譯者前言
本文介紹了IBM JDK 1.2.2到1.4.1 SR1版本垃圾收集原理,虛擬機內部內存分配及管理的機制。根據IBM的說明,本文檔也適合JDK 1.4.2。總體感覺翻譯這篇文檔比Sun HotSpot虛擬機的內存管理機制的那一篇要更加吃力一些。文檔中介紹了很多的細節,也有較多的陌生的詞。在文檔的最后附有中英文詞匯對照表。如果有錯誤之處,希望大家踴躍指出。如果你的英語水平可以的話,建議去讀原文。
了解虛擬機內部內存管理以及垃圾收集的機制,可能有助于你調優虛擬機。另外,翻譯這篇文章主要的原因是IBM JVM 和HotSpot JVM的有很大的區別,基本上是兩套差異較大的思路出來的產品。HotSpot是分代的,IBM JVM是不分的。但是根據IBM的文檔,在1.5以及后續的版本中,提供了分代收集的策略。JRockit可以同時支持分代和不分代的兩種策略。看來大家都在互相取長補短啊。
原文出自
http://www-128.ibm.com/developerworks/java/jdk/diagnosis/142.html
Garbage Collection and Storage Allocation techniques
轉載請注明出處(http://www.tkk7.com/yoda/),謝謝!
1 簡介
本文檔描述從1.2.2到1.4.1 SR1的存儲組件(ST)功能。(譯者注:根據IBM的說明,本文檔也適合JDK 1.4.2)
存儲組件(Storage Component)用來分配堆中的存儲空間,這些存儲空間定義了對象、數組以及類。每個對象在存儲空間中占有一部分存儲,如果從虛擬機活動狀態中存在到這個對象的引用(指針),這個對象就是可到達的;當虛擬機活動狀態不再存在到這個對象的引用,這個對象就被視為垃圾,他占用的存儲空間可以被重新使用。當申請重用發生時,垃圾收集器必須進行一些清理工作,以確保該對象所關聯的監視器能夠被釋放回對應的監視器池中。存儲組件并不是等同對待所有的對象,比如類對象以及線程對象是在堆的一個特殊空間(Pinned Cluster,固化簇)內進行分配的;在追蹤整個堆的時候,引用對象和其派生對象也是被特殊處理的。在4.4章"引用對象"中對于這種特殊情況有詳細的闡述。
1.1 對象分配
對象分配是由對于某個分配接口的調用來驅動的,例如stCacheAlloc, stAllocObject, stAllocArray, stAllocClass。調用這些接口會在堆上分配一塊空間,但是調用時的參數有所不同。stCacheAlloc函數是為小對象的高效分配所設計的,每個線程會預先從堆中申請一塊獨享的空間,叫做線程本地堆(Thread Local Heap),簡稱TLH。小對象在這個空間內直接進行分配。一個新的對象從線程本地堆的底部開始分配,由于無需獲取堆鎖,所以這種分配動作是非常高效的。如果對象較小(當前上限是512字節),那么即使使用stAllocObject和stAllocArray接口,對象也會分配在線程本地堆。
1.2 可到達對象
線程執行棧、類內部的靜態對象以及本地和全局的JNI引用共同構成了虛擬機的活動狀態。虛擬機內部調用的函數會導致在C執行棧上生成一個幀,這些信息用來尋找根對象,從根對象出發來尋找被引用的對象。這個過程會一直重復直到找到全部可到達對象。
1.3 垃圾收集
當堆內存空間不足,導致虛擬機內存分配失敗時,就會發生垃圾收集。垃圾收集的第一步工作就是找到堆中全部的垃圾,這個工作可以由任何線程的內存分配失敗激活,也可以由顯式調用System.gc()函數激活。首先,要獲取垃圾收集所需的全部鎖,這可以保證對于當時擁有臨界鎖的線程不會被掛起。通過執行管理接口(execution manager, XM)來掛起其他線程,以確保對于調用線程,其他線程的掛起狀態是可進入的,這個狀態包括在掛起時刻的從頂到底的執行棧以及寄存器狀態,以用來追蹤對象引用。在此之后,垃圾收集才可以開始工作,包含3個階段:
· 標識
· 清理
· 壓縮(可選的)
1.3.1 標識階段
在標識階段,所有的被虛擬機活動狀態引用,或者靜態的,或者固化字符串以及被JNI引用的對象都被標識。這個動作創建了JVM引用的根對象,這些根對象可能會依次引用其他對象,因此,標識階段的第二部分工作就是從根對象出發,掃描其他被引用對象。這兩步工作產生一個活動對象集合。
分配集合(allocbits)中的每個比特位標識堆中的一個8字節段,一旦分配了一個對象,分配集合中的對應比特位會被標識。垃圾收集器開始追蹤棧時,首先比較指向堆底和堆頂的指針,確保指針指向的是8字節邊界的對象,然后對分配集合中對應的比特位進行標識,表示該指針指向一個活動對象。然后在標識集合(markbits)中對對應的比特位進行標識,表明該對象處于被引用狀態。
最后,垃圾收集器掃描對象的域字段查找被這個對象引用的其他對象,這個掃描過程是準確完成的,因為方法指針存儲在第一個字單元,垃圾收集器能夠知道對象的類型。在對象鏈接時(對象第一個實例創建之前),類裝載器會創建一個偏移集合,這個偏移集合中記錄了對象中引用其他對象的字段偏移位置,垃圾收集器通過訪問這個偏移集合找到對應的域及其引用的其他對象。
1.3.2 清理階段
標識階段之后,在標識集合中包含了堆中所有可到達對象的標志。標識集合必須是分配集合的一個子集,清理階段的工作就是找到這兩個集合之間的差集,也就是在那些已經分配但是不再被引用的對象。
最起初,清理階段就是從堆底開始掃描,依次訪問堆中的每個對象。對象的長度存儲在一個字單元中,對于每個對象,垃圾收集器檢測對應的分配標識位和標識標識位以定位垃圾。
現在,使用bitsweep技術無需掃描整個堆,這樣就避免了頁交換的額外消耗。bitsweep技術直接在標識集合中尋找長的連續的0(未被標識的對象),這段長的連續的0可能表示一段空閑空間。找到這樣的序列之后,垃圾收集器檢測序列開始前的對象的長度,以檢測可以被釋放的空閑空間的大小。
1.3.3 壓縮階段
垃圾收集器將垃圾從堆中移除之后,將剩下的對象向一側壓縮排列,以便移除這些對象之間的空閑空間。由于壓縮動作消耗很大,所以應該盡量避免。在4.3.1章對于如何避免壓縮有詳細的闡述。
壓縮是一個非常復雜的過程,因為句柄已經不再存在于虛擬機中了。如果垃圾收集器移動了某個對象,那么需要修改所有指向這個對象的引用。如果有來自棧的引用,那么就無法確定是這個引用確實是對象引用(有可能是一個浮點數),所以這個對象就不能移動。這種對象臨時固定在他原來的位置,并且在頭信息中使用對應比特位標識。類似的,在JNI操作的過程中,從JNI引用的Java對象也是固化的,無法移動,直到JNI操作結束。利用mptr低三位設置為0,可移動的對象在兩個階段內被壓縮到一起。這3個比特位中一個用來標識對象已經被清理,注意,清理標識位出現在兩個地方:link域(即OLINK_IsSwapped)和mptr (GC_FirstSwapped)。這兩種情況,都會設置最低的比特位(x01)。
在壓縮階段的最后,所有線程通過XM恢復運行。
2 數據區域
2.1 一個對象

圖表 1 一個對象
圖表1是堆中一個對象的布局
· size + flags (大小和標識)
size + flags在32位架構上占4字節,在64位架構上占8字節,主要目的是用來存儲對象的大小。由于對象都是從8字節邊界開始,并且對象大小可以被8整除,最低3個比特位不被使用,垃圾收集器用來作為標識位以標識對象的不同狀態。另外,由于對象大小是有限的,所以最高2個比特位也用來作為標識位(mptr也是8字節邊界的)。
size + flags 中的標識位如下:
§ 第1位有多個用途。在清理階段作為清理標識,在壓縮階段也會用到它。第1位還是多次固化標識位,用來標識該對象被多次固化。在垃圾收集的一個周期,多次固化標識位被清除,用作其他用途,然后恢復
§ 第2位是dosed位。如果從棧或者寄存器有到某個對象的“引用”,就會在dosed位進行標識。這里“引用”是指在本次垃圾收集周期不能移動該對象,因為垃圾收集器無法確定該“引用”是一個真正指向對象的引用還是碰巧只是一個和對象句柄值相等的整數
§ 第3位是固化標識位。固化的對象就是從堆之外有指向這個對象的引用,例如線程和類對象。此類對象無法移動
§ 32位架構的第31位或者64位架構的第63位是鎖(flat lock)競爭位,被鎖管理模塊(locking, LK)使用
§ 32位架構的第32位或者64位架構的第64位是哈希標識位,表示一個對象已經返回了哈希值。因為對象的哈希值就是對象的地址,如果垃圾收集器移動了這個對象,需要維護這個值
· mptr
mptr槽位在32位架構上占4字節,在64位架構上占8字節,mptr是8字節邊界的(譯者注:原文為The mptr slot is grained on an 8-byte boundary, not the size + flags. 不知道如何翻譯才是準確的),功能為以下兩種之一
§ 如果對象不是數組,mptr指向類方法表,垃圾收集器據此找到類信息。通過這種方式,垃圾收集器知道對象是從哪個類實例化的。類的方法表和類本身的信息由類加載器組件(class loader, CL)分配,但是不存儲在堆空間
§ 如果對象是數組,mptr是數組內條目的計數
· locknflags
locknflags槽位在32位架構上占4字節,在64位架構上占8字節,但是只有低4字節被使用。主要作用是用來保存鎖信息。另外還包含3個標識比特位
§ 第2比特位是數組標識。如果對象是數組,則該標識位設置為1,mptr槽位保存數組中對象的個數
§ 第3比特位是哈希和移動標識位,如果這個標識位被設置為1,表明該對象被移動過,可以在對象在移動之前的位置找到其哈希值
§ (譯者注:在圖表1中并未畫出locknflags槽位,原文如此,筆誤?)
· 對象數據
這里是開始記錄對象數據的位置
size + flags, mptr以及locknflags一起稱為對象頭信息
2.2 堆

圖表 2 堆
圖表2是堆的示意圖。堆是虛擬機在初始化時從操作系統申請的一段連續的內存空間。堆底是堆的開始地址,堆頂是堆的結束地址,堆上限是堆中當前使用部分的結束地址。堆上限可以擴展和收縮。-Xmx參數限制了從堆底到堆頂的最大值,如果未設置,默認值如下:
· Xmx
§ Windows: 物理內存的一半,最小16MB,最大2GB-1
§ OS/390 和 AIX: 64MB
§ Linux: 物理內存的一半,最小16MB,最大512MB-1
· Xms
§ Windows, AIX, Linux: 4MB
§ OS/390: 1MB
2.2.1 設置堆大小
對于大多數應用而言,默認的設置即可滿足需求。在運行時,堆會自動擴展到一個穩定的狀態,保證在任何時刻堆中活動對象占堆大小的70%,在這種狀態下,垃圾收集的頻率和暫停時間都是可以接受的。
對于某些應用而言,默認參數可能無法保證應用的良好運行,下面列出可能出現的問題以及應對策略。使用verbosegc可以監控堆的使用情況。
· 在堆到達穩定狀態之前,垃圾收集發生的過于頻繁
使用verbosegc檢測堆到達穩定狀態時的大小,然后設置-Xms參數等于該大小
· 堆已經擴展到最大限制,但是堆占用率仍然高于70%
增加-Xmx的設置,以使得堆能夠擴展到一個能夠保證占用率不高于70%的大小。但是需要注意的是,要保證堆的內存都是從物理內存占用,避免出現頁交換
· 堆占用率在70%,但是垃圾收集發生的頻率過高
修改-Xminf參數。默認是0.3,表示堆要通過擴展保證有30%的空閑空間。例如,設置該參數為0.4,會降低垃圾收集發生的頻率
· 暫停時間過長
嘗試使用-Xgcpolicy:optavgpause參數。在堆的占用比增高的情況下,該參數能夠保證垃圾收集時間的穩定,但是會帶來大約5%的吞吐量的下降,具體視應用而定
另外,還有一些小提示:
· 確保堆不會發生頁交換(即堆內存全部從物理內存中獲取)
· 避免使用finalizer。你不能確保finalizer執行的時機,這樣會帶來一些問題。在verbosegc的輸出中,可以看到是否已經執行了finalizer。如果確實需要使用finalizer,需要注意以下三個關鍵點
§ 不要在finalizer方法中創建新的對象
§ 不要依賴finalizer來釋放一些本地資源
§ 不要在finalizer方法中進行長時間執行的或者阻斷式的動作
· 避免壓縮。verbosegc的輸出中可以顯示是否進行了壓縮動作。通常,壓縮動作是由于大塊內存的分配引發的,所以,要分析應用中對于大塊內存的需求,比如,一個大的數組對象,可以將其拆分成多個小片段
2.3 分配集合和標識集合

圖表 3 堆以及分配集合和標識集合
圖表3是堆、分配集合和標識集合的示意圖。這兩個比特位集合標記了堆中對象的狀態。因為堆中對象都是8字節邊界的,所以每個比特位對應1個8字節段,這兩個比特位集合的大小為堆大小的1/64。
一旦在堆中分配了一個對象,在分配集合中對應對象開始地址的比特位被設置為1。分配集合只是標識了對象被分配,但是無法得知對象是否是活動的。在垃圾收集的標識階段,標識集合中對應的比特位會被設置,以表示對象是活動的。圖表4表示堆中的2個對象,分配集合中對應比特位都被設置為1.
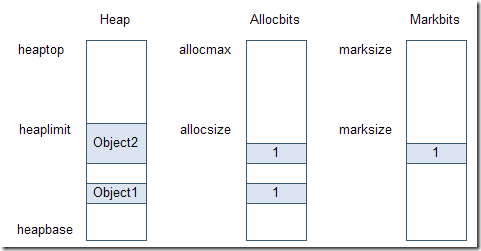
圖表 4 堆中一些對象
在標識階段,Object2是被引用的,Object1是未被引用的,所以在標識集合中對應
Object2的比特位被設置為1,在清理階段,Object1會被垃圾收集。
2.4 系統堆
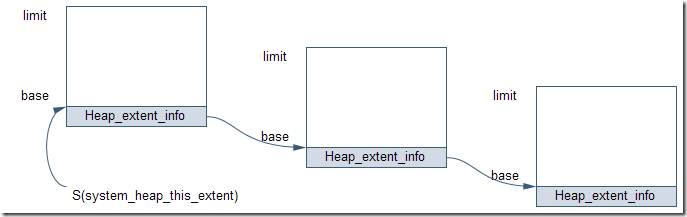
圖表 5 系統堆
系統堆中包含的對象是跨越整個虛擬機生命周期的對象,通常這些對象是系統級的類對象、可共享的中間對象以及應用級對象。垃圾收集器不會收集系統堆中的對象,因為這些對象在整個虛擬機生命周期內都是可達到的,或者是應用需要共享的一些對象。圖表5是系統堆的示意圖。系統堆不是連續的存儲空間,而是由多個存儲段構成的鏈。系統堆的初始大小在32位架構上是128KB,在64位架構上是8MB。如果系統堆被對象充滿,虛擬機會重新分配一塊空間,并且加入到系統堆的鏈表中來。
2.5 空閑鏈表
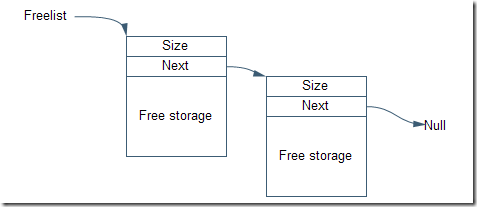
圖表 6 空閑鏈表
圖表6表示空閑鏈表,鏈表的頭是一個全局的指針,指向空閑鏈表的第一個存儲段。空閑鏈表的每個存儲段都有一個大小字段和一個指向下一個空閑存儲段的指針,鏈表的最后一個空閑存儲段的Next為空指針。
posted on 2008-04-22 11:20
YODA 閱讀(3632)
評論(0) 編輯 收藏