碼:?
|
|
class Topic {
? ? boolean
isAllowReply(){
? ? ? ? Calendar dueDate =
Calendar.getInstance();
? ? ? ? dueDate.setTime(lastUpdatedTime);
? ? ? ? dueDate.add(Calendar.DATE, forum.timeToLive);
? ?
? ? ? ? Date now = newDate();
? ? ? ? return
now.after(dueDate.getTime());
? ? }
}
|
注意這個(gè)isAllowReply方法,他和持久化完全不發(fā)生一丁點(diǎn)關(guān)系。在實(shí)際的開(kāi)發(fā)中,我們同樣會(huì)遇到很多這種不需要持久化的業(yè)務(wù)邏輯(主要發(fā)生在日期運(yùn)算、數(shù)值運(yùn)算和枚舉運(yùn)算方面),這種domain
logic不管脫離不脫離所在的框架,它的行為都是一致的。對(duì)于這種domain
logic,業(yè)務(wù)邏輯層并不需要提供封裝方法,它可以適用于任何場(chǎng)合。
原文地址:
http://www.cnblogs.com/idior/archive/2005/07/04/186086.html近日?有關(guān)o/r?m的討論突然多了起來(lái).?在這里覺(jué)得有必要澄清一些概念,?免的大家討論來(lái)討論去,?才發(fā)現(xiàn)最根本的理解有問(wèn)題.
1.?何謂實(shí)體?
實(shí)體(類(lèi)似于j2ee中的Entity?Bean)通常指一個(gè)承載數(shù)據(jù)的對(duì)象,?但是注意它也是可以有行為的!?只不過(guò)它的行為一般只操作自身的數(shù)據(jù).?比如下面這個(gè)例子:
class?Person
{
??string?firstName;
??string?lastName;
??public?void?GetName()
??{
?????return??lastName+firstName;
??}???
}
GetName就是它的一個(gè)行為.
2?何謂對(duì)象?
對(duì)象最重要的特性在于它擁有行為.?僅僅擁有數(shù)據(jù),你可以稱(chēng)它為對(duì)象,?但是它卻失去它最重要的靈魂.?
class?Person
{
??string?firstName;
??string?lastName;
??Role?role;
??int?baseWage;
??public?void?GetSalary()
??{
?????return?baseWage*role.GetFactory();
??}???
}
這樣需要和別的對(duì)象(不是Value?Object)打交道的對(duì)象,我就不再稱(chēng)其為實(shí)體.?領(lǐng)域模型就是指由這些具有業(yè)務(wù)邏輯的對(duì)象構(gòu)成的模型.
3.?E/R?M?or?O/R?M?!!
仔細(xì)想想我們?yōu)槭裁葱枰猳/r?m,無(wú)非是想利用oo的多態(tài)來(lái)處理復(fù)雜的業(yè)務(wù)邏輯,?而不是靠一堆的if?else.?
而現(xiàn)在在很多人的手上o/r?m全變成了e/r?m.他們不考慮對(duì)象的行為,?而全關(guān)注于如何保存數(shù)據(jù).這樣也難怪他們會(huì)產(chǎn)生將CRUD這些操作放入對(duì)象中的念頭.?如果你不能深刻理解oo,?那么我不推薦你使用o/r?m,?Table?Gateway,?Row?Gateway才是你想要的東西.
作為一個(gè)O/R?M框架,很重要的一點(diǎn)就是實(shí)現(xiàn)映射的透明性(Transparent),比較顯著的特點(diǎn)就是在代碼中我們是看不到SQL語(yǔ)句的(框架自動(dòng)生成了)。這里所指的O/R?M就是類(lèi)似于此的框架,
4.?POEAA中的相關(guān)概念
??很多次發(fā)現(xiàn)有人錯(cuò)用其中的概念,?這里順便總結(jié)一下:
??1.?Table?Gateway
????以表為單位的實(shí)體,基本沒(méi)有行為,只有CRUD操作.
??2.?Row?Gateway
????以行為單位的實(shí)體,基本沒(méi)有行為,只有CRUD操作.
??3.?Active?Record
????以行為單位的實(shí)體,擁有一些基本的操作自身數(shù)據(jù)的行為(如上例中的GetName),同時(shí)包含有CRUD操作.
其實(shí)Active?Record最符合某些簡(jiǎn)單的需求,?接近于E/R?m.
通常也有很多人把它當(dāng)作O/R?m.不過(guò)需要注意的是Active?Record中是充滿(mǎn)了SQL語(yǔ)句的(不像orm的SQL透明),?所以有人想起來(lái)利用O/R?m來(lái)實(shí)現(xiàn)"Active?Record",?雖然在他們眼里看起來(lái)很方便,?其實(shí)根本就是返祖.
用CodeGenerator來(lái)實(shí)現(xiàn)Active?Record也許是一個(gè)比較好的方法.
??4.?Data?Mapper
這才是真正的O/R?m,Hibernate等等工具的目標(biāo).
5.O/R?M需要關(guān)注的地方?(希望大家?guī)兔ν晟埔幌?
?1.?關(guān)聯(lián),?O/R?M是如何管理類(lèi)之間的關(guān)聯(lián).當(dāng)然這不僅于o/r?m有關(guān)與設(shè)計(jì)者的設(shè)計(jì)水平也有很大關(guān)系.
?2.?O/R?M對(duì)繼承關(guān)系的處理.
?3.?O/R?M對(duì)事務(wù)的支持.
?4.?O/R?M對(duì)查詢(xún)的支持.
?
以上觀點(diǎn)僅屬個(gè)人意見(jiàn),?不過(guò)在大家討論有關(guān)O/R?m之前,?希望先就一些基本概念達(dá)成共識(shí),?不然討論下去會(huì)越離越遠(yuǎn).?
(建議:?如果對(duì)oo以及dp沒(méi)有一定程度的了解,?最好別使用o/r?m,?dataset?加上codesmith或許是更好的選擇)
from http://www.code365.com/web/122/Article/17927.Asp
Thomas Bayes,一位偉大的數(shù)學(xué)大師,他的理論照亮了今天的計(jì)算領(lǐng)域,和他的同事們不同:他認(rèn)為上帝的存在可以通過(guò)方程式證明,他最重要的作品被別人發(fā)行,而他已經(jīng)去世241年了。
18世紀(jì)牧師們關(guān)于概率的理論成為應(yīng)用發(fā)展的數(shù)學(xué)基礎(chǔ)的一部分。
搜索巨人Google和Autonomy,一家出售信息恢復(fù)工具的公司,都使用了貝葉斯定理(Bayesian
principles)為數(shù)據(jù)搜索提供近似的(但是技術(shù)上不確切)結(jié)果。研究人員還使用貝葉斯模型來(lái)判斷癥狀和疾病之間的相互關(guān)系,創(chuàng)建個(gè)人機(jī)器人,開(kāi)發(fā)
能夠根據(jù)數(shù)據(jù)和經(jīng)驗(yàn)來(lái)決定行動(dòng)的人工智能設(shè)備。
 雖然聽(tīng)起來(lái)很深?yuàn)W,而這個(gè)原理的意思--大致說(shuō)起來(lái)--卻很簡(jiǎn)單:某件事情發(fā)生的概率大致可以由它過(guò)去發(fā)生的頻率近似地估計(jì)出來(lái)。研究人員把這個(gè)原理應(yīng)用在每件事上,從基因研究到過(guò)濾電子郵件。
雖然聽(tīng)起來(lái)很深?yuàn)W,而這個(gè)原理的意思--大致說(shuō)起來(lái)--卻很簡(jiǎn)單:某件事情發(fā)生的概率大致可以由它過(guò)去發(fā)生的頻率近似地估計(jì)出來(lái)。研究人員把這個(gè)原理應(yīng)用在每件事上,從基因研究到過(guò)濾電子郵件。
在明尼蘇達(dá)州大學(xué)的網(wǎng)站上能夠找到一份詳細(xì)的數(shù)學(xué)概要。而在Gametheory.net上的一個(gè)Bayes Rule Applet程序讓你能夠回答諸如“如果你測(cè)試某種疾病,有多大風(fēng)險(xiǎn)”之類(lèi)的問(wèn)題。
貝葉斯理論的一個(gè)出名的倡導(dǎo)者就是微軟。該公司把概率用于它的Notification Platform。該技術(shù)將會(huì)被內(nèi)置到微軟未來(lái)的軟件中,而且讓計(jì)算機(jī)和蜂窩電話能夠自動(dòng)地過(guò)濾信息,不需要用戶(hù)幫助,自動(dòng)計(jì)劃會(huì)議并且和其他人聯(lián)系。
如果成功的話,該技術(shù)將會(huì)導(dǎo)致“context server”--一種電子管家的出現(xiàn),它能夠解釋人的日常生活習(xí)慣并在不斷變換的環(huán)境中組織他們的生活。
“Bayes的研究被用于決定我應(yīng)該怎樣最好地分配計(jì)算和帶寬,” Eric Horvitz表示,他是微軟研究部門(mén)Adaptive
Systems & Interaction
Group的高級(jí)研究員和分組管理者。“我個(gè)人相信在這個(gè)不確定的世界里,你不能夠知道每件事,而概率論是任何智能的基礎(chǔ)。”
到今年年底,Intel也將發(fā)布它自己的基于貝葉斯理論的工具包。一個(gè)關(guān)于照相機(jī)的實(shí)驗(yàn)警告醫(yī)生說(shuō)病人可能很快遭受痛苦。在本周晚些時(shí)候在該公司的Developer Forum(開(kāi)發(fā)者論壇)上將討論這種發(fā)展。
雖然它在今天很流行,Bayes的理論并不是一直被廣泛接受的:就在10年前,Bayes研究人員還在他們的專(zhuān)業(yè)上躊躇不前。但是其后,改進(jìn)的數(shù)學(xué)模型,更快的計(jì)算機(jī)和實(shí)驗(yàn)的有效結(jié)果增加了這種學(xué)派新的可信程度。
“問(wèn)題之一是它被過(guò)度宣傳了,” Intel微處理器實(shí)驗(yàn)室的應(yīng)用軟件和技術(shù)管理經(jīng)理Omid Moghadam表示。“事實(shí)上,能夠處理任何事情的能力并不存在。真正的執(zhí)行在過(guò)去的10年里就發(fā)生了。”
Bayes啞元
Bayes的理論可以粗略地被簡(jiǎn)述成一條原則:為了預(yù)見(jiàn)未來(lái),必須要看看過(guò)去。Bayes的理論表示未來(lái)某件事情發(fā)生的概率可以通過(guò)計(jì)算它過(guò)去發(fā)生的頻率來(lái)估計(jì)。一個(gè)彈起的硬幣正面朝上的概率是多少?實(shí)驗(yàn)數(shù)據(jù)表明這個(gè)值是50%。
 “Bayes表示從本質(zhì)上說(shuō),每件事都有不確定性,你有不同的概率類(lèi)型,”斯坦佛的管理科學(xué)和工程系(Department of Management Science and Engineering at Stanford)的教授Ron Howard表示。
“Bayes表示從本質(zhì)上說(shuō),每件事都有不確定性,你有不同的概率類(lèi)型,”斯坦佛的管理科學(xué)和工程系(Department of Management Science and Engineering at Stanford)的教授Ron Howard表示。
例如,假設(shè)不是硬幣,一名研究人員把塑料圖釘往上拋,想要看看它釘頭朝上落地的概率有多大,或者有多少可能性是側(cè)面著地,而釘子是指向什么方向的。形狀,成型過(guò)程中的誤差,重量分布和其他的因素都會(huì)影響該結(jié)果。
Bayes技術(shù)的吸引力在于它的簡(jiǎn)單性。預(yù)測(cè)完全取決于收集到的數(shù)據(jù)--獲得的數(shù)據(jù)越多,結(jié)果就越好。另一個(gè)優(yōu)點(diǎn)在于Bayes模型能夠自我糾正,也就是說(shuō)數(shù)據(jù)變化了,結(jié)果也就跟著變化。
概率論的思想改變了人們和計(jì)算機(jī)互動(dòng)的方式。“這種想法是計(jì)算機(jī)能夠更象一個(gè)幫助者而不僅僅是一個(gè)終端設(shè)備,” Peter Norvig表示。他是Google的安全質(zhì)量總監(jiān)。他說(shuō)“你在尋找的是一些指導(dǎo),而不是一個(gè)標(biāo)準(zhǔn)答案。”
從這種轉(zhuǎn)變中,研究獲益非淺。幾年前,所謂的Boolean搜索引擎的一般使用需要把搜索按照“if, and, or but”的語(yǔ)法進(jìn)行提交,然后去尋找匹配的詞。現(xiàn)在的搜索引擎采用了復(fù)雜的運(yùn)算法則來(lái)搜索數(shù)據(jù)庫(kù),并找出可能的匹配。
如同圖釘?shù)哪莻€(gè)例子顯示的那樣,復(fù)雜性和對(duì)于更多數(shù)據(jù)的需要可能很快增長(zhǎng)。由于功能強(qiáng)大的計(jì)算機(jī)的出現(xiàn),對(duì)于把好的猜測(cè)轉(zhuǎn)變成近似的輸出所必須的結(jié)果進(jìn)行控制成為可能。
更重要的是,UCLA的Judea Pearl這樣的研究人員研究出如何讓Bayes模型能夠更好地追蹤不同的現(xiàn)象之間條件關(guān)系的方法,這樣能夠極大地減少計(jì)算量。
例如,對(duì)于人口進(jìn)行大規(guī)模的關(guān)于肺癌成因的調(diào)查可能會(huì)發(fā)現(xiàn)它是一種不太廣泛的疾病,但是如果局限在吸煙者范圍內(nèi)進(jìn)行調(diào)查就可能會(huì)發(fā)現(xiàn)一些關(guān)聯(lián)性。對(duì)于肺癌患者進(jìn)行檢查能夠幫助調(diào)查清楚習(xí)慣和這種疾病之間的關(guān)系。
 “每一個(gè)單獨(dú)的屬性或者征兆都可能取決于很多不同的事情,但是直接決定它的卻是為數(shù)不多的事情,”斯坦佛計(jì)算機(jī)科學(xué)系(computer
science department at Stanford)的助理教授Daphne
Koller表示。“在過(guò)去的15年左右的時(shí)間里,人們?cè)诠ぞ叻矫孢M(jìn)行了改革,這讓你能夠描繪出大量人群的情況。”
“每一個(gè)單獨(dú)的屬性或者征兆都可能取決于很多不同的事情,但是直接決定它的卻是為數(shù)不多的事情,”斯坦佛計(jì)算機(jī)科學(xué)系(computer
science department at Stanford)的助理教授Daphne
Koller表示。“在過(guò)去的15年左右的時(shí)間里,人們?cè)诠ぞ叻矫孢M(jìn)行了改革,這讓你能夠描繪出大量人群的情況。”
和其他一些項(xiàng)目一樣,Koller是使用概率論技術(shù)來(lái)更好地把病癥和疾病聯(lián)系起來(lái),并把遺傳基因和特定的細(xì)胞現(xiàn)象聯(lián)系起來(lái)。
記錄演講
一項(xiàng)相關(guān)的技術(shù),名為Hidden Markov模型,讓概率能夠預(yù)測(cè)次序。例如,一個(gè)演講識(shí)別應(yīng)用知道經(jīng)常在“q”之后的字母是“u”。除了這些,該軟件還能夠計(jì)算“Qagga”(一種滅絕了的斑馬的名稱(chēng))一詞出現(xiàn)的概率。
概率技術(shù)已經(jīng)內(nèi)置在微軟的產(chǎn)品中了。Outlook Mobile
Manage是一個(gè)能夠決定什么時(shí)候往移動(dòng)設(shè)備上發(fā)出一封內(nèi)勤的電子郵的軟件。它是從Priorities發(fā)展而來(lái)的,Priorities是微軟在
1998年公布的一個(gè)實(shí)驗(yàn)系統(tǒng)。Windows XP的故障檢修引擎也依賴(lài)于概率計(jì)算。
隨著該公司的Notification Platform開(kāi)始內(nèi)置在產(chǎn)品中,在未來(lái)的一年中會(huì)有更多的應(yīng)用軟件發(fā)布,微軟的Horvitz這樣表示。
Notification
Platform的一個(gè)重要組成部分名為Coordinate,它從個(gè)人日歷,鍵盤(pán),傳感器照相機(jī)以及其他來(lái)源收集數(shù)據(jù),來(lái)了解某個(gè)人生活和習(xí)慣。收集的
數(shù)據(jù)可能包括到達(dá)的時(shí)間,工作時(shí)間和午餐的時(shí)間長(zhǎng)度,哪種類(lèi)型的電話或電子郵件被保存,而哪些信息被刪除,在某天的特定時(shí)間里鍵盤(pán)被使用的頻率,等等。
這些數(shù)據(jù)可以被用來(lái)管理信息流和使用者收到的其他信息。例如,如果一位經(jīng)理在下午2:40發(fā)送了一封電子郵件給一名員工,
Coordinate可以檢查該員工的日歷程序,然后發(fā)現(xiàn)他在下午2:00有一個(gè)會(huì)議。該程序還可以掃描關(guān)于該員工習(xí)慣的數(shù)據(jù),然后發(fā)現(xiàn)該員工通常會(huì)在有
會(huì)議之后大約一個(gè)小時(shí)才重新使用鍵盤(pán)。該程序可能還能夠發(fā)現(xiàn)該名員工通常會(huì)在5分鐘之內(nèi)回復(fù)該經(jīng)理的電子郵件。根據(jù)上面這些數(shù)據(jù),該軟件能夠估計(jì)出該員工
可能至少在20分鐘之內(nèi)不可能回復(fù)該電子郵件,該軟件可能會(huì)把這條信息發(fā)送到該員工的手提電話上。同時(shí),該軟件可能會(huì)決定不把別人的電子郵件也轉(zhuǎn)發(fā)出去。
“我們正在平衡以打攪你為代價(jià)所獲得信息的價(jià)值,” Horvitz表示。使用這個(gè)軟件,他堅(jiān)持道,“能夠讓更多的人跟上事情的發(fā)展,而不被大量的信息所淹沒(méi)。”
Horvitz補(bǔ)充道,隱私和對(duì)于這些功能的用戶(hù)控制是確定的。呼叫者并不知道為什么一條信息可能會(huì)被優(yōu)先或推遲處理。
微軟還把Bayes模型使用在其他的一些產(chǎn)品上,包括DeepListener 以及Quartet (語(yǔ)音激活),SmartOOF 以及TimeWave (聯(lián)系控制)。消費(fèi)者多媒體軟件也獲益非淺,Horvitz表示。
Bayes技術(shù)不僅僅被應(yīng)用在PC領(lǐng)域。在University of
Rochester,研究人員發(fā)現(xiàn)一個(gè)人的步伐可以在一步前發(fā)生改變。雖然這種改變對(duì)于人類(lèi)來(lái)說(shuō)太過(guò)于細(xì)微,一臺(tái)和電腦連接在一起的照相機(jī)可以捕捉并跟蹤
這種動(dòng)作。如果行走異常出現(xiàn),計(jì)算機(jī)就能夠發(fā)出警報(bào)。
一個(gè)實(shí)驗(yàn)用的安全照相機(jī)采用了同樣的原理:大部分到達(dá)機(jī)場(chǎng)的人都會(huì)在停車(chē)以后直接走向目的地,所以如果有人停了車(chē),然后走向另一輛車(chē)就不太正常,因此就可能引發(fā)警報(bào)。今年秋天一個(gè)創(chuàng)建Bayes模型和技術(shù)信息的基本引擎將會(huì)公布在Intel的開(kāi)發(fā)者網(wǎng)站上。
理論沖突
雖然該技術(shù)聽(tīng)起來(lái)簡(jiǎn)單易懂,關(guān)于它的計(jì)算可能卻比較慢。Horvitz回憶說(shuō)他是斯坦佛20世紀(jì)80年代僅有的兩個(gè)概率和人工智能的畢業(yè)生之一。其他所有的人學(xué)習(xí)的是邏輯系統(tǒng),采用的是“if and then”的模式和世界互動(dòng)。
 “概率論那時(shí)候不流行,” Horvitz表示。但是當(dāng)邏輯系統(tǒng)不能夠預(yù)測(cè)所有的意外情況時(shí),潮流發(fā)生了轉(zhuǎn)變。
“概率論那時(shí)候不流行,” Horvitz表示。但是當(dāng)邏輯系統(tǒng)不能夠預(yù)測(cè)所有的意外情況時(shí),潮流發(fā)生了轉(zhuǎn)變。
很多研究人員開(kāi)始承認(rèn)人類(lèi)的決策過(guò)程比原來(lái)想象的要神秘的多。“在人工智能領(lǐng)域存在著文化偏見(jiàn),” Koller表示。“人們現(xiàn)在承認(rèn)他們并不知道他們的腦子是如何工作的。”
即便在他的時(shí)代,Bayes發(fā)現(xiàn)他自己置身于主流之外。他于1702年出生于倫敦,后來(lái)他成為了一名Presbyterian
minister。雖然他看到了自己的兩篇論文被發(fā)表了,他的理論很有效,但是《Essay Toward Solving a Problem in
the Doctrine of Chances》卻一直到他死后的第三年,也就是1764年才被發(fā)表。
他的王室成員身份一直是個(gè)謎,直到最近幾年,新發(fā)現(xiàn)的一些信件表明他私下和英格蘭其他一些思想家看法一致。
“就我所知,他從來(lái)沒(méi)有寫(xiě)下貝葉斯定理,” Howard表示。
神學(xué)家Richard Price和法國(guó)的數(shù)學(xué)家Pierre Simon
LaPlace成為了早期的支持者。該理論和后來(lái)George Boole,布爾數(shù)學(xué)之父,的理論背道而馳。George
Boole的理論是基于代數(shù)邏輯的,并最終導(dǎo)致了二進(jìn)制系統(tǒng)的誕生。也是皇室成員之一的Boole死于1864年。
雖然概率的重要性不容置疑,可是關(guān)于它的應(yīng)用的爭(zhēng)論卻沒(méi)有停止過(guò)。批評(píng)者周期性地聲稱(chēng)Bayes模型依賴(lài)于主觀的數(shù)據(jù),而讓人類(lèi)去判斷答案是否正確。而概率論模型沒(méi)有完全解決在人類(lèi)思維過(guò)程中存在的細(xì)微差別的問(wèn)題。
“兒童如何學(xué)習(xí)現(xiàn)在還不是很清楚,”IBM研究部門(mén)的科學(xué)和軟件副總裁 Alfred
Spector這樣表示。他計(jì)劃把統(tǒng)計(jì)學(xué)方法和邏輯系統(tǒng)在他的Combination
Hypothesis之中結(jié)合起來(lái)。“我最初相信是統(tǒng)計(jì)學(xué)的范疇,但是從某方面說(shuō),你將會(huì)發(fā)現(xiàn)不僅僅是統(tǒng)計(jì)學(xué)的問(wèn)題。”
但是,很有可能概率論是基礎(chǔ)。
“這是個(gè)基礎(chǔ),” Horvitz表示。“它被忽略了一段時(shí)間,但是它是推理的基礎(chǔ)。”