Posted on 2009-07-30 17:11
龍旋風 閱讀(348)
評論(1) 編輯 收藏

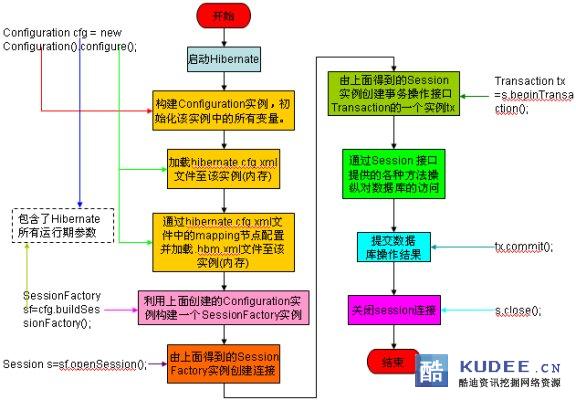
工作原理
1. 讀取并解析配置文件
2. 讀取并解析映射信息,創建SessionFactory
3. 打開Sesssion
4. 創建事務Transation
5. 持久化操作
6. 提交事務
7. 關閉Session
8. 關閉SesstionFactory
為什么要用:
1. 對JDBC訪問數據庫的代碼做了封裝,大大簡化了數據訪問層繁瑣的重復性代碼。
2. Hibernate是一個基于JDBC的主流持久化框架,是一個優秀的ORM實現。他很大程度的簡化DAO層的編碼工作
3. hibernate使用Java反射機制,而不是字節碼增強程序來實現透明性。
4. hibernate的性能非常好,因為它是個輕量級框架。映射的靈活性很出色。它支持各種關系數據庫,從一對一到多對多的各種復雜關系。
2. Hibernate是如何延遲加載?
1. Hibernate2延遲加載實現:a)實體對象 b)集合(Collection)
2. Hibernate3 提供了屬性的延遲加載功能
當Hibernate在查詢數據的時候,數據并沒有存在與內存中,當程序真正對數據的操作時,對象才存在與內存中,就實現了延遲加載,他節省了服務器的內存開銷,從而提高了服務器的性能。
3. Hibernate中怎樣實現類之間的關系?(如:一對多、多對多的關系)
類與類之間的關系主要體現在表與表之間的關系進行操作,它們都市對對象進行操作,我們程序中把所有的表與類都映射在一起,它們通過配置文件中的many-to-one、one-to-many、many-to-many、
4. 說下Hibernate的緩存機制
1. 內部緩存存在Hibernate中又叫一級緩存,屬于應用事物級緩存
2. 二級緩存:
a) 應用及緩存
b) 分布式緩存
條件:數據不會被第三方修改、數據大小在可接受范圍、數據更新頻率低、同一數據被系統頻繁使用、非 關鍵數據
c) 第三方緩存的實現
6. 如何優化Hibernate?
2. 靈活使用單向一對多關聯
3. 不用一對一,用多對一取代
4. 配置對象緩存,不使用集合緩存
5. 一對多集合使用Bag,多對多集合使用Set
6. 繼承類使用顯式多態
7. 表字段要少,表關聯不要怕多,有二級緩存撐腰
spring工作機制及為什么要用?
1.spring mvc請所有的請求都提交給DispatcherServlet,它會委托應用系統的其他模塊負責負責對請求進行真正的處理工作。
2.DispatcherServlet查詢一個或多個HandlerMapping,找到處理請求的Controller.
3.DispatcherServlet請請求提交到目標Controller
4.Controller進行業務邏輯處理后,會返回一個ModelAndView
5.Dispathcher查詢一個或多個ViewResolver視圖解析器,找到ModelAndView對象指定的視圖對象
6.視圖對象負責渲染返回給客戶端。
為什么用:
{AOP 讓開發人員可以創建非行為性的關注點,稱為橫切關注點,并將它們插入到應用程序代碼中。使用 AOP 后,公共服務 (比如日志、持久性、事務等)就可以分解成方面并應用到域對象上,同時不會增加域對象的對象模型的復雜性。
IOC 允許創建一個可以構造對象的應用環境,然后向這些對象傳遞它們的協作對象。正如單詞 倒置 所表明的,IOC 就像反 過來的 JNDI。沒有使用一堆抽象工廠、服務定位器、單元素(singleton)和直接構造(straight construction),每一個對象都是用 其協作對象構造的。因此是由容器管理協作對象(collaborator)。
Spring即使一個AOP框架,也是一IOC容器。 Spring 最好的地方是它有助于您替換對象。有了 Spring,只要用 JavaBean 屬性和配置文件加入依賴性(協作對象)。然后可以很容易地在需要時替換具有類似接口的協作對象。}