????作者:江南白衣,原文出處:?http://www.tkk7.com/calvin/archive/2007/01/31/96844.html?,轉載請保留出處。
??? 如果說Google的搜索引擎是免費的早餐,Gmail們是免費的午餐的話,
??? http://labs.google.com/papers/ 就是Google給開發人員們的一份免費的晚餐。
??? 不過,咋看著一桌飯菜可能不知道從哪吃起,在自己不熟悉的領域啃英文也不是一件愉快的事情。
一、一份PPT與四份中文翻譯?
??? 幸好,有一位面試google不第的老兄,自我爆發搞了一份Google Interal的PPT:
??? http://cbcg.net/talks/googleinternals/index.html,大家鼠標點點就能跟著他匆匆過一遍google的內部架構。
???然后又有崮崮山路上走9遍(http://sharp838.mblogger.cn)與美人他爹(http://my.donews.com/eraera/),翻譯了其中最重要的四份論文:
二、Google帝國的技術基石
???? Google帝國,便建立在大約45萬臺的Server上,其中大部分都是"cheap x86 boxes"。而這45萬臺Server,則建立于下面的key infrastructure:
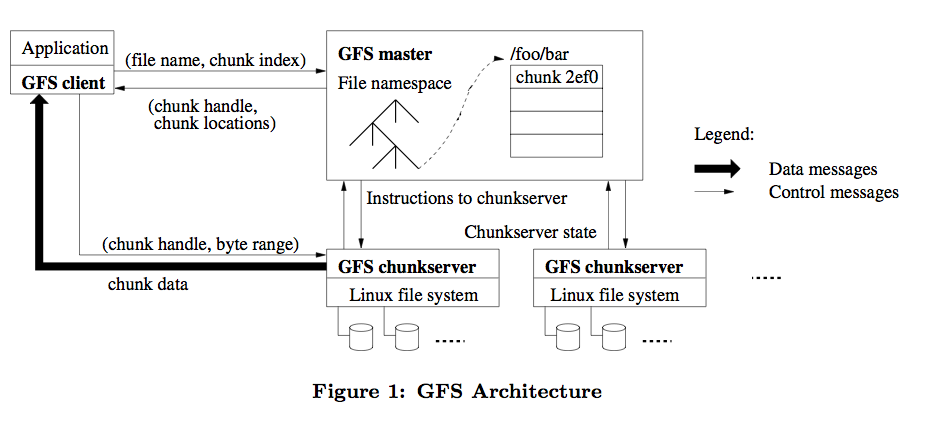
???? 1.GFS(Google File System):
???? GFS是適用于大規模分布式數據處理應用的分布式文件系統,是Google一切的基礎,它基于普通的硬件設備,實現了容錯的設計與極高的性能。????
???? 李開復說:Google最厲害的技術是它的storage。我認為學計算機的學生都應該看看這篇文章(再次感謝翻譯的兄弟)。????
????
???? 它以64M為一個Chunk(Block),每個Chunk至少存在于三臺機器上,交互的簡單過程見:
?????
???? 
???? 2.MapReduce
??? MapReduce是一個分布式處理海量數據集的編程模式,讓程序自動分布到一個由普通機器組成的超大集群上并發執行。像Grep-style job,日志分析等都可以考慮采用它。
????MapReduce的run-time系統會解決輸入數據的分布細節,跨越機器集群的程序執行調度,處理機器的失效,并且管理機器之間的通訊請求。這樣的模式允許程序員可以不需要有什么并發處理或者分布式系統的經驗,就可以處理超大的分布式系統得資源。
???? 我自己接觸MapReduce是Lucene->Nutch->Hadoop的路線。
???? Hadoop是Lucene之父Doug Cutting的又一力作,是Java版本的分布式文件系統與Map/Reduce實現。
???? Hadoop的文檔并不詳細,再看一遍Google這篇中文版的論文,一切清晰很多(又一次感謝翻譯的兄弟)。????
???? 孟巖也有一篇很清晰的博客:Map Reduce - the Free Lunch is not over?
???? 3.BigTable
???? BigTable 是Google Style的數據庫,使用結構化的文件來存儲數據。
???? 雖然不支持關系型數據查詢,但卻是建立GFS/MapReduce基礎上的,分布式存儲大規模結構化數據的方案。
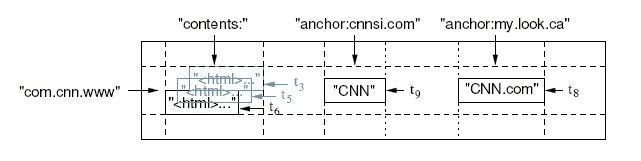
???? BigTable是一個稀疏的,多維的,排序的Map,每個Cell由行關鍵字,列關鍵字和時間戳三維定位.Cell的內容是一個不解釋的字符串。
???? 比如下表存儲每個網站的內容與被其他網站的反向連接的文本。
???? 反向的URL com.cnn.www(www.cnn.com)是行的關鍵字;contents列存儲網頁內容,每個內容有一個時間戳;因為有兩個反向連接,所以archor列族有兩列:anchor:cnnsi.com和anchhor:my.look.ca,列族的概念,使得表可以橫向擴展,archor的列數并不固定。
???
??? 為了并發讀寫,熱區,HA等考慮,BigTable當然不會存在逗號分割的文本文件中,,是存儲在一種叫SSTable的數據庫結構上,并有BMDiff和Zippy兩種不同側重點的壓縮算法。
4.Sawzall
??? Sawzall是一種建立在MapReduce基礎上的領域語言,可以被認為是分布式的awk。它的程序控制結構(if,while)與C語言無異,但它的領域語言語義使它完成相同功能的代碼與MapReduce的C++代碼相比簡化了10倍不止。
1????proto?"cvsstat.proto"
2????submits:?table?sum[hour:?int]?of?count:?int;
3????log:?ChangelistLog?=?input;
4????hour:?int?=?hourof(log.time)
5????emit?submits[hour]?<-?1;
????
???? 天書嗎?慢慢看吧。
???? 我們這次是統計在每天24小時里CVS提交的次數。
???? 首先它的變量定義類似Pascal? (i:int=0; 即定義變量i,類型為int,初始值為0)
???? 1:引入cvsstat.proto協議描述,作用見后。
???? 2:定義int數組submits 存放統計結果,用hour作下標。
???? 3.循環的將文件輸入轉換為ChangelistLog 類型,存儲在log變量里,類型及轉換方法在前面的cvsstat.proto描述。
???? 4.取出changlog中的提交時間log.time的hour值。
???? 5.emit聚合,在sumits結果數組里,為該hour的提交數加1,然后自動循環下一個輸入。
???? 居然讀懂了,其中1、2步是準備與定義,3、4步是Map,第5步是Reduce。
三.?小結:
? 本文只是簡單的介紹Google的技術概貌,大家知道以后除了可作談資外沒有任何作用,我們真正要學習的骨血,是論文里如何解決高并發,高可靠性等的設計思路和細節.....