o語言從誕生到普及已經(jīng)三年了,先行者大都是Web開發(fā)的背景,也有了一些普及型的書籍,可系統(tǒng)開發(fā)背景的人在學(xué)習(xí)這些書籍的時(shí)候,總有語焉不詳?shù)母杏X,網(wǎng)上也有若干流傳甚廣的文章,可其中或多或少總有些與事實(shí)不符的技術(shù)描述。希望這篇文章能為比較缺少系統(tǒng)編程背景的Web開發(fā)人員介紹一下goroutine背后的系統(tǒng)知識。
1. 操作系統(tǒng)與運(yùn)行庫
2. 并發(fā)與并行 (Concurrency and Parallelism)
3. 線程的調(diào)度
4. 并發(fā)編程框架
5. goroutine
1. 操作系統(tǒng)與運(yùn)行庫
對于普通的電腦用戶來說,能理解應(yīng)用程序是運(yùn)行在操作系統(tǒng)之上就足夠了,可對于開發(fā)者,我們還需要了解我們寫的程序是如何在操作系統(tǒng)之上運(yùn)行起來的,操作系統(tǒng)如何為應(yīng)用程序提供服務(wù),這樣我們才能分清楚哪些服務(wù)是操作系統(tǒng)提供的,而哪些服務(wù)是由我們所使用的語言的運(yùn)行庫提供的。
除了內(nèi)存管理、文件管理、進(jìn)程管理、外設(shè)管理等等內(nèi)部模塊以外,操作系統(tǒng)還提供了許多外部接口供應(yīng)用程序使用,這些接口就是所謂的“系統(tǒng)調(diào)用”。從DOS時(shí)代開始,系統(tǒng)調(diào)用就是通過軟中斷的形式來提供,也就是著名的INT 21,程序把需要調(diào)用的功能編號放入AH寄存器,把參數(shù)放入其他指定的寄存器,然后調(diào)用INT 21,中斷返回后,程序從指定的寄存器(通常是AL)里取得返回值。這樣的做法一直到奔騰2也就是P6出來之前都沒有變,譬如windows通過INT 2E提供系統(tǒng)調(diào)用,Linux則是INT 80,只不過后來的寄存器比以前大一些,而且可能再多一層跳轉(zhuǎn)表查詢。后來,Intel和AMD分別提供了效率更高的SYSENTER/SYSEXIT和SYSCALL/SYSRET指令來代替之前的中斷方式,略過了耗時(shí)的特權(quán)級別檢查以及寄存器壓棧出棧的操作,直接完成從RING 3代碼段到RING 0代碼段的轉(zhuǎn)換。
系統(tǒng)調(diào)用都提供什么功能呢?用操作系統(tǒng)的名字加上對應(yīng)的中斷編號到谷歌上一查就可以得到完整的列表 (Windows, Linux),這個列表就是操作系統(tǒng)和應(yīng)用程序之間溝通的協(xié)議,如果需要超出此協(xié)議的功能,我們就只能在自己的代碼里去實(shí)現(xiàn),譬如,對于內(nèi)存管理,操作系統(tǒng)只提供進(jìn)程級別的內(nèi)存段的管理,譬如Windows的virtualmemory系列,或是Linux的brk,操作系統(tǒng)不會去在乎應(yīng)用程序如何為新建對象分配內(nèi)存,或是如何做垃圾回收,這些都需要應(yīng)用程序自己去實(shí)現(xiàn)。如果超出此協(xié)議的功能無法自己實(shí)現(xiàn),那我們就說該操作系統(tǒng)不支持該功能,舉個例子,Linux在2.6之前是不支持多線程的,無論如何在程序里模擬,我們都無法做出多個可以同時(shí)運(yùn)行的并符合POSIX 1003.1c語義標(biāo)準(zhǔn)的調(diào)度單元。
可是,我們寫程序并不需要去調(diào)用中斷或是SYSCALL指令,這是因?yàn)椴僮飨到y(tǒng)提供了一層封裝,在Windows上,它是NTDLL.DLL,也就是常說的Native API,我們不但不需要去直接調(diào)用INT 2E或SYSCALL,準(zhǔn)確的說,我們不能直接去調(diào)用INT 2E或SYSCALL,因?yàn)閃indows并沒有公開其調(diào)用規(guī)范,直接使用INT 2E或SYSCALL無法保證未來的兼容性。在Linux上則沒有這個問題,系統(tǒng)調(diào)用的列表都是公開的,而且Linus非常看重兼容性,不會去做任何更改,glibc里甚至專門提供了syscall(2)來方便用戶直接用編號調(diào)用,不過,為了解決glibc和內(nèi)核之間不同版本兼容性帶來的麻煩,以及為了提高某些調(diào)用的效率(譬如__NR_ gettimeofday),Linux上還是對部分系統(tǒng)調(diào)用做了一層封裝,就是VDSO (早期叫linux-gate.so)。
可是,我們寫程序也很少直接調(diào)用NTDLL或者VDSO,而是通過更上一層的封裝,這一層處理了參數(shù)準(zhǔn)備和返回值格式轉(zhuǎn)換、以及出錯處理和錯誤代碼轉(zhuǎn)換,這就是我們所使用語言的運(yùn)行庫,對于C語言,Linux上是glibc,Windows上是kernel32(或調(diào)用msvcrt),對于其他語言,譬如Java,則是JRE,這些“其他語言”的運(yùn)行庫通常最終還是調(diào)用glibc或kernel32。
“運(yùn)行庫”這個詞其實(shí)不止包括用于和編譯后的目標(biāo)執(zhí)行程序進(jìn)行鏈接的庫文件,也包括了腳本語言或字節(jié)碼解釋型語言的運(yùn)行環(huán)境,譬如Python,C#的CLR,Java的JRE。
對系統(tǒng)調(diào)用的封裝只是運(yùn)行庫的很小一部分功能,運(yùn)行庫通常還提供了諸如字符串處理、數(shù)學(xué)計(jì)算、常用數(shù)據(jù)結(jié)構(gòu)容器等等不需要操作系統(tǒng)支持的功能,同時(shí),運(yùn)行庫也會對操作系統(tǒng)支持的功能提供更易用更高級的封裝,譬如帶緩存和格式的IO、線程池。
所以,在我們說“某某語言新增了某某功能”的時(shí)候,通常是這么幾種可能:
1. 支持新的語義或語法,從而便于我們描述和解決問題。譬如Java的泛型、Annotation、lambda表達(dá)式。
2. 提供了新的工具或類庫,減少了我們開發(fā)的代碼量。譬如Python 2.7的argparse
3. 對系統(tǒng)調(diào)用有了更良好更全面的封裝,使我們可以做到以前在這個語言環(huán)境里做不到或很難做到的事情。譬如Java NIO
但任何一門語言,包括其運(yùn)行庫和運(yùn)行環(huán)境,都不可能創(chuàng)造出操作系統(tǒng)不支持的功能,Go語言也是這樣,不管它的特性描述看起來多么炫麗,那必然都是其他語言也可以做到的,只不過Go提供了更方便更清晰的語義和支持,提高了開發(fā)的效率。
2. 并發(fā)與并行 (Concurrency and Parallelism)
并發(fā)是指程序的邏輯結(jié)構(gòu)。非并發(fā)的程序就是一根竹竿捅到底,只有一個邏輯控制流,也就是順序執(zhí)行的(Sequential)程序,在任何時(shí)刻,程序只會處在這個邏輯控制流的某個位置。而如果某個程序有多個獨(dú)立的邏輯控制流,也就是可以同時(shí)處理(deal)多件事情,我們就說這個程序是并發(fā)的。這里的“同時(shí)”,并不一定要是真正在時(shí)鐘的某一時(shí)刻(那是運(yùn)行狀態(tài)而不是邏輯結(jié)構(gòu)),而是指:如果把這些邏輯控制流畫成時(shí)序流程圖,它們在時(shí)間線上是可以重疊的。
并行是指程序的運(yùn)行狀態(tài)。如果一個程序在某一時(shí)刻被多個CPU流水線同時(shí)進(jìn)行處理,那么我們就說這個程序是以并行的形式在運(yùn)行。(嚴(yán)格意義上講,我們不能說某程序是“并行”的,因?yàn)?#8220;并行”不是描述程序本身,而是描述程序的運(yùn)行狀態(tài),但這篇小文里就不那么咬文嚼字,以下說到“并行”的時(shí)候,就是指代“以并行的形式運(yùn)行”)顯然,并行一定是需要硬件支持的。
而且不難理解:
1. 并發(fā)是并行的必要條件,如果一個程序本身就不是并發(fā)的,也就是只有一個邏輯控制流,那么我們不可能讓其被并行處理。
2. 并發(fā)不是并行的充分條件,一個并發(fā)的程序,如果只被一個CPU流水線進(jìn)行處理(通過分時(shí)),那么它就不是并行的。
3. 并發(fā)只是更符合現(xiàn)實(shí)問題本質(zhì)的表達(dá)方式,并發(fā)的最初目的是簡化代碼邏輯,而不是使程序運(yùn)行的更快;
這幾段略微抽象,我們可以用一個最簡單的例子來把這些概念實(shí)例化:用C語言寫一個最簡單的HelloWorld,它就是非并發(fā)的,如果我們建立多個線程,每個線程里打印一個HelloWorld,那么這個程序就是并發(fā)的,如果這個程序運(yùn)行在老式的單核CPU上,那么這個并發(fā)程序還不是并行的,如果我們用多核多CPU且支持多任務(wù)的操作系統(tǒng)來運(yùn)行它,那么這個并發(fā)程序就是并行的。
還有一個略微復(fù)雜的例子,更能說明并發(fā)不一定可以并行,而且并發(fā)不是為了效率,就是Go語言例子里計(jì)算素?cái)?shù)的sieve.go。我們從小到大針對每一個因子啟動一個代碼片段,如果當(dāng)前驗(yàn)證的數(shù)能被當(dāng)前因子除盡,則該數(shù)不是素?cái)?shù),如果不能,則把該數(shù)發(fā)送給下一個因子的代碼片段,直到最后一個因子也無法除盡,則該數(shù)為素?cái)?shù),我們再啟動一個它的代碼片段,用于驗(yàn)證更大的數(shù)字。這是符合我們計(jì)算素?cái)?shù)的邏輯的,而且每個因子的代碼處理片段都是相同的,所以程序非常的簡潔,但它無法被并行,因?yàn)槊總€片段都依賴于前一個片段的處理結(jié)果和輸出。
并發(fā)可以通過以下方式做到:
1. 顯式地定義并觸發(fā)多個代碼片段,也就是邏輯控制流,由應(yīng)用程序或操作系統(tǒng)對它們進(jìn)行調(diào)度。它們可以是獨(dú)立無關(guān)的,也可以是相互依賴需要交互的,譬如上面提到的素?cái)?shù)計(jì)算,其實(shí)它也是個經(jīng)典的生產(chǎn)者和消費(fèi)者的問題:兩個邏輯控制流A和B,A產(chǎn)生輸出,當(dāng)有了輸出后,B取得A的輸出進(jìn)行處理。線程只是實(shí)現(xiàn)并發(fā)的其中一個手段,除此之外,運(yùn)行庫或是應(yīng)用程序本身也有多種手段來實(shí)現(xiàn)并發(fā),這是下節(jié)的主要內(nèi)容。
2. 隱式地放置多個代碼片段,在系統(tǒng)事件發(fā)生時(shí)觸發(fā)執(zhí)行相應(yīng)的代碼片段,也就是事件驅(qū)動的方式,譬如某個端口或管道接收到了數(shù)據(jù)(多路IO的情況下),再譬如進(jìn)程接收到了某個信號(signal)。
并行可以在四個層面上做到:
1. 多臺機(jī)器。自然我們就有了多個CPU流水線,譬如Hadoop集群里的MapReduce任務(wù)。
2. 多CPU。不管是真的多顆CPU還是多核還是超線程,總之我們有了多個CPU流水線。
3. 單CPU核里的ILP(Instruction-level parallelism),指令級并行。通過復(fù)雜的制造工藝和對指令的解析以及分支預(yù)測和亂序執(zhí)行,現(xiàn)在的CPU可以在單個時(shí)鐘周期內(nèi)執(zhí)行多條指令,從而,即使是非并發(fā)的程序,也可能是以并行的形式執(zhí)行。
4. 單指令多數(shù)據(jù)(Single instruction, multiple data. SIMD),為了多媒體數(shù)據(jù)的處理,現(xiàn)在的CPU的指令集支持單條指令對多條數(shù)據(jù)進(jìn)行操作。
其中,1牽涉到分布式處理,包括數(shù)據(jù)的分布和任務(wù)的同步等等,而且是基于網(wǎng)絡(luò)的。3和4通常是編譯器和CPU的開發(fā)人員需要考慮的。這里我們說的并行主要針對第2種:單臺機(jī)器內(nèi)的多核CPU并行。
關(guān)于并發(fā)與并行的問題,Go語言的作者Rob Pike專門就此寫過一個幻燈片:http://talks.golang.org/2012/waza.slide
在CMU那本著名的《Computer Systems: A Programmer’s Perspective》里的這張圖也非常直觀清晰:
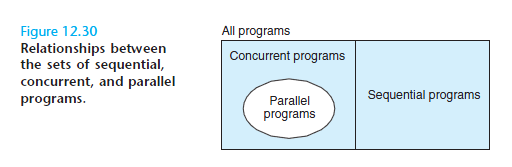
3. 線程的調(diào)度
上一節(jié)主要說的是并發(fā)和并行的概念,而線程是最直觀的并發(fā)的實(shí)現(xiàn),這一節(jié)我們主要說操作系統(tǒng)如何讓多個線程并發(fā)的執(zhí)行,當(dāng)然在多CPU的時(shí)候,也就是并行的執(zhí)行。我們不討論進(jìn)程,進(jìn)程的意義是“隔離的執(zhí)行環(huán)境”,而不是“單獨(dú)的執(zhí)行序列”。
我們首先需要理解IA-32 CPU的指令控制方式,這樣才能理解如何在多個指令序列(也就是邏輯控制流)之間進(jìn)行切換。CPU通過CS:EIP寄存器的值確定下一條指令的位置,但是CPU并不允許直接使用MOV指令來更改EIP的值,必須通過JMP系列指令、CALL/RET指令、或INT中斷指令來實(shí)現(xiàn)代碼的跳轉(zhuǎn);在指令序列間切換的時(shí)候,除了更改EIP之外,我們還要保證代碼可能會使用到的各個寄存器的值,尤其是棧指針SS:ESP,以及EFLAGS標(biāo)志位等,都能夠恢復(fù)到目標(biāo)指令序列上次執(zhí)行到這個位置時(shí)候的狀態(tài)。
線程是操作系統(tǒng)對外提供的服務(wù),應(yīng)用程序可以通過系統(tǒng)調(diào)用讓操作系統(tǒng)啟動線程,并負(fù)責(zé)隨后的線程調(diào)度和切換。我們先考慮單顆單核CPU,操作系統(tǒng)內(nèi)核與應(yīng)用程序其實(shí)是也是在共享同一個CPU,當(dāng)EIP在應(yīng)用程序代碼段的時(shí)候,內(nèi)核并沒有控制權(quán),內(nèi)核并不是一個進(jìn)程或線程,內(nèi)核只是以實(shí)模式運(yùn)行的,代碼段權(quán)限為RING 0的內(nèi)存中的程序,只有當(dāng)產(chǎn)生中斷或是應(yīng)用程序呼叫系統(tǒng)調(diào)用的時(shí)候,控制權(quán)才轉(zhuǎn)移到內(nèi)核,在內(nèi)核里,所有代碼都在同一個地址空間,為了給不同的線程提供服務(wù),內(nèi)核會為每一個線程建立一個內(nèi)核堆棧,這是線程切換的關(guān)鍵。通常,內(nèi)核會在時(shí)鐘中斷里或系統(tǒng)調(diào)用返回前(考慮到性能,通常是在不頻繁發(fā)生的系統(tǒng)調(diào)用返回前),對整個系統(tǒng)的線程進(jìn)行調(diào)度,計(jì)算當(dāng)前線程的剩余時(shí)間片,如果需要切換,就在“可運(yùn)行”的線程隊(duì)列里計(jì)算優(yōu)先級,選出目標(biāo)線程后,則保存當(dāng)前線程的運(yùn)行環(huán)境,并恢復(fù)目標(biāo)線程的運(yùn)行環(huán)境,其中最重要的,就是切換堆棧指針ESP,然后再把EIP指向目標(biāo)線程上次被移出CPU時(shí)的指令。Linux內(nèi)核在實(shí)現(xiàn)線程切換時(shí),耍了個花槍,它并不是直接JMP,而是先把ESP切換為目標(biāo)線程的內(nèi)核棧,把目標(biāo)線程的代碼地址壓棧,然后JMP到__switch_to(),相當(dāng)于偽造了一個CALL __switch_to()指令,然后,在__switch_to()的最后使用RET指令返回,這樣就把棧里的目標(biāo)線程的代碼地址放入了EIP,接下來CPU就開始執(zhí)行目標(biāo)線程的代碼了,其實(shí)也就是上次停在switch_to這個宏展開的地方。
這里需要補(bǔ)充幾點(diǎn):(1) 雖然IA-32提供了TSS (Task State Segment),試圖簡化操作系統(tǒng)進(jìn)行線程調(diào)度的流程,但由于其效率低下,而且并不是通用標(biāo)準(zhǔn),不利于移植,所以主流操作系統(tǒng)都沒有去利用TSS。更嚴(yán)格的說,其實(shí)還是用了TSS,因?yàn)橹挥型ㄟ^TSS才能把堆棧切換到內(nèi)核堆棧指針SS0:ESP0,但除此之外的TSS的功能就完全沒有被使用了。(2) 線程從用戶態(tài)進(jìn)入內(nèi)核的時(shí)候,相關(guān)的寄存器以及用戶態(tài)代碼段的EIP已經(jīng)保存了一次,所以,在上面所說的內(nèi)核態(tài)線程切換時(shí),需要保存和恢復(fù)的內(nèi)容并不多。(3) 以上描述的都是搶占式(preemptively)的調(diào)度方式,內(nèi)核以及其中的硬件驅(qū)動也會在等待外部資源可用的時(shí)候主動調(diào)用schedule(),用戶態(tài)的代碼也可以通過sched_yield()系統(tǒng)調(diào)用主動發(fā)起調(diào)度,讓出CPU。
現(xiàn)在我們一臺普通的PC或服務(wù)里通常都有多顆CPU (physical package),每顆CPU又有多個核 (processor core),每個核又可以支持超線程 (two logical processors for each core),也就是邏輯處理器。每個邏輯處理器都有自己的一套完整的寄存器,其中包括了CS:EIP和SS:ESP,從而,以操作系統(tǒng)和應(yīng)用的角度來看,每個邏輯處理器都是一個單獨(dú)的流水線。在多處理器的情況下,線程切換的原理和流程其實(shí)和單處理器時(shí)是基本一致的,內(nèi)核代碼只有一份,當(dāng)某個CPU上發(fā)生時(shí)鐘中斷或是系統(tǒng)調(diào)用時(shí),該CPU的CS:EIP和控制權(quán)又回到了內(nèi)核,內(nèi)核根據(jù)調(diào)度策略的結(jié)果進(jìn)行線程切換。但在這個時(shí)候,如果我們的程序用線程實(shí)現(xiàn)了并發(fā),那么操作系統(tǒng)可以使我們的程序在多個CPU上實(shí)現(xiàn)并行。
這里也需要補(bǔ)充兩點(diǎn):(1) 多核的場景里,各個核之間并不是完全對等的,譬如在同一個核上的兩個超線程是共享L1/L2緩存的;在有NUMA支持的場景里,每個核訪問內(nèi)存不同區(qū)域的延遲是不一樣的;所以,多核場景里的線程調(diào)度又引入了“調(diào)度域”(scheduling domains)的概念,但這不影響我們理解線程切換機(jī)制。(2) 多核的場景下,中斷發(fā)給哪個CPU?軟中斷(包括除以0,缺頁異常,INT指令)自然是在觸發(fā)該中斷的CPU上產(chǎn)生,而硬中斷則又分兩種情況,一種是每個CPU自己產(chǎn)生的中斷,譬如時(shí)鐘,這是每個CPU處理自己的,還有一種是外部中斷,譬如IO,可以通過APIC來指定其送給哪個CPU;因?yàn)檎{(diào)度程序只能控制當(dāng)前的CPU,所以,如果IO中斷沒有進(jìn)行均勻的分配的話,那么和IO相關(guān)的線程就只能在某些CPU上運(yùn)行,導(dǎo)致CPU負(fù)載不均,進(jìn)而影響整個系統(tǒng)的效率。
4. 并發(fā)編程框架
以上大概介紹了一個用多線程來實(shí)現(xiàn)并發(fā)的程序是如何被操作系統(tǒng)調(diào)度以及并行執(zhí)行(在有多個邏輯處理器時(shí)),同時(shí)大家也可以看到,代碼片段或者說邏輯控制流的調(diào)度和切換其實(shí)并不神秘,理論上,我們也可以不依賴操作系統(tǒng)和其提供的線程,在自己程序的代碼段里定義多個片段,然后在我們自己程序里對其進(jìn)行調(diào)度和切換。
為了描述方便,我們接下來把“代碼片段”稱為“任務(wù)”。
和內(nèi)核的實(shí)現(xiàn)類似,只是我們不需要考慮中斷和系統(tǒng)調(diào)用,那么,我們的程序本質(zhì)上就是一個循環(huán),這個循環(huán)本身就是調(diào)度程序schedule(),我們需要維護(hù)一個任務(wù)的列表,根據(jù)我們定義的策略,先進(jìn)先出或是有優(yōu)先級等等,每次從列表里挑選出一個任務(wù),然后恢復(fù)各個寄存器的值,并且JMP到該任務(wù)上次被暫停的地方,所有這些需要保存的信息都可以作為該任務(wù)的屬性,存放在任務(wù)列表里。
看起來很簡單啊,可是我們還需要解決幾個問題:
(1) 我們運(yùn)行在用戶態(tài),是沒有中斷或系統(tǒng)調(diào)用這樣的機(jī)制來打斷代碼執(zhí)行的,那么,一旦我們的schedule()代碼把控制權(quán)交給了任務(wù)的代碼,我們下次的調(diào)度在什么時(shí)候發(fā)生?答案是,不會發(fā)生,只有靠任務(wù)主動調(diào)用schedule(),我們才有機(jī)會進(jìn)行調(diào)度,所以,這里的任務(wù)不能像線程一樣依賴內(nèi)核調(diào)度從而毫無顧忌的執(zhí)行,我們的任務(wù)里一定要顯式的調(diào)用schedule(),這就是所謂的協(xié)作式(cooperative)調(diào)度。(雖然我們可以通過注冊信號處理函數(shù)來模擬內(nèi)核里的時(shí)鐘中斷并取得控制權(quán),可問題在于,信號處理函數(shù)是由內(nèi)核調(diào)用的,在其結(jié)束的時(shí)候,內(nèi)核重新獲得控制權(quán),隨后返回用戶態(tài)并繼續(xù)沿著信號發(fā)生時(shí)被中斷的代碼路徑執(zhí)行,從而我們無法在信號處理函數(shù)內(nèi)進(jìn)行任務(wù)切換)
(2) 堆棧。和內(nèi)核調(diào)度線程的原理一樣,我們也需要為每個任務(wù)單獨(dú)分配堆棧,并且把其堆棧信息保存在任務(wù)屬性里,在任務(wù)切換時(shí)也保存或恢復(fù)當(dāng)前的SS:ESP。任務(wù)堆棧的空間可以是在當(dāng)前線程的堆棧上分配,也可以是在堆上分配,但通常是在堆上分配比較好:幾乎沒有大小或任務(wù)總數(shù)的限制、堆棧大小可以動態(tài)擴(kuò)展(gcc有split stack,但太復(fù)雜了)、便于把任務(wù)切換到其他線程。
到這里,我們大概知道了如何構(gòu)造一個并發(fā)的編程框架,可如何讓任務(wù)可以并行的在多個邏輯處理器上執(zhí)行呢?只有內(nèi)核才有調(diào)度CPU的權(quán)限,所以,我們還是必須通過系統(tǒng)調(diào)用創(chuàng)建線程,才可以實(shí)現(xiàn)并行。在多線程處理多任務(wù)的時(shí)候,我們還需要考慮幾個問題:
(1) 如果某個任務(wù)發(fā)起了一個系統(tǒng)調(diào)用,譬如長時(shí)間等待IO,那當(dāng)前線程就被內(nèi)核放入了等待調(diào)度的隊(duì)列,豈不是讓其他任務(wù)都沒有機(jī)會執(zhí)行?
在單線程的情況下,我們只有一個解決辦法,就是使用非阻塞的IO系統(tǒng)調(diào)用,并讓出CPU,然后在schedule()里統(tǒng)一進(jìn)行輪詢,有數(shù)據(jù)時(shí)切換回該fd對應(yīng)的任務(wù);效率略低的做法是不進(jìn)行統(tǒng)一輪詢,讓各個任務(wù)在輪到自己執(zhí)行時(shí)再次用非阻塞方式進(jìn)行IO,直到有數(shù)據(jù)可用。
如果我們采用多線程來構(gòu)造我們整個的程序,那么我們可以封裝系統(tǒng)調(diào)用的接口,當(dāng)某個任務(wù)進(jìn)入系統(tǒng)調(diào)用時(shí),我們就把當(dāng)前線程留給它(暫時(shí))獨(dú)享,并開啟新的線程來處理其他任務(wù)。
(2) 任務(wù)同步。譬如我們上節(jié)提到的生產(chǎn)者和消費(fèi)者的例子,如何讓消費(fèi)者在數(shù)據(jù)還沒有被生產(chǎn)出來的時(shí)候進(jìn)入等待,并且在數(shù)據(jù)可用時(shí)觸發(fā)消費(fèi)者繼續(xù)執(zhí)行呢?
在單線程的情況下,我們可以定義一個結(jié)構(gòu),其中有變量用于存放交互數(shù)據(jù)本身,以及數(shù)據(jù)的當(dāng)前可用狀態(tài),以及負(fù)責(zé)讀寫此數(shù)據(jù)的兩個任務(wù)的編號。然后我們的并發(fā)編程框架再提供read和write方法供任務(wù)調(diào)用,在read方法里,我們循環(huán)檢查數(shù)據(jù)是否可用,如果數(shù)據(jù)還不可用,我們就調(diào)用schedule()讓出CPU進(jìn)入等待;在write方法里,我們往結(jié)構(gòu)里寫入數(shù)據(jù),更改數(shù)據(jù)可用狀態(tài),然后返回;在schedule()里,我們檢查數(shù)據(jù)可用狀態(tài),如果可用,則激活需要讀取此數(shù)據(jù)的任務(wù),該任務(wù)繼續(xù)循環(huán)檢測數(shù)據(jù)是否可用,發(fā)現(xiàn)可用,讀取,更改狀態(tài)為不可用,返回。代碼的簡單邏輯如下:
struct chan { bool ready, int data }; int read (struct chan *c) { while (1) { if (c->ready) { c->ready = false; return c->data; } else { schedule(); } } } void write (struct chan *c, int i) { while (1) { if (c->ready) { schedule(); } else { c->data = i; c->ready = true; schedule(); // optional return; } } }很顯然,如果是多線程的話,我們需要通過線程庫或系統(tǒng)調(diào)用提供的同步機(jī)制來保護(hù)對這個結(jié)構(gòu)體內(nèi)數(shù)據(jù)的訪問。
以上就是最簡化的一個并發(fā)框架的設(shè)計(jì)考慮,在我們實(shí)際開發(fā)工作中遇到的并發(fā)框架可能由于語言和運(yùn)行庫的不同而有所不同,在功能和易用性上也可能各有取舍,但底層的原理都是殊途同歸。
譬如,glic里的getcontext/setcontext/swapcontext系列庫函數(shù)可以方便的用來保存和恢復(fù)任務(wù)執(zhí)行狀態(tài);Windows提供了Fiber系列的SDK API;這二者都不是系統(tǒng)調(diào)用,getcontext和setcontext的man page雖然是在section 2,但那只是SVR4時(shí)的歷史遺留問題,其實(shí)現(xiàn)代碼是在glibc而不是kernel;CreateFiber是在kernel32里提供的,NTDLL里并沒有對應(yīng)的NtCreateFiber。
在其他語言里,我們所謂的“任務(wù)”更多時(shí)候被稱為“協(xié)程”,也就是Coroutine。譬如C++里最常用的是Boost.Coroutine;Java因?yàn)橛幸粚幼止?jié)碼解釋,比較麻煩,但也有支持協(xié)程的JVM補(bǔ)丁,或是動態(tài)修改字節(jié)碼以支持協(xié)程的項(xiàng)目;PHP和Python的generator和yield其實(shí)已經(jīng)是協(xié)程的支持,在此之上可以封裝出更通用的協(xié)程接口和調(diào)度;另外還有原生支持協(xié)程的Erlang等,筆者不懂,就不說了,具體可參見Wikipedia的頁面:http://en.wikipedia.org/wiki/Coroutine
由于保存和恢復(fù)任務(wù)執(zhí)行狀態(tài)需要訪問CPU寄存器,所以相關(guān)的運(yùn)行庫也都會列出所支持的CPU列表。
從操作系統(tǒng)層面提供協(xié)程以及其并行調(diào)度的,好像只有OS X和iOS的Grand Central Dispatch,其大部分功能也是在運(yùn)行庫里實(shí)現(xiàn)的。
5. goroutine
Go語言通過goroutine提供了目前為止所有(我所了解的)語言里對于并發(fā)編程的最清晰最直接的支持,Go語言的文檔里對其特性也描述的非常全面甚至超過了,在這里,基于我們上面的系統(tǒng)知識介紹,列舉一下goroutine的特性,算是小結(jié):
(1) goroutine是Go語言運(yùn)行庫的功能,不是操作系統(tǒng)提供的功能,goroutine不是用線程實(shí)現(xiàn)的。具體可參見Go語言源碼里的pkg/runtime/proc.c
(2) goroutine就是一段代碼,一個函數(shù)入口,以及在堆上為其分配的一個堆棧。所以它非常廉價(jià),我們可以很輕松的創(chuàng)建上萬個goroutine,但它們并不是被操作系統(tǒng)所調(diào)度執(zhí)行
(3) 除了被系統(tǒng)調(diào)用阻塞的線程外,Go運(yùn)行庫最多會啟動$GOMAXPROCS個線程來運(yùn)行g(shù)oroutine
(4) goroutine是協(xié)作式調(diào)度的,如果goroutine會執(zhí)行很長時(shí)間,而且不是通過等待讀取或?qū)懭隿hannel的數(shù)據(jù)來同步的話,就需要主動調(diào)用Gosched()來讓出CPU
(5) 和所有其他并發(fā)框架里的協(xié)程一樣,goroutine里所謂“無鎖”的優(yōu)點(diǎn)只在單線程下有效,如果$GOMAXPROCS > 1并且協(xié)程間需要通信,Go運(yùn)行庫會負(fù)責(zé)加鎖保護(hù)數(shù)據(jù),這也是為什么sieve.go這樣的例子在多CPU多線程時(shí)反而更慢的原因
(6) Web等服務(wù)端程序要處理的請求從本質(zhì)上來講是并行處理的問題,每個請求基本獨(dú)立,互不依賴,幾乎沒有數(shù)據(jù)交互,這不是一個并發(fā)編程的模型,而并發(fā)編程框架只是解決了其語義表述的復(fù)雜性,并不是從根本上提高處理的效率,也許是并發(fā)連接和并發(fā)編程的英文都是concurrent吧,很容易產(chǎn)生“并發(fā)編程框架和coroutine可以高效處理大量并發(fā)連接”的誤解。
(7) Go語言運(yùn)行庫封裝了異步IO,所以可以寫出貌似并發(fā)數(shù)很多的服務(wù)端,可即使我們通過調(diào)整$GOMAXPROCS來充分利用多核CPU并行處理,其效率也不如我們利用IO事件驅(qū)動設(shè)計(jì)的、按照事務(wù)類型劃分好合適比例的線程池。在響應(yīng)時(shí)間上,協(xié)作式調(diào)度是硬傷。
(8) goroutine最大的價(jià)值是其實(shí)現(xiàn)了并發(fā)協(xié)程和實(shí)際并行執(zhí)行的線程的映射以及動態(tài)擴(kuò)展,隨著其運(yùn)行庫的不斷發(fā)展和完善,其性能一定會越來越好,尤其是在CPU核數(shù)越來越多的未來,終有一天我們會為了代碼的簡潔和可維護(hù)性而放棄那一點(diǎn)點(diǎn)性能的差別。