SolrCloud是基于Solr和Zookeeper的分布式搜索方案,是正在開發中的Solr4.0的核心組件之一,它的主要思想是使用Zookeeper作為集群的配置信息中心。它有幾個特色功能:1)集中式的配置信息 2)自動容錯 3)近實時搜索 4)查詢時自動負載均衡 
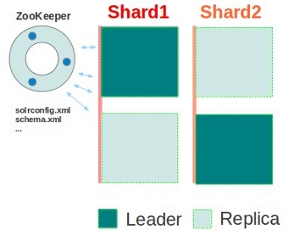
基本可以用上面這幅圖來概述,這是一個擁有4個Solr節點的集群,索引分布在兩個Shard里面,每個Shard包含兩個Solr節點,一個是Leader節點,一個是Replica節點,此外集群中有一個負責維護集群狀態信息的Overseer節點,它是一個總控制器。集群的所有狀態信息都放在Zookeeper集群中統一維護。從圖中還可以看到,任何一個節點都可以接收索引更新的請求,然后再將這個請求轉發到文檔所應該屬于的那個Shard的Leader節點,Leader節點更新結束完成,最后將版本號和文檔轉發給同屬于一個Shard的replicas節點。
下面我們來看一個簡單的SolrCloud集群的配置過程。
首先去https://builds.apache.org/job/Solr-trunk/lastSuccessfulBuild/artifact/artifacts/下載Solr4.0的源碼和二進制包,注意Solr4.0現在還在開發中,因此這里是Nightly Build版本。
示例1,簡單的包含2個Shard的集群
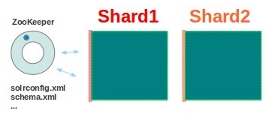
這個示例中,我們把一個collection的索引數據分布到兩個shard上去,步驟如下:
為了弄2個solr服務器,我們拷貝一份example目錄
然后啟動第一個solr服務器,并初始化一個新的solr集群,
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar
-DzkRun參數是啟動一個嵌入式的Zookeeper服務器,它會作為solr服務器的一部分,-Dbootstrap_confdir參數是上傳本地的配置文件上傳到zookeeper中去,作為整個集群共用的配置文件,-DnumShards指定了集群的邏輯分組數目。
然后啟動第二個solr服務器,并將其引向集群所在位置
cd example2
java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar
-DzkHost=localhost:9983就是指明了Zookeeper集群所在位置
我們可以打開http://localhost:8983/solr/collection1/admin/zookeeper.jsp 或者http://localhost:8983/solr/#/cloud看看目前集群的狀態,
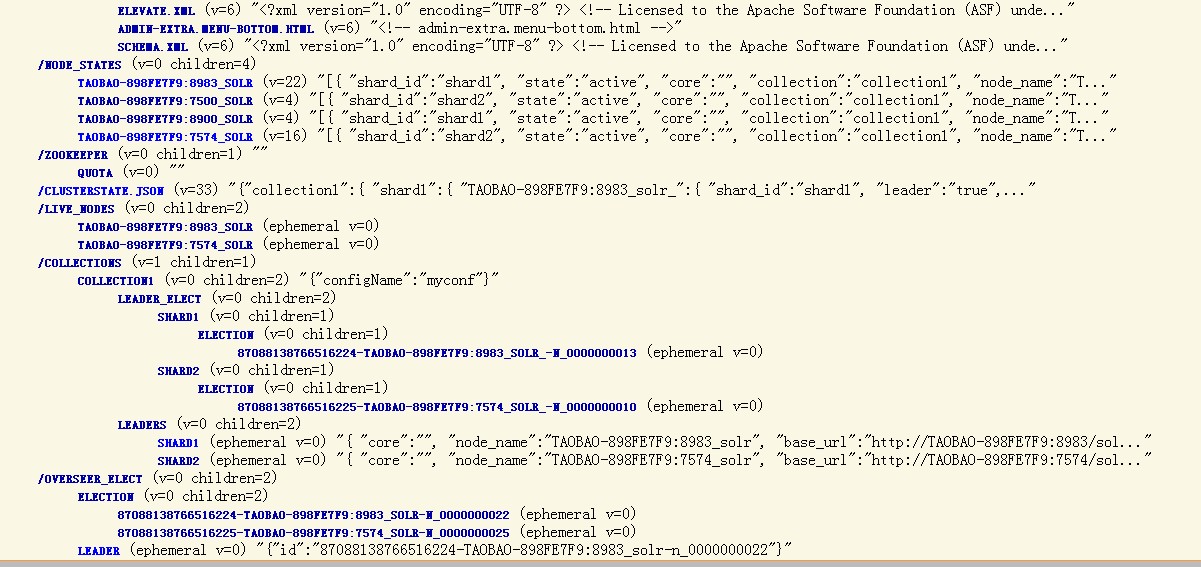
現在,我們可以試試索引一些文檔,
cd exampledocs
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar ipod_video.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar monitor.xml
java -Durl=http://localhost:8983/solr/collection1/update -jar post.jar mem.xml
最后,來試試分布式搜索吧:
http://localhost:8983/solr/collection1/select?q
Zookeeper維護的集群狀態數據是存放在solr/zoo_data目錄下的。
現在我們來剖析下這樣一個簡單的集群構建的基本流程:
先從第一臺solr服務器說起:
1) 它首先啟動一個嵌入式的Zookeeper服務器,作為集群狀態信息的管理者,
2) 將自己這個節點注冊到/node_states/目錄下
3) 同時將自己注冊到/live_nodes/目錄下
4)創建/overseer_elect/leader,為后續Overseer節點的選舉做準備,新建一個Overseer,
5) 更新/clusterstate.json目錄下json格式的集群狀態信息
6) 本機從Zookeeper中更新集群狀態信息,維持與Zookeeper上的集群信息一致
7)上傳本地配置文件到Zookeeper中,供集群中其他solr節點使用
8) 啟動本地的Solr服務器,
9) Solr啟動完成后,Overseer會得知shard中有第一個節點進來,更新shard狀態信息,并將本機所在節點設置為shard1的leader節點,并向整個集群發布最新的集群狀態信息。
10)本機從Zookeeper中再次更新集群狀態信息,第一臺solr服務器啟動完畢。
然后來看第二臺solr服務器的啟動過程:
1) 本機連接到集群所在的Zookeeper,
2) 將自己這個節點注冊到/node_states/目錄下
3) 同時將自己注冊到/live_nodes/目錄下
4) 本機從Zookeeper中更新集群狀態信息,維持與Zookeeper上的集群信息一致
5) 從集群中保存的配置文件加載Solr所需要的配置信息
6) 啟動本地solr服務器,
7) solr啟動完成后,將本節點注冊為集群中的shard,并將本機設置為shard2的Leader節點,
8) 本機從Zookeeper中再次更新集群狀態信息,第二臺solr服務器啟動完畢。
示例2,包含2個shard的集群,每個shard中有replica節點
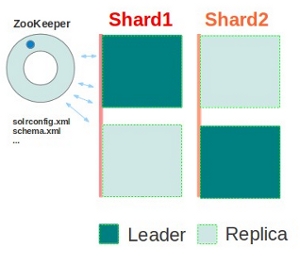
如圖所示,集群包含2個shard,每個shard中有兩個solr節點,一個是leader,一個是replica節點,
cp -r example exampleB
cp -r example2 example2B
cd exampleB
java -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar
我們可以打開http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4個節點的集群的狀態,
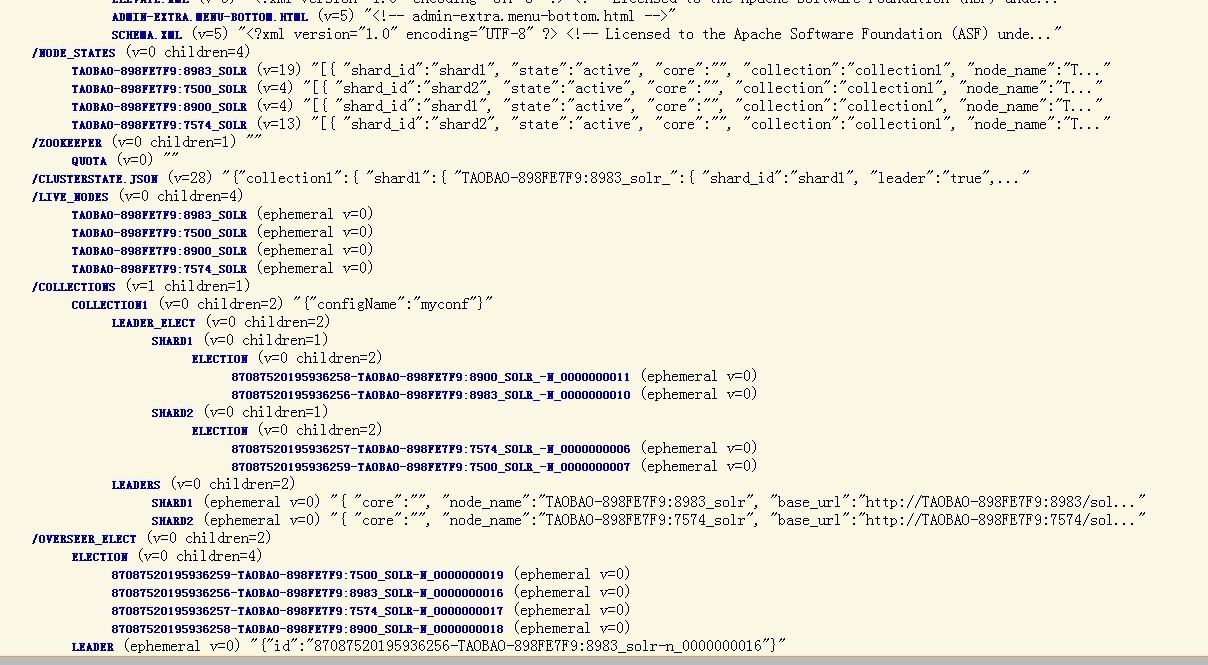
這個集群現在就具備容錯性了,你可以試著干掉一個Solr服務器,然后再發送查詢請求。背后的實質是集群的ov erseer會監測各個shard的leader節點,如果leader節點掛了,則會啟動自動的容錯機制,會從同一個shard中的其他replica節點集中重新選舉出一個leader節點,甚至如果overseer節點自己也掛了,同樣會自動在其他節點上啟用新的overseer節點,這樣就確保了集群的高可用性。
示例3 包含2個shard的集群,帶shard備份和zookeeper集群機制
上一個示例中存在的問題是:盡管solr服務器可以容忍掛掉,但集群中只有一個zookeeper服務器來維護集群的狀態信息,單點的存在即是不穩定的根源。如果這個zookeeper服務器掛了,那么分布式查詢還是可以工作的,因為每個solr服務器都會在內存中維護最近一次由zookeeper維護的集群狀態信息,但新的節點無法加入集群,集群的狀態變化也不可知了。因此,為了解決這個問題,需要對Zookeeper服務器也設置一個集群,讓其也具備高可用性和容錯性。
有兩種方式可選,一種是提供一個外部獨立的Zookeeper集群,另一種是每個solr服務器都啟動一個內嵌的Zookeeper服務器,再將這些Zookeeper服務器組成一個集群。 我們這里用后一種做示例:
cd example
java -Dbootstrap_confdir=./solr/conf -Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jar
cd example2
java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd exampleB
java -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
cd example2B
java -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar
我們可以打開http://localhost:8983/solr/collection1/admin/zookeeper.jsp 看看包含4個節點的集群的狀態,可以發現其實和上一個沒有任何區別。
后續的文章將從實現層面對SolrCloud這個分布式搜索解決方案進行進一步的深入剖析。
posted on 2012-07-04 18:40
SIMONE 閱讀(1063)
評論(0) 編輯 收藏 所屬分類:
solr