Posted on 2010-01-23 21:03
周舒陽 閱讀(2968)
評論(4) 編輯 收藏

本期Blog原文參見:
http://www.liferay.com/web/shuyang.zhou/blog/-/blogs/io-performance
IO操作幾乎對于所有的應用都是非常重要的,因為IO操作非常容易導致性能瓶頸。
在Java的世界里存在兩大類IO,傳統IO(TIO)和新IO(NIO)。外加一個即將到來的增強版的NIO——NIO2(JDK7)。
NIO(以及NIO2)主要用于在一些特定情況下增強性能、提供更好的操作系統層次IO功能集成,但它們無法完全替代TIO!在許多情況下TIO仍然是你唯一的選擇。
今天我們就來討論一下TIO的性能問題。
IO的性能瓶頸主要分為兩類:
- 錯誤的使用緩沖(buffer)
- 過度的同步保護
我們都知道buffer能夠增加IO的性能,但不是每個人都知道如何正確的使用buffer,在本文結束時我會給出一些最佳實踐建議。
第一部分:
對于1,錯誤的使用緩沖(buffer),存在兩點非常流行的錯誤用法和一個感念上的誤解
- a)為內存IO類(In-memory IO class)添加緩沖(錯誤用法)
- b)為已添加buffer的IO類再次添加buffer(錯誤用法)
- c)Buffer版的IO類和顯式使用buffer間的關系(概念上的誤解)
對于a),這是非常荒謬的!添加buffer的目的是為了將對IO設備的多次訪問合并為一次訪問從而提高性能,In-memory類(如ByteArrayInput/OutputStream)根本就不會訪問任何IO設備,所以對它們添加buffer是完全沒有必要的。
對于b),這是完全多余的!你只需要buffer一次就可以了,多于一次的buffer只會引入更多的棧調用和垃圾創建。
對于c),這需要多一點解釋:
從本質上講,這兩種做法是要達到相同的目的,但方法不同,這也導致了它們之間具有巨大的性能差異!
針對這一問題我做了一個測試,比較使用Buffer版的IO類和顯式使用buffer在讀/寫文件時的性能差異。
下面的測試結果顯式了兩者的性能差異:
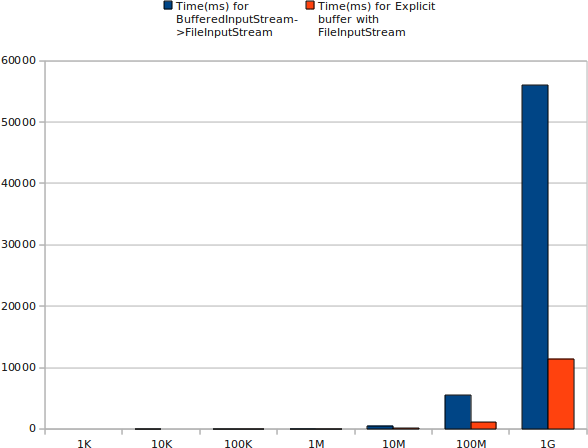
讀測試結果:(所有數據都是在JVM預熱后取得的,每個采樣點的時間是10次讀取操作的總時間,單位為毫秒)
| 文件大小 |
1K |
10K
|
100K
|
1M
|
10M
|
100M
|
1G
|
| BufferedInputStream |
0 |
1
|
5 |
53 |
549 |
5492 |
56002 |
| 顯式使用byte[]在FileInputStream上讀取 |
0 |
0 |
1
|
10
|
113
|
1126
|
11448
|
 寫測試結果:
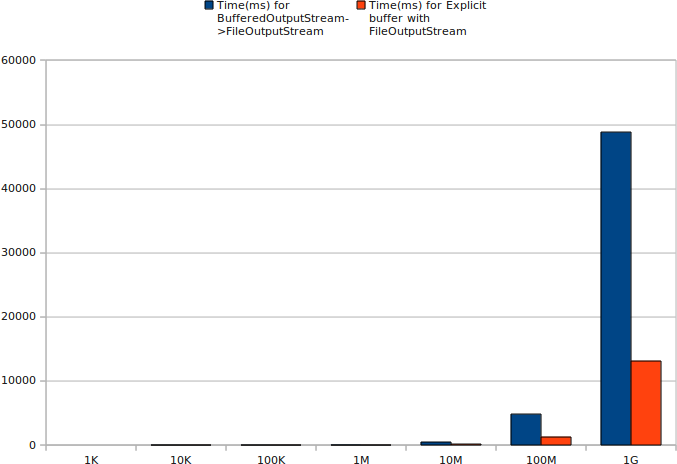
寫測試結果:(所有數據都是在JVM預熱后取得的,每個采樣點的時間是10次寫入操作的總時間,單位為毫秒)
| 文件大小 |
1K |
10K
|
100K
|
1M
|
10M
|
100M
|
1G
|
| BufferedOutputStream |
0 |
1
|
5 |
45 |
472 |
4793 |
48794 |
| 顯式使用byte[]在FileOuputStream上寫入 |
0 |
1 |
1
|
10
|
124
|
1300
|
13138
|
為什么會有如此大的性能差異呢?有兩點原因:
-
Buffer版的IO類導致很多無謂的棧調用(都是裝飾者模式惹得禍decorator pattern)
-
JDK中所有的Buffer版IO類都是線程安全的,這就意味著它們添加了大量的同步保護(將在第二部分中詳細解釋)
現在你知道了顯式使用buffer要比使用Buffer版的IO類具有更好的性能,所以請盡量多顯式使用buffer,但在兩種特殊情況下你仍然需要Buffer版的IO類:
-
當你在使用第三方庫時,庫的api需要IO類作為參數,并且你確定他們內部的代碼采用流式方式編碼(非塊式操作),也就是沒有顯式使用buffer。在不修改他們代碼的前提下,你只能通過傳入Buffer版的IO類對象來提升性能。
-
另外一種情況就是,如果你很懶,你會更傾向于使用Buffer版的IO類,因為它們能節省你幾行代碼(相對于顯式使用buffer)。
第二部分:
對于2,過度的同步保護,我指的是JDK的IO包,也就是java.io包。
我一點也不喜歡這個包里面的代碼,因為他們都是線程安全的,也就意味著許多同步保護。如果我需要同步保護,我會自己去做,而且我絕不會去添加任何多余的保護。但在這一點上JDK的IO包把我逼得無路可走

只要你使用JDK的IO包,你就被迫的添加了許多同步保護,即使你完全確定你的代碼運行在單一線程的環境下,你也不能回避這些不必要的保護。你也許會好奇的問,這真的是一個嚴重的問題嗎?JVM在運行時會對弱競爭的鎖進行優化,不是嗎?顯然,它做的優化還不到家,讓我們來看一下性能測試結果。
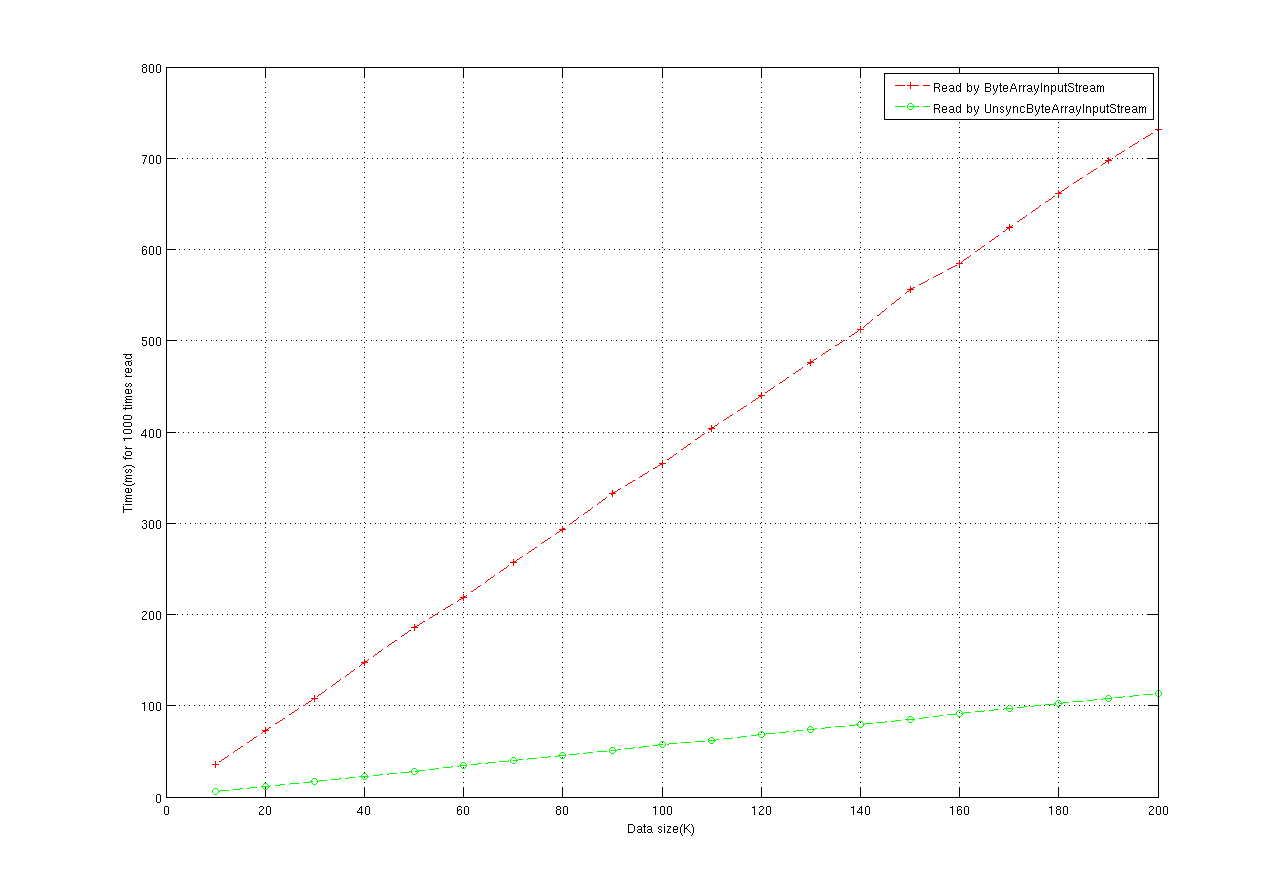
我翻版了一批JDK IO包中常用的類,這個翻版完全是API層次的翻版,也就是說全部代碼是參照JDK IO包的Javadoc寫成, 沒有直接借用JDK的源碼。因為JDK源碼大部分使用GPL協議發布,而Liferay的代碼采用MIT協議發布,為了不引起IP糾紛只好照葫蘆畫瓢。而實際上從0開始創建這些類一點也不難(僅僅是裝飾者模式而已),只是非常的繁瑣。在我的翻版類中,我移除了全部的同步保護。而我的測試也進行在單一線程環境下,所以不用擔心線程安全的問題。
測試包含兩部分,第一部分比較原始JDK IO類和我的unsyc版的IO類在讀取內存數據(In-memory data)時的性能差異,第二部分比較原始JDK IO類和我的unsyc版的IO類在寫入內存數據(In-memory data)時的性能差異。之所以采用內存數據而不是磁盤數據是為了放大同步操作對整體性能的影響,以便于分析。
讀測試結果:
 寫測試結果:
寫測試結果:
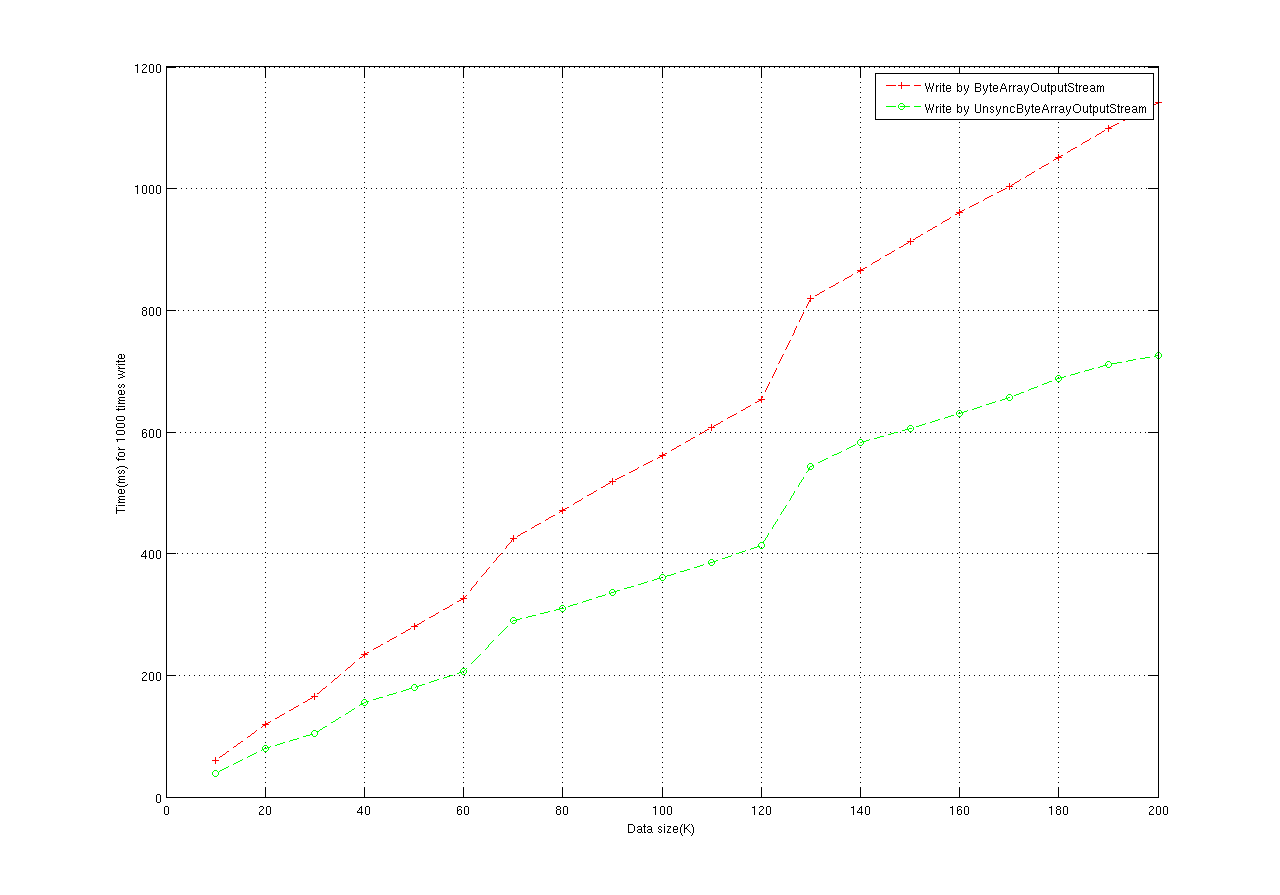
寫數據的測試曲線不像讀的那樣平滑,原因在于它內部使用了一個動態增長的byte[],這導致大量GC活動(與上一期Blog中我們討論SB時看到的問題相似)。
好了,現在你應該看到了同步保護是一項多么沉重的操作。我們日常開發中存在大量局限在方法調用棧內的IO類使用,這些情況都是絕對發生在單一線程環境下的。另外一些時候,即使IO對象的引用超出了方法調用棧的作用域,但我們可以通過分析得知它仍然只會被單一線程所訪問,比如web開發中,針對一個request的全部處理一般都是由一個worker thread來完成的(除非你的后臺還有其他的異步服務線程與worker間交換數據,但這很少見)。對于這樣的情況,你大可以放心的使用這些unsyc的IO類(com.liferay.portal.kernel.io.unsync)。
更多關于unsycIO類的信息請查看Liferay的JIRA鏈接:
http://issues.liferay.com/browse/LPS-6648
最后給大家留下一些建議:
-
如果可能請盡量顯式使用buffer,而不是使用Buffer版的IO類。
-
僅在使用第三方類庫和你很懶的時候使用Buffer版的IO類。
-
當你確定你的代碼運行在單一線程環境下,或者你自己添加了同步保護時,請使用com.liferay.portal.kernel.io.unsync包中的IO類。它們能大幅提高你的應用的IO性能。
這里我提供了一個消除了對Liferay其他類文件依賴的com.liferay.portal.kernel.io.unsync包供大家下載使用。不過還是推薦大家直接學習使用Liferay:)
http://www.tkk7.com/Files/ShuyangZhou/IOPerformance/src.zip