2012年2月21日
版權信息: 可以任意轉載, 轉載時請務必以超鏈接形式標明文章原文出處, 即下面的聲明.
原文出處:http://blog.chenlb.com/2009/06/java-classloader-architecture.html
jvm classLoader architecture:
- Bootstrap ClassLoader/啟動類加載器
主要負責jdk_home/lib目錄下的核心 api 或 -Xbootclasspath 選項指定的jar包裝入工作。 - Extension ClassLoader/擴展類加載器
主要負責jdk_home/lib/ext目錄下的jar包或 -Djava.ext.dirs 指定目錄下的jar包裝入工作。 - System ClassLoader/系統(tǒng)類加載器
主要負責java -classpath/-Djava.class.path所指的目錄下的類與jar包裝入工作。 - User Custom ClassLoader/用戶自定義類加載器(java.lang.ClassLoader的子類)
在程序運行期間, 通過java.lang.ClassLoader的子類動態(tài)加載class文件, 體現(xiàn)java動態(tài)實時類裝入特性。
類加載器的特性:
- 每個ClassLoader都維護了一份自己的名稱空間, 同一個名稱空間里不能出現(xiàn)兩個同名的類。
- 為了實現(xiàn)java安全沙箱模型頂層的類加載器安全機制, java默認采用了 " 雙親委派的加載鏈 " 結構。

classloader-architecture

classloader-class-diagram
類圖中, BootstrapClassLoader是一個單獨的java類, 其實在這里, 不應該叫他是一個java類。因為,它已經完全不用java實現(xiàn)了。它是在jvm啟動時, 就被構造起來的, 負責java平臺核心庫。
自定義類加載器加載一個類的步驟

classloader-load-class
ClassLoader 類加載邏輯分析, 以下邏輯是除 BootstrapClassLoader 外的類加載器加載流程:
- // 檢查類是否已被裝載過
- Class c = findLoadedClass(name);
- if (c == null ) {
- // 指定類未被裝載過
- try {
- if (parent != null ) {
- // 如果父類加載器不為空, 則委派給父類加載
- c = parent.loadClass(name, false );
- } else {
- // 如果父類加載器為空, 則委派給啟動類加載加載
- c = findBootstrapClass0(name);
- }
- } catch (ClassNotFoundException e) {
- // 啟動類加載器或父類加載器拋出異常后, 當前類加載器將其
- // 捕獲, 并通過findClass方法, 由自身加載
- c = findClass(name);
- }
- }
線程上下文類加載器
java默認的線程上下文類加載器是 系統(tǒng)類加載器(AppClassLoader)。
- // Now create the class loader to use to launch the application
- try {
- loader = AppClassLoader.getAppClassLoader(extcl);
- } catch (IOException e) {
- throw new InternalError(
- "Could not create application class loader" );
- }
-
- // Also set the context class loader for the primordial thread.
- Thread.currentThread().setContextClassLoader(loader);
以上代碼摘自sun.misc.Launch的無參構造函數Launch()。
使用線程上下文類加載器, 可以在執(zhí)行線程中, 拋棄雙親委派加載鏈模式, 使用線程上下文里的類加載器加載類.
典型的例子有, 通過線程上下文來加載第三方庫jndi實現(xiàn), 而不依賴于雙親委派.
大部分java app服務器(jboss, tomcat..)也是采用contextClassLoader來處理web服務。
還有一些采用 hotswap 特性的框架, 也使用了線程上下文類加載器, 比如 seasar (full stack framework in japenese).
線程上下文從根本解決了一般應用不能違背雙親委派模式的問題.
使java類加載體系顯得更靈活.
隨著多核時代的來臨, 相信多線程開發(fā)將會越來越多地進入程序員的實際編碼過程中. 因此,
在編寫基礎設施時, 通過使用線程上下文來加載類, 應該是一個很好的選擇。
當然, 好東西都有利弊. 使用線程上下文加載類, 也要注意, 保證多根需要通信的線程間的類加載器應該是同一個,
防止因為不同的類加載器, 導致類型轉換異常(ClassCastException)。
為什么要使用這種雙親委托模式呢?
- 因為這樣可以避免重復加載,當父親已經加載了該類的時候,就沒有必要子ClassLoader再加載一次。
- 考慮到安全因素,我們試想一下,如果不使用這種委托模式,那我們就可以隨時使用自定義的String來動態(tài)替代java核心api中定義類型,這樣會存在非常大的安全隱患,而雙親委托的方式,就可以避免這種情況,因為String已經在啟動時被加載,所以用戶自定義類是無法加載一個自定義的ClassLoader。
java動態(tài)載入class的兩種方式:
- implicit隱式,即利用實例化才載入的特性來動態(tài)載入class
- explicit顯式方式,又分兩種方式:
- java.lang.Class的forName()方法
- java.lang.ClassLoader的loadClass()方法
用Class.forName加載類
Class.forName使用的是被調用者的類加載器來加載類的。
這種特性, 證明了java類加載器中的名稱空間是唯一的, 不會相互干擾。
即在一般情況下, 保證同一個類中所關聯(lián)的其他類都是由當前類的類加載器所加載的。
- public static Class forName(String className)
- throws ClassNotFoundException {
- return forName0(className, true , ClassLoader.getCallerClassLoader());
- }
-
- /** Called after security checks have been made. */
- private static native Class forName0(String name, boolean initialize,
- ClassLoader loader)
- throws ClassNotFoundException;
上面中 ClassLoader.getCallerClassLoader 就是得到調用當前forName方法的類的類加載器
static塊在什么時候執(zhí)行?
- 當調用forName(String)載入class時執(zhí)行,如果調用ClassLoader.loadClass并不會執(zhí)行.forName(String,false,ClassLoader)時也不會執(zhí)行.
- 如果載入Class時沒有執(zhí)行static塊則在第一次實例化時執(zhí)行.比如new ,Class.newInstance()操作
- static塊僅執(zhí)行一次
各個java類由哪些classLoader加載?
- java類可以通過實例.getClass.getClassLoader()得知
- 接口由AppClassLoader(System ClassLoader,可以由ClassLoader.getSystemClassLoader()獲得實例)載入
- ClassLoader類由bootstrap loader載入
NoClassDefFoundError和ClassNotFoundException
- NoClassDefFoundError:當java源文件已編譯成.class文件,但是ClassLoader在運行期間在其搜尋路徑load某個類時,沒有找到.class文件則報這個錯
- ClassNotFoundException:試圖通過一個String變量來創(chuàng)建一個Class類時不成功則拋出這個異常
一:使用場景
1)使用的地方:樹形結構,分支結構等
2)使用的好處:降低客戶端的使用,為了達到元件與組合件使用的一致性,增加了元件的編碼
3)使用后的壞處:代碼不容易理解,需要你認真去研究,發(fā)現(xiàn)元件與組合件是怎么組合的
二:一個實際的例子
畫圖形,這個模式,稍微要難理解一點,有了例子就說明了一切,我畫的圖是用接口做的,代碼實現(xiàn)是抽象類為基類,你自己選擇了,接口也可以。

1)先建立圖形元件
package com.mike.pattern.structure.composite;
/**
* 圖形元件
*
* @author taoyu
*
* @since 2010-6-23
*/
public abstract class Graph {
/**圖形名稱*/
protected String name;
public Graph(String name){
this.name=name;
}
/**畫圖*/
public abstract void draw()throws GraphException;
/**添加圖形*/
public abstract void add(Graph graph)throws GraphException;
/**移掉圖形*/
public abstract void remove(Graph graph)throws GraphException;
}
2)建立基礎圖形圓
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 圓圖形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Circle extends Graph {
public Circle(String name){
super(name);
}
/**
* 圓添加圖形
* @throws GraphException
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("圓是基礎圖形,不能添加");
}
/**
* 圓畫圖
*/
@Override
public void draw()throws GraphException {
print(name+"畫好了");
}
/**
* 圓移掉圖形
*/
@Override
public void remove(Graph graph)throws GraphException {
throw new GraphException("圓是基礎圖形,不能移掉");
}
}
3)建立基礎圖形長方形
package com.mike.pattern.structure.composite;
import static com.mike.util.Print.print;
/**
* 長方形
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Rectangle extends Graph {
public Rectangle(String name){
super(name);
}
/**
* 長方形添加
*/
@Override
public void add(Graph graph) throws GraphException {
throw new GraphException("長方形是基礎圖形,不能添加");
}
/**
* 畫長方形
*/
@Override
public void draw() throws GraphException {
print(name+"畫好了");
}
@Override
public void remove(Graph graph) throws GraphException {
throw new GraphException("長方形是基礎圖形,不能移掉");
}
}
4)最后簡歷組合圖形
package com.mike.pattern.structure.composite;
import java.util.ArrayList;
import java.util.List;
import static com.mike.util.Print.print;
/**
* 圖形組合體
*
* @author taoyu
*
* @since 2010-6-23
*/
public class Picture extends Graph {
private List<Graph> graphs;
public Picture(String name){
super(name);
/**默認是10個長度*/
graphs=new ArrayList<Graph>();
}
/**
* 添加圖形元件
*/
@Override
public void add(Graph graph) throws GraphException {
graphs.add(graph);
}
/**
* 圖形元件畫圖
*/
@Override
public void draw() throws GraphException {
print("圖形容器:"+name+" 開始創(chuàng)建");
for(Graph g : graphs){
g.draw();
}
}
/**
* 圖形元件移掉圖形元件
*/
@Override
public void remove(Graph graph) throws GraphException {
graphs.remove(graph);
}
}
5)最后測試
public static void main(String[] args)throws GraphException {
/**畫一個圓,圓里包含一個圓和長方形*/
Picture picture=new Picture("立方體圓");
picture.add(new Circle("圓"));
picture.add(new Rectangle("長方形"));
Picture root=new Picture("怪物圖形");
root.add(new Circle("圓"));
root.add(picture);
root.draw();
}
6)使用心得:的確降低了客戶端的使用情況,讓整個圖形可控了,當是你要深入去理解,才真名明白采用該模式的含義,不太容易理解。
一:使用場景
1)使用的地方:我想使用兩個不同類的方法,這個時候你需要把它們組合起來使用
2)目前使用的情況:我會把兩個類用戶組合的方式放到一起,編程思想think in java里已經提到個,能盡量用組合就用組合,繼承一般考慮再后。
3)使用后的好處:你不需要改動以前的代碼,只是新封裝了一新類,由這個類來提供兩個類的方法,這個時候:一定會想到facade外觀模式,本來是多個類使用的情況,我新封裝成一個類來使用,而這個類我采用組合的方式來包裝新的方法。我的理解是,設計模式本身就是為了幫助解決特定的業(yè)務場景而故意把模式劃分對應的模式類別,其實大多數情況,都解決了同樣的問題,這個時候其實沒有必要過多的糾纏到模式的名字上了,你有好的注意,你甚至取一個新的名字來概括這樣的使用場景。
4)使用的壞處:適配器模式,有兩種方式來實現(xiàn)。一個是組合一個是繼承,我覺得,首先應該考慮組合,能用組合就不要用繼承,這是第一個。第二個,你采用繼承來實現(xiàn),那肯定會加大繼承樹結構,如果你的繼承關系本身就很復雜了,這肯定會加大繼承關系的維護,不有利于代碼的理解,或則更加繁瑣。繼承是為了解決重用的為題而出現(xiàn)的,所以我覺得不應該濫用繼承,有機會可以考慮同樣別的方案。
二:一個實際的例子
關聯(lián)營銷的例子,用戶購買完商品后,我又推薦他相關別的商品
由于減少代碼,方法我都不采用接口,直接由類來提供,代碼只是一個范例而已,都精簡了。
1)創(chuàng)建訂單信息
public class Order {
private Long orderId;
private String nickName;
public Order(Long orderId,String nickName){
this.orderId=orderId;
this.nickName=nickName;
}
/**
* 用戶下訂單
*/
public void insertOrder(){
}
}
2)商品信息
public class Auction {
/**商品名稱*/
private String name;
/**制造商*/
private String company;
/**制造日期*/
private Date date;
public Auction(String name,String company, Date date){
this.name=name;
this.company=company;
this.date=date;
}
/**
* 推廣的商品列表
*/
public void commendAuction(){
}
}
3)購物
public class Trade {
/**用戶訂單*/
private Order order;
/**商品信息*/
private Auction auction;
public Trade(Order order ,Auction auction){
this.order=order;
this.auction=auction;
}
/**
* 用戶產生訂單以及后續(xù)的事情
*/
public void trade(){
/**下訂單*/
order.insertOrder();
/**關聯(lián)推薦相關的商品*/
auction.commendAuction();
}
}
4)使用心得:其實外面采用了很多繼承的方式,order繼承auction之后,利用super .inserOrder()再加一個auction.recommendAuction(),實際上大同小異,我到覺得采用組合更容易理解以及代碼更加優(yōu)美點。
一:使用場景
1)使用到的地方:如果你想創(chuàng)建類似汽車這樣的對象,首先要創(chuàng)建輪子,玻璃,桌椅,發(fā)動機,外廓等,這些部件都創(chuàng)建好后,最后創(chuàng)建汽車成品,部件的創(chuàng)建和汽車的組裝過程本身都很復雜的情況,希望把部件的創(chuàng)建和成品的組裝分開來做,這樣把要做的事情分割開來,降低對象實現(xiàn)的復雜度,也降低以后成本的維護,把汽車的部件創(chuàng)建和組裝過程獨立出兩個對應的工廠來做,有點類似建立兩個對應的部件創(chuàng)建工廠和汽車組裝工廠兩個工廠,而工廠只是創(chuàng)建一個成品,并沒有把里面的步驟也獨立出來,應該說Builder模式比工廠模式又進了一步。
2)采用Builder模式后的好處:把一個負責的對象的創(chuàng)建過程分解,把一個對象的創(chuàng)建分成兩個對象來負責創(chuàng)建,代碼更有利于維護,可擴性比較好。
3)采用Builder模式后的壞處:實現(xiàn)起來,對應的接口以及部件的對象的創(chuàng)建比較多,代碼相對來講,比較多了,估計剛開始你會有點暈,這個可以考慮代碼精簡的問題,增加代碼的可讀性。
二:一個實際的例子
汽車的組裝
1)首先創(chuàng)建汽車這個成品對象,包含什么的成員
public class Car implements Serializable{
/**
* 汽車序列號
*/
private static final long serialVersionUID = 1L;
/**汽車輪子*/
private Wheel wheel;
/**汽車發(fā)動機*/
private Engine engine;
/**汽車玻璃*/
private Glass glass;
/**汽車座椅*/
private Chair chair;
public Wheel getWheel() {
return wheel;
}
public void setWheel(Wheel wheel) {
this.wheel = wheel;
}
public Engine getEngine() {
return engine;
}
public void setEngine(Engine engine) {
this.engine = engine;
}
public Glass getGlass() {
return glass;
}
public void setGlass(Glass glass) {
this.glass = glass;
}
public Chair getChair() {
return chair;
}
public void setChair(Chair chair) {
this.chair = chair;
}
}
2)創(chuàng)建對應汽車零部件
public class Wheel {
public Wheel(){
print("--汽車輪子構建完畢--");
}
}
public class Engine {
public Engine(){
print("--汽車發(fā)動機構建完畢--");
}
}
public class Glass {
public Glass(){
print("--汽車玻璃構建完畢--");
}
}
public class Chair {
public Chair(){
print("--汽車座椅構建完畢--");
}
}
3)開始重點了,汽車成品的組裝過程
public interface Builder {
/**組裝汽車輪子*/
public void buildWheel();
/**組裝汽車發(fā)動機*/
public void buildEngine();
/**組裝汽車玻璃*/
public void buildGlass();
/**組裝汽車座椅*/
public void buildChair();
/**返回組裝好的汽車*/
public Car getCar();
}
以及實現(xiàn)類
public class CarBuilder implements Builder {
/**汽車成品*/
private Car car;
public CarBuilder(){
car=new Car();
}
/**組裝汽車輪子*/
@Override
public void buildChair() {
car.setChair(new Chair());
}
/**組裝汽車發(fā)動機*/
@Override
public void buildEngine() {
car.setEngine(new Engine());
}
/**組裝汽車玻璃*/
@Override
public void buildGlass() {
car.setGlass(new Glass());
}
/**組裝汽車座椅*/
@Override
public void buildWheel() {
car.setWheel(new Wheel());
}
/**返回組裝好的汽車*/
@Override
public Car getCar() {
buildChair();
buildEngine();
buildGlass();
buildWheel();
print("--整個汽車構建完畢--");
return car;
}
}
4)最后汽車創(chuàng)建測試
public static void main(String[] args) {
/**創(chuàng)建汽車組裝*/
Builder carBuilder=new CarBuilder();
Car car=carBuilder.getCar();
}
最后輸出:
--汽車座椅構建完畢--
--汽車發(fā)動機構建完畢--
--汽車玻璃構建完畢--
--汽車輪子構建完畢--
--整個汽車構建完畢--
5)體會心得:Builder模式實際的重點就把汽車的組裝過程和零部件的生產分開來實現(xiàn),零部件的生成主要靠自己的對象來實現(xiàn),我上面只是在構造函數里創(chuàng)建了,比較簡單,而重點汽車的組裝則交給CarBuilder來實現(xiàn),最終由builder來先負責零部件的創(chuàng)建,最后返回出成品的汽車。
一:使用場景
1)經常使用的地方:一個類只有一個實例,eg:頁面訪問統(tǒng)計pv,統(tǒng)計的個數就只能保證一個實例的統(tǒng)計。
2)我們目前使用的情況:比如我想創(chuàng)建一個對象,這個對象希望只有一份實例的維護,在內存的保存也只有一份,也就是在同一個jvm的java堆里只保存一份實例對象,所以你會想一辦法,在創(chuàng)建這個對象的時候,就已經能保證只有一份。
3)怎么改進:定義該對象的時候,就保證是同一份實例,比如:定義為私有構造函數,防止通過new的方式可以創(chuàng)建對象,然后在對象里定義一個靜態(tài)的私有成員(本身對象的一個實例),然后再創(chuàng)建一個外面訪問該對象的方法就好了。
4)改進的好處:代碼在編譯代碼這個級別就被控制了,不至于在jvm里運行的時候才來保證,把唯一實例的創(chuàng)建保證在編譯階段;jvm里內存只有一份,從而內存占有率更低,以及更方便java垃圾回收
5)改進后的壞處:只能是代碼稍微需要更多點,其實大家最后發(fā)現(xiàn)改進后的壞處,都是代碼定義比之間要多一點,但以后的維護代碼就降下來了,也短暫的代碼量偏大來換取以后代碼的精簡。
二:一個實際的例子
總體的例子
package com.mike.pattern.singleton;
/**
* 總統(tǒng)
*
* @author taoyu
*
* @since 2010-6-22
*/
public class President {
private President(){
System.out.println("總統(tǒng)已經選舉出來了");
}
/**總統(tǒng)只有一個*/
private static President president=new President();
/**
* 返回總統(tǒng)
*/
public static President getPresident(){
return president;
}
/**
* 總統(tǒng)宣布選舉成功
*/
public void announce(){
System.out.println("偉大的中國人民,我將成你們新的總統(tǒng)");
}
}
/**
* @param args
*/
public static void main(String[] args) {
President president=President.getPresident();
president.announce();
}
1.使用場景
1)子類過多,不容易管理;構造對象過程過長;精簡代碼創(chuàng)建;
2)目前我們代碼情況: 編寫代碼的時候,我們經常都在new對象,創(chuàng)建一個個的對象,而且還有很多麻煩的創(chuàng)建方式,eg:HashMap<String,Float> grade=new HashMap<String,Float>(),這樣的代碼創(chuàng)建方式太冗長了,難道你沒有想過把這個創(chuàng)建變的短一點么,比如:HashMap<String,Float>grade=HashMapFactory.new(),可以把你創(chuàng)建精簡一點;你也可以還有別的需求,在創(chuàng)建對象的時候,你需要不同的情況,創(chuàng)建統(tǒng)一種類別的對象,eg:我想生成不同的汽車,創(chuàng)建小轎車,創(chuàng)建卡車,創(chuàng)建公交汽車等等,都屬于同種類別:汽車,你難道沒有想過,我把這些創(chuàng)建的對象在一個工廠里來負責創(chuàng)建,我把創(chuàng)建分開化,交給一人來負責,這樣可以讓代碼更加容易管理,創(chuàng)建方式也可以簡單點。
比如:Car BMW=CarFactory.create(bmw); 把創(chuàng)建new由一個統(tǒng)一負責,這樣管理起來相當方便
3)怎么改進:這個時候,你會想到,創(chuàng)建這樣同類別的東西,我把這個權利分出去,讓一個人來單獨管理,它只負責創(chuàng)建我的對象這個事情,所以你單獨簡歷一個對象來創(chuàng)建同類的對象,這個時候,你想這個東西有點像工廠一樣,生成同樣的產品,所以取了個名字:工廠模式,顧名思義,只負責對象的創(chuàng)建
4)改進后的好處:代碼更加容易管理了,代碼的創(chuàng)建要簡潔很多。
5)改進后的壞處:那就是你需要單獨加一個工廠對象來負責創(chuàng)建,多需要寫點代碼。
2.一個實際的例子
創(chuàng)建寶馬汽車與奔馳汽車的例子
1)先提取出一個汽車的公用接口Car
public interface Car{
/**行駛*/
public void drive();
}
2)寶馬和奔馳汽車對象
public class BMWCar implements Car {
/**
* 汽車發(fā)動
*/
public void drive(){
System.out.println("BMW Car drive");
}
}
public class BengCar implements Car {
/**
* 汽車發(fā)動
*/
public void drive(){
System.out.println("BengChi Care drive");
}
}
3)單獨一個汽車工廠來負責創(chuàng)建
public class FactoryCar {
/**
* 制造汽車
*
* @param company 汽車公司
* @return 汽車
* @throws CreateCarException 制造汽車失敗異常
*/
public static Car createCar(Company company)throws CreateCarException{
if(company==Company.BMW){
return new BMWCar();
}else if(company==Company.Beng){
return new BengCar();
}
return null;
}
}
4)最后的代碼實現(xiàn):
Car BMWCar=FactoryCar.createCar(Company.BMW);
BMWCar.drive();
1. 我說下我對設計模式的理解:任何一樣事物都是因為有需求的驅動才誕生的,所以設計模式也不例外,我們平時在編寫代碼的時候,隨著時間的深入,發(fā)現(xiàn)很多代碼很難維護,可擴展性級差,以及代碼的效率也比較低,這個時候你肯定會想辦法讓代碼變的優(yōu)美又能解決你項目中的問題,所以在面向對象語言里,你肯定會去發(fā)現(xiàn)很多可以重用的公用的方法,比如:接口的存在,你自然就想到了,讓你定義的方法與你的實現(xiàn)分開,也可以很方便把不同的類與接口匹配起來,形成了一個公用的接口,你會發(fā)現(xiàn)這樣做,好處會是非常多的,解決了你平時想把代碼的申明與邏輯實現(xiàn)的分開。
2. 這個時候,你發(fā)現(xiàn)了,本身面向對象的語言里,已經暗藏了很多好處,你肯定會仔細去分析面向對象這個語言,認真去挖掘里面更多的奧秘,最后,你發(fā)現(xiàn)了,原來你可以把面向對象的特性提取成一個公用的實現(xiàn)案例,這些案例里能幫助你解決你平時編寫代碼的困擾,而這樣一群人,就是所謂gof的成員,他們從平時設計建筑方面找到了靈感,建筑的設計也可以公用化以及重用化,所以他們也提取了相關的軟件設計方面的公用案例,也就有了下面的相關的所謂23種設計模式,而里面這么多模式,你也可以把他們歸類起來,最后發(fā)現(xiàn)就幾類模式:創(chuàng)建,結構,行為等模式類別,而這些現(xiàn)成的方案,也可以在實際應用中充分發(fā)揮作用,隨著大家的使用以及理解,發(fā)現(xiàn)其實這些所謂的模式里,你的確可以讓你的代碼變的更加優(yōu)美與簡練。
3. 我比較喜歡把代碼變的更加優(yōu)美與簡練,優(yōu)美的代碼就是一看就懂,結構很清晰,而簡歷就是一目了然,又可以解決你的問題,就是代碼又少效率又高,所以平時要養(yǎng)成寫java doc的習慣,這樣的代碼才為清晰,所以才會更加優(yōu)美。
4. 這些就是我對設計模式的理解,所以這么好的寶貝,我們不去深入的了解,的確可惜了,這就叫站到巨人的肩膀上.....
一:網絡配置
1.關掉防火墻
1) 重啟后生效
開啟: chkconfig iptables on
關閉: chkconfig iptables off
2) 即時生效,重啟后失效
開啟: service iptables start
關閉: service iptables stop
2.下載軟件
wget curl
3.安裝和解壓
安裝 rpm -ivh
升級 rpm -Uvh
卸載 rpm -e
tar -zxvf
二:網卡設置
1、 設置ip地址(即時生效,重啟失效)
#ifconfig eth0 ip地址 netmask 子網掩碼
2、 設置ip地址(重啟生效,永久生效)
#setup
3、 通過配置文件設置ip地址(重啟生效,永久生效)
#vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0 #設備名,與文件同名。
ONBOOT=yes #在系統(tǒng)啟動時,啟動本設備。
BOOTPROTO=static
IPADDR=202.118.75.91 #此網卡的IP地址
NETMASK=255.255.255.0 #子網掩碼
GATEWAY=202.118.75.1 #網關IP
MACADDR=00:02:2D:2E:8C:A8 #mac地址
4、 重啟網絡服務
#service network restart //重啟所有網卡
5、 禁用網卡,啟動網卡
#ifdown eth0
#ifup eth0
6、 屏蔽網卡,顯示網卡
#ifconfig eth0 down
#ifconfig eth0 up
7、 配置DNS客戶端(最多三個)
#vi /etc/resolv.conf
nameserver 202.99.96.68
8、更改主機名(即時生效)
#hostname 主機名
9、更改主機名(重啟計算機生效,永久生效)
#vi /etc/sysconfig/network
HOSTNAME=主機名
三:兩臺linux拷貝命令:scp
1.安裝scp:yum install openssh-clients
2.scp -r 本地用戶名@IP地址:文件名1 遠程用戶名@IP地址:文件名2
摘要: 作者:NetSeek http://www.linuxtone.org (IT運維專家網|集群架構|性能調優(yōu))歡迎轉載,轉載時請務必以超鏈接形式標明文章原始出處和作者信息及本聲明.首發(fā)時間: 2008-11-25 更新時間:2009-1-14目 錄一、 Nginx 基礎知識二、 Nginx 安裝及調試三、 Nginx Rewrite四、 Nginx Redirect五、 Nginx 目錄自動加斜線...
閱讀全文
一:quartz簡介 OpenSymphony 的Quartz提供了一個比較完美的任務調度解決方案。 Quartz 是個開源的作業(yè)調度框架,定時調度器,為在 Java 應用程序中進行作業(yè)調度提供了簡單卻強大的機制。
Quartz中有兩個基本概念:作業(yè)和觸發(fā)器。作業(yè)是能夠調度的可執(zhí)行任務,觸發(fā)器提供了對作業(yè)的調度
二:quartz spring配置詳解- 為什么不適用java.util.Timer結合java.util.TimerTask
1.主要的原因,適用不方便,特別是制定具體的年月日時分的時間,而quartz使用類似linux上的cron配置,很方便的配置每隔時間執(zhí)行觸發(fā)。
2.其次性能的原因,使用jdk自帶的Timer不具備多線程,而quartz采用線程池,性能上比timer高出很多。
在spring里主要分為兩種使用方式:第一種,也是目前使用最多的方式,spring提供的MethodInvokingJobDetailFactoryBean代理類,通過雷利類直接調用任務類的某個函數;第二種,程序里實現(xiàn)quartz接口,quartz通過該接口進行調度。
主要講解通過spring提供的代理類MethodInvokingJobDetailFactoryBean 1.業(yè)務邏輯類:業(yè)務邏輯是獨立的,本身就與quartz解耦的,并沒有深入進去,這對業(yè)務來講是很好的一個方式。
public class TestJobTask{ /**
*業(yè)務邏輯處理
*/ public void service(){
/**業(yè)務邏輯*/ 
..
}
}
2.增加一個線程池 <!-- 線程執(zhí)行器配置,用于任務注冊 --><bean id="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="10" />
<property name="maxPoolSize" value="100" />
<property name="queueCapacity" value="500" />
</bean>
3.定義業(yè)務邏輯類
<!-- 業(yè)務對象 --><bean id="testJobTask" class="com.mike.scheduling.TestJobTask" />
4.增加quartz調用業(yè)務邏輯
<!-- 調度業(yè)務 --><bean id="jobDetail" class="org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="testJobTask" />
<property name="targetMethod" value="service" />
</bean>
5.增加調用的觸發(fā)器,觸發(fā)的時間,有兩種方式:
第一種觸發(fā)時間,采用類似linux的cron,配置時間的表示發(fā)出豐富 <bean id="cronTrigger" class="org.springframework.scheduling.quartz.CronTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="cronExpression" value="10 0/1 * * * ?" />
</bean>
Cron表達式“10 */1 * * * ?”意為:從10秒開始,每1分鐘執(zhí)行一次 第二種,采用比較簡話的方式,申明延遲時間和間隔時間
<bean id="taskTrigger" class="org.springframework.scheduling.quartz.SimpleTriggerBean"> <property name="jobDetail" ref="jobDetail" />
<property name="startDelay" value="10000" />
<property name="repeatInterval" value="60000" />
</bean>
延遲10秒啟動,然后每隔1分鐘執(zhí)行一次 6.開始調用
<!-- 設置調度 --><bean class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="cronTrigger" />
</list>
</property>
<property name="taskExecutor" ref="executor" />
</bean>
7.結束:啟動容器即可,已經將spring和quartz結合完畢。 Cron常用的表達式 "0 0 12 * * ?" 每天中午12點觸發(fā)"0 15 10 ? * *" 每天上午10:15觸發(fā)
"0 15 10 * * ?" 每天上午10:15觸發(fā)
"0 15 10 * * ? *" 每天上午10:15觸發(fā)
"0 15 10 * * ? 2005" 2005年的每天上午10:15觸發(fā)
"0 * 14 * * ?" 在每天下午2點到下午2:59期間的每1分鐘觸發(fā)
"0 0/5 14 * * ?" 在每天下午2點到下午2:55期間的每5分鐘觸發(fā)
"0 0/5 14,18 * * ?" 在每天下午2點到2:55期間和下午6點到6:55期間的每5分鐘觸發(fā)
"0 0-5 14 * * ?" 在每天下午2點到下午2:05期間的每1分鐘觸發(fā)
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44觸發(fā)
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15觸發(fā)
"0 15 10 15 * ?" 每月15日上午10:15觸發(fā)
"0 15 10 L * ?" 每月最后一日的上午10:15觸發(fā)
"0 15 10 ? * 6L" 每月的最后一個星期五上午10:15觸發(fā)
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一個星期五上午10:15觸發(fā)
"0 15 10 ? * 6#3" 每月的第三個星期五上午10:15觸發(fā)
三:quartz原理
根據上面spring的配置,我們就比較清楚quartz的內部情況,下面我們主要詳解配置涉及到的每個點 1.我們先從最后一個步驟看起,
SchedulerFactoryBean ,scheduler的工廠實現(xiàn),里面可以生產出對應的多個jobDetail和trigger,每個jobDetail對應trigger代表一個任務
Quartz的SchedulerFactory是標準的工廠類,不太適合在Spring環(huán)境下使用。此外,為了保證Scheduler能夠感知 Spring容器的生命周期,完成自動啟動和關閉的操作,必須讓Scheduler和Spring容器的生命周期相關聯(lián)。以便在Spring容器啟動后, Scheduler自動開始工作,而在Spring容器關閉前,自動關閉Scheduler。為此,Spring提供 SchedulerFactoryBean,這個FactoryBean大致?lián)碛幸韵碌墓δ埽?nbsp; 1)以更具Bean風格的方式為Scheduler提供配置信息;
2)讓Scheduler和Spring容器的生命周期建立關聯(lián),相生相息;
3)通過屬性配置部分或全部代替Quartz自身的配置文件。
2.jobDetail,表示一個可執(zhí)行的業(yè)務調用
3.trigger:調度的時間計劃,什么時候,每隔多少時間可執(zhí)行等時間計劃
4.ThreadPoolTaskExecutor,線程池,用來并行執(zhí)行每個對應的job,提高效率,這也是上面提到不推薦使用jdk自身timer的一個很重要的原因
一:事務的概念
事務必須服從ISO/IEC所制定的ACID原則。ACID是原子性(atomicity)、一致性(consistency)、隔離性(isolation)和持久性(durability)的縮寫 事務的原子性:表示事務執(zhí)行過程中的任何失敗都將導致事務所做的任何修改失效。
一致性表示當事務執(zhí)行失敗時,所有被該事務影響的數據都應該恢復到事務執(zhí)行前的狀態(tài)。
隔離性表示在事務執(zhí)行過程中對數據的修改,在事務提交之前對其他事務不可見。
持久性表示已提交的數據在事務執(zhí)行失敗時,數據的狀態(tài)都應該正確。 二:事務的場景
1.與銀行相關的業(yè)務,重要的數據,與錢相關的內容不能出任何錯。
2.系統(tǒng)內部認為重要的數據,都需要事務的支持,防止重要數據的不一致。
3.具體的業(yè)務場景:銀行業(yè)務,支付業(yè)務,交易業(yè)務等。
三:事務的實現(xiàn)方式
首先說一下事務的類型,主要包含一下三種:JDBC事務,JTA事務,容器事務
1、JDBC事務 JDBC 事務是用 Connection 對象控制的。JDBC Connection 接口( java.sql.Connection )提供了兩種事務模式:自動提交和手工提交。 java.sql.Connection 提供了以下控制事務的方法: public void setAutoCommit(boolean) public boolean getAutoCommit() public void commit() public void rollback() 使用 JDBC 事務界定時,您可以將多個 SQL 語句結合到一個事務中。JDBC 事務的一個缺點是事務的范圍局限于一個數據庫連接。一個 JDBC 事務不能跨越多個數據庫。 2、JTA(Java Transaction API)事務 JTA是一種高層的,與實現(xiàn)無關的,與協(xié)議無關的API,應用程序和應用服務器可以使用JTA來訪問事務。 JTA允許應用程序執(zhí)行分布式事務處理--在兩個或多個網絡計算機資源上訪問并且更新數據,這些數據可以分布在多個數據庫上。JDBC驅動程序的JTA支持極大地增強了數據訪問能力。 如果計劃用 JTA 界定事務,那么就需要有一個實現(xiàn) javax.sql.XADataSource 、 javax.sql.XAConnection 和 javax.sql.XAResource 接口的 JDBC 驅動程序。一個實現(xiàn)了這些接口的驅動程序將可以參與 JTA 事務。一個 XADataSource 對象就是一個 XAConnection 對象的工廠。 XAConnection s 是參與 JTA 事務的 JDBC 連接。 您將需要用應用服務器的管理工具設置 XADataSource 。從應用服務器和 JDBC 驅動程序的文檔中可以了解到相關的指導。 J2EE 應用程序用 JNDI 查詢數據源。一旦應用程序找到了數據源對象,它就調用 javax.sql.DataSource.getConnection() 以獲得到數據庫的連接。 XA 連接與非 XA 連接不同。一定要記住 XA 連接參與了 JTA 事務。這意味著 XA 連接不支持 JDBC 的自動提交功能。同時,應用程序一定不要對 XA 連接調用 java.sql.Connection.commit() 或者 java.sql.Connection.rollback() 。相反,應用程序應該使用 UserTransaction.begin()、 UserTransaction.commit() 和 serTransaction.rollback() 。 3、容器事務 容器事務主要是J2EE應用服務器提供的,容器事務大多是基于JTA完成,這是一個基于JNDI的,相當復雜的API實現(xiàn)。相對編碼實現(xiàn)JTA事務管理,我們可以通過EJB容器提供的容器事務管理機制(CMT)完成同一個功能,這項功能由J2EE應用服務器提供。這使得我們可以簡單的指定將哪個方法加入事務,一旦指定,容器將負責事務管理任務。這是我們土建的解決方式,因為通過這種方式我們可以將事務代碼排除在邏輯編碼之外,同時將所有困難交給J2EE容器去解決。使用EJB CMT的另外一個好處就是程序員無需關心JTA API的編碼,不過,理論上我們必須使用EJB。 四、三種事務差異 1、JDBC事務控制的局限性在一個數據庫連接內,但是其使用簡單。 2、JTA事務的功能強大,事務可以跨越多個數據庫或多個DAO,使用也比較復雜。 3、容器事務,主要指的是J2EE應用服務器提供的事務管理,局限于EJB應用使用。
五:詳解事務
1.首先看一下目前使用最多的spring事務,目前spring配置分為聲明式事務和編程式事務。
1)編程式事務
主要是實現(xiàn)接口PlatformTransactionManager

實現(xiàn)了事務管理的接口有非常多,這里主要講DataSourceTransactionManager和數據庫jdbc相關的事務處理方式
之前有接觸過hadoop,但都比較淺顯,對立面的東東不是很清楚!
打算后面在hadoop上花時間把里面的內容,好好學學,這篇博客將在后面陸續(xù)更新hadoop學習筆記。
一:Mina概要 Apache Mina是一個能夠幫助用戶開發(fā)高性能和高伸縮性網絡應用程序的框架。它通過Java nio技術基于TCP/IP和UDP/IP協(xié)議提供了抽象的、事件驅動的、異步的API。
如下的特性:
1、 基于Java nio的TCP/IP和UDP/IP實現(xiàn)
基于RXTX的串口通信(RS232)
VM 通道通信
2、通過filter接口實現(xiàn)擴展,類似于Servlet filters
3、low-level(底層)和high-level(高級封裝)的api:
low-level:使用ByteBuffers
High-level:使用自定義的消息對象和解碼器
4、Highly customizable(易用的)線程模式(MINA2.0 已經禁用線程模型了):
單線程
線程池
多個線程池
5、基于java5 SSLEngine的SSL、TLS、StartTLS支持
6、負載平衡
7、使用mock進行單元測試
8、jmx整合
9、基于StreamIoHandler的流式I/O支持
10、IOC容器的整合:Spring、PicoContainer
11、平滑遷移到Netty平臺
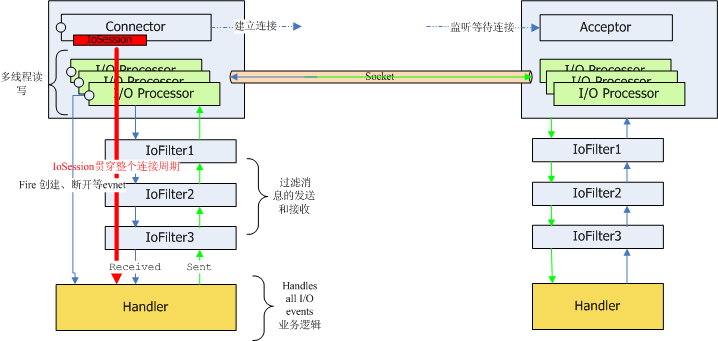
二:實踐 首先講一下客戶端的通信過程:
1.通過SocketConnector同服務器端建立連接
2.鏈接建立之后I/O的讀寫交給了I/O Processor線程,I/O Processor是多線程的
3.通過I/O Processor讀取的數據經過IoFilterChain里所有配置的IoFilter,IoFilter進行消息的過濾,格式的轉換,在這個層面可以制定一些自定義的協(xié)議
4.最后IoFilter將數據交給Handler進行業(yè)務處理,完成了整個讀取的過程
5.寫入過程也是類似,只是剛好倒過來,通過IoSession.write寫出數據,然后Handler進行寫入的業(yè)務處理,處理完成后交給IoFilterChain,進行消息過濾和協(xié)議的轉換,最后通過I/O Processor將數據寫出到socket通道
IoFilterChain作為消息過濾鏈
1.讀取的時候是從低級協(xié)議到高級協(xié)議的過程,一般來說從byte字節(jié)逐漸轉換成業(yè)務對象的過程
2.寫入的時候一般是從業(yè)務對象到字節(jié)byte的過程
IoSession貫穿整個通信過程的始終
客戶端通信過程
1.創(chuàng)建服務器
package com.gewara.web.module.base;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.service.IoAcceptor;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketAcceptor;
/**
* Mina服務器
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloServer {
private static final int PORT = 8901;// 定義監(jiān)聽端口
public static void main(String[] args) throws IOException{
// 創(chuàng)建服務端監(jiān)控線程
IoAcceptor acceptor = new NioSocketAcceptor();
// 設置日志記錄器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 設置編碼過濾器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定業(yè)務邏輯處理器
acceptor.setHandler(new HelloServerHandler());
// 設置端口號
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 啟動監(jiān)聽線程
acceptor.bind();
}
}
2.創(chuàng)建服務器端業(yè)務邏輯
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
/**
* 服務器端業(yè)務邏輯
*
* @author mike
*
* @since 2012-3-15
*/public class HelloServerHandler
extends IoHandlerAdapter {
@Override
/**
* 連接創(chuàng)建事件
*/ public void sessionCreated(IoSession session){
// 顯示客戶端的ip和端口
System.out.println(session.getRemoteAddress().toString());
}
@Override
/**
* 消息接收事件
*/ public void messageReceived(IoSession session, Object message)
throws Exception{
String str = message.toString();
if (str.trim().equalsIgnoreCase("quit")){
// 結束會話
session.close(
true);
return;
}
// 返回消息字符串
session.write("Hi Client!");
// 打印客戶端傳來的消息內容
System.out.println("Message written
" + str);
}
}
3.創(chuàng)建客戶端
package com.gewara.web.module.base;
import java.net.InetSocketAddress;
import java.nio.charset.Charset;
import org.apache.mina.core.future.ConnectFuture;
import org.apache.mina.filter.codec.ProtocolCodecFilter;
import org.apache.mina.filter.codec.textline.TextLineCodecFactory;
import org.apache.mina.filter.logging.LoggingFilter;
import org.apache.mina.transport.socket.nio.NioSocketConnector;
/**
* Mina客戶端
*
* @author mike
*
* @since 2012-3-15
*/
public class HelloClient {
public static void main(String[] args){
// 創(chuàng)建客戶端連接器.
NioSocketConnector connector = new NioSocketConnector();
// 設置日志記錄器
connector.getFilterChain().addLast("logger", new LoggingFilter());
// 設置編碼過濾器
connector.getFilterChain().addLast("codec",
new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 設置連接超時檢查時間
connector.setConnectTimeoutCheckInterval(30);
// 設置事件處理器
connector.setHandler(new HelloClientHandler());
// 建立連接
ConnectFuture cf = connector.connect(new InetSocketAddress("192.168.2.89", 8901));
// 等待連接創(chuàng)建完成
cf.awaitUninterruptibly();
// 發(fā)送消息
cf.getSession().write("Hi Server!");
// 發(fā)送消息
cf.getSession().write("quit");
// 等待連接斷開
cf.getSession().getCloseFuture().awaitUninterruptibly();
// 釋放連接
connector.dispose();
}
}
4.客戶端業(yè)務邏輯
package com.gewara.web.module.base;
import org.apache.mina.core.service.IoHandlerAdapter;
import org.apache.mina.core.session.IoSession;
public class HelloClientHandler extends IoHandlerAdapter {
@Override
/**
* 消息接收事件
*/
public void messageReceived(IoSession session, Object message) throws Exception{
//顯示接收到的消息
System.out.println("server message:"+message.toString());
}
}
5.先啟動服務器端,然后啟動客戶端
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - CREATED
/192.168.2.89:2691
2012-03-15 14:45:41,456 INFO logging.LoggingFilter - OPENED
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=11 cap=2048: 48 69 20 53 65 72 76 65 72 21 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
Message written
Hi Server!
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - SENT: HeapBuffer[pos=0 lim=0 cap=0: empty]
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - RECEIVED: HeapBuffer[pos=0 lim=5 cap=2048: 71 75 69 74 0A]
2012-03-15 14:45:41,487 DEBUG codec.ProtocolCodecFilter - Processing a MESSAGE_RECEIVED
for session 1
2012-03-15 14:45:41,487 INFO logging.LoggingFilter - CLOSED
1.首先看服務器
// 創(chuàng)建服務端監(jiān)控線程
IoAcceptor acceptor = new NioSocketAcceptor();
// 設置日志記錄器
acceptor.getFilterChain().addLast("logger", new LoggingFilter());
// 設置編碼過濾器
acceptor.getFilterChain().addLast("codec",new ProtocolCodecFilter(new TextLineCodecFactory(Charset.forName("UTF-8"))));
// 指定業(yè)務邏輯處理器
acceptor.setHandler(new HelloServerHandler());
// 設置端口號
acceptor.setDefaultLocalAddress(new InetSocketAddress(PORT));
// 啟動監(jiān)聽線程
acceptor.bind();
1)先創(chuàng)建NioSocketAcceptor nio的接收器,談到Socket就要說到Reactor模式 當前分布式計算 Web Services盛行天下,這些網絡服務的底層都離不開對socket的操作。他們都有一個共同的結構:1. Read request2. Decode request3. Process service 4. Encode reply5. Send reply 
但這種模式在用戶負載增加時,性能將下降非常的快。我們需要重新尋找一個新的方案,保持數據處理的流暢,很顯然,事件觸發(fā)機制是最好的解決辦法,當有事件發(fā)生時,會觸動handler,然后開始數據的處理。
Reactor模式類似于AWT中的Event處理。
Reactor模式參與者
1.Reactor 負責響應IO事件,一旦發(fā)生,廣播發(fā)送給相應的Handler去處理,這類似于AWT的thread
2.Handler 是負責非堵塞行為,類似于AWT ActionListeners;同時負責將handlers與event事件綁定,類似于AWT addActionListener

并發(fā)系統(tǒng)常采用reactor模式,簡稱觀察者模式,代替常用的多線程處理方式,利用有限的系統(tǒng)的資源,提高系統(tǒng)的吞吐量。
可以看一下這篇文章,講解的很生動具體,一看就明白reactor模式的好處
http://daimojingdeyu.iteye.com/blog/828696 Reactor模式是編寫高性能網絡服務器的必備技術之一,它具有如下的優(yōu)點: 1)響應快,不必為單個同步時間所阻塞,雖然Reactor本身依然是同步的; 2)編程相對簡單,可以最大程度的避免復雜的多線程及同步問題,并且避免了多線程/進程的切換開銷; 3)可擴展性,可以方便的通過增加Reactor實例個數來充分利用CPU資源; 4)可復用性,reactor框架本身與具體事件處理邏輯無關,具有很高的復用性; 2)其次,再說說NIO的基本原理和使用 NIO 有一個主要的類Selector,這個類似一個觀察者,只要我們把需要探知的socketchannel告訴Selector,我們接著做別的事情,當有事件發(fā)生時,他會通知我們,傳回一組 SelectionKey,我們讀取這些Key,就會獲得我們剛剛注冊過的socketchannel,然后,我們從這個Channel中讀取數據,放心,包準能夠讀到,接著我們可以處理這些數據。
Selector內部原理實際是在做一個對所注冊的channel的輪詢訪問,不斷的輪詢(目前就這一個算法),一旦輪詢到一個channel有所注冊的事情發(fā)生,比如數據來了,他就會站起來報告,交出一把鑰匙,讓我們通過這把鑰匙(SelectionKey表示 SelectableChannel 在 Selector 中的注冊的標記。 )來讀取這個channel的內容。
一:基本原理 主要是要實現(xiàn)網絡之間的通訊,
網絡通信需要做的就是將流從一臺計算機傳輸到另外一臺計算機,基于傳輸協(xié)議和網絡IO來實現(xiàn),其中傳輸協(xié)議比較出名的有http、 tcp、udp等等,http、tcp、udp都是在基于Socket概念上為某類應用場景而擴展出的傳輸協(xié)議,網絡IO,主要有bio、nio、aio 三種方式,所有的分布式應用通訊都基于這個原理而實現(xiàn)。
二:實踐
在分布式服務框架中,一個最基礎的問題就是遠程服務是怎么通訊的,在Java領域中有很多可實現(xiàn)遠程通訊的技術:RMI、MINA、ESB、Burlap、Hessian、SOAP、EJB和JMS
既然引入出了這么多技術,那我們就順道深入挖掘下去,了解每個技術框架背后的東西:
1.首先看RMI
RMI主要包含如下內容:
遠程服務的接口定義
·遠程服務接口的具體實現(xiàn) ·樁(Stub)和框架(Skeleton)文件 ·一個運行遠程服務的服務器 ·一個RMI命名服務,它允許客戶端去發(fā)現(xiàn)這個遠程服務 ·類文件的提供者(一個HTTP或者FTP服務器) ·一個需要這個遠程服務的客戶端程序 來看下基于RMI的一次完整的遠程通信過程的原理:
1)客戶端發(fā)起請求,請求轉交至RMI客戶端的stub類;
2)stub類將請求的接口、方法、參數等信息進行序列化;
3)基于tcp/ip將序列化后的流傳輸至服務器端;
4)服務器端接收到流后轉發(fā)至相應的skelton類;
5)skelton類將請求的信息反序列化后調用實際的處理類;
6)處理類處理完畢后將結果返回給skelton類;
7)Skelton類將結果序列化,通過tcp/ip將流傳送給客戶端的stub;
8)stub在接收到流后反序列化,將反序列化后的Java Object返回給調用者。
RMI應用級協(xié)議內容:
基于Java串行化機制將請求的java object信息轉化為流。
根據采用的協(xié)議啟動相應的監(jiān)聽端口,當有流進入后基于Java串行化機制將流進行反序列化,并根據RMI協(xié)議獲取到相應的處理對象信息,進行調用并處理,處理完畢后的結果同樣基于java串行化機制進行返回。
tcp/ip。
原理講了,開始實踐:
創(chuàng)建RMI程序的6個步驟:
1、定義一個遠程接口的接口,該接口中的每一個方法必須聲明它將產生一個RemoteException異常。
2、定義一個實現(xiàn)該接口的類。
3、使用RMIC程序生成遠程實現(xiàn)所需的殘根和框架。
4、創(chuàng)建一個服務器,用于發(fā)布2中寫好的類。
5. 創(chuàng)建一個客戶程序進行RMI調用。
6、啟動rmiRegistry并運行自己的遠程服務器和客戶程序
1)首先創(chuàng)建遠程接口:
/**
* 遠程接口
*
* @author mike
*
* @since 2012-3-14
*/
public interface Hello extends Remote {
/**
* 測試rmi
*
* @return hello
* @throws RemoteException
*/
public String hello()throws RemoteException;
}
2)創(chuàng)建接口實現(xiàn)
package com.gewara.rmi;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
/**
* 遠程接口實現(xiàn)
*
* @author mike
*
* @since 2012-3-14
*/
public class HelloImpl extends UnicastRemoteObject implements Hello {
/**
* seria id
*/
private static final long serialVersionUID = -7931720891757437009L;
protected HelloImpl() throws RemoteException {
super();
}
/**
* hello實現(xiàn)
*
* @return hello world
* @throws RemoteException
*/
public String hello() throws RemoteException {
return "hello world";
}
}
3)創(chuàng)建服務器端
package com.gewara.rmi;
import java.rmi.Naming;
import java.rmi.registry.LocateRegistry;
public class Server {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* RMI Server
*/
public Server() {
try {
//創(chuàng)建遠程對象
Hello hello=new HelloImpl();
//啟動注冊表
LocateRegistry.createRegistry(10009);
//將名稱綁定到對象
Naming.bind(RMI_URL, hello);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* @param args
*/
public static void main(String[] args) {
new Server();
}
}
4)創(chuàng)建客服端
package com.gewara.rmi;
import java.rmi.Naming;
public class Client {
private static final String RMI_URL="rmi://192.168.2.89:10009/server";
/**
* @param args
*/
public static void main(String[] args) {
try {
String result=((Hello)Naming.lookup(RMI_URL)).hello();
System.out.println(result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
5)先啟動服務器端,然后再啟動客戶端
顯示結果:hello world
由于涉及到的內容比較多,打算每一篇里講一個遠程通訊框架,繼續(xù)詳解RMI
三:詳解RMI內部原理
1. RMI基本結構:包含兩個獨立的程序,服務器和客戶端,服務器創(chuàng)建多個遠程對象,讓遠程對象能夠被引用,等待客戶端調用這些遠程對象的方法。客戶端從服務器獲取到一個或則多個遠程對象的引用,然后調用遠程對象方法,主要涉及到RMI接口、回調等技術。
2.RMI回調:服務器提供遠程對象引用供客戶端調用,客戶端主動調用服務器,如果服務器主動打算調用客戶端,這就叫回調。
3.命名遠程對象:客戶端通過一個命名或則一個查找服務找到遠程服務,遠程服務包含Java的命名和查找接口(Java Naming and Directory Interface)JNDI
RMI提供了一種服務:RMI注冊rmiregistry,默認端口:1099,主機提供遠程服務,接受服務,啟動注冊服務的命令:start rmiregistry
客戶端使用一個靜態(tài)類Naming到達RMI注冊處,通過方法lookup()方法,客戶來詢問注冊。
一:spring概要 簡單來說,Spring是一個輕量級的控制反轉(IoC)和面向切面(AOP)的容器框架。
◆
控制反轉——Spring通過一種稱作控制反轉(IoC)的技術促進了松耦合。當應用了IoC,一個對象依賴的其它對象會通過被動的方式傳遞進來,而不是這個對象自己創(chuàng)建或者查找依賴對象。你可以認為IoC與JNDI相反——不是對象從容器中查找依賴,而是容器在對象初始化時不等對象請求就主動將依賴傳遞給它。
◆
面向切面——Spring提供了
面向切面編程的豐富支持,允許通過分離應用的業(yè)務邏輯與系統(tǒng)級服務(例如審計(auditing)和事務(transaction)管理)進行內聚性的開發(fā)。應用對象只實現(xiàn)它們應該做的——完成業(yè)務邏輯——僅此而已。它們并不負責(甚至是意識)其它的系統(tǒng)級關注點,例如日志或事務支持。
◆
容器——Spring包含并管理應用對象的配置和生命周期,在這個意義上它是一種容器,你可以配置你的每個bean如何被創(chuàng)建——基于一個可配置
原型(prototype),你的bean可以創(chuàng)建一個單獨的實例或者每次需要時都生成一個新的實例——以及它們是如何相互關聯(lián)的。然而,Spring不應該被混同于傳統(tǒng)的重量級的EJB容器,它們經常是龐大與笨重的,難以使用。
◆
框架——Spring可以將簡單的組件配置、組合成為復雜的應用。在Spring中,應用對象被聲明式地組合,典型地是在一個XML文件里。Spring也提供了很多基礎功能(事務管理、持久化框架集成等等),將應用邏輯的開發(fā)留給了你。
所有Spring的這些特征使你能夠編寫更干凈、更可管理、并且更易于測試的代碼。它們也為Spring中的各種模塊提供了基礎支持。
二:spring的整個生命周期 首先說一下spring的整個初始化過程,web應用中創(chuàng)建spring容器有兩種方式: 第一種:在web.xml里直接配置spring容器,servletcontextlistener
第二種:通過load-on-startup servlet實現(xiàn)。
主要就說一下第一種方式:
spring提供了ServletContextListener的實現(xiàn)類ContextLoaderListener,該類作為listener使用,在創(chuàng)建時自動查找WEB-INF目錄下的applicationContext.xml,該文件是默認查找的,如果只有一個就不需要配置初始化xml參數,如果需要配置,設置contextConfigLocation為application的xml文件即可。可以好好閱讀一下ContextLoaderListener的源代碼,就可以很清楚的知道spring的整個加載過程。
spring容器的初始化代碼如下:
/** * Initialize the root web application context.
*/
public void contextInitialized(ServletContextEvent event) {
this.contextLoader = createContextLoader();
if (this.contextLoader == null) {
this.contextLoader = this;
}
this.contextLoader.initWebApplicationContext(event.getServletContext());//contextLoader初始化web應用容器
}
繼續(xù)分析initWebApplicationContext做了什么事情:
/**
* Initialize Spring's web application context for the given servlet context,
* according to the "{@link #CONTEXT_CLASS_PARAM contextClass}" and
* "{@link #CONFIG_LOCATION_PARAM contextConfigLocation}" context-params.
* @param servletContext current servlet context
* @return the new WebApplicationContext
* @see #CONTEXT_CLASS_PARAM
* @see #CONFIG_LOCATION_PARAM
*/
public WebApplicationContext initWebApplicationContext(ServletContext servletContext) {
//首先創(chuàng)建一個spring的父容器,類似根節(jié)點root容器,而且只能是一個,如果已經創(chuàng)建,拋出對應的異常
if (servletContext.getAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE) != null) {
throw new IllegalStateException(
"Cannot initialize context because there is already a root application context present - " +
"check whether you have multiple ContextLoader* definitions in your web.xml!");
}
Log logger = LogFactory.getLog(ContextLoader.class);
servletContext.log("Initializing Spring root WebApplicationContext");
if (logger.isInfoEnabled()) {
logger.info("Root WebApplicationContext: initialization started");
}
long startTime = System.currentTimeMillis();
try {
// Determine parent for root web application context, if any.
ApplicationContext parent = loadParentContext(servletContext);//創(chuàng)建通過web.xml配置的父容器
具體里面的代碼是怎么實現(xiàn)的,就不在這里進行詳解了
// Store context in local instance variable, to guarantee that
// it is available on ServletContext shutdown.
this.context = createWebApplicationContext(servletContext, parent);//主要的創(chuàng)建過程都在改方法內,可以自己去看源代碼
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, this.context);
//把spring初始好的容器加載到servletcontext內,相當于servletcontext包含webapplicationcontext
ClassLoader ccl = Thread.currentThread().getContextClassLoader();
if (ccl == ContextLoader.class.getClassLoader()) {
currentContext = this.context;
}
else if (ccl != null) {
currentContextPerThread.put(ccl, this.context);
}
if (logger.isDebugEnabled()) {
logger.debug("Published root WebApplicationContext as ServletContext attribute with name [" +
WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE + "]");
}
if (logger.isInfoEnabled()) {
long elapsedTime = System.currentTimeMillis() - startTime;
logger.info("Root WebApplicationContext: initialization completed in " + elapsedTime + " ms");
}
return this.context;
}
catch (RuntimeException ex) {
logger.error("Context initialization failed", ex);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, ex);
throw ex;
}
catch (Error err) {
logger.error("Context initialization failed", err);
servletContext.setAttribute(WebApplicationContext.ROOT_WEB_APPLICATION_CONTEXT_ATTRIBUTE, err);
throw err;
}
}
看到這里基本已經清楚了整個spring容器的加載過程,如果還想了解更加深入,請查看我紅色標注的方法體。
其次再說一下spring的IOC和AOP使用的場景,由于原理大家都很清楚了,那就說一下它們使用到的地方:
IOC使用的場景:
管理bean的依賴關系,目前主流的電子商務網站基本都采用spring管理業(yè)務層代碼的依賴關系,包括:淘寶,支付寶,阿里巴巴,百度等公司。
一:struts2概要 以WebWork優(yōu)秀設計思想為核心,吸收了struts1的部分優(yōu)點。
二:struts2詳解 主要就是詳解struts2與struts1之間的區(qū)別,以及為什么要采用webwork重新設計新框架,以及吸收了struts1的哪部分優(yōu)點。
首先將區(qū)別:- 最大的區(qū)別是與servlet成功解耦,不在依賴容器來初始化HttpServletRequest和HttpServletResponse
struts1里依賴的核心控制器為ActionServlet而struts2依賴ServletDispatcher,一個是servlet一個是filter,正是采用了filter才不至于和servlet耦合,所有的數據 都是通過攔截器來實現(xiàn),如下圖顯示:

- web層表現(xiàn)層的豐富,struts2已經可以使用jsp、velocity、freemarker
- 線程模式方面:struts1的action是單例模式而且必須是線程安全或同步的,是struts2的action對每一個請求都產生一個新的實例,因此沒有線程安全問 題。
- 封裝請求參數:是struts1采用ActionForm封裝請求參數,都必須繼承ActionForm基類,而struts2通過bean的屬性封裝,大大降低了耦合。
- 類型轉換:struts1封裝的ActionForm都是String類型,采用Commons- Beanutils進行類型轉換,每個類一個轉換器;struts2采用OGNL進行類型轉 換,支持基本數據類型和封裝類型的自動轉換。
- 數據校驗:struts1在ActionForm中重寫validate方法;struts2直接重寫validate方法,直接在action里面重寫即可,不需要繼承任何基類,實際的調用順序是,validate()-->execute(),會在執(zhí)行execute之前調用validate,也支持xwork校驗框架來校驗。
其次,講一下為什么要采用webwork來重新設計struts2
首先的從核心控制器談起,struts2的FilterDispatcher,這里我們知道是一個filter而不是一個servlet,講到這里很多人還不是很清楚web.xml里它們之間的聯(lián)系,先簡短講一下它們的加載順序,context-param(應用范圍的初始化參數)-->listener(監(jiān)聽應用端的任何修改通知)-->filter(過濾)-->servlet。
filter在執(zhí)行servlet之間就以及調用了,所以才有可能解脫完全依賴servlet的局面,那我們來看看這個filter做了什么事情:
/** * Process an action or handle a request a static resource.
* <p/>
* The filter tries to match the request to an action mapping.
* If mapping is found, the action processes is delegated to the dispatcher's serviceAction method.
* If action processing fails, doFilter will try to create an error page via the dispatcher.
* <p/>
* Otherwise, if the request is for a static resource,
* the resource is copied directly to the response, with the appropriate caching headers set.
* <p/>
* If the request does not match an action mapping, or a static resource page,
* then it passes through.
*
* @see javax.servlet.Filter#doFilter(javax.servlet.ServletRequest, javax.servlet.ServletResponse, javax.servlet.FilterChain)
*/
public void doFilter(ServletRequest req, ServletResponse res, FilterChain chain) throws IOException, ServletException {
HttpServletRequest request = (HttpServletRequest) req;
HttpServletResponse response = (HttpServletResponse) res;
ServletContext servletContext = getServletContext();
String timerKey = "FilterDispatcher_doFilter: ";
try {
// FIXME: this should be refactored better to not duplicate work with the action invocation
ValueStack stack = dispatcher.getContainer().getInstance(ValueStackFactory.class).createValueStack();
ActionContext ctx = new ActionContext(stack.getContext());
ActionContext.setContext(ctx);
UtilTimerStack.push(timerKey);
request = prepareDispatcherAndWrapRequest(request, response);
ActionMapping mapping;
try {
mapping = actionMapper.getMapping(request, dispatcher.getConfigurationManager());
} catch (Exception ex) {
log.error("error getting ActionMapping", ex);
dispatcher.sendError(request, response, servletContext, HttpServletResponse.SC_INTERNAL_SERVER_ERROR, ex);
return;
}
if (mapping == null) {
// there is no action in this request, should we look for a static resource?
String resourcePath = RequestUtils.getServletPath(request);
if ("".equals(resourcePath) && null != request.getPathInfo()) {
resourcePath = request.getPathInfo();
}
if (staticResourceLoader.canHandle(resourcePath)) {
staticResourceLoader.findStaticResource(resourcePath, request, response);
} else {
// this is a normal request, let it pass through
chain.doFilter(request, response);
}
// The framework did its job here
return;
}
dispatcher.serviceAction(request, response, servletContext, mapping);//過濾用戶請求,攔截器執(zhí)行,把對應的action請求轉到業(yè)務action執(zhí)行 }
finally {
try {
ActionContextCleanUp.cleanUp(req);
} finally {
UtilTimerStack.pop(timerKey);
}
}
}
對應的action參數由攔截器獲取。
解耦servlet是struts2采用webwork思路的最重要的一個原因,也迎合了整個技術的一個發(fā)展方向,解耦一直貫穿于整個框架。
JVM specification對JVM內存的描述
首先我們來了解JVM specification中的JVM整體架構。如下圖:

主要包括兩個子系統(tǒng)和兩個組件: Class loader(類裝載器) 子系統(tǒng),Execution engine(執(zhí)行引擎) 子系統(tǒng);Runtime data area (運行時數據區(qū)域)組件, Native interface(本地接口)組件。
Class loader子系統(tǒng)的作用 :根據給定的全限定名類名(如 java.lang.Object)來裝載class文件的內容到 Runtime data area中的method area(方法區(qū)域)。Javsa程序員可以extends java.lang.ClassLoader類來寫自己的Class loader。
Execution engine子系統(tǒng)的作用 :執(zhí)行classes中的指令。任何JVM specification實現(xiàn)(JDK)的核心是Execution engine, 換句話說:Sun 的JDK 和IBM的JDK好壞主要取決于他們各自實現(xiàn)的Execution engine的好壞。每個運行中的線程都有一個Execution engine的實例。
Native interface組件 :與native libraries交互,是其它編程語言交互的接口。
Runtime data area 組件:這個組件就是JVM中的內存

Runtime data area 主要包括五個部分:Heap (堆), Method Area(方法區(qū)域), Java Stack(java的棧), Program Counter(程序計數器), Native method stack(本地方法棧)。Heap 和Method Area是被所有線程的共享使用的;而Java stack, Program counter 和Native method stack是以線程為粒度的,每個線程獨自擁有。
Heap
Java程序在運行時創(chuàng)建的所有類實或數組都放在同一個堆中。而一個Java虛擬實例中只存在一個堆空間,因此所有線程都將共享這個堆。每一個java程序獨占一個JVM實例,因而每個java程序都有它自己的堆空間,它們不會彼此干擾。但是同一java程序的多個線程都共享著同一個堆空間,就得考慮多線程訪問對象(堆數據)的同步問題。 (這里可能出現(xiàn)的異常java.lang.OutOfMemoryError: Java heap space)
JVM堆一般又可以分為以下三部分:

Ø Perm
Perm代主要保存class,method,filed對象,這部門的空間一般不會溢出,除非一次性加載了很多的類,不過在涉及到熱部署的應用服務器的時候,有時候會遇到java.lang.OutOfMemoryError : PermGen space 的錯誤,造成這個錯誤的很大原因就有可能是每次都重新部署,但是重新部署后,類的class沒有被卸載掉,這樣就造成了大量的class對象保存在了perm中,這種情況下,一般重新啟動應用服務器可以解決問題。
Ø Tenured
Tenured區(qū)主要保存生命周期長的對象,一般是一些老的對象,當一些對象在Young復制轉移一定的次數以后,對象就會被轉移到Tenured區(qū),一般如果系統(tǒng)中用了application級別的緩存,緩存中的對象往往會被轉移到這一區(qū)間。
Ø Young
Young區(qū)被劃分為三部分,Eden區(qū)和兩個大小嚴格相同的Survivor區(qū),其中Survivor區(qū)間中,某一時刻只有其中一個是被使用的,另外一個留做垃圾收集時復制對象用,在Young區(qū)間變滿的時候,minor GC就會將存活的對象移到空閑的Survivor區(qū)間中,根據JVM的策略,在經過幾次垃圾收集后,任然存活于Survivor的對象將被移動到Tenured區(qū)間。
Method area
在Java虛擬機中,被裝載的class的信息存儲在Method area的內存中。當虛擬機裝載某個類型時,它使用類裝載器定位相應的
class文件,然后讀入這個class文件內容并把它傳輸到虛擬機中。緊接著虛擬機提取其中的類型信息,并將這些信息存儲到方法區(qū)。該類型中的類(靜態(tài))變量同樣也存儲在方法區(qū)中。與Heap 一樣,method area是多線程共享的,因此要考慮多線程訪問的同步問題。比如,假設同時兩個線程都企圖訪問一個名為Lava的類,而這個類還沒有內裝載入虛擬機,那么,這時應該只有一個線程去裝載它,而另一個線程則只能等待。 (這里可能出現(xiàn)的異常java.lang.OutOfMemoryError: PermGen full)
Java stack
Java stack以幀為單位保存線程的運行狀態(tài)。虛擬機只會直接對Java stack執(zhí)行兩種操作:以幀為單位的壓棧或出棧。每當線程調用一個方法的時候,就對當前狀態(tài)作為一個幀保存到
java stack中(壓棧);當一個方法調用返回時,從java stack彈出一個幀(出棧)。棧的大小是有一定的限制,這個可能出現(xiàn)StackOverFlow問題。 下面的程序可以說明這個問題。
public class TestStackOverFlow {
public static void main(String[] args) {
Recursive r = new Recursive();
r.doit(10000);
// Exception in thread "main" java.lang.StackOverflowError
}
}
class Recursive {
public int doit(int t) { if (t <= 1) { return 1;
}
return t + doit(t - 1);
}
}
Program counter
每個運行中的Java程序,每一個線程都有它自己的PC寄存器,也是該線程啟動時創(chuàng)建的。PC寄存器的內容總是指向下一條將被執(zhí)行指令的餓“地址”,這里的“地址”可以是一個本地指針,也可以是在方法區(qū)中相對應于該方法起始指令的偏移量。
Native method stack
對于一個運行中的Java程序而言,它還能會用到一些跟本地方法相關的數據區(qū)。當某個線程調用一個本地方法時,它就進入了一個全新的并且不再受虛擬機限制的世界。本地方法可以通過本地方法接口來訪問虛擬機的運行時數據區(qū),不止與此,它還可以做任何它想做的事情。比如,可以調用寄存器,或在操作系統(tǒng)中分配內存等。總之,本地方法具有和JVM相同的能力和權限。 (這里出現(xiàn)JVM無法控制的內存溢出問題native heap OutOfMemory )
JVM提供了相應的參數來對內存大小進行配置。

正如上面描述,JVM中堆被分為了3個大的區(qū)間,同時JVM也提供了一些選項對Young,Tenured的大小進行控制。
Ø Total Heap
-Xms :指定了JVM初始啟動以后初始化內存
-Xmx:指定JVM堆得最大內存,在JVM啟動以后,會分配-Xmx參數指定大小的內存給JVM,但是不一定全部使用,JVM會根據-Xms參數來調節(jié)真正用于JVM的內存
-Xmx -Xms之差就是三個Virtual空間的大小
Ø Young Generation
-XX:NewRatio=8意味著tenured 和 young的比值8:1,這樣eden+2*survivor=1/9
堆內存
-XX:SurvivorRatio=32意味著eden和一個survivor的比值是32:1,這樣一個Survivor就占Young區(qū)的1/34.
-Xmn 參數設置了年輕代的大小
Ø Perm Generation
-XX:PermSize=16M -XX:MaxPermSize=64M
Thread Stack
-XX:Xss=128K
1.數據量大以及訪問量很大的表,必須建立索引
2.不要在建立了索引的字段上做以下操作: ◆避免對索引字段進行計算操作
◆避免在索引列上使用IS NULL和IS NOT NULL
◆避免建立索引的列中使用空值
3.避免復雜的操作:
◆sql語句里出現(xiàn)多重查詢嵌套
◆避免建立過多的表關聯(lián),較少關聯(lián)關系
4.減少模糊查詢:避免使用like語句,盡量把結果比較放到應用服務器端,通過java代碼過濾5.WHERE的使用
◆避免對where條件采用計算
◆避免在where條件中使用in,not in,or或則havin,可以使用 exist 和not exist代替 in和not in
◆不要以字符格式聲明數字,要以數字格式聲明字符值,否則索引將失效
6.采用臨時表
數據庫端性能非常低- 優(yōu)化數據庫服務器端的配置參數
- 應用服務器端數據連接池的配置參數修改
- 應用服務器端的sql審核,建立更好的索引以及修改不好的sql語句:關聯(lián)表過多,查詢的數據量過大,表設計不合理等
- 應用服務器端拆解過大的表,分為多張表,甚至把一個數據庫分為多個數據庫
- 數據庫服務器端拆解為讀/寫分離,Master/Slave方式,一臺寫主機對應兩臺或則多臺讀的備用機器
應用服務器端- 訪問壓力過大,1臺機器不能承受,該為多臺機器,應用服務器配置為集群模式
1. 多線程概念:
線程是指進程中的一個執(zhí)行流程,一個進程中可以運行多個線程。比如java.exe進程中可以運行很多線程。線程總是屬于某個進程,進程中的多個線程共享進程的內存。
- 多線程的實現(xiàn)方式和啟動
- 多線程是依靠什么方式解決資源競爭
- 多線程的各種狀態(tài)以及優(yōu)先級
- 多線程的暫停方式
2. 多線程詳解 1)多線程的實現(xiàn)方式和啟動:- 繼承Thread和是實現(xiàn)Runnable接口,重寫run方法
- 啟動只有一種方式:通過start方法,虛擬機會調用run方法
2) 多線程依靠什么解決資源競爭- 鎖機制:分為對象鎖和類鎖,在多個線程調用的情況,每個對象鎖都是唯一的,只有獲取了鎖才能調用synchronized方法
- synchronize同步:分為同步方法和同步方法塊
- 什么時候獲取鎖:每次調用到synchronize方法,這個時候去獲取鎖資源,如果線程獲取到鎖則別的線程只有等到同步方法介紹后,釋放鎖后,別的線程 才能繼續(xù)使用
3)線程的幾種狀態(tài)- 主要分為:新狀態(tài)(還沒有調用start方法),可執(zhí)行狀態(tài)(調用start方法),阻塞狀態(tài),死亡狀態(tài)
默認優(yōu)先級為normal(5),優(yōu)先級數值在1-10之間
4) 多線程的暫停方式- sleep:睡眠單位為毫秒
- wait,waitAll,notify,notifyAll,wait等待,只有通過wait或者waitAll喚醒
- yield:cpu暫時停用
- join
- HashSet概要:
- 采用HashMap存儲,key直接存取值,value存儲一個object
- 存儲的key值是唯一的
- HashSet中元素的順序是隨機的,包括添加(add())和輸出都是無序的
代碼就不具體詳解了,主要就是通過封裝HashMap組成。
1.Hashtable概要:實現(xiàn)Map接口的同步實現(xiàn)- 線程安全
- 不能存儲null到key和value
- HashTable中hash數組默認大小是11,增加的方式是 old*2+1。HashMap中hash數組的默認大小是16,而且一定是2的指數
區(qū)別 | Hashtable | Hashmap |
繼承、實現(xiàn) | Hashtable extends Dictionaryimplements Map, Cloneable,Serializable | HashMap extends AbstractMap implements Map, Cloneable,Serializable |
線程同步 | 已經同步過的可以安全使用 | 未同步的,可以使用Colletcions進行同步Map Collections.synchronizedMap(Map m) |
對null的處理
| Hashtable table = new Hashtable(); table.put(null, "Null"); table.put("Null", null); table.contains(null); table.containsKey(null); table.containsValue(null); 后面的5句話在編譯的時候不會有異常,可在運行的時候會報空指針異常具體原因可以查看源代碼 public synchronized V put(K key, V value) { // Make sure the value is not null if (value == null) { throw new NullPointerException(); } | HashMap map = new HashMap();
map.put(null, "Null"); map.put("Null", null); map.containsKey(null); map.containsValue(null); 以上這5條語句無論在編譯期,還是在運行期都是沒有錯誤的. 在HashMap中,null可以作為鍵,這樣的鍵只有一個;可以有一個或多個鍵所對應的值為null。當get()方法返回null值時,即可以表示 HashMap中沒有該鍵,也可以表示該鍵所對應的值為null。因此,在HashMap中不能由get()方法來判斷HashMap中是否存在某個鍵,而應該用containsKey()方法來判斷。 |
增長率 | protected void rehash() { int oldCapacity = table.length; Entry[] oldMap = table; int newCapacity = oldCapacity * 2 + 1; Entry[] newMap = new Entry[newCapacity]; modCount++; threshold = (int)(newCapacity * loadFactor); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry old = oldMap[i] ; old != null ; ) { Entry e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = newMap[index]; newMap[index] = e; } } }
| void addEntry(int hash, K key, V value, int bucketIndex) { Entry e = table[bucketIndex]; table[bucketIndex] = new Entry(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
|
哈希值的使用 | HashTable直接使用對象的hashCode,代碼是這樣的: public synchronized booleancontainsKey(Object key) { Entry tab[] = table; int hash = key.hashCode(); int index = (hash & 0x7FFFFFFF) % tab.length; for (Entry e = tab[index] ; e !=null ; e = e.next) { if ((e.hash == hash) && e.key.equals(key)) { return true; } } return false; } | HashMap重新計算hash值,而且用與代替求模 public boolean containsKey(Object key) { Object k = maskNull(key); int hash = hash(k.hashCode()); int i = indexFor(hash, table.length); Entry e = table[i]; while (e != null) { if (e.hash == hash && eq(k, e.key)) return true; e = e.next; } return false; } |