Author:放翁(文初)
Email:fangweng@taobao.com
Blog:http://blog.csdn.net/cenwenchu79
當前問題:
1. 不小比重的Rest請求都是無效請求,全部接納數據消耗比較多的時間。
2. Multipart類型的大文件流請求無法做到合理快速過濾。(參數錯誤請求,數據文件過多請求,文件大小過大請求)
歸結來說,TOP平臺處理的服務在解析參數時比較消耗時間和帶寬(客戶端網絡速度慢導致傳輸字節流比較慢,文件比較大導致帶寬占用嚴重)
處理方式:
通過自行解析字節流方式來lazy化處理請求,減少無效請求對于解析參數時間消耗(導致web容器連接消耗)及帶寬消耗。
優化目標:
Get由于內容長度有限不列入在優化范圍。
優化Post方式的請求(普通的和Multipart),要求優化后:在正常請求處理上兩者處理速度不低于傳統方式,非正常請求在策略命中情況下(后面會談到什么情況下優化失效),性能有明顯提高。
具體實現:
由于現在用的是傳統IO模式,因此可以用流的方式來lazy解析和處理請求(NIO用channel + buffer package就無法lazy了)。
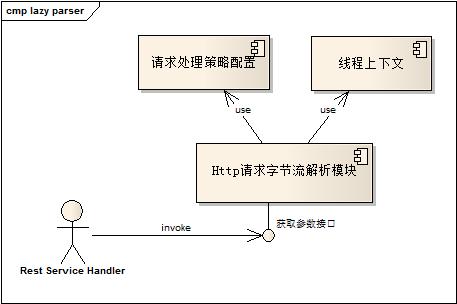
一共有三個組件角色:
1. 請求處理配置策略:配置在解析參數時,優先的規則(參數可以從header,uri,post body中獲取,相互之間的優先性),異常拋出規則(字節流長度,文件大小,文件個數限制等),字節流解析模塊的參數配置(字節流解析的窗口大小,超時時間等)。
2. 線程上下文:用來保存處理過的請求參數。一來復用,二來也是由于請求字節流處理不可逆(不保存字節流副本),必須保留。
3. Http請求字節流解析模塊。根據具體的配置以及解析策略來解析字節流,同時將解析結果保存在線程上下文中。主要的實現代碼在于對Post消息體逐步解析部分(普通的Post和multipart)
壓力測試結果:
• 正常請求場景( 100并發用戶,multipart 文件大小300k,當前業務場景這個值已經滿足了):
普通post的處理能力1000TPS。(servlet方式處理差不多,不過有波動)
multipart處理能力610TPS。(apache開源項目fileupload,處理能力400TPS左右)
錯誤請求場景
異常情況的處理有了很大提高,對于遠程客戶端傳輸較慢或者是大流量圖片的錯誤請求都有很大的優化。
優化存在問題:
1. 參數缺失導致優化失效。
2. sign類似的交驗,導致獲取所有的參數。
3. 當前圖片限制在300k,由于考慮處理速度快,就都沒有設置超過閥值存儲到本地,因此在高并發大流量的情況下也會有內存問題,當然已經做了部分保護。
針對上面的兩個問題,作了部分的協議限制,對于API2.0希望將所有的系統參數和業務參數區分開,放入到Http header中或者url中,這樣可以避免系統參數缺失導致優化失敗,同時大量過濾系統參數出現問題的無效請求。
Sign類似的交驗放在流程最后,避免過早獲取所有參數。
作安全保護,設定簡單丟棄或者io交互來緩解這個問題。
這部分內容還有很多可以做得工作,其實最初的目的就是為了防止系統對于無效請求的處理消耗,我想在很多系統都會有這樣的問題,利用緩存設置黑名單防止攻擊也是這樣的初衷。因此這點可以考慮在很多系統設計的時候都作一樣的優化,對正常的不能優化,起碼對錯誤的可以做一些優化,防止在異常請求高漲的時候,系統被擊垮.