將樣本數(shù)據(jù)成功轉(zhuǎn)化為向量表示之后,計(jì)算機(jī)才算開(kāi)始真正意義上的“學(xué)習(xí)”過(guò)程。
再重復(fù)一次,所謂樣本,也叫訓(xùn)練數(shù)據(jù),是由人工進(jìn)行分類處理過(guò)的文檔集合,計(jì)算機(jī)認(rèn)為這些數(shù)據(jù)的分類是絕對(duì)正確的,可以信賴的(但某些方法也有針對(duì)訓(xùn)練數(shù)據(jù)可能有錯(cuò)誤而應(yīng)對(duì)的措施)。接下來(lái)的一步便是由計(jì)算機(jī)來(lái)觀察這些訓(xùn)練數(shù)據(jù)的特點(diǎn),來(lái)猜測(cè)一個(gè)可能的分類規(guī)則(這個(gè)分類規(guī)則也可以叫做分類器,在機(jī)器學(xué)習(xí)的理論著作中也叫做一個(gè)“假設(shè)”,因?yàn)楫吘故菍?duì)真實(shí)分類規(guī)則的一個(gè)猜測(cè)),一旦這個(gè)分類滿足一些條件,我們就認(rèn)為這個(gè)分類規(guī)則大致正確并且足夠好了,便成為訓(xùn)練階段的最終產(chǎn)品——分類器!再遇到新的,計(jì)算機(jī)沒(méi)有見(jiàn)過(guò)的文檔時(shí),便使用這個(gè)分類器來(lái)判斷新文檔的類別。
舉一個(gè)現(xiàn)實(shí)中的例子,人們?cè)u(píng)價(jià)一輛車是否是“好車”的時(shí)候,可以看作一個(gè)分類問(wèn)題。我們也可以把一輛車的所有特征提取出來(lái)轉(zhuǎn)化為向量形式。在這個(gè)問(wèn)題中詞典向量可以為:
D=(價(jià)格,最高時(shí)速,外觀得分,性價(jià)比,稀有程度)
則一輛保時(shí)捷的向量表示就可以寫(xiě)成
vp=(200萬(wàn),320,9.5,3,9)
而一輛豐田花冠則可以寫(xiě)成
vt=(15萬(wàn),220,6.0,8,3)
找不同的人來(lái)評(píng)價(jià)哪輛車算好車,很可能會(huì)得出不同的結(jié)論。務(wù)實(shí)的人認(rèn)為性價(jià)比才是評(píng)判的指標(biāo),他會(huì)認(rèn)為豐田花冠是好車而保時(shí)捷不是;喜歡奢華的有錢(qián)人可能以稀有程度來(lái)評(píng)判,得出相反的結(jié)論;喜歡綜合考量的人很可能把各項(xiàng)指標(biāo)都加權(quán)考慮之后才下結(jié)論。
可見(jiàn),對(duì)同一個(gè)分類問(wèn)題,用同樣的表示形式(同樣的文檔模型),但因?yàn)殛P(guān)注數(shù)據(jù)不同方面的特性而可能得到不同的結(jié)論。這種對(duì)文檔數(shù)據(jù)不同方面?zhèn)戎氐牟煌瑢?dǎo)致了原理和實(shí)現(xiàn)方式都不盡相同的多種方法,每種方法也都對(duì)文本分類這個(gè)問(wèn)題本身作了一些有利于自身的假設(shè)和簡(jiǎn)化,這些假設(shè)又接下來(lái)影響著依據(jù)這些方法而得到的分類器最終的表現(xiàn),可謂環(huán)環(huán)相連,絲絲入扣,冥冥之中自有天意呀(這都什么詞兒……)。
比較常見(jiàn),家喻戶曉,常年被評(píng)為國(guó)家免檢產(chǎn)品(?!)的分類算法有一大堆,什么決策樹(shù),Rocchio,樸素貝葉斯,神經(jīng)網(wǎng)絡(luò),支持向量機(jī),線性最小平方擬合,kNN,遺傳算法,最大熵,Generalized Instance Set等等等等(這張單子還可以繼續(xù)列下去)。在這里只挑幾個(gè)最具代表性的算法侃一侃。
Rocchio算法
Rocchio算法應(yīng)該算是人們思考文本分類問(wèn)題時(shí)最先能想到,也最符合直覺(jué)的解決方法。基本的思路是把一個(gè)類別里的樣本文檔各項(xiàng)取個(gè)平均值(例如把所有“體育”類文檔中詞匯“籃球”出現(xiàn)的次數(shù)取個(gè)平均值,再把“裁判”取個(gè)平均值,依次做下去),可以得到一個(gè)新的向量,形象的稱之為“質(zhì)心”,質(zhì)心就成了這個(gè)類別最具代表性的向量表示。再有新文檔需要判斷的時(shí)候,比較新文檔和質(zhì)心有多么相像(八股點(diǎn)說(shuō),判斷他們之間的距離)就可以確定新文檔屬不屬于這個(gè)類。稍微改進(jìn)一點(diǎn)的Rocchio算法不盡考慮屬于這個(gè)類別的文檔(稱為正樣本),也考慮不屬于這個(gè)類別的文檔數(shù)據(jù)(稱為負(fù)樣本),計(jì)算出來(lái)的質(zhì)心盡量靠近正樣本同時(shí)盡量遠(yuǎn)離負(fù)樣本。Rocchio算法做了兩個(gè)很致命的假設(shè),使得它的性能出奇的差。一是它認(rèn)為一個(gè)類別的文檔僅僅聚集在一個(gè)質(zhì)心的周圍,實(shí)際情況往往不是如此(這樣的數(shù)據(jù)稱為線性不可分的);二是它假設(shè)訓(xùn)練數(shù)據(jù)是絕對(duì)正確的,因?yàn)樗鼪](méi)有任何定量衡量樣本是否含有噪聲的機(jī)制,因而也就對(duì)錯(cuò)誤數(shù)據(jù)毫無(wú)抵抗力。
不過(guò)Rocchio產(chǎn)生的分類器很直觀,很容易被人類理解,算法也簡(jiǎn)單,還是有一定的利用價(jià)值的(做漢奸狀),常常被用來(lái)做科研中比較不同算法優(yōu)劣的基線系統(tǒng)(Base Line)。
樸素貝葉斯算法(Naive Bayes)
貝葉斯算法關(guān)注的是文檔屬于某類別概率。文檔屬于某個(gè)類別的概率等于文檔中每個(gè)詞屬于該類別的概率的綜合表達(dá)式。而每個(gè)詞屬于該類別的概率又在一定程度上可以用這個(gè)詞在該類別訓(xùn)練文檔中出現(xiàn)的次數(shù)(詞頻信息)來(lái)粗略估計(jì),因而使得整個(gè)計(jì)算過(guò)程成為可行的。使用樸素貝葉斯算法時(shí),在訓(xùn)練階段的主要任務(wù)就是估計(jì)這些值。
樸素貝葉斯算法的公式只有一個(gè)
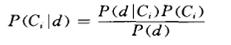
其中P(d| Ci)=P(w1|Ci) P(w2|Ci) …P(wi|Ci) P(w1|Ci) …P(wm|Ci) (式1)
P(wi|Ci)就代表詞匯wi屬于類別Ci的概率。
這其中就蘊(yùn)含著樸素貝葉斯算法最大的兩個(gè)缺陷。
首先,P(d| Ci)之所以能展開(kāi)成(式1)的連乘積形式,就是假設(shè)一篇文章中的各個(gè)詞之間是彼此獨(dú)立的,其中一個(gè)詞的出現(xiàn)絲毫不受另一個(gè)詞的影響(回憶一下概率論中變量彼此獨(dú)立的概念就可以知道),但這顯然不對(duì),即使不是語(yǔ)言學(xué)專家的我們也知道,詞語(yǔ)之間有明顯的所謂“共現(xiàn)”關(guān)系,在不同主題的文章中,可能共現(xiàn)的次數(shù)或頻率有變化,但彼此間絕對(duì)談不上獨(dú)立。
其二,使用某個(gè)詞在某個(gè)類別訓(xùn)練文檔中出現(xiàn)的次數(shù)來(lái)估計(jì)P(wi|Ci)時(shí),只在訓(xùn)練樣本數(shù)量非常多的情況下才比較準(zhǔn)確(考慮扔硬幣的問(wèn)題,得通過(guò)大量觀察才能基本得出正反面出現(xiàn)的概率都是二分之一的結(jié)論,觀察次數(shù)太少時(shí)很可能得到錯(cuò)誤的答案),而需要大量樣本的要求不僅給前期人工分類的工作帶來(lái)更高要求(從而成本上升),在后期由計(jì)算機(jī)處理的時(shí)候也對(duì)存儲(chǔ)和計(jì)算資源提出了更高的要求。
kNN算法則又有所不同,在kNN算法看來(lái),訓(xùn)練樣本就代表了類別的準(zhǔn)確信息(因此此算法產(chǎn)生的分類器也叫做“基于實(shí)例”的分類器),而不管樣本是使用什么特征表示的。其基本思想是在給定新文檔后,計(jì)算新文檔特征向量和訓(xùn)練文檔集中各個(gè)文檔的向量的相似度,得到K篇與該新文檔距離最近最相似的文檔,根據(jù)這K篇文檔所屬的類別判定新文檔所屬的類別(注意這也意味著kNN算法根本沒(méi)有真正意義上的“訓(xùn)練”階段)。這種判斷方法很好的克服了Rocchio算法中無(wú)法處理線性不可分問(wèn)題的缺陷,也很適用于分類標(biāo)準(zhǔn)隨時(shí)會(huì)產(chǎn)生變化的需求(只要?jiǎng)h除舊訓(xùn)練文檔,添加新訓(xùn)練文檔,就改變了分類的準(zhǔn)則)。
kNN唯一的也可以說(shuō)最致命的缺點(diǎn)就是判斷一篇新文檔的類別時(shí),需要把它與現(xiàn)存的所有訓(xùn)練文檔全都比較一遍,這個(gè)計(jì)算代價(jià)并不是每個(gè)系統(tǒng)都能夠承受的(比如我將要構(gòu)建的一個(gè)文本分類系統(tǒng),上萬(wàn)個(gè)類,每個(gè)類即便只有20個(gè)訓(xùn)練樣本,為了判斷一個(gè)新文檔的類別,也要做20萬(wàn)次的向量比較!)。一些基于kNN的改良方法比如Generalized Instance Set就在試圖解決這個(gè)問(wèn)題。
下一節(jié)繼續(xù)講和訓(xùn)練階段有關(guān)的話題,包括概述已知性能最好的SVM算法。明兒見(jiàn)!(北京人兒,呵呵)