今天是第三章的剩余部分:4.性能度量指標(biāo),5.分代收集的基本原理。
性能度量 一些指標(biāo)用來評估垃圾收集的性能,包括:
吞吐量(Throughput)
一個很長的周期中,除去花費在垃圾收集上的時間占總時間的百分比。
垃圾收集開銷(Garbage collection overhead)
與吞吐量相反,這是垃圾收集占總時間的百分比。
(譯注:為什么需要兩個指標(biāo)呢?對于并發(fā)的垃圾收集算法,垃圾收集的部分任務(wù)和
應(yīng)用系統(tǒng)同時運行導(dǎo)致上述兩個指標(biāo)加起來會大于100%)
暫停時間(Pause time)
垃圾收集發(fā)生時,應(yīng)用系統(tǒng)暫停的時間。
收集頻率(Frequency of collection)
垃圾收集相對于應(yīng)用系統(tǒng)運行發(fā)生的頻率。
占用空間(Footprint)
一種大小的指標(biāo),例如堆大小。
反應(yīng)時間(Promptness)
對象變成垃圾之后到
內(nèi)存可用的時間
一個交互式應(yīng)用需要較低的暫停時間,反之持續(xù)的執(zhí)行時間對于非交互式應(yīng)用更加重要。一個實時應(yīng)用程序要求在垃圾收集中的暫停以及收集
器的整個周期擁有較少的抖動。運行在個人計算機或嵌入式設(shè)備中的應(yīng)用可能主要關(guān)心小的空間占用。
分代收集 使用分代(generational collection)收集技術(shù)時,內(nèi)存分為很多代(generations),分離的存儲池存儲不同年齡的對象。例如,最通用的配置
中有兩代:一個用于存放年輕的對象,另一存放年老的對象。
不同的代使用不同的算法執(zhí)行垃圾收集任務(wù),每個算法會基于本代獨特的特征進行
優(yōu)化。分代的垃圾收集基于一種被稱為弱分代假設(shè)(weak
generational hypothesis),它是關(guān)于在幾種語言(包括
java語言)編寫的應(yīng)用程序中觀察到的結(jié)果:
大部分的分配的對象不會被引用(存活)很長時間,這些對象在年輕的時候就死掉了
年老對象引用年輕對象的情況很少出現(xiàn)
年輕代的收集發(fā)生的相對頻繁、有效、快速,因為年輕代的空間通常比較小并且有很多的對象都不再被引用。
在年輕代幾次收集后仍然生存的對象最終會晉升(promoted)或者被授予(tenured)到年老代。如圖1。年老代一般比年輕代大,并且增長的速度
很慢。結(jié)果是,年老代的收集很少發(fā)生,但是會花費更長的時間才能完成。

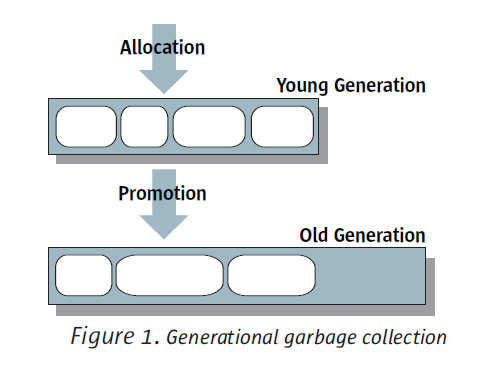
圖1 分代的垃圾收集
為年輕代
設(shè)計的收集算法主要關(guān)注在速度方面,因為垃圾收集經(jīng)常發(fā)生。另一方面,在空間方面更有效率的算法管理著年老代,因為年老代占據(jù)了
大部分的堆空間并且年老代的垃圾密度比較低。
此文已轉(zhuǎn)移到:
http://www.xiegq.com/2013/09/16/39.html