
Nginx以其消耗資源少,承受并發量大,配置文件簡潔等特點,深受廣大sa們的喜歡,但是網上傳播的nginx 配置并沒有對做過多的優化。那么接下來,我就從某大型媒體網站的實際運維nginx優化角度,來給大家講解一下nginx主要優化的那些方面。
一、編譯方面優化
1、首先就要從configure 參數分析,根據網上最常用的configure 參數來說,大都是
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --with-http_ssl_module |
應該說這個參數是通用的,適用于各種環境的需要,比如php環境、純靜態文件環境、代理環境等等。編譯nginx程序文件大約有2M大小,跟全面優化的500多K,相差了不少。
下面我們修改一下參數,減少不必要的功能。
純靜態文件環境參數
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --without-http_fastcgi_module --without-http_proxy_module --without-http_upstream_ip_hash_module --without-http_autoindex_module --without-http_ssi_module --without-http_proxy_module --without-mail_pop3_module --without-mail_imap_module --without-mail_smtp_module --without-http_uwsgi_module --without-http_scgi_module --without-http_memcached_module |
去掉了在mail模塊fastcgi模塊 代理模塊 ip_hash模塊等,在純靜態文件用不到的模塊,現在看看nginx程序文件是不是少了一些。
Php環境的話,只需要去掉--with-http_fastcgi_module 重新編譯即可。
代理環境的話,只需要去掉--with_proxy_module重新編譯即可。
2、去掉nginx 默認的debug跟蹤設置。這一步需要修改nginx 源碼。
cd nginx-1.0.x
vim auto/cc/gcc |
第175行
前面加#注釋掉改行。
這樣的話,編譯的參數,就會減少到500多K的標準,這樣在大并發量的條件下,性能提升明顯。
二、利用google-perftools來優化高并發條件下的nginx
在32位系統下,可以直接安裝google-peftools,64位條件下,需要先安裝libunwind庫。然后再nginx configure 參數增加--with-google_perftools_module 重新編譯安裝nginx 。
這里以64位環境為準
1)安裝libunwind庫
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99.tar.gz
tar zxvf libunwind-0.99.tar.gz
cd libunwind-0.99/
CFLAGS=-fPIC ./configure –prefix=/usr
make CFLAGS=-fPIC
make CFLAGS=-fPIC install |
Nginx以其消耗資源少,承受并發量大,配置文件簡潔等特點,深受廣大sa們的喜歡,但是網上傳播的nginx 配置并沒有對做過多的優化。那么接下來,我就從某大型媒體網站的實際運維nginx優化角度,來給大家講解一下nginx主要優化的那些方面。
一、編譯方面優化
1、首先就要從configure 參數分析,根據網上最常用的configure 參數來說,大都是
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --with-http_ssl_module |
應該說這個參數是通用的,適用于各種環境的需要,比如php環境、純靜態文件環境、代理環境等等。編譯nginx程序文件大約有2M大小,跟全面優化的500多K,相差了不少。
下面我們修改一下參數,減少不必要的功能。
純靜態文件環境參數
| ./configure --prefix=/usr/local/nginx --user=www --group=www --with-http_stub_status_module --without-http_fastcgi_module --without-http_proxy_module --without-http_upstream_ip_hash_module --without-http_autoindex_module --without-http_ssi_module --without-http_proxy_module --without-mail_pop3_module --without-mail_imap_module --without-mail_smtp_module --without-http_uwsgi_module --without-http_scgi_module --without-http_memcached_module |
去掉了在mail模塊fastcgi模塊 代理模塊 ip_hash模塊等,在純靜態文件用不到的模塊,現在看看nginx程序文件是不是少了一些。
Php環境的話,只需要去掉--with-http_fastcgi_module 重新編譯即可。
代理環境的話,只需要去掉--with_proxy_module重新編譯即可。
2、去掉nginx 默認的debug跟蹤設置。這一步需要修改nginx 源碼。
cd nginx-1.0.x
vim auto/cc/gcc |
第175行
前面加#注釋掉改行。
這樣的話,編譯的參數,就會減少到500多K的標準,這樣在大并發量的條件下,性能提升明顯。
二、利用google-perftools來優化高并發條件下的nginx
在32位系統下,可以直接安裝google-peftools,64位條件下,需要先安裝libunwind庫。然后再nginx configure 參數增加--with-google_perftools_module 重新編譯安裝nginx 。
這里以64位環境為準
1)安裝libunwind庫
wget http://download.savannah.gnu.org/releases/libunwind/libunwind-0.99.tar.gz
tar zxvf libunwind-0.99.tar.gz
cd libunwind-0.99/
CFLAGS=-fPIC ./configure –prefix=/usr
make CFLAGS=-fPIC
make CFLAGS=-fPIC install |
Java代碼編譯是由Java源碼編譯器來完成,流程圖如下所示:

Java字節碼的執行是由JVM執行引擎來完成,流程圖如下所示:
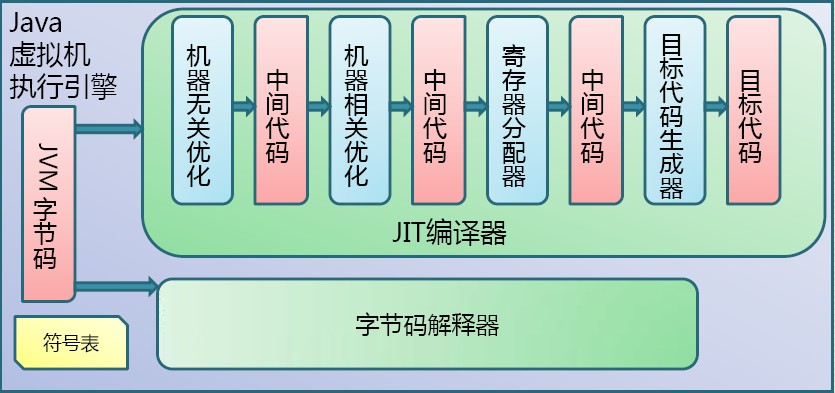
Java代碼編譯和執行的整個過程包含了以下三個重要的機制:
● Java源碼編譯機制
● 類加載機制
● 類執行機制
Java源碼編譯機制
Java 源碼編譯由以下三個過程組成:
● 分析和輸入到符號表
● 注解處理
● 語義分析和生成class文件
流程圖如下所示:

最后生成的class文件由以下部分組成:
● 結構信息。包括class文件格式版本號及各部分的數量與大小的信息。
● 元數據。對應于Java源碼中聲明與常量的信息。包含類/繼承的超類/實現的接口的聲明信息、域與方法聲明信息和常量池。
● 方法信息。對應Java源碼中語句和表達式對應的信息。包含字節碼、異常處理器表、求值棧與局部變量區大小、求值棧的類型記錄、調試符號信息。
類加載機制
JVM的類加載是通過ClassLoader及其子類來完成的,類的層次關系和加載順序可以由下圖來描述:

1)Bootstrap ClassLoader
負責加載$JAVA_HOME中jre/lib/rt.jar里所有的class,由C++實現,不是ClassLoader子類
2)Extension ClassLoader
負責加載java平臺中擴展功能的一些jar包,包括$JAVA_HOME中jre/lib/*.jar或-Djava.ext.dirs指定目錄下的jar包
3)App ClassLoader
負責記載classpath中指定的jar包及目錄中class
4)Custom ClassLoader
屬于應用程序根據自身需要自定義的ClassLoader,如tomcat、jboss都會根據j2ee規范自行實現ClassLoader
加載過程中會先檢查類是否被已加載,檢查順序是自底向上,從Custom ClassLoader到BootStrap ClassLoader逐層檢查,只要某個classloader已加載就視為已加載此類,保證此類只所有ClassLoader加載一次。而加載的順序是自頂向下,也就是由上層來逐層嘗試加載此類。
類執行機制
JVM是基于棧的體系結構來執行class字節碼的。線程創建后,都會產生程序計數器(PC)和棧(Stack),程序計數器存放下一條要執行的指令在方法內的偏移量,棧中存放一個個棧幀,每個棧幀對應著每個方法的每次調用,而棧幀又是有局部變量區和操作數棧兩部分組成,局部變量區用于存放方法中的局部變量和參數,操作數棧中用于存放方法執行過程中產生的中間結果。棧的結構如下圖所示:

模型驅動的軟件測試技術
一、引言
模型驅動的軟件測試(Model-Driven Test)技術是針對軟件中的一些常見的軟件模型而提出的一種測試技術,如故障模型、安全模型、死鎖模型等。模型驅動的軟件測試以明確描述系統預期行為的抽象模型為依據,根據模型覆蓋測試準則自動生成抽象的測試用例,自動地產生測試腳本,執行測試并自動評價測試結果,從而有效提高測試效率。這一技術正成為當前軟件工程學術界研究的一個重要方向。
近年來,基于模型的軟件測試技術得到快速的發展,大量的軟件測試工具被研制出來從而可以自動地檢測軟件中的故障,并且在對一些大型商業軟件和開源軟件的測試中發現了大量的以前測試沒有發現的軟件故障和安全隱患。
二、模型驅動的軟件測試技術的特點
與其他測試技術相比,基于模型的軟件測試技術具有如下特點:
(1)故障模型根據被測試應用程序的分析設計模型及其生成測試模型、產生測試用例和進行測試結果評價。
(2)大大提高了測試自動化水平以及測試效率。
(3)部分解決了測試失效辨識問題,往往能發現其他測試技術難以發現的故障,保證了軟件質量。
(4)有利于測試用例的重用,并可以應用成熟的理論和技術獲得比較完善的分析結果。
三、軟件模型分類
軟件模型是對軟件行為和軟件結構的抽象描述。軟件模型通常可以分為以下7 類:
(1)故障模型
故障模型主要是會引起錯誤的常見軟件模型, 應該盡量避免, 如內存泄漏故障(MLF) 、使用空指針故障(NPDF) 、數組越界故障(OOBF) 、非法計算類故障(ILCF) 、使用未初始化變量的故障(UVF) 、不完備的構造函數故障(ICF) 以及操作符異常故障(OAF) 等。
(2)安全漏洞模型
安全漏洞模型為他人攻擊軟件提供可能。而一旦軟件被攻擊成功,系統就可能發生癱瘓,所造成的危害可能更大。因此,此類漏洞應當盡量避免,如:緩沖區溢出漏洞模型、被感染數據漏洞模型、競爭條件漏洞模型等。
(3)差性能模型
該模型在軟件動態運行時效率比較低下,因此建議采用更高效的代碼來完成同樣的功能。這類模型主要包括調用了不必要的基本類型包裝類的構造方法、空字符串的比較、拷貝字符串、未聲明為static 的內部類、參數為常數的數學方法、創建不必要的對象以及聲明未使用的屬性及方法等。
(4)并發故障模型
該模型主要是針對程序員對多線程的編碼機制不十分了解,對各種同步的方法、Java 存儲器模型和Java 虛擬機的工作機制不是很清楚,而且由于線程啟動的任意性和不確定性使用戶無法確定所編寫的代碼具體何時執行而導致對公共區域的錯誤使用,如死鎖等。
(5)不良習慣模型
該模型主要是由于程序員編寫代碼的不好習慣造成的一些錯誤。包括文件的空輸入、垃圾回收的問題,類、方法和域的命名問題,方法調用,對象序列化,域初始化等。
(6)代碼國際化模型
該模型主要是在語言進行國際化的過程中,可能造成本地設置和程序需求不符的情況,造成匹配錯誤。
(7)易誘騙代碼模型
該模型主要指代碼中容易引起歧義的、迷惑人的編寫方式。比如無意義的比較,永遠是真值的判斷,條件分支使用相同的代碼,聲明了卻未使用的域等,即那些混淆視聽,無法正常判斷程序的真正意圖的代碼。
四、模型驅動的軟件測試過程
模型驅動的軟件測試方法通過對測試過程的抽象化,分離測試模型和測試執行,從而能夠通過正向或逆向手段建立針對WA某方面特征的測試模型,并重用有針對性的測試執行手段。傳統黑盒、白盒測試方法與模型驅動的軟件測試方法并不矛盾,它們可以被包含到模型驅動的軟件測試過程中。
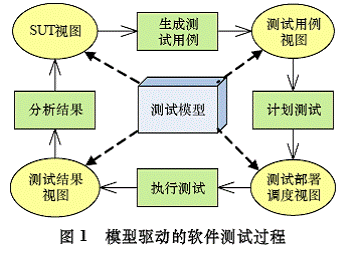
如圖1所示,測試模型是模型驅動的軟件測試的核心概念,它在測試的不同階段表現為不同視圖。
(1)通過被測系統(SUT)視圖得到測試模型;
(2)基于測試模型,自動化或半自動化地得到測試用例集,通過測試用例視圖描述;
(3)在測試執行階段,測試部署和調度視圖通過相應模型描述測試的執行環境以及執行過程;
(4)根據部署調度模型自動執行測試用例,生成的結果通過測試結果視圖顯示,并將某些結果直接反饋給被測系統模型、測試用例模型以及部署調度模型,在各自視圖上直觀的顯示出來,便于分析結果進行回歸測試。
五、模型驅動的軟件測試工具
模型驅動的軟件測試必須有相關工具支持。當前,有代表性的模型驅動的軟件測試工具中有:
(1)支持狀態機模型的工具。包括:Software Engineering Technology的測試工具toolSET_Certify,運行于RISC6000和SUN平臺;IBM的GOTCHA,可以根據用戶事先確定的測試充分性準則進行基于軟件狀態模型的測試例生成;IBM 的TCBean是一個提供測試腳本管理功能的基于狀態機的測試引擎。
(2)支持馬爾可夫鏈模型的工具。包括:Cleanroom Software Engineering的CleanTest,支持統計測試,是商用的使用模型及統計測試例生成工具;IBM 的CleanroomCertification Assistant,可以自動化統計驗證過程,通過使用概率分布產生測試例,并對測試結果進行分析。
(3)對UML模型提供測試支持的工具。包括:SilverMark公司針對IBM 公司的VisualAge開發的支持測試用例生成和回歸測試的TestMetor和UML Designer Connection。
如何進行需求矩陣管理
產品經理需要掌握并管理產品的全部需求,需求是軟件項目成敗的關鍵所在,好的需求應具備“內涵一致,外延完整”的特質,這個特質可以保證需求分析無歧義、完整、一致、正確、可行、必要、可檢驗、可跟蹤。
軟件需求是多層次的,包括業務需求、用戶需求、功能需求和非功能需求。如下圖所示:

啟動一個新產品時,產品經理需和各方進行充分的溝通,深刻理解客戶或者公司高層對系統、產品高層次的目標要求,將業務需求反映在產品的創意階段、策劃階段的《產品項目策劃書》、《產品項目規劃方案》中予以說明。
用戶需求主要描述了用戶能使用系統來做什么,用例、場景描述都是表達用戶需求的有效途徑。這部分需求通常在用例文檔或方案腳本說明中予以說明。
功能需求定義了開發人員必須實現的軟件功能,用戶能夠利用這些功能完成任務,從而滿足業務需求。功能需求通常是通過對系統特性的描述表現出來的,它記錄在《軟件需求規格說明書》(SRS)中。《軟件需求規格說明書》完整地描述了軟件系統的預期特性,是開發、測試、質量保證、項目管理的重要依據。因設計的產品功能一般都較為復雜,業務規則的描述也需盡可能詳盡,所以通常情況下《軟件需求規格說明書》并不是一份文檔,而是根據功能模塊的劃分由多個子文件組成。每一篇需求說明文檔中均必須包含功能列表和功能詳細描述,可依據實際業務情況增加數據字典方面的描述。《軟件需求規格說明書》中的功能列表需要和《需求跟蹤矩陣》一一對應,包括功能點編號、功能點名稱。需要強調一點,需求文檔的重點是說明功能所在,無需描述界面中的Icon、色彩、像素等信息,為避免和界面設計稿等展示高保真產品原型的文檔發生沖突,需求文檔中應盡量全部采用低保真界面,界面類描述交由《交互設計說明書》及界面設計稿、Html文件去說明。
《軟件需求規格說明書》中還應包括非功能需求,非功能需求描述了系統展現給用戶的行為和執行的操作等,它包括產品必須遵從的標準、規范和約束,操作界面的具體細節要求,性能要求,設計或實現的約束條件及質量屬性。通俗地講,非功能需求是這樣一種需求,它不是解決“我想要我的系統實現這種功能”,而是解決“如何使這個系統能在實際環境中運行”。在非功能需求中,針對性能方面一般需要有單點、混合、持續三方面的要求:
1、在單點方面,要求延遲和吞吐量有對應關系,假如我們設計一款BS軟件,要求打開登錄頁面的延遲要求為響應時間3秒、抖動2秒,那么一定要在吞吐量的要求上寫上針對這一點的高峰并發人數,比如100人。
2、在混合方面,產品經理依據業務的實際情況,定義混合并發值,并依據單點定義的部分或全部點以百分比的形式分配并發比例,注意混合下的并發值不得高于單點下的并發值。比如定義混合并發值200人,其中20%訪問首頁,20%登錄,20%上傳文件,40%瀏覽頁面。
3、在持續方面,通常定義為單點最高并發值二分之一情況下的2*24小時或3*24小時持續測試。比如定義50人并發下持續性測試時間2*24小時。
《需求跟蹤矩陣》主要是跟蹤及統計功能需求和非功能需求。當需求基線第一次形成時就需要填寫這個文檔,這篇文檔中的功能點名稱和編號需和需求文檔中對應,不得存在差異,每個功能點都需要定義它的級別(P1、P2、P3,P1為最高級別)。通常,重要程度為P1級的功能點數,不超過50%;或者P1級和P2級的功能點數,不超過80%。需求發生變更時,需填寫《需求跟蹤矩陣》中的需求變更記錄表用以記錄新增、修改、刪除的功能點,并需在各模塊的功能點列表中標記變更狀態,通常如有新增功能,則增加在相應模塊底部,字體設置為紅色,如有刪除功能,用藍色標記。
在《需求跟蹤矩陣》的需求變更統計表中,有一組圖表可以直觀地展現各階段需求變更工作量、項目整體需求變更率、項目整體功能點變化的情況,如下圖所示:

以上主要解釋并分析了需求的四個層次,以及如何管理需求跟蹤矩陣,希望能對產品經理們有所啟發。
最后附上Jan L.A. Van de Snepscheut的一段話,可以細細品味:就理論而言,理論和實踐并無差異。但真付諸實行之時,差異即開始顯現。
序言:不知道有多少人對開源社區真的很有了解,個人以為在自動化測試中,開源也是一個很好的利器,往往商業性的工具針對普遍人群,而自動化測試是“定制型”的,不一定特別適合,而且自動化測試是預言型的,所以一般而言,可以考慮開源。因為可以快速應用其提高效率,我個人覺得:自動化測試在追求發展過程中,要學會借助各種工具提高效率,而不是僅僅局限于一種。還是那句話,能提高測試效率和工作效率的才是王道,“摘花折草即可傷人也”。
一、自動化測試中的開源軟件分類
開源工具因為其零許可費以及開放和自由的理念逐漸得到了大家的認可和廣泛的傳播,而且由于自動化測試的差異性,其開源軟件的靈活性更能在自動化測試中很好的體現,而且隨著開源軟件和自動化測試的發展,其開源工具在自動化測試中也形成了一股應用的趨勢。其實,在工作中,我們都在不斷的與自動化測試打著交道。
在自動化測試過程中,我們與之打交道的開源工具,可以分為
1、編程語言與平臺,即在自動化測試過程中應用的語言和操作系統
1)Andriod,大家應該都有所了解,其是以Liunx為內核底層來支持不同硬件,并在其上搭建一個類java的運行環境,其大概有幾層,包括:linux內核、底層庫、JAVA框架(包括其API)、Andriod應用程序。
2)LINUX,大家熟知的開源操作系統。
3)腳本語言:Python、ruby、perl等,這些都是在自動化測試中因為其簡便性與動態性多有用到的編程語言。這些語言的維護、開發和發展都是通過開源社區和開源標準組織(例如ISO和Ecma)進行的,所以它們稱為開源語言。而java因為受Oracle支配,所以稱得上開源不開源,我也不是很清楚…
4)Flex:是在FLASH基礎上做的一層封裝,提供了組件庫,開發人員可以直接編寫MXML,即在FLEX中布局用戶界面組件的一種XML語言來搭建用戶界面。同時,完成負責數據邏輯的ActionScript腳本,最好編程成FLASH文件。所以,有些用戶界面是用FLEX開發的。
……
2、開源開發工具
1)Eclipse,這個用過java的一般都很熟悉吧,是一款很好的IDE。其是基于”OSGi”的“即插即用”理念,所有功能以組件形式存在。其理念我覺得非常好,其插件只要遵循其平臺的規范,就能集成到其中應用。例如:Pydev是一款python的插件,jython是一款Java與python集成的插件,還有andriod、ant等集成的插件,當然,我覺得可以的話,最好先應用一下獨立版,再去在eclipse中應用,這樣,可以更好的了解其運作原理。
而且,我覺得這種理念在自動化測試中也可以很好的應用,使得各個工具之間能夠在一個平臺上作為模塊互相通用,而且也能獨自使用。其IBM rational開發的jazz平臺也是基于一種這么理念的。
2)Ant,這個大家也許不是很熟悉,但是開發過java應用程序或者做個持續集成的也有有所了解,它就是一款構建的工具,即用XML描述任務的形式,自動完成其定義的工作,例如:可以幫助開發人員自動完成編譯、單元測試、打包、發布等工作。
3)Maven,Java開源項目的開發管理工具,涵蓋了項目構建、文檔管理、報告生成等方面,與Ant功能類似,其差別在于ant每一個項目需要獨立維護一個XML構建描述文件,而Maven能夠幫助快速搭建一個項目框架,而無需從頭編寫,其是一種“約定勝于配置”的理念,即先抽象出一個原型。這理念也可應用在自動化測試中的,即先提供一個腳本模板,然后根據這個模板,搭建一定的測試流程。
4)版本管理工具,例如:SVN和CVS,其都能夠應用腳本控制其代碼版本的簽入和簽出,在其自動化測試中也能有一定應用,方便管理腳本與代碼程序。
5)Bugzilla,缺陷管理工具,可以管理和跟蹤缺陷,即,可以在自動化測試中應用來管理相應結果或者缺陷跟蹤等。
6)Junit,大家都恨熟知的吧,單元測試的一款工具,即事先規定好單元測試模板,開發人員只需去根據被測試代碼,搭建其測試代碼即可。
7)TestNG,與junit類似。在自動化測試中也能有所應用。
3、編程及測試框架與庫
1)在J2EE開發中,大家熟知的SSH,即Spring、Struts、Hibernate。具體的大家可以去查閱相關資料,我想說的是,如果大家深入學習的話,會發現,其開發理念和自動化測試思想很相似,像Struts的MVC思想,與自動化測試的分層理念可以很好的結合。Hibernate的數據庫持久層思想也可以用于自動化測試的數據管理應用,總之,了解這些軟件設計框架,對于加強自動化測試思想的理解很有幫助。
2)Selenium,大家都很清楚的web自動化測試框架,很多人都說這是一種工具,其實說工具也行,框架也一樣,其提供了一種測試web的自動化思想,即采用繞過web中“同源策略”的方法,用JS來控制web的操作。你可以編寫腳本應用其API,來控制web的相應控件的操作。一般是集成在你的自動化測試管理框架或者系統平臺中的。
3)Robutium,andriod UI測試的一個自動化測試框架,理念類似,只是應用場合不一樣。
4)Abbot,測試java UI的一個自動化測試框架,其錄制的測試用例是用XML進行描述,其只能用錄制的方式生成XML文件,而且其abbot只能去讀取XML,所以你可以自己寫一個腳本庫去生成相應的XML去控制aboot,其在測試java UI方面的穩定性還是不錯的。
當然,還有各種各樣的編程框架與自動化測試框架,但是隨著接觸的多了,你會發現其理念都是一樣的,所以要學會自己從各個工具中提煉其思想與共性。
4、應用服務器軟件
1)web服務器,舉一個例子,大家熟知的Tomcat,其中也繼承了J2EE中的servlet,其web服務器的作用主要是提供HTTP協議操作,將web客戶端提交的頁面請求進行處理后,然后動態返回相應的HTML頁面即可。
2)數據庫,MySQL,開源的關系數據庫系統,在一般的中小型項目還是很好用的,數據庫設計在自動化測試中,個人認為也很重要,如果將自動化測試設計成一個平臺的話,需要涉及大量的測試用例與腳本、測試用戶權限的管理等。所以,數據庫設計需要在自動化測試平臺設計之前,定義好表以及表之間的聯系,方便以后拓展使用。
二、如何去保證開源工具的應用
1、在自動化測試開展過程中,首先要對其測試需求以及對自動化測試的開展程度進行分析,包括自動化測試的規模、自動化測試的緊急程度以及實際需要應用程度、自動化測試的成本考慮等因素。
2、之后,就去根據相應的需求,在不同方面采用不同的測試軟件或者工具,不需要局限和死專于一種,哪種能提高效率,就盡快采用。
3、總之,在這些軟件或者工具的基礎上,如果要規模化的話,你需要有一個自己定義好的平臺進行規范,各個工具軟件框架都可以以模塊化的形式存在,當然,我建議最好要慎重考慮其“高內聚、低耦合”的思想。
三、開源工具的應用策略
我大概想了一下,其在自動化測試應用中,這些工具都扮演著不同的角色,對推動這個測試,甚至說軟件行業都起到很大作用。
1)常規的開發和測試流程
當然這個自動化測試不會起到主要性的作用,但是能提高一定的效率。
2)持續集成的流程
需要搭配單元測試框架、構建工具、以及持續集成管理工具(例如:cruisecontrol)
3)敏捷開發與測試流程
敏捷開發中我覺得自動化測試是很重要的一個角色,其能夠快速保證其發布周期。
4)云端測試流程
現在出來的云端提交測試,需要自動化形式提交以及進行相應的處理,其都是在web上面進行提交與返回的。
總之,“預先善其事,必先利其器”,但是,在眾多的自動化測試軟件工具和框架中,我們要保持一個清醒的思想,要能夠去抓到本質,真正能為我所用,就像武俠小說里面似的,俠客之路,從手中有劍到手中無劍、從有招到無招,從無心到有心。共勉之。
摘要:
你的項目出了嚴重問題,客戶向你公司的領導投訴,你的領導興師問罪要追究責任!這是測試的錯?開發的錯?PM的錯?還是研發流程的錯?中國教育制度的錯?社會的錯?反正、總之、一定、必須不是我的錯!
事件回放:
某項目部署給客戶后,重現了一些以前已經解決的問題,而這些問題測試時并沒有出現。經檢查,發現測試的版本不是部署的版本,不知道為什么老版本部署給客戶了。領導要追究責任,于是大家各有說法:
開發人員說:我是按要求打標簽的,沒有問題。
測試人員說:我是在提交區中取版本來測試的,我沒有出錯。
實施人員說:我是按照開發給我的版本去部署的,我沒有過失。
最后終于有人說:是之前已經離職的某某弄錯版本號導致的。
思考:
1、該事件反應了什么問題?將來應該如何改進?
2、這么多問題中,最大的問題是哪個問題?
在繼續往下閱讀之前,建議你先寫寫對以上問題的想法,然后再繼續閱讀。
本事件并沒有什么標準的答案,下面分析僅供大家參考,歡迎大家提出自己的想法!
事件的補充說明:
這是發生在我以前公司的真實個案。第一次聽說時,我覺得很不可思議,也覺得非常的丟人!
客戶當前版本是1.1,我們打算為之安裝1.2版本,安裝后客戶反饋怎么以前已經解決的缺陷又再次出現了?檢查后發現,原來我們安裝的是1.0版本的程序。相當于大家辛辛苦苦地奮戰了數天,最后竟然沒有將工作成果給客戶,而是將以前的東西給客戶了。作為軟件公司來說,這是一個超級低級的錯誤!
經過檢查,終于發現了問題的真正原因:開發人員A讓實施人員B直接在他的電腦上取安裝程序,而不是根據研發流程的要求到配置庫中取,而該開發人員A讓實施人員B所取的版本,是1.0版本的老程序,而不是最新的1.2。這個原因主要是通過實施人員B得到的,但開發人員A已經離職了,“死無對證”!
似乎整個事件需要負責任的就是這位已經離職的仁兄,而該仁兄已經離職,更加是百口莫辯。我的領導對于這樣的結論,苦笑說:呵呵,這樣好,推到一個離職的人身上!
問題1:某些人員失職,沒執行流程!
開發人員A和實施人員B違反了相關規定,嚴重失職,應為此負責。而開發人員A已經離職,故應由實施人員B來負擔主要責任。這樣處理是否合適呢?
問題2:研發流程和公司制度有漏洞,應進一步改善!
研發流程雖然規定了要從配置庫中取安裝程序,但沒有版本確認的步驟,而且安裝程序應該由配置人員提供,而不應該由實施人員直接問開發人員要,這是流程中需要改善的。
于是配置管理員提出建議:規定所有的安裝程序只能由配置管理員提供,不能通過其他途徑!
但項目經理、開發、實施都反對,因為經常需要加班,往往在加班的時候需要提供安裝程序,但這個時候配置管理員往往已經下班了,無法向配置管理員要安裝程序。如果配置管理員就算沒事干都好,愿意一起加班的話,可以這樣規定。
于是配置管理員就再無意見了……
另HR提出,此事其實是開發人員A付主要責任的,出現這樣的問題原因之一是離職交接沒有做好,工作沒有檢查好。此意見一出,項目組、負責交接A工作的開發、同意A離職的部門經理,幾乎全部暈倒了!交接已經做得很不錯了,什么問題都要防住,你叫這個交接怎樣做?
研發流程和制度確實需要不斷完善,但如果老是從細節上規定,是不是有點本末倒置呢?研發工作中的問題總是很多的,不太可能規定所有細節的,而且一旦規定了一些細節,似乎避免了一個問題,但會帶來更多的問題。
問題3:喜歡做好好先生、好好小姐!
事件中其實很多人大概知道問題所在的,但就不指出來,不想得罪人,要做“好人”。如果要追求責任,那么最好將錯賴在一個不能追究責任的人身上,就是那位可能是很無辜的已經離職的仁兄。或者將錯賴在制度和流程上,這招是最絕的,沒有人需要負責,這是制度的錯、社會的錯!
問題4:沒有人首先從自己身上找原因,每個人首先想到的是推卸責任!
研發工作中的很多成果,是經過一系列的環節和各人的配合作出來的,任何一個環節有問題,都可能會導致最終成果出問題。那似乎將各環節責任、流程等定義好,就可以很好地追求責任了?
如果某個環節都留下一些隱患,但不至于馬上出問題,但經過多個環節累積之后,問題爆發!這時應該哪個環節負責呢?
如果前面某個環節出現一些問題,但下一個環節的人發現了并及時提出來,最終不影響最終成果,這是不是一種很好的效果呢?
如果每個人除了做好本職工作,還主動提醒他人,主動提供一些有利于項目的建議,幫助項目成功,這是不是非常好呢?
軟件研發中的問題,往往不是某個環節造成的,而是各種因素作用逐步導致的。項目需要團隊一起努力、互相糾正、互相提醒,每個人都應該為項目的最終成功負責!某項目出問題了,是不是應該整個項目組都應該負責呢?是不是大家應該首先從自己身上找原因呢?
哪個問題更加嚴重?
個人認為問題4是最嚴重的問題,流程、制度、職責等這些,如果為了解決某一問題而去修改和細化,可能會陷入無休止的類似工作中。這和修復一個bug的道理是一樣的,每修復1個bug,可能會帶來10個bug。過于從細節上細化流程和制度,我個人是不太贊同的,會陷入某種死循環。
我們喜歡說依法辦事,往往用法律來比喻,我們研發過程也需要有法可依。法律規定的一般是不能做什么,但我們流程中規的的往往是必須做什么、應該做什么等,一旦規定應該怎樣做,就很容易出問題。研發活動是很復雜的智力活動,不應該在一些細節上套太多的框框條條。
做好團隊建設,樹立良好的團隊觀,項目團隊應該是“一榮俱榮,一損俱損”的!要打造這樣的團隊是不容易的,但也不是很難,其實取決于公司領導的管理思想。以目標來驅動,鼓勵創新,允許犯錯,獎勵自我批評,這些都有助于良好的團隊建設。但有些領導喜歡工廠化管理,喜歡將工作細化,喜歡根據工作職責來考核,喜歡根據問題多少來考核,這樣難以避免這些踢皮球事件了。
這個事件我有什么責任?
說了這么多別人的問題,我是不是應該從自己身上找找原因呢?
我不直接負責該項目工作,是公司的常務副總,公司中的大部分員工都是經過我面試進來的,我一直在盡力打造良好的團隊文化,而研發流程大部分是由我制定的,或者是經過我批準的。要興師問罪的是公司的大領導,不是我,其實如果要問起罪來,可以說公司內部的跟研發相關的所有問題,我都需要負責任!因為這些事基本上都是我管的。
出現踢皮球事件,我覺得很無奈。自己一直以來期望做到的團隊“一榮俱榮、一損俱損”,在事到臨頭的時候,只是一種口號而已,我需要檢討自己的做法和想法。那種美好的團隊建設可能只是一種烏托邦,可能難以實現甚至無法實現,但我覺得我還是應該繼續為之努力的。
其他的一些想法:
這只是一個小小的案例,但相信很多朋友會經歷過類似的情況。推卸責任可能是人的本能反應吧,我也會這樣。大家都能主動從自己身上找原因,這可能是一個遙遠的夢。
我曾經試過參加一個會,兩個高層在PK,老板在一旁看,PK一大通后,最后那項大家都不想干的工作落到了一直沒有出聲的我的頭上,剛才PK的兩個人,都一致同意讓我來做這項工作!我只能說:很無語……
有些事情我們可能控制不了,但如果咱們能帶領一個團隊的話,我們應該在能力范圍內做一些對團隊各人都有益的事情,盡量打造好的團隊氣氛,擋住影響團隊氣氛的外部的不利影響。對你的團隊成員好,將來得到的回報肯定會遠遠大于你的付出!
如果還想在測試這條路上繼續走下去的話,那么下面這些東西就是我們必須去掌握的,至少你還不想止步于簡單的黑盒測試~~其實,一直想去接觸Linux下的應用測試,這樣能學到東西會很多,而且會非常的受用。之前聽小布老師講,如果你想在IT技術上長期發展下去,那么你就大膽擁抱Linux吧,因為在這里你能學到東西遠勝過于你在Windows平臺下學到的東西,而其中最經典的一段話就是:如果你一直跟隨微軟的技術,那么終究會被拖死,因為微軟的技術一直在變化,而你卻需要不斷的去學習他的東西。而Linux不一樣,它更多的是讓你去理解底層的技術,讓你從原理上去理解技術的核心,永遠以不變應萬變的姿態去面對未來的技術革新。
我想作為一個測試人員,如果你確實還沒接觸過網絡、數據通信方面的技術,那么咱們的路還很長,至少我認為軟件測試并非只停留在上層的應用,而測試的最高境界應該是對底層核心技術的測試,通過架構分析、協議數據包分析等等來測試出結果~~~所以我們應該掌握的技術有:TCP/IP、Socket、多線程,這些是必須的。
1、先來看看TCP/IP的體系結構,如下圖:

TCP/IP協議實際上就是在物理網上的一組完整的網絡協議。其中TCP是提供傳輸層服務,而IP則是提供網絡層服務。下面是各個層的協議說明:
IP: 網間協議(Internet Protocol) 負責主機間數據的路由和網絡上數據的存儲。同時為ICMP,TCP,UDP提供分組發送服務。用戶進程通常不需要涉及這一層。
ARP: 地址解析協議(Address Resolution Protocol)
此協議將網絡地址映射到硬件地址。
RARP: 反向地址解析協議(Reverse Address Resolution Protocol)
此協議將硬件地址映射到網絡地址
ICMP: 網間報文控制協議(Internet Control Message Protocol)
此協議處理信關和主機的差錯和傳送控制。
TCP: 傳送控制協議(Transmission Control Protocol)
這是一種提供給用戶進程的可靠的全雙工字節流面向連接的協議。它要為用戶進程提供虛電路服務,并為數據可靠傳輸建立檢查。(注:大多數網絡用戶程序使用TCP)
UDP: 用戶數據報協議(User Datagram Protocol)
這是提供給用戶進程的無連接協議,用于傳送數據而不執行正確性檢查。
FTP: 文件傳輸協議(File Transfer Protocol)
允許用戶以文件操作的方式(文件的增、刪、改、查、傳送等)與另一主機相互通信。
SMTP: 簡單郵件傳送協議(Simple Mail Transfer Protocol)
SMTP協議為系統之間傳送電子郵件。
TELNET:終端協議(Telnet Terminal Procotol)
允許用戶以虛終端方式訪問遠程主機
HTTP: 超文本傳輸協議(Hypertext Transfer Procotol)
TFTP: 簡單文件傳輸協議(Trivial File Transfer Protocol)
2、TCP/IP協議的核心部分是傳輸層協議(TCP、UDP),網絡層協議(IP)和物理接口層,這三層通常是在操作系統內核中實現。通常用戶的服務需要通過應用程序來實現,所以在底層與應用層就是通過套接字來實現,也就是我們通常所說的Socket來建立連接的。具體如下圖所示:
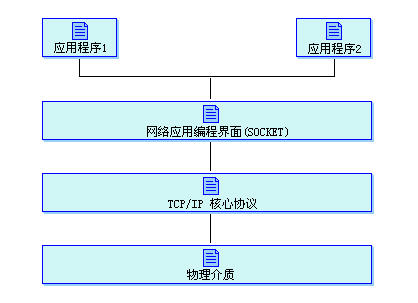
TCP/IP協議核心與應用程序關系如上圖所示,所以對照這個圖來理解我們的應用層開發,就直觀多了,特別是對一些應用進行性能測試時,基于什么協議來通信,分析也會得心應手了。
所以說測試要學的東西還很多,到最后技術也許比開發人員都要牛,最重要的是這些東西能夠給你的工作帶來實際的幫助。正所謂高手過招比的內功,這些都是內功的修煉,別等到用的時候才發現自己不會,那就遲了。測試的路還很長,埋頭學習吧,啥也不說~~
從Java平臺的邏輯結構上來看,我們可以從下圖來了解JVM:

從上圖能清晰看到Java平臺包含的各個邏輯模塊,也能了解到JDK與JRE的區別
對于JVM自身的物理結構,我們可以從下圖鳥瞰一下:

對于JVM的學習,在我看來這么幾個部分最重要:
● Java代碼編譯和執行的整個過程
● JVM內存管理及垃圾回收機制
下面將這兩個部分進行詳細學習。