c++ difference from java
1. take charge of object management , negotiate ownershiop ,use scoped_ptr,
not to transfer other's ownership
2. use c++ template to express seperation corncern ,such as (static)polymorphy and policy
3. disable copy constructor and assign operator by yourself
4. polymorphy by pointer
5. 使用 template ,macro 取得類似動態語言的能力
6. 偏好無狀態的 函數
Myisam is preferred without transaction and little
update(delete)
Big than 4G datafile can user Myisam merge table.
InnoDB with auto_increment primary key is preferred.
Few storage process
Guess: 20m
records max per table , 500G
data max per tablespace , 256 tables per database (may problem)
Use prepared statement and batch
Optimize Your Queries For the Query Cache
// query cache does NOT work
$r = mysql_query("SELECT username FROM user WHERE signup_date >= CURDATE()");
// query cache works!
$today = date("Y-m-d");
$r = mysql_query("SELECT username FROM user WHERE signup_date >= '$today'");
EXPLAIN Your SELECT Queries
LIMIT 1 When Getting a Unique Row
Index and Use Same Column Types for Joins
Do Not ORDER BY RAND()
Avoid SELECT *
t is a good habit to always specify which
columns you need when you are doing your SELECT’s.
Use ENUM over VARCHAR
Use NOT NULL If You Can
Store IP Addresses as UNSIGNED INT (?)
Fixed-length (Static) Tables are Faster
Vertical Partitioning
Vertical Partitioning is the act of splitting your table
structure in a vertical manner for optimization reasons.
Example
1: You might have a users table that contains
home addresses, that do not get read often. You can choose to split your table
and store the address info on a separate table. This way your main users table
will shrink in size. As you know, smaller tables perform faster.
Example
2: You have a “last_login” field in your
table. It updates every time a user logs in to the website. But every update on
a table causes the query cache for that table to be flushed. You can put that
field into another table to keep updates to your users table to a minimum.
But you also need to make sure you don’t constantly need to
join these 2 tables after the partitioning or you might actually suffer
performance decline.
Split the Big DELETE or INSERT Queries
If you have some kind of maintenance script
that needs to delete large numbers of rows, just use the LIMIT clause to do it
in smaller batches to avoid this congestion.
Smaller Columns Are Faster
Use an Object Relational Mapper
f you do not need the time component, use
DATE instead of DATETIME.
Consider horizontally spitting many-columned tables if
they contain a lot of NULLs or rarely used columns.
Be an SQL programmer who thinks in sets, not procedural
programming paradigms
InnoDB can’t optimize SELECT COUNT(*) queries. Use counter
tables! That’s how to scale InnoDB.
Prefer MM with hive
refer :
http://blog.tuvinh.com/top-20-mysql-best-practices/
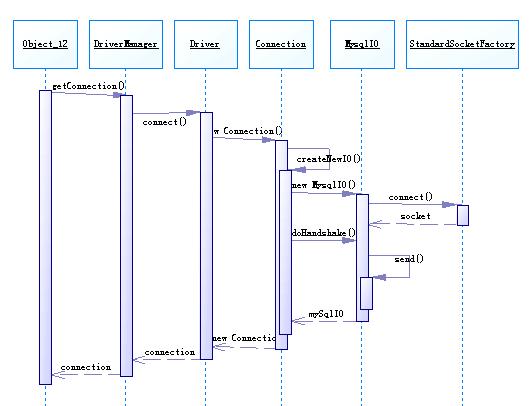
從時序圖中可以看到,createNewIO()就是新建了一個com.mysql.jdbc.MysqlIO,利用 com.mysql.jdbc.StandardSocketFactory來創建一個socket。然后就由這個mySqlIO來與MySql服務器進行握手(doHandshake()),這個doHandshake主要用來初始化與Mysql server的連接,負責登陸服務器和處理連接錯誤。在其中會分析所連接的mysql server的版本,根據不同的版本以及是否使用SSL加密數據都有不同的處理方式,并把要傳輸給數據庫server的數據都放在一個叫做packet的 buffer中,調用send()方法往outputStream中寫入要發送的數據。
useServerPreparedStmts置為true的話,mysql驅動可以通過PreparedStatement的子類ServerPreparedStatement來實現真正的PreparedStatement的功能
第一位表示數據包的開始位置,就是數據存放的起始位置,一般都設置為0,就是從第一個位置開始。第二和第三個字節標識了這個數據包的大小,注意的是,這個大小是出去標識的4個字節的大小,對于非最后一個數據包來說,這個大小都是一樣的,就是splitSize,也就是maxThreeBytes,它的值是 255 * 255 * 255。
最后一個字節中存放的就是數據包的編號了,從0開始遞增。
在標識位設置完畢之后,就可以把255 * 255 * 255大小的數據從我們準備好的待發送數據包中copy出來了,注意,前4位已經是標識位了,所以應該從第五個位置開始copy數據
# packetToSend = compressPacket(headerPacket, HEADER_LENGTH,
# splitSize, HEADER_LENGTH);
LoadBalancingConnectionProxy
package java.lang.reflect 。 proxy .
http://developer.51cto.com/art/200907/137823.htm
http://dev.mysql.com/doc/refman/5.1/en/connector-j-reference-implementation-notes.html
PreparedStatements are implemented by the driver, as MySQL
does not have a prepared statement feature. Because of this,
the driver does not implement
getParameterMetaData() or
getMetaData() as it would require the
driver to have a complete SQL parser in the client.
Starting with version 3.1.0 MySQL Connector/J, server-side
prepared statements and binary-encoded result sets are used
when the server supports them.
但這是不是說PreparedStatement沒用呢?不是的,PreparedStatement有其他的好處:
1.代碼的可讀性和可維護性
2.最重要的一點是極大地提高了安全性,可以防止SQL注入
然后我又看了一些網上其他人的經驗,基本和我的判斷一致,有兩點要特別提請大家注意:
1.并不是說PreparedStatement在所有的DB上都不會提高效率,PreparedStatement需要服務器端的支持,比如在
Oracle上就會有顯著效果。上面說的測試都是在MySQL上測試的,我找到了一個MySQL架構師的帖子,比較明確地說明了MySQL不支持
PreparedStatement。
2.即便PreparedStatement不能提高性能,在少數使用時甚至會降低效率,但仍然應該使用PreparedStatement!因為其他好
處實在是太大了!當然,當SQL查詢比較復雜時,可能PreparedStatement好處會更大,只是我沒有測試,不敢肯定。
3.既然PreparedStatement不能提高效率,那PreparedStatement Pool也就沒有必要了。但可以看到每次新建Connection的開銷實在很大,因此Connection Pool絕對必要。
download ,annatation and tools 兩個項目。
添加相關的 jar.
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="master.classpath" />
<target name="create_table">
<hibernatetool destdir="${script.dir}">
<annotationconfiguration configurationfile="src/hibernate.cfg.xml" />
<hbm2ddl export="false" create="true" delimiter=";" format="true" outputfilename="create-tables.sql" />
</hibernatetool>
</target>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="logi">
<property name="show_sql">true</property>
<mapping class="com.tt.logi.target.Target"/>
</session-factory>
</hibernate-configuration>
import java.io.Serializable;
import javax.persistence.Basic;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Target implements Serializable{
private Long id;
private String name;
@Id
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
@Basic
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
wget ftp://ftp.jaist.ac.jp/pub/mysql/Downloads/MySQL-5.1/mysql-5.1.41.tar.gz
tar -xzf
./configure --prefix=/usr/local/mysql51m --without-debug --enable-local-infile --enable-assembler --enable-thread-safe-client --with-plugins=all
make
su -
make install
groupadd mysql
useradd -g mysql mysql
bin/mysql_install_db --user=mysql --datadir=/var/lib/mysql51m/data
chown -R mysql /var/lib/mysql51m/
chgrp -R mysql /var/lib/mysql51m/
cp share/mysql/my-innodb-heavy-4G.cnf my.cnf
vi my.cnf
datadir = /var/lib/mysql51m/data
.bin/mysqld_safe --defaults-file=/usr/local/mysql51m/my.cnf &
bin/mysql --defaults-file=my.cnf -uroot
./mysqladmin -u root password ‘humber’
grant all on *.* to root@% identified by 'humber'
default-character-set=utf8
init_connect='SET NAMES utf8'
default-storage-engine = INNODB
jmap -heap 16761
jstat -gcutil 16761
jmap -finalizerinfo 16761
jmap -histo 16761
jstack -l 16761
jinfo 16761
Examine the fatal error log file. Default file name is hs_err_pidpid.log in the working-directory.
-XX:+HeapDumpOnOutOfMemoryError
java -agentlib:hprof=heap=dump,format=b application
$ jmap -dump:format=b,file=snapshot.jmap process-pid
1、在jvm啟動時加上:
-agentlib:hprof=heap=sites,file=heap.txt
,然后執行一段時間后執行 kill -3
<pid>,就可以獲取jvm的內存鏡像。類似的通過-agentlib:hprof=cpu=samples,file=cpu.txt查
看cpu的狀況。
http://java.sun.com/javase/6/webnotes/trouble/other/matrix6-Unix.html
Quick Troubleshooting Tips on Solaris OS and Linux for Java SE 6
This "Quick Start Guide" gives you some quick tips for troubleshooting.
The subsections list some typical functions that can help you in
troubleshooting, including one or more ways to get the
information or perform the action.
These tips are organized as follows:
Hung, Deadlocked, or Looping Process
Post-mortem Diagnostics, Memory Leaks
Monitoring
Actions on a Remote Debug Server
Other Functions
Hung, Deadlocked, or Looping Process
- Print thread stack for all Java threads:
- Control-"
- kill -QUIT pid
- jstack pid (or jstack -F pid if jstack pid does not respond)
- Detect deadlocks:
- Request deadlock detection: JConsole tool, Threads tab
- Print information on deadlocked threads: Control-"
- Print list of concurrent locks owned by each thread: -XX:+PrintConcurrentLocks set, then Control-"
- Print lock information for a process: jstack -l pid
- Get a heap histogram for a process:
- Start Java process with -XX:+PrintClassHistogram, then Control-"
- jmap -histo pid (with -F option if pid does not respond)
- Dump Java heap for a process in binary format to file:
- jmap -dump:format=b,file=filename pid (with -F option if pid does not respond)
- Print shared object mappings for a process:
- Print heap summary for a process:
- Print finalization information for a process:
- Attach the command-line debugger to a process:
- jdb -connect sun.jvm.hotspot.jdi.SAPIDAttachingConnector:pid=pid
Post-mortem Diagnostics, Memory Leaks
- Examine the fatal error log file. Default file name is hs_err_pidpid.log in the working-directory.
- Create a heap dump:
- Start the application with HPROF enabled: java -agentlib:hprof=file=file,format=b application; then Control-"
- Start the application with HPROF enabled: java -agentlib:hprof=heap=dump application
- JConsole tool, MBeans tab
- Start VM with -XX:+HeapDumpOnOutOfMemoryError; if OutOfMemoryError is thrown, VM generates a heap dump.
- Browse Java heap dump:
- Dump Java heap from core file in binary format to a file:
- jmap -dump:format=b,file=filename corefile
- Get a heap histogram for a process:
- Start Java process with -XX:+PrintClassHistogram, then Control-"
- jmap -histo pid (with -F option if pid does not respond)
- Get a heap histogram from a core file:
- Print shared object mappings from a core file:
- Print heap summary from a core file:
- Print finalization information from a core file:
- jmap -finalizerinfo corefile
- Print Java configuration information from a core file:
- Print thread trace from a core file:
- Print lock information from a core file:
- Attach the command-line debugger to a core file on the same machine:
- jdb -connect sun.jvm.hotspot.jdi.SACoreAttachingConnector:javaExecutable=path,core=corefile
- Attach the command-line debugger to a core file on a different machine:
- On the machine with the core file: jsadebugd path corefile
and on the machine with the debugger: jdb -connect
sun.jvm.hotspot.jdi.SADebugServerAttachingConnector:debugServerName=machine
- libumem can be used to debug memory leaks.
Monitoring
Note: The vmID argument for the jstat command is the virtual machine identifier.
See the jstat man page for a detailed explanation.
- Print statistics on the class loader:
- Print statistics on the compiler:
- Compiler behavior: jstat -compiler vmID
- Compilation method statistics: jstat -printcompilation vmID
- Print statistics on garbage collection:
- Summary of statistics: jstat -gcutil vmID
- Summary of statistics, with causes: jstat -gccause vmID
- Behavior of the gc heap: jstat -gc vmID
- Capacities of all the generations: jstat -gccapacity vmID
- Behavior of the new generation: jstat -gcnew vmID
- Capacity of the new generation: jstat -gcnewcapacity vmID
- Behavior of the old and permanent generations: jstat -gcold vmID
- Capacity of the old generation: jstat -gcoldcapacity vmID
- Capacity of the permanent generation: jstat -gcpermcapacity vmID
- Monitor objects awaiting finalization:
- JConsole tool, VM Summary tab
- jmap -finalizerinfo pid
- getObjectPendingFinalizationCount method in java.lang.management.MemoryMXBean class
- Monitor memory:
- Heap allocation profiles via HPROF: java -agentlib:hprof=heap=sites
- JConsole tool, Memory tab
- Control-" prints generation information.
- Monitor CPU usage:
- By thread stack: java -agentlib:hprof=cpu=samples application
- By method: java -agentlib:hprof=cpu=times application
- JConsole tool, Overview and VM Summary tabs
- Monitor thread activity:
- JConsole tool, Threads tab
- Monitor class activity:
- JConsole tool, Classes tab
Actions on a Remote Debug Server
First, attach the debug daemon jsadebugd, then execute the command:
- Dump Java heap in binary format to a file: jmap -dump:format=b,file=filename hostID
- Print shared object mappings: jmap hostID
- Print heap summary : jmap -heap hostID
- Print finalization information : jmap -finalizerinfo hostID
- Print lock information : jstack -l hostID
- Print thread trace : jstack hostID
- Print Java configuration information: jinfo hostID
Other Functions
- Interface with the instrumented Java virtual machines:
- Monitor for the creation and termination of instrumented VMs: jstatd daemon
- List the instrumented VMs: jps
- Provide interface between remote monitoring tools and local VMs: jstatd daemon
- Request garbage collection: JConsole tool, Memory tab
- Print Java configuration information from a running process:
- Dynamically set, unset, or change the value of certain Java VM flags for a process:
- Print command-line flags passed to the VM:
- Print Java system properties:
- Pass a Java VM flag to the virtual machine:
- jconsole -Jflag ...
- jhat -Jflag ...
- jmap -Jflag ...
- Print statistics of permanent generation of Java heap, by class loader:
- Report on monitor contention.
- java -agentlib:hprof=monitor=y application
- Evaluate or execute a script in interactive or batch mode:
- Interface dynamically with an MBean, via JConsole tool, MBean tab:
- Show tree structure.
- Set an attribute value.
- Invoke an operation.
- Subscribe to notification.
- Run interactive command-line debugger:
- Launch a new VM for the class: jdb class
- Attach debugger to a running VM: jdb -attach address
http://www.tkk7.com/justinchen/archive/2009/01/08/248738.html
netstat -n | awk '/^tcp/ {++state[$NF]} END {for(key in state) print key,""t",state[key]}'
set nocompatible
set autoindent
set smartindent
set ignorecase
syntax enable
set wrap
set showmatch
set foldmarker={{{,}}}
set tabstop=4
set shiftwidth=4
set ruler
set expandtab
set backspace=eol,start,indent
set whichwrap+=<,>,h,l
set nobackup
setlocal noswapfile
set bufhidden=hide
syntax on
set tags=./tags,~/apsara/tags
set path+=/usr/include/c++/**,~/apsara/include/**
filetype plugin on
filetype indent on
autocmd filetype java,c,cpp setlocal textwidth=100
set pastetoggle=<F7>
nmap <F2> :set nonumber!<CR>
nmap <F8> :TlistToggle<CR>
imap <F11> <C-x><C-p>
map <F12> :!ctags -R --c++-kinds=+p --fields=+iaS --exclude=build --extra=+q .<CR>
map <F6> :w<CR>
imap <F6> <ESC>:w<CR>a
map <F3> /<C-R><C-W><CR>
有 c support 支持,很棒。
-
避免對shared_ptr所管理的對象的直接內存管理操作,以免造成該對象的重釋放
shared_ptr并不能對循環引用的對象內存自動管理(這點是其它各種引用計數管理內存方式的通病)。
-
不要構造一個臨時的shared_ptr作為函數的參數。
如下列代碼則可能導致內存泄漏:
void test()
{
foo(boost::shared_ptr<implementation>(new implementation()),g());
}
正確的用法為:
void test()
{
boost::shared_ptr<implementation> sp (new implementation());
foo(sp,g());
}
-
Employee boss("Morris, Melinda", 83000);
Employee* s = &boss;
This is usually not a good idea. As a rule of thumb, C++ pointers should
only refer to objects allocated wth new.
copy:http://www.diybl.com/course/3_program/c++/cppjs/20090403/163770.html
抄錄備忘:
其實沒有.h也能很好的工作,但是當你發現一個外部鏈接的函數或外部變量,需要許多份
聲明,因為c++這種語言,在使用函數和變量的時候,必須將他聲明,為何要聲明?聲明之后才
知道他的規格,才能更好的發現不和規格的部分.你別妄想一個編譯單元,會自動從另一個
編譯單元那里得到什么信息,知道你是如何定義這個函數的.
所以說,只要使用到該函數的單元,就必須寫一份聲明在那個.cpp里面,這樣是不是很麻煩,
而且,如果要修改,就必須一個一個修改.這真讓人受不了.
.h就是為了解決這個問題而誕生,他包含了這些公共的東西.然后所有需要使用該函數的.cpp,只需要
用#include包含進去便可.以后需要修改,也只是修改一份內容.
請注意不要濫用.h,.h里面不要寫代碼,.h不是.cpp的倉庫,什么都塞到里面.
如果在里面寫代碼,當其他.cpp包含他的時候,就會出現重復定義的情況,
比如將函數func(){printf};放到頭文件a.h,里面還有一些a.cpp需要的聲明等;
然后你發現b.cpp需要用到a.cpp里面的一個函數,就很高興的將a.h包含進來.
注意,#include并不是什么申請指令,他就是將指定的文件的內容,原封不動的拷貝
進來.
這時候實際上a.cpp和b.cpp都有一個func()函數的定義.
如果這個函數是內部鏈接static的話,還好,浪費了一倍空間;
如果是extern,外部鏈接(這個是默認情況),那么根據在同一個程序內不可出現
同名函數的要求,連接器會毫不留情給你一個連接錯誤!
http://www.cnblogs.com/shelvenn/archive/2008/02/02/1062446.html
一. Perspective and Metaphor
Platform
Kernel
Framework
二. Philosophy and discipline
Be aware of context
Extreme maintenance
Be pragmatic
Extreme abstract: Program to an interface (abstraction), not an implementation
Extreme separation of concerns
Extreme readability
Testability
No side effect
Do not repeat yourself
三. Principle
DIP ,dependency inversion of control
OCP , open close
LSP , liskov substitute
ISP , interface segregation
SRP , single responsibility
LKP, Lease knowledge principle
四. design pattern
Construction
Behavior
Structure
五. anti-pattern、bad smell
Long method
Diverse change
Repeated code
Talk to stranger
Pre optimize
六. algorithms
nLongN
Divided and conqueror
七. architecture
Hierarchal
Pipes and filter
Micro kernel
Broker
Black Board
Interpreter
八. Distributed & concurrent
What to concurrent
Scalability
Stretch key dimensions to see what breaks
九. languages
Ruby
Erlang
assemble
C
C++
Java
Python
Scala
Be ware of different program paradigms.
十. Performance
Minimize remote calls and other I/O
Speed-up data conversion
release resource as soon as possible
十一. architectures' future
軟件設計思想的發展邏輯,大致是提高抽象程度 ,separation of concern 程度。
fn(design )= fn1(abstraction )+ fn2(separation of concern).
由于大規模數據處理時代的來臨,下一代設計范式的重點:
1. 將是如何提高distributed(--concurrent) programing 的抽象程度 和 separation of concern 程度。
2. dsl ,按照以上的公式,也確實是一個好的方向。
十二. Reference
<art agile software development>
<prerefactor>
<design patterns>
<beautiful architecture>
<refactor>
<pattern oriented software architecture>
<extreme software development>
<beautiful code>
<patterns for parallel programming>
<java concurrent programming in practice>
<java performance tuning>
<the definite guide to hadoop>
<greenplum>
<DryadLINQ>
<software architecture in practice>
<97 things architecture should known>
http://en.wikipedia.org/wiki/Programming_paradigm
拷貝
mingliu.ttc simsun.ttf SURSONG.TTF tahomabd.ttf tahoma.ttf verdanab.ttf verdanai.ttf verdana.ttf verdanaz.ttf
#mv simsun.ttc /usr/share/fonts/local/simsun.ttf
#cd /usr/share/fonts/local/
sudo mkfontscale
sudo mkfontdir
sudo fc-cache
cp fonts.scale fonts.dir
sudo chmod 755 *
sudo chkfontpath --add /usr/share/fonts/local/
#/etc/init.d/xfs restart
查檢是否安裝成功
fc-list |grep Sim
NSimSun:style=Regular
SimSun:style=Regular
SimSun\-PUA:style=Regular
experience learned.
1. first think algorithm before concurrent
2. first solve top problem
3. memory can be problem with huge data processing
4. not to use refletion frequently
5. prefering strategy that can optimize both cpu and memory .
technical
1. thread synchronizing is how to queuing
be sure to use "while(!Thread.currentThread.isInterupted())
2. prefer high level synchronizing facility to low level methodology such as await,notify
3. dedicated sorter is much faster
以前聽過用友的牛人關于軟件設計范型的時代劃分,記得不太準確,不過基本上是業界公認的。
大致上是:過程式、面向對象、組件、面向服務。
未來呢?我忘記了,抑或是 dsl ?
我以往也沒有自己的認識,不過,最近我有自己的看法
軟件設計思想的發展邏輯,大致是提高抽象程度 ,seperation of concern 程度。
fn(design )= fn1(abstraction )+ fn2(seperation of concern).
由于大規模數據處理時代的來臨,下一代設計范式的重點:
- 將是如何提高concurrent programing 的抽象程度 和 seperation of concern 程度。
- 至于dsl ,我研究不多,不過,按照以上的公式,也確實是一個好的方向。
對于英文詞語的使用,是因為,我想更能表達我的意思,不至于誤解。見諒。
歡迎批評指正!
最近看的東西,備忘。
Dryad
DryadLinq
GreenPlum。
技術上看:
Dryad 牛
商業上看,
只有microsoft(Dryad),oracle (?),ibm (?)
其他的cloud data engine 似乎難免被收購宿命,一如bea 。。。。etc .
?google (
Sawzall) ?amazon
?hadoop ,pig
中國:
?友友系統
Saas business
一. chain
customer : operator :application :feature: platform .
二. operator
三. application
office
erp
mall
game
四. feature
search engine
monitor system
security
dynamic language
special db system
special file system
五. platform
virtual computing resource system
cloud file system
cloud db system
cloud os
六. chance
big fish or small fish should find their way to survive.
安裝和配置簡述
* 英文指南
* 配置tomcat
o 修改 server.xml ,在connector 加 URIEncoding="UTF-8"
o 修改 catalina.sh ,加一行 CATALINA_OPTS="-DHUDSON_HOME=~/apprun/hudsonhome/ -Xms512m -Xmx512m"
+ 其中 HUDSON_HOME 是 hudson 的配置和運行文件所在地
o 修改 tomcat-users.xml
+ <role rolename="admin"/>
+ <user username="hudson" password="hudson" roles="admin"/>
* 把下載的hudson.war 放在 tomcat 的webapps 下,hudson 會自動啟動起來,部署就完成了
o 可以訪問,比如 http://****:18080/hudson/
* 安裝 jdk
* 安裝 ant
* 配置hudson
o 配置和管理需要登陸 ,login
o 打開管理頁面,比如 http://****:18080/hudson/configure
o 配置安全 ,Enable security ,兩個選項:Delegate to servlet container --〉Legacy mode
o 配置 jdk 路徑, 比如 /home/**/tools/jdk1.6.0_13/
o 配置 ant 路徑, 比如 /home/**/apprun/ant171
o 配置 System Admin E-mail Address ,//寫一個很多項目公用的email
o 記得 save
* 新建一個job
o 配置和管理需要登陸 ,login
o new job ,選項 :Build a free-style software project
o 配置 ,比如 :**:18080/hudson/job/icontent/configure
+ 填寫svn 路徑 ,比如 :http://svn.****
+ Build Triggers,選Poll SCM ,schedule 符合 cron 規則
+ Build ,invoke ant ,填寫 ant target
+ Post-build Actions ,選 E-mail Notification , Recipients 填寫郵件地址
* 配置linux 的環境變量
o vi .bash_profile
o JAVA_HOME=$HOME/tools/jdk1.6.0_13
o PATH=$JAVA_HOME/bin:$PATH:$HOME/bin:$HOME/apprun/ant171/bin
o LANG=zh_CN.GB2312 //encoding 與.java 源代碼文件的編碼一致 ,這樣javadoc 不會有警告
o LC_CTYPE=zh_CN.GB2312
easy!
great tool!
1. hibernate 變得不太重要了,jdbc 就很好
2. 數據庫不夠用了,bdb
3. bdb 不夠用了, 自己寫b+ tree
4. java 不行了,得用 c++
看來,這個轉變是個革命。搞不好得丟飯碗。
從想做一個創業者,到想做一個proferssional 。
<西津渡圖解軟件項目管理 〉從1年半之前,每當有新的感受,就修訂一些。為自己的成長作個備注吧。
code-block with mingw ,setup .
set path=c:\program file\code blocks\mingw\bin;%path%
bjam --toolset=gcc-3.4.5 --prefix=d:\boost\b137345 --build-type=complete install
很久沒有來blogjava 了。
一個原因是,關注的內容與blogjava 的東西,重疊的太少了。
不過,我也納悶,我該去哪里找自己的同好?
blogjava 在云計算,web2.0 ,這些前途領域,沒有什么內容。
struts,hibernate,spring, acegi,lucene 這些都是成熟的東西了。
說一下我最近用過的東西:
hadoop,hbase,zookeeper,深入研究了java concurrent.
下一步的方向是寫一個,distribute document oriented file system.
技術和互聯網的發展,絕對是web2.0,云計算,兩端厚的架構。blogjava 也該多這方面的內容了。
Conducting and Reviewing the Software Design Model
The design model resides at the core of the software engineering process. It is the place where quality is built into the software (and the place where quality is assessed. For this checklist, the more questions that elicit a negative response, the higher the risk that the analysis model will adequately serve its purpose. . For this checklist, the more questions that elicit a negative response, the higher the risk that the design model will not adequately serve its purpose.
General issues:
o Does the overall design implement all explicit requirements? Has a traceability table been developed?
設計對需求的匹配?
o Does the overall design achieve all implicit requirements?
o Is the design represented in a form that is easily understood by outsiders?
易理解?
o Is design notation standardized? Consistent?
o Does the overall design provide sufficient information for test case design?
可測試。
o Is the design created using recognizable architectural and procedural patterns?
常用的架構 和模式?
o Does the design strive to incorporate reusable components?
重用組件?
o Is the design modular?
模塊化
o Has the design defined both procedural and data abstractions that can be reused?
重用的過程 / 數據 抽象?
o Has the design been defined and represented in a stepwise fashion?
逐漸細化的表述?
o Has the resultant software architecture been partitioned for ease of implementation? Maintenance?
可部署性? 可維護性?
o Have the concepts of information hiding and functional independence been followed throughout the design?
封裝性?
o Has a Design Specification been developed for the software?
文檔?
For data design:
o Have data objected defined in the analysis model been properly translated into required data structured?
數據映射with analysis?
o Do the data structures contain all attributes defined in the analysis model?
數據屬性?
o Have any new data structures and/or attributes been defined at design time?
新的數據結構?
o How do any new data structures and/or attributes related to the analysis model and to overall user requirements?
用戶需求與數據結構匹配嗎?
o Have the simplest data structures required to do the job been chosen?
數據結構簡單嗎?
o Can the data structures be implemented directly in the programming language of choice?
編程語言適合數據結構?
o How are data communicated between software components?
軟件組件之間的數據交換?
o Do explicit data components (e.g., a database) exist? If so, what is their role?
數據庫?
For architectural design:
o Has a library of architectural styles been considered prior to the definition of the resultant software architecture?
架構模式?
o Has architectural tradeoff analysis been performed?
架構分析的tradeoff?
o Is the resultant software architecture a recognizable architectural style?
認可的架構風格?
o Has the architecture been exercised against existing usage scenarios?
架構有應用示例嗎?
o Has an appropriate mapping been used to translate the analysis model into the architectural model?
分析和架構之間的mapping?
o Can quality characteristics associated with the resultant architecture (e.g., a factored call-and-return architecture) be readily identified from information provided in the design model?
架構的質量特點?
For user interface design:
o Have the results of task analysis been documented?
o Have goals for each user task been identified?
o Has an action sequence been defined for each user task?
o Have various states of the interface been documented?
o Have objects and actions that appear within the context of the interface been defined?
o Have the three "golden rules" (SEPA, 5/e, p. 402) been maintained throughout the GUI design?
o Has flexible interaction been defined as a design criterion throughout the interface?
o Have expert and novice modes of interaction been defined?
o Have technical internals been hidden from the causal user?
o Is the on-screen metaphor (if any) consistent with the overall applications?
o Are icons clear and understandable?
o Is interaction intuitive?
o Is system response time consistent across all tasks?
o Has an integrated help facility been implemented?
o Are all error message displayed by the interface easy to understand? Do they help the user resolve the problem quickly?
o Is color being used effectively?
o Has a prototype for the interface been developed?
o Have user's impressions of the prototype been collected in an organized manner?
For component-level design:
* Have proof of correctness techniques (SEPA, 5/e, Chapter 26) been applied to all algorithms?
算法正確性?
* Has each algorithm been "desk-tested" to uncover errors? Is each algorithm correct?
算法?
* Is the design of the algorithm consistent with the data structured that the component manipulates?
算法?
* Have algorithmic design alternatives been considered? If yes, why was this design chosen?
替代算法考慮了嗎?
* Has the complexity of each algorithm been computed?
每個算法的復雜性考慮了嗎?
* Have structured programming constructs been used throughout?
結構好嗎?
西津渡最近在修改
99街購物搜索引擎,www.99jie.com
根據體會,修訂了圖解軟件項目管理一文。這是今年以來的第三次較大修訂。
有需要者請下載。
西津渡圖解軟件項目管理
下邊是目錄。
第一章 項目管理的目標
一、 產品,周期,成本的約束。
二、 關鍵路徑管理
三、 可行性分析很重要
四、 人際技巧
五、 談判技巧
第二章 項目過程
一、 計劃階段
二、 架構階段和技術攻關
三、 迭代階段
四、 結束階段
第三章 分析,形成specification
一、 最重要的是specification 發揮作用
二、 重要的創造性工作
三、 選擇適合的表達方式
四、 數據以及數據的key 和約束
五、 測試腳本
六、 Review ,評審
第四章 設計系統UI
一、 一幅圖勝過千句話
第五章 設計,code ,build ,test
第六章 部署和重構
第七章 風險
一、 分析風險
二、 技術風險
三、 所有的風險是人的風險,trust and capable
四、 記住50%以上的軟件項目以失敗告終
五、 所有的風險是管理的風險,遵循一套項目管理哲學
第八章 保持項目的進展
一、 對項目負責,做出決定
二、 讓進展可見,持續集成
三、執行,并檢查
四、 解決沖突,大家都是兄弟姐妹
五、 能擔當者是項目經理
六、 關鍵路徑的變更
第九章 總結經驗
第十章 一些效率關鍵指標
第十一章 項目管理工具
第十二章 參考
第十三章 口訣
http://www.xker.com/edu/dev/104/0652109570034579.html
十二、不要在循環中調用synchronized(同步)方法
方法的同步需要消耗相當大的資料,在一個循環中調用它絕對不是一個好主意。
例子:
import java.util.Vector;
public class SYN {
public synchronized void method (Object o) {
}
private void test () {
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i)); // violation
}
}
private Vector vector = new Vector (5, 5);
}
更正:
不要在循環體中調用同步方法,如果必須同步的話,推薦以下方式:
import java.util.Vector;
public class SYN {
public void method (Object o) {
}
private void test () {
synchronized{//在一個同步塊中執行非同步方法
for (int i = 0; i < vector.size(); i++) {
method (vector.elementAt(i));
}
}
}
private Vector vector = new Vector (5, 5);
}
十三、將try/catch塊移出循環
把try/catch塊放入循環體內,會極大的影響性能,如果編譯JIT被關閉或者你所使用的是一個不帶JIT的JVM,性能會將下降21%之多!
例子:
import java.io.FileInputStream;
public class TRY {
void method (FileInputStream fis) {
for (int i = 0; i < size; i++) {
try { // violation
_sum += fis.read();
} catch (Exception e) {}
}
}
private int _sum;
}
更正:
將try/catch塊移出循環
void method (FileInputStream fis) {
try {
for (int i = 0; i < size; i++) {
_sum += fis.read();
}
} catch (Exception e) {}
}
參考資料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.81 – 83
十九、不要在循環體中實例化變量
在循環體中實例化臨時變量將會增加內存消耗
例子:
import java.util.Vector;
public class LOOP {
void method (Vector v) {
for (int i=0;i < v.size();i++) {
Object o = new Object();
o = v.elementAt(i);
}
}
}
更正:
在循環體外定義變量,并反復使用
import java.util.Vector;
public class LOOP {
void method (Vector v) {
Object o;
for (int i=0;i<v.size();i++) {
o = v.elementAt(i);
}
}
}
二十一、盡可能的使用棧變量
如果一個變量需要經常訪問,那么你就需要考慮這個變量的作用域了。static? local?還是實例變量?訪問靜態變量和實例變量將會比訪問局部變量多耗費2-3個時鐘周期。
例子:
public class USV {
void getSum (int[] values) {
for (int i=0; i < value.length; i++) {
_sum += value[i]; // violation.
}
}
void getSum2 (int[] values) {
for (int i=0; i < value.length; i++) {
_staticSum += value[i];
}
}
private int _sum;
private static int _staticSum;
}
更正:
如果可能,請使用局部變量作為你經常訪問的變量。
你可以按下面的方法來修改getSum()方法:
void getSum (int[] values) {
int sum = _sum; // temporary local variable.
for (int i=0; i < value.length; i++) {
sum += value[i];
}
_sum = sum;
}
參考資料:
Peter Haggar: "Practical Java - Programming Language Guide".
Addison Wesley, 2000, pp.122 – 125
http://www.javafan.net/menu/jczs/200701/20070108185247.html
1). 簡單的認為 .append() 效率好于 "+" 是錯誤的!
2). 不要使用 new 創建 String
3). 注意 .intern() 的使用
4). 在編譯期能夠確定字符串值的情況下,使用"+"效率最高
5). 避免使用 "+=" 來構造字符串
6). 在聲明StringBuffer對象的時候,指定合適的capacity,不要使用默認值(18)
7). 注意以下二者的區別不一樣
- String s = "a" + "b";
- String s = "a";
s += "b";
關鍵點
1. 無論何時只要可能的話使用字符串字面量來常見字符串而不是使用new關鍵字來創建字符串。
2. 無論何時當你要使用new關鍵字來創建很多內容重復的字符串的話,請使用String.intern()方法。
3. +操作符會為字符串連接提供最佳的性能――當字符串是在編譯期決定的時候。
4. 如果字符串在運行期決定,使用一個合適的初期容量值初始化的StringBuffer會為字符串連接提供最佳的性能。
q16 版.
安裝后,把所有的dll 拷貝到system32.
經過一段時間的折騰。一堆東西能避免使用就避免使用。
castor, dwr, acegi, 幾乎扔掉。
spring ,hibernate 也只用在適當的場合。
struts2 ,也只用在適當的場合。
一些偷懶的技術,盡量避免。
opensession in view.
一直困擾于 indexSearcher 的重新 new ,query filter 的cache 沒了。
重讀solr ,發現非常好。也許我應該考慮用 solr 了。
Caching
- Configurable Query Result, Filter, and Document cache instances
- Pluggable Cache implementations
- Cache warming in background
-
When a new searcher is opened, configurable searches are run against it
in order to warm it up to avoid slow first hits. During warming, the
current searcher handles live requests.
- Autowarming in background
- The
most recently accessed items in the caches of the current searcher are
re-populated in the new searcher, enabing high cache hit rates across
index/searcher changes.
- Fast/small filter implementation
- User level caching with autowarming support
9-26
今天,我發現,我可以用不同的方式實現cache ,也許在我的情況下比solr 的方式更好。
在一臺 8G ,2 dual core cpu 的2u , struts2+spring+hibernate .
開源軟件,用什么樣的 proxy, cache, web container 達到最好的性能。
瓶頸在于:
tomcat 只能用到2g ram
經過研究,
xmx 在windows 2003,jdk1.5.06 ,1999M.
所以如果是一臺單純的web container server 就不要搞8G了, 1U 的4G ok.
需要用到那么高的性能場景,只能是兩臺1U做 banlance.
再次研究
用 session stick ,balance 2 個 tomcat ,應該可以達到較好的性能。
環境 apache + tomcat , ajp 連接。
apr
jvm 優化
nio , connector 優化。
c3p0.
情況下
用jmeter ,tomcat 到 1000 并發沒有問題。
發現一個問題: apache 的 250 個 worker 限制。
導致單純的 tomcat 性能更好。比用ajp.
一個 threadgroup, 3個http sample, 1000 ,5428。
看來,需要編譯 apache.
http://www.mchange.com/projects/c3p0/#configuration_properties
spring+hibernate
連接池
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"/>
<property name="jdbcUrl" value="jdbc:mysql://localhost:3306/openfire"/>
<property name="user" value="root"/>
<property name="password" value="password"/>
</bean>
</beans>
tomcat jndi:
<Resource auth="Container"
description="DB Connection"
driverClass="com.mysql.jdbc.Driver"
maxPoolSize="4"
minPoolSize="2"
acquireIncrement="1"
name="jdbc/TestDB"
user="test"
password="ready2go"
factory="org.apache.naming.factory.BeanFactory"
type="com.mchange.v2.c3p0.ComboPooledDataSource"
jdbcUrl="jdbc:mysql://localhost:3306/test?autoReconnect=true" />
建議:c3p0.propertyies
c3p0.acquireIncrement=5
c3p0.idleConnectionTestPeriod=1800
c3p0.initialPoolSize=5
c3p0.maxIdleTime=1000
c3p0.maxPoolSize=20
c3p0.maxStatements=100
c3p0.minPoolSize=5
just hibernate:
hibernate.connection.provider_class=org.hibernate.connection.C3P0ConnectionProvider
調優:在我的環境下
maxpoolSize 30, 1822 , 15, 1655 。 可能和測試過程有關。
maxStatement 加上, 3600。嚴重影響性能。
擴大 xms xmx 512 ,957
tree 結構很常見,當persist 到數據庫中。
有些操作,在db 中更好。
1。取得所有的葉子節點。
SELECT Name FROM Projects p
WHERE NOT EXISTS(
SELECT * FROM Projects
WHERE Parent=p.VertexId)
2。multilevel operation ,用數據庫的輔助表, 用triger 。
CREATE TABLE ProjectPaths(
VertexId INTEGER,
Depth INTEGER,
Path VARCHAR(300) 。
)
3. 用 hibernate 時,如果 stack over flow,考慮用 stack 代替recursive algrithm
public void traverseDepthFirst( AST ast )
{
// Root AST node cannot be null or
// traversal of its subtree is impossible.
if ( ast == null )
{
throw new IllegalArgumentException(
"node to traverse cannot be null!" );
}
// Map to hold parents of each
// AST node. Unfortunately the AST
// interface does not provide a method
// for finding the parent of a node, so
// we use the Map to save them.
Map parentNodes = new HashMap();
// Start tree traversal with first child
// of the specified root AST node.
AST currentNode = ast.getFirstChild();
// Remember parent of first child.
parentNodes.put( currentNode , ast );
// Iterate through nodes, simulating
// recursive tree traversal, and add them
// to queue in proper order for later
// linear traversal. This "flattens" the
// into a linear list of nodes which can
// be visited non-recursively.
while ( currentNode != null )
{
// Visit the current node.
strategy.visit( currentNode );
// Move down to current node's first child
// if it exists.
AST childNode = currentNode.getFirstChild();
// If the child is not null, make it
// the current node.
if ( childNode != null )
{
// Remember parent of the child.
parentNodes.put( childNode , currentNode );
// Make child the current node.
currentNode = childNode;
continue;
}
while ( currentNode != null )
{
// Move to next sibling if any.
AST siblingNode = currentNode.getNextSibling();
if ( siblingNode != null )
{
// Get current node's parent.
// This is also the parent of the
// sibling node.
AST parentNode = (AST)parentNodes.get( currentNode );
// Remember parent of sibling.
parentNodes.put( siblingNode , parentNode );
// Make sibling the current node.
currentNode = siblingNode;
break;
}
// Move up to parent if no sibling.
// If parent is root node, we're done.
currentNode = (AST)parentNodes.get( currentNode );
if ( currentNode.equals( ast ) )
{
currentNode = null;
}
}
}
參考:
http://wordhoard.northwestern.edu/userman/hibernatechanges.html
《Tansact Sql cookbook.》
一、one-many ,需要一個有序的list. 建議影射方式 :
private List _items;
<bag
name="items"
inverse="true" //盡量使用雙向關聯
order-by="DATE_TIME"
cascade="all">
<key column="BLOG_ID"/>
<one-to-many class="BlogItem"/>
</bag>
many-to-many ,建議用 set
二、one-to-one 適用
通過主鍵進行關聯
相當于把大表拆分為多個小表
例如把大字段單獨拆分出來,以提高數據庫操作的性能
三、composite element ,必須依賴的導航關系
<list name="lineItems" table="line_items">
<key column="order_id"/>
<list-index column="line_number"/>
<composite-element class="LineItem">
<property name="quantity"/>
<many-to-one name="product" column="product_id"/>
</composite-element>
</list>
四、 one-one formula , 很復雜,有點不明白
<class name="Person">
<id name="name"/>
<one-to-one name="address"
cascade="all">
<formula>name</formula>
<formula>'HOME'</formula>
</one-to-one>
<one-to-one name="mailingAddress"
cascade="all">
<formula>name</formula>
<formula>'MAILING'</formula>
</one-to-one>
</class>
<class name="Address" batch-size="2"
check="addressType in ('MAILING', 'HOME', 'BUSINESS')">
<composite-id>
<key-many-to-one name="person"
column="personName"/>
<key-property name="type"
column="addressType"/>
</composite-id>
<property name="street" type="text"/>
<property name="state"/>
<property name="zip"/>
</class>
五、繼承關系, per subclass table ,no discriminator ,joined-subclass
六、tree
拷貝: http://www.thogau.net/tutorials/tree/tutorial02-01.jsp
package net.thogau.website.model;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.lang.builder.EqualsBuilder;
import org.apache.commons.lang.builder.HashCodeBuilder;
import org.apache.commons.lang.builder.ToStringBuilder;
import org.apache.commons.lang.builder.ToStringStyle;
/**
* This class implements a persisted tree node.
*
* @author <a href="mailto:thogau@thogau.net">thogau</a>
*
* @struts.form include-all="false" extends="BaseForm"
* @hibernate.class table="node"
*/
public class Node extends BaseObject implements Serializable {
// mapped to primary key in node table
protected Long id;
protected String name;
protected Node parent = null;
protected List children = new ArrayList();
/**
* @hibernate.id column="id" generator-class="native" unsaved-value="null"
* @struts.form-field
*/
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
/**
* Returns the node name.
*
* @return String
*
* @hibernate.property column="name" not-null="true" unique="true"
* @struts.form-field
* @struts.validator type="required"
*
*/
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* Returns the node's children.
*
* @return List
*
* @hibernate.list cascade="all-delete-orphan" inverse="true"
* @hibernate.collection-one-to-many class="net.thogau.website.model.Node"
* @hibernate.collection-index column="position"
* @hibernate.collection-key column="parent_id"
* @struts.form-field
*/
public List getChildren() {
return children;
}
public void setChildren(List children) {
this.children = children;
}
/**
* Returns the position of the node in the children list (if it has parent).
* @return int
*
* @hibernate.property column="position"
*/
public int getPosition() {
try{
return parent.getChildren().indexOf(this);
}
catch(NullPointerException e){
// if it has no parent, position makes no sense
return -1;
}
}
public void setPosition(int position) { /* not used */ }
/**
* Returns the node's parent.
*
* @return Node
*
* @hibernate.many-to-one column = "parent_id" class="net.thogau.website.model.Node" cascade = "none"
* @hibernate.column name="parent_id"
*/
public Node getParent() {
return parent;
}
public void setParent(Node n) {
this.parent = n;
}
/**
* @see java.lang.Object#equals(Object)
*/
public boolean equals(Object object) {
if (!(object instanceof Node)) {
return false;
}
Node rhs = (Node) object;
return new EqualsBuilder().append(this.name, rhs.name).append(
this.children, rhs.children).append(this.parent, rhs.parent)
.append(this.id, rhs.id).isEquals();
}
/**
* @see java.lang.Object#hashCode()
*/
public int hashCode() {
return new HashCodeBuilder(1036586079, -537109207).append(this.name)
.append(this.parent.getName()).append(this.id)
.toHashCode();
}
/**
* @see java.lang.Object#toString()
*/
public String toString() {
return new ToStringBuilder(this, ToStringStyle.MULTI_LINE_STYLE)
.append("name", this.name).append("parent", this.parent)
.append("id", this.id).append("position", this.getPosition()).toString();
}
}
好像,equal ,hash 是必須的。
# /**
# * 樹形遍歷
# * 不用遞歸,用堆棧.
# * 這里只是做為例子,本人不建議把業務邏輯封裝在Entity層.
# */
# public List getVisitResults() {
# List l = new ArrayList();
# Stack s = new Stack();
# s.push(this);
# while (s.empty() == false) {
# Cat c = (Cat) s.pop();
# l.add(c);
# List children = c.getChildren();
# if (children != null) {
# for (int i = 0; i < hildren.size(); i++) {
# Cat cat = (Cat) children.get(i);
# s.push(cat);
# }//end for
# }//end if
# }//end while
# return l;
# }
searcher 新開后,cache 會失效。
所以,重新開 searcher 的頻率對于很重的訪問量來說,不能太頻繁。這樣查詢肯定有不能同步的問題。
對于不要求同步的場景來說,夠了。
繼續研究。
在 conf/catalina/localhost/ 建 solr.xml
jndi solr/home :
<Context docBase="D:\sourcecode\apache-solr\dist\solr.war" debug="0" crossContext="true" >
<Environment name="solr/home" type="java.lang.String" value="D:\sourcecode\solr-sample\solr" override="true" />
</Context>
solr/home 的結構
conf
data/index
清凈拳。
拳打六根清凈,念佛
拳打陰陽分明,悟空
拳打呼吸到腫,得道。
拳打恍恍惚惚,歸無。
tomcat6 , jetty6 采用 jsp2.1。
由于 nio 帶來的性能提升,tomcat6 不能被忽略。
辦法1:
http://www.devzuz.org/blogs/bporter/2006/08/05/1154706744655.html<ww:select list="#{'default' : 'Maven 2.x Repository', 'legacy' : 'Maven 1.x Repository'}" />
改用-------------------------------------------------------------
<ww:select list="#@java.util.HashMap@{'default' : 'Maven 2.x Repository', 'legacy' : 'Maven 1.x Repository'}" />
這樣 jsp2.1 el 就不會有問題了。
辦法2: 對于舊的程序,不愿意改了,可以向后兼容
http://today.java.net/lpt/a/272#backwards-compatibility必須用 Servlet 2.5 XSD.
<web-app xmlns="http://java.sun.com/xml/ns/javaee" version="2.5" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/javaee
http://java.sun.com/xml/ns/javaee/web-app_2_5.xsd">
<jsp-property-group>
<deferred-syntax-allowed-as-literal>
true
</deferred-syntax-allowed-as-literal>
</jsp-property-group>
或者在頁面中
<%@page language="java" deferredSyntaxAllowedAsLiteral="true" %>
辦法3 :不用 jsp2.1 el
> <jsp-config>
> <jsp-property-group>
> <url-pattern>*.jsp</url-pattern>
> <el-ignored>true</el-ignored>
> </jsp-property-group>
> </jsp-config>
http://www.mail-archive.com/dev@struts.apache.org/msg28920.html
我現在的疑問
在一個頁面中采用兩個 el 引擎,是否會對性能造成一定影響?
較小。
LoadModule cache_module modules/mod_cache.so
LoadModule disk_cache_module modules/mod_disk_cache.so
LoadModule mem_cache_module modules/mod_mem_cache.so
<IfModule mod_cache.c>
<IfModule mod_mem_cache.c>
CacheEnable mem /images
CacheEnable mem /styles
CacheEnable mem /scripts
MCacheSize 10240
MCacheMaxObjectCount 100
MCacheMinObjectSize 1
MCacheMaxObjectSize 2048
</IfModule>
</IfModule>
LoadModule proxy_http_module modules/mod_proxy_http.so
<VirtualHost *:80>
RewriteLogLevel 3
RewriteLog "f:/temp/logs/lelerewrite.log"
RewriteEngine on
RewriteRule ^(.*)\.html$ http://www.lele.com/ [P]
ProxyPass /images !
ProxyPass /styles !
ProxyPass /scripts !
ProxyPass / http://localhost:8082/
ProxyPassReverse / http://localhost:8082/
ServerName www.lele.com:8082
CustomLog logs/lele_access.log common
DocumentRoot "D:/apachedocroot/www.lele.com/"
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
一 、tomcat 中要配置:<connector ,proxy ,> .否則返回有問題。
二、 mod_proxy_ajp 在 apr 情況下性能應該比 mod_http_proxy 好。
關閉 缺省主機的 log
#customLog logs/access.log common
在 virtualhost 中加
CustomLog logs/lele_access.log common
LoadModule mod_rewrite
在 <virtualHost> 中
RewriteLogLevel 3
RewriteLog "f:/temp/logs/sosorewrite.log"
RewriteEngine on
RewriteRule ^(.*)\.html$ /index.php
一、修改 http.conf
loadmodule mod_proxy
loadmobule mod_proxy_ajp
增加
ProxyRequests Off
<Proxy *>
Order
deny,allow
Allow from all
</Proxy>
<VirtualHost *:80>
ProxyPass /images !
ProxyPass /styles !
ProxyPass /scripts !
ProxyPass / ajp://localhost:8009/
ProxyPassReverse / ajp://localhost:8009/
ServerName www.lele.com:8082
CustomLog logs/lele_access.log common
DocumentRoot "D:/apachedocroot/www.lele.com/"
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
tomcat 不用做修改。
安裝 tomcat apr, 性能會比較好。
一、 在 http.conf 末尾加
Listen 80
NameVirtualHost *:80
<VirtualHost *:80>
DocumentRoot "D:/apachedocroot/www.soso.com/"
ServerName www.soso.com
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
<VirtualHost *:80>
DocumentRoot "D:/apachedocroot/static.soso.com/"
ServerName static.soso.com
<Directory />
Options FollowSymLinks
AllowOverride None
Order allow,deny
Allow from all
</Directory>
</VirtualHost>
二、修改 hosts 文件
三、 httpd.ext -S 測試配置
只是愈多愈好。
配置 apache2.2.4 ,php 5.2.3.
1. 解壓到 c:\php
2. 拷貝 php.ini-dist 到 c:\windows 為 php.ini
** 不能用recommend**
3. 拷貝 php5ts.dll 到 c:\windows\system32
配置:apache ,http.conf
1. LoadModule php5_module "c:/php/php5apache2_2.dll"
** 對應apache2.2 必須用這個**
2. AddType application/x-httpd-php .php
3. if module dir_modle ,
DirectoryIndex index.php ,index.html
配置php.ini ,啟動 mysql
extension=php_mysql.dll
extension=php_mysqli.dll
測試
phpinfo.php
<? echo phpinfo(); ?>
ok.