#
https://www.oschina.net/news/91924/10-open-source-technology-trends-2018
http://www.iteye.com/news/32843
JAX-RS 2比JAX-RS 1增加了過濾器、攔截器、異步處理等特性。@import url(http://www.tkk7.com/CuteSoft_Client/CuteEditor/Load.ashx?type=style&file=SyntaxHighlighter.css);@import url(/css/cuteeditor.css);
JAXRSClientSpringBoot
CXFSpringBoot
Restfull Webservice書源碼
JAX-RS 2.0 REST客戶端編程實例
本人的DEMO
設計文檔模板:
- 系統(tǒng)背景和定位
- 業(yè)務需求描述
- 領域語言整理,主要是整理領域中的各種術語的定義,名詞解釋
- 領域劃分(分析出子域、核心域、支撐域)
- 系統(tǒng)用例圖
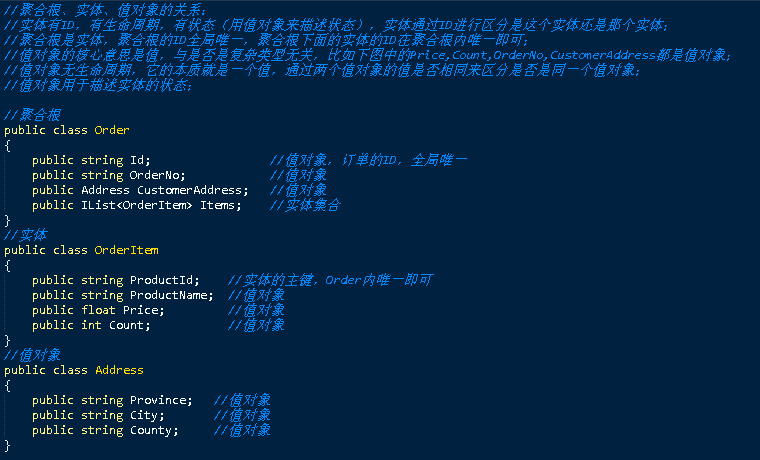
- 每個子域的領域模型設計(實體、值對象、聚合、領域事件,需要注意的是:領域模型是需要抽象的,要分析業(yè)務本質,而不是簡單的直接對需求進行建模)
- 領域模型詳細說明(如為什么這樣設計的原因、模型內對象的關系、各種業(yè)務規(guī)則、數(shù)據(jù)一致性規(guī)則等)
- 領域服務、倉儲、工廠設計
- Saga業(yè)務流程設計
- 關鍵聚合根的狀態(tài)流轉圖
- 場景走查(講述如何通過領域模型、領域服務、倉儲、Saga流程等完成系統(tǒng)用例以及關鍵業(yè)務流程的)
- 架構設計(如傳統(tǒng)三層架構、經(jīng)典四層架構、CQRS/ES架構)
一些其他的思考:
- 去除一切花俏的建模技巧,我覺得最重要的方向就是去努力分析問題和事物的本質,針對這個本質進行領域建模。這個領域建模,最主要的還是鍛煉的人的事物抽象能力。10個人,建出來的領域模型都不同。本質原因就是大家對同一個問題的理解不同,對事物的本質的理解不同。雖然最終都能解決當前的問題,但是對適應未來需求變化的能力卻是不同。
- 所以,我們要把時間花在多理解業(yè)務上,讓自己成為領域專家,只有這樣,才能充分理解業(yè)務。多理解一點業(yè)務,你才能更好的抽象出業(yè)務本質背后的領域模型。很少有人能做到很快理解業(yè)務,并很快針對業(yè)務設計出正確的領域模型,至少我是不行。
- 領域建模需要時間,是一個迭代的過程,人無完人。而時間很多時候也不會很充足,所以,不太可能一步到位把領域設計做的很完美。我們在整體項目規(guī)劃的時候可能會有個大的架構設計、業(yè)務大圖(邊界思維),但是不可能達到領域設計的粒度,只能是一期一期的完善,到最后可能才會有完整的上面的目錄內容。每一期都需要考慮支持的場景約束、上下文、系統(tǒng)邊界、持續(xù)集成的相關設計。設計product, not project。
從遇到問題開始
當人們要做一個軟件系統(tǒng)時,一般總是因為遇到了什么問題,然后希望通過一個軟件系統(tǒng)來解決。
比如,我是一家企業(yè),然后我覺得我現(xiàn)在線下銷售自己的產(chǎn)品還不夠,我希望能夠在線上也能銷售自己的產(chǎn)品。所以,自然而然就想到要做一個普通電商系統(tǒng),用于實現(xiàn)在線銷售自己企業(yè)產(chǎn)品的目的。
再比如,我是一家互聯(lián)網(wǎng)公司,公司有很多系統(tǒng)對外提供服務,面向很多客戶端設備。但是最近由于各種原因,導致服務經(jīng)常出故障。所以,我們希望通過各種措施提高服務的質量和穩(wěn)定性。其中的一個措施就是希望能做一個灰度發(fā)布的平臺,這個平臺可以提供灰度發(fā)布的服務。然后,當某個業(yè)務系統(tǒng)做了一些修改并需要發(fā)布時,可以使用我們的灰度發(fā)布平臺來非常方便的實現(xiàn)灰度發(fā)布的功能。比如在灰度發(fā)布平臺上方便的定制允許哪些特定的客戶端才會訪問新服務,哪些客戶端繼續(xù)使用老服務。灰度發(fā)布平臺可以提供各種灰度的策略。有了這樣的灰度發(fā)布機制,那即便系統(tǒng)的新邏輯有什么問題,受影響的面也不會很大,在可控范圍內。所以,如果公司里的所有對外提供服務的系統(tǒng)都接入了灰度平臺,那這些系統(tǒng)的發(fā)布環(huán)節(jié)就可以更加有保障了。
總之,我們做任何一個軟件系統(tǒng),都是有原因的,否則就沒必要做這個系統(tǒng),而這個原因就是我們遇到的問題。所以,通過問題,我們就知道了我們需要一個什么樣的系統(tǒng),這個系統(tǒng)解決什么樣的問題。最后,我們就很自然的得出了一個目標,即知道了自己要什么。比如我要做一個論壇、一個博客系統(tǒng)、一個電商平臺、一個灰度發(fā)布系統(tǒng)、一個IDE、一個分布式消息隊列、一個通信框架,等等。
DDD切入點1 - 理解概念
DDD的全稱為Domain-driven Design,即領域驅動設計。下面我從領域、問題域、領域模型、設計、驅動這幾個詞語的含義和聯(lián)系的角度去闡述DDD是如何融入到我們平時的軟件開發(fā)初期階段的。要理解什么是領域驅動設計,首先要理解什么是領域,什么是設計,還有驅動是什么意思,什么驅動什么。
什么是領域(Domain)?
前面我們已經(jīng)清楚的知道我們現(xiàn)在要做一個什么樣的系統(tǒng),這個系統(tǒng)需要解決什么問題。我認為任何一個系統(tǒng)都會屬于某個特定的領域,比如論壇是一個領域,只要你想做一個論壇,那這個論壇的核心業(yè)務是確定的,比如都有用戶發(fā)帖、回帖等核心基本功能。比如電商平臺、普通電商系統(tǒng),這種都屬于網(wǎng)上電商領域,只要是這個領域的系統(tǒng),那都有商品瀏覽、購物車、下單、減庫存、付款交易等核心環(huán)節(jié)。所以,同一個領域的系統(tǒng)都具有相同的核心業(yè)務,因為他們要解決的問題的本質是類似的。
因此,我們可以推斷出,一個領域本質上可以理解為就是一個問題域,只要是同一個領域,那問題域就相同。所以,只要我們確定了系統(tǒng)所屬的領域,那這個系統(tǒng)的核心業(yè)務,即要解決的關鍵問題、問題的范圍邊界就基本確定了。通常我們說,要成為一個領域的專家,必須要在這個領域深入研究很多年才行。因為只有你研究了很多年,你才會遇到非常多的該領域的問題,同時你解決這個領域中的問題的經(jīng)驗也非常豐富。很多時候,領域專家比技術專家更加吃香,比如金融領域的專家。
什么是設計(Design)?
DDD中的設計主要指領域模型的設計。為什么是領域模型的設計而不是架構設計或其他的什么設計呢?因為DDD是一種基于模型驅動開發(fā)的軟件開發(fā)思想,強調領域模型是整個系統(tǒng)的核心,領域模型也是整個系統(tǒng)的核心價值所在。每一個領域,都有一個對應的領域模型,領域模型能夠很好的幫我們解決復雜的業(yè)務問題。
從領域和代碼實現(xiàn)的角度來理解,領域模型綁定了領域和代碼實現(xiàn),確保了最終的代碼實現(xiàn)就一定是解決了領域中的核心問題的。因為:1)領域驅動領域模型設計;2)領域模型驅動代碼實現(xiàn)。我們只要保證領域模型的設計是正確的,就能確定領域模型可以解決領域中的核心問題;同理,我們只要保證代碼實現(xiàn)是嚴格按照領域模型的意圖來落地的,那就能保證最后出來的代碼能夠解決領域的核心問題的。這個思路,和傳統(tǒng)的分析、設計、編碼這幾個階段被割裂(并且每個階段的產(chǎn)物也不同)的軟件開發(fā)方法學形成鮮明的對比。
什么是驅動(Driven)?
上面其實已經(jīng)提到了,就是:1)領域驅動領域模型設計;2)領域模型驅動代碼實現(xiàn)。這個就和我們傳統(tǒng)的數(shù)據(jù)庫驅動開發(fā)的思路形成對比了。DDD中,我們總是以領域為邊界,分析領域中的核心問題(核心關注點),然后設計對應的領域模型,再通過領域模型驅動代碼實現(xiàn)。而像數(shù)據(jù)庫設計、持久化技術等這些都不是DDD的核心,而是外圍的東西。
領域驅動設計(DDD)告訴我們的最大價值我覺得是:當我們要開發(fā)一個系統(tǒng)時,應該盡量先把領域模型想清楚,然后再開始動手編碼,這樣的系統(tǒng)后期才會很好維護。但是,很多項目(尤其是互聯(lián)網(wǎng)項目,為了趕工)都是一開始模型沒想清楚,一上來就開始建表寫代碼,代碼寫的非常冗余,完全是過程是的思考方式,最后導致系統(tǒng)非常難以維護。而且更糟糕的是,出來混總是要還的,前期的領域模型設計的不好,不夠抽象,如果你的系統(tǒng)會長期需要維護和適應業(yè)務變化,那后面你一定會遇到各種問題維護上的困難,比如數(shù)據(jù)結構設計不合理,代碼到處冗余,改BUG到處引入新的BUG,新人對這種代碼上手困難,等。而那時如果你再想重構模型,那要付出的代價會比一開始重新開發(fā)還要大,因為你還要考慮兼容歷史的數(shù)據(jù),數(shù)據(jù)遷移,如何平滑發(fā)布等各種頭疼的問題。所以,就導致我們最后天天加班。
雖然,我們都知道這個道理,但是我也明白,人的習慣很難改變的,大部分人都很難從面向過程式的想到哪里寫到哪里的思想轉變?yōu)榛谙到y(tǒng)化的模型驅動的思維。我想,這或許是DDD很難在中國或國外流行起來的原因吧。但是,我想這不應該成為我們放棄學習DDD的原因,對吧!
概念總結:
- 領域就是問題域,有邊界,領域中有很多問題;
- 任何一個系統(tǒng)要解決的那個大問題都對應一個領域;
- 通過建立領域模型來解決領域中的核心問題,模型驅動的思想;
- 領域建模的目標針對我們在領域中所關心的問題,即只針對核心關注點,而不是整個領域中的所有問題;
- 領域模型在設計時應考慮一定的抽象性、通用性,以及復用價值;
- 通過領域模型驅動代碼的實現(xiàn),確保代碼讓領域模型落地,代碼最終能解決問題;
- 領域模型是系統(tǒng)的核心,是領域內的業(yè)務的直接沉淀,具有非常大的業(yè)務價值;
- 技術架構設計或數(shù)據(jù)存儲等是在領域模型的外圍,幫助領域模型進行落地;
DDD切入點2 - 理解領域、拆分領域、細化領域
理解領域知識是基礎
上面我們通過第一步,雖然我們明確了要做一個什么樣的系統(tǒng),該系統(tǒng)主要解決什么問題,但是就這樣我們還無法開始進行實際的需求分析和模型設計,我們還必須將我們的問題進行拆分,需求進行細化。有些時候,需求方,即提出問題的人,很可能自己不清楚具體想要什么。他只知道一個概念,一個大的目標。比如他只知道要做一個股票交易系統(tǒng),一個灰度發(fā)布系統(tǒng),一個電商平臺,一個開發(fā)工具,等。但是他不清楚這些系統(tǒng)應該具體做成什么樣子。這個時候,我認為領域專家就非常重要了,DDD也非常強調領域專家的重要性。因為領域專家對這個領域非常了解,對領域內的各種業(yè)務場景和各種業(yè)務規(guī)則也非常清楚,總之,對這個領域內的一切業(yè)務相關的知識都非常了解。所以,他們自然就有能力表達出系統(tǒng)該做成什么樣子。所以,要知道一個系統(tǒng)到底該做成什么樣子,到底哪些是核心業(yè)務關注點,只能靠沉淀領域內的各種知識,別無他法。因此,假設你現(xiàn)在打算做一個電商平臺,但是你對這個領域沒什么了解,那你一定得先去了解下該領域內主流的電商平臺,比如淘寶、天貓、京東、亞馬遜等。這個了解的過程就是你沉淀領域知識的過程。如果你不了解,就算你領域建模的能力再強,各種技術架構能力再強也是使不上力。領域專家不是某個固定的角色,而是某一類人,這類人對這個領域非常了解。比如,一個開發(fā)人員也可以是一個領域專家。假設你在一個公司開發(fā)和維護一個系統(tǒng)已經(jīng)好幾年了,但是這個系統(tǒng)的產(chǎn)品經(jīng)理(PD)可能已經(jīng)換過好幾任了,這種情況下,我相信這幾任產(chǎn)品經(jīng)理都沒有比你更熟悉這個領域。
拆分領域
上面我們明白了,領域建模的基礎是要先理解領域,讓自己成為領域專家。如果做到了這點,我們就打好了堅實的基礎了。但是,有時一個領域往往太復雜,涉及到的領域概念、業(yè)務規(guī)則、交互流程太多,導致我們沒辦法直接針對這個大的領域進行領域建模。所以,我們需要將領域進行拆分,本質上就是把大問題拆分為小問題,然后各個擊破的思路。然后既然把一個大的領域劃分為了多個小的領域(子域),那最關鍵的就是要理清每個子域的邊界;然后要搞清楚哪些子域是核心子域,哪些是非核心子域,哪些是公共支撐子域;然后,還要思考子域之間的聯(lián)系是什么。那么,我們該如何劃分子域呢?我的個人看法是從業(yè)務相關性的角度去思考,也就是我們平時說的按業(yè)務功能為出發(fā)點進行劃分。還是拿經(jīng)典的電商系統(tǒng)來分析,通常一個電商系統(tǒng)都會包含好幾個大塊,比如:
- 會員中心:負責用戶賬號登錄、用戶信息的管理;
- 商品中心:負責商品的展示、導航、維護;
- 訂單中心:負責訂單的生成和生命周期管理;
- 交易中心:負責交易相關的業(yè)務;
- 庫存中心:負責維護商品的庫存;
- 促銷中心:負責各種促銷活動的支持;
上面這些中心看起來很自然,因為大家對電子商務的這個領域都已經(jīng)非常熟悉了,所以都沒什么疑問,好像很自然的樣子。所以,領域劃分是不是就是沒什么挑戰(zhàn)了呢?顯然不是。之所以我們覺得子域劃分很簡單,是因為我們對整個大領域非常了解了。如果我們遇到一個冷門的領域,就沒辦法這么容易的去劃分子域了。這就需要我們先去努力理解領域內的知識。所以,我個人從來不相信什么子域劃分的技巧什么的東西,因為我覺得這個工作沒有任何訣竅可以使用。當我們不了解一個東西的時候,如何去拆解它?當我們對整個領域有一定的熟悉了,了解了領域內的相關業(yè)務的本質和關系,我們就自然而然的能劃分出合理的子域了。不過并不是所有的系統(tǒng)都需要劃分子域的,有些系統(tǒng)只是解決一個小問題,這個問題不復雜,可能只有一兩個核心概念。所以,這種系統(tǒng)完全不需要再劃分子域。但不是絕對的,當一個領域,我們的關注點越來越多,每個關注點我們關注的信息越來越多的時候,我們會不由自主的去進一步的劃分子域。比如,也許我們一開始將商品和商品的庫存都放在商品中心里,但是后來由于庫存的維護越來越復雜,導致揉在一起對我們的系統(tǒng)維護帶來一定的困難時,我們就會考慮將兩者進行拆分,這個就是所謂的業(yè)務垂直分割。
細化子域
通過上面的兩步,我們了解了領域里的知識,也對領域進行了子域劃分。但這樣還不夠,憑這些我們還無法進行后續(xù)的領域模型設計。我們還必須再進一步細化每個子域,進一步明確每個子域的核心關注點,即需求細化。我覺得我們需要細化的方面有以下幾點:
- 梳理領域概念:梳理出領域內我們關注的概念、概念的關系,并統(tǒng)一交流詞匯,形成統(tǒng)一語言;
- 梳理業(yè)務規(guī)則:梳理出領域內我們關注的各種業(yè)務規(guī)則,DDD中叫不變性(invariants),比如唯一性規(guī)則,余額不能小于零等;
- 梳理業(yè)務場景:梳理出領域內的核心業(yè)務場景,比如電商平臺中的加入購物車、提交訂單、發(fā)起付款等核心業(yè)務場景;
- 梳理業(yè)務流程:梳理出領域內的關鍵業(yè)務流程,比如訂單處理流程,退款流程等;
從上面這4個方面,我們從領域概念、業(yè)務規(guī)則、交互場景、業(yè)務流程等維度梳理了我們到底要什么,整理了整個系統(tǒng)應該具備的功能。這個工作我覺得是一個非常具有創(chuàng)造性和有難度的工作。我們一方面會主觀的定義我們想要什么;另一方面,我們還會思考我們要的東西的合理性。我認為這個就是產(chǎn)品經(jīng)理的工作,產(chǎn)品經(jīng)理必須要負起職責,把他的產(chǎn)品充分設計好,從各個方面去考慮,如何設計一個產(chǎn)品,才能更好的解決用戶的核心訴求,即領域內的核心問題。如果對領域不夠了解,如果想不清楚用戶到底要什么,如果思考問題不夠全面,談何設計出一個合理的產(chǎn)品呢?
關于領域概念的梳理,我覺得可以采用四色原型分析法,這個分析法通過系統(tǒng)的方法,將概念劃分為不同的種類,為不同種類的概念標注不同的顏色。然后將這些概念有機的組合起來,從而讓我們可以清晰的分析出概念和概念之間的關系。有興趣的同學可以在網(wǎng)上搜索下四色原型。
注意:上面我說的這四點,重點是梳理出我們要什么功能,而不是思考如何實現(xiàn)這些功能,如何實現(xiàn)是軟件設計人員的職責。
DDD切入點3 - 領域模型設計
這部分內容,我想學習DDD的人都很熟悉了。DDD原著中提出了很多實用的建模工具:聚合、實體、值對象、工廠、倉儲、領域服務、領域事件。我們可以使用這些工具,來設計每一個子域的領域模型。最終通過領域模型圖將設計沉淀下來。要使用這些工具,首先就要理解每個工具的含義和使用場景。不要以為很簡單哦,比如聚合的劃分就是一個非常具有藝術的活。同一個系統(tǒng),不同的人設計出來的聚合是完全不同的。而且很有可能高手之間的最后設計出來的差別反而更大,實際上我認為是世界觀的相互碰撞,呵呵。所以,要領域建模,我覺得每個人都應該去學學哲學知識,這有助于我們更好的認識世界,更好的理解事物的本質。
關于這些建模工具的概念和如何運用我就不多展開了,我博客里也有很多這方面的介紹。下面我再講一下我認為比較重要的東西,比如到底該如何領域建模?步驟應該是怎么樣的?
領域建模的方法
通過上面我介紹的細化子域的內容,現(xiàn)在再來談該如何領域建模,我覺得就方便很多了。我的主要方法是:
- 劃分好邊界上下文,通常每個子域(sub domain)對應一個邊界上下文(bounded context),同一個邊界上下文中的概念是明確的,沒有任何歧義;
- 在每個邊界上下文中設計領域模型,具體的領域模型設計方法有很多種,如以場景為出發(fā)點的四色原型分析法,或者我早期寫的這篇文章;這個步驟最核心的就是找出聚合根,并找出每個聚合根包含的信息;關于如何設計聚合,可以看一下我寫的這篇文章;
- 畫出領域模型圖,圈出每個模型中的聚合邊界;
- 設計領域模型時,要考慮該領域模型是否滿足業(yè)務規(guī)則,同時還要綜合考慮技術實現(xiàn)等問題,比如并發(fā)問題;領域模型不是概念模型,概念模型不關注技術實現(xiàn),領域模型關心;所以領域模型才能直接指導編碼實現(xiàn);
- 思考領域模型是如何在業(yè)務場景中發(fā)揮作用的,以及是如何參與到業(yè)務流程的每個環(huán)節(jié)的;
- 場景走查,確認領域模型是否能滿足領域中的業(yè)務場景和業(yè)務流程;
- 模型持續(xù)重構、完善、精煉;
領域模型的核心作用:
- 抽象了領域內的核心概念,并建立概念之間的關系;
- 領域模型承擔了領域內的狀態(tài)的維護;
- 領域模型維護了領域內的數(shù)據(jù)之間的業(yè)務規(guī)則,數(shù)據(jù)一致性;
下圖是我最近做個一個普通電商系統(tǒng)的商品中心的領域模型圖,給大家參考:
領域模型設計只是軟件設計中的一小部分
需要特別注意的是,領域模型設計只是整個軟件設計中的很小一部分。除了領域模型設計之外,要落地一個系統(tǒng),我們還有非常多的其他設計要做,比如:
- 容量規(guī)劃
- 架構設計
- 數(shù)據(jù)庫設計
- 緩存設計
- 框架選型
- 發(fā)布方案
- 數(shù)據(jù)遷移、同步方案
- 分庫分表方案
- 回滾方案
- 高并發(fā)解決方案
- 一致性選型
- 性能壓測方案
- 監(jiān)控報警方案
等等。上面這些都需要我們平時的大量學習和積累。作為一個合格的開發(fā)人員或架構師,我覺得除了要會DDD領域驅動設計,還要會上面這么多的技術能力,確實是非常不容易的。所以,千萬不要以為會DDD了就以為自己很牛逼,實際上你會的只是軟件設計中的冰山一角而已。
總結
本文的重點是基于我個人對DDD的一些理解,希望能整理出一些自己總結出來的一些感悟和經(jīng)驗,并分享給大家。我相信很多人已經(jīng)看過太多DDD書上的東西,我總是感覺書上的東西看似都太”正規(guī)“,很多時候我們讀了之后很難消化,就算理解了書里的內容,當我們想要運用到實踐中時,總是感覺無從下手。本文希望通過通俗易懂的文字,介紹了一部分我對DDD的學習感悟和實踐心得,希望能給大家一些啟發(fā)和幫助。
最近幾年,在DDD的領域,我們經(jīng)常會看到CQRS架構的概念。我個人也寫了一個ENode框架,專門用來實現(xiàn)這個架構。CQRS架構本身的思想其實非常簡單,就是讀寫分離。是一個很好理解的思想。就像我們用MySQL數(shù)據(jù)庫的主備,數(shù)據(jù)寫到主,然后查詢從備來查,主備數(shù)據(jù)的同步由MySQL數(shù)據(jù)庫自己負責,這是一種數(shù)據(jù)庫層面的讀寫分離。關于CQRS架構的介紹其實已經(jīng)非常多了,大家可以自行百度或google。我今天主要想總結一下這個架構相對于傳統(tǒng)架構(三層架構、DDD經(jīng)典四層架構)在數(shù)據(jù)一致性、擴展性、可用性、伸縮性、性能這幾個方面的異同,希望可以總結出一些優(yōu)點和缺點,為大家在做架構選型時提供參考。
前言
CQRS架構由于本身只是一個讀寫分離的思想,實現(xiàn)方式多種多樣。比如數(shù)據(jù)存儲不分離,僅僅只是代碼層面讀寫分離,也是CQRS的體現(xiàn);然后數(shù)據(jù)存儲的讀寫分離,C端負責數(shù)據(jù)存儲,Q端負責數(shù)據(jù)查詢,Q端的數(shù)據(jù)通過C端產(chǎn)生的Event來同步,這種也是CQRS架構的一種實現(xiàn)。今天我討論的CQRS架構就是指這種實現(xiàn)。另外很重要的一點,C端我們還會引入Event Sourcing+In Memory這兩種架構思想,我認為這兩種思想和CQRS架構可以完美的結合,發(fā)揮CQRS這個架構的最大價值。
數(shù)據(jù)一致性
傳統(tǒng)架構,數(shù)據(jù)一般是強一致性的,我們通常會使用數(shù)據(jù)庫事務保證一次操作的所有數(shù)據(jù)修改都在一個數(shù)據(jù)庫事務里,從而保證了數(shù)據(jù)的強一致性。在分布式的場景,我們也同樣希望數(shù)據(jù)的強一致性,就是使用分布式事務。但是眾所周知,分布式事務的難度、成本是非常高的,而且采用分布式事務的系統(tǒng)的吞吐量都會比較低,系統(tǒng)的可用性也會比較低。所以,很多時候,我們也會放棄數(shù)據(jù)的強一致性,而采用最終一致性;從CAP定理的角度來說,就是放棄一致性,選擇可用性。
CQRS架構,則完全秉持最終一致性的理念。這種架構基于一個很重要的假設,就是用戶看到的數(shù)據(jù)總是舊的。對于一個多用戶操作的系統(tǒng),這種現(xiàn)象很普遍。比如秒殺的場景,當你下單前,也許界面上你看到的商品數(shù)量是有的,但是當你下單的時候,系統(tǒng)提示商品賣完了。其實我們只要仔細想想,也確實如此。因為我們在界面上看到的數(shù)據(jù)是從數(shù)據(jù)庫取出來的,一旦顯示到界面上,就不會變了。但是很可能其他人已經(jīng)修改了數(shù)據(jù)庫中的數(shù)據(jù)。這種現(xiàn)象在大部分系統(tǒng)中,尤其是高并發(fā)的WEB系統(tǒng),尤其常見。
所以,基于這樣的假設,我們知道,即便我們的系統(tǒng)做到了數(shù)據(jù)的強一致性,用戶還是很可能會看到舊的數(shù)據(jù)。所以,這就給我們設計架構提供了一個新的思路。我們能否這樣做:我們只需要確保系統(tǒng)的一切添加、刪除、修改操作所基于的數(shù)據(jù)是最新的,而查詢的數(shù)據(jù)不必是最新的。這樣就很自然的引出了CQRS架構了。C端數(shù)據(jù)保持最新、做到數(shù)據(jù)強一致;Q端數(shù)據(jù)不必最新,通過C端的事件異步更新即可。所以,基于這個思路,我們開始思考,如何具體的去實現(xiàn)CQ兩端。看到這里,也許你還有一個疑問,就是為何C端的數(shù)據(jù)是必須要最新的?這個其實很容易理解,因為你要修改數(shù)據(jù),那你可能會有一些修改的業(yè)務規(guī)則判斷,如果你基于的數(shù)據(jù)不是最新的,那意味著判斷就失去意義或者說不準確,所以基于老的數(shù)據(jù)所做的修改是沒有意義的。
擴展性
傳統(tǒng)架構,各個組件之間是強依賴,都是對象之間直接方法調用;而CQRS架構,則是事件驅動的思想;從微觀的聚合根層面,傳統(tǒng)架構是應用層通過過程式的代碼協(xié)調多個聚合根一次性以事務的方式完成整個業(yè)務操作。而CQRS架構,則是以Saga的思想,通過事件驅動的方式,最終實現(xiàn)多個聚合根的交互。另外,CQRS架構的CQ兩端也是通過事件的方式異步進行數(shù)據(jù)同步,也是事件驅動的一種體現(xiàn)。上升到架構層面,那前者就是SOA的思想,后者是EDA的思想。SOA是一個服務調用另一個服務完成服務之間的交互,服務之間緊耦合;EDA是一個組件訂閱另一個組件的事件消息,根據(jù)事件信息更新組件自己的狀態(tài),所以EDA架構,每個組件都不會依賴其他的組件;組件之間僅僅通過topic產(chǎn)生關聯(lián),耦合性非常低。
上面說了兩種架構的耦合性,顯而易見,耦合性低的架構,擴展性必然好。因為SOA的思路,當我要加一個新功能時,需要修改原來的代碼;比如原來A服務調用了B,C兩個服務,后來我們想多調用一個服務D,則需要改A服務的邏輯;而EDA架構,我們不需要動現(xiàn)有的代碼,原來有B,C兩訂閱者訂閱A產(chǎn)生的消息,現(xiàn)在只需要增加一個新的消息訂閱者D即可。
從CQRS的角度來說,也有一個非常明顯的例子,就是Q端的擴展性。假設我們原來Q端只是使用數(shù)據(jù)庫實現(xiàn)的,但是后來系統(tǒng)的訪問量增大,數(shù)據(jù)庫的更新太慢或者滿足不了高并發(fā)的查詢了,所以我們希望增加緩存來應對高并發(fā)的查詢。那對CQRS架構來說很容易,我們只需要增加一個新的事件訂閱者,用來更新緩存即可。應該說,我們可以隨時方便的增加Q端的數(shù)據(jù)存儲類型。數(shù)據(jù)庫、緩存、搜索引擎、NoSQL、日志,等等。我們可以根據(jù)自己的業(yè)務場景,選擇合適的Q端數(shù)據(jù)存儲,實現(xiàn)快速查詢的目的。這一切都歸功于我們C端記錄了所有模型變化的事件,當我們要增加一種新的View存儲時,可以根據(jù)這些事件得到View存儲的最新狀態(tài)。這種擴展性在傳統(tǒng)架構下是很難做到的。
可用性
可用性,無論是傳統(tǒng)架構還是CQRS架構,都可以做到高可用,只要我們做到讓我們的系統(tǒng)中每個節(jié)點都無單點即可。但是,相比之下,我覺得CQRS架構在可用性方面,我們可以有更多的回避余地和選擇空間。
傳統(tǒng)架構,因為讀寫沒有分離,所以可用性要把讀寫合在一起綜合考慮,難度會比較更大。因為傳統(tǒng)架構,如果一個系統(tǒng)的高峰期的并發(fā)寫入很大,比如為2W,并發(fā)讀取也很大,比如為10W。那該系統(tǒng)必須優(yōu)化到能同時支持這種高并發(fā)的寫入和查詢,否則系統(tǒng)就會在高峰時掛掉。這個就是基于同步調用思路的系統(tǒng)的缺點,沒有一個東西去削峰填谷,保存瞬間多出來的請求,而必須讓系統(tǒng)不管遇到多少請求,都必須能及時處理完,否則就會造成雪崩效應,造成系統(tǒng)癱瘓。但是一個系統(tǒng),不會一直處在高峰,高峰可能只有半小時或1小時;但為了確保高峰時系統(tǒng)不掛掉,我們必須使用足夠的硬件去支撐這個高峰。而大部分時候,都不需要這么高的硬件資源,所以會造成資源的浪費。所以,我們說基于同步調用、SOA思想的系統(tǒng)的實現(xiàn)成本是非常昂貴的。
而在CQRS架構下,因為CQRS架構把讀和寫分離了,所以可用性相當于被隔離在了兩個部分去考慮。我們只需要考慮C端如何解決寫的可用性,Q端如何解決讀的可用性即可。C端解決可用性,我覺得是更加容易的,因為C端是消息驅動的。我們要做任何數(shù)據(jù)修改時,都會發(fā)送Command到分布式消息隊列,然后后端消費者處理Command->產(chǎn)生領域事件->持久化事件->發(fā)布事件到分布式消息隊列->最后事件被Q端消費。這個鏈路是消息驅動的。相比傳統(tǒng)架構的直接服務方法調用,可用性要高很多。因為就算我們處理Command的后端消費者暫時掛了,也不會影響前端Controller發(fā)送Command,Controller依然可用。從這個角度來說,CQRS架構在數(shù)據(jù)修改上可用性要更高。不過你可能會說,要是分布式消息隊列掛了呢?呵呵,對,這確實也是有可能的。但是一般分布式消息隊列屬于中間件,一般中間件都具有很高的可用性(支持集群和主備切換),所以相比我們的應用來說,可用性要高很多。另外,因為命令是先發(fā)送到分布式消息隊列,這樣就能充分利用分布式消息隊列的優(yōu)勢:異步化、拉模式、削峰填谷、基于隊列的水平擴展。這些特性可以保證即便前端Controller在高峰時瞬間發(fā)送大量的Command過來,也不會導致后端處理Command的應用掛掉,因為我們是根據(jù)自己的消費能力拉取Command。這點也是CQRS C端在可用性方面的優(yōu)勢,其實本質也是分布式消息隊列帶來的優(yōu)勢。所以,從這里我們可以體會到EDA架構(事件驅動架構)是非常有價值的,這個架構也體現(xiàn)了我們目前比較流行的Reactive Programming(響應式編程)的思想。
然后,對于Q端,應該說和傳統(tǒng)架構沒什么區(qū)別,因為都是要處理高并發(fā)的查詢。這點以前怎么優(yōu)化的,現(xiàn)在還是怎么優(yōu)化。但是就像我上面可擴展性里強調的,CQRS架構可以更方便的提供更多的View存儲,數(shù)據(jù)庫、緩存、搜索引擎、NoSQL,而且這些存儲的更新完全可以并行進行,互相不會拖累。理想的場景,我覺得應該是,如果你的應用要實現(xiàn)全文索引這種復雜查詢,那可以在Q端使用搜索引擎,比如ElasticSearch;如果你的查詢場景可以通過keyvalue這種數(shù)據(jù)結構滿足,那我們可以在Q端使用Redis這種NoSql分布式緩存。總之,我認為CQRS架構,我們解決查詢問題會比傳統(tǒng)架構更加容易,因為我們選擇更多了。但是你可能會說,我的場景只能用關系型數(shù)據(jù)庫解決,且查詢的并發(fā)也是非常高。那沒辦法了,唯一的辦法就是分散查詢IO,我們對數(shù)據(jù)庫做分庫分表,以及對數(shù)據(jù)庫做一主多備,查詢走備機。這點上,解決思路就是和傳統(tǒng)架構一樣了。
性能、伸縮性
本來想把性能和伸縮性分開寫的,但是想想這兩個其實有一定的關聯(lián),所以決定放在一起寫。
伸縮性的意思是,當一個系統(tǒng),在100人訪問時,性能(吞吐量、響應時間)很不錯,在100W人訪問時性能也同樣不錯,這就是伸縮性。100人訪問和100W人訪問,對系統(tǒng)的壓力顯然是不同的。如果我們的系統(tǒng),在架構上,能夠做到通過簡單的增加機器,就能提高系統(tǒng)的服務能力,那我們就可以說這種架構的伸縮性很強。那我們來想想傳統(tǒng)架構和CQRS架構在性能和伸縮性上面的表現(xiàn)。
說到性能,大家一般會先思考一個系統(tǒng)的性能瓶頸在哪里。只要我們解決了性能瓶頸,那系統(tǒng)就意味著具有通過水平擴展來達到可伸縮的目的了(當然這里沒有考慮數(shù)據(jù)存儲的水平擴展)。所以,我們只要分析一下傳統(tǒng)架構和CQRS架構的瓶頸點在哪里即可。
傳統(tǒng)架構,瓶頸通常在底層數(shù)據(jù)庫。然后我們一般的做法是,對于讀:通常使用緩存就可以解決大部分查詢問題;對于寫:辦法也有很多,比如分庫分表,或者使用NoSQL,等等。比如阿里大量采用分庫分表的方案,而且未來應該會全部使用高大上的OceanBase來替代分庫分表的方案。通過分庫分表,本來一臺數(shù)據(jù)庫服務器高峰時可能要承受10W的高并發(fā)寫,如果我們把數(shù)據(jù)放到十臺數(shù)據(jù)庫服務器上,那每臺機器只需要承擔1W的寫,相對于要承受10W的寫,現(xiàn)在寫1W就顯得輕松很多了。所以,應該說數(shù)據(jù)存儲對傳統(tǒng)架構來說,也早已不再是瓶頸了。
傳統(tǒng)架構一次數(shù)據(jù)修改的步驟是:1)從DB取出數(shù)據(jù)到內存;2)內存修改數(shù)據(jù);3)更新數(shù)據(jù)回DB。總共涉及到2次數(shù)據(jù)庫IO。
然后CQRS架構,CQ兩端加起來所用的時間肯定比傳統(tǒng)架構要多,因為CQRS架構最多有3次數(shù)據(jù)庫IO,1)持久化命令;2)持久化事件;3)根據(jù)事件更新讀庫。為什么說最多?因為持久化命令這一步不是必須的,有一種場景是不需要持久化命令的。CQRS架構中持久化命令的目的是為了做冪等處理,即我們要防止同一個命令被處理兩次。那哪一種場景下可以不需要持久化命令呢?就是當命令時在創(chuàng)建聚合根時,可以不需要持久化命令,因為創(chuàng)建聚合根所產(chǎn)生的事件的版本號總是為1,所以我們在持久化事件時根據(jù)事件版本號就能檢測到這種重復。
所以,我們說,你要用CQRS架構,就必須要接受CQ數(shù)據(jù)的最終一致性,因為如果你以讀庫的更新完成為操作處理完成的話,那一次業(yè)務場景所用的時間很可能比傳統(tǒng)架構要多。但是,如果我們以C端的處理為結束的話,則CQRS架構可能要快,因為C端可能只需要一次數(shù)據(jù)庫IO。我覺得這里有一點很重要,對于CQRS架構,我們更加關注C端處理完成所用的時間;而Q端的處理稍微慢一點沒關系,因為Q端只是供我們查看數(shù)據(jù)用的(最終一致性)。我們選擇CQRS架構,就必須要接受Q端數(shù)據(jù)更新有一點點延遲的缺點,否則就不應該使用這種架構。所以,希望大家在根據(jù)你的業(yè)務場景做架構選型時一定要充分認識到這一點。
另外,上面再談到數(shù)據(jù)一致性時提到,傳統(tǒng)架構會使用事務來保證數(shù)據(jù)的強一致性;如果事務越復雜,那一次事務鎖的表就越多,鎖是系統(tǒng)伸縮性的大敵;而CQRS架構,一個命令只會修改一個聚合根,如果要修改多個聚合根,則通過Saga來實現(xiàn)。從而繞過了復雜事務的問題,通過最終一致性的思路做到了最大的并行和最少的并發(fā),從而整體上提高系統(tǒng)的吞吐能力。
所以,總體來說,性能瓶頸方面,兩種架構都能克服。而只要克服了性能瓶頸,那伸縮性就不是問題了(當然,這里我沒有考慮數(shù)據(jù)丟失而帶來的系統(tǒng)不可用的問題。這個問題是所有架構都無法回避的問題,唯一的解決辦法就是數(shù)據(jù)冗余,這里不做展開了)。兩者的瓶頸都在數(shù)據(jù)的持久化上,但是傳統(tǒng)的架構因為大部分系統(tǒng)都是要存儲數(shù)據(jù)到關系型數(shù)據(jù)庫,所以只能自己采用分庫分表的方案。而CQRS架構,如果我們只關注C端的瓶頸,由于C端要保存的東西很簡單,就是命令和事件;如果你信的過一些成熟的NoSQL(我覺得使用文檔性數(shù)據(jù)庫如MongoDB這種比較適合存儲命令和事件),且你也有足夠的能力和經(jīng)驗去運維它們,那可以考慮使用NoSQL來持久化。如果你覺得NoSQL靠不住或者沒辦法完全掌控,那可以使用關系型數(shù)據(jù)庫。但這樣你也要付出努力,比如需要自己負責分庫分表來保存命令和事件,因為命令和事件的數(shù)據(jù)量都是很大的。不過目前一些云服務如阿里云,已經(jīng)提供了DRDS這種直接支持分庫分表的數(shù)據(jù)庫存儲方案,極大的簡化了我們存儲命令和事件的成本。就我個人而言,我覺得我還是會采用分庫分表的方案,原因很簡單:確保數(shù)據(jù)可靠落地、成熟、可控,而且支持這種只讀數(shù)據(jù)的落地,框架內置要支持分庫分表也不是什么難事。所以,通過這個對比我們知道傳統(tǒng)架構,我們必須使用分庫分表(除非阿里這種高大上可以使用OceanBase);而CQRS架構,可以帶給我們更多選擇空間。因為持久化命令和事件是很簡單的,它們都是不可修改的只讀數(shù)據(jù),且對kv存儲友好,也可以選擇文檔型NoSQL,C端永遠是新增數(shù)據(jù),而沒有修改或刪除數(shù)據(jù)。最后,就是關于Q端的瓶頸,如果你Q端也是使用關系型數(shù)據(jù)庫,那和傳統(tǒng)架構一樣,該怎么優(yōu)化就怎么優(yōu)化。而CQRS架構允許你使用其他的架構來實現(xiàn)Q,所以優(yōu)化手段相對更多。
結束語
我覺得不論是傳統(tǒng)架構還是CQRS架構,都是不錯的架構。傳統(tǒng)架構門檻低,懂的人也多,且因為大部分項目都沒有什么大的并發(fā)寫入量和數(shù)據(jù)量。所以應該說大部分項目,采用傳統(tǒng)架構就OK了。但是通過本文的分析,大家也知道了,傳統(tǒng)架構確實也有一些缺點,比如在擴展性、可用性、性能瓶頸的解決方案上,都比CQRS架構要弱一點。大家有其他意見,歡迎拍磚,交流才能進步,呵呵。所以,如果你的應用場景是高并發(fā)寫、高并發(fā)讀、大數(shù)據(jù),且希望在擴展性、可用性、性能、可伸縮性上表現(xiàn)更優(yōu)秀,我覺得可以嘗試CQRS架構。但是還有一個問題,CQRS架構的門檻很高,我認為如果沒有成熟的框架支持,很難使用。而目前據(jù)我了解,業(yè)界還沒有很多成熟的CQRS框架,java平臺有axon framework, jdon framework;.NET平臺,ENode框架正在朝這個方向努力。所以,我想這也是為什么目前幾乎沒有使用CQRS架構的成熟案例的原因之一。另一個原因是使用CQRS架構,需要開發(fā)者對DDD有一定的了解,否則也很難實踐,而DDD本身要理解沒個幾年也很難運用到實際。還有一個原因,CQRS架構的核心是非常依賴于高性能的分布式消息中間件,所以要選型一個高性能的分布式消息中間件也是一個門檻(java平臺有RocketMQ),.NET平臺我個人專門開發(fā)了一個分布式消息隊列EQueue,呵呵。另外,如果沒有成熟的CQRS框架的支持,那編碼復雜度也會很復雜,比如Event Sourcing,消息重試,消息冪等處理,事件的順序處理,并發(fā)控制,這些問題都不是那么容易搞定的。而如果有框架支持,由框架來幫我們搞定這些純技術問題,開發(fā)人員只需要關注如何建模,實現(xiàn)領域模型,如何更新讀庫,如何實現(xiàn)查詢,那使用CQRS架構才有可能,因為這樣才可能比傳統(tǒng)的架構開發(fā)更簡單,且能獲得很多CQRS架構所帶來的好處。
這是一個使用Spring Boot和Axon以及Docker構建的Event Sorucing源碼項目,技術特點:
1.使用Java 和Spring Boot實現(xiàn)微服務;
2.使用命令和查詢職責分離 (CQRS) 和 Event Sourcing (ES) 的框架Axon Framework v2, MongoDB 和 RabbitMQ;
3.使用Docker構建 交付和運行;
4.集中配置和使用Spring Cloud服務注冊;
5.使用Swagger 和 SpringFox 提供API文檔
項目源碼:
GitHub工作原理:
這個應用使用CQRS架構模式構建,在CQRS命令如ADD是和查詢VIEW(where id=1)分離的,在這個案例中領域部分代碼已經(jīng)分離成兩個組件:一個是屬于命令這邊的微服務和屬性查詢這邊的微服務。
微服務是單個職責的功能,自己的數(shù)據(jù)存儲,每個能彼此獨立擴展部署。
屬于命令這邊的微服務和屬性查詢這邊的微服務都是使用Spring Boot框架開發(fā)的,在命令微服務和查詢微服務之間通訊是事件驅動,事件是通過RabbitMQ消息在微服務組件之間傳遞,消息提供了一種進程節(jié)點或微服務之間可擴展的事件載體,包括與傳統(tǒng)遺留系統(tǒng)或其他系統(tǒng)的松耦合通訊都可以通過消息進行。
請注意,服務之間不能彼此共享數(shù)據(jù)庫,這是很重要,因為微服務應該是高度自治自主的,這樣反過來有助于服務能夠彼此獨立地擴展伸縮規(guī)模。
CQRS中命令是“改變狀態(tài)的動作”。命令的微服務包含所有領域邏輯和業(yè)務規(guī)則,命令被用于增加新的產(chǎn)品或改變它們的狀態(tài),這些命令針對某個具體產(chǎn)品的執(zhí)行會導致事件Event產(chǎn)生,這會通過Axon框架持久化到MongoDB中,然后通過RabbitMQ傳播給其他節(jié)點進程或微服務。
在event-sourcing中,事件是狀態(tài)改變的原始記錄,它們用于系統(tǒng)來重新建立實體的當前狀態(tài)(通過重新播放過去的事件到當前就可以構建當前的狀態(tài)),這聽上去會很慢,但是實際上,事件都很簡單,執(zhí)行非常快,也能采取‘快照’策略進行優(yōu)化。
請注意,在DDD中,實體是指一個聚合根實體。
上面是命令這邊的微服務,下面看看查詢這邊的微服務:
查詢微服務一般扮演一種事件監(jiān)聽器和視圖角色,它監(jiān)聽到命令那邊發(fā)出的事件,然后處理它們以符合查詢這邊的要求。
在這個案例中,查詢這邊只是簡單建立和維持了一個 ‘materialised view’或‘projection’ ,其中保留了產(chǎn)品的最新狀態(tài),也就是產(chǎn)品id和描述以及是否被賣出等等信息,查詢這邊能夠被復制多次以方便擴展,消息可以保留在RabbitMQ隊列中實現(xiàn)持久保存,這種臨時保存消息方式可以防止查詢這邊微服務當機。
命令微服務和查詢微服務兩者都有REST API,提供外界客戶端訪問。
下面看看如何通過Docker運行這個案例,需要 Ubuntu 16.04:
1.Docker ( v1.8.2)
2.Docker-compose ( v1.7.1)
在一個空目錄,執(zhí)行下面命令下載docker-compose:
$ wget https://raw.githubusercontent.com/benwilcock/microservice-sampler/master/docker-compose.yml
注意:不要更改文件名稱。
啟動微服務:只是簡單一個命令:
$ docker-compose up
你會看到許多下載信息和日志輸出在屏幕上,這是Docker image將被下載和運行。一共有六個docker,分別是: ‘mongodb’, ‘rabbitmq’, ‘config’, ‘discovery’, ‘product-cmd-side’, 和 ‘product-qry-side’.
使用下面命令進行測試增加一個新產(chǎn)品:
$ curl -X POST -v --header "Content-Type: application/json" --header "Accept: */*" "http://localhost:9000/products/add/1?name=Everything%20Is%20Awesome"
查詢這個新產(chǎn)品:
$ curl http://localhost:9001/products/1
Microservices With Spring Boot, Axon CQRS/ES, and Docker