#
WINDOWS+MAC+LINUX版的都有
http://robomongo.org/
OK,又是周末晚上,沒有約會,只有一大瓶Shasta汽水和全是快節奏的音樂…那就研究一下程序吧。
一時興起,我下載了D-link無線路由器(型號:DIR-100 revA)的固件程序 v1.13。使用工具Binwalk,很快的就從中發現并提取出一個只讀SquashFS文件系統,沒用多大功夫我就將這個固件程序的web server(/bin/webs)加載到了IDA中:
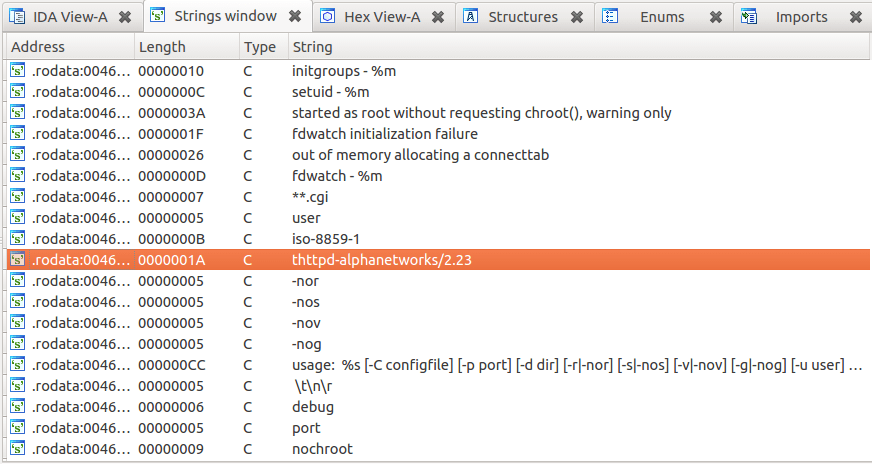
/bin/webs中的字符信息
基于上面的字符信息可以看出,這個/bin/webs二進制程序是一個修改版的thttpd,提供路由器管理員界面操作功能。看起來是經過了臺灣明泰科技(D-Link的一個子公司)的修改。他們甚至很有心計的將他們很多自定義的函數名都輔以“alpha”前綴:
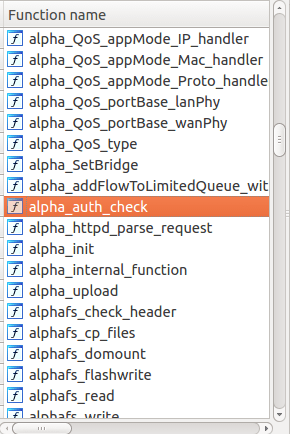
明泰科技的自定義函數
這個alpha_auth_check函數看起來很有意思!
這個函數被很多地方調用,最明顯的一個是來自alpha_httpd_parse_request函數:
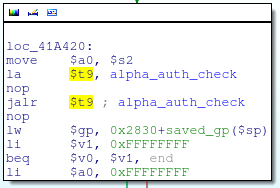
調用alpha_auth_check函數
我們可以看到alpha_auth_check函數接收一個參數(是存放在寄存器$s2里);如果alpha_auth_check返回-1(0xFFFFFFFF),程序將會跳到alpha_httpd_parse_request的結尾處,否則,它將繼續處理請求。
寄存器$s2在被alpha_auth_check函數使用前的一些操作代碼顯示,它是一個指向一個數據結構體的指針,里面有一個char*指針,會指向從HTTP請求里接收到的各種數據;比如HTTP頭信息和請求地址URL:
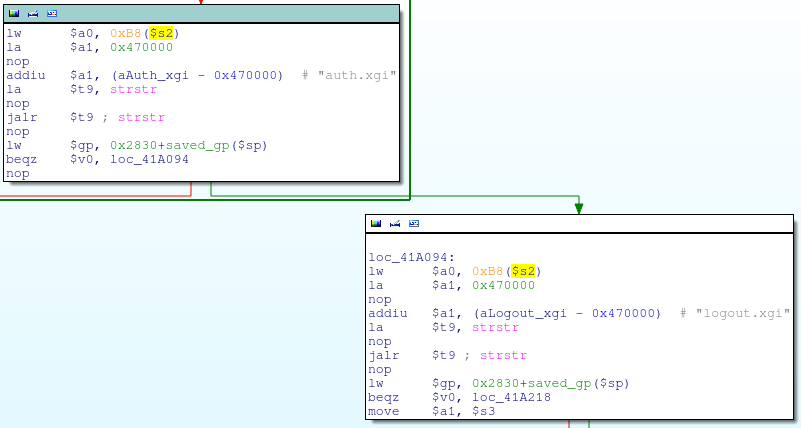
$s2是一個指向一個數據結構體的指針
我們現在可以模擬出alpha_auth_check函數和數據結構體的大概樣子:
struct http_request_t { char unknown[0xB8]; char *url; // At offset 0xB8 into the data structure }; int alpha_auth_check(struct http_request_t *request);alpha_auth_check本身是一個非常簡單的函數。它會針對http_request_t結構體里的一些指針進行字符串strcmp比較操作,然后調用check_login函數,實際上就是身份驗證檢查。如果一旦有字符串比較成功或check_login成功,它會返回1;否者,它會重定向瀏覽器到登錄頁,返回-1;
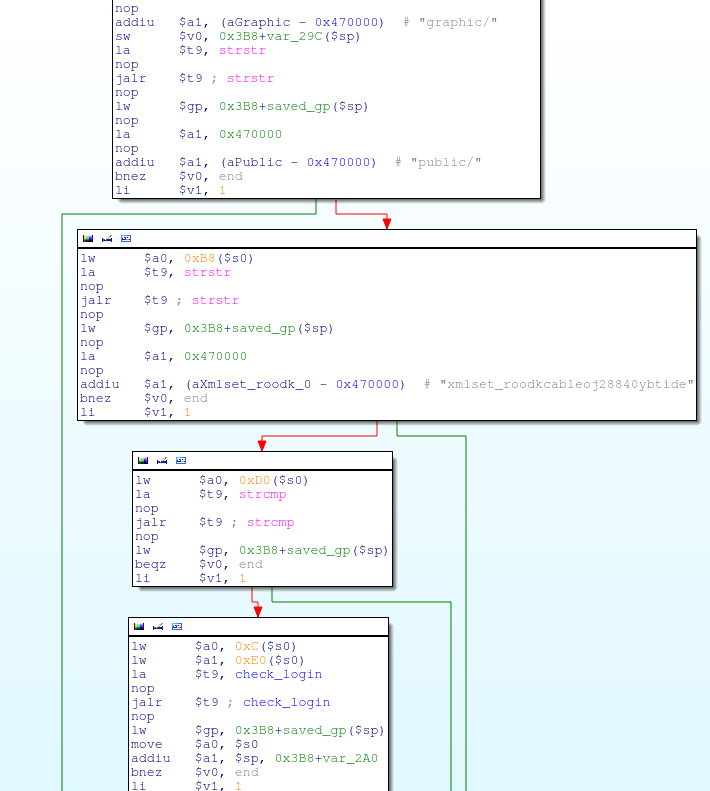
alpha_auth_check函數代碼片段
這些字符串比較過程看起來非常有趣。它們提取請求的URL地址(在http_request_t數據結構體的偏移量0xB8處),檢查它們是否含有字符串“graphic/” 或 “public/”。這些都是位于路由器的Web目錄下的公開子目錄,如果請求地址包含這樣的字符串,這些請求就可以不經身份認證就能執行。
然而,這最后一個strcmp卻是相當的吸引眼球:
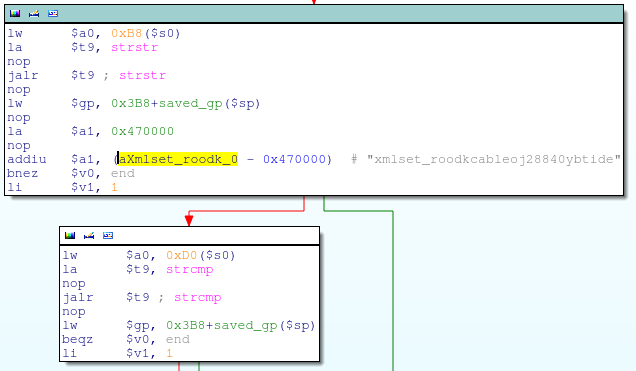
alpha_auth_check函數中一個非常有趣的字符串比較
這個操作是將http_request_t結構體中偏移量0xD0的字符串指針和字符串“xmlset_roodkcableoj28840ybtide”比較,如果字符匹配,就會跳過check_login函數,alpha_auth_check操作返回1(認證通過)。
我在谷歌上搜索了一下“xmlset_roodkcableoj28840ybtide”字符串,只發現在一個俄羅斯論壇里提到過它,說這是一個在/bin/webs里一個“非常有趣”的一行。我非常同意。
那么,這個神秘的字符串究竟是和什么東西進行比較?如果回顧一下調用路徑,我們會發現http_request_t結構體被傳進了好幾個函數:
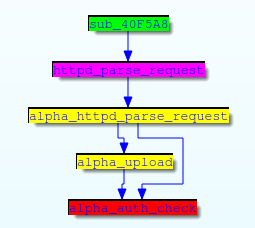
事實證明,http_request_t結構體中處在偏移量 0xD0處的指針是由httpd_parse_request函數賦值的:
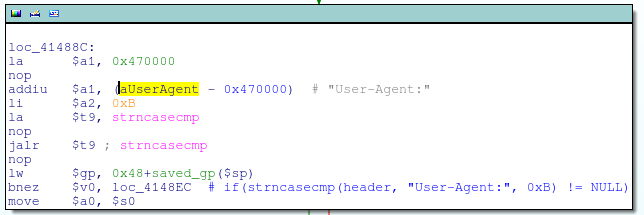
檢查HTTP頭信息中的User-Agent值
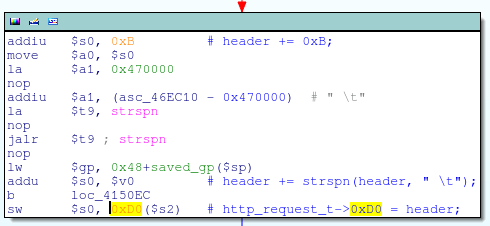
將http_request_t + 0xD0指針指向頭信息User-Agent字符串
這代碼實際上就是:
if(strstr(header, "User-Agent:") != NULL) { http_request_t->0xD0 = header + strlen("User-Agent:") + strspn(header, " \t"); }知道了http_request_t偏移量0xD0處的指針指向User-Agent頭信息,我們可以推測出alpha_auth_check函數的結構:
#define AUTH_OK 1 #define AUTH_FAIL -1 int alpha_auth_check(struct http_request_t *request) { if(strstr(request->url, "graphic/") || strstr(request->url, "public/") || strcmp(request->user_agent, "xmlset_roodkcableoj28840ybtide") == 0) { return AUTH_OK; } else { // These arguments are probably user/pass or session info if(check_login(request->0xC, request->0xE0) != 0) { return AUTH_OK; } } return AUTH_FAIL; }換句話說,如果瀏覽器的User-Agent值是 “xmlset_roodkcableoj28840ybtide”(不帶引號),你就可以不經任何認證而能訪問web控制界面,能夠查看/修改路由器的 設置(下面是D-Link路由器(DI-524UP)的截圖,我沒有 DIR-100型號的,但DI-524UP型號使用的是相同的固件):

訪問型號DI-524UP路由器的主界面
基于HTML頁上的源代碼信息和Shodan搜索結果,差不多可以得出這樣的結論:下面的這些型號的D-Link路由器將會受到影響:
- DIR-100
- DI-524
- DI-524UP
- DI-604S
- DI-604UP
- DI-604+
- TM-G5240
除此之外,幾款Planex路由器顯然也是用的同樣的固件程序:
你很酷呀,D-Link。
腳注:萬 能的網友指出,字符串“xmlset_roodkcableoj28840ybtide”是一個倒序文,反過來讀就是 “editby04882joelbackdoor_teslmx”——edit by 04882joel backdoor _teslmx,這個后門的作者真是位天才!
分布式文件系統比較出名的有HDFS 和 GFS,其中HDFS比較簡單一點。本文是一篇描述非常簡潔易懂的漫畫形式講解HDFS的原理。比一般PPT要通俗易懂很多。不難得的學習資料。
1、三個部分: 客戶端、nameserver(可理解為主控和文件索引,類似linux的inode)、datanode(存放實際數據)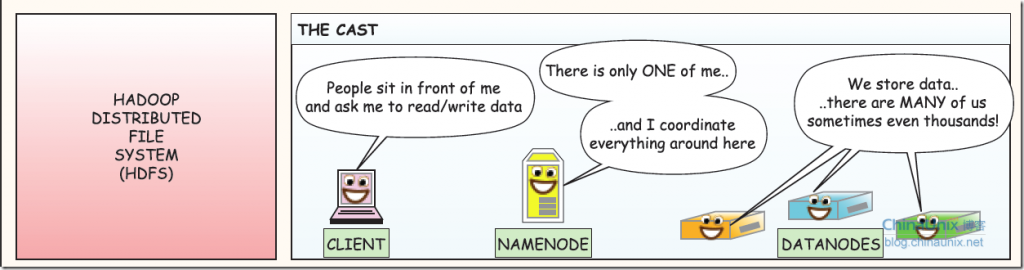 在這里,client的形式我所了解的有兩種,通過hadoop提供的api所編寫的程序可以和hdfs進行交互,另外一種就是安裝了hadoop的datanode其也可以通過命令行與hdfs系統進行交互,如在datanode上上傳則使用如下命令行:bin/hadoop fs -put example1 user/chunk/
在這里,client的形式我所了解的有兩種,通過hadoop提供的api所編寫的程序可以和hdfs進行交互,另外一種就是安裝了hadoop的datanode其也可以通過命令行與hdfs系統進行交互,如在datanode上上傳則使用如下命令行:bin/hadoop fs -put example1 user/chunk/
2、如何寫數據過程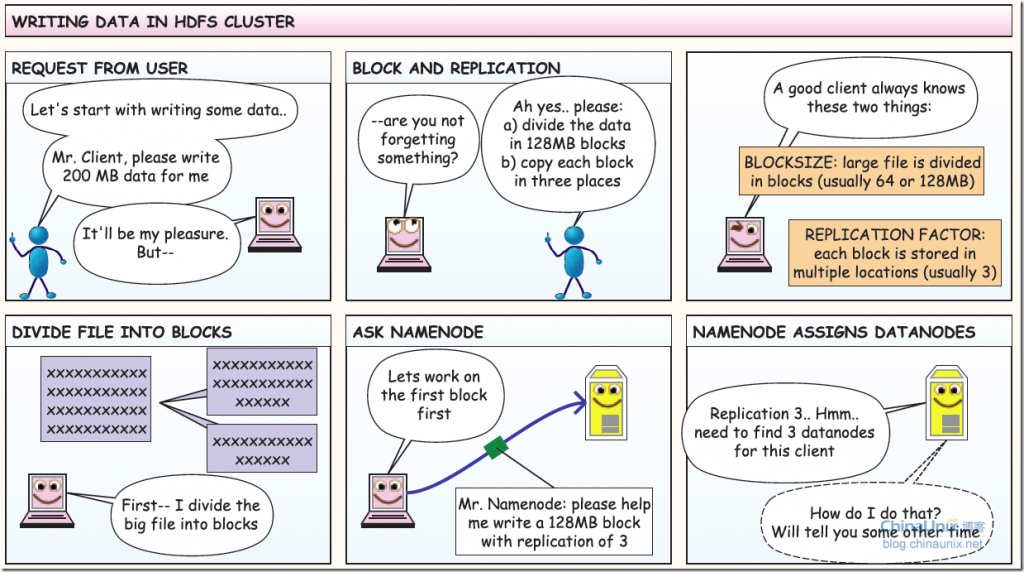

 3、讀取數據過程
3、讀取數據過程 4、容錯:第一部分:故障類型及其檢測方法(nodeserver 故障,和網絡故障,和臟數據問題)
4、容錯:第一部分:故障類型及其檢測方法(nodeserver 故障,和網絡故障,和臟數據問題)
 5、容錯第二部分:讀寫容錯
5、容錯第二部分:讀寫容錯 6、容錯第三部分:dataNode 失效
6、容錯第三部分:dataNode 失效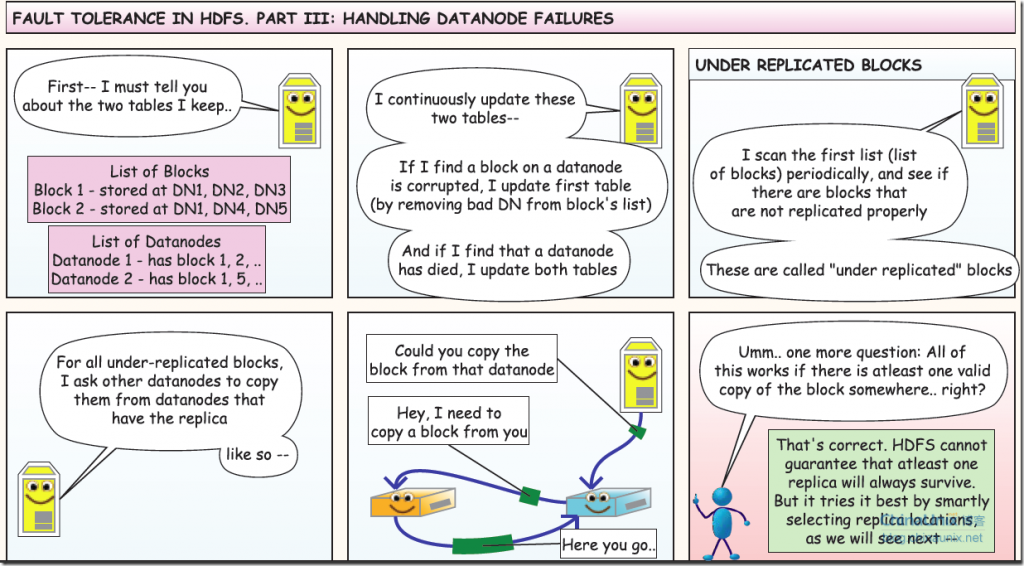 7、備份規則
7、備份規則 8、結束語
8、結束語
1.vi 模式
a) 一般模式: vi 處理文件時,一進入該文件,就是一般模式了.
b) 編輯模式:在一般模式下可以進行刪除,復制,粘貼等操作,卻無法進行編輯操作。等按下‘i,I,o,O,a,A,r,R’等
字母之后才能進入編輯模式.通常在linux中,按下上述字母時,左下方會出現'INSERT'或者‘REPLACE’字樣,才可以
輸入任何文字到文件中.要回到一般模式,按下[ESC]鍵即可.
c) 命令行模式:在一般模式中,輸入“: 或者/或者?”,即可將光標移動到最下面一行,在該模式下,您可以搜索數據,而且讀取,
存盤,大量刪除字符,離開vi,顯示行號等操作.
2.vi 常用命令匯總:
2.1 一般模式
a) 移動光標:
--> 上下左右方向鍵 ↑↓← →
--> 翻頁 pagedown / pageup 按鍵
--> 數字 0 : 將光標移動到當前行首
--> $ : 將光標移動到當前行尾
--> G : 移動到這個文件的最后一行 nG : n 為數字,移動到這個文件的第n行.
--> gg: 移動到這個文件的第一行 相當于 1G
b) 搜索與替換
--> /word : 從光標開始,向下查詢一個名為word的字符串。
--> :n1、n2s/word1/word2/g : n1 與n2 為數字.在第n1與n2行之間尋找word1這個字符串,
并將該字符串替換為word2。
--> :1、$s/word1/word2/g : 從第一行到最后一行尋找word1字符串,并將該字符串替換為word2
--> :1、$s/word1/word2/gc: 從第一行到最后一行尋找word1字符串,并將該字符串替換為word2。
并且在替換之前顯示提示符給用戶確認(conform)是否需要替換。
c) 刪除,復制,粘貼
--> x,X : 在一行中,x為向后刪除一個字符(相當于del鍵),X為向前刪除一個字符(相當于backspace鍵)。
--> dd : 刪除光標所在的那一整行。
--> ndd : n 為數字。從光標開始,刪除向下n列。
--> yy : 復制光標所在的那一行。
--> nyy : n為數字。復制光標所在的向下n行。
--> p,P : p 為將已復制的數據粘貼到光標的下一行,P則為貼在光標的上一行。
--> u : 復原前一個操作
--> CTRL + r : 重做上一個操作。
--> 小數點'.': 重復前一個動作。
2.2 編輯模式:
a) i, I : 在光標所在處插入輸入文字,已存在的文字向后退。i 為‘從當前光標所在處插入’,I 為‘在當前所在行的一個非空格符處開始插入’。
b) a, A : a 為‘從當前光標所在處的下一個字符開始插入’。A 為‘從光標所在行的最后一個字符處開始插入’。
c) o,O : 這是英文o的大小寫。o為‘在當前光標所在行的下一行處插入新的一行’。O表示‘在當前光標所在行的上一行插入新的一行’。
d) r,R : 替換:r 會替換光標所在的那一個字符。 R : 會一直替換光標所在的字符,直到按下esc 鍵為止。
e) ESC : 進入一般模式。
2.3 命令模式:
a) :w : 將編輯的數據寫入硬盤
b) :q : 離開vi
c) :q! : 強制離開,不存儲
d) :wq : 存儲后離開
e) :wq! : 強制存儲后離開
3. vim 附加命令行
3.1 塊選擇(visual block)
v 字符選擇,將光標經過的地方反白顯示
V 行選擇,會將光標經過的行反白選擇
ctrl + v 塊選擇,可以用長方形的方式選擇數據
y 復制反白的地方
d 將反白的地方刪除掉
3.2 多文件編輯
:n 編輯下一個文件
:N 編輯上一個文件
:files 列出當前vim 打開的所有文件
3.3 多窗口功能
:sp 【filename】打開一個新窗口,如果加filename,表示在新窗口打開一個新文件
否則表示兩個窗口為同一個文件內容
ctrl+wj 先按下ctrl ,再按下w后,放開所有按鍵,然后按下j,則光標可移動到下方的窗口
ctrl+wk 同上,不過光標移動到上面的窗口
ctrl+wq 其實就是:q結束離開。
本教程使用 JDK 6 和 Tomcat 7,其他版本類似。
基本步驟:
使用 java 創建一個 keystore 文件
配置 Tomcat 以使用該 keystore 文件
測試
配置應用以便使用 SSL ,例如 https://localhost:8443/yourApp
1. 創建 keystore 文件
執行 keytool -genkey -alias tomcat -keyalg RSA 結果如下
loiane:bin loiane$ keytool -genkey -alias tomcat -keyalg RSA
Enter keystore password: password
Re-enter new password: password
What is your first and last name?
[Unknown]: Loiane Groner
What is the name of your organizational unit?
[Unknown]: home
What is the name of your organization?
[Unknown]: home
What is the name of your City or Locality?
[Unknown]: Sao Paulo
What is the name of your State or Province?
[Unknown]: SP
What is the two-letter country code for this unit?
[Unknown]: BR
Is CN=Loiane Groner, OU=home, O=home, L=Sao Paulo, ST=SP, C=BR correct?
[no]: y
Enter key password for
(RETURN if same as keystore password): password
Re-enter new password: password
這樣就在用戶的主目錄下創建了一個 .keystore 文件
2. 配置 Tomcat 以使用 keystore 文件
打開 server.xml 找到下面被注釋的這段
<!--
<Connector port="8443" protocol="HTTP/1.1" SSLEnabled="true"
maxThreads="150" scheme="https" secure="true"
clientAuth="false" sslProtocol="TLS" />
-->
干掉注釋,并將內容改為
<Connector SSLEnabled="true" acceptCount="100" clientAuth="false"
disableUploadTimeout="true" enableLookups="false" maxThreads="25"
port="8443" keystoreFile="/Users/loiane/.keystore" keystorePass="password"
protocol="org.apache.coyote.http11.Http11NioProtocol" scheme="https"
secure="true" sslProtocol="TLS" />
3. 測試
啟動 Tomcat 并訪問 https://localhost:8443. 你將看到 Tomcat 默認的首頁。
需要注意的是,如果你訪問默認的 8080 端口,還是有效的。
4. 配置應用使用 SSL
打開應用的 web.xml 文件,增加配置如下:
<security-constraint>
<web-resource-collection>
<web-resource-name>securedapp</web-resource-name>
<url-pattern>/*</url-pattern>
</web-resource-collection>
<user-data-constraint>
<transport-guarantee>CONFIDENTIAL</transport-guarantee>
</user-data-constraint>
</security-constraint>
將 URL 映射設為 /* ,這樣你的整個應用都要求是 HTTPS 訪問,而 transport-guarantee 標簽設置為 CONFIDENTIAL 以便使應用支持 SSL。
如果你希望關閉 SSL ,只需要將 CONFIDENTIAL 改為 NONE 即可。
如果是MAVEN的TOMCAT插件,則加入如下配置
<build>
<finalName>test-dropbox</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.5.1</version>
<configuration>
<source>1.6</source>
<target>1.6</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.tomcat.maven</groupId>
<artifactId>tomcat7-maven-plugin</artifactId>
<version>2.0</version>
<configuration>
<httpsPort>8443</httpsPort>
<keystorePass>password</keystorePass>
<keystoreFile>C:\Users\PAUL\.keystore</keystoreFile>
</configuration>
</plugin>
</plugins>
</build>
用xshell連接vm上的ubuntu
1.
File->new
在host里面填寫你要連接的主機的ip地址 192.168.1.x
2.點Authentication出現下面的對話框
User Name 里面填的是你要連接要主機上的用戶名 隨便填寫
Password 你設定的密碼,不要忘了。
然后你可以測試下是否可以進去了,
File->open
選擇你新建的 點擊connect。
碰到的問題,我在點了connect 在xshell下面出現如下的代碼:
Xshell displays "Could not connect to 'hostname' (port 22): Connection failed." message.
說明沒有開啟SSH的22端口
在ubuntu終端下運行
sudo netstat –antup
看下面是否有一個22端口,如果沒有需要安裝SSHD服務,可以直接運行安裝服務
sudo apt-get install openssh-server
安裝完之后再查看一下是否開啟了22端口,如果開啟了,那么用xshell來連接基本上就沒什么問題了
還有一個是在xshell中的中文亂碼問題
輸入:
Locale
輸出:
LANG=zh_CN.UTF-8
LC_CTYPE=”zh_CN.UTF-8″
LC_NUMERIC=”zh_CN.UTF-8″
LC_TIME=”zh_CN.UTF-8″
LC_COLLATE=”zh_CN.UTF-8″
LC_MONETARY=”zh_CN.UTF-8″
LC_MESSAGES=”zh_CN.UTF-8″
LC_PAPER=”zh_CN.UTF-8″
LC_NAME=”zh_CN.UTF-8″
LC_ADDRESS=”zh_CN.UTF-8″
LC_TELEPHONE=”zh_CN.UTF-8″
LC_MEASUREMENT=”zh_CN.UTF-8″
LC_IDENTIFICATION=”zh_CN.UTF-8″
LC_ALL=
說明系統的中文編碼是采用utf8的,為了在xshell中正常的顯示中文,我們要把xshell編碼方式改成utf8
[文件]–>[打開]–>在打開的session中選擇連接的那個 ,點擊properties -> [Terminal ] ,在右邊的translation先選擇utf8,然后重新連接服務器即可。
如何將windwos上的文件傳輸到虛擬機上的linux 上
輸入:
rz –help
如果出現
程序“rz”尚未安裝。 您可以使用以下命令安裝:
sudo apt-get install lrzsz
說明你還沒有安裝rz 輸入:
sudo apt-get install lrzsz
安裝rz
切換到你要存放文件的目錄
File->Transfer->Send ZMODEM,出現一個對話框,選擇你要傳輸的文件就可以了。
- For disable IPv6 on Ubuntu Server, we need add these configuration lines in /etc/sysctl.conf
# IPv6 configuration
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
-
Reload configurationf or sysctl.conf
sysctl -p
-
Check IPv6 is disabled on Ubuntu Server
root@ip-10-48-234-13:/# ip addr1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 12:31:3c:03:e9:fb brd ff:ff:ff:ff:ff:ff
inet 10.48.234.13/23 brd 10.48.235.255 scope global eth0
先查看
rpm -qa | grep java
顯示如下信息:
javapackages-tools-0.9.1-1.2.amzn1.noarch
java-1.6.0-openjdk-1.6.0.0-62.1.11.11.90.55.amzn1.x86_64
tzdata-java-2013c-2.18.amzn1.noarch
卸載:
rpm -e --nodeps javapackages-tools-0.9.1-1.2.amzn1.noarch
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-62.1.11.11.90.55.amzn1.x86_64
rpm -e --nodeps tzdata-java-2013c-2.18.amzn1.noarch
還有一些其他的命令
rpm -qa | grep gcj
rpm -qa | grep jdk
如果出現找不到openjdk source的話,那么還可以這樣卸載
yum -y remove java java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
yum -y remove java java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
<1># rpm -qa|grep jdk ← 查看jdk的信息或直接執行
或
# rpm -q jdk
或
# java -version
<2># rpm -qa | grep gcj ← 確認gcj的版本號
<3># yum -y remove java-1.4.2-gcj-compat ← 卸載gcj
安裝SUN JDK
http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase6-419409.html#jdk-6u45-oth-JPR