
2012年9月6日
Linux中JDK1.6的安裝和配置方法
一、安裝
創(chuàng)建安裝目錄,在/usr/java下建立安裝路徑,并將文件考到該路徑下:
# mkdir /usr/java
1、jdk-6u11-linux-i586.bin 這個(gè)是自解壓的文件,在linux上安裝如下:
# chmod 755 jdk-6u11-linux-i586.bin
# ./jdk-6u11-linux-i586.bin (注意,這個(gè)步驟一定要在jdk-6u11-linux-i586.bin所在目錄下)
在按提示輸入yes后,jdk被解壓。
出現(xiàn)一行字:Do you aggree to the above license terms? [yes or no]
安裝程序在問您是否愿意遵守剛才看過的許可協(xié)議。當(dāng)然要同意了,輸入"y" 或 "yes" 回車。
2、若是用jdk-6u11-linux-i586-rpm.bin 這個(gè)也是一個(gè)自解壓文件,不過解壓后的文件是jdk-6u11-linux-i586-rpm 包,執(zhí)行rpm命令裝到linux上就可以了。安裝如下:
#chmod 755 ./jdk-6u11-linux-i586-rpm
# ./jdk-6u11-linux-i586-rpm .bin
# rpm -ivh jdk-6u11-linux-i586-rpm
出現(xiàn)一行字:Do you aggree to the above license terms? [yes or no]
安裝程序在問您是否愿意遵守剛才看過的許可協(xié)議。當(dāng)然要同意了,輸入"y" 或 "yes" 回車。
安裝軟件會(huì)將JDK自動(dòng)安裝到 /usr/java/目錄下。
二、配置
#vi /etc/profile
在里面添加如下內(nèi)容
export JAVA_HOME=/usr/java/jdk1.6.0_27
export JAVA_BIN=/usr/java/jdk1.6.0_27/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
讓/etc/profile文件修改后立即生效 ,可以使用如下命令:
# . /etc/profile
注意: . 和 /etc/profile 有空格.
重啟測(cè)試
java -version
set 查看環(huán)境變量
pwd 顯示當(dāng)前位置
samba文件共享服務(wù)可以讓linux和linux系統(tǒng)、linux和windows系統(tǒng)之間共享文件
服務(wù)查詢
默認(rèn)情況下,Linux系統(tǒng)在默認(rèn)安裝中已經(jīng)安裝了Samba服務(wù)包的一部分,為了對(duì)整個(gè)過程有一個(gè)完整的了解,在此先將這部分卸載掉。使用命令
rpm -qa | grep samba,默認(rèn)情況下可以查詢到兩個(gè)已經(jīng)存在的包:
samba-client-xxx-xxx
samba-common-xxx.xxx
卸載Samba
用rpm -e 將兩個(gè)包卸載掉。對(duì)于samba-common-xxx.xxx,因?yàn)榕c其它rpm包之間存在依賴關(guān)系,所以必須加參數(shù)-f和--nodeps,-f是指強(qiáng)制,--nodeps是指不檢查依賴關(guān)系,具體完整命令為:
rpm -e samba-common-xxx -f --nodeps
rpm -e samba-client-xxx -f –nodeps
掛在鏡像文件
因?yàn)榘惭bsamba你需要下載對(duì)應(yīng)的安裝包,一般系統(tǒng)盤就有這些軟件,所以可以直接掛載上去
mount -o loop /home/rhel-server-6.2-x86_64-dvd.iso /media/OS
這樣就將系統(tǒng)盤掛載到指定的OS目錄了,在OS目錄下的Packages下有很多安裝包可以使用。
安裝Samba
用以下命令安裝:
rpm -ivh samba-xxx.rpm -f --nodeps
rpm -ivh samba-client-xxx.rpm -f --nodeps
rpm -ivh samba-common-xxx.rpm -f --nodeps
安裝完成后,使用命令rpm -qa | grep samba進(jìn)行查詢,發(fā)現(xiàn)搭建samba服務(wù)器所依賴的所有服務(wù)器都已經(jīng)安裝好了即可。
安裝完成后配置/etc/samba/smb.conf配置文件,你可以備份原來的配置,把下面的配置覆蓋當(dāng)前配置即可:
[global]
workgroup=takecar
netbios name=Linux-108.12
server string=Linux Samba Server TestServer
#security=share
security=user
map to guest=Bad User
[takecar]
path=/opt/takecar
writable=yes
browseable=yes
guest ok=yes
以上就是配置匿名用戶共享目錄/opt/takecar
其中writable是寫入權(quán)限、browseable是瀏覽權(quán)限、guest是貴賓用戶
建立相應(yīng)目錄并授權(quán)
[root@localhost ~]# mkdir -p /opt/linuxsir
[root@localhost ~]# id nobody
uid=99(nobody) gid=99(nobody) groups=99(nobody)
[root@localhost ~]# chown -R nobody:nobody /opt/linuxsir
注釋:關(guān)于授權(quán)nobody,我們先用id命令查看了nobody用戶的信息,發(fā)現(xiàn)他的用戶組也是nobody,我們要以這個(gè)為準(zhǔn)。有些系統(tǒng)nobody用戶組并非是nobody ;
啟動(dòng)smbd和nmbd服務(wù)器
[root@localhost ~]# smbd
[root@localhost ~]# nmbd
關(guān)閉和查詢服務(wù)
pkill smbd
pkill nmbd
pgrep smbd
pgrep nmbd
如果啟動(dòng)后不能訪問可能是防火墻原因,關(guān)閉防火墻
service iptables stop
chkconfig iptables off
設(shè)置服務(wù)開機(jī)啟動(dòng) ntsysv命令可以進(jìn)入圖形界面設(shè)置,如果windows不能建立linux的共享目錄可能是window中的某個(gè)服務(wù)原因。
可以在運(yùn)行輸入 secpol.msc命令 進(jìn)入本地策略/安全選項(xiàng), 設(shè)置
直接用進(jìn)程殺死程序
ps -ef|grep smb
kill -9 pid #pid 為相應(yīng)的進(jìn)程號(hào)
#直接查看指定端口的進(jìn)程pid
netstat -anp|grep 9217
摘要: oracle job有定時(shí)執(zhí)行的功能,可以在指定的時(shí)間點(diǎn)或每天的某個(gè)時(shí)間點(diǎn)自行執(zhí)行任務(wù)。 一、查詢系統(tǒng)中的job,可以查詢視圖 --相關(guān)視圖select * from dba_jobs;select * from all_jobs;select * from user_jobs;-- 查詢字段描述/*字段(列) 類型 描述JOB ...
閱讀全文
// 方式一:
double f = 3.1516;
BigDecimal b = new BigDecimal(f);
double f1 = b.setScale(2, BigDecimal.ROUND_HALF_UP).doubleValue();
// 方式二:
new java.text.DecimalFormat("#.00").format(3.1415926);// #.00 表示兩位小數(shù) #.0000四位小數(shù) 以此類推…
// 方式三:
double d = 3.1415926;
String result = String.format("%.2f", d);// %.2f %. 表示 小數(shù)點(diǎn)前任意位數(shù) 2 表示兩位小數(shù) 格式后的結(jié)果為f 表示浮點(diǎn)型。
//方法四:
Math.round(5.2644555 * 100) * 0.01d;
//String.format("%0" + 15 + "d", 23) 23不足15為就在前面補(bǔ)0在使用cxf實(shí)現(xiàn)webservice時(shí),經(jīng)常碰到的問題就是如果在服務(wù)端,修改了一個(gè)接口的簽名實(shí)現(xiàn),如增加一個(gè)字段,或者刪除一個(gè)字段。在這種情況下,在默認(rèn)的配置中,就會(huì)報(bào)以下的錯(cuò)誤信息:
org.apache.cxf.interceptor.Fault: Unmarshalling Error: unexpected element . Expected elements are
這種錯(cuò)誤即客戶端使用的傳輸對(duì)象與服務(wù)端接收的參數(shù)的字段不匹配。但如果,每次修改服務(wù)端的實(shí)現(xiàn),都需要更新客戶端時(shí),就會(huì)出現(xiàn)一些問題,如在某些情況下,客戶端的更新是不可能的事(如不在自己掌握之內(nèi),或者服務(wù)不能隨便更新,或者其它計(jì)劃時(shí))。
如果避免這種問題,其實(shí)也很簡(jiǎn)單,就是禁用cxf中的字段信息驗(yàn)證,如果禁用掉此驗(yàn)證,就不再會(huì)對(duì)相應(yīng)的字段信息進(jìn)行驗(yàn)證,同時(shí)沒有的字段也會(huì)自動(dòng)的忽略。整個(gè)解決只需要增加以下的一行配置即可,在cxf.xml(spring集成文件)中增加以下配置項(xiàng):
<cxf:properties>
<entry key="set-jaxb-validation-event-handler" value="false"/>
</cxf:properties>
這樣,即會(huì)禁用掉所有cxf的數(shù)據(jù)驗(yàn)證,在大多數(shù)情況下,這可以滿足我們的要求(除非你有其它和cxf集成的數(shù)據(jù)驗(yàn)證要求)。
轉(zhuǎn)載請(qǐng)標(biāo)明出處:i flym
本文地址:http://www.iflym.com/index.php/code/201307310001.html
摘要: 副標(biāo)題:利用ant腳本 自動(dòng)構(gòu)建svn增量/全量 系統(tǒng)程序升級(jí)包 首先請(qǐng)?jiān)试S我這樣說,作為開發(fā)或測(cè)試,你一定要具備這種本領(lǐng)。你可以手動(dòng)打包、部署你的工程,但這不是最好的方法。最好的方式就是全自動(dòng)化的方式。開發(fā)人員提交了代碼后,可以自動(dòng)構(gòu)建、打包、部署到測(cè)試環(huán)境。測(cè)試通過后進(jìn)入到模擬環(huán)境或是直接發(fā)布的生產(chǎn)環(huán)境,這個(gè)過程可以是全自動(dòng)的。但這個(gè)自動(dòng)化的方式有一些公司用到了,但也有很多公司還不知道,他們...
閱讀全文
posted @
2013-11-05 09:01 hoojo 閱讀(17052) |
評(píng)論 (2) |
編輯 收藏ant 命令行方式執(zhí)行build javac編譯class出現(xiàn) 泛型無(wú)法轉(zhuǎn)換 無(wú)法確定 <X>X 的類型參數(shù);對(duì)于上限為 X,java.lang.Object 的類型變量 X,不存在唯一最大實(shí)例
解決方法:
需要用到eclipse的jdt來編譯class,不能再使用javac的默認(rèn)編譯方式。
在eclipse或MyEclipse的eclipse/plugin目錄中找到org.eclipse.jdt.core_3.5.2.v_981_R35x.jar里面找到j(luò)dtCompilerAdapter.jar
還有
org.eclipse.jdt.compiler.tool_1.0.100.v_972_R35x.jar
org.eclipse.jdt.core_3.5.2.v_981_R35x.jar
org.eclipse.jdt.debug.ui_3.4.1.v20090811_r351.jar
jdtCompilerAdapter.jar
并拷貝到ant_home/lib下。
在ant的build.xml腳本中加入
<property name="build.compiler" value="org.eclipse.jdt.core.JDTCompilerAdapter"/>
<javac nowarn="false" debug="true" debuglevel="source,lines,vars" destdir="${dist.path}/classes" source="1.6" target="1.6" encoding="utf-8" fork="true" memoryMaximumSize="512m" includeantruntime="false">
或者
<javac compiler="org.eclipse.jdt.core.JDTCompilerAdapter" nowarn="false" debug="true" debuglevel="source,lines,vars" destdir="${dist.path}/classes" source="1.6" target="1.6" encoding="utf-8" fork="true" memoryMaximumSize="512m" includeantruntime="false"/>
如果是用eclipse運(yùn)行ant腳本,在右鍵菜單選擇從RUN as Ant 啟動(dòng)build.xml時(shí),在對(duì)話框中 選擇Runtime jRE:run in the same JRE as workspace.

記得要引入上面需要的幾個(gè)jar包
摘要: 一、摘要 上兩篇文章分別介紹了Spring3.3 整合 Hibernate3、MyBatis3.2 配置多數(shù)據(jù)源/動(dòng)態(tài)切換數(shù)據(jù)源 方法 和 Spring3 整合Hibernate3.5 動(dòng)態(tài)切換SessionFactory (切換數(shù)據(jù)庫(kù)方言),這篇文章將介紹Spring整合Mybatis 如何完成SqlSessionFactory的動(dòng)態(tài)切換的。并且會(huì)簡(jiǎn)單的介紹下MyBatis整合Spring中的...
閱讀全文
posted @
2013-10-22 10:27 hoojo 閱讀(17005) |
評(píng)論 (3) |
編輯 收藏
摘要: 一、緣由 上一篇文章Spring3.3 整合 Hibernate3、MyBatis3.2 配置多數(shù)據(jù)源/動(dòng)態(tài)切換數(shù)據(jù)源 方法介紹到了怎么樣在Sping、MyBatis、Hibernate整合的應(yīng)用中動(dòng)態(tài)切換DataSource數(shù)據(jù)源的方法,但最終遺留下一個(gè)問題:不能切換數(shù)據(jù)庫(kù)方言。數(shù)據(jù)庫(kù)方言可能在當(dāng)前應(yīng)用的架構(gòu)中意義不是很大,但是如果單純用MyBatis或Hibernate做數(shù)據(jù)庫(kù)持久化操作,還...
閱讀全文
摘要: 一、開篇 這里整合分別采用了Hibernate和MyBatis兩大持久層框架,Hibernate主要完成增刪改功能和一些單一的對(duì)象查詢功能,MyBatis主要負(fù)責(zé)查詢功能。所以在出來數(shù)據(jù)庫(kù)方言的時(shí)候基本上沒有什么問題,但唯一可能出現(xiàn)問題的就是在hibernate做添加操作生成主鍵策略的時(shí)候。因?yàn)槲覀兌贾纇ibernate的數(shù)據(jù)庫(kù)本地方言會(huì)針對(duì)不同的數(shù)據(jù)庫(kù)采用不同的主鍵生成策略。 所以針對(duì)這一問...
閱讀全文
posted @
2013-10-12 10:53 hoojo 閱讀(12374) |
評(píng)論 (5) |
編輯 收藏
摘要: 基于HTTP的長(zhǎng)連接,是一種通過長(zhǎng)輪詢方式實(shí)現(xiàn)"服務(wù)器推"的技術(shù),它彌補(bǔ)了HTTP簡(jiǎn)單的請(qǐng)求應(yīng)答模式的不足,極大地增強(qiáng)了程序的實(shí)時(shí)性和交互性。 一、什么是長(zhǎng)連接、長(zhǎng)輪詢? 用通俗易懂的話來說,就是客戶端不停的向服務(wù)器發(fā)送請(qǐng)求以獲取最新的數(shù)據(jù)信息。這里的“不停”其實(shí)是有停止的,只是我們?nèi)搜蹮o(wú)法分辨是否停止,它只是一種快速的停下然后又立即開始連接而已。 二、長(zhǎng)連接...
閱讀全文
UML是一種通用的建模語(yǔ)言,其表達(dá)能力相當(dāng)?shù)膹?qiáng),不僅可以用于軟件系統(tǒng)的建模,而且可用于業(yè)務(wù)建模以及其它非軟件系統(tǒng)建模。UML綜合了各種面向?qū)ο蠓椒ㄅc表示法的優(yōu)點(diǎn),至提出之日起就受到了廣泛的重視并得到了工業(yè)界的支持。
本章將按視圖、模型元素、圖以及公共機(jī)制依次介紹UML的構(gòu)造和基本元素,以使得讀者對(duì)UML有一個(gè)總體了解,其具體細(xì)節(jié)將在后續(xù)章節(jié)中詳細(xì)描述。
畫圖工具:eDraw、jude


歡迎大家繼續(xù)支持和關(guān)注我的博客:
http://hoojo.cnblogs.com
http://blog.csdn.net/IBM_hoojo
也歡迎大家和我交流、探討IT方面的知識(shí)。
email:hoojo_@126.com
如果你覺得本文不錯(cuò)的話,請(qǐng)你點(diǎn)擊屏幕右下方的 。如果你以后會(huì)用到這篇文章的或覺得以后要重新翻閱的話,你可以點(diǎn)擊屏幕右下角的
。如果你以后會(huì)用到這篇文章的或覺得以后要重新翻閱的話,你可以點(diǎn)擊屏幕右下角的 。如果你覺得我的博文不錯(cuò)或是想在第一時(shí)間看到我的動(dòng)態(tài)的話,你可以點(diǎn)擊屏幕右下角
。如果你覺得我的博文不錯(cuò)或是想在第一時(shí)間看到我的動(dòng)態(tài)的話,你可以點(diǎn)擊屏幕右下角 。如果你想說點(diǎn)什么的話,你可以點(diǎn)擊屏幕右下方的
。如果你想說點(diǎn)什么的話,你可以點(diǎn)擊屏幕右下方的 。如果你都點(diǎn)過了,那真的太謝謝你了,兄弟太支持了。此時(shí),或許你可以點(diǎn)擊
。如果你都點(diǎn)過了,那真的太謝謝你了,兄弟太支持了。此時(shí),或許你可以點(diǎn)擊 按鈕,然后看看博文的導(dǎo)航繼續(xù)瀏覽其他文章。
按鈕,然后看看博文的導(dǎo)航繼續(xù)瀏覽其他文章。
1. UML的組成
UML由視圖(View)、圖(Diagram)、模型元素(Model Element)和通用機(jī)制(General Mechanism)等幾個(gè)部分組成。
a) 視圖(View): 是表達(dá)系統(tǒng)的某一方面的特征的UML建模元素的子集,由多個(gè)圖構(gòu)成,是在某一個(gè)抽象層上,對(duì)系統(tǒng)的抽象表示。
b) 圖(Diagram): 是模型元素集的圖形表示,通常是由弧(關(guān)系)和頂點(diǎn)(其他模型元素)相互連接構(gòu)成的。
c) 模型元素(Model Element):代表面向?qū)ο笾械念悺?duì)象、消息和關(guān)系等概念,是構(gòu)成圖的最基本的常用概念。
d) 通用機(jī)制(General Mechanism):用于表示其他信息,比如注釋、模型元素的語(yǔ)義等。另外,UML還提供擴(kuò)展機(jī)制,使UML語(yǔ)言能夠適應(yīng)一個(gè)特殊的方法(或過程),或擴(kuò)充至一個(gè)組織或用戶。
成")
2. UML視圖的分類
UML是用來描述模型的,用模型來描述系統(tǒng)的機(jī)構(gòu)或靜態(tài)特征,以及行為或動(dòng)態(tài)特征。從不同的視角為系統(tǒng)構(gòu)架建模,形成系統(tǒng)的不同視圖。

(1) 用例視圖(Use Case View),強(qiáng)調(diào)從用戶的角度看到的或需要的系統(tǒng)功能,是被稱為參與者的外部用戶所能觀察到的系統(tǒng)功能的模型圖。
(2) 邏輯視圖(Logical View),展現(xiàn)系統(tǒng)的靜態(tài)或結(jié)構(gòu)組成及特征,也稱為結(jié)構(gòu)模型視圖(Structural Model View)或靜態(tài)視圖(Static View)。
(3) 并發(fā)視圖(Concurrent View),體現(xiàn)了系統(tǒng)的動(dòng)態(tài)或行為特征,也稱為行為模型視圖(Behavioral Model View)或動(dòng)態(tài)視圖(Dynamic View)。
(4) 組件視圖(Component View),體現(xiàn)了系統(tǒng)實(shí)現(xiàn)的結(jié)構(gòu)和行為特征,也稱為實(shí)現(xiàn)模型視圖(Implementation Model View)。
(5) 配置視圖(Deployment View),體現(xiàn)了系統(tǒng)實(shí)現(xiàn)環(huán)境的結(jié)構(gòu)和行為特征,也稱為環(huán)境模型視圖(Environment Model View)或物理視圖(Physical View)。
視圖是由圖組成的,UML提供9種不同的圖:

(1) 用例圖(Use Case Diagram),描述系統(tǒng)功能;
(2) 類圖(Class Diagram),描述系統(tǒng)的靜態(tài)結(jié)構(gòu);
(3) 對(duì)象圖(Object Diagram),描述系統(tǒng)在某個(gè)時(shí)刻的靜態(tài)結(jié)構(gòu);
(4) 組件圖(Component Diagram),描述了實(shí)現(xiàn)系統(tǒng)的元素的組織;
(5) 配置圖(Deployment Diagram),描述了環(huán)境元素的配置,并把實(shí)現(xiàn)系統(tǒng)的元素映射到配置上;
(6) 狀態(tài)圖(State Diagram),描述了系統(tǒng)元素的狀態(tài)條件和響應(yīng);
(7) 時(shí)序圖(Sequence Diagram),按時(shí)間順序描述系統(tǒng)元素間的交互;
(8) 協(xié)作圖(Collaboration Diagram),按照時(shí)間和空間順序描述系統(tǒng)元素間的交互和它們之間的關(guān)系;
(9) 活動(dòng)圖(Activity Diagram),描述了系統(tǒng)元素的活動(dòng);
建模方法由建模語(yǔ)言和建模過程兩部分構(gòu)成。其中建模語(yǔ)言是用來表述設(shè)計(jì)方法的表示法,建模過程是對(duì)設(shè)計(jì)中所應(yīng)采取的步驟的描述。UML是一種建模語(yǔ)言,它在很大程度上獨(dú)立于建模過程。在實(shí)際建模中,建模人員最好把UML用于以用案驅(qū)動(dòng)的、以體系機(jī)構(gòu)為中心的、迭代的和漸增式的開發(fā)過程中。
一般而言,軟件系統(tǒng)的體系結(jié)構(gòu)給出了軟件系統(tǒng)的組織、組成系統(tǒng)的構(gòu)造元素及其接口的選擇、系統(tǒng)的行為和體系結(jié)構(gòu)風(fēng)格等信息。也就是說,它不僅關(guān)心系統(tǒng)的結(jié)構(gòu)和行為等功能性需求,而且也涉及系統(tǒng)的性能、易理解性、易復(fù)用性等非功能性需求。如下圖所示,UML利用用戶模型視圖、結(jié)構(gòu)模型視圖、行為模型視圖、實(shí)現(xiàn)模型視圖和環(huán)境模型視圖來描述軟件系統(tǒng)的體系結(jié)構(gòu)。
根據(jù)它們?cè)诓煌軜?gòu)視圖的應(yīng)用,可以把9種圖分成:

(1) 用戶模型視圖:用例圖;
(2) 結(jié)構(gòu)模型視圖:類圖和對(duì)象;
(3) 行為模型視圖:狀態(tài)圖、時(shí)序圖、協(xié)作圖和活動(dòng)圖(動(dòng)態(tài)圖);
(4) 實(shí)現(xiàn)模型視圖:組件圖;
(5) 環(huán)境模型視圖:配置圖。
用戶模型視圖由專門描述最終用戶、分析人員和測(cè)試人員看到的系統(tǒng)行為的用案組成,它實(shí)際上是從用戶角度來描述系統(tǒng)應(yīng)該具有的功能。用戶模型視圖所描述的系統(tǒng)功能依靠外部用戶或者另外一個(gè)系統(tǒng)來激活,為用戶或者另一系統(tǒng)提供服務(wù),從而實(shí)現(xiàn)用戶或另一系統(tǒng)與系統(tǒng)的交互。系統(tǒng)實(shí)現(xiàn)的最終目標(biāo)是提供用戶模型視圖中所描述的功能。在UML中,用戶模型視圖是由用案圖組成。
結(jié)構(gòu)模型視圖描述組成系統(tǒng)的類、對(duì)象以及它們之間的關(guān)系等靜態(tài)結(jié)構(gòu),用來支持系統(tǒng)的功能需求,即描述系統(tǒng)內(nèi)部功能是如何設(shè)計(jì)的。結(jié)構(gòu)模型視圖由類圖和對(duì)象圖構(gòu)成,主要供設(shè)計(jì)人員和開發(fā)人員使用。
行為模型視圖主要用來描述形成系統(tǒng)并發(fā)與同步機(jī)制的線程和進(jìn)程,其關(guān)注的重點(diǎn)是系統(tǒng)的性能、易伸縮性和系統(tǒng)的吞吐量等非功能性需求。行為模型視圖利用并發(fā)來描述資源的高效使用、并行執(zhí)行和處理異步事件。除了講系統(tǒng)劃分為并發(fā)執(zhí)行的控制線程之外,行為模型還必須處理通信和這些線程及進(jìn)程之間的同步問題。行為模型視圖主要供系統(tǒng)開發(fā)人員和系統(tǒng)集成人員使用,它由序列圖、協(xié)作圖、狀態(tài)圖和活動(dòng)圖組成。
實(shí)現(xiàn)模型視圖用來描述系統(tǒng)的實(shí)現(xiàn)模塊它們之間的依賴關(guān)系以及資源分配情況。這種視圖主要用于系統(tǒng)的配置管理,它是由一些獨(dú)立的構(gòu)件組成的。實(shí)現(xiàn)模型視圖由構(gòu)件圖組成。其中構(gòu)件是代碼模塊,不同類型的代碼模塊形成不同的構(gòu)件。實(shí)現(xiàn)模型視圖主要供開發(fā)人員使用。
環(huán)境模型視圖用來描述物理系統(tǒng)的硬件拓?fù)浣Y(jié)構(gòu)。例如,系統(tǒng)中的計(jì)算機(jī)和設(shè)備的分布情況以及它們之間的連接方式,其中計(jì)算機(jī)和設(shè)備統(tǒng)稱為節(jié)點(diǎn)。在UML中環(huán)境模型視圖是由部署圖來表示的。系統(tǒng)部署圖描述了系統(tǒng)構(gòu)件在節(jié)點(diǎn)上的分布情況,即用來描述軟件構(gòu)件到物理節(jié)點(diǎn)的映射。部署圖主要供開發(fā)人員、系統(tǒng)集成人員和測(cè)試人員使用。
上面每一種視圖反映了系統(tǒng)的一個(gè)特定方面,不同人員可以單獨(dú)的使用其中每一種視圖,從而可以關(guān)注特定的體系結(jié)構(gòu)問題。但在通常情況下,由于系統(tǒng)的最終目標(biāo)是提供用戶模型視圖中描述的功能以及其它一些非功能性需求,因此,用戶模型視圖是其它視圖的核心基礎(chǔ),其它視圖的構(gòu)造都依賴與用戶模型視圖中所描述的類容。
細(xì)心的讀者已經(jīng)發(fā)現(xiàn),每一種UML圖都是由多個(gè)圖組成的,每一種圖都是體系結(jié)構(gòu)某個(gè)側(cè)面的表示,各種圖實(shí)際上是一致的,所有的圖在一起組成了系統(tǒng)的完整視圖。如下圖所示,UML中總共提供了用案圖、類圖、對(duì)象圖、序列圖、協(xié)作圖、狀態(tài)圖、活動(dòng)圖、構(gòu)建圖和部署圖9種圖。根據(jù)它們描述的是系統(tǒng)的靜態(tài)結(jié)構(gòu)還是動(dòng)態(tài)行為,可以將它們分為靜態(tài)圖和動(dòng)態(tài)圖兩類。再進(jìn)一步介紹這9中UML圖時(shí),先了解下什么是模型元素:

3. UML的建模機(jī)制
UML有兩套建模機(jī)制:靜態(tài)建模機(jī)制和動(dòng)態(tài)建模機(jī)制。靜態(tài)建模機(jī)制包括用例圖、類圖、對(duì)象圖、包、組件圖和配置圖。動(dòng)態(tài)建模機(jī)制包括狀態(tài)圖、時(shí)序圖、協(xié)作圖、活動(dòng)圖。
(1) 用例圖:用例的可視化工具,它提供計(jì)算機(jī)系統(tǒng)的高層次的用戶視圖,表示以外部活動(dòng)者的角度來看系統(tǒng)將是怎樣使用的。
用例圖(用案圖)是用于描述一組用案,參與者以及它們之間的連接關(guān)系。一個(gè)用案圖描述了一組動(dòng)作序列,每一個(gè)序列表示系統(tǒng)的外部設(shè)施(系統(tǒng)的參與者)與系統(tǒng)本身的交互。從一個(gè)特定參與者的角度看,一個(gè)用案完成對(duì)其有價(jià)值的工作。如圖2.5所示,用案圖僅僅是從參與者使用系統(tǒng)的角度來描述系統(tǒng)中的信息,即站在系統(tǒng)外部查看系統(tǒng)應(yīng)該具有什么功能,而并不描述該功能在軟件內(nèi)部是如何實(shí)現(xiàn)的。用案可以應(yīng)用于整個(gè)系統(tǒng),也可以應(yīng)用于系統(tǒng)的一個(gè)部分,包括子系統(tǒng)、單個(gè)的類或者接口。通常,用案不僅代表這些元素所期望的行為,而且還可以把這些元素用作開發(fā)過程中測(cè)試用案的基礎(chǔ)。
用例圖包括以下3方面內(nèi)容:
(a) 用例(Use Case)
(b) 參與者(Actor)
(c) 依賴、泛化和關(guān)聯(lián)關(guān)系
用例圖示例:

(2) 類圖:描述類、接口、協(xié)作以及它們之間關(guān)系的圖。
類圖是用于描述一組類、接口、協(xié)作以及它們之間的靜態(tài)關(guān)系。在面向?qū)ο笙到y(tǒng)的建模中,類圖是最為常用的圖,它用來闡明系統(tǒng)的靜態(tài)結(jié)構(gòu)。事實(shí)上類是對(duì)一組具有相同屬性、操作、關(guān)系和語(yǔ)義的對(duì)象的描述,其中對(duì)類的屬性和操作進(jìn)行描述時(shí)的一個(gè)最重要的細(xì)節(jié)就是它的可見性。
類可以以多種形式連接,例如關(guān)聯(lián)、泛化、依賴和實(shí)現(xiàn)等。一個(gè)典型的系統(tǒng)中通常有若干個(gè)類圖。一個(gè)類圖不一定要包含系統(tǒng)中所有的類,一個(gè)類可以加到幾個(gè)類圖中。
類圖示例:

(3) 對(duì)象圖:表示在某一時(shí)間上一組對(duì)象以及它們之間的關(guān)系的圖。對(duì)象圖可以被看做是類圖在系統(tǒng)某一時(shí)刻的實(shí)例。
對(duì)象圖是類圖的實(shí)例,用來描述特定運(yùn)行時(shí)刻一組對(duì)象之間的關(guān)系。也就是說,對(duì)象用于描述交互的靜態(tài)部分,它由參與協(xié)作的有關(guān)對(duì)象組成。但不包括在對(duì)象之間傳遞的任何消息。
在創(chuàng)建對(duì)象圖時(shí),建模人員并不需要用單個(gè)的對(duì)象圖來描述系統(tǒng)中的每一個(gè)對(duì)象。事實(shí)上,絕大多數(shù)系統(tǒng)中都會(huì)包含成百上千的對(duì)象。用對(duì)象來描述系統(tǒng)的所有對(duì)象以及它們之間的關(guān)系一般是不太現(xiàn)實(shí)的。因此,建模人員可以選擇所感興趣的對(duì)象極其之間的關(guān)系來描述。
對(duì)象圖中所使用的符號(hào)和類圖中使用的符號(hào)幾乎完全相同,區(qū)別僅在于對(duì)象圖的對(duì)象名帶有下劃線,而且類與類之間關(guān)系的所有的實(shí)例都要畫出來。

(4) 組件圖:描述軟件組件以及組件之間的關(guān)系,組件本身是代碼的物理模塊,組件圖則顯示了代碼的結(jié)構(gòu)。
組件圖(構(gòu)件圖)是用于描述一組構(gòu)件之間的組織和依賴關(guān)系,用于建模系統(tǒng)的靜態(tài)實(shí)現(xiàn)視圖。構(gòu)件可以是可執(zhí)行程序集、庫(kù)、表、文件和文檔等,它包含了邏輯類或者邏輯類的實(shí)現(xiàn)信息,因此結(jié)構(gòu)模型視圖和實(shí)現(xiàn)模型視圖之間存在映射關(guān)系。
構(gòu)建圖中也可以包括包或子系統(tǒng),它們都是用于將模型元素組成較大的組塊。
組件圖例圖:

(5) 配置圖:描述系統(tǒng)硬件的物理拓?fù)浣Y(jié)構(gòu)以及在此結(jié)構(gòu)上執(zhí)行的軟件。配置圖可以顯示計(jì)算節(jié)點(diǎn)的拓?fù)浣Y(jié)構(gòu)和通信路徑、結(jié)點(diǎn)上運(yùn)行的軟件組件、軟件組件包含的邏輯單元(對(duì)象、類)等。配置圖常常用于幫助理解分布式系統(tǒng)。
配置圖(部署圖)用來描述系統(tǒng)運(yùn)行是進(jìn)行處理的節(jié)點(diǎn)以及在節(jié)點(diǎn)上活動(dòng)的構(gòu)件的配置。部署圖用來對(duì)系統(tǒng)的環(huán)境模型視圖進(jìn)行建模。在大多數(shù)情況下,部署圖用來描述系統(tǒng)硬件的擴(kuò)普結(jié)構(gòu)。
在UML中,建模人員可以用類圖來描述系統(tǒng)的靜態(tài)結(jié)構(gòu),可以用序列圖、協(xié)作圖、狀態(tài)圖、活動(dòng)圖來描述系統(tǒng)的動(dòng)態(tài)行為,而用部署圖來描述軟件所執(zhí)行所需的處理器和設(shè)備的拓?fù)浣Y(jié)構(gòu)。

(6) 狀態(tài)圖:通過類對(duì)象的生命周期建立模型來描述對(duì)象隨時(shí)間變化的動(dòng)態(tài)行為。
狀態(tài)圖實(shí)際上是一種由狀態(tài)、變遷、事件和活動(dòng)組成的狀態(tài)機(jī)。狀態(tài)圖描述從狀態(tài)到狀態(tài)的控制流,常用于系統(tǒng)的動(dòng)態(tài)特性建模。在大多數(shù)情況下,它用來對(duì)反應(yīng)型對(duì)象的行為建模。
在UML中,狀態(tài)圖可以用來對(duì)一個(gè)對(duì)象按事件排序的行為建模。一個(gè)狀態(tài)圖是強(qiáng)調(diào)從狀態(tài)到狀態(tài)的控制流的狀態(tài)機(jī)的簡(jiǎn)單表示。一般而言,狀態(tài)圖是對(duì)類所描述的設(shè)施的補(bǔ)充說明,它描述了類的所有對(duì)象可能具有的狀態(tài)以及引起狀態(tài)變化的事件。

(7) 時(shí)序圖:交互圖描述了一個(gè)交互,它由一組對(duì)象和它們之間的關(guān)系組成,并且還包括在對(duì)象間傳遞的信息。交互圖表達(dá)對(duì)象之間的交互,是描述一組對(duì)象如何協(xié)作完成某個(gè)行為的模型化工具。
序列圖和協(xié)作圖統(tǒng)稱為交互圖。其中,序列圖用來描述對(duì)象之間消息發(fā)送的先后次序,闡明對(duì)象之間的交互過程以及在系統(tǒng)執(zhí)行過程中的某一具體時(shí)刻將會(huì)發(fā)生什么事件。序列圖是一種強(qiáng)調(diào)時(shí)間順序的交互圖,其中對(duì)象沿橫軸方向排列,消息沿縱軸方向排列。
![Product-seq[6]](http://www.tkk7.com/images/blogjava_net/hoojo/WindowsLiveWriter/UMLUML_E9F6/Product-seq%5B6%5D_thumb.png "Product-seq[6]")
序列圖中的對(duì)象生命線是一條垂直的虛線,它表示一個(gè)對(duì)象在一段時(shí)間內(nèi)存在。由于序列圖中大多數(shù)對(duì)象都存在于整個(gè)交互過程中,因此這些對(duì)象全部排列在圖的頂部,它們的生命線從圖的頂部畫到圖的底部。每個(gè)對(duì)象的下方有一個(gè)矩形條,它與對(duì)象的生命線重疊,它表示該對(duì)象的控制焦點(diǎn)。序列圖中的消息可以有序號(hào),但由于這種圖上的消息已經(jīng)從縱軸上按時(shí)間順序排序,因此消息序號(hào)通常予以省略。
(8) 協(xié)作圖:包含類元角色和關(guān)聯(lián)角色,而不僅僅是類元和關(guān)聯(lián)。協(xié)作圖強(qiáng)調(diào)參加交互的各對(duì)象的組織。協(xié)作圖只對(duì)相互間有交互作用的對(duì)象和這些對(duì)象間的關(guān)系建模,而忽略了其他對(duì)象和關(guān)聯(lián)。協(xié)作圖也是一種交互圖,它強(qiáng)調(diào)收發(fā)消息的對(duì)象的組織結(jié)構(gòu)。
協(xié)作圖和序列圖是協(xié)作的,它們可以互相轉(zhuǎn)換。在多數(shù)情況下,協(xié)作圖主要對(duì)單調(diào)的、順序的控制流建模,但它也可以用來對(duì)包括迭代和分支在內(nèi)的復(fù)雜控制流進(jìn)行建模。
一般而言,建模人員可以創(chuàng)建多個(gè)協(xié)作圖,其中一些是主要的,另外一些是可選擇的路徑或者異常條件。建模人員可以用包來組織這些協(xié)作圖,并給每個(gè)圖起一個(gè)合適的名字,以便與其它圖區(qū)別開。

(9) 活動(dòng)圖:用于展現(xiàn)參與行為的類的活動(dòng)或動(dòng)作。
活動(dòng)圖是狀態(tài)圖的一種特殊情況,其中幾乎所有或大多數(shù)狀態(tài)都處于活動(dòng)狀態(tài),而且?guī)缀跛谢蛘叽蠖鄶?shù)變遷都是由源狀態(tài)中活動(dòng)的完成觸發(fā)的。活動(dòng)圖本質(zhì)上是一種流程圖,它描述了從活動(dòng)到活動(dòng)的控制流。
可以把活動(dòng)圖看作是新樣的交互圖,但交互圖觀察的是傳遞消息的對(duì)象,而活動(dòng)圖觀察到的是對(duì)象之間傳送的消息。盡管兩者在語(yǔ)義上的區(qū)別很細(xì)微,但它們使用不同的方式來看系統(tǒng)的。

如果你覺得本文不錯(cuò)的話,請(qǐng)你點(diǎn)擊屏幕右下方的 。如果你以后會(huì)用到這篇文章的或覺得以后要重新翻閱的話,你可以點(diǎn)擊屏幕右下角的 。如果你覺得我的博文不錯(cuò)或是想在第一時(shí)間看到我的動(dòng)態(tài)的話,你可以點(diǎn)擊屏幕右下角 。如果你想說點(diǎn)什么的話,你可以點(diǎn)擊屏幕右下方的 。如果你都點(diǎn)過了,那真的太謝謝你了,兄弟太支持了。此時(shí),或許你可以點(diǎn)擊 按鈕,然后看看博文的導(dǎo)航繼續(xù)瀏覽其他文章。
最后,歡迎大家繼續(xù)支持和關(guān)注我的博客:
http://hoojo.cnblogs.com
http://blog.csdn.net/IBM_hoojo
也歡迎大家和我交流、探討IT方面的知識(shí)。
摘要: 在flex組件中嵌入html代碼,可以利用flex iframe。這個(gè)在很多時(shí)候會(huì)用到的,有時(shí)候flex必須得這樣做,如果你不這樣做還真不行…… flex而且可以和html進(jìn)行JavaScript交互操作,flex調(diào)用到html中的JavaScript方法以及獲取調(diào)用后的返回值。 1、flex iframe下載地址:https://github.com/downloads/flex...
閱讀全文
一、UML中的六大關(guān)系
在UML類圖中,常見的有以下幾種關(guān)系: 泛化(Generalization), 實(shí)現(xiàn)(Realization),關(guān)聯(lián)(Association),聚合(Aggregation),組合(Composition),依賴(Dependency)。

1.1、 繼承關(guān)系—泛化(Generalization)
指的是一個(gè)類(稱為子類、子接口)繼承另外的一個(gè)類(稱為父類、父接口)的功能,并可以增加它自己的新功能的能力,繼承是類與類或者接口與接口之間最常見的關(guān)系;在Java中用extends關(guān)鍵字。

【泛化關(guān)系】是一種繼承關(guān)系,表示一般與特殊的關(guān)系,它指定了子類如何特化父類的所有特征和行為。例如:貓頭鷹是鳥的一種,即有鳥的特性也有貓頭鷹的共性。
【箭頭指向】帶三角箭頭的實(shí)線,箭頭指向父類。
【描述】上圖中的類bird有嘴、翅膀、羽毛等屬性。會(huì)飛、會(huì)唧唧喳喳的叫,那么就有這些方法。而貓頭鷹有大眼睛和捕捉老鼠的本領(lǐng),這則是自身的特性。
1.2、 實(shí)現(xiàn)關(guān)系(Realization)
指的是一個(gè)class類實(shí)現(xiàn)interface接口(可以是多個(gè))的功能;實(shí)現(xiàn)是類與接口之間最常見的關(guān)系;在Java中此類關(guān)系通過關(guān)鍵字implements明確標(biāo)識(shí)。

【實(shí)現(xiàn)關(guān)系】是一種類與接口的關(guān)系,表示類是接口所有特征和行為的實(shí)現(xiàn).
【箭頭指向】帶三角箭頭的虛線,箭頭指向接口。
【描述】上圖中IFly是一個(gè)接口,接口中有時(shí)間、速度等常量,還有一個(gè)fly方法。FlyImpl繼承了這個(gè)IFly接口后,需要實(shí)現(xiàn)fly方法,同時(shí)實(shí)現(xiàn)類也可以擁有自己的屬性和方法。
1.3、 依賴(Dependency)
可以簡(jiǎn)單的理解,就是一個(gè)類A使用到了另一個(gè)類B,而這種使用關(guān)系是具有偶然性的、臨時(shí)性的、非常弱的,但是B類的變化會(huì)影響到A;比如某人要過河,需要借用一條船,此時(shí)人與船之間的關(guān)系就是依賴;表現(xiàn)在代碼層面,為類B作為參數(shù)、屬性被類A在某個(gè)method方法中使用;

【依賴關(guān)系】是一種使用的關(guān)系,即一個(gè)類的實(shí)現(xiàn)需要另一個(gè)類的協(xié)助,所以要盡量不使用雙向的互相依賴。
【代碼表現(xiàn)】局部變量、方法的參數(shù)或者對(duì)靜態(tài)方法的調(diào)用
【箭頭及指向】帶箭頭的虛線,指向被使用者
【描述】Bird類中有一個(gè)setFly方法,它需要使用者用到IFly接口的實(shí)現(xiàn),那么這種關(guān)系就是依賴關(guān)系。
1.4、 關(guān)聯(lián)
他體現(xiàn)的是兩個(gè)類、或者類與接口之間語(yǔ)義級(jí)別的一種強(qiáng)依賴關(guān)系,比如我和我的朋友;這種關(guān)系比依賴更強(qiáng)、不存在依賴關(guān)系的偶然性、關(guān)系也不是臨時(shí)性的,一般是長(zhǎng)期性的,而且雙方的關(guān)系一般是平等的、關(guān)聯(lián)可以是單向、雙向的;表現(xiàn)在代碼層面,為被關(guān)聯(lián)類B以類屬性的形式出現(xiàn)在關(guān)聯(lián)類A中,也可能是關(guān)聯(lián)類A引用了一個(gè)類型為被關(guān)聯(lián)類B的全局變量;

【關(guān)聯(lián)關(guān)系】是一種擁有的關(guān)系,它使一個(gè)類知道另一個(gè)類的屬性和方法;如:老師與學(xué)生,丈夫與妻子關(guān)聯(lián)可以是雙向的,也可以是單向的。雙向的關(guān)聯(lián)可以有兩個(gè)箭頭或者沒有箭頭,單向的關(guān)聯(lián)有一個(gè)箭頭。
【代碼體現(xiàn)】成員變量
【箭頭及指向】帶普通箭頭的實(shí)心線,指向被擁有者
【描述】在Bird類中有一個(gè)IFly類型的fly屬性,需要提供IFly的接口實(shí)現(xiàn)。Bird對(duì)象會(huì)利用IFly接口的實(shí)現(xiàn)完成fly方法。
1.4.1、雙向關(guān)聯(lián)
雙方都知道對(duì)方的存在,都可以調(diào)用對(duì)方的公共屬性、方法。

【關(guān)聯(lián)關(guān)系】雙方都有關(guān)聯(lián)的關(guān)系,通過自身對(duì)對(duì)方關(guān)聯(lián)的屬性來訪問對(duì)方的屬性和方法。
【代碼體現(xiàn)】成員變量
【箭頭及指向】用不帶箭頭的實(shí)線連接雙方
【描述】在中國(guó)一個(gè)妻子只能嫁給一個(gè)丈夫,一個(gè)丈夫也只能取一個(gè)妻子。
1.4.2、自身關(guān)聯(lián)
自己關(guān)聯(lián)自己,這種情況比較少出現(xiàn)但是也有用到。

【自關(guān)聯(lián)關(guān)系】雙方都有關(guān)聯(lián)的關(guān)系,通過自身對(duì)自身關(guān)聯(lián)的屬性引用來訪問對(duì)方的屬性和方法。
【代碼體現(xiàn)】成員變量
【箭頭及指向】用帶普通箭頭的實(shí)線連接自己
【描述】在盜夢(mèng)空間中,演員需要在夢(mèng)中再造夢(mèng),這種夢(mèng)中夢(mèng)的情況跟上圖描述很符合。
1.5、 聚合(Aggregation)
聚合是關(guān)聯(lián)關(guān)系的一種特例,他體現(xiàn)的是整體與部分、擁有的關(guān)系,即has-a的關(guān)系,此時(shí)整體與部分之間是可分離的,他們可以具有各自的生命周期,部分可以屬于多個(gè)整體對(duì)象,也可以為多個(gè)整體對(duì)象共享;比如計(jì)算機(jī)與CPU、公司與員工的關(guān)系等;表現(xiàn)在代碼層面,和關(guān)聯(lián)關(guān)系是一致的,只能從語(yǔ)義級(jí)別來區(qū)分;

【聚合關(guān)系】是整體與部分的關(guān)系,且部分可以離開整體而單獨(dú)存在。如車和輪胎是整體和部分的關(guān)系,輪胎離開車仍然可以存在。聚合關(guān)系是關(guān)聯(lián)關(guān)系的一種,是強(qiáng)的關(guān)聯(lián)關(guān)系;關(guān)聯(lián)和聚合在語(yǔ)法上無(wú)法區(qū)分,必須考察具體的邏輯關(guān)系。
【代碼體現(xiàn)】成員變量
【箭頭及指向】帶空心菱形的實(shí)心線,菱形指向整體
【描述】birdChild一只鳥有很多鳥寶寶,所以自引用。鳥有很多不同數(shù)量和顏色的羽毛,所以引用關(guān)系是0~*。
1.6、 組合(Composition)
組合也是關(guān)聯(lián)關(guān)系的一種特例,他體現(xiàn)的是一種contains-a的關(guān)系,這種關(guān)系比聚合更強(qiáng),也稱為強(qiáng)聚合;他同樣體現(xiàn)整體與部分間的關(guān)系,但此時(shí)整體與部分是不可分的,整體的生命周期結(jié)束也就意味著部分的生命周期結(jié)束;比如你和你的大腦;表現(xiàn)在代碼層面,和關(guān)聯(lián)關(guān)系是一致的,只能從語(yǔ)義級(jí)別來區(qū)分;

【組合關(guān)系】是整體與部分的關(guān)系,但部分不能離開整體而單獨(dú)存在。如公司和部門是整體和部分的關(guān)系,沒有公司就不存在部門。組合關(guān)系是關(guān)聯(lián)關(guān)系的一種,是比聚合關(guān)系還要強(qiáng)的關(guān)系,它要求普通的聚合關(guān)系中代表整體的對(duì)象負(fù)責(zé)代表部分的對(duì)象的生命周期。
【代碼體現(xiàn)】成員變量
【箭頭及指向】帶實(shí)心菱形的實(shí)線,菱形指向整體
【描述】一個(gè)學(xué)校由多個(gè)班級(jí)組成,班級(jí)離開學(xué)校也就不存在、而學(xué)校離開班級(jí)也不成立。像這種不可分離的關(guān)系就需要用組合。
綜合示例

對(duì)于繼承、實(shí)現(xiàn)這兩種關(guān)系沒多少疑問,他們體現(xiàn)的是一種類與類、或者類與接口間的縱向關(guān)系;其他的四者關(guān)系則體現(xiàn)的是類與類、或者類與接口間的引用、橫向關(guān)系,是比較難區(qū)分的,有很多事物間的關(guān)系要想準(zhǔn)備定位是很難的,前面也提到,這幾種關(guān)系都是語(yǔ)義級(jí)別的,所以從代碼層面并不能完全區(qū)分各種關(guān)系;但總的來說,后幾種關(guān)系所表現(xiàn)的強(qiáng)弱程度依次為:泛化 = 實(shí)現(xiàn) > 組合 > 聚合 > 關(guān)聯(lián) > 依賴。
異常信息如下:
org.springframework.beans.ConversionNotSupportedException: Failed to convert property value of type 'java.util.Date' to required type 'java.sql.Timestamp' for property 'wfsj'; nested exception is java.lang.IllegalStateException: Cannot convert value of type [java.util.Date] to required type [java.sql.Timestamp] for property 'wfsj': no matching editors or conversion strategy found
at org.springframework.beans.BeanWrapperImpl.convertIfNecessary(BeanWrapperImpl.java:463)
at org.springframework.beans.BeanWrapperImpl.convertForProperty(BeanWrapperImpl.java:494)
at org.springframework.beans.BeanWrapperImpl.setPropertyValue(BeanWrapperImpl.java:1097)
at org.springframework.beans.BeanWrapperImpl.setPropertyValue(BeanWrapperImpl.java:882)
at org.springframework.flex.core.io.SpringPropertyProxy.setValue(SpringPropertyProxy.java:182)
at flex.messaging.io.amf.Amf3Input.readScriptObject(Amf3Input.java:438)
at flex.messaging.io.amf.Amf3Input.readObjectValue(Amf3Input.java:152)
at flex.messaging.io.amf.Amf3Input.readObject(Amf3Input.java:130)
at flex.messaging.io.amf.Amf3Input.readArray(Amf3Input.java:358)
…………
at flex.messaging.io.amf.AmfMessageDeserializer.readObject(AmfMessageDeserializer.java:227)
at flex.messaging.io.amf.AmfMessageDeserializer.readBody(AmfMessageDeserializer.java:206)
at flex.messaging.io.amf.AmfMessageDeserializer.readMessage(AmfMessageDeserializer.java:126)
at flex.messaging.endpoints.amf.SerializationFilter.invoke(SerializationFilter.java:145)
at flex.messaging.endpoints.BaseHTTPEndpoint.service(BaseHTTPEndpoint.java:291)
at flex.messaging.endpoints.AMFEndpoint$$EnhancerByCGLIB$$6f090fa2.service(<generated>)
at org.springframework.flex.servlet.MessageBrokerHandlerAdapter.handle(MessageBrokerHandlerAdapter.java:109)
…………
Caused by: java.lang.IllegalStateException: Cannot convert value of type [java.util.Date] to required type [java.sql.Timestamp] for property 'wfsj': no matching editors or conversion strategy found
at org.springframework.beans.TypeConverterDelegate.convertIfNecessary(TypeConverterDelegate.java:264)
at org.springframework.beans.BeanWrapperImpl.convertIfNecessary(BeanWrapperImpl.java:448)
... 59 more
看異常信息大概知道屬性wfsj這個(gè)字段,不能完成java.util.Date 到 java.sql.Timestamp 日期時(shí)間戳的轉(zhuǎn)換。后面還有提示, 沒有找到匹配的conversion或editor。
conversion 在Spring中轉(zhuǎn)換對(duì)象屬性會(huì)用到,而editor和converter 以及formatter也是在轉(zhuǎn)換對(duì)象(String –> Date, String –> Timestamp),從字符串到對(duì)象,從對(duì)象到字符串的時(shí)候會(huì)經(jīng)常用到。
解決方法:
<bean id="customConfigProcessor" class="com.jp.tic.framework.flex.converter.CustomAmfConversionServiceConfigProcessor"/>
<flex:message-broker services-config-path="/WEB-INF/flex/services-config.xml">
<flex:exception-translator ref="flexExceptionTranslator" />
<flex:config-processor ref="configProcessor"/>
<flex:config-processor ref="customConfigProcessor"/>
<!--<flex:message-interceptor ref="flexMessageInterceptor" />
<flex:message-interceptor ref="loginMessageInterceptor" />-->
</flex:message-broker>
為message-broker對(duì)象注入CustomAmfConversionServiceConfigProcessor對(duì)象,CustomAmfConversionServiceConfigProcessor是繼承AbstractAmfConversionServiceConfigProcessor對(duì)象。
AbstractAmfConversionServiceConfigProcessor對(duì)象中提供了對(duì)各個(gè)類型轉(zhuǎn)換serialization/deserialization的方法。
package com.jp.tic.framework.flex.converter;
import java.util.HashSet;
import java.util.Set;
import org.springframework.flex.core.io.AbstractAmfConversionServiceConfigProcessor;
/**
* <b>function:</b> 自定義AMF轉(zhuǎn)換服務(wù)
* @author hoojo
* @createDate 2013-7-17 下午01:35:12
* @file CustomAmfConversionServiceConfigProcessor.java
* @package com.jp.tic.framework.flex.converter
* @project JTZHJK-Server
* @blog http://blog.csdn.net/IBM_hoojo
* @email hoojo_@126.com
* @version 1.0
*/
public class CustomAmfConversionServiceConfigProcessor extends AbstractAmfConversionServiceConfigProcessor {
private static Set<Class<?>> classes = new HashSet<Class<?>>();
@Override
protected Set<Class<?>> findTypesToRegister() { return classes;
}
}
如果你還需要添加更多自己的轉(zhuǎn)化服務(wù),那么你需要給CustomAmfConversionServiceConfigProcessor 注入conversionService對(duì)象。
<!-- 添加配置類型轉(zhuǎn)換器、轉(zhuǎn)換服務(wù) -->
<bean id="conversionService" class="org.springframework.format.support.FormattingConversionServiceFactoryBean">
<property name="converters">
<list>
<bean class="com.jp.tic.framework.mvc.convert.StringToTimestampConverter"/>
<bean class="com.jp.tic.framework.mvc.convert.DateToTimestampConverter"/>
</list>
</property>
<property name="formatters">
<list>
<bean class="com.jp.tic.framework.mvc.formatter.SimpleDateTimeFormatAnnotationFormatterFactory"/>
<bean class="com.jp.tic.framework.mvc.formatter.TimestampFormatterFactory"/>
</list>
</property>
</bean>
<bean id="customConfigProcessor" class="com.jp.tic.framework.flex.converter.CustomAmfConversionServiceConfigProcessor">
<property name="conversionService" ref="conversionService"/>
</bean>
摘要: 一、 概述與介紹 ActiveMQ 是Apache出品,最流行的、功能強(qiáng)大的即時(shí)通訊和集成模式的開源服務(wù)器。ActiveMQ 是一個(gè)完全支持JMS1.1和J2EE 1.4規(guī)范的 JMS Provider實(shí)現(xiàn)。提供客戶端支持跨語(yǔ)言和協(xié)議,帶有易于在充分支持JMS 1.1和1.4使用J2EE企業(yè)集成模式和許多先進(jìn)的功能。 二、 特性 1、 多種語(yǔ)言和協(xié)議編寫客戶端。語(yǔ)言: Java...
閱讀全文
摘要: 一、概述 ant 是一個(gè)將軟件編譯、測(cè)試、部署等步驟聯(lián)系在一起加以自動(dòng)化的一個(gè)工具,大多用于Java環(huán)境中的軟件開發(fā)。在實(shí)際軟件開發(fā)中,有很多地方可以用到ant。 開發(fā)環(huán)境: System:Windows JDK:1.6+ IDE:eclipse ant:1.9.1 Email:hoojo_@126.com Blog:http://blog.csdn....
閱讀全文
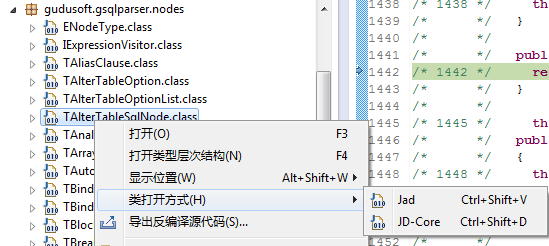
Eclipse下的Java反編譯插件:Eclipse Class Decompiler,整合了目前最好的2個(gè)Java反編譯工具Jad和JD-Core,并且和Eclipse Class Viewer無(wú)縫集成,能夠很方便的使用本插件查看類庫(kù)源碼,以及采用本插件進(jìn)行Debug調(diào)試。
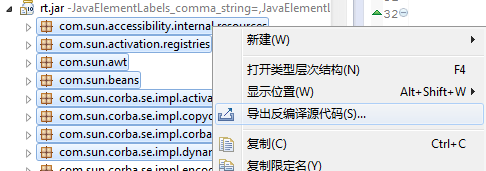
轉(zhuǎn)載自:http://bbs.csdn.net/topics/390263414
Eclipse Class Decompiler插件: http://download.csdn.net/detail/ibm_hoojo/5250263
下載后,解壓可以看到如下目錄,復(fù)制所有文件粘貼到你的eclipse或MyEclipse的目錄:D:\MyEclipse 6.5\myeclipse\eclipse下,選擇覆蓋即可。然后重新啟動(dòng)eclipse。

下圖為Eclipse Class Decompiler的首選項(xiàng)頁(yè)面,可以選擇缺省的反編譯器工具,并進(jìn)行反編譯器的基本設(shè)置。缺省的反編譯工具為JD-Core,JD-Core更為先進(jìn)一些,支持泛型、Enum、注解等JDK1.5以后才有的新語(yǔ)法。
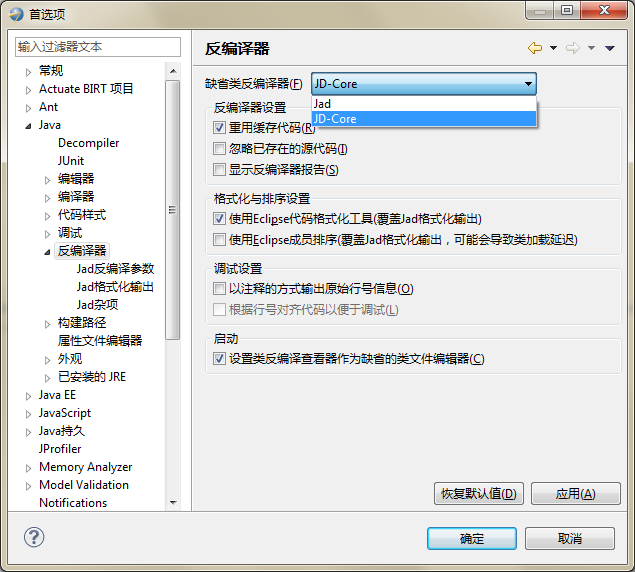
首選項(xiàng)配置選項(xiàng):
1.重用緩存代碼:只會(huì)反編譯一次,以后每次打開該類文件,都顯示的是緩存的反編譯代碼。
2.忽略已存在的源代碼:若未選中,則查看Class文件是否已綁定了Java源代碼,如果已綁定,則顯示Java源代碼,如果未綁定,則反編譯Class文件。若選中此項(xiàng),則忽略已綁定的Java源代碼,顯示反編譯結(jié)果。
3.顯示反編譯器報(bào)告:顯示反編譯器反編譯后生成的數(shù)據(jù)報(bào)告及異常信息。
4.使用Eclipse代碼格式化工具:使用Eclipse格式化工具對(duì)反編譯結(jié)果重新格式化排版,反編譯整個(gè)Jar包時(shí),此操作會(huì)消耗一些時(shí)間。
5.使用Eclipse成員排序:使用Eclipse成員排序?qū)Ψ淳幾g結(jié)果重新格式化排版,反編譯整個(gè)Jar包時(shí),此操作會(huì)消耗大量時(shí)間。
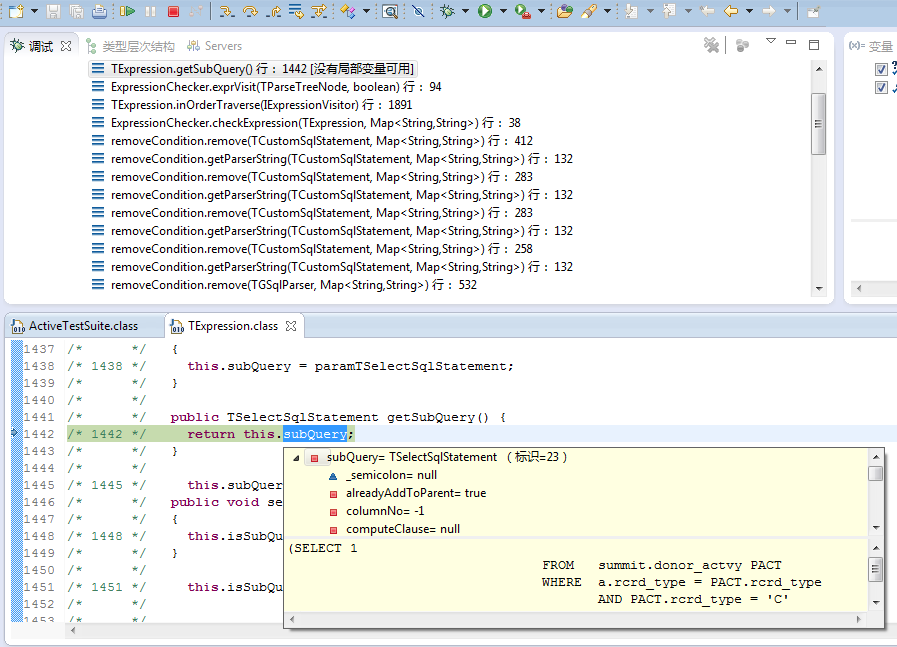
6.以注釋方式輸出原始行號(hào)信息:如果Class文件包含原始行號(hào)信息,則會(huì)將行號(hào)信息以注釋的方式打印到反編譯結(jié)果中。
7.根據(jù)行號(hào)對(duì)齊源代碼以便于調(diào)試:若選中該項(xiàng),插件會(huì)采用AST工具分析反編譯結(jié)果,并根據(jù)行號(hào)信息調(diào)整代碼順序,以便于Debug過程中的單步跟蹤調(diào)試。
8.設(shè)置類反編譯查看器作為缺省的類文件編輯器:默認(rèn)為選中,將忽略Eclipse自帶的Class Viewer,每次Eclipse啟動(dòng)后,默認(rèn)使用本插件提供的類查看器打開Class文件。
插件提供了系統(tǒng)菜單,工具欄,當(dāng)打開了插件提供的類反編譯查看器后,會(huì)激活菜單和工具欄選項(xiàng),可以方便的進(jìn)行首選項(xiàng)配置,切換反編譯工具重新反編譯,以及導(dǎo)出反編譯結(jié)果。
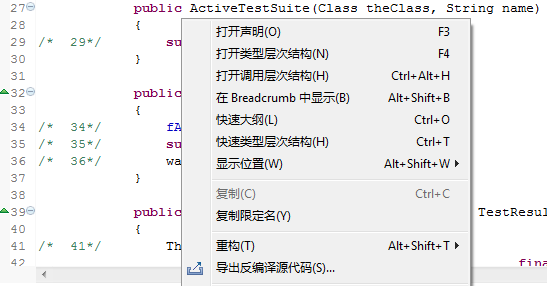
類反編譯查看器右鍵菜單包含了Eclipse自帶類查看器右鍵菜單的全部選項(xiàng),并增加了一個(gè)“導(dǎo)出反編譯源代碼”菜單項(xiàng)。
打開項(xiàng)目路徑下的Class文件,如果設(shè)置類反編譯查看器為缺省的查看器,直接雙擊Class文件即可,如果沒有設(shè)置為缺省查看器,可以使用右鍵菜單進(jìn)行查看。
Eclipse Class Decompiler插件也提供了反編譯整個(gè)Jar文件或者Java包的反編譯。該操作支持Package Explorer對(duì)包顯示布局的操作,如果是平鋪模式布局,則導(dǎo)出的源代碼不包含子包,如果是層級(jí)模式布局,則導(dǎo)出選中的包及其所有的子包。
Debug調(diào)試:可以在首選項(xiàng)選中對(duì)齊行號(hào)進(jìn)行單步跟蹤調(diào)試,和普通的包含源代碼時(shí)的調(diào)試操作完全一致,同樣的也可以設(shè)置斷點(diǎn)進(jìn)行跟蹤。
轉(zhuǎn)載:http://bbs.csdn.net/topics/390263414
摘要: 上一篇文章介紹到怎么在自己的Java環(huán)境中搭建openfire插件開發(fā)的環(huán)境,同時(shí)介紹到怎樣一步步簡(jiǎn)單的開發(fā)openfire插件。一步步很詳細(xì)的介紹到簡(jiǎn)單插件開發(fā),帶Servlet的插件的開發(fā)、帶JSP頁(yè)面插件的開發(fā),以及怎么樣將開發(fā)好的插件打包、部署到openfire服務(wù)器。 如果你沒有看上一篇文章的話,請(qǐng)你還是看看。http://www.cnblogs.com/hoojo/ar...
閱讀全文
摘要: 這篇是簡(jiǎn)單插件開發(fā),下篇聊天記錄插件。 開發(fā)環(huán)境: System:Windows WebBrowser:IE6+、Firefox3+ JavaEE Server:tomcat5.0.2.8、tomcat6 IDE:eclipse、MyEclipse 8 開發(fā)依賴庫(kù): Jdk1.6、jasper-compiler.jar、jasper-runtime.jar、openfire.jar...
閱讀全文
posted @
2013-03-07 11:25 hoojo 閱讀(10380) |
評(píng)論 (1) |
編輯 收藏 本人是做Java開發(fā)的,在程序開發(fā)中會(huì)經(jīng)常使用到OpenSource開源框架,這些框架大多都靈活、簡(jiǎn)單、易用、方便。而且開源框架一般會(huì)提供一些基本的配置,如我們常用的框架就有Hibernate要配置對(duì)象實(shí)體到數(shù)據(jù)庫(kù)的映射;Spring要配置bean的管理及其對(duì)象、屬性的注入;Struts要配置Action對(duì)象和返回的資源路徑;MyBatis要配置CRUD(增刪改查)的相關(guān)SQL語(yǔ)句。這些配置你不能省略,必須得有,沒有程序也不會(huì)自動(dòng)添加。我們也是極可能的簡(jiǎn)化這些配置,不管怎么樣簡(jiǎn)化但這些配置是不能省略,雖然這些框架給我們開發(fā)程序都提供了很大方面上的便利。
但有時(shí)候你是否有糾結(jié)這么樣的一個(gè)問題:到底是用XML配置?還是用Annotation注解配置?或是用XML和Annotation混合配置?
首先看看兩種配置的優(yōu)缺點(diǎn)比較
XML它是無(wú)可代替的超文本標(biāo)記語(yǔ)言,可讀性、傳輸性好,它還具有一下優(yōu)點(diǎn):
1、可讀性、傳輸性好:XML可擴(kuò)展標(biāo)記語(yǔ)言,最大的優(yōu)勢(shì)在于開發(fā)者能夠?yàn)檐浖可矶ㄖ七m用的標(biāo)記,使代碼可讀性大大提升。
2、靈活性、易用性、擴(kuò)展性、移植性好:利用XML配置能使軟件更具擴(kuò)展性。如Spring將class間的依賴配置在XML中,最大限度地提升應(yīng)用的可擴(kuò)展性。同樣,如果是基于接口注入方式,可以隨便切換接口實(shí)現(xiàn)類進(jìn)行注入即可。
3、驗(yàn)證機(jī)制:具有成熟的驗(yàn)證機(jī)制確保程序正確性。利用Schema或DTD可以對(duì)XML的正確性進(jìn)行驗(yàn)證,避免了非法的配置導(dǎo)致應(yīng)用程序出錯(cuò)。
4、修改配置而無(wú)需變動(dòng)現(xiàn)有程序、無(wú)需重新編譯。
雖然XML有如此多的好處,但它也不是萬(wàn)能的,XML也有自身的缺點(diǎn):
1、開發(fā)友好性支持:需要解析工具或類庫(kù)的支持。如果你的XML配置需要用到XML的提示或是解析編譯,需要用到Schema或DTD進(jìn)行驗(yàn)證。
2、性能影響:解析XML勢(shì)必會(huì)影響應(yīng)用程序性能,占用系統(tǒng)資源。至少你會(huì)用到一些解析XML的技術(shù)去解析節(jié)點(diǎn)元素內(nèi)容。
3、維護(hù)性高:配置文件過多導(dǎo)致管理變得困難。
4、編譯期無(wú)法對(duì)其配置項(xiàng)的正確性進(jìn)行驗(yàn)證,或要查錯(cuò)只能在運(yùn)行期。如Spring Bean配置了一個(gè)錯(cuò)誤的類路徑class。
5、IDE 無(wú)法驗(yàn)證配置項(xiàng)的正確性無(wú)能為力。如Spring注入一個(gè)錯(cuò)誤的對(duì)象或?qū)傩浴?br>6、查錯(cuò)變得困難。往往配置的一個(gè)手誤導(dǎo)致莫名其妙的錯(cuò)誤。
7、開發(fā)人員不得不同時(shí)維護(hù)代碼和配置文件,開發(fā)效率變得低下。
8、配置項(xiàng)與代碼間存在潛規(guī)則,改變了任何一方都有可能影響另外一方。
讓我們來看看Annotation的優(yōu)點(diǎn)
1、保存在class文件中,降低維護(hù)成本。
2、無(wú)需工具支持,無(wú)需解析。
3、編譯期即可驗(yàn)證正確性,查錯(cuò)變得容易,雖然有部分錯(cuò)誤需要在運(yùn)行期間才能看到。
4、配置簡(jiǎn)單、簡(jiǎn)約,提升開發(fā)效率。
同樣Annotation也不是萬(wàn)能的,它也有很多缺點(diǎn)
1、若要對(duì)配置項(xiàng)進(jìn)行修改,不得不修改Java文件,重新編譯打包應(yīng)用。
2、配置項(xiàng)編碼在Java文件中,可擴(kuò)展性差、移植性性低。
那到底用什么樣的配置呢,在這里我談?wù)勎覀€(gè)人的看法:
1、在開發(fā)期間我們用Annotation注解,這樣在一定程度上不僅可以省去對(duì)XML配置文件的維護(hù),而且大大的提高了開發(fā)效率,縮短了開發(fā)周期。
2、開發(fā)后期,項(xiàng)目功能完成,我們可以將Annotation配置轉(zhuǎn)換為XML配置,禁用Annotation即可。這樣做的理由是如果項(xiàng)目上線,我們需要修改相關(guān)代碼的配置,直接改XML、properties配置文件即可。這樣就不需要開發(fā)人員找到相應(yīng)的代碼修改源代碼、重新編譯打包發(fā)布。而xml的配置是可以直接修改的,不需要重新編譯,只需重啟下你的服務(wù)器即可。
如果這樣是不是即利用到框架給我們提供的Annotation注解,也利用到了XML配置。充分的發(fā)揮了開源框架給我們提供的技術(shù)應(yīng)用。
3、混合模式,Annotation和XML相互運(yùn)用。需要?jiǎng)討B(tài)配置、后期經(jīng)常性修改的就用XML配置,如果是不怎么修改的就用Annotation。或許這種混合模式更適合我們,你覺得呢?O(∩_∩)O~
1. 全文檢索系統(tǒng)與Lucene簡(jiǎn)介
1.1 什么是全文檢索與全文檢索系統(tǒng)
全文檢索是指計(jì)算機(jī)索引程序通過掃描文章中的每一個(gè)詞,對(duì)每一個(gè)詞建立一個(gè)索引,指明該詞在文章中出現(xiàn)的次數(shù)和位置,當(dāng)用戶查詢時(shí),檢索程序就根據(jù)事先建立的索引進(jìn)行查找,并將查找的結(jié)果反饋給用戶的檢索方式。這個(gè)過程類似于通過字典中的檢索字表查字的過程。
全文檢索的方法主要分為按字檢索和按詞檢索兩種。按字檢索是指對(duì)于文章中的每一個(gè)字都建立索引,檢索時(shí)將詞分解為字的組合。對(duì)于各種不同的語(yǔ)言而言,字有不同的含義,比如英文中字與詞實(shí)際上是合一的,而中文中字與詞有很大分別。按詞檢索指對(duì)文章中的詞,即語(yǔ)義單位建立索引,檢索時(shí)按詞檢索,并且可以處理同義項(xiàng)等。英文等西方文字由于按照空白切分詞,因此實(shí)現(xiàn)上與按字處理類似,添加同義處理也很容易。中文等東方文字則需要切分字詞,以達(dá)到按詞索引的目的,關(guān)于這方面的問題,是當(dāng)前全文檢索技術(shù)尤其是中文全文檢索技術(shù)中的難點(diǎn),在此不做詳述。
全文檢索系統(tǒng)是按照全文檢索理論建立起來的用于提供全文檢索服務(wù)的軟件系統(tǒng)。一般來說,全文檢索需要具備建立索引和提供查詢的基本功能,此外現(xiàn)代的全文檢索系統(tǒng)還需要具有方便的用戶接口、面向WWW[1]的開發(fā)接口、二次應(yīng)用開發(fā)接口等等。功能上,全文檢索系統(tǒng)核心具有建立索引、處理查詢返回結(jié)果集、增加索引、優(yōu)化索引結(jié)構(gòu)等等功能,外圍則由各種不同應(yīng)用具有的功能組成。結(jié)構(gòu)上,全文檢索系統(tǒng)核心具有索引引擎、查詢引擎、文本分析引擎、對(duì)外接口等等,加上各種外圍應(yīng)用系統(tǒng)等等共同構(gòu)成了全文檢索系統(tǒng)。圖1.1展示了上述全文檢索系統(tǒng)的結(jié)構(gòu)與功能。

在上圖中,我們看到:全文檢索系統(tǒng)中最為關(guān)鍵的部分是全文檢索引擎,各種應(yīng)用程序都需要建立在這個(gè)引擎之上。一個(gè)全文檢索應(yīng)用的優(yōu)異程度,根本上由全文檢索引擎來決定。因此提升全文檢索引擎的效率即是我們提升全文檢索應(yīng)用的根本。另一個(gè)方面,一個(gè)優(yōu)異的全文檢索引擎,在做到效率優(yōu)化的同時(shí),還需要具有開放的體系結(jié)構(gòu),以方便程序員對(duì)整個(gè)系統(tǒng)進(jìn)行優(yōu)化改造,或者是添加原有系統(tǒng)沒有的功能。比如在當(dāng)今多語(yǔ)言處理的環(huán)境下,有時(shí)需要給全文檢索系統(tǒng)添加處理某種語(yǔ)言或者文本格式的功能,比如在英文系統(tǒng)中添加中文處理功能,在純文本系統(tǒng)中添加XML或者HTML格式的文本處理功能,系統(tǒng)的開放性和擴(kuò)充性就十分的重要。
1.2 什么是Lucene
Lucene是apache軟件基金會(huì)jakarta項(xiàng)目組的一個(gè)子項(xiàng)目,是一個(gè)開放源代碼的全文檢索引擎工具包,即它不是一個(gè)完整的全文檢索引擎,而是一個(gè)全文檢索引擎的架構(gòu),提供了完整的查詢引擎和索引引擎,部分文本分析引擎(英文與德文兩種西方語(yǔ)言)。Lucene的目的是為軟件開發(fā)人員提供一個(gè)簡(jiǎn)單易用的工具包,以方便的在目標(biāo)系統(tǒng)中實(shí)現(xiàn)全文檢索的功能,或者是以此為基礎(chǔ)建立起完整的全文檢索引擎。
Lucene的原作者是Doug Cutting,他是一位資深全文索引/檢索專家,曾經(jīng)是V-Twin搜索引擎的主要開發(fā)者,后在Excite擔(dān)任高級(jí)系統(tǒng)架構(gòu)設(shè)計(jì)師,目前從事于一些Internet底層架構(gòu)的研究。早先發(fā)布在作者自己的http://www.lucene.com/,后來發(fā)布在SourceForge,2001年年底成為apache軟件基金會(huì)jakarta的一個(gè)子項(xiàng)目:http://jakarta.apache.org/lucene/。
1.3 Lucene的應(yīng)用、特點(diǎn)及優(yōu)勢(shì)
作為一個(gè)開放源代碼項(xiàng)目,Lucene從問世之后,引發(fā)了開放源代碼社群的巨大反響,程序員們不僅使用它構(gòu)建具體的全文檢索應(yīng)用,而且將之集成到各種系統(tǒng)軟件中去,以及構(gòu)建Web應(yīng)用,甚至某些商業(yè)軟件也采用了Lucene作為其內(nèi)部全文檢索子系統(tǒng)的核心。apache軟件基金會(huì)的網(wǎng)站使用了Lucene作為全文檢索的引擎,IBM的開源軟件eclipse的2.1版本中也采用了Lucene作為幫助子系統(tǒng)的全文索引引擎,相應(yīng)的IBM的商業(yè)軟件Web Sphere中也采用了Lucene。Lucene以其開放源代碼的特性、優(yōu)異的索引結(jié)構(gòu)、良好的系統(tǒng)架構(gòu)獲得了越來越多的應(yīng)用。
Lucene作為一個(gè)全文檢索引擎,其具有如下突出的優(yōu)點(diǎn):
(1)索引文件格式獨(dú)立于應(yīng)用平臺(tái)。Lucene定義了一套以8位字節(jié)為基礎(chǔ)的索引文件格式,使得兼容系統(tǒng)或者不同平臺(tái)的應(yīng)用能夠共享建立的索引文件。
(2)在傳統(tǒng)全文檢索引擎的倒排索引的基礎(chǔ)上,實(shí)現(xiàn)了分塊索引,能夠針對(duì)新的文件建立小文件索引,提升索引速度。然后通過與原有索引的合并,達(dá)到優(yōu)化的目的。
(3)優(yōu)秀的面向?qū)ο蟮南到y(tǒng)架構(gòu),使得對(duì)于Lucene擴(kuò)展的學(xué)習(xí)難度降低,方便擴(kuò)充新功能。
(4)設(shè)計(jì)了獨(dú)立于語(yǔ)言和文件格式的文本分析接口,索引器通過接受Token流完成索引文件的創(chuàng)立,用戶擴(kuò)展新的語(yǔ)言和文件格式,只需要實(shí)現(xiàn)文本分析的接口。
(5)已經(jīng)默認(rèn)實(shí)現(xiàn)了一套強(qiáng)大的查詢引擎,用戶無(wú)需自己編寫代碼即使系統(tǒng)可獲得強(qiáng)大的查詢能力,Lucene的查詢實(shí)現(xiàn)中默認(rèn)實(shí)現(xiàn)了布爾操作、模糊查詢(Fuzzy Search)、分組查詢等等。
面對(duì)已經(jīng)存在的商業(yè)全文檢索引擎,Lucene也具有相當(dāng)?shù)膬?yōu)勢(shì):
首先,它的開發(fā)源代碼發(fā)行方式(遵守Apache Software License),在此基礎(chǔ)上程序員不僅僅可以充分的利用Lucene所提供的強(qiáng)大功能,而且可以深入細(xì)致的學(xué)習(xí)到全文檢索引擎制作技術(shù)和面相對(duì)象編程的實(shí)踐,進(jìn)而在此基礎(chǔ)上根據(jù)應(yīng)用的實(shí)際情況編寫出更好的更適合當(dāng)前應(yīng)用的全文檢索引擎。在這一點(diǎn)上,商業(yè)軟件的靈活性遠(yuǎn)遠(yuǎn)不及Lucene。其次,Lucene秉承了開放源代碼一貫的架構(gòu)優(yōu)良的優(yōu)勢(shì),設(shè)計(jì)了一個(gè)合理而極具擴(kuò)充能力的面向?qū)ο蠹軜?gòu),程序員可以在Lucene的基礎(chǔ)上擴(kuò)充各種功能,比如擴(kuò)充中文處理能力,從文本擴(kuò)充到HTML、PDF等等文本格式的處理,編寫這些擴(kuò)展的功能不僅僅不復(fù)雜,而且由于Lucene恰當(dāng)合理的對(duì)系統(tǒng)設(shè)備做了程序上的抽象,擴(kuò)展的功能也能輕易的達(dá)到跨平臺(tái)的能力。最后,轉(zhuǎn)移到apache軟件基金會(huì)后,借助于apache軟件基金會(huì)的網(wǎng)絡(luò)平臺(tái),程序員可以方便的和開發(fā)者、其它程序員交流,促成資源的共享,甚至直接獲得已經(jīng)編寫完備的擴(kuò)充功能。最后,雖然Lucene使用Java語(yǔ)言寫成,但是開放源代碼社區(qū)的程序員正在不懈的將之使用各種傳統(tǒng)語(yǔ)言實(shí)現(xiàn)(例如.net framework),在遵守Lucene索引文件格式的基礎(chǔ)上,使得Lucene能夠運(yùn)行在各種各樣的平臺(tái)上,系統(tǒng)管理員可以根據(jù)當(dāng)前的平臺(tái)適合的語(yǔ)言來合理的選。
2. Lucene系統(tǒng)結(jié)構(gòu)分析
2.1 系統(tǒng)結(jié)構(gòu)組織
Lucene作為一個(gè)優(yōu)秀的全文檢索引擎,其系統(tǒng)結(jié)構(gòu)具有強(qiáng)烈的面向?qū)ο筇卣鳌J紫仁嵌x了一個(gè)與平臺(tái)無(wú)關(guān)的索引文件格式,其次通過抽象將系統(tǒng)的核心組成部分設(shè)計(jì)為抽象類,具體的平臺(tái)實(shí)現(xiàn)部分設(shè)計(jì)為抽象類的實(shí)現(xiàn),此外與具體平臺(tái)相關(guān)的部分比如文件存儲(chǔ)也封裝為類,經(jīng)過層層的面向?qū)ο笫降奶幚恚罱K達(dá)成了一個(gè)低耦合高效率,容易二次開發(fā)的檢索引擎系統(tǒng)。
以下將討論Lucene系統(tǒng)的結(jié)構(gòu)組織,并給出系統(tǒng)結(jié)構(gòu)與源碼組織圖:

從圖中我們清楚的看到,Lucene的系統(tǒng)由基礎(chǔ)結(jié)構(gòu)封裝、索引核心、對(duì)外接口三大部分組成。其中直接操作索引文件的索引核心又是系統(tǒng)的重點(diǎn)。Lucene的將所有源碼分為了7個(gè)模塊(在java語(yǔ)言中以包即package來表示),各個(gè)模塊所屬的系統(tǒng)部分也如上圖所示。需要說明的是org.apache.lucene.queryPaser是做為org.apache.lucene.search的語(yǔ)法解析器存在,不被系統(tǒng)之外實(shí)際調(diào)用,因此這里沒有當(dāng)作對(duì)外接口看待,而是將之獨(dú)立出來。
從面象對(duì)象的觀點(diǎn)來考察,Lucene應(yīng)用了最基本的一條程序設(shè)計(jì)準(zhǔn)則:引入額外的抽象層以降低耦合性。首先,引入對(duì)索引文件的操作org.apache.lucene.store的封裝,然后將索引部分的實(shí)現(xiàn)建立在(org.apache.lucene.index)其之上,完成對(duì)索引核心的抽象。在索引核心的基礎(chǔ)上開始設(shè)計(jì)對(duì)外的接口org.apache.lucene.search與org.apache.lucene.analysis。在每一個(gè)局部細(xì)節(jié)上,比如某些常用的數(shù)據(jù)結(jié)構(gòu)與算法上,Lucene也充分的應(yīng)用了這一條準(zhǔn)則。在高度的面向?qū)ο罄碚摰闹蜗拢沟肔ucene的實(shí)現(xiàn)容易理解,易于擴(kuò)展。
Lucene在系統(tǒng)結(jié)構(gòu)上的另一個(gè)特點(diǎn)表現(xiàn)為其引入了傳統(tǒng)的客戶端服務(wù)器結(jié)構(gòu)以外的的應(yīng)用結(jié)構(gòu)。Lucene可以作為一個(gè)運(yùn)行庫(kù)被包含進(jìn)入應(yīng)用本身中去,而不是做為一個(gè)單獨(dú)的索引服務(wù)器存在。這自然和Lucene開放源代碼的特征分不開,但是也體現(xiàn)了Lucene在編寫上的本來意圖:提供一個(gè)全文索引引擎的架構(gòu),而不是實(shí)現(xiàn)。
2.2 數(shù)據(jù)流分析
了解數(shù)據(jù)流分析的重要性:
理解Lucene系統(tǒng)結(jié)構(gòu)的另一個(gè)方式是去探討其中數(shù)據(jù)流的走向,并以此摸清楚Lucene系統(tǒng)內(nèi)部的調(diào)用時(shí)序。在此基礎(chǔ)上,我們能夠更加深入的理解Lucene的系統(tǒng)結(jié)構(gòu)組織,以方便以后在Lucene系統(tǒng)上的開發(fā)工作。這部分的分析,是深入Lucene系統(tǒng)的鑰匙,也是進(jìn)行重寫的基礎(chǔ)。
Lucene系統(tǒng)中的主要的數(shù)據(jù)流以及它們之間的關(guān)系圖:

圖2.2很好的表明了Lucene在內(nèi)部的數(shù)據(jù)流組織情況,并且沿著數(shù)據(jù)流的方向我們也可以對(duì)與Lucene內(nèi)部的執(zhí)行時(shí)序有一個(gè)清楚的了解。現(xiàn)在將圖中的涉及到的流的類型與各個(gè)邏輯對(duì)應(yīng)系統(tǒng)的相關(guān)部分的關(guān)系說明一下。
圖中共存在4種數(shù)據(jù)流,分別是文本流、token流、字節(jié)流與查詢語(yǔ)句對(duì)象流。文本流表示了對(duì)于索引目標(biāo)和交互控制的抽象,即用文本流表示了將要索引的文件,用文本流向用戶輸出信息;在實(shí)際的實(shí)現(xiàn)中,Lucene中的文本流采用了UCS-2作為編碼,以達(dá)到適應(yīng)多種語(yǔ)言文字的處理的目的。Token流是Lucene內(nèi)部所使用的概念,是對(duì)傳統(tǒng)文字中的詞的概念的抽象,也是Lucene在建立索引時(shí)直接處理的最小單位;簡(jiǎn)單的講Token就是一個(gè)詞和所在域值的組合,后面在敘述文件格式時(shí)也將繼續(xù)涉及到token,這里不詳細(xì)展開。字節(jié)流則是對(duì)文件抽象的直接操作的體現(xiàn),通過固定長(zhǎng)度的字節(jié)(Lucene定義為8比特位長(zhǎng),后面文件格式將詳細(xì)敘述)流的處理,將文件操作解脫出來,也做到了與平臺(tái)文件系統(tǒng)的無(wú)關(guān)性。查詢語(yǔ)句對(duì)象流則是僅僅在查詢語(yǔ)句解析時(shí)用到的概念,它對(duì)查詢語(yǔ)句抽象,通過類的繼承結(jié)構(gòu)反映查詢語(yǔ)句的結(jié)構(gòu),將之傳送到查找邏輯來進(jìn)行查找的操作。
圖中的涉及到了多種邏輯,基本上直接對(duì)應(yīng)于系統(tǒng)某一模塊,但是也有跨模塊調(diào)用的問題發(fā)生,這是因?yàn)長(zhǎng)ucene的重用程度非常好,因此很多實(shí)現(xiàn)直接調(diào)用了以前的工作成果,這在某種程度上其實(shí)是加強(qiáng)了模塊耦合性,但是也是為了避免系統(tǒng)的過于龐大和不必要的重復(fù)設(shè)計(jì)的一種折衷體現(xiàn)。詞法分析邏輯對(duì)應(yīng)于org.apache.lucene.analysis部分。查詢語(yǔ)句語(yǔ)法分析邏輯對(duì)應(yīng)于org.apache.lucene.queryParser部分,并且調(diào)用了org.apache.lucene.analysis的代碼。查詢結(jié)束之后向評(píng)分排序邏輯輸出token流,繼而由評(píng)分排序邏輯處理之后給出文本流的結(jié)果,這一部分的實(shí)現(xiàn)也包含在了org.apache.lucene.search中。索引構(gòu)建邏輯對(duì)應(yīng)于org.apache.lucene.index部分。索引查找邏輯則主要是org.apache.lucene.search,但是也大量的使用了org.apache.lucene.index部分的代碼和接口定義。存儲(chǔ)抽象對(duì)應(yīng)于org.apache.lucene.store。沒有提到的模塊則是做為系統(tǒng)公共基礎(chǔ)設(shè)施存在。
2.3 基于Lucene的應(yīng)用開發(fā)
首先,我們需要的是按照目標(biāo)語(yǔ)言的詞法結(jié)構(gòu)來構(gòu)建相應(yīng)的詞法分析邏輯,實(shí)現(xiàn)Lucene在org.apache.lucene.analysis中定義的接口,為L(zhǎng)ucene提供目標(biāo)系統(tǒng)所使用的語(yǔ)言處理能力。Lucene默認(rèn)的已經(jīng)實(shí)現(xiàn)了英文和德文的簡(jiǎn)單詞法分析邏輯(按照空格分詞,并去除常用的語(yǔ)法詞,如英語(yǔ)中的is,am,are等等)。在這里,主要需要參考實(shí)現(xiàn)的接口在org.apache.lucene.analysis中的Analyzer.java和Tokenizer.java中定義,Lucene提供了很多英文規(guī)范的實(shí)現(xiàn)樣本,也可以做為實(shí)現(xiàn)時(shí)候的參考資料。其次,需要按照被索引的文件的格式來提供相應(yīng)的文本分析邏輯,這里是指除開詞法分析之外的部分,比如HTML文件,通常需要把其中的內(nèi)容按照所屬于域分門別類加入索引,這就需要從org.apache.lucene.document中定義的類document繼承,定義自己的HTMLDocument類,然后就可以將之交給org.apache.lucene.index模塊來寫入索引文件。完成了這兩步之后,Lucene全文檢索引擎就基本上完備了。這個(gè)過程可以用下圖表示:

下面是使用java語(yǔ)言開發(fā),Lucene系統(tǒng)能夠方便的嵌入到整個(gè)系統(tǒng)中去,作為一個(gè)API集來調(diào)用。這個(gè)過程十分簡(jiǎn)單,以下便是一個(gè)示例程序,配合注釋理解起來很容易。

2.4 Lucene索引文件格式
首先在Lucene的文件格式中,以字節(jié)為基礎(chǔ),定義了如下的數(shù)據(jù)類型:
表 3.1 Lucene文件格式中定義的數(shù)據(jù)類型
| 數(shù)據(jù)類型 | 所占字節(jié)長(zhǎng)度(字節(jié)) | 說明 |
| Byte | 1 | 基本數(shù)據(jù)類型,其他數(shù)據(jù)類型以此為基礎(chǔ)定義 |
| UInt32 | 4 | 32位無(wú)符號(hào)整數(shù),高位優(yōu)先 |
| UInt64 | 8 | 64位無(wú)符號(hào)整數(shù),高位優(yōu)先 |
| VInt | 不定,最少1字節(jié) | 動(dòng)態(tài)長(zhǎng)度整數(shù),每字節(jié)的最高位表明還剩多少字節(jié),每字節(jié)的低七位表明整數(shù)的值,高位優(yōu)先。可以認(rèn)為值可以為無(wú)限大。其示例如下 | 值 | 字節(jié)1 | 字節(jié)2 | 字節(jié)3 | | 0 | 00000000 | | | | 1 | 00000001 | | | | 2 | 00000010 | | | | 127 | 01111111 | | | | 128 | 10000000 | 00000001 | | | 129 | 10000001 | 00000001 | | | 130 | 10000010 | 00000001 | | | 16383 | 10000000 | 10000000 | 00000001 | | 16384 | 10000001 | 10000000 | 00000001 | | 16385 | 10000010 | 10000000 | 00000001 | |
| Chars | 不定,最少1字節(jié) | 采用UTF-8編碼[20]的Unicode字符序列 |
| String | 不定,最少2字節(jié) | 由VInt和Chars組成的字符串類型,VInt表示Chars的長(zhǎng)度,Chars則表示了String的值 |
以上的數(shù)據(jù)類型就是Lucene索引文件格式中用到的全部數(shù)據(jù)類型,由于它們都以字節(jié)為基礎(chǔ)定義而來,因此保證了是平臺(tái)無(wú)關(guān),這也是Lucene索引文件格式平臺(tái)無(wú)關(guān)的主要原因。接下來我們看看Lucene索引文件的概念組成和結(jié)構(gòu)組成。

以上就是Lucene的索引文件的概念結(jié)構(gòu)。Lucene索引index由若干段(segment)組成,每一段由若干的文檔(document)組成,每一個(gè)文檔由若干的域(field)組成,每一個(gè)域由若干的項(xiàng)(term)組成。項(xiàng)是最小的索引概念單位,它直接代表了一個(gè)字符串以及其在文件中的位置、出現(xiàn)次數(shù)等信息。域是一個(gè)關(guān)聯(lián)的元組,由一個(gè)域名和一個(gè)域值組成,域名是一個(gè)字串,域值是一個(gè)項(xiàng),比如將“標(biāo)題”和實(shí)際標(biāo)題的項(xiàng)組成的域。文檔是提取了某個(gè)文件中的所有信息之后的結(jié)果,這些組成了段,或者稱為一個(gè)子索引。子索引可以組合為索引,也可以合并為一個(gè)新的包含了所有合并項(xiàng)內(nèi)部元素的子索引。我們可以清楚的看出,Lucene的索引結(jié)構(gòu)在概念上即為傳統(tǒng)的倒排索引結(jié)構(gòu)。
從概念上映射到結(jié)構(gòu)中,索引被處理為一個(gè)目錄(文件夾),其中含有的所有文件即為其內(nèi)容,這些文件按照所屬的段不同分組存放,同組的文件擁有相同的文件名,不同的擴(kuò)展名。此外還有三個(gè)文件,分別用來保存所有的段的記錄、保存已刪除文件的記錄和控制讀寫的同步,它們分別是segments,deletable和lock文件,都沒有擴(kuò)展名。每個(gè)段包含一組文件,它們的文件擴(kuò)展名不同,但是文件名均為記錄在文件segments中段的名字。讓我們看如下的結(jié)構(gòu)圖3.2:

每個(gè)段的文件中,主要記錄了兩大類的信息:域集合與項(xiàng)集合。這兩個(gè)集合中所含有的文件在圖3.2中均有表明。由于索引信息是靜態(tài)存儲(chǔ)的,域集合與項(xiàng)集合中的文件組采用了一種類似的存儲(chǔ)辦法:一個(gè)小型的索引文件,運(yùn)行時(shí)載入內(nèi)存;一個(gè)對(duì)應(yīng)于索引文件的實(shí)際信息文件,可以按照索引中指示的偏移量隨機(jī)訪問;索引文件與信息文件在記錄的排列順序上存在隱式的對(duì)應(yīng)關(guān)系,即索引文件中按照“索引項(xiàng)1、索引項(xiàng)2…”排列,則信息文件則也按照“信息項(xiàng)1、信息項(xiàng)2…”排列。比如在圖3.2所示文件中,segment1.fdx與segment1.fdt之間,segment1.tii與segment1.tis、segment1.prx、segment1.frq之間,都存在這樣的組織關(guān)系。而域集合與項(xiàng)集合之間則通過域的在域記錄文件(比如segment1.fnm)中所記錄的域記錄號(hào)維持對(duì)應(yīng)關(guān)系,在圖3.2中segment1.fdx與segment1.tii中就是通過這種方式保持聯(lián)系。這樣,域集合和項(xiàng)集合不僅僅聯(lián)系起來,而且其中的文件之間也相互聯(lián)系起來。此外,標(biāo)準(zhǔn)化因子文件和被刪除文檔文件則提供了一些程序內(nèi)部的輔助設(shè)施(標(biāo)準(zhǔn)化因子用在評(píng)分排序機(jī)制中,被刪除文檔是一種偽刪除手段)。這樣,整個(gè)段的索引信息就通過這些文檔有機(jī)的組成。
2.5 一些公用的基礎(chǔ)類
基礎(chǔ)結(jié)構(gòu)封裝,或者基礎(chǔ)類,由org.apache.lucene.util和org.apache.lucene.document兩個(gè)包組成,前者定義了一些常量和優(yōu)化過的常用的數(shù)據(jù)結(jié)構(gòu)和算法,后者則是對(duì)于文檔(document)和域(field)概念的一個(gè)類定義。以下我們用列表的方式來分析這些封裝類,指出其要點(diǎn);
表 3.2 基礎(chǔ)類包org.apache.lucene.util
| 類 | 說明 |
| Arrays | 一個(gè)關(guān)于數(shù)組的排序方法的靜態(tài)類,提供了優(yōu)化的基于快排序的排序方法sort |
| BitVector | C/C++語(yǔ)言中位域的java實(shí)現(xiàn)品,但是加入了序列化能力 |
| Constants | 常量靜態(tài)類,定義了一些常量 |
| PriorityQueue | 一個(gè)優(yōu)先隊(duì)列的抽象類,用于后面實(shí)現(xiàn)各種具體的優(yōu)先隊(duì)列,提供常數(shù)時(shí)間內(nèi)的最小元素訪問能力,內(nèi)部實(shí)現(xiàn)機(jī)制是哈析表和堆排序算法 |
表 3.3 基礎(chǔ)類包org.apache.lucene.document
| 類 | 說明 |
| Document | 是文檔概念的一個(gè)實(shí)現(xiàn)類,每個(gè)文檔包含了一個(gè)域表(fieldList),并提供了一些實(shí)用的方法,比如多種添加域的方法、返回域表的迭代器的方法 |
| Field | 是域概念的一個(gè)實(shí)現(xiàn)類,每個(gè)域包含了一個(gè)域名和一個(gè)值,以及一些相關(guān)的屬性 |
| DateField | 提供了一些輔助方法的靜態(tài)類,這些方法將java中Date和Time數(shù)據(jù)類型和String相互轉(zhuǎn)化 |
org.apache.lucene.store包:存儲(chǔ)抽象是唯一能夠直接對(duì)索引文件存取的包,因此其主要目的是抽象出和平臺(tái)文件系統(tǒng)無(wú)關(guān)的存儲(chǔ)抽象,提供諸如目錄服務(wù)(增、刪文件)、輸入流和輸出流。在分析其實(shí)現(xiàn)之前,首先我們看一下UML圖;

圖 3.3 存儲(chǔ)抽象實(shí)現(xiàn)UML圖(一)

圖 3.4 存儲(chǔ)抽象實(shí)現(xiàn)UML圖(二)

圖 3.4 存儲(chǔ)抽象實(shí)現(xiàn)UML圖(三)
圖3.2到3.4展示了整個(gè)org.apache.lucene.store中主要的繼承體系。共有三個(gè)抽象類定義:Directory、InputStream和OutputStrem,構(gòu)成了一個(gè)完整的基于抽象文件系統(tǒng)的存取體系結(jié)構(gòu),在此基礎(chǔ)上,實(shí)作出了兩個(gè)實(shí)現(xiàn)品:(FSDirectory,F(xiàn)SInputStream,F(xiàn)SOutputStream)和(RAMDirectory,RAMInputStream和RAMOutputStream)。前者是以實(shí)際的文件系統(tǒng)做為基礎(chǔ)實(shí)現(xiàn)的,后者則是建立在內(nèi)存中的虛擬文件系統(tǒng)。前者主要用來永久的保存索引文件,后者的作用則在于索引操作時(shí)是在內(nèi)存中建立小的索引,然后一次性的輸出合并到文件中去,這一點(diǎn)我們?cè)诤竺娴乃饕壿嫴糠帜軌蚩吹健4送猓€定以了org.apache.lucene.store.lock和org.apache.lucene.store.with兩個(gè)輔助內(nèi)部實(shí)現(xiàn)的類用在實(shí)現(xiàn)Directory方法的makeLock的時(shí)候,以在鎖定索引讀寫之前來讓客戶程序做一些準(zhǔn)備工作。
(FSDirectory,F(xiàn)SInputStream,F(xiàn)SOutputStream)的內(nèi)部實(shí)現(xiàn)依托于java語(yǔ)言中的io類庫(kù),只是簡(jiǎn)單的做了一個(gè)外部邏輯的包裝。這當(dāng)然要?dú)w功于java語(yǔ)言所提供的跨平臺(tái)特性,同時(shí)也帶了一些隱患:文件存取的效率提升需要依耐于文件類庫(kù)的優(yōu)化。如果需要繼續(xù)優(yōu)化文件存取的效率,應(yīng)該還提供一個(gè)文件與目錄的抽象,以根據(jù)各種文件系統(tǒng)或者文件類型來提供一個(gè)優(yōu)化的機(jī)會(huì)。當(dāng)然,這是應(yīng)用開發(fā)者所不需要關(guān)系的問題。
(RAMDirectory,RAMInputStream和RAMOutputStream)的內(nèi)部實(shí)現(xiàn)就比較直接了,直接采用了虛擬的文件RAMFile類(定義于文件RAMDirectory.java中)來表示文件,目錄則看作一個(gè)String與RAMFile對(duì)應(yīng)的關(guān)聯(lián)數(shù)組。RAMFile中采用數(shù)組來表示文件的存儲(chǔ)空間。在此的基礎(chǔ)上,完成各項(xiàng)操作的實(shí)現(xiàn),就形成了基于內(nèi)存的虛擬文件系統(tǒng)。因?yàn)樵趯?shí)際使用時(shí),并不會(huì)牽涉到很大字節(jié)數(shù)量的文件,因此這種設(shè)計(jì)是簡(jiǎn)單直接的,也是高效率的。
3. Lucene索引構(gòu)建邏輯模塊分析
3.1對(duì)象體系與UML圖
1. 項(xiàng)(Term)
項(xiàng)(Term):包括概念所實(shí)際涉及的類、永久化類。項(xiàng)(Term)所表示的是一個(gè)字符串,它擁有域、頻數(shù)和位置信息等等屬性。因此,Lucene中設(shè)計(jì)了兩個(gè)類來表示這個(gè)概念,如下圖

圖 4.1 UML圖(-)
上圖中,有意的突出了類Term和TermInfo中的數(shù)據(jù)成員,因?yàn)樗从沉藢?duì)于項(xiàng)(Term)這個(gè)概念的具體表示。同時(shí)上圖中也同時(shí)列出了用于永久化項(xiàng)(Term)的代理類TermInfosWriter和TermInfosReader,它們完成永久化的功能,需要注意的是,TermInfosReader內(nèi)部使用了數(shù)組indexTerms和indexInfos來存儲(chǔ)一系列項(xiàng);而TermInfosWriter則是一個(gè)類似于鏈表的結(jié)構(gòu),通過一個(gè)other指向下一個(gè)TermInfosWriter,每一個(gè)TermInfosWriter只負(fù)責(zé)本身那個(gè)lastTerm和lastTi的永久化工作。這是一個(gè)設(shè)計(jì)上的技巧,通過批量讀取(或者稱為緩沖的方式)來獲得讀入時(shí)候的效率優(yōu)化;而通過一個(gè)鏈表式的、各負(fù)其責(zé)的方式,來獲得寫出時(shí)候的設(shè)計(jì)簡(jiǎn)化。
項(xiàng)(term)這部分的設(shè)計(jì)中,還有一些重要的接口和類:

圖 4.2 UML圖(二)
圖4.2中,我們看到三個(gè)類:TermEnum、TermDocs與TermPositions,第一個(gè)是抽象類,后兩個(gè)都是接口。TermEnum的設(shè)計(jì)主要用在后面Segment和Document等等的實(shí)現(xiàn)中,以提供枚舉其中每一個(gè)項(xiàng)(Term)的能力。TermDocs是一個(gè)接口,用來繼承以提供返回<document, frequency>值對(duì)的能力,通過這個(gè)接口就可以獲得某個(gè)項(xiàng)(Term)在某個(gè)文檔中出現(xiàn)的頻數(shù)。TermPositions則是在TermDocs上的擴(kuò)展,將項(xiàng)(Term)在文檔中的位置信息也表示出來。TermDocs(TermPositions)接口的使用方式類似于java中的Enumration接口,即通過next方法跳轉(zhuǎn),通過doc,freq等方法獲得當(dāng)前的屬性值。
2. 域(Field)
由于Field的基本概念在org.apache.lucene.document中已經(jīng)做了定義,因此在這部分主要是針對(duì)項(xiàng)文件(.fnm文件、.fdx文件、.fdt文件)所需要的信息再來設(shè)計(jì)一些類。

圖 4.3 UML圖(三)
圖 4.3中展示的,就是表示與域(Field)所關(guān)聯(lián)的屬性信息的類。其中isIndexed表示的這個(gè)域的值是否被索引過,即值是否被分詞然后索引;另外兩個(gè)屬性所表示的意思則很明顯:一個(gè)是域的名字,一個(gè)是域的編號(hào)。
關(guān)于域表和存取邏輯的UML圖:

FieldInfos即為域表的概念表示,內(nèi)部采用了冗余的方式以獲取在通過域的編號(hào)訪問或者通過域的名字來訪問時(shí)候的高效率。FieldsReader與FieldsWriter則分別是寫出和讀入的代理類。在功能和實(shí)現(xiàn)上,這兩個(gè)類都比較簡(jiǎn)單。
3. 文檔(document)
文檔(document)同樣也是在org.apache.lucene.document中定義過的結(jié)構(gòu)。由于對(duì)于這部分比較重要,我們也來看看其UML圖:

圖 4.5 UML圖(五)
在圖4.5中我們看到,Document的設(shè)計(jì)基本上沿用了鏈表的處理方法。左邊的Document類作為一個(gè)數(shù)據(jù)外包類,用來提供對(duì)于內(nèi)部結(jié)構(gòu)DocumentFieldList的增加刪除訪問操作等等。DocumentFieldList才是實(shí)際上的數(shù)據(jù)存儲(chǔ)單位,它用了鏈表的處理方法,直接指向一個(gè)當(dāng)前的Field對(duì)象和下一個(gè)DocumentFieldList對(duì)象,這個(gè)與前面的類似。為了能夠逐個(gè)訪問鏈表中的節(jié)點(diǎn),還設(shè)計(jì)了DocumentFieldEnumeration枚舉類。

圖 4.6 UML圖(六)
實(shí)際上定義于org.apache.lucene.index中的有關(guān)于Document的就是永久化的代理類。在圖4.6中給出了其UML圖。需要說明的是為什么沒有出現(xiàn)讀入的方法:這個(gè)方法已經(jīng)隱含在圖4.5中Document類中的add方法中了,結(jié)合圖2.4中的程序代碼段,我們就能夠清楚的理解這種設(shè)計(jì)。
4. 段(segment)
段(Segment)這一部分設(shè)計(jì)的比較特殊,在實(shí)現(xiàn)簡(jiǎn)單的對(duì)象結(jié)構(gòu)之上,還特意的設(shè)計(jì)了用于段之間合并的類。接下來,我們?nèi)匀徊扇?duì)照UML分析的方式逐個(gè)敘述。接下來我們看Lucene中如何表示段這個(gè)概念。

圖 4.7 UML圖(七)
Lucene定義了一個(gè)類SegmentInfo用來表示每一個(gè)段(Segment)的信息,包括名字(name)、含有的文檔的數(shù)目(docCount)和段所位于的目錄的位置(dir)。根據(jù)索引文件中的段的意義,有了這三點(diǎn),就能唯一確定一個(gè)段了。SegmentInfos這個(gè)類則是用來表示一個(gè)段的鏈表(從標(biāo)準(zhǔn)的java.util.Vector繼承而來),實(shí)際上,也就是索引(index)的意思了。需要注意的是,這里并沒有在SegmentInfo中安插一個(gè)文檔(document)的鏈表。這樣做的原因牽涉到Lucene內(nèi)部對(duì)于文檔(相當(dāng)于一個(gè)被索引文件)的處理;Lucene內(nèi)部采用了賦予文檔編號(hào),給域賦值的方式來處理文檔,即加入的文檔順次編號(hào),以后用文檔號(hào)表示文檔,而路徑信息,文件名字等等在以后索引查找需要的屬性,都作為域存儲(chǔ)下來;因此SegmentInfo中并沒有另外存儲(chǔ)一個(gè)文檔(document)的鏈表,對(duì)于這些的寫出和讀入,則交給了永久化的代理類來做。

圖 4.8 UML圖(八)
圖4.8給出了負(fù)責(zé)段(segment)的讀入操作的代理類,而負(fù)責(zé)段(segment)的寫出操作也同樣沒有定義,這些操作都直接實(shí)現(xiàn)在了類IndexWriter類中。段的操作同樣采用了之前的數(shù)組或者說是緩沖的處理方式。
針對(duì)前面項(xiàng)(term)那部分定義的幾個(gè)接口,段(segment)這部分也需要做相應(yīng)的接口實(shí)現(xiàn),因?yàn)樘峁┲苯颖闅v訪問段中的各個(gè)項(xiàng)的能力對(duì)于檢索來說,無(wú)疑是十分重要的。即這部分的設(shè)計(jì),實(shí)際上都是在為了檢索在服務(wù)。

圖 4.9 UML圖(九)

圖 4.10 UML圖(十)
圖4.9和圖4.10分別展示了前面項(xiàng)(term)那里定義的接口是如何在這里通過繼承實(shí)現(xiàn)的。Lucene在處理這部分的時(shí)候,也是分成兩部分(Segment與Segments開頭的類)來實(shí)現(xiàn),而且很合理的運(yùn)用了數(shù)組的技法,以及注意了繼承重用。但是細(xì)化到局部,終歸是比較簡(jiǎn)單的按照語(yǔ)義來獲得結(jié)果而已了。
Lucene為了兼顧建立索引時(shí)的效率和讀取索引查找的速度,引入了分小段建立索引的方式,即每一次批量建立索引時(shí),先在內(nèi)存中的虛擬文件系統(tǒng)中為每一個(gè)文檔單獨(dú)建立一個(gè)段,然后在輸出的時(shí)候?qū)⑦@些段合并之后輸出成為索引文件,這時(shí)僅僅存在一個(gè)段。多次建立的索引后,如果想優(yōu)化索引文件,也可采取合并段的方法,將索引中的段合并成為一個(gè)段。我們來看一下在IndexWriter類中相應(yīng)的方法的實(shí)現(xiàn),來了解一下這中建立索引的實(shí)現(xiàn)。

在mergeSegments函數(shù)中,將用到幾個(gè)重要的類結(jié)構(gòu),它們記錄了合并時(shí)候的一些重要信息,完成合并時(shí)候的工作。接下來,我們來看這幾個(gè)類的UML圖:

圖 4.12 UML圖(十一)
從圖4.12中,我們看到Lucene設(shè)計(jì)一個(gè)類SegmentMergeInfo用來保存每一個(gè)被合并的段的信息,也保存能夠訪問其內(nèi)部的接口句柄,也就是說合并時(shí)的操作使用這個(gè)類作為對(duì)被合并的段的操作代理。類SegmentMergeQueue則設(shè)計(jì)為org.apache.lucene.util.PriorityQueue的子類,做為SegmentMergeInfo的容器類,而且附帶能夠自動(dòng)排序。SegmentMerger是主要進(jìn)行操作的類,主要完成合并各個(gè)數(shù)據(jù)項(xiàng)的問題。
5. IndexReader類與IndexWirter類
最后剩下的,就是整個(gè)索引邏輯部分的使用接口類了。外界通過這兩個(gè)類以及文檔(document)類的構(gòu)造函數(shù)調(diào)用之,比如圖2.4中的代碼示例所示。下面我們來看一下這部分最后兩個(gè)類的UML圖:

圖 4.13 UML圖(十二)
IndexWriter的設(shè)計(jì)與IndexReader的設(shè)計(jì)很不相同,前者是一個(gè)實(shí)現(xiàn)類,而后者是一個(gè)抽象類,帶有沒有實(shí)現(xiàn)的接口。IndexWriter的主要作用就是接收新加入的文檔(document),然后在內(nèi)部為之生成相應(yīng)的小段,最后再合并并向索引文件中輸出,圖4.11中已經(jīng)給出了一些實(shí)現(xiàn)的代碼。由于Lucene在面向?qū)ο笊戏庋b的努力,通過各個(gè)構(gòu)造函數(shù)就已經(jīng)完成了對(duì)于各個(gè)概念的構(gòu)造過程,剩下部分的代碼主要是依據(jù)各個(gè)數(shù)組或者是鏈表中的信息,逐個(gè)逐個(gè)的將信息寫出到相應(yīng)的文件中去了。IndexReader部分則只是做了接口設(shè)計(jì),沒有具體的實(shí)現(xiàn),這個(gè)和本部分所完成的主要功能有關(guān):索引構(gòu)建邏輯。設(shè)計(jì)這個(gè)抽象類的目的是,預(yù)先完成一些函數(shù),為以后的檢索(search)部分的各種形式的IndexReader鋪平道路,也是利用了在同一個(gè)包內(nèi)可以方便訪問其它類的保護(hù)變量這個(gè)java語(yǔ)言的限制。
3.2 數(shù)據(jù)流邏輯
從宏觀上明白一個(gè)系統(tǒng)的設(shè)計(jì),理清楚其中的運(yùn)行規(guī)律,最好的方式應(yīng)該是通過數(shù)據(jù)流圖。在分析了各個(gè)位于索引構(gòu)建邏輯部分的類的設(shè)計(jì)之后,我們接下來就通過分析數(shù)據(jù)流圖的方式來總結(jié)一下。但是由于之前提到的原因:索引讀入部分在這一部分并沒有完全實(shí)現(xiàn),所以我們?cè)跀?shù)據(jù)流圖中主要給出的是索引構(gòu)建的數(shù)據(jù)流圖。

對(duì)于圖4.14中所描述的內(nèi)容,結(jié)合Lucene源代碼中的一些文件看,能夠加深理解。準(zhǔn)備階段可以參考demo文件夾中的org.apache.lucene.demo.IndexFiles類和java文件夾中的org.apache.lucene.document文件包。索引構(gòu)建階段的主要源碼位于java文件夾中org.apache.lucene.index.IndexWriter類,因此這部分可以結(jié)合這個(gè)類的實(shí)現(xiàn)來看。至于內(nèi)存文件系統(tǒng),比較復(fù)雜,但是這時(shí)的邏輯相對(duì)簡(jiǎn)單,因此也不難理解。
上面的數(shù)據(jù)流圖十分清楚的勾畫除了整個(gè)索引構(gòu)建邏輯這部分的設(shè)計(jì):通過層層嵌套的類結(jié)構(gòu),在構(gòu)建時(shí)候即分步驟有計(jì)劃的生成了索引結(jié)構(gòu),將之存儲(chǔ)到內(nèi)存中的文件系統(tǒng)中,然后通過對(duì)內(nèi)存中的文件系統(tǒng)優(yōu)化合并輸出到實(shí)際的文件系統(tǒng)中。
本文是在我2010年學(xué)習(xí)Lucene的時(shí)候在互聯(lián)網(wǎng)上摘抄整理而來,當(dāng)時(shí)是在一家電子商務(wù)公司做商品檢索需要用到Lucene,所以就研究了下。這篇文章也是在當(dāng)時(shí)在網(wǎng)絡(luò)上閱讀Lucene相關(guān)知識(shí)整理而來的。