前記
幾年前在讀Google的BigTable論文的時候,當時并沒有理解論文里面表達的思想,因而囫圇吞棗,并沒有注意到SSTable的概念。再后來開始關注HBase的設計和源碼后,開始對BigTable傳遞的思想慢慢的清晰起來,但是因為事情太多,沒有安排出時間重讀BigTable的論文。在項目里,我因為自己在學HBase,開始主推HBase,而另一個同事則因為對Cassandra比較感冒,因而他主要關注Cassandra的設計,不過我們兩個人偶爾都會討論一下技術、設計的各種觀點和心得,然后他偶然的說了一句:Cassandra和HBase都采用SSTable格式存儲,然后我本能的問了一句:什么是SSTable?他并沒有回答,可能也不是那么幾句能說清楚的,或者他自己也沒有嘗試的去問過自己這個問題。然而這個問題本身卻一直困擾著我,因而趁著現在有一些時間深入學習HBase和Cassandra相關設計的時候先把這個問題弄清楚了。
SSTable的定義
要解釋這個術語的真正含義,最好的方法就是從它的出處找答案,所以重新翻開BigTable的論文。在這篇論文中,最初對SSTable是這么描述的(第三頁末和第四頁初):
簡單的非直譯:
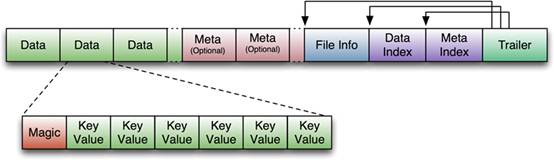
SSTable是Bigtable內部用于數據的文件格式,它的格式為文件本身就是一個排序的、不可變的、持久的Key/Value對Map,其中Key和value都可以是任意的byte字符串。使用Key來查找Value,或通過給定Key范圍遍歷所有的Key/Value對。每個SSTable包含一系列的Block(一般Block大小為64KB,但是它是可配置的),在SSTable的末尾是Block索引,用于定位Block,這些索引在SSTable打開時被加載到內存中,在查找時首先從內存中的索引二分查找找到Block,然后一次磁盤尋道即可讀取到相應的Block。還有一種方案是將這個SSTable加載到內存中,從而在查找和掃描中不需要讀取磁盤。這個貌似就是HFile第一個版本的格式么,貼張圖感受一下:
在HBase使用過程中,對這個版本的HFile遇到以下一些問題(參考
這里):
1. 解析時內存使用量比較高。
2. Bloom Filter和Block索引會變的很大,而影響啟動性能。具體的,Bloom Filter可以增長到100MB每個HFile,而Block索引可以增長到300MB,如果一個HRegionServer中有20個HRegion,則他們分別能增長到2GB和6GB的大小。HRegion需要在打開時,需要加載所有的Block索引到內存中,因而影響啟動性能;而在第一次Request時,需要將整個Bloom Filter加載到內存中,再開始查找,因而Bloom Filter太大會影響第一次請求的延遲。
而HFile在版本2中對這些問題做了一些優化,具體會在HFile解析時詳細說明。
SSTable作為存儲使用
繼續BigTable的論文往下走,在5.3 Tablet Serving小節中這樣寫道(第6頁):
第一段和第三段簡單描述,非翻譯:
在新數據寫入時,這個操作首先提交到日志中作為redo紀錄,最近的數據存儲在內存的排序緩存memtable中;舊的數據存儲在一系列的SSTable
中。在recover中,tablet
server從METADATA表中讀取metadata,metadata包含了組成Tablet的所有SSTable(紀錄了這些SSTable的元
數據信息,如SSTable的位置、StartKey、EndKey等)以及一系列日志中的redo點。Tablet
Server讀取SSTable的索引到內存,并replay這些redo點之后的更新來重構memtable。
在讀時,完成格式、授權等檢查后,讀會同時讀取SSTable、memtable(HBase中還包含了BlockCache中的數據)并合并他們的結果,由于SSTable和memtable都是字典序排列,因而合并操作可以很高效完成。
SSTable在Compaction過程中的使用
在BigTable論文5.4 Compaction小節中是這樣說的:
隨著memtable大小增加到一個閥值,這個memtable會被凍住而創建一個新的memtable以供使用,而舊的memtable會轉換成一個SSTable而寫道GFS中,這個過程叫做minor compaction。這個minor compaction可以減少內存使用量,并可以減少日志大小,因為持久化后的數據可以從日志中刪除。在minor compaction過程中,可以繼續處理讀寫請求。
每次minor compaction會生成新的SSTable文件,如果SSTable文件數量增加,則會影響讀的性能,因而每次讀都需要讀取所有SSTable文件,然后合并結果,因而對SSTable文件個數需要有上限,并且時不時的需要在后臺做merging compaction,這個merging compaction讀取一些SSTable文件和memtable的內容,并將他們合并寫入一個新的SSTable中。當這個過程完成后,這些源SSTable和memtable就可以被刪除了。
如果一個merging compaction是合并所有SSTable到一個SSTable,則這個過程稱做major compaction。一次major compaction會將mark成刪除的信息、數據刪除,而其他兩次compaction則會保留這些信息、數據(mark的形式)。Bigtable會時不時的掃描所有的Tablet,并對它們做major compaction。這個major compaction可以將需要刪除的數據真正的刪除從而節省空間,并保持系統一致性。SSTable的locality和In Memory
在Bigtable中,它的本地性是由Locality group來定義的,即多個column family可以組合到一個locality group中,在同一個Tablet中,使用單獨的SSTable存儲這些在同一個locality group的column family。HBase把這個模型簡化了,即每個column family在每個HRegion都使用單獨的HFile存儲,HFile沒有locality group的概念,或者一個column family就是一個locality group。在Bigtable中,還可以支持在locality group級別設置是否將所有這個locality group的數據加載到內存中,在HBase中通過column family定義時設置。這個內存加載采用延時加載,主要應用于一些小的column family,并且經常被用到的,從而提升讀的性能,因而這樣就不需要再從磁盤中讀取了。SSTable壓縮
Bigtable的壓縮是基于locality group級別:
Bigtable的壓縮以SSTable中的一個Block為單位,雖然每個Block為壓縮單位損失一些空間,但是采用這種方式,我們可以以Block為單位讀取、解壓、分析,而不是每次以一個“大”的SSTable為單位讀取、解壓、分析。SSTable的讀緩存
為了提升讀的性能,Bigtable采用兩層緩存機制:
兩層緩存分別是:
1. High Level,緩存從SSTable讀取的Key/Value對。提升那些傾向重復的讀取相同的數據的操作(引用局部性原理)。
2. Low Level,BlockCache,緩存SSTable中的Block。提升那些傾向于讀取相近數據的操作。
Bloom Filter
前文有提到Bigtable采用合并讀,即需要讀取每個SSTable中的相關數據,并合并成一個結果返回,然而每次讀都需要讀取所有SSTable,自然會耗費性能,因而引入了Bloom Filter,它可以很快速的找到一個RowKey不在某個SSTable中的事實(注:反過來則不成立)。
SSTable設計成Immutable的好處
在SSTable定義中就有提到SSTable是一個Immutable的order map,這個Immutable的設計可以讓系統簡單很多:
關于Immutable的優點有以下幾點:1. 在讀SSTable是不需要同步。讀寫同步只需要在memtable中處理,為了減少memtable的讀寫競爭,Bigtable將memtable的row設計成copy-on-write,從而讀寫可以同時進行。2. 永久的移除數據轉變為SSTable的Garbage Collect。每個Tablet中的SSTable在METADATA表中有注冊,master使用mark-and-sweep算法將SSTable在GC過程中移除。3. 可以讓Tablet Split過程變的高效,我們不需要為每個子Tablet創建新的SSTable,而是可以共享父Tablet的SSTable。
posted on 2015-09-25 01:35
DLevin 閱讀(15887)
評論(0) 編輯 收藏 所屬分類:
HBase