大數據我們都知道hadoop,可是還會各種各樣的技術進入我們的視野:Spark,Storm,impala,讓我們都反映不過來。為了能夠更好的架構大數據項目,這里整理一下,供技術人員,項目經理,架構師選擇合適的技術,了解大數據各種技術之間的關系,選擇合適的語言。
我們可以帶著下面問題來閱讀本文章:
1.hadoop都包含什么技術
2.Cloudera公司與hadoop的關系是什么,都有什么產品,產品有什么特性
3.Spark與hadoop的關聯是什么?
4.Storm與hadoop的關聯是什么?
![]()
hadoop家族
創始人:Doug Cutting
整個Hadoop家族由以下幾個子項目組成:
Hadoop Common:
Hadoop體系最底層的一個模塊,為Hadoop各子項目提供各 種工具,如:配置文件和日志操作等。詳細可查看
Hadoop技術內幕 深入解析HADOOP COMMON和HDFS架構設計與實現原理大全1-9章
HDFS:
是Hadoop應用程序中主要的分布式儲存系統, HDFS集群包含了一個NameNode(主節點),這個節點負責管理所有文件系統的元數據及存儲了真實數據的DataNode(數據節點,可以有很多)。HDFS針對海量數據所設計,所以相比傳統文件系統在大批量小文件上的優化,HDFS優化的則是對小批量大型文件的訪問和存儲。下面為詳細資料:
什么是HDFS及HDFS架構設計
HDFS+MapReduce+Hive快速入門
Hadoop2.2.0中HDFS為何具有高可用性
Java創建hdfs文件實例
MapReduce:
是一個軟件框架,用以輕松編寫處理海量(TB級)數據的并行應用程序,以可靠和容錯的方式連接大型集群中上萬個節點(商用硬件)。
詳細可查看:
Hadoop簡介(1):什么是Map/Reduce
Hadoop MapReduce基礎
MapReduce工作原理講解
手把手交你寫Mapreduce程序實例并部署在Hadoop2.2.0上運行
Hive:
Apache Hive是Hadoop的一個數據倉庫系統,促進了數據的綜述(將結構化的數據文件映射為一張數據庫表)、即席查詢以及存儲在Hadoop兼容系統中的大型數據集分析。Hive提供完整的SQL查詢功能——HiveQL語言,同時當使用這個語言表達一個邏輯變得低效和繁瑣時,HiveQL還允許傳統的Map/Reduce程序員使用自己定制的Mapper和Reducer。hive類似CloudBase,基于hadoop分布式計算平臺上的提供data warehouse的sql功能的一套軟件。使得存儲在hadoop里面的海量數據 的匯總,即席查詢簡單化。
詳細可查看:
Hive的起源及詳細介紹
hive詳解視頻
Pig:
Apache Pig是一個用于大型數據集分析的平臺,它包含了一個用于數據分析應用的高級語言以及評估這些應用的基礎設施。Pig應用的閃光特性在于它們的結構經得起大量的并行,也就是說讓它們支撐起非常大的數據集。Pig的基礎設施層包含了產生Map-Reduce任務的編譯器。Pig的語言層當前包含了一個原生語言——Pig Latin,開發的初衷是易于編程和保證可擴展性。
Pig是SQL-like語言,是在MapReduce上構建的一種高級查詢語言,把一些運算編譯進MapReduce模型的Map和Reduce中,并且用戶可以定義自己的功能。Yahoo網格運算部門開發的又一個克隆Google的項目Sawzall。
詳細可查看:
pig入門簡單操作及語法包括支持數據類型、函數、關鍵字、操作符等
hadoop家族Pig和Hive有什么不同?
HBase:
Apache HBase是Hadoop數據庫,一個分布式、可擴展的大數據存儲。它提供了大數據集上隨機和實時的讀/寫訪問,并針對了商用服務器集群上的大型表格做出優化——上百億行,上千萬列。其核心是Google Bigtable論文的開源實現,分布式列式存儲。就像Bigtable利用GFS(Google File System)提供的分布式數據存儲一樣,它是Apache Hadoop在HDFS基礎上提供的一個類Bigatable。
詳細可查看:
hbase與傳統數據的區別
HBASE分布式安裝視頻下載分享
ZooKeeper:
Zookeeper是Google的Chubby一個開源的實現。它是一個針對大型分布式系統的可靠協調系統,提供的功能包括:配置維護、名字服務、 分布式同步、組服務等。ZooKeeper的目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的接口和性能高效、功能穩定的系統提供給用戶。
詳細可查看:
什么是Zookeeper,Zookeeper的作用是什么,在Hadoop及hbase中具體作用是什么
Avro:
Avro是doug cutting主持的RPC項目,有點類似Google的protobuf和Facebook的thrift。avro用來做以后hadoop的RPC,使hadoop的RPC模塊通信速度更快、數據結構更緊湊。
Sqoop:
Sqoop是一個用來將Hadoop和關系型數據庫中的數據相互轉移的工具,可以將一個關系型數據庫中數據導入Hadoop的HDFS中,也可以將HDFS中數據導入關系型數據庫中。
詳細可查看:
Sqoop詳細介紹包括:sqoop命令,原理,流程
Mahout:
Apache Mahout是個可擴展的機器學習和數據挖掘庫,當前Mahout支持主要的4個用例:
推薦挖掘:搜集用戶動作并以此給用戶推薦可能喜歡的事物。
聚集:收集文件并進行相關文件分組。
分類:從現有的分類文檔中學習,尋找文檔中的相似特征,并為無標簽的文檔進行正確的歸類。
頻繁項集挖掘:將一組項分組,并識別哪些個別項會經常一起出現。
Cassandra:
Apache Cassandra是一個高性能、可線性擴展、高有效性數據庫,可以運行在商用硬件或云基礎設施上打造完美的任務關鍵性數據平臺。在橫跨數據中心的復制中,Cassandra同類最佳,為用戶提供更低的延時以及更可靠的災難備份。通過log-structured update、反規范化和物化視圖的強支持以及強大的內置緩存,Cassandra的數據模型提供了方便的二級索引(column indexe)。
Chukwa:
Apache Chukwa是個開源的數據收集系統,用以監視大型分布系統。建立于HDFS和Map/Reduce框架之上,繼承了Hadoop的可擴展性和穩定性。Chukwa同樣包含了一個靈活和強大的工具包,用以顯示、監視和分析結果,以保證數據的使用達到最佳效果。
Ambari:
Apache Ambari是一個基于web的工具,用于配置、管理和監視Apache Hadoop集群,支持Hadoop HDFS,、Hadoop MapReduce、Hive、HCatalog,、HBase、ZooKeeper、Oozie、Pig和Sqoop。Ambari同樣還提供了集群狀況儀表盤,比如heatmaps和查看MapReduce、Pig、Hive應用程序的能力,以友好的用戶界面對它們的性能特性進行診斷。
HCatalog
Apache HCatalog是Hadoop建立數據的映射表和存儲管理服務,它包括:
提供一個共享模式和數據類型機制。
提供一個抽象表,這樣用戶就不需要關注數據存儲的方式和地址。
為類似Pig、MapReduce及Hive這些數據處理工具提供互操作性。
------------------------------------------------------------------------------------------------------------------------------------------------
Chukwa:
Chukwa是基于Hadoop的大集群監控系統,由yahoo貢獻。
------------------------------------------------------------------------------------------------------------------------------------------------
Cloudera系列產品:
創始組織:Cloudera公司
1.Cloudera Manager:
有四大功能
(1)管理
(2)監控
(3)診斷
(4)集成
Cloudera Manager四大功能
2.Cloudera CDH:英文名稱:CDH (Cloudera's Distribution, including Apache Hadoop)
Cloudera對hadoop做了相應的改變。
Cloudera公司的發行版,我們將該版本稱為CDH(Cloudera Distribution Hadoop)。
詳細可以查看
Cloudera Hadoop什么是CDH及CDH版本介紹
相關資料
CDH3實戰Hadoop(HDFS) , HBase , Zookeeper , Flume , Hive
CDH4安裝實踐HDFS、HBase、Zookeeper、Hive、Oozie、Sqoop
Hadoop CDH四種安裝方式總結及實例指導
hadoop的CDH4及CDH5系列文檔下載分享
3.Cloudera Flume
Flume是Cloudera提供的日志收集系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;
Flume是Cloudera提供的一個高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸的系統,Flume支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力。
Flume最早是Cloudera提供的日志收集系統,目前是Apache下的一個孵化項目,Flume支持在日志系統中定制各類數據發送方,用于收集數據;同時,Flume提供對數據進行簡單處理,并寫到各種數據接受方(可定制)的能力 Flume提供了從console(控制臺)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系統,支持TCP和UDP等2種模式),exec(命令執行)等數據源上收集數據的能力。
Flume采用了多Master的方式。為了保證配置數據的一致性,Flume[1]引入了ZooKeeper,用于保存配置數據,ZooKeeper本身可保證配置數據的一致性和高可用,另外,在配置數據發生變化時,ZooKeeper可以通知Flume Master節點。Flume Master間使用gossip協議同步數據。
詳細可查看:
什么是 flume 日志收集,flume的特性
什么是 flume 日志收集,flume的原理是什么,flume會遇到什么問題
4.Cloudera Impala
什么是impala,如何安裝使用Impala
5.Cloudera hue
Hue是cdh專門的一套web管理器,它包括3個部分hue ui,hue server,hue db。hue提供所有的cdh組件的shell界面的接口。你可以在hue編寫mr,查看修改hdfs的文件,管理hive的元數據,運行Sqoop,編寫Oozie工作流等大量工作。
詳細可查看:
cloudera hue安裝及Oozie的安裝
什么是Oozie?Oozie簡介
Cloudera Hue 使用經驗分享,遇到的問題及解決方案
------------------------------------------------------------------------------------------------------------------------------------------------
Spark
創始組織:加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發
Spark 是一種與 Hadoop 相似的開源集群計算環境,但是兩者之間還存在一些不同之處,這些有用的不同之處使 Spark 在某些工作負載方面表現得更加優越,換句話說,Spark 啟用了內存分布數據集,除了能夠提供交互式查詢外,它還可以優化迭代工作負載。
Spark 是在 Scala 語言中實現的,它將 Scala 用作其應用程序框架。與 Hadoop 不同,Spark 和 Scala 能夠緊密集成,其中的 Scala 可以像操作本地集合對象一樣輕松地操作分布式數據集。
盡管創建 Spark 是為了支持分布式數據集上的迭代作業,但是實際上它是對 Hadoop 的補充,可以在 Hadoo 文件系統中并行運行。通過名為 Mesos 的第三方集群框架可以支持此行為。Spark 由加州大學伯克利分校 AMP 實驗室 (Algorithms, Machines, and People Lab) 開發,可用來構建大型的、低延遲的數據分析應用程序。
可以詳細了解
科普Spark,Spark是什么,如何使用Spark(1)
科普Spark,Spark核心是什么,如何使用Spark(2)
優酷土豆用Spark完善大數據分析
Hadoop新成員Hadoop-Cloudera公司將Spark加入Hadoop
Storm
創始人:Twitter
Twitter將Storm正式開源了,這是一個分布式的、容錯的實時計算系統,它被托管在GitHub上,遵循 Eclipse Public License 1.0。Storm是由BackType開發的實時處理系統,BackType現在已在Twitter麾下。GitHub上的最新版本是Storm 0.5.2,基本是用Clojure寫的。
詳細可以了解:
storm入門介紹
Storm-0.9.0.1安裝部署 指導
總體認識storm包括概念,場景,組成
大數據架構師:hadoop、Storm改選哪一個?
大數據架構:flume-ng+Kafka+Storm+HDFS 實時系統組合
]]>
]]>
]]>
先來看張表,了解下典型的NoSQL數據庫的分類
| 臨時性鍵值存儲 | 永久性鍵值存儲 | 面向文檔的數據庫 | 面向列的數據庫 |
| Memcached | Tokyo Tyrant | MangoDB | Cassandra |
| Redis | Flare | CouchDB | HBase |
| ROMA | HyperTable | ||
| Redis |
1. CouchDB
- 所用語言: Erlang
- 特點:DB一致性,易于使用
- 使用許可: Apache
- 協議: HTTP/REST
- 雙向數據復制,
- 持續進行或臨時處理,
- 處理時帶沖突檢查,
- 因此,采用的是master-master復制(見編注2)
- MVCC – 寫操作不阻塞讀操作
- 可保存文件之前的版本
- Crash-only(可靠的)設計
- 需要不時地進行數據壓縮
- 視圖:嵌入式 映射/減少
- 格式化視圖:列表顯示
- 支持進行服務器端文檔驗證
- 支持認證
- 根據變化實時更新
- 支持附件處理
- 因此, CouchApps(獨立的 js應用程序)
- 需要 jQuery程序庫
最佳應用場景:適用于數據變化較少,執行預定義查詢,進行數據統計的應用程序。適用于需要提供數據版本支持的應用程序。
例如: CRM、CMS系統。 master-master復制對于多站點部署是非常有用的。
(編注2:master-master復制:是一種數據庫同步方法,允許數據在一組計算機之間共享數據,并且可以通過小組中任意成員在組內進行數據更新。)
2. Redis
- 所用語言:C/C++
- 特點:運行異常快
- 使用許可: BSD
- 協議:類 Telnet
- 有硬盤存儲支持的內存數據庫,
- 但自2.0版本以后可以將數據交換到硬盤(注意, 2.4以后版本不支持該特性!)
- Master-slave復制(見編注3)
- 雖然采用簡單數據或以鍵值索引的哈希表,但也支持復雜操作,例如 ZREVRANGEBYSCORE。
- INCR & co (適合計算極限值或統計數據)
- 支持 sets(同時也支持 union/diff/inter)
- 支持列表(同時也支持隊列;阻塞式 pop操作)
- 支持哈希表(帶有多個域的對象)
- 支持排序 sets(高得分表,適用于范圍查詢)
- Redis支持事務
- 支持將數據設置成過期數據(類似快速緩沖區設計)
- Pub/Sub允許用戶實現消息機制
最佳應用場景:適用于數據變化快且數據庫大小可遇見(適合內存容量)的應用程序。
例如:股票價格、數據分析、實時數據搜集、實時通訊。
(編注3:Master-slave復制:如果同一時刻只有一臺服務器處理所有的復制請求,這被稱為 Master-slave復制,通常應用在需要提供高可用性的服務器集群。)
3. MongoDB
- 所用語言:C++
- 特點:保留了SQL一些友好的特性(查詢,索引)。
- 使用許可: AGPL(發起者: Apache)
- 協議: Custom, binary( BSON)
- Master/slave復制(支持自動錯誤恢復,使用 sets 復制)
- 內建分片機制
- 支持 javascript表達式查詢
- 可在服務器端執行任意的 javascript函數
- update-in-place支持比CouchDB更好
- 在數據存儲時采用內存到文件映射
- 對性能的關注超過對功能的要求
- 建議最好打開日志功能(參數 –journal)
- 在32位操作系統上,數據庫大小限制在約2.5Gb
- 空數據庫大約占 192Mb
- 采用 GridFS存儲大數據或元數據(不是真正的文件系統)
最佳應用場景:適用于需要動態查詢支持;需要使用索引而不是 map/reduce功能;需要對大數據庫有性能要求;需要使用 CouchDB但因為數據改變太頻繁而占滿內存的應用程序。
例如:你本打算采用 MySQL或 PostgreSQL,但因為它們本身自帶的預定義欄讓你望而卻步。
4. Riak
- 所用語言:Erlang和C,以及一些Javascript
- 特點:具備容錯能力
- 使用許可: Apache
- 協議: HTTP/REST或者 custom binary
- 可調節的分發及復制(N, R, W)
- 用 JavaScript or Erlang在操作前或操作后進行驗證和安全支持。
- 使用JavaScript或Erlang進行 Map/reduce
- 連接及連接遍歷:可作為圖形數據庫使用
- 索引:輸入元數據進行搜索(1.0版本即將支持)
- 大數據對象支持( Luwak)
- 提供“開源”和“企業”兩個版本
- 全文本搜索,索引,通過 Riak搜索服務器查詢( beta版)
- 支持Masterless多站點復制及商業許可的 SNMP監控
最佳應用場景:適用于想使用類似 Cassandra(類似Dynamo)數據庫但無法處理 bloat及復雜性的情況。適用于你打算做多站點復制,但又需要對單個站點的擴展性,可用性及出錯處理有要求的情況。
例如:銷售數據搜集,工廠控制系統;對宕機時間有嚴格要求;可以作為易于更新的 web服務器使用。
5. Membase
- 所用語言: Erlang和C
- 特點:兼容 Memcache,但同時兼具持久化和支持集群
- 使用許可: Apache 2.0
- 協議:分布式緩存及擴展
- 非常快速(200k+/秒),通過鍵值索引數據
- 可持久化存儲到硬盤
- 所有節點都是唯一的( master-master復制)
- 在內存中同樣支持類似分布式緩存的緩存單元
- 寫數據時通過去除重復數據來減少 IO
- 提供非常好的集群管理 web界面
- 更新軟件時軟無需停止數據庫服務
- 支持連接池和多路復用的連接代理
最佳應用場景:適用于需要低延遲數據訪問,高并發支持以及高可用性的應用程序
例如:低延遲數據訪問比如以廣告為目標的應用,高并發的 web 應用比如網絡游戲(例如 Zynga)
6. Neo4j
- 所用語言: Java
- 特點:基于關系的圖形數據庫
- 使用許可: GPL,其中一些特性使用 AGPL/商業許可
- 協議: HTTP/REST(或嵌入在 Java中)
- 可獨立使用或嵌入到 Java應用程序
- 圖形的節點和邊都可以帶有元數據
- 很好的自帶web管理功能
- 使用多種算法支持路徑搜索
- 使用鍵值和關系進行索引
- 為讀操作進行優化
- 支持事務(用 Java api)
- 使用 Gremlin圖形遍歷語言
- 支持 Groovy腳本
- 支持在線備份,高級監控及高可靠性支持使用 AGPL/商業許可
最佳應用場景:適用于圖形一類數據。這是 Neo4j與其他nosql數據庫的最顯著區別
例如:社會關系,公共交通網絡,地圖及網絡拓譜
7. Cassandra
- 所用語言: Java
- 特點:對大型表格和 Dynamo支持得最好
- 使用許可: Apache
- 協議: Custom, binary (節約型)
- 可調節的分發及復制(N, R, W)
- 支持以某個范圍的鍵值通過列查詢
- 類似大表格的功能:列,某個特性的列集合
- 寫操作比讀操作更快
- 基于 Apache分布式平臺盡可能地 Map/reduce
- 我承認對 Cassandra有偏見,一部分是因為它本身的臃腫和復雜性,也因為 Java的問題(配置,出現異常,等等)
最佳應用場景:當使用寫操作多過讀操作(記錄日志)如果每個系統組建都必須用 Java編寫(沒有人因為選用 Apache的軟件被解雇)
例如:銀行業,金融業(雖然對于金融交易不是必須的,但這些產業對數據庫的要求會比它們更大)寫比讀更快,所以一個自然的特性就是實時數據分析
8. HBase
(配合 ghshephard使用)
- 所用語言: Java
- 特點:支持數十億行X上百萬列
- 使用許可: Apache
- 協議:HTTP/REST (支持 Thrift,見編注4)
- 在 BigTable之后建模
- 采用分布式架構 Map/reduce
- 對實時查詢進行優化
- 高性能 Thrift網關
- 通過在server端掃描及過濾實現對查詢操作預判
- 支持 XML, Protobuf, 和binary的HTTP
- Cascading, hive, and pig source and sink modules
- 基于 Jruby( JIRB)的shell
- 對配置改變和較小的升級都會重新回滾
- 不會出現單點故障
- 堪比MySQL的隨機訪問性能
最佳應用場景:適用于偏好BigTable:)并且需要對大數據進行隨機、實時訪問的場合。
例如: Facebook消息數據庫(更多通用的用例即將出現)
編注4:Thrift 是一種接口定義語言,為多種其他語言提供定義和創建服務,由Facebook開發并開源。
當然,所有的系統都不只具有上面列出的這些特性。這里我僅僅根據自己的觀點列出一些我認為的重要特性。與此同時,技術進步是飛速的,所以上述的內容肯定需要不斷更新。我會盡我所能地更新這個列表。
]]>
//模板路徑
String modelPath="D:\Excel.xls"
//sheet的名字
String sheetName="sheet1";
獲取Excel模板對象
try {
File file = new File(modelPath);
if(!file.exists()){
System.out.println("模板文件:"+modelPath+"不存在!");
}
fs = new POIFSFileSystem(new FileInputStream(file));
wb = new HSSFWorkbook(fs);
sheet = wb.getSheet(sheetName);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//從heet中獲取行數
int rowNum = sheet.getLastRowNum();
//獲取行里面的總列數
row = sheet.getRow(i); //i:第I行
// 獲取行里面的總列數
int columnNum = 0;
if(row!=null){
columnNum = row.getPhysicalNumberOfCells();
}
//獲取單元格的值
HSSFCell cell = sheet.getRow(i).getCell(j); //第i行,第j列
String cellValue = cell.getStringCellValue();
//替換數據 本人的數據存放在Map中
for (Entry<String, Object> entry : param.entrySet()) {
String key = entry.getKey();
if(key.equals(cellValue)){
String value = entry.getValue().toString();
setCellStrValue(i, j, value);//設置第i行,第j列的值為Value
}
}
完整代碼:
/**
* 替換Excel模板中的數據
* @param sheetName Sheet名字
* @param modelPath 模板路徑
* @param param 需要替換的數據
* @return
* @author 劉澤中
* @Date: 2015年12月11日
*/
public HSSFWorkbook replaceExcel(String sheetName,String modelPath,Map<String, Object> param){
//獲取所讀取excel模板的對象
try {
File file = new File(modelPath);
if(!file.exists()){
System.out.println("模板文件:"+modelPath+"不存在!");
}
fs = new POIFSFileSystem(new FileInputStream(file));
wb = new HSSFWorkbook(fs);
sheet = wb.getSheet(sheetName);
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
replaceExcelDate(param);
return wb;
}
/**
* 根據 Map中的數據替換Excel模板中指定數據
* @param param
* @author 劉澤中
* @Date: 2015年12月11日
*/
public void replaceExcelDate(Map<String, Object> param){
// 獲取行數
int rowNum = sheet.getLastRowNum();
for (int i = 0; i < rowNum; i++) {
row = sheet.getRow(i);
// 獲取行里面的總列數
int columnNum = 0;
if(row!=null){
columnNum = row.getPhysicalNumberOfCells();
}
for (int j = 0; j < columnNum; j++) {
HSSFCell cell = sheet.getRow(i).getCell(j);
String cellValue = cell.getStringCellValue();
for (Entry<String, Object> entry : param.entrySet()) {
String key = entry.getKey();
if(key.equals(cellValue)){
String value = entry.getValue().toString();
setCellStrValue(i, j, value);
}
}
}
}
}
/**
* 設置字符串類型的數據
* @param rowIndex--行值 從0開始
* @param cellnum--列值 從0開始
* @param value--字符串類型的數據
*
* @author 劉澤中
* @Date: 2015年12月11日
*/
public void setCellStrValue(int rowIndex, int cellnum, String value) {
HSSFCell cell = sheet.getRow(rowIndex).getCell(cellnum);
cell.setCellValue(value);
}



]]>
}
2、將響應結果返回:
注:由于項目是UTF-8,需要轉碼。
]]>
http://httpd.apache.org/
http://tomcat.apache.org/download-connectors.cgi
參考URL:http://blog.csdn.net/wubai250/article/details/8533968
下載解壓tar.gz,使用命令tar -zxvf *.tar.gz解壓http和tomcat-connector
注:jdk、Tomcat安裝不再此處描述,可在網上搜索。1、安裝Apache2(httpd-2.2.31)
$cd httpd-2.2.31
$./configure --prefix=/env/web/apache/
$make
$make install
安裝成功后,進入
$ cd /env/web/apache/bin
$ ./apachectl -k start
打開httpd.conf之后查找Listen這行
改成Listen 80 注:80端口要是被占用了就啟動不了的,如果被占用可以改成7160之類的
再查找ServerName
改成
ServerName localhost:80
就修改這2個地方就完成了,可以啟動了
2、安裝tomcat-connectors-1.2.40-src
CentOS環境下整合Apache和Tomcat
轉載:http://www.aiplaypc.com/111.html
1、先去apache官網下載tomcat與apache關聯的相關應用,地址http://tomcat.apache.org/download-connectors.cgi
2、解壓下載的 tar -xzvf tomcat-connectors-1.2.40-src.tar.gz
3、進入cd /tomcat-connectors-1.2.40-src/native ,輸入命令:./configure --with-apxs=/env/web/apache/bin/apxs(注:此處為apache安裝路徑)
$make
$make install
注意:安裝完成tomcat-connectors之后,查看apache目錄下的modules目錄,是否多出一些.so文件。這些文件即jk的配置信息文件
3、配置負載均衡
A)、修改http.conf配置文件
<VirtualHost *:80> ServerName test.XXX.com ProxyPass / balancer://cluster/ stickysession=jsessionid nofailover=on ProxyPassReverse / balancer://cluster ErrorLog logs/test.XXX.com-error_log CustomLog logs/test.XXX.com-access_log common</VirtualHost>
ProxyRequests Off<Proxy balancer://cluster>
#注此處端口不是8080那個端口,而是負載均衡使用的端口 BalancerMember ajp://127.0.0.1:8089 loadfactor=1 route=jvm1 BalancerMember ajp://127.0.0.1:9099 loadfactor=1 route=jvm2</Proxy>
注:參考http://www.cnblogs.com/fx2008/p/4086555.html
B)、配置tomcat
修改端口,具體詳見上述鏈接描述
注:jdk、Tomcat安裝不再此處描述,可在網上搜索。
$ ./apachectl -k start
打開httpd.conf之后查找Listen這行
改成Listen 80
注:80端口要是被占用了就啟動不了的,如果被占用可以改成7160之類的
再查找ServerName
改成
ServerName localhost:80
就修改這2個地方就完成了,可以啟動了
2、安裝tomcat-connectors-1.2.40-src
CentOS環境下整合Apache和Tomcat
轉載:http://www.aiplaypc.com/111.html
#注此處端口不是8080那個端口,而是負載均衡使用的端口
注:參考http://www.cnblogs.com/fx2008/p/4086555.html
B)、配置tomcat
修改端口,具體詳見上述鏈接描述
]]>
注:jdk、tomcat安裝不再描述
2、安裝apache httpd
查看是否有安裝httpd :rpm -qa httpd
安裝httpd : yum install httpd
卸載httpd : yum remove httpd
3、默認安裝路徑:/etc/httpd
啟動httpd: cd /etc/init.d/ ./httpd start
停止httpd: cd /etc/init.d/ ./httpd stop
4、修改/etc/httpd/conf/httpd.conf
#同一端口,不同域名配置必須下一行
NameVirtualHost *:80
]]>
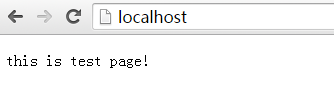
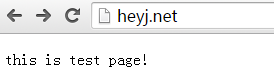
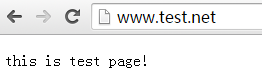
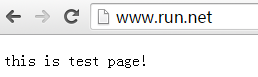
2、修改 C:\Windows\System32\drivers\etc\hosts 文件
增加域名映射本服務器地址(可換成IP地址):
3、tomcat目錄下的conf文件夾, server.xml
修改8080端口,改為80
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/>
<Connector connectionTimeout="20000" port="80" protocol="HTTP/1.1" redirectPort="8443"/>
修改Host端口對應的配置
<Alias>heyj.net</Alias>
<Alias>www.test.net</Alias>
<Alias>www.run.net</Alias>
</Host>
]]>
]]>