
2017年9月7日
原文鏈接:http://www.cnblogs.com/juandx/p/4962089.html
python中對(duì)文件、文件夾(文件操作函數(shù))的操作需要涉及到os模塊和shutil模塊。
得到當(dāng)前工作目錄,即當(dāng)前Python腳本工作的目錄路徑: os.getcwd()
返回指定目錄下的所有文件和目錄名:os.listdir()
函數(shù)用來刪除一個(gè)文件:os.remove()
刪除多個(gè)目錄:os.removedirs(r“c:\python”)
檢驗(yàn)給出的路徑是否是一個(gè)文件:os.path.isfile()
檢驗(yàn)給出的路徑是否是一個(gè)目錄:os.path.isdir()
判斷是否是絕對(duì)路徑:os.path.isabs()
檢驗(yàn)給出的路徑是否真地存:os.path.exists()
返回一個(gè)路徑的目錄名和文件名:os.path.split()
eg os.path.split(‘/home/swaroop/byte/code/poem.txt’)
結(jié)果:(‘/home/swaroop/byte/code’, ‘poem.txt’)
分離擴(kuò)展名:os.path.splitext()
獲取路徑名:os.path.dirname()
獲取文件名:os.path.basename()
運(yùn)行shell命令: os.system()
讀取和設(shè)置環(huán)境變量:os.getenv() 與os.putenv()
給出當(dāng)前平臺(tái)使用的行終止符:os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’
指示你正在使用的平臺(tái):os.name 對(duì)于Windows,它是’nt’,而對(duì)于Linux/Unix用戶,它是’posix’
重命名:os.rename(old, new)
創(chuàng)建多級(jí)目錄:os.makedirs(r“c:\python\test”)
創(chuàng)建單個(gè)目錄:os.mkdir(“test”)
獲取文件屬性:os.stat(file)
修改文件權(quán)限與時(shí)間戳:os.chmod(file)
終止當(dāng)前進(jìn)程:os.exit()
獲取文件大小:os.path.getsize(filename)
文件操作:
os.mknod(“test.txt”) 創(chuàng)建空文件
fp = open(“test.txt”,w) 直接打開一個(gè)文件,如果文件不存在則創(chuàng)建文件
關(guān)于open 模式:
w 以寫方式打開,
a 以追加模式打開 (從 EOF 開始, 必要時(shí)創(chuàng)建新文件)
r+ 以讀寫模式打開
w+ 以讀寫模式打開 (參見 w )
a+ 以讀寫模式打開 (參見 a )
rb 以二進(jìn)制讀模式打開
wb 以二進(jìn)制寫模式打開 (參見 w )
ab 以二進(jìn)制追加模式打開 (參見 a )
rb+ 以二進(jìn)制讀寫模式打開 (參見 r+ )
wb+ 以二進(jìn)制讀寫模式打開 (參見 w+ )
ab+ 以二進(jìn)制讀寫模式打開 (參見 a+ )
fp.read([size]) #size為讀取的長度,以byte為單位
fp.readline([size]) #讀一行,如果定義了size,有可能返回的只是一行的一部分
fp.readlines([size]) #把文件每一行作為一個(gè)list的一個(gè)成員,并返回這個(gè)list。其實(shí)它的內(nèi)部是通過循環(huán)調(diào)用readline()來實(shí)現(xiàn)的。如果提供size參數(shù),size是表示讀取內(nèi)容的總長,也就是說可能只讀到文件的一部分。
fp.write(str) #把str寫到文件中,write()并不會(huì)在str后加上一個(gè)換行符
fp.writelines(seq) #把seq的內(nèi)容全部寫到文件中(多行一次性寫入)。這個(gè)函數(shù)也只是忠實(shí)地寫入,不會(huì)在每行后面加上任何東西。
fp.close() #關(guān)閉文件。python會(huì)在一個(gè)文件不用后自動(dòng)關(guān)閉文件,不過這一功能沒有保證,最好還是養(yǎng)成自己關(guān)閉的習(xí)慣。 如果一個(gè)文件在關(guān)閉后還對(duì)其進(jìn)行操作會(huì)產(chǎn)生ValueError
fp.flush() #把緩沖區(qū)的內(nèi)容寫入硬盤
fp.fileno() #返回一個(gè)長整型的”文件標(biāo)簽“
fp.isatty() #文件是否是一個(gè)終端設(shè)備文件(unix系統(tǒng)中的)
fp.tell() #返回文件操作標(biāo)記的當(dāng)前位置,以文件的開頭為原點(diǎn)
fp.next() #返回下一行,并將文件操作標(biāo)記位移到下一行。把一個(gè)file用于for … in file這樣的語句時(shí),就是調(diào)用next()函數(shù)來實(shí)現(xiàn)遍歷的。
fp.seek(offset[,whence]) #將文件打操作標(biāo)記移到offset的位置。這個(gè)offset一般是相對(duì)于文件的開頭來計(jì)算的,一般為正數(shù)。但如果提供了whence參數(shù)就不一定了,whence可以為0表示從頭開始計(jì)算,1表示以當(dāng)前位置為原點(diǎn)計(jì)算。2表示以文件末尾為原點(diǎn)進(jìn)行計(jì)算。需要注意,如果文件以a或a+的模式打開,每次進(jìn)行寫操作時(shí),文件操作標(biāo)記會(huì)自動(dòng)返回到文件末尾。
fp.truncate([size]) #把文件裁成規(guī)定的大小,默認(rèn)的是裁到當(dāng)前文件操作標(biāo)記的位置。如果size比文件的大小還要大,依據(jù)系統(tǒng)的不同可能是不改變文件,也可能是用0把文件補(bǔ)到相應(yīng)的大小,也可能是以一些隨機(jī)的內(nèi)容加上去。
目錄操作:
os.mkdir(“file”) 創(chuàng)建目錄
復(fù)制文件:
shutil.copyfile(“oldfile”,”newfile”) oldfile和newfile都只能是文件
shutil.copy(“oldfile”,”newfile”) oldfile只能是文件夾,newfile可以是文件,也可以是目標(biāo)目錄
復(fù)制文件夾:
shutil.copytree(“olddir”,”newdir”) olddir和newdir都只能是目錄,且newdir必須不存在
重命名文件(目錄)
os.rename(“oldname”,”newname”) 文件或目錄都是使用這條命令
移動(dòng)文件(目錄)
shutil.move(“oldpos”,”newpos”)
刪除文件
os.remove(“file”)
刪除目錄
os.rmdir(“dir”)只能刪除空目錄
shutil.rmtree(“dir”) 空目錄、有內(nèi)容的目錄都可以刪
轉(zhuǎn)換目錄
os.chdir(“path”) 換路徑
Python讀寫文件
1.open
使用open打開文件后一定要記得調(diào)用文件對(duì)象的close()方法。比如可以用try/finally語句來確保最后能關(guān)閉文件。
file_object = open(‘thefile.txt’)
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
注:不能把open語句放在try塊里,因?yàn)楫?dāng)打開文件出現(xiàn)異常時(shí),文件對(duì)象file_object無法執(zhí)行close()方法。
2.讀文件
讀文本文件
input = open('data', 'r')
#第二個(gè)參數(shù)默認(rèn)為r
input = open('data')
1
2
3
讀二進(jìn)制文件
input = open('data', 'rb')
1
讀取所有內(nèi)容
file_object = open('thefile.txt')
try:
all_the_text = file_object.read( )
finally:
file_object.close( )
1
2
3
4
5
讀固定字節(jié)
file_object = open('abinfile', 'rb')
try:
while True:
chunk = file_object.read(100)
if not chunk:
break
do_something_with(chunk)
finally:
file_object.close( )
1
2
3
4
5
6
7
8
9
讀每行
list_of_all_the_lines = file_object.readlines( )
1
如果文件是文本文件,還可以直接遍歷文件對(duì)象獲取每行:
for line in file_object:
process line
1
2
3.寫文件
寫文本文件
output = open('data', 'w')
1
寫二進(jìn)制文件
output = open('data', 'wb')
1
追加寫文件
output = open('data', 'w+')
1
寫數(shù)據(jù)
file_object = open('thefile.txt', 'w')
file_object.write(all_the_text)
file_object.close( )
1
2
3
寫入多行
file_object.writelines(list_of_text_strings)
1
注意,調(diào)用writelines寫入多行在性能上會(huì)比使用write一次性寫入要高。
在處理日志文件的時(shí)候,常常會(huì)遇到這樣的情況:日志文件巨大,不可能一次性把整個(gè)文件讀入到內(nèi)存中進(jìn)行處理,例如需要在一臺(tái)物理內(nèi)存為 2GB 的機(jī)器上處理一個(gè) 2GB 的日志文件,我們可能希望每次只處理其中 200MB 的內(nèi)容。
在 Python 中,內(nèi)置的 File 對(duì)象直接提供了一個(gè) readlines(sizehint) 函數(shù)來完成這樣的事情。以下面的代碼為例:
file = open('test.log', 'r')sizehint = 209715200 # 200Mposition = 0lines = file.readlines(sizehint)while not file.tell() - position < 0: position = file.tell() lines = file.readlines(sizehint)
1
每次調(diào)用 readlines(sizehint) 函數(shù),會(huì)返回大約 200MB 的數(shù)據(jù),而且所返回的必然都是完整的行數(shù)據(jù),大多數(shù)情況下,返回的數(shù)據(jù)的字節(jié)數(shù)會(huì)稍微比 sizehint 指定的值大一點(diǎn)(除最后一次調(diào)用 readlines(sizehint) 函數(shù)的時(shí)候)。通常情況下,Python 會(huì)自動(dòng)將用戶指定的 sizehint 的值調(diào)整成內(nèi)部緩存大小的整數(shù)倍。
file在python是一個(gè)特殊的類型,它用于在python程序中對(duì)外部的文件進(jìn)行操作。在python中一切都是對(duì)象,file也不例外,file有file的方法和屬性。下面先來看如何創(chuàng)建一個(gè)file對(duì)象:
file(name[, mode[, buffering]])
1
file()函數(shù)用于創(chuàng)建一個(gè)file對(duì)象,它有一個(gè)別名叫open(),可能更形象一些,它們是內(nèi)置函數(shù)。來看看它的參數(shù)。它參數(shù)都是以字符串的形式傳遞的。name是文件的名字。
mode是打開的模式,可選的值為r w a U,分別代表讀(默認(rèn)) 寫 添加支持各種換行符的模式。用w或a模式打開文件的話,如果文件不存在,那么就自動(dòng)創(chuàng)建。此外,用w模式打開一個(gè)已經(jīng)存在的文件時(shí),原有文件的內(nèi)容會(huì)被清空,因?yàn)橐婚_始文件的操作的標(biāo)記是在文件的開頭的,這時(shí)候進(jìn)行寫操作,無疑會(huì)把原有的內(nèi)容給抹掉。由于歷史的原因,換行符在不同的系統(tǒng)中有不同模式,比如在 unix中是一個(gè)\n,而在windows中是‘\r\n’,用U模式打開文件,就是支持所有的換行模式,也就說‘\r’ ‘\n’ ‘\r\n’都可表示換行,會(huì)有一個(gè)tuple用來存貯這個(gè)文件中用到過的換行符。不過,雖說換行有多種模式,讀到python中統(tǒng)一用\n代替。在模式字符的后面,還可以加上+ b t這兩種標(biāo)識(shí),分別表示可以對(duì)文件同時(shí)進(jìn)行讀寫操作和用二進(jìn)制模式、文本模式(默認(rèn))打開文件。
buffering如果為0表示不進(jìn)行緩沖;如果為1表示進(jìn)行“行緩沖“;如果是一個(gè)大于1的數(shù)表示緩沖區(qū)的大小,應(yīng)該是以字節(jié)為單位的。
file對(duì)象有自己的屬性和方法。先來看看file的屬性。
closed #標(biāo)記文件是否已經(jīng)關(guān)閉,由close()改寫
encoding #文件編碼
mode #打開模式
name #文件名
newlines #文件中用到的換行模式,是一個(gè)tuple
softspace #boolean型,一般為0,據(jù)說用于print
1
2
3
4
5
6
file的讀寫方法:
F.read([size]) #size為讀取的長度,以byte為單位
F.readline([size])
#讀一行,如果定義了size,有可能返回的只是一行的一部分
F.readlines([size])
#把文件每一行作為一個(gè)list的一個(gè)成員,并返回這個(gè)list。其實(shí)它的內(nèi)部是通過循環(huán)調(diào)用readline()來實(shí)現(xiàn)的。如果提供size參數(shù),size是表示讀取內(nèi)容的總長,也就是說可能只讀到文件的一部分。
F.write(str)
#把str寫到文件中,write()并不會(huì)在str后加上一個(gè)換行符
F.writelines(seq)
#把seq的內(nèi)容全部寫到文件中。這個(gè)函數(shù)也只是忠實(shí)地寫入,不會(huì)在每行后面加上任何東西。
file的其他方法:
F.close()
#關(guān)閉文件。python會(huì)在一個(gè)文件不用后自動(dòng)關(guān)閉文件,不過這一功能沒有保證,最好還是養(yǎng)成自己關(guān)閉的習(xí)慣。如果一個(gè)文件在關(guān)閉后還對(duì)其進(jìn)行操作會(huì)產(chǎn)生ValueError
F.flush()
#把緩沖區(qū)的內(nèi)容寫入硬盤
F.fileno()
#返回一個(gè)長整型的”文件標(biāo)簽“
F.isatty()
#文件是否是一個(gè)終端設(shè)備文件(unix系統(tǒng)中的)
F.tell()
#返回文件操作標(biāo)記的當(dāng)前位置,以文件的開頭為原點(diǎn)
F.next()
#返回下一行,并將文件操作標(biāo)記位移到下一行。把一個(gè)file用于for ... in file這樣的語句時(shí),就是調(diào)用next()函數(shù)來實(shí)現(xiàn)遍歷的。
F.seek(offset[,whence])
#將文件打操作標(biāo)記移到offset的位置。這個(gè)offset一般是相對(duì)于文件的開頭來計(jì)算的,一般為正數(shù)。但如果提供了whence參數(shù)就不一定了,whence可以為0表示從頭開始計(jì)算,1表示以當(dāng)前位置為原點(diǎn)計(jì)算。2表示以文件末尾為原點(diǎn)進(jìn)行計(jì)算。需要注意,如果文件以a或a+的模式打開,每次進(jìn)行寫操作時(shí),文件操作標(biāo)記會(huì)自動(dòng)返回到文件末尾。
F.truncate([size])
#把文件裁成規(guī)定的大小,默認(rèn)的是裁到當(dāng)前文件操作標(biāo)記的位置。如果size比文件的大小還要大,依據(jù)系統(tǒng)的不同可能是不改變文件,也可能是用0把文件補(bǔ)到相應(yīng)的大小,也可能是以一些隨機(jī)的內(nèi)容加上去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
http://www.cnblogs.com/allenblogs/archive/2010/09/13/1824842.html
http://www.cnblogs.com/rollenholt/archive/2012/04/23/2466179.html
首先 dfs.replication這個(gè)參數(shù)是個(gè)client參數(shù),即node level參數(shù)。需要在每臺(tái)datanode上設(shè)置。
其實(shí)默認(rèn)為3個(gè)副本已經(jīng)夠用了,設(shè)置太多也沒什么用。
一個(gè)文件,上傳到hdfs上時(shí)指定的是幾個(gè)副本就是幾個(gè)。以后你修改了副本數(shù),對(duì)已經(jīng)上傳了的文件也不會(huì)起作用。可以再上傳文件的同時(shí)指定創(chuàng)建的副本數(shù)
Hadoop dfs -D dfs.replication=1 -put 70M logs/2
可以通過命令來更改已經(jīng)上傳的文件的副本數(shù):
hadoop fs -setrep -R 3 /
查看當(dāng)前hdfs的副本數(shù)
hadoop fsck -locations
FSCK started by hadoop from /172.18.6.112 for path / at Thu Oct 27 13:24:25 CST 2011
....................Status: HEALTHY
Total size: 4834251860 B
Total dirs: 21
Total files: 20
Total blocks (validated): 82 (avg. block size 58954290 B)
Minimally replicated blocks: 82 (100.0 %)
Over-replicated blocks: 0 (0.0 %)
Under-replicated blocks: 0 (0.0 %)
Mis-replicated blocks: 0 (0.0 %)
Default replication factor: 3
Average block replication: 3.0
Corrupt blocks: 0
Missing replicas: 0 (0.0 %)
Number of data-nodes: 3
Number of racks: 1
FSCK ended at Thu Oct 27 13:24:25 CST 2011 in 10 milliseconds
The filesystem under path '/' is HEALTHY
某個(gè)文件的副本數(shù),可以通過ls中的文件描述符看到
hadoop dfs -ls
-rw-r--r-- 3 hadoop supergroup 153748148 2011-10-27 16:11 /user/hadoop/logs/201108/impression_witspixel2011080100.thin.log.gz
如果你只有3個(gè)datanode,但是你卻指定副本數(shù)為4,是不會(huì)生效的,因?yàn)槊總€(gè)datanode上只能存放一個(gè)副本。
參考:http://blog.csdn.net/lskyne/article/details/8898666
轉(zhuǎn)自:https://www.cnblogs.com/shabbylee/p/6792555.html
由于歷史原因,Python有兩個(gè)大的版本分支,Python2和Python3,又由于一些庫只支持某個(gè)版本分支,所以需要在電腦上同時(shí)安裝Python2和Python3,因此如何讓兩個(gè)版本的Python兼容,如何讓腳本在對(duì)應(yīng)的Python版本上運(yùn)行,這個(gè)是值得總結(jié)的。
對(duì)于Ubuntu 16.04 LTS版本來說,Python2(2.7.12)和Python3(3.5.2)默認(rèn)同時(shí)安裝,默認(rèn)的python版本是2.7.12。
當(dāng)然你也可以用python2來調(diào)用。
如果想調(diào)用python3,就用python3.
對(duì)于Windows,就有點(diǎn)復(fù)雜了。因?yàn)椴徽損ython2還是python3,python可執(zhí)行文件都叫python.exe,在cmd下輸入python得到的版本號(hào)取決于環(huán)境變量里哪個(gè)版本的python路徑更靠前,畢竟windows是按照順序查找的。比如環(huán)境變量里的順序是這樣的:
那么cmd下的python版本就是2.7.12。
反之,則是python3的版本號(hào)。
這就帶來一個(gè)問題了,如果你想用python2運(yùn)行一個(gè)腳本,一會(huì)你又想用python3運(yùn)行另一個(gè)腳本,你怎么做?來回改環(huán)境變量顯然很麻煩。
網(wǎng)上很多辦法比較簡單粗暴,把兩個(gè)python.exe改名啊,一個(gè)改成python2.exe,一個(gè)改成python3.exe。這樣做固然可以,但修改可執(zhí)行文件的方式,畢竟不是很好的方法。
我仔細(xì)查找了一些python技術(shù)文檔,發(fā)現(xiàn)另外一個(gè)我覺得比較好的解決辦法。
借用py的一個(gè)參數(shù)來調(diào)用不同版本的Python。py -2調(diào)用python2,py -3調(diào)用的是python3.
當(dāng)python腳本需要python2運(yùn)行時(shí),只需在腳本前加上,然后運(yùn)行py xxx.py即可。
#! python2
當(dāng)python腳本需要python3運(yùn)行時(shí),只需在腳本前加上,,然后運(yùn)行py xxx.py即可。
#! python3
就這么簡單。
同時(shí),這也完美解決了在pip在python2和python3共存的環(huán)境下報(bào)錯(cuò),提示Fatal error in launcher: Unable to create process using '"'的問題。
當(dāng)需要python2的pip時(shí),只需
py -2 -m pip install xxx
當(dāng)需要python3的pip時(shí),只需
py -3 -m pip install xxx
python2和python3的pip package就這樣可以完美分開了。
Sentry權(quán)限控制通過Beeline(Hiveserver2 SQL 命令行接口)輸入Grant 和 Revoke語句來配置。語法跟現(xiàn)在的一些主流的關(guān)系數(shù)據(jù)庫很相似。需要注意的是:當(dāng)sentry服務(wù)啟用后,我們必須使用beeline接口來執(zhí)行hive查詢,Hive Cli并不支持sentry。
CREATE ROLE Statement
CREATE ROLE語句創(chuàng)建一個(gè)可以被賦權(quán)的角色。權(quán)限可以賦給角色,然后再分配給各個(gè)用戶。一個(gè)用戶被分配到角色后可以執(zhí)行該角色的權(quán)限。
只有擁有管理員的角色可以create/drop角色。默認(rèn)情況下,hive、impala和hue用戶擁有管理員角色。
CREATE ROLE [role_name];
DROP ROLE Statement
DROP ROLE語句可以用來從數(shù)據(jù)庫中移除一個(gè)角色。一旦移除,之前分配給所有用戶的該角色將會(huì)取消。之前已經(jīng)執(zhí)行的語句不會(huì)受到影響。但是,因?yàn)閔ive在執(zhí)行每條查詢語句之前會(huì)檢查用戶的權(quán)限,處于登錄活躍狀態(tài)的用戶會(huì)話會(huì)受到影響。
DROP ROLE [role_name];
GRANT ROLE Statement
GRANT ROLE語句可以用來給組授予角色。只有sentry的管理員用戶才能執(zhí)行該操作。
GRANT ROLE role_name [, role_name]
TO GROUP (groupName) [,GROUP (groupName)]
REVOKE ROLE Statement
REVOKE ROLE語句可以用來從組移除角色。只有sentry的管理員用戶才能執(zhí)行該操作。
REVOKE ROLE role_name [, role_name]
FROM GROUP (groupName) [,GROUP (groupName)]
GRANT (PRIVILEGE) Statement
授予一個(gè)對(duì)象的權(quán)限給一個(gè)角色,該用戶必須為sentry的管理員用戶。
GRANT
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
TO ROLE (roleName) [,ROLE (roleName)]
REVOKE (PRIVILEGE) Statement
因?yàn)橹挥姓J(rèn)證的管理員用戶可以創(chuàng)建角色,從而只有管理員用戶可以取消一個(gè)組的權(quán)限。
REVOKE
(PRIVILEGE) [, (PRIVILEGE) ]
ON (OBJECT) (object_name)
FROM ROLE (roleName) [,ROLE (roleName)]
GRANT (PRIVILEGE) ... WITH GRANT OPTION
在cdh5.2中,你可以委托給其他角色來授予和解除權(quán)限。比如,一個(gè)角色被授予了WITH GRANT OPTION的權(quán)限可以GRANT/REVOKE同樣的權(quán)限給其他角色。因此,如果一個(gè)角色有一個(gè)庫的所有權(quán)限并且設(shè)置了 WITH GRANT OPTION,該角色分配的用戶可以對(duì)該數(shù)據(jù)庫和其中的表執(zhí)行GRANT/REVOKE語句。
GRANT
(PRIVILEGE)
ON (OBJECT) (object_name)
TO ROLE (roleName)
WITH GRANT OPTION
只有一個(gè)帶GRANT選項(xiàng)的特殊權(quán)限的角色或者它的父級(jí)權(quán)限可以從其他角色解除這種權(quán)限。一旦下面的語句執(zhí)行,所有跟其相關(guān)的grant權(quán)限將會(huì)被解除。
REVOKE
(RIVILEGE)
ON (BJECT) (bject_name)
FROM ROLE (roleName)
Hive目前不支持解除之前賦予一個(gè)角色 WITH GRANT OPTION 的權(quán)限。要想移除WITH GRANT OPTION、解除權(quán)限,可以重新去除 WITH GRANT OPTION這個(gè)標(biāo)記來再次附權(quán)。
SET ROLE Statement
SET ROLE語句可以給當(dāng)前會(huì)話選擇一個(gè)角色使之生效。一個(gè)用戶只能啟用分配給他的角色。任何不存在的角色和當(dāng)前用戶不能使用的角色是不能生效的。如果沒有使用任何角色,用戶將會(huì)使用任何一個(gè)屬于他的角色的權(quán)限。
選擇一個(gè)角色使用:
To enable a specific role:
使用所有的角色:
To enable a specific role:
關(guān)閉所有角色
SET ROLE NONE;
SHOW Statement
顯示當(dāng)前用戶擁有庫、表、列相關(guān)權(quán)限的數(shù)據(jù)庫:
SHOW DATABASES;
顯示當(dāng)前用戶擁有表、列相關(guān)權(quán)限的表;
SHOW TABLES;
顯示當(dāng)前用戶擁有SELECT權(quán)限的列:
SHOW COLUMNS (FROM|IN) table_name [(FROM|IN) db_name];
顯示當(dāng)前系統(tǒng)中所有的角色(只有管理員用戶可以執(zhí)行):
SHOW ROLES;
顯示當(dāng)前影響當(dāng)前會(huì)話的角色:
SHOW CURRENT ROLES;
顯示指定組的被分配到的所有角色(只有管理員用戶和指定組內(nèi)的用戶可以執(zhí)行)
SHOW ROLE GRANT GROUP (groupName);
SHOW語句可以用來顯示一個(gè)角色被授予的權(quán)限或者顯示角色的一個(gè)特定對(duì)象的所有權(quán)限。
顯示指定角色的所有被賦予的權(quán)限。(只有管理員用戶和指定角色分配到的用戶可以執(zhí)行)。下面的語句也會(huì)顯示任何列級(jí)的權(quán)限。
SHOW GRANT ROLE (roleName);
顯示指定對(duì)象的一個(gè)角色的所有被賦予的權(quán)限(只有管理員用戶和指定角色分配到的用戶可以執(zhí)行)。下面的語句也會(huì)顯示任何列級(jí)的權(quán)限。
SHOW GRANT ROLE (roleName) on (OBJECT) (objectName);
----------------------------我也是有底線的-----------------------------
摘要: Python 里面的編碼和解碼也就是 unicode 和 str 這兩種形式的相互轉(zhuǎn)化。編碼是 unicode -> str,相反的,解碼就是 str -> unicode。剩下的問題就是確定何時(shí)需要進(jìn)行編碼或者解碼了.關(guān)于文件開頭的"編碼指示",也就是 # -*- codin...
閱讀全文
一、前言
早上醒來打開微信,同事反饋kafka集群從昨天凌晨開始寫入頻繁失敗,趕緊打開電腦查看了kafka集群的機(jī)器監(jiān)控,日志信息,發(fā)現(xiàn)其中一個(gè)節(jié)點(diǎn)的集群負(fù)載從昨天凌晨突然掉下來了,和同事反饋的時(shí)間點(diǎn)大概一致,于是乎就登錄服務(wù)器開始干活。
二、排錯(cuò)
1、查看機(jī)器監(jiān)控,看是否能大概定位是哪個(gè)節(jié)點(diǎn)有異常
技術(shù)分享
2、根據(jù)機(jī)器監(jiān)控大概定位到其中一個(gè)異常節(jié)點(diǎn),登錄服務(wù)器查看kafka日志,發(fā)現(xiàn)有報(bào)錯(cuò)日志,并且日志就停留在這個(gè)這個(gè)時(shí)間點(diǎn):
[2017-06-01 16:59:59,851] ERROR Processor got uncaught exception. (kafka.network.Processor)
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:174)
at sun.nio.ch.IOUtil.read(IOUtil.java:195)
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379)
at org.apache.kafka.common.network.PlaintextTransportLayer.read(PlaintextTransportLayer.java:108)
at org.apache.kafka.common.network.NetworkReceive.readFromReadableChannel(NetworkReceive.java:97)
at org.apache.kafka.common.network.NetworkReceive.readFrom(NetworkReceive.java:71)
at org.apache.kafka.common.network.KafkaChannel.receive(KafkaChannel.java:160)
at org.apache.kafka.common.network.KafkaChannel.read(KafkaChannel.java:141)
at org.apache.kafka.common.network.Selector.poll(Selector.java:286)
at kafka.network.Processor.run(SocketServer.scala:413)3、查看kafka進(jìn)程和監(jiān)聽端口情況,發(fā)現(xiàn)都正常,尼瑪假死了
ps -ef |grep kafka ## 查看kafka的進(jìn)程
netstat -ntlp |grep 9092 ##9092kafka的監(jiān)聽端口4、既然已經(jīng)假死了,只能重啟了
ps -ef |grep kafka |grep -v grep |awk ‘{print $2}‘ | xargs kill -9
/usr/local/kafka/bin;nohup ./kafka-server-start.sh ../config/server.properties &5、重啟后在觀察該節(jié)點(diǎn)的kafka日志,在一頓index重建之后,上面的報(bào)錯(cuò)信息在瘋狂的刷,最后谷歌一番,解決了該問題
三、解決方案:
在
/usr/local/kafka/binkafka-run-class.sh去掉
-XX:+DisableExplicitGC添加
-XX:MaxDirectMemorySize=512m在一次重啟kafka,問題解決。
摘要: 我們每次執(zhí)行hive的hql時(shí),shell里都會(huì)提示一段話:[python] view plaincopy... Number of reduce tasks not specified. Estimated from input data size: 50...
閱讀全文
摘要: spark 累加歷史主要用到了窗口函數(shù),而進(jìn)行全部統(tǒng)計(jì),則需要用到rollup函數(shù)
1 應(yīng)用場景:
1、我們需要統(tǒng)計(jì)用戶的總使用時(shí)長(累加歷史)
2、前臺(tái)展現(xiàn)頁面需要對(duì)多個(gè)維度進(jìn)行查詢,如:產(chǎn)品、地區(qū)等等
3、需要展現(xiàn)的表格頭如: 產(chǎn)品、2015-04、2015-05、2015-06
2 原始數(shù)據(jù):
product_code |event_date |dur...
閱讀全文
摘要: Spark1.4發(fā)布,支持了窗口分析函數(shù)(window functions)。在離線平臺(tái)中,90%以上的離線分析任務(wù)都是使用Hive實(shí)現(xiàn),其中必然會(huì)使用很多窗口分析函數(shù),如果SparkSQL支持窗口分析函數(shù),
那么對(duì)于后面Hive向SparkSQL中的遷移的工作量會(huì)大大降低,使用方式如下:
1、初始化數(shù)據(jù)
創(chuàng)建表
[sql] view plain cop...
閱讀全文
1.in 不支持子查詢 eg. select * from src where key in(select key from test);
支持查詢個(gè)數(shù) eg. select * from src where key in(1,2,3,4,5);
in 40000個(gè) 耗時(shí)25.766秒
in 80000個(gè) 耗時(shí)78.827秒
2.union all/union
不支持頂層的union all eg. select key from src UNION ALL select key from test;
支持select * from (select key from src union all select key from test)aa;
不支持 union
支持select distinct key from (select key from src union all select key from test)aa;
3.intersect 不支持
4.minus 不支持
5.except 不支持
6.inner join/join/left outer join/right outer join/full outer join/left semi join 都支持
left outer join/right outer join/full outer join 中間必須有outer
join是最簡單的關(guān)聯(lián)操作,兩邊關(guān)聯(lián)只取交集;
left outer join是以左表驅(qū)動(dòng),右表不存在的key均賦值為null;
right outer join是以右表驅(qū)動(dòng),左表不存在的key均賦值為null;
full outer join全表關(guān)聯(lián),將兩表完整的進(jìn)行笛卡爾積操作,左右表均可賦值為null;
left semi join最主要的使用場景就是解決exist in;
Hive不支持where子句中的子查詢,SQL常用的exist in子句在Hive中是不支持的
不支持子查詢 eg. select * from src aa where aa.key in(select bb.key from test bb);
可用以下兩種方式替換:
select * from src aa left outer join test bb on aa.key=bb.key where bb.key <> null;
select * from src aa left semi join test bb on aa.key=bb.key;
大多數(shù)情況下 JOIN ON 和 left semi on 是對(duì)等的
A,B兩表連接,如果B表存在重復(fù)數(shù)據(jù)
當(dāng)使用JOIN ON的時(shí)候,A,B表會(huì)關(guān)聯(lián)出兩條記錄,應(yīng)為ON上的條件符合;
而是用LEFT SEMI JOIN 當(dāng)A表中的記錄,在B表上產(chǎn)生符合條件之后就返回,不會(huì)再繼續(xù)查找B表記錄了,
所以如果B表有重復(fù),也不會(huì)產(chǎn)生重復(fù)的多條記錄。
left outer join 支持子查詢 eg. select aa.* from src aa left outer join (select * from test111)bb on aa.key=bb.a;
7. hive四中數(shù)據(jù)導(dǎo)入方式
1)從本地文件系統(tǒng)中導(dǎo)入數(shù)據(jù)到Hive表
create table wyp(id int,name string) ROW FORMAT delimited fields terminated by '\t' STORED AS TEXTFILE;
load data local inpath 'wyp.txt' into table wyp;
2)從HDFS上導(dǎo)入數(shù)據(jù)到Hive表
[wyp@master /home/q/hadoop-2.2.0]$ bin/hadoop fs -cat /home/wyp/add.txt
hive> load data inpath '/home/wyp/add.txt' into table wyp;
3)從別的表中查詢出相應(yīng)的數(shù)據(jù)并導(dǎo)入到Hive表中
hive> create table test(
> id int, name string
> ,tel string)
> partitioned by
> (age int)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY '\t'
> STORED AS TEXTFILE;
注:test表里面用age作為了分區(qū)字段,分區(qū):在Hive中,表的每一個(gè)分區(qū)對(duì)應(yīng)表下的相應(yīng)目錄,所有分區(qū)的數(shù)據(jù)都是存儲(chǔ)在對(duì)應(yīng)的目錄中。
比如wyp表有dt和city兩個(gè)分區(qū),則對(duì)應(yīng)dt=20131218city=BJ對(duì)應(yīng)表的目錄為/user/hive/warehouse/dt=20131218/city=BJ,
所有屬于這個(gè)分區(qū)的數(shù)據(jù)都存放在這個(gè)目錄中。
hive> insert into table test
> partition (age='25')
> select id, name, tel
> from wyp;
也可以在select語句里面通過使用分區(qū)值來動(dòng)態(tài)指明分區(qū):
hive> set hive.exec.dynamic.partition.mode=nonstrict;
hive> insert into table test
> partition (age)
> select id, name,
> tel, age
> from wyp;
Hive也支持insert overwrite方式來插入數(shù)據(jù)
hive> insert overwrite table test
> PARTITION (age)
> select id, name, tel, age
> from wyp;
Hive還支持多表插入
hive> from wyp
> insert into table test
> partition(age)
> select id, name, tel, age
> insert into table test3
> select id, name
> where age>25;
4)在創(chuàng)建表的時(shí)候通過從別的表中查詢出相應(yīng)的記錄并插入到所創(chuàng)建的表中
hive> create table test4
> as
> select id, name, tel
> from wyp;
8.查看建表語句
hive> show create table test3;
9.表重命名
hive> ALTER TABLE events RENAME TO 3koobecaf;
10.表增加列
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT);
11.添加一列并增加列字段注釋
hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');
12.刪除表
hive> DROP TABLE pokes;
13.top n
hive> select * from test order by key limit 10;
14.創(chuàng)建數(shù)據(jù)庫
Create Database baseball;
14.alter table tablename change oldColumn newColumn column_type 修改列的名稱和類型
alter table yangsy CHANGE product_no phone_no string
15.導(dǎo)入.sql文件中的sql
spark-sql --driver-class-path /home/hadoop/hive/lib/mysql-connector-java-5.1.30-bin.jar -f testsql.sql
insert into table CI_CUSER_20141117154351522 select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_d01_3845.L2_01_01_04 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO left join DW_COCLBL_D01_20140515 dw_coclbl_d01_3845 on dw_coclbl_m02_3848.PRODUCT_NO = dw_coclbl_d01_3845.PRODUCT_NO
insert into CI_CUSER_20141117142123638 ( PRODUCT_NO,ATTR_COL_0000,ATTR_COL_0001) select mainResult.PRODUCT_NO,dw_coclbl_m02_3848.L1_01_02_01,dw_coclbl_m02_3848.L1_01_03_01 from (select PRODUCT_NO from CI_CUSER_20141114203632267) mainResult left join DW_COCLBL_M02_201407 dw_coclbl_m02_3848 on mainResult.PRODUCT_NO = dw_coclbl_m02_3848.PRODUCT_NO
CREATE TABLE ci_cuser_yymmddhhmisstttttt_tmp(product_no string) row format serde 'com.bizo.hive.serde.csv.CSVSerde' ;
LOAD DATA LOCAL INPATH '/home/ocdc/coc/yuli/test123.csv' OVERWRITE INTO TABLE test_yuli2;
創(chuàng)建支持CSV格式的testfile文件
CREATE TABLE test_yuli7 row format serde 'com.bizo.hive.serde.csv.CSVSerde' as select * from CI_CUSER_20150310162729786;
不依賴CSVSerde的jar包創(chuàng)建逗號(hào)分隔的表
"create table " +listName+ " ROW FORMAT DELIMITED FIELDS TERMINATED BY ','" +
" as select * from " + listName1;
create table aaaa ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE as select * from
ThriftServer 開啟FAIR模式
SparkSQL Thrift Server 開啟FAIR調(diào)度方式:
1. 修改$SPARK_HOME/conf/spark-defaults.conf,新增
2. spark.scheduler.mode FAIR
3. spark.scheduler.allocation.file /Users/tianyi/github/community/apache-spark/conf/fair-scheduler.xml
4. 修改$SPARK_HOME/conf/fair-scheduler.xml(或新增該文件), 編輯如下格式內(nèi)容
5. <?xml version="1.0"?>
6. <allocations>
7. <pool name="production">
8. <schedulingMode>FAIR</schedulingMode>
9. <!-- weight表示兩個(gè)隊(duì)列在minShare相同的情況下,可以使用資源的比例 -->
10. <weight>1</weight>
11. <!-- minShare表示優(yōu)先保證的資源數(shù) -->
12. <minShare>2</minShare>
13. </pool>
14. <pool name="test">
15. <schedulingMode>FIFO</schedulingMode>
16. <weight>2</weight>
17. <minShare>3</minShare>
18. </pool>
19. </allocations>
20. 重啟Thrift Server
21. 執(zhí)行SQL前,執(zhí)行
22. set spark.sql.thriftserver.scheduler.pool=指定的隊(duì)列名
等操作完了 create table yangsy555 like CI_CUSER_YYMMDDHHMISSTTTTTT 然后insert into yangsy555 select * from yangsy555
創(chuàng)建一個(gè)自增序列表,使用row_number() over()為表增加序列號(hào) 以供分頁查詢
create table yagnsytest2 as SELECT ROW_NUMBER() OVER() as id,* from yangsytest;

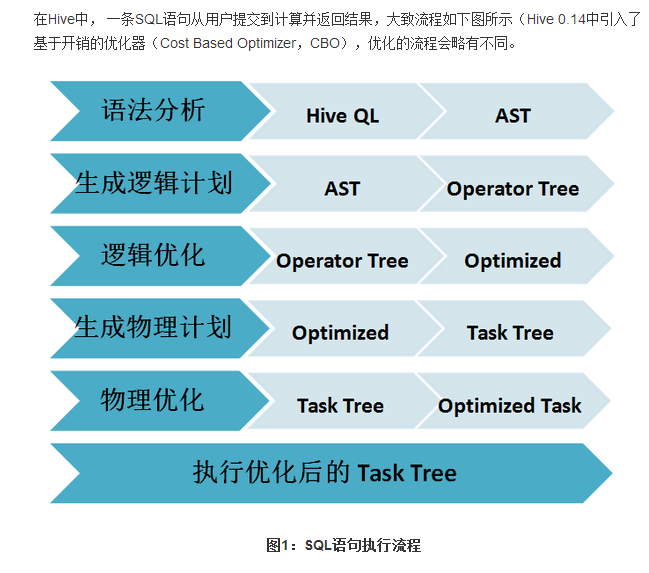
Sparksql的解析與Hiveql的解析的執(zhí)行流程:
如果用傳統(tǒng)SCP遠(yuǎn)程拷貝,速度是比較慢的。現(xiàn)在采用lz4壓縮傳輸。LZ4是一個(gè)非常快的無損壓縮算法,壓縮速度在單核300MB/S,可擴(kuò)展支持多核CPU。它還具有一個(gè)非常快速的解碼器,速度單核可達(dá)到和超越1GB/S。通常能夠達(dá)到多核系統(tǒng)上的RAM速度限制。
你PV 全命為Pipe Viewer,利用它我們可以查看到命令執(zhí)行的進(jìn)度。
下面介紹下lz4和pv的安裝,下載軟件:
下載pv-1.1.4.tar.gz wget http://sourceforge.jp/projects/sfnet_pipeviewer/downloads/pipeviewer/1.1.4/pv-1.1.4.tar.bz2/
下lz4的包難一些,可能要FQ:https://dl.dropboxusercontent.com/u/59565338/LZ4/lz4-r108.tar.gz
安裝灰常簡單:
pv安裝:
[root ~]$ tar jxvf pv-1.1.4.tar.bz2
[root ~]$ cd pv-1.1.4
[root pv-1.1.4]$ ./configure && make && make install
lz4安裝:
[root ~]$ tar zxvf lz4-r108.tar.gz
[root ~]$ cd lz4-r108
[root lz4-r108]$ make && make install
用法:(-c 后指定要傳輸?shù)奈募瑂sh -p 是指定端口,后面的ip是目標(biāo)主機(jī)的ip, -xC指定傳到目標(biāo)主機(jī)下的那個(gè)目錄下,別的不用修改):
tar -c mysql-slave-3307 |pv|lz4 -B4|ssh -p10022 -c arcfour128 -o"MACs umac-64@openssh.com" 192.168.100.234 "lz4 -d |tar -xC /data"
下面是我線上傳一個(gè)從庫的效果:
看到了吧,25.7G 只需要接近3分鐘,這樣遠(yuǎn)比scp速度快上了好幾倍,直接scp拷貝離散文件,很消耗IO,而使用LZ4快速壓縮,對(duì)性能影響不大,傳輸速度快
PS:下次補(bǔ)充同機(jī)房不同網(wǎng)段的傳輸效果及跨機(jī)房的傳輸效果^0^
作者:陸炫志
出處:xuanzhi的博客 http://www.cnblogs.com/xuanzhi201111
您的支持是對(duì)博主最大的鼓勵(lì),感謝您的認(rèn)真閱讀。本文版權(quán)歸作者所有,歡迎轉(zhuǎn)載,但請(qǐng)保留該聲明。
王 騰騰 和 邵 兵
2015 年 11 月 26 日發(fā)布
WeiboGoogle+用電子郵件發(fā)送本頁面
Comments 1
引子
隨著云時(shí)代的來臨,大數(shù)據(jù)(Big data)也獲得了越來越多的關(guān)注。著云臺(tái)的分析師團(tuán)隊(duì)認(rèn)為,大數(shù)據(jù)(Big data)通常用來形容一個(gè)公司創(chuàng)造的大量非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù),這些數(shù)據(jù)在下載到關(guān)系型數(shù)據(jù)庫用于分析時(shí)會(huì)花費(fèi)過多時(shí)間和金錢。大數(shù)據(jù)分析常和云計(jì)算聯(lián)系到一起,因?yàn)閷?shí)時(shí)的大型數(shù)據(jù)集分析需要像 MapReduce 一樣的框架來向數(shù)十、數(shù)百或甚至數(shù)千的電腦分配工作。
“大數(shù)據(jù)”在互聯(lián)網(wǎng)行業(yè)指的是這樣一種現(xiàn)象:互聯(lián)網(wǎng)公司在日常運(yùn)營中生成、累積的用戶網(wǎng)絡(luò)行為數(shù)據(jù)。這些數(shù)據(jù)的規(guī)模是如此龐大,以至于不能用 G 或 T 來衡量。所以如何高效的處理分析大數(shù)據(jù)的問題擺在了面前。對(duì)于大數(shù)據(jù)的處理優(yōu)化方式有很多種,本文中主要介紹在使用 Hadoop 平臺(tái)中對(duì)數(shù)據(jù)進(jìn)行壓縮處理來提高數(shù)據(jù)處理效率。
壓縮簡介
Hadoop 作為一個(gè)較通用的海量數(shù)據(jù)處理平臺(tái),每次運(yùn)算都會(huì)需要處理大量數(shù)據(jù),我們會(huì)在 Hadoop 系統(tǒng)中對(duì)數(shù)據(jù)進(jìn)行壓縮處理來優(yōu)化磁盤使用率,提高數(shù)據(jù)在磁盤和網(wǎng)絡(luò)中的傳輸速度,從而提高系統(tǒng)處理數(shù)據(jù)的效率。在使用壓縮方式方面,主要考慮壓縮速度和壓縮文件的可分割性。綜合所述,使用壓縮的優(yōu)點(diǎn)如下:
1. 節(jié)省數(shù)據(jù)占用的磁盤空間;
2. 加快數(shù)據(jù)在磁盤和網(wǎng)絡(luò)中的傳輸速度,從而提高系統(tǒng)的處理速度。
壓縮格式
Hadoop 對(duì)于壓縮格式的是自動(dòng)識(shí)別。如果我們壓縮的文件有相應(yīng)壓縮格式的擴(kuò)展名(比如 lzo,gz,bzip2 等)。Hadoop 會(huì)根據(jù)壓縮格式的擴(kuò)展名自動(dòng)選擇相對(duì)應(yīng)的解碼器來解壓數(shù)據(jù),此過程完全是 Hadoop 自動(dòng)處理,我們只需要確保輸入的壓縮文件有擴(kuò)展名。
Hadoop 對(duì)每個(gè)壓縮格式的支持, 詳細(xì)見下表:
表 1. 壓縮格式
壓縮格式 工具 算法 擴(kuò)展名 多文件 可分割性
DEFLATE 無 DEFLATE .deflate 不 不
GZIP gzip DEFLATE .gzp 不 不
ZIP zip DEFLATE .zip 是 是,在文件范圍內(nèi)
BZIP2 bzip2 BZIP2 .bz2 不 是
LZO lzop LZO .lzo 不 是
如果壓縮的文件沒有擴(kuò)展名,則需要在執(zhí)行 MapReduce 任務(wù)的時(shí)候指定輸入格式。
1
2
3
4
5
hadoop jar /usr/home/hadoop/hadoop-0.20.2/contrib/streaming/
hadoop-streaming-0.20.2-CD H3B4.jar -file /usr/home/hadoop/hello/mapper.py -mapper /
usr/home/hadoop/hello/mapper.py -file /usr/home/hadoop/hello/
reducer.py -reducer /usr/home/hadoop/hello/reducer.py -input lzotest -output result4 -
jobconf mapred.reduce.tasks=1*-inputformatorg.apache.hadoop.mapred.LzoTextInputFormat*
性能對(duì)比
Hadoop 下各種壓縮算法的壓縮比,壓縮時(shí)間,解壓時(shí)間見下表:
表 2. 性能對(duì)比
壓縮算法 原始文件大小 壓縮文件大小 壓縮速度 解壓速度
gzip 8.3GB 1.8GB 17.5MB/s 58MB/s
bzip2 8.3GB 1.1GB 2.4MB/s 9.5MB/s
LZO-bset 8.3GB 2GB 4MB/s 60.6MB/s
LZO 8.3GB 2.9GB 49.3MB/s 74.6MB/s
因此我們可以得出:
1) Bzip2 壓縮效果明顯是最好的,但是 bzip2 壓縮速度慢,可分割。
2) Gzip 壓縮效果不如 Bzip2,但是壓縮解壓速度快,不支持分割。
3) LZO 壓縮效果不如 Bzip2 和 Gzip,但是壓縮解壓速度最快!并且支持分割!
這里提一下,文件的可分割性在 Hadoop 中是很非常重要的,它會(huì)影響到在執(zhí)行作業(yè)時(shí) Map 啟動(dòng)的個(gè)數(shù),從而會(huì)影響到作業(yè)的執(zhí)行效率!
所有的壓縮算法都顯示出一種時(shí)間空間的權(quán)衡,更快的壓縮和解壓速度通常會(huì)耗費(fèi)更多的空間。在選擇使用哪種壓縮格式時(shí),我們應(yīng)該根據(jù)自身的業(yè)務(wù)需求來選擇。
下圖是在本地壓縮與通過流將壓縮結(jié)果上傳到 BI 的時(shí)間對(duì)比。
圖 1. 時(shí)間對(duì)比
圖 1. 時(shí)間對(duì)比
使用方式
MapReduce 可以在三個(gè)階段中使用壓縮。
1. 輸入壓縮文件。如果輸入的文件是壓縮過的,那么在被 MapReduce 讀取時(shí),它們會(huì)被自動(dòng)解壓。
2.MapReduce 作業(yè)中,對(duì) Map 輸出的中間結(jié)果集壓縮。實(shí)現(xiàn)方式如下:
1)可以在 core-site.xml 文件中配置,代碼如下
圖 2. core-site.xml 代碼示例
圖 2. core-site.xml 代碼示例
2)使用 Java 代碼指定
1
2
conf.setCompressMapOut(true);
conf.setMapOutputCompressorClass(GzipCode.class);
最后一行代碼指定 Map 輸出結(jié)果的編碼器。
3.MapReduce 作業(yè)中,對(duì) Reduce 輸出的最終結(jié)果集壓。實(shí)現(xiàn)方式如下:
1)可以在 core-site.xml 文件中配置,代碼如下
圖 3. core-site.xml 代碼示例
圖 3. core-site.xml 代碼示例
2)使用 Java 代碼指定
1
2
conf.setBoolean(“mapred.output.compress”,true);
conf.setClass(“mapred.output.compression.codec”,GzipCode.class,CompressionCodec.class);
最后一行同樣指定 Reduce 輸出結(jié)果的編碼器。
壓縮框架
我們前面已經(jīng)提到過關(guān)于壓縮的使用方式,其中第一種就是將壓縮文件直接作為入口參數(shù)交給 MapReduce 處理,MapReduce 會(huì)自動(dòng)根據(jù)壓縮文件的擴(kuò)展名來自動(dòng)選擇合適解壓器處理數(shù)據(jù)。那么到底是怎么實(shí)現(xiàn)的呢?如下圖所示:
圖 4. 壓縮實(shí)現(xiàn)情形
圖 4. 壓縮實(shí)現(xiàn)情形
我們?cè)谂渲?Job 作業(yè)的時(shí)候,會(huì)設(shè)置數(shù)據(jù)輸入的格式化方式,使用 conf.setInputFormat() 方法,這里的入口參數(shù)是 TextInputFormat.class。
TextInputFormat.class 繼承于 InputFormat.class,主要用于對(duì)數(shù)據(jù)進(jìn)行兩方面的預(yù)處理。一是對(duì)輸入數(shù)據(jù)進(jìn)行切分,生成一組 split,一個(gè) split 會(huì)分發(fā)給一個(gè) mapper 進(jìn)行處理;二是針對(duì)每個(gè) split,再創(chuàng)建一個(gè) RecordReader 讀取 split 內(nèi)的數(shù)據(jù),并按照
的形式組織成一條 record 傳給 map 函數(shù)進(jìn)行處理。此類在對(duì)數(shù)據(jù)進(jìn)行切分之前,會(huì)首先初始化壓縮解壓工程類 CompressionCodeFactory.class,通過工廠獲取實(shí)例化的編碼解碼器 CompressionCodec 后對(duì)數(shù)據(jù)處理操作。
下面我們來詳細(xì)的看一下從壓縮工廠獲取編碼解碼器的過程。
壓縮解壓工廠類 CompressionCodecFactory
壓縮解壓工廠類 CompressionCodeFactory.class 主要功能就是負(fù)責(zé)根據(jù)不同的文件擴(kuò)展名來自動(dòng)獲取相對(duì)應(yīng)的壓縮解壓器 CompressionCodec.class,是整個(gè)壓縮框架的核心控制器。我們來看下 CompressionCodeFactory.class 中的幾個(gè)重要方法:
1. 初始化方法
圖 5. 代碼示例
圖 5. 代碼示例
① getCodeClasses(conf) 負(fù)責(zé)獲取關(guān)于編碼解碼器 CompressionCodec.class 的配置信息。下面將會(huì)詳細(xì)講解。
② 默認(rèn)添加兩種編碼解碼器。當(dāng) getCodeClass(conf) 方法沒有讀取到相關(guān)的編碼解碼器 CompressionCodec.class 的配置信息時(shí),系統(tǒng)會(huì)默認(rèn)添加兩種編碼解碼器 CompressionCodec.class,分別是 GzipCode.class 和 DefaultCode.class。
③ addCode(code) 此方法用于將編碼解碼器 CompressionCodec.class 添加到系統(tǒng)緩存中。下面將會(huì)詳細(xì)講解。
2. getCodeClasses(conf)
圖 6. 代碼示例
圖 6. 代碼示例
① 這里我們可以看,系統(tǒng)讀取關(guān)于編碼解碼器 CompressionCodec.class 的配置信息在 core-site.xml 中 io.compression.codes 下。我們看下這段配置文件,如下圖所示:
圖 7. 代碼示例
圖 7. 代碼示例
Value 標(biāo)簽中是每個(gè)編碼解碼 CompressionCodec.class 的完整路徑,中間用逗號(hào)分隔。我們只需要將自己需要使用到的編碼解碼配置到此屬性中,系統(tǒng)就會(huì)自動(dòng)加載到緩存中。
除了上述的這種方式以外,Hadoop 為我們提供了另一種加載方式:代碼加載。同樣最終將信息配置在 io.compression.codes 屬性中,代碼如下:
1
2
conf.set("io.compression.codecs","org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,com.hadoop.compression.lzo.LzopCodec");)
3. addCode(code) 方法添加編碼解碼器
圖 8. 代碼示例
圖 8. 代碼示例
addCodec(codec) 方法入口參數(shù)是個(gè)編碼解碼器 CompressionCodec.class,這里我們會(huì)首先接觸到它的一個(gè)方法。
① codec.getDefaultExtension() 方法看方法名的字面意思我們就可以知道,此方法用于獲取此編碼解碼所對(duì)應(yīng)文件的擴(kuò)展名,比如,文件名是 xxxx.gz2,那么這個(gè)方法的返回值就是“.bz2”,我們來看下 org.apache.hadoop.io.compress.BZip2Codec 此方法的實(shí)現(xiàn)代碼:
圖 9. 代碼示例
圖 9. 代碼示例
② Codecs 是一個(gè) SortedMap 的示例。這里有個(gè)很有意思的地方,它將 Key 值,也就是通過 codec.getDefaultExtension() 方法獲取到的文件擴(kuò)展名進(jìn)行了翻轉(zhuǎn),舉個(gè)例子,比如文件名擴(kuò)展名“.bz2”,將文件名翻轉(zhuǎn)之后就變成了“2zb.”。
系統(tǒng)加載完所有的編碼解碼器后,我們可以得到這樣一個(gè)有序映射表,如下:
圖 10. 代碼示例
圖 10. 代碼示例
現(xiàn)在編碼解碼器都有了,我們?cè)趺吹玫綄?duì)應(yīng)的編碼解碼器呢?看下面這個(gè)方法。
4. getCodec() 方法
此方法用于獲取文件所對(duì)應(yīng)的的編碼解碼器 CompressionCodec.class。
圖 11. 代碼示例
圖 11. 代碼示例
getCodec(Path) 方法的輸入?yún)?shù)是 Path 對(duì)象,保存著文件路徑。
① 將文件名翻轉(zhuǎn)。如 xxxx.bz2 翻轉(zhuǎn)成 2zb.xxxx。
② 獲取 codecs 集合中最接近 2zb.xxxx 的值。此方法有返回值同樣是個(gè) SortMap 對(duì)象。
在這里對(duì)返回的 SortMap 對(duì)象進(jìn)行第二次篩選。
編碼解碼器 CompressionCodec
剛剛在介紹壓縮解壓工程類 CompressionCodeFactory.class 的時(shí)候,我們多次提到了壓縮解壓器 CompressionCodecclass,并且我們?cè)谏衔闹羞€提到了它其中的一個(gè)用于獲取文件擴(kuò)展名的方法 getDefaultExtension()。
壓縮解壓工程類 CompressionCodeFactory.class 使用的是抽象工廠的設(shè)計(jì)模式。它是一個(gè)接口,制定了一系列方法,用于創(chuàng)建特定壓縮解壓算法。下面我們來看下比較重要的幾個(gè)方法:
1. createOutputStream() 方法對(duì)數(shù)據(jù)流進(jìn)行壓縮。
圖 12. 代碼示例
圖 12. 代碼示例
此方法提供了方法重載。
① 基于流的壓縮處理;
② 基于壓縮機(jī) Compress.class 的壓縮處理
2. createInputStream() 方法對(duì)數(shù)據(jù)流進(jìn)行解壓。
圖 13. 代碼示例
圖 13. 代碼示例
這里的解壓方法同樣提供了方法重載。
① 基于流的解壓處理;
② 基于解壓機(jī) Decompressor.class 的解壓處理;
關(guān)于壓縮/解壓流與壓縮/解壓機(jī)會(huì)在下面的文章中我們會(huì)詳細(xì)講解。此處暫作了解。
3. getCompressorType() 返回需要的編碼器的類型。
getDefaultExtension() 獲取對(duì)應(yīng)文件擴(kuò)展名的方法。前文已提到過,不再敖述。
壓縮機(jī) Compressor 和解壓機(jī) Decompressor
前面在編碼解碼器部分的 createInputStream() 和 createInputStream() 方法中我們提到過 Compressor.class 和 Decompressor.class 對(duì)象。在 Hadoop 的實(shí)現(xiàn)中,數(shù)據(jù)編碼器和解碼器被抽象成了兩個(gè)接口:
1. org.apache.hadoop.io.compress.Compressor;
2. org.apache.hadoop.io.compress.Decompressor;
它們規(guī)定了一系列的方法,所以在 Hadoop 內(nèi)部的編碼/解碼算法實(shí)現(xiàn)都需要實(shí)現(xiàn)對(duì)應(yīng)的接口。在實(shí)際的數(shù)據(jù)壓縮與解壓縮過程,Hadoop 為用戶提供了統(tǒng)一的 I/O 流處理模式。
我們看一下壓縮機(jī) Compressor.class,代碼如下:
圖 14. 代碼示例
圖 14. 代碼示例
① setInput() 方法接收數(shù)據(jù)到內(nèi)部緩沖區(qū),可以多次調(diào)用;
② needsInput() 方法用于檢查緩沖區(qū)是否已滿。如果是 false 則說明當(dāng)前的緩沖區(qū)已滿;
③ getBytesRead() 輸入未壓縮字節(jié)的總數(shù);
④ getBytesWritten() 輸出壓縮字節(jié)的總數(shù);
⑤ finish() 方法結(jié)束數(shù)據(jù)輸入的過程;
⑥ finished() 方法用于檢查是否已經(jīng)讀取完所有的等待壓縮的數(shù)據(jù)。如果返回 false,表明壓縮器中還有未讀取的壓縮數(shù)據(jù),可以繼續(xù)通過 compress() 方法讀取;
⑦ compress() 方法獲取壓縮后的數(shù)據(jù),釋放緩沖區(qū)空間;
⑧ reset() 方法用于重置壓縮器,以處理新的輸入數(shù)據(jù)集合;
⑨ end() 方法用于關(guān)閉解壓縮器并放棄所有未處理的輸入;
⑩ reinit() 方法更進(jìn)一步允許使用 Hadoop 的配置系統(tǒng),重置并重新配置壓縮器;
為了提高壓縮效率,并不是每次用戶調(diào)用 setInput() 方法,壓縮機(jī)就會(huì)立即工作,所以,為了通知壓縮機(jī)所有數(shù)據(jù)已經(jīng)寫入,必須使用 finish() 方法。finish() 調(diào)用結(jié)束后,壓縮機(jī)緩沖區(qū)中保持的已經(jīng)壓縮的數(shù)據(jù),可以繼續(xù)通過 compress() 方法獲得。至于要判斷壓縮機(jī)中是否還有未讀取的壓縮數(shù)據(jù),則需要利用 finished() 方法來判斷。
壓縮流 CompressionOutputStream 和解壓縮流 CompressionInputStream
前文編碼解碼器部分提到過 createInputStream() 方法返回 CompressionOutputStream 對(duì)象,createInputStream() 方法返回 CompressionInputStream 對(duì)象。這兩個(gè)類分別繼承自 java.io.OutputStream 和 java.io.InputStream。從而我們不難理解,這兩個(gè)對(duì)象的作用了吧。
我們來看下 CompressionInputStream.class 的代碼:
圖 15. 代碼示例
圖 15. 代碼示例
可以看到 CompressionOutputStream 實(shí)現(xiàn)了 OutputStream 的 close() 方法和 flush() 方法,但用于輸出數(shù)據(jù)的 write() 方法以及用于結(jié)束壓縮過程并將輸入寫到底層流的 finish() 方法和重置壓縮狀態(tài)的 resetState() 方法還是抽象方法,需要 CompressionOutputStream 的子類實(shí)現(xiàn)。
Hadoop 壓縮框架中為我們提供了一個(gè)實(shí)現(xiàn)了 CompressionOutputStream 類通用的子類 CompressorStream.class。
圖 16. 代碼示例
圖 16. 代碼示例
CompressorStream.class 提供了三個(gè)不同的構(gòu)造函數(shù),CompressorStream 需要的底層輸出流 out 和壓縮時(shí)使用的壓縮器,都作為參數(shù)傳入構(gòu)造函數(shù)。另一個(gè)參數(shù)是 CompressorStream 工作時(shí)使用的緩沖區(qū) buffer 的大小,構(gòu)造時(shí)會(huì)利用這個(gè)參數(shù)分配該緩沖區(qū)。第一個(gè)可以手動(dòng)設(shè)置緩沖區(qū)大小,第二個(gè)默認(rèn) 512,第三個(gè)沒有緩沖區(qū)且不可使用壓縮器。
圖 17. 代碼示例
圖 17. 代碼示例
在 write()、compress()、finish() 以及 resetState() 方法中,我們發(fā)現(xiàn)了壓縮機(jī) Compressor 的身影,前面文章我們已經(jīng)介紹過壓縮機(jī)的的實(shí)現(xiàn)過程,通過調(diào)用 setInput() 方法將待壓縮數(shù)據(jù)填充到內(nèi)部緩沖區(qū),然后調(diào)用 needsInput() 方法檢查緩沖區(qū)是否已滿,如果緩沖區(qū)已滿,將調(diào)用 compress() 方法對(duì)數(shù)據(jù)進(jìn)行壓縮。流程如下圖所示:
圖 18. 調(diào)用流程圖
圖 18. 調(diào)用流程圖
結(jié)束語
本文深入到 Hadoop 平臺(tái)壓縮框架內(nèi)部,對(duì)其核心代碼以及各壓縮格式的效率進(jìn)行對(duì)比分析,以幫助讀者在使用 Hadoop 平臺(tái)時(shí),可以通過對(duì)數(shù)據(jù)進(jìn)行壓縮處理來提高數(shù)據(jù)處理效率。當(dāng)再次面臨海量數(shù)據(jù)處理時(shí), Hadoop 平臺(tái)的壓縮機(jī)制可以讓我們事半功倍。
相關(guān)主題
Hadoop 在線 API
《Hadoop 技術(shù)內(nèi)幕深入解析 HADOOP COMMON 和 HDFS 架構(gòu)設(shè)計(jì)與實(shí)現(xiàn)原理》
developerWorks 開源技術(shù)主題:查找豐富的操作信息、工具和項(xiàng)目更新,幫助您掌握開源技術(shù)并將其用于 IBM 產(chǎn)品。
Linux系統(tǒng)查看當(dāng)前主機(jī)CPU、內(nèi)存、機(jī)器型號(hào)及主板信息:
查看CPU信息(型號(hào))
# cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
查看內(nèi)存信息
# cat /proc/meminfo
查看主板型號(hào):
# dmidecode |grep -A16 "System Information$"
查看機(jī)器型號(hào)
# dmidecode | grep "Product Name"
查看當(dāng)前操作系統(tǒng)內(nèi)核信息
# uname -a
查看當(dāng)前操作系統(tǒng)發(fā)行版信息
# cat /etc/issue | grep Linux
本文介紹Hadoop YARN最近版本中增加的幾個(gè)非常有用的特性,包括:
(1)ResourceManager HA
在apache hadoop 2.4或者CDH5.0.0版本之后,增加了ResourceManger HA特性,支持基于Zookeeper的熱主備切換,具體配置參數(shù)可以參考Cloudera的文檔:ResourceManager HA配置。
需要注意的是,ResourceManager HA只完成了第一個(gè)階段的設(shè)計(jì),即備ResourceManager啟動(dòng)后,會(huì)殺死之前正在運(yùn)行的Application,然后從共享存儲(chǔ)系統(tǒng)中讀取這些Application的元數(shù)據(jù)信息,并重新提交這些Application。啟動(dòng)ApplicationMaster后,剩下的容錯(cuò)功能就交給ApplicationMaster實(shí)現(xiàn)了,比如MapReduce的ApplicationMaster會(huì)不斷地將完成的任務(wù)信息寫到HDFS上,這樣,當(dāng)它重啟時(shí),可以重新讀取這些日志,進(jìn)而只需重新運(yùn)行那些未完成的任務(wù)。ResourceManager HA第二個(gè)階段的任務(wù)是,備ResourceManager接管主ResourceManager后,無需殺死那些正在運(yùn)行的Application,讓他們像任何事情沒有發(fā)生一樣運(yùn)行下去。
(2) 磁盤容錯(cuò)
在apache hadoop 2.4或者CDH5.0.0版本之后,增加了幾個(gè)對(duì)多磁盤非常友好地參數(shù),這些參數(shù)允許YARN更好地使用NodeManager上的多塊磁盤,相關(guān)jira為:YARN-1781,主要新增了三個(gè)參數(shù):
yarn.nodemanager.disk-health-checker.min-healthy-disks:NodeManager上最少保證健康磁盤比例,當(dāng)健康磁盤比例低于該值時(shí),NodeManager不會(huì)再接收和啟動(dòng)新的Container,默認(rèn)值是0.25,表示25%;
yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage:一塊磁盤的最高使用率,當(dāng)一塊磁盤的使用率超過該值時(shí),則認(rèn)為該盤為壞盤,不再使用該盤,默認(rèn)是100,表示100%,可以適當(dāng)調(diào)低;
yarn.nodemanager.disk-health-checker.min-free-space-per-disk-mb:一塊磁盤最少保證剩余空間大小,當(dāng)某塊磁盤剩余空間低于該值時(shí),將不再使用該盤,默認(rèn)是0,表示0MB。
(3)資源調(diào)度器
Fair Scheduler:Fair Scheduler增加了一個(gè)非常有用的新特性,允許用戶在線將一個(gè)應(yīng)用程序從一個(gè)隊(duì)列轉(zhuǎn)移到另外一個(gè)隊(duì)列,比如將一個(gè)重要作業(yè)從一個(gè)低優(yōu)先級(jí)隊(duì)列轉(zhuǎn)移到高優(yōu)先級(jí)隊(duì)列,操作命令是:bin/yarn application -movetoqueue appID -queue targetQueueName,相關(guān)jira為:YARN-1721。
Capacity Scheduler:Capacity Scheduler中資源搶占功能經(jīng)過了充分的測(cè)試,可以使用了。
原創(chuàng)文章,轉(zhuǎn)載請(qǐng)注明: 轉(zhuǎn)載自董的博客
本文鏈接地址: http://dongxicheng.org/mapreduce-nextgen/hadoop-yarn-recently-new-features/