2008年3月31日
#

其實就是關鍵一句話:
window.opener.document.getElementById("XXX").value=“123456”;
例程如下:
http://www.tkk7.com/Files/junglesong/ParentChildWnd20080520140659.rar
類之間關聯的Hibernate表現
在Java程序中,類之間存在多種包含關系,典型的三種關聯關系有:一個類擁有另一個類的成員,一個類擁有另一個類的集合的成員;兩個類相互擁有對象的集合的成員.在Hibernate中,我們可以使用映射文件中的many-to-one, one-to-many, many-to-many來實現它們.這樣的關系在Hibernate中簡稱為多對一,一對多和多對多.
多對一的類代碼
事件與地點是典型的多對一關系,多個事件可以在一個地點發生(時間不同),一個地點可發生多個事件.它們的對應關系是(多)事件對(一)地點.
兩個類的代碼如右:
public class Event{
private String id;
private String name;
private Location location;
}
public class Location{
private String id;
private String name;
}
多對一的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Event"
table="Event_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<many-to-one name="location" column="locationId" class="com.sitinspring.domain.Location"/>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Location"
table="Location_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
</class>
</hibernate-mapping>
多對一的表數據

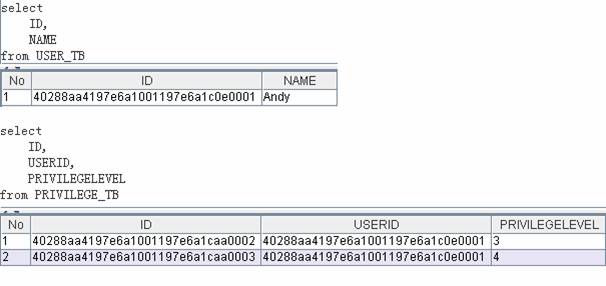
一對多的類代碼
如果一個用戶有多個權限,那么User類和Privilege類就構成了一對多的關系,User類將包含一個Privilege類的集合.
public class User{
private String id;
private String name;
private Set<Privilege> privileges=new LinkedHashSet<Privilege>();
}
public class Privilege{
private String id;
private String userId;
private int privilegeLevel;
}
一對多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="User_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<set name="privileges">
<key column="userId"/>
<one-to-many class="com.sitinspring.domain.Privilege"/>
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Privilege"
table="Privilege_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="userId" column="userId" />
<property name="privilegeLevel" column="privilegeLevel" />
</class>
</hibernate-mapping>
一對多的表數據
多對多
多對多關系 是指兩個類相互擁有對方的集合,如文章和標簽兩個類,一篇文章可能有多個標簽,一個標簽可能對應多篇文章.要實現這種關系需要一個中間表的輔助.
類代碼如右:
public class Article{
private String id;
private String name;
private Set<Tag> tags = new HashSet<Tag>();
}
public class Tag{
private String id;
private String name;
private Set<Article> articles = new HashSet<Article>();
}
多對多的映射文件
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Article" table="ARTICLE_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="tags" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="ARTICLEID" />
<many-to-many column="TAGID" class="com.sitinspring.domain.Tag" />
</set>
</class>
</hibernate-mapping>
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.Tag" table="TAG_TB">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="NAME" />
<set name="articles" table="ARTICLETAG_TB" cascade="all" lazy="false">
<key column="TAGID" />
<many-to-many column="ARTICLEID" class="com.sitinspring.domain.Article" />
</set>
</class>
</hibernate-mapping>
多對多的表數據

源碼下載:
http://www.tkk7.com/Files/junglesong/HibernateMapping20080430203526.rar
Criteria查詢
Hibernate中的Criteria API提供了另一種查詢持久化的方法。它讓你能夠使用簡單的API動態的構建查詢,它靈活的特性通常用于搜索條件的數量可變的情況。
Criteria查詢之所以靈活是因為它可以借助Java語言,在Java的幫助下它擁有超越HQL的功能。Criteria查詢也是Hibernate竭力推薦的一種面向對象的查詢方式。
Criteria查詢的缺點在于只能檢索完整的對象,不支持統計函數,它本身的API也抬高了一定的學習坡度。
Criteria查詢示例代碼
Session session=HibernateUtil.getSession();
Criteria criteria=session.createCriteria(User.class);
// 條件一:名稱以關開頭
criteria.add(Restrictions.like("name", "關%"));
// 條件二:email出現在數組中
String[] arr={"1@2.3","2@2.3","3@2.3"};
criteria.add(Restrictions.in("email", arr));
// 條件三:password等于一
criteria.add(Restrictions.eq("password", "1"));
// 排序條件:按登錄時間升序
criteria.addOrder(Order.asc("lastLoginTime"));
List<User> users=(List<User>)criteria.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
Criteria查詢實際產生的SQL語句
select
this_.ID as ID0_0_,
this_.name as name0_0_,
this_.pswd as pswd0_0_,
this_.email as email0_0_,
this_.lastLoginTime as lastLogi5_0_0_,
this_.lastLoginIp as lastLogi6_0_0_
from
USERTABLE_OKB this_
where
this_.name like '關%'
and this_.email in (
'1@2.3', '2@2.3', '3@2.3'
)
and this_.pswd='1'
order by
this_.lastLoginTime asc
注:參數是手工加上的。
HQL介紹
Hibernate中不使用SQL而是有自己的面向對象查詢語言,該語言名為Hibernate查詢語言(Hibernate Query Language).HQL被有意設計成類似SQL,這樣開發人員可以利用已有的SQL知識,降低學習坡度.它支持常用的SQL特性,這些特性被封裝成面向對象的查詢語言,從某種意義上來說,由HQL是面向對象的,因此比SQL更容易編寫.
本文將逐漸介紹HQL的特性.
查詢數據庫中所有實例
要得到數據庫中所有實例,HQL寫為”from 對象名”即可,不需要select子句,當然更不需要Where子句.代碼如右.
Query query=session.createQuery("from User");
List<User> users=(List<User>)query.list();
for(User user:users){
System.out.println(user);
}
限制返回的實例數
設置查詢的maxResults屬性可限制返回的實例(記錄)數,代碼如右:
Query query=session.createQuery("from User order by name");
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
分頁查詢
分頁是Web開發的常見課題,每種數據庫都有自己特定的分頁方案,從簡單到復雜都有.在Hibernate中分頁問題可以通過設置firstResult和maxResult輕松的解決.
代碼如右:
Query query=session.createQuery("from User order by name");
query.setFirstResult(3);
query.setMaxResults(5);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
條件查詢
條件查詢只要增加Where條件即可.
代碼如右:
Hibernate中條件查詢的實現方式有多種,這種方式的優點在于能顯示完整的SQL語句(包括參數)如下.
select
user0_.ID as ID0_,
user0_.name as name0_,
user0_.pswd as pswd0_,
user0_.email as email0_,
user0_.lastLoginTime as lastLogi5_0_,
user0_.lastLoginIp as lastLogi6_0_
from
USERTABLE_OKB user0_
where
user0_.name like '何%'
public static void fetchByName(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name like'"+prefix+"%'");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
位置參數條件查詢
HQL中也可以象jdbc中PreparedStatement一樣為SQL設定參數,但不同的是下標從0開始.
代碼如右:
public static void fetchByPos(String prefix){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=?");
// 注意下標是從0開始,和jdbc中PreparedStatement從1開始不同
query.setParameter(0, prefix);
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名參數條件查詢
使用位置參數條件查詢最大的不便在于下標與?號位置的對應上,如果參數較多容易導致錯誤.這時采用命名參數條件查詢更好.
使用命名參數時無需知道每個參數的索引位置,這樣就可以節省填充查詢參數的時間.
如果有一個命名參數出現多次,那在每個地方都會設置它.
public static void fetchByNamedParam(){
Session session=HibernateUtil.getSession();
Query query=session.createQuery("from User where name=:name");
query.setParameter("name", "李白");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
}
命名查詢
命名查詢是嵌在XML映射文件中的查詢。通常,將給定對象的所有查詢都放在同一文件中,這種方式可使維護相對容易些。命名查詢語句寫在映射定義文件的最后面。
執行代碼如下:
Session session=HibernateUtil.getSession();
Query query=session.getNamedQuery("user.sql");
List<User> users=(List<User>)query.list();
System.out.println("返回的User實例數為"+users.size());
for(User user:users){
System.out.println(user);
}
HibernateUtil.closeSession(session);
映射文件節選:
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
<query name="user.sql">
<![CDATA[from User where email='2@2.3']]>
</query>
</hibernate-mapping>
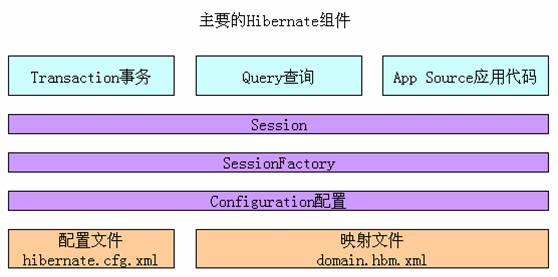
主要的Hibernate組件
Configuration類
Configuration類啟動Hibernate的運行環境部分,用于加載映射文件以及為它們創建一個SessionFacotry。完成這兩項功能后,就可丟棄Configuration類。
// 從hibernate.cfg.xml創建SessionFactory 示例
sessionFactory = new Configuration().configure()
.buildSessionFactory();
SessionFactory類
Hibernate中Session表示到數據庫的連接(不止于此),而SessionFactory接口提供Session類的實例。
SessionFactory實例是線程安全的,通常在整個應用程序中共享。
從Configuration創建SessionFacotry的代碼如右。
// 從hibernate.cfg.xml創建SessionFactory 示例
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session類
Session表示到數據庫的連接,session類的實例是到Hibernate框架的主要接口,使你能夠持久化對象,查詢持久化以及將持久化對象轉換為臨時對象。
Session實例不是線程安全的,只能將其用于應用中的事務和工作單元。
創建Session實例的代碼如右:
SessionFactory sessionFactory = new Configuration().configure()
.buildSessionFactory();
Session session=sessionFactory.openSession();
保存一個對象
用Hibernate持久化一個臨時對象也就是將它保存在Session實例中:
對user實例調用save時,將給該實例分配一個生成的ID值,并持久化該實例,在此之前實例的id是null,之后具體的id由生成器策略決定,如果生成器類型是assignd,Hibernate將不會給其設置ID值。
Flush()方法將內存中的持久化對象同步到數據庫。存儲對象時,Session不會立即將其寫入數據庫;相反,session將大量數據庫寫操作加入隊列,以最大限度的提高性能。
User user=new User(“Andy”,22);
Session session=sessionFatory.openSession();
session.save(user);
session.flush();
session.close();
保存或更新一個對象
Hibernate提供了一種便利的方法用于在你不清楚實例對應的數據在數據庫中的狀態時保存或更新一個對象,也就是說,你不能確定具體是要保存save還是更新update,只能確定需要把對象同步到數據庫中。這個方法就是saveOrUpdate。
Hibernate在持久化時會查看實例的id屬性,如果其為null則判斷此對象是臨時的,在數據庫中找不到對應的實例,其后選擇保存這個對象;而不為空時則意味著對象已經持久化,應該在數據庫中更新該對象,而不是將其插入。
User user=。。。;
Session session=sessionFatory.openSession();
session.saveOrUpdate(user);
Session.flush();
session.close();
刪除一個對象
從數據庫刪除一個對象使用session的delete方法,執行刪除操作后,對象實例依然存在,但數據庫中對應的記錄已經被刪除。
User user=。。。;
Session session=sessionFatory.openSession();
session.delete(user);
session.flush();
session.close();
以ID從數據庫中取得一個對象
如果已經知道一個對象的id,需要從數據庫中取得它,可以使用Session的load方法來返回它。代碼如右.
注意此放在id對應的記錄不存在時會拋出一個HibernateException異常,它是一個非檢查性異常。對此的正確處理是捕獲這個異常并返回一個null。
使用此想法如果采用默認的懶惰加載會導致異常,對此最簡單的解決方案是把默認的懶惰加載屬性修改為false。如右:
User user=(User)session.load(User.class,"008");
session.close();
-----------------------------------------------
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
。。。。
</class>
</hibernate-mapping>
檢索一批對象
檢索一批對象需要使用HQL,session接口允許你創建Query對象以檢索持久化對象,HQL是面向對象的,你需要針對類和屬性來書寫你的HQL而不是表和字段名。
從數據庫中查詢所有用戶對象如下:
Query query=session.createQuery(“from User”);// 注意這里User是類名,from前沒有select。
List<User> users=(List<User>)query.list();
從數據庫中查詢名為“Andy”的用戶如下:
String name=“Andy”;
Query query=session.createQuery(“from User where name=‘”+name+”’”);
List<User> users=(List<User>)query.list();
以上方法類似于Statement的寫法,你還可以如下書寫:
Query query=session.createQuery("from User user where user.name = :name");
query.setString("name", “Andy");
List<User> users=(List<User>)query.list();
Hibernate的映射文件
映射文件也稱映射文檔,用于向Hibernate提供關于將對象持久化到關系數據庫中的信息.
持久化對象的映射定義可全部存儲在同一個映射文件中,也可將每個對象的映射定義存儲在獨立的文件中.后一種方法較好,因為將大量持久化類的映射定義存儲在一個文件中比較麻煩,建議采用每個類一個文件的方法來組織映射文檔.使用多個映射文件還有一個優點:如果將所有映射定義都存儲到一個文件中,將難以調試和隔離特定類的映射定義錯誤.
映射文件的命名規則是,使用持久化類的類名,并使用擴展名hbm.xml.
映射文件需要在hibernate.cfg.xml中注冊,最好與領域對象類放在同一目錄中,這樣修改起來很方便.
領域對象和類
public class User{
// ID
private String id;
// 名稱
private String name;
// 密碼
private String password;
// 郵件
private String email;
// 上次登錄時間
private String lastLoginTime;
// 上次登錄ip
private String lastLoginIp;
public User(String name,String password,String email){
this.name=name;
this.password=password;
this.email=email;
}
}
<?xml version="1.0"?><!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"><hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class></hibernate-mapping>
hibernate.cfg.xml中的映射文件設置
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數據源設置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數據庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創建表.這個選項在第一次啟動程序時放開,以后切記關閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化類的映射文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
映射文件物理位置示例
映射文件的基本結構
映射定義以hibernate-mapping元素開始, package屬性設置映射中非限定類名的默認包.設置這個屬性后,對于映射文件中列出的其它持久化類,只需給出類名即可.要引用指定包外的持久化類,必須在映射文件中提供全限定類名.
在hibernate-mapping標簽之后是class標簽.class標簽開始指定持久化類的映射定義.table屬性指定用于存儲對象狀態的關系表.class元素有很多屬性,下面將逐個介紹.
ID
Id元素描述了持久化類的主碼以及他們的值如何生成.每個持久化類必須有一個ID元素,它聲明了關系表的主碼.如右:
Name屬性指定了持久化類中用于保存主碼值的屬性,該元素表明,User類中有一個名為id的屬性.如果主碼字段與對象屬性不同,則可以使用column屬性.
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
生成器
生成器創建持久化類的主碼值.Hibernate提供了多個生成器實現,它們采用了不同的方法來創建主碼值.有的是自增長式的,有點創建十六進制字符串, 還可以讓外界生成并指定對象ID,另外還有一種Select生成器你那個從數據庫觸發器trigger檢索值來獲得主碼值.
右邊使用了用一個128-bit的UUID算法生成字符串類型的標識符, 這在一個網絡中是唯一的(使用了IP地址)。UUID被編碼為一個32位16進制數字的字符串 .這對字段類型是字符串的id字段特別有效.UUID作為ID字段主鍵是非常合適的,比自動生成的long類型id方式要好。
UUID示例
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
自動增長的id
<id name="id" column="ID" type="long">
<generator class="native"/>
</id>
屬性
在映射定義中,property元素與持久化對象的一個屬性對應,name表示對象的屬性名,column表示對應表中的列(字段),type屬性指定了屬性的對象類型,如果type被忽略的話,Hibernate將使用運行階段反射機制來判斷類型.
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
獲取Hibernate
在創建Hibernate項目之前,我們需要從網站獲得最新的Hibernate版本。Hibernate主頁是www.hibernate.org,找到其菜單中的download連接,選擇最新的Hibernate版本即可。下載后將其解開到一個目錄中。
右邊是解開后的主要目錄。其中最重要的是hibernate.jar,它包含全部框架代碼;lib目錄,包括Hibernate的所有依賴庫;doc目錄,包括JavDocs和參考文檔。
Hibernate的配置文件
Hibernate能夠與從應用服務器(受控環境,如Tomcat,Weblogic,JBoss)到獨立的應用程序(非受控環境,如獨立應用程序)的各種環境和諧工作,這在一定程度上要歸功于其配置文件hibernate.cfg.xml,通過特定的設置Hibernate就能與各種環境配合。右邊是hibernate.cfg.xml的一個示例。
配置Hibernate的所有屬性是一項艱巨的任務,下面將依此介紹Hibernate部署將用到的基本配置。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數據源設置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數據庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創建表.這個選項在第一次啟動程序時放開,以后切記關閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
<!-- 持久化類的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
使用Hibernate管理的JDBC連接
右邊配置文件中的Database connection settings 部分制定了Hibernate管理的JDBC連接, 這在非受控環境如桌面應用程序中很常見。
其中各項屬性為:
connection.driver_class:用于特定數據庫的JDBC連接類
connection.url:數據庫的完整JDBC URL
connection.username:用于連接到數據庫的用戶名
connection.password:用戶密碼
這種方案可用于非受控環境和基本測試,但不宜在生產環境中使用。
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- Database connection settings -->
<property name="connection.driver_class">org.hsqldb.jdbcDriver</property>
<property name="connection.url">jdbc:hsqldb:hsql://localhost</property>
<property name="connection.username">sa</property>
<property name="connection.password"></property>
<!-- JDBC connection pool (use the built-in) -->
<property name="connection.pool_size">1</property>
<!-- SQL dialect -->
<property name="dialect">org.hibernate.dialect.HSQLDialect</property>
<!-- Enable Hibernate's automatic session context management -->
<property name="current_session_context_class">thread</property>
。。。。。。。。
</session-factory>
</hibernate-configuration>
使用JNDI 數據源
在受控環境中,我們可以使用容器提供的數據源,這將使數據庫訪問更加快捷,右邊就是使用Tomcat提供的數據源的配置部分。
附:Server.Xml中的數據源設置
<Context path="/MyTodoes" reloadable="true" docBase="E:\Program\Programs\MyTodoes" workDir="E:\Program\Programs\MyTodoes\work" >
<Resource name="jdbc/myoracle" auth="Container"
type="javax.sql.DataSource" driverClassName="oracle.jdbc.OracleDriver"
url="jdbc:oracle:thin:@192.168.104.173:1521:orcl"
username="hy" password="123456" maxActive="20" maxIdle="10"
maxWait="-1"/>
</Context>
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數據源設置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數據庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
</hibernate-configuration>
數據庫方言
Dialect屬性能告知Hibernate執行特定的操作如分頁時需要使用那種SQL方言,如MySql的分頁方案和Oracle的大相徑庭,如設置錯誤或沒有設置一定會導致問題。
附錄:常見的數據庫方言
DB2 :org.hibernate.dialect.DB2Dialect
MySQL :org.hibernate.dialect.MySQLDialect
Oracle (any version) :org.hibernate.dialect.OracleDialect
Oracle 9i/10g :org.hibernate.dialect.Oracle9Dialect
Microsoft SQL Server :org.hibernate.dialect.SQLServerDialect
Sybase Anywhere :org.hibernate.dialect.SybaseAnywhereDialect
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數據源設置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
<!-- SQL方言,org.hibernate.dialect.OracleDialect適合所有Oracle數據庫 -->
<property name="dialect">
org.hibernate.dialect.OracleDialect
</property>
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
</hibernate-configuration>
其它屬性
show_sql:它可以在程序運行過程中顯示出真正執行的SQL語句來,建議將這個屬性始終打開,它將有益于錯誤診斷。
format_sql:將這個屬性設置為true能將輸出的SQL語句整理成規范的形狀,更方便用于查看SQL語句。
hbm2ddl.auto:將其設置為create能在程序啟動是根據類映射文件的定義創建實體對象對應的表,而不需要手動去建表,這在程序初次安裝時很方便。
如果表已經創建并有數據,切記關閉這個屬性,否則在創建表時也會清除掉原有的數據,這也許會導致很嚴重的后果。
從后果可能帶來的影響來考慮,在用戶處安裝完一次后就應該刪除掉這個節點
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
。。。。。。
<!-- 顯示SQL語句 -->
<property name="show_sql">true</property>
<!-- SQL語句整形 -->
<property name="format_sql">true</property>
<!-- 啟動時創建表.這個選項在第一次啟動程序時放開,以后切記關閉 -->
<!-- <property name="hbm2ddl.auto">create</property> -->
。。。。。。
</hibernate-configuration>
映射定義
在hibernate.cfg.xml中,還有一個重要部分就是映射定義,這些文件用于向Hibernate提供關于將對象持久化到關系數據庫的信息。
一般來說,領域層有一個領域對象就有一個映射文件,建議將它們放在同一目錄(domain)下以便查閱和修改,映射文件的命名規則是:持久化類的類名+.hbm.xml
<?xml version='1.0' encoding='utf-8'?>
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory name="java:comp/env/hibernate/SessionFactory">
<!-- JNDI數據源設置 -->
<property name="connection.datasource">
java:comp/env/jdbc/myoracle
</property>
。。。。。。
<!-- 持久化類的配置文件 -->
<mapping resource="com/sitinspring/domain/User.hbm.xml" />
<mapping resource="com/sitinspring/domain/Privilege.hbm.xml" />
<mapping resource="com/sitinspring/domain/Article.hbm.xml" />
<mapping resource="com/sitinspring/domain/Record.hbm.xml" />
</session-factory>
</hibernate-configuration>
本文假定讀者已經熟知以下知識
能夠熟練使用JDBC創建Java應用程序;
創建過以數據庫為中心的應用
理解基本的關系理論和結構化查詢語言SQL (Strutured Query Language)
Hibernate
Hibernate是一個用于開發Java應用的對象/關系映射框架。它通過在數據庫中為開發人員存儲應用對象,在數據庫和應用之間提供了一座橋梁,開發人員不必編寫大量的代碼來存儲和檢索對象,省下來的精力更多的放在問題本身上。
持久化與關系數據庫
持久化的常見定義:使數據的存活時間超過創建該數據的進程的存活時間。數據持久化后可以重新獲得它;如果外界進程沒有修改它,它將與持久化之前相同。對于一般應用來說,持久化指的是將數據存儲在關系數據庫中。
關系數據庫是為管理數據而設計的,它在存儲數據方面很流行,這主要歸功于易于使用SQL來創建和訪問。
關系數據庫使用的模型被稱為關系模型,它使用二維表來表示數據。這種數據邏輯視圖表示了用戶如何看待包含的數據。表可以通過主碼和外碼相互關聯。主碼唯一的標識了表中的一行,而外碼是另一個表中的主碼。
對象/關系阻抗不匹配
關系數據庫是為管理數據設計的,它適合于管理數據。然而,在面向對象的應用中,將對象持久化為關系模型可能會遇到問題。這個問題的根源是因為關系數據庫管理數據,而面向對象的應用是為業務問題建模而設計的。由于這兩種目的不同,要使這兩個模型協同工作可能具有挑戰性。這個問題被稱為 對象/關系阻抗不匹配(Object/relational impedance mismatch)或簡稱為阻抗不匹配
阻抗不匹配的幾個典型方面
在應用中輕易實現的對象相同或相等,這樣的關系在關系數據庫中不存在。
在面向對象語言的一項核心特性是繼承,繼承很重要,因為它允許創建問題的精確模型,同時可以在層次結構中自上而下的共享屬性和行為。而關系數據庫不支持繼承的概念。
對象之間可以輕易的實現一對一,一對多和多對多的關聯關系,而數據庫并不理解這些,它只知道外碼指向主碼。
對象/關系映射
前頁列舉了一些阻抗不匹配的問題,當然開發人員是可以解決這些問題,但這一過程并不容易。對象/關系映射(Object/Relational Mapping)就是為解決這些問題而開發的。
ORM在對象模型和關系模型之間架起了一座橋梁,讓應用能夠直接持久化對象,而不要求在對象和關系之間進行轉換。Hibernate就是ORM工具中最成功的一種。它的主要優點是簡單,靈活,功能完備和高效。
Hibernate的優點之一:簡單
Hibernate不像有些持久化方案那樣需要很多的類和配置屬性,它只需要一個運行階段配置文件已經為每個要持久化的應用對象指定一個XML格式的映射文件。
映射文件可以很短,讓框架決定映射的其它內容,也可以通過制定額外的屬性,如屬性的可選列名,向框架提供更多信息。如右就是一個映射文檔的示例。
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 3.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="org.hibernate.auction">
<class name="com.sitinspring.domain.User"
table="USERTABLE_OKB" lazy="false">
<id name="id" column="ID" >
<generator class="uuid.hex"/>
</id>
<property name="name" column="name" />
<property name="password" column="pswd" />
<property name="email" column="email" />
<property name="lastLoginTime" column="lastLoginTime" />
<property name="lastLoginIp" column="lastLoginIp" />
</class>
</hibernate-mapping>
Hibernate的優點之二:功能完備
Hibernate支持所有的面向對象特性,包括繼承,自定義對象類型和集合。它可以讓你創建模型時不必考慮持久層的局限性。
Hibernate提供了一個名為HQL的查詢語言,它與SQL非常相似,只是用對象屬性名代替了表的列。很多通過SQL實現的常用功能都能用HQL實現。
Hibernate的優點之三:高效
Hibernate使用懶惰加載提高了性能,在Hibernate并不在加載父對象時就加載對象集合,而只在應用需要訪問時才生成。這就避免了檢索不必要的對象而影響性能。
Hibernate允許檢索主對象時選擇性的禁止檢索關聯的對象,這也是一項改善性能的特性。
對象緩存在提高應用性能方面也發揮了很大的作用。Hibernate支持各種開源和緩存產品,可為持久化類或持久化對象集合啟用緩存。
總結
在同一性,繼承和關聯三方面,對象模型和關系模型存在著阻抗不匹配,這是眾多ORM框架致力解決的問題,hibernate是這些方案中最成功的一個,它的主要優點是簡單,靈活,功能完備和高效。
使用Hibernate不要求領域對象實現特別的接口或使用應用服務器,它支持集合,繼承,自定義數據類型,并攜帶一種強大的查詢語言HQL,能減少很多持久化方面的工作量,使程序員能把更多精力轉移到問題本身上來。
C/S 架構
C/S 架構是一種典型的兩層架構,其全程是Client/Server,即客戶端服務器端架構,其客戶端包含一個或多個在用戶的電腦上運行的程序,而服務器端有兩種,一種是數據庫服務器端,客戶端通過數據庫連接訪問服務器端的數據;另一種是Socket服務器端,服務器端的程序通過Socket與客戶端的程序通信。
C/S 架構也可以看做是胖客戶端架構。因為客戶端需要實現絕大多數的業務邏輯和界面展示。這種架構中,作為客戶端的部分需要承受很大的壓力,因為顯示邏輯和事務處理都包含在其中,通過與數據庫的交互(通常是SQL或存儲過程的實現)來達到持久化數據,以此滿足實際項目的需要。
C/S 架構的優缺點
優點:
1.C/S架構的界面和操作可以很豐富。
2.安全性能可以很容易保證,實現多層認證也不難。
3.由于只有一層交互,因此響應速度較快。
缺點:
1.適用面窄,通常用于局域網中。
2.用戶群固定。由于程序需要安裝才可使用,因此不適合面向一些不可知的用戶。
3.維護成本高,發生一次升級,則所有客戶端的程序都需要改變。
B/S架構
B/S架構的全稱為Browser/Server,即瀏覽器/服務器結構。Browser指的是Web瀏覽器,極少數事務邏輯在前端實現,但主要事務邏輯在服務器端實現,Browser客戶端,WebApp服務器端和DB端構成所謂的三層架構。B/S架構的系統無須特別安裝,只有Web瀏覽器即可。
B/S架構中,顯示邏輯交給了Web瀏覽器,事務處理邏輯在放在了WebApp上,這樣就避免了龐大的胖客戶端,減少了客戶端的壓力。因為客戶端包含的邏輯很少,因此也被成為瘦客戶端。
B/S架構的優缺點
優點:
1)客戶端無需安裝,有Web瀏覽器即可。
2)BS架構可以直接放在廣域網上,通過一定的權限控制實現多客戶訪問的目的,交互性較強。
3)BS架構無需升級多個客戶端,升級服務器即可。
缺點:
1)在跨瀏覽器上,BS架構不盡如人意。
2)表現要達到CS程序的程度需要花費不少精力。
3)在速度和安全性上需要花費巨大的設計成本,這是BS架構的最大問題。
4)客戶端服務器端的交互是請求-響應模式,通常需要刷新頁面,這并不是客戶樂意看到的。(在Ajax風行后此問題得到了一定程度的緩解)
String的特殊之處
String是Java編程中很常見的一個類,這個類的實例是不可變的(immutable ).為了提高效率,JVM內部對其操作進行了一些特殊處理,本文就旨在于幫助大家辨析這些特殊的地方.
在進入正文之前,你需要澄清這些概念:
1) 堆與棧
2) 相同與相等,==與equals
3) =的真實意義.
棧與堆
1. 棧(stack)與堆(heap)都是Java用來在內存中存放數據的地方。與C++不同,Java自動管理棧和堆,程序員不能直接地設置棧或堆。每個函數都有自己的棧,而一個程序只有一個堆.
2. 棧的優勢是,存取速度比堆要快,僅次于直接位于CPU中的寄存器。但缺點是,存在棧中的數據大小與生存期必須是確定的,缺乏靈活性。另外,棧數據可以共享,詳見第3點。堆的優勢是可以動態地分配內存大小,生存期也不必事先告訴編譯器,Java的垃圾收集器會自動收走這些不再使用的數據。但缺點是,由于要在運行時動態分配內存,存取速度較慢。 3. Java中的數據類型有兩種。 一種是基本類型(primitive types), 共有8種,即int, short, long, byte, float, double, boolean, char(注意,并沒有string的基本類型)。這種類型的定義是通過諸如int a = 3; long b = 255L;的形式來定義的,稱為自動變量。值得注意的是,自動變量存的是字面值,不是類的實例,即不是類的引用,這里并沒有類的存在。如int a = 3; 這里的a是一個指向int類型的引用,指向3這個字面值。這些字面值的數據,由于大小可知,生存期可知(這些字面值固定定義在某個程序塊里面,程序塊退出后,字段值就消失了),出于追求速度的原因,就存在于棧中。 另外,棧有一個很重要的特殊性,就是存在棧中的數據可以共享。假設我們同時定義 int a = 3; int b = 3; 編譯器先處理int a = 3;首先它會在棧中創建一個變量為a的引用,然后查找有沒有字面值為3的地址,沒找到,就開辟一個存放3這個字面值的地址,然后將a指向3的地址。接著處理int b = 3;在創建完b的引用變量后,由于在棧中已經有3這個字面值,便將b直接指向3的地址。這樣,就出現了a與b同時均指向3的情況。 特別注意的是,這種字面值的引用與類對象的引用不同。假定兩個類對象的引用同時指向一個對象,如果一個對象引用變量修改了這個對象的內部狀態,那么另一個對象引用變量也即刻反映出這個變化。相反,通過字面值的引用來修改其值,不會導致另一個指向此字面值的引用的值也跟著改變的情況。如上例,我們定義完a與 b的值后,再令a=4;那么,b不會等于4,還是等于3。在編譯器內部,遇到a=4;時,它就會重新搜索棧中是否有4的字面值,如果沒有,重新開辟地址存放4的值;如果已經有了,則直接將a指向這個地址。因此a值的改變不會影響到b的值。 另一種是包裝類數據,如Integer, String, Double等將相應的基本數據類型包裝起來的類。這些類數據全部存在于堆中,Java用new()語句來顯示地告訴編譯器,在運行時才根據需要動態創建,因此比較靈活,但缺點是要占用更多的時間。
相同與相等,==與equals
在Java中,相同指的是兩個變量指向的地址相同,地址相同的變量自然值相同;而相等是指兩個變量值相等,地址可以不同.
相同的比較使用==,而相等的比較使用equals.
對于字符串變量的值比較來說,我們一定要使用equals而不是==.
=的真實意義
=即賦值操作,這里沒有問題,關鍵是這個值有時是真正的值,有的是地址,具體來說會根據等號右邊的部分而變化.
如果是基本類型(八種),則賦值傳遞的是確定的值,即把右邊變量的值傳遞給左邊的變量.
如果是類類型,則賦值傳遞的是變量的地址,即把等號左邊的變量地址指向等號右邊的變量地址.
指出下列代碼的輸出
String andy="andy";
String bill="andy";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
String str=“andy”的機制分析
上頁代碼的輸出是andy和bill地址相同.
當通過String str=“andy”;的方式定義一個字符串時,JVM先在棧中尋找是否有值為“andy”的字符串,如果有則將str指向棧中原有字符串的地址;如果沒有則創建一個,再將str的地址指向它. String andy=“andy”這句代碼走的是第二步,而String bill=“andy”走的是第一步,因此andy和bill指向了同一地址,故而andy==bill,andy和bill地址相等,所以輸出是andy和bill地址相同.
這樣做能節省空間—少創建一個字符串;也能節省時間—定向總比創建要省時.
指出下列代碼的輸出
String andy="andy";
String bill="andy";
bill="bill";
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
輸出及解釋
上頁代碼的輸出是:andy和bill地址不同
當執行bill=“bill”一句時,外界看來好像是給bill變換了一個新值bill,但JVM的內部操作是把棧變量bill的地址重新指向了棧中一塊值為bill的新地址,這是因為字符串的值是不可變的,要換值(賦值操作)只有將變量地址重新轉向. 這樣andy和bill的地址在執行bill=“bill”一句后就不一樣了,因此輸出是andy和bill地址不同.
指出下列代碼的輸出
String andy=new String("andy");
String bill=new String("andy");
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出及機制分析
andy和bill地址不同
andy和bill值相等
我們知道new操作新建出來的變量一定處于堆中,字符串也是一樣.
只要是用new()來新建對象的,都會在堆中創建,而且其字符串是單獨存值的,即每個字符串都有自己的值,自然地址就不會相同.因此輸出了andy和bill地址不同.
equals操作比較的是值而不是地址,地址不同的變量值可能相同,因此輸出了andy和bill值相等.
指出下列代碼的輸出
String andy=new String("andy");
String bill=new String(andy);
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出
andy和bill地址不同
andy和bill值相等
道理仍和第八頁相同.只要是用new()來新建對象的,都會在堆中創建,而且其字符串是單獨存值的,即每個字符串都有自己的值,自然地址就不會相同.
指出下列代碼的輸出
String andy="andy";
String bill=new String(“Bill");
bill=andy;
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出及解析
andy和bill地址相同
andy和bill值相等
String bill=new String(“Bill”)一句在棧中創建變量bill,指向堆中創建的”Bill”,這時andy和bill地址和值都不相同;而執行bill=andy;一句后,棧中變量bill的地址就指向了andy,這時bill和andy的地址和值都相同了.而堆中的”Bill”則沒有指向它的指針,此后這塊內存將等待被垃圾收集.
指出下列代碼的輸出
String andy="andy";
String bill=new String("bill");
andy=bill;
// 地址比較
if(andy==bill){
System.out.println("andy和bill地址相同");
}
else{
System.out.println("andy和bill地址不同");
}
// 值比較
if(andy.equals(bill)){
System.out.println("andy和bill值相等");
}
else{
System.out.println("andy和bill值不等");
}
輸出
andy和bill地址相同
andy和bill值相等
道理同第十二頁
結論
使用諸如String str = “abc”;的語句在棧中創建字符串時時,str指向的字符串不一定會被創建!唯一可以肯定的是,引用str本身被創建了。至于這個引用到底是否指向了一個新的對象,必須根據上下文來考慮,如果棧中已有這個字符串則str指向它,否則創建一個再指向新創建出來的字符串. 清醒地認識到這一點對排除程序中難以發現的bug是很有幫助的。
使用String str = “abc”;的方式,可以在一定程度上提高程序的運行速度,因為JVM會自動根據棧中數據的實際情況來決定是否有必要創建新對象。而對于String str = new String(“abc”);的代碼,則一概在堆中創建新對象,而不管其字符串值是否相等,是否有必要創建新對象,從而加重了程序的負擔。
如果使用new()來新建字符串的,都會在堆中創建字符串,而且其字符串是單獨存值的,即每個字符串都有自己的值,且其地址絕不會相同
當比較包裝類里面的數值是否相等時,用equals()方法;當測試兩個包裝類的引用是否指向同一個對象時,用==。
由于String類的immutable性質,當String變量需要經常變換其值如SQL語句拼接,HTML文本輸出時,應該考慮使用StringBuffer類,以提高程序效率。
摘要: 序言:本指南旨在幫助你建立全面的個人品牌戰略。個人品牌的建立是你銷售自己從而在商業上取得成功的重要一環。個人品牌的建立是一個持續的過程正如你不斷認識自己的過程。你自己強大了,品牌也亦然。在全球化導致工作競爭加劇的今天,個人品牌的提升也顯得尤為重要。正如像金子那樣發光,你能在人群中嶄露自己,就能步入精英的行列。如今這場角力將比你的預想更為激烈和艱難。
或許是David Samuel這個家伙把我帶進個人品牌研究這一行的,幾年前我看了他的報告。他在報告中說了我們為什么需要個人品牌。當時他的聽眾來自一個電信大公司:
“如果我們根據人的智力把他們劃分三六九等,那么他們就是一群A,一群B,一群C和一群D。因為全球化趨勢,C群和D群的工作已經被外包了。一切已經過去了。至于留下的你們,現在就要為躋身A群和B群而開始競爭。或許在這個人才濟濟的群體中,你會想用大聲嚷嚷來取得關注了。如何才能讓自己受到關注?你該如何讓自己發光以證明自己可以獲得額外的工作機會?你該如何從身邊每個人都像你一樣能干甚至更甚于你的環境中勝出?如果你身邊的每個人都是很能干的A群B群,你又該如何與他
閱讀全文