基本類型編碼
在前文有提到消息是一系列的基本類型以及其他消息類型的組合,因而基本類型是probobuf編碼實現的基礎,這些基本類型有:
| .proto Type | Java Type | C++ Type | Wire Type |
| double | double | double | WIRETYPE_FIXED64(1) |
| float | float | float | WIRETYPE_FIXED32(5) |
| int64 | long | int64 | WIRETYPE_VARINT(0) |
| int32 | int | int32 | WIRETYPE_VARINT(0) |
| uint64 | long | unit64 | WIRETYPE_VARINT(0) |
| uint32 | int | unit32 | WIRETYPE_VARINT(0) |
| sint64 | long | int64 | WIRETYPE_VARINT(0) |
| sint32 | int | int32 | WIRETYPE_VARINT(0) |
| fixed64 | long | unit64 | WIRETYPE_FIXED64(1) |
| fixed32 | int | unit32 | WIRETYPE_FIXED32(5) |
| sfixed64 | long | int64 | WIRETYPE_FIXED64(1) |
| sfixed32 | int | int32 | WIRETYPE_FIXED32(5) |
| bool | boolean | bool | WIRETYPE_VARINT(0) |
| string | String | string | WIRETYPE_LENGTH_DELIMITED(2) |
| bytes | ByteString | string | WIRETYPE_LENGTH_DELIMITED(2) |
在Java種對不同類型的選擇,其他的類型區別很明顯,主要在與int32、uint32、sint32、fixed32中以及對應的64位版本的選擇,因為在Java中這些類型都用int(long)來表達,但是protobuf內部使用ZigZag編碼方式來處理多余的符號問題,但是在編譯生成的代碼中并沒有驗證邏輯,比如uint的字段不能傳入負數之類的。而從編碼效率上,對fixed32類型,如果字段值大于2^28,它的編碼效率比int32更加有效;而在負數編碼上sint32的效率比int32要高;uint32則用于字段值永遠是正整數的情況。
在實現上,protobuf使用CodedOutputStream實現序列化邏輯、CodedInputStream實現反序列化邏輯,他們都包含write/read基本類型和Message類型的方法,write方法中同時包含fieldNumber和value參數,在寫入時先寫入由fieldNumber和WireType組成的tag值(添加這個WireType類型信息是為了在對無法識別的字段編碼時可以通過這個類型信息判斷使用那種方式解析這個未知字段,所以這幾種類型值即可),這個tag值是一個可變長int類型,所謂的可變長類型就是一個字節的最高位(msb,most significant bit)用1表示后一個字節屬于當前字段,而最高位0表示當前字段編碼結束。在寫入tag值后,再寫入字段值value,對不同的字段類型采用不同的編碼方式:
1. 對int32/int64類型,如果值大于等于0,直接采用可變長編碼,否則,采用64位的可變長編碼,因而其編碼結果永遠是10個字節,所有說它int32/int64類型在編碼負數效率很低(然而這里我一直木有想明白對int32類型為什么需要做64位的符號擴展,不擴展,5個字節就可以了啊,而且對64位的負數也不需要用符號擴展,或者無法符號擴展,google上也沒有找到具體原因)。
2. 對uint32/uint64類型,也采用變長編碼,不對負數做驗證。
3. 對sint32/sint64類型,首先對該值做ZigZag編碼,以保留,然后將編碼后的值采用變長編碼。所謂ZigZag編碼即將負數轉換成正數,而所有正數都乘2,如0編碼成0,-1編碼成1,1編碼成2,-2編碼成3,以此類推,因而它對負數的編碼依然保持比較高的效率。
4. 對fixed32/sfixed32/fixed64/sfixed64類型,直接將該值以小端模式的固定長度編碼。
5. 對double類型,先將double轉換成long類型,然后以8個字節固定長度小端模式寫入。
6. 對float類型,先將float類型轉換成int類型,然后以4個字節固定長度小端模式寫入。
7. 對bool類型,寫0或1的一個字節。
8. 對string類型,使用UTF-8編碼獲取字節數組,然后先用變長編碼寫入字節數組長度,然后寫入所有的字節數組。
9. 對bytes類型(ByteString),先用變長編碼寫入長度,然后寫入整個字節數組。
10. 對枚舉類型(類型值WIRETYPE_VARINT),用int32編碼方式寫入定義枚舉項時給定的值(因而在給枚舉類型項賦值時不推薦使用負數,因為int32編碼方式對負數編碼效率太低)。
11. 對內嵌Message類型(類型值WIRETYPE_LENGTH_DELIMITED),先寫入整個Message序列化后字節長度,然后寫入整個Message。
注:ZigZag編碼實現:(n << 1) ^ (n >> 31) / (n << 1) ^ (n >> 63);在CodedOutputStream中還存在一些用于計算某個字段可能占用的字節數的compute靜態方法,這里不再詳述。
在protobuf的序列化中,所有的類型最終都會轉換成一個可變長int/long類型、固定長度的int/long類型、byte類型以及byte數組。對byte類型的寫只是簡單的對內部buffer的賦值:
public void writeRawByte(final byte value) throws IOException {
if (position == limit) {
refreshBuffer();
}
buffer[position++] = value;
}
對32位可變長整形實現為:
public void writeRawVarint32(int value) throws IOException {
while (true) {
if ((value & ~0x7F) == 0) {
writeRawByte(value);
return;
} else {
writeRawByte((value & 0x7F) | 0x80);
value >>>= 7;
}
}
}
對于定長,protobuf采用小端模式,如對32位定長整形的實現: public void writeRawLittleEndian32(final int value) throws IOExcep-tion {
writeRawByte((value ) & 0xFF);
writeRawByte((value >> 8) & 0xFF);
writeRawByte((value >> 16) & 0xFF);
writeRawByte((value >> 24) & 0xFF);
}
對byte數組,可以簡單理解為依次調用writeRawByte()方法,只是CodedOutputStream在實現時做了部分性能優化。這里不詳細介紹。
對CodedInputStream則是根據CodedOutputStream的編碼方式進行解碼,因而也不詳述,其中關于ZigZag的解碼:(n >>> 1) ^ -(n & 1)
repeated字段編碼
對于repeated字段,一般有兩種編碼方式:
1. 每個項都先寫入tag,然后寫入具體數據。如對基本類型:
而對message類型:
| Tag | Length | Data | Tag | Length | Data | … |
2. 先寫入tag,后count,再寫入count個項,每個項包含length|data數據。即:
| Tag | Count | Length | Data | Length | Data | … |
從編碼效率的角度來看,個人感覺第二中情況更加有效,然而不知道處于什么原因考慮,protobuf采用了第一種方式來編碼,個人能想到的一個理由是第一種情況下,每個消息項都是相對獨立的,因而在傳輸過程中接收端每接收到一個消息項就可以進行解析,而不需要等待整個repeated字段的消息包。對于基本類型,protobuf也采用了第一種編碼方式,后來發現這種編碼方式效率太低,因而可以添加[packed = true]的描述將其轉換成第三種編碼方式(第二種方式的變種,對基本數據類型,比第二種方式更加有效):
3. 先寫入tag,后寫入字段的總字節數,再寫入每個項數據。即:
| Tag | dataByteSize | Data | Data | … |
目前protobuf只支持基本類型的packed修飾,因而如果將packed添加到非repeated字段或非基本類型的repeated字段,編譯器在編譯.proto文件時會報錯。
未識別字段編碼
在protobuf中,將所有未識別字段保存在UnknownFieldSet中,并且在每個由protobuf編譯生成的Message類以及GeneratedMessage.Builder中保存了UnknownFieldSet字段unknownFields;該字段可以從CodedInputStream中初始化(調用UnknownFieldSet.Builder的mergeFieldFrom()方法)或從用戶自己通過Builder設置;在序列化時,調用UnknownFieldSet的writeTo()方法將自身內容序列化到CodedOutputStream中。
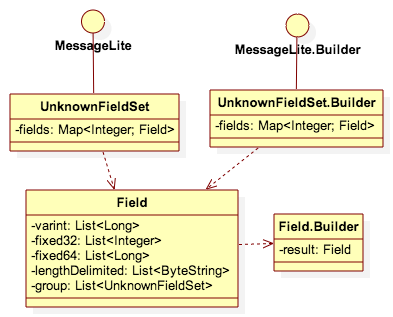
UnknownFieldSet顧名思義是未知字段的集合,其內部數據結構是一個FieldNumber到Field的Map,而一個Field用于表達一個未知字段,它可以是任何值,因而它包含了所有5中類型的List字段,這里并沒有對一個Field驗證,因而允許多個相同FieldNumber的未知字段,并且他們可以是任意類型值。UnknownFieldSet采用MessageLite編程模式,因而它實現了MessageLite接口,并且定義了一個Builder類實現MessageLite.Builder接口用于手動或從CodedInputStream中構建UnknownFieldSet。雖然Field本身沒有實現MessageLite接口,它依然實現了該接口的部分方法,如writeTo()、getSerializedSize()用于實現向CodedOutputStream中序列化自身,并且定義了Field.Builder類用于構建Field實例。
在一個Message序列化時(writeTo()方法實現),在寫完所有可識別的字段以及擴展字段,這個定義在Message中的UnknownFieldSet也會被寫入CodedOutputStream中;而在從CodedInputStream中解析時,對任何未知字段也都會被寫入這個UnknownFieldSet中。
擴展字段編碼
在寫框架代碼時,經常由擴展性的需求,在Java中,只需要簡單的定義一個父類或接口即可解決,如果框架本身還負責構建實例本身,可以使用反射或暴露Factory類也可以順利實現,然而對序列化來說,就很難提供這種動態plugin機制了。然而protobuf還是提出來一個相對可以接受的機制(語法有點怪異,但是至少可以用):在一個message中定義它支持的可擴展字段值的范圍,然后用戶可以使用extend關鍵字擴展該message定義(具體參考相關章節)。在實現中,所有這些支持字段擴展的message類型繼承自ExtendableMessage類(它本身繼承自GeneratedMessage類)并實現ExtendableMessageOrBuilder接口,而它們的Builder類則繼承自ExtendableBuilder類并且同時也實現了ExtendableMessageOrBuilder接口。
ExtendableMessage和ExtendableBuilder類都包含FieldSet<FieldDescriptor>類型的字段用于保存該message所有的擴展字段值。FieldSet中保存了FieldDescriptor到其Object值的Map,然而在ExtendableMessage和ExtendableBuilder中則使用GeneratedExtension來表識一個擴展字段,這是因為GeneratedExtension除了包含對一個擴展字段的描述信息FieldDescriptor外,還存儲了該擴展字段的類型、默認值等信息,在protobuf消息定義編譯器中會為每個擴展字段生成相應的GeneratedExtension實例以供用戶使用:
public static final GeneratedExtension<Foo, Integer> bar = Generated-Message.newFileScopedGeneratedExtension( Integer.
class,
null );

bar.internalInit(descriptor.getExtensions().get(0));
Base base = Base.newBuilder().setExtension(SearchRequestProtos.bar, 11).build();
用戶使用該bar靜態字段用于作為key與它對應的值關聯,這種關聯關系寫入extensions字段中。從而在序列化時,對每個字段,按正常的值字段先寫Tag在寫實際值內容將它序列化到CodedOutputStream中(ExtensionWriter.writeUntil()方法);在反序列化中,我們需要告訴protobuf哪些字段是擴展字段,從而它在解析到無法識別的字段可以判斷這個字段是否是擴展字段,因而protobuf提供了ExtensionRegistry類,它用于注冊所有識別的擴展字段,并且在protobuf編譯出來的代碼中也存在一個靜態方法將所有已定義的擴展字段注冊到用戶提供的ExtensionRegistry實例中: public static void registerAllExtensions(ExtensionRegistry registry) {
registry.add(SearchRequestProtos.bar);
}

posted on 2015-04-01 09:23
DLevin 閱讀(11400)
評論(1) 編輯 收藏 所屬分類:
Protobuf