在上一篇《
Java Cache-EHCache系列之AA-Tree實現溢出到磁盤的數據管理(1)》已經詳細講解了EHCache中在AATreeSet中對AA Tree算法的實現,并且指出EHCache是采用它作為空閑磁盤管理數據結構,本文主要關注于EHCache是如何采用AATreeSet類來管理空閑磁盤的(這里的磁盤管理是只EHCache data文件中的空閑磁盤)。
空閑磁盤管理數據結構和算法
在上一篇《
Java Cache-EHCache系列之AA-Tree實現溢出到磁盤的數據管理》有提到類似內存分配管理,空閑磁盤管理可以采用多種數據結構,也有多種算法實現,EHCache采用AA Tree作為空閑磁盤的數據結構,以及首次適應算法和最壞適應算法相結合的算法。
最壞適應算法(Worst Fit),在《計算機操作系統(湯子瀛版)》中對該算法描述如下:最壞適應分配算法要掃瞄整個空閑分區表或鏈表,總是挑選一個最大的空閑分區分分割給作業使用,其優點是可使剩下的空閑區不至于太小,產生碎片的幾率最小,對中小作業有利,同時最壞適應算法查找效率很高。該算法要求將所有的空閑分區按其容量以從大到小的順序形成一空閑分區鏈,查找時只要看第一個分區能否滿足作業要求。但該算法的缺點也時明顯的,它會使存儲器中缺乏大的空閑分區。最壞適應算法與前面所述的首次適應算法、循環首次適應算法、最佳適應算法一起被成為順序搜索算法。
首次適應算法在《計算機操作系統(湯子瀛版)》描述如下:我們以空閑分區鏈為例來說明采用FF算法時的分配情況。FF算法要求空閑分區鏈以地址遞增次序鏈接。在分配內存時,從鏈首開始順序查找,直到找到一個大小能滿足要求的空閑分區為止;然后再按照作業的大小,從該分區中劃出一塊內存空間分配給請求者,余下的空閑分區仍留在空閑鏈中。若從鏈首直至鏈尾都不能找到一個滿足要求的分區,則此次內存分配失敗,返回。該算法傾向于有限利用內存中低地址部分的空閑分區,從而保留了高地址部分的大空閑區。這給尾以后到達的大作業分配大的內存空間創造了條件。其缺點時低地址部分不斷被劃分,會留下許多難以利用的、很小的空閑分區,而每次查找右都時從低地址部分開始,這無疑會增加查找可用空閑分區時的開銷。
作為Cache的溢出數據文件作為Cache的交換區,顯然我們希望數據文件越小越好,此時一般的選擇是使用首次適應算法(First Fit)。然而雖然FF算法能盡可能多的利用數據文件低地址部分的磁盤空間以減少磁盤文件的大小,但是它的缺點也是明顯的,而WF算法雖然效率很高,但是它很容易使數據文件膨脹導致磁盤利用率很低。因而EHCache的空閑磁盤去管理時采用了兩種結合的方法:即空閑鏈(AA Tree鏈)的以磁盤地址順序排列,樹的每個節點包含一個字段用于紀錄當前節點以及其所有子節點中的最大size,在查找時,以層級順序遍歷,并且優先選擇左子樹(磁盤地址低的Region)。
EHCache將一個空閑磁盤區抽象成一個Region類,它包含start、end字段,用于紀錄在當前該區域在磁盤文件中的其實位置;并且每個Region實例是AA Tree中的一個節點,因而它繼承自AATreeSet.AbstractTreeNode類,即繼承了該類的left、right、level字段;根據Region的比較算法,它大致上以Region所在磁盤文件的位置排序(而不是以Region的大小來排序),因而為了提升查找性能,它還包含了一個long類型的contiguous字段,該單詞字面意思是“臨近的、連續的”,用于表示該當前Region臨近節點的區域的最大Region大小,即該字段表示當前Region以及其所有子節點的最大Region的大小,從而當在查找時,只有如果要查找的size比當前Region的contiguous字段要大的話,就可以不用繼續查找其子節點了,并且通過該字段也實現了最壞適應算法。在每次更新左子節點和右子節點時都會調整contiguous的大小,在新創建一個Region節點時也會更新contiguous字段大小,從而保證當前Region中的contiguous始終是其所有子節點的最大size,對于葉子節點,其contiguous的值是當前Region的size。在計算size時,start,end值是閉合的。
public abstract static class AbstractTreeNode<E> implements Node<E> {
private Node<E> left;
private Node<E> right;
private int level;
.....
}
public class Region extends AATreeSet.AbstractTreeNode<Comparable> implements Comparable<Comparable> {
private long start;
private long end;
private long contiguous;
public Region(long start, long end) {
super();
this.start = start;
this.end = end;
updateContiguous();
}
public long contiguous() {
if (getLeft().getPayload() == null && getRight().getPayload() == null) {
return size();
} else {
return contiguous;
}
}
private void updateContiguous() {
Region left = (Region) getLeft().getPayload();
Region right = (Region) getRight().getPayload();
long leftContiguous = left == null ? 0 : left.contiguous();
long rightContiguous = right == null ? 0 : right.contiguous();
contiguous = Math.max(size(), Math.max(leftContiguous, rightContiguous));
}
public void setLeft(AATreeSet.Node<Comparable> l) {
super.setLeft(l);
updateContiguous();
}
public void setRight(AATreeSet.Node<Comparable> r) {
super.setRight(r);
updateContiguous();
}
public long size() {
// since it is all inclusive
return (isNull() ? 0 : this.end - this.start + 1);
}
//Region的比較算法,使Region在這棵AA Tree中大致保持其在數據文件中的排序順序
public int compareTo(Comparable other) {
if (other instanceof Region) {
return compareTo((Region) other);
} else if (other instanceof Long) {
return compareTo((Long) other);
} else {
throw new AssertionError("Unusual Type " + other.getClass());
}
}
private int compareTo(Region r) {
if (this.start > r.start || this.end > r.end) {
return 1;
} else if (this.start < r.start || this.end < r.end) {
return -1;
} else {
return 0;
}
}
private int compareTo(Long l) {
if (l.longValue() > end) {
return -1;
} else if (l.longValue() < start) {
return 1;
} else {
return 0;
}
}
}
EHCache中對空閑磁盤的分配與回收
在C語言中使用malloc和free來對內存的分配與回收,在C++中使用new和delete,在Java中只有new,在EHCache中則將磁盤空間的分配與回收抽象成FileAllocationTree類,它提供alloc、free、mark等接口用于管理磁盤區的分配與回收。另外EHCache還增加了RegionSet類,它繼承子AATreeSet類,用于表達它專門用于存儲Region節點。這里吐槽一下,FileAllocationTree竟然設計成繼承自RegionSet而不是組合。。。。。所有這些類的結構圖如下:
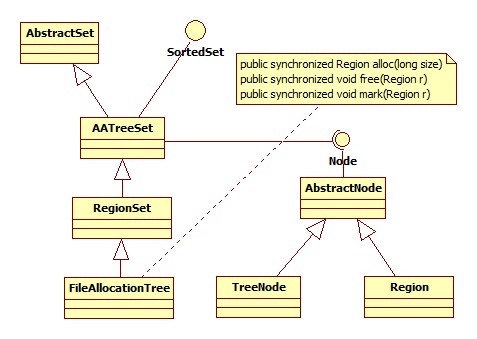 磁盤的分配
磁盤的分配
磁盤的分配分成一下幾個步驟(邏輯比較簡單,就不貼代碼了):
- 根據傳入的size,在AA Tree中查找到一個可以容納傳入size大小的Region節點,并將找到的Region的前size部分分配出一個新的Region并返回。
查找邏輯在RegionSet類中實現(find方法),它從root節點向下查找,因為root節點的contiguous字段保存了整棵樹的最大size,因而先檢查root節點的contiguous,如果size比root的Contiguous要大,則拋異常,因為整棵樹中已經沒有比傳入的size要大的Region。然后層級遍歷AA樹,如果當前節點的size要比傳入的size大或相等,則找到足以容納傳入size大小的Region節點,以當前節點的size大小的前部分新創建一個Region返回;否則如果它的左子樹的contiguous字段要比傳入size大,則向左子樹查找;否則如果它的右子樹的contiguous字段要比傳入的size大,則向右子樹查找;否則,拋出異常,因為左右子樹都找不到可以容納size大小的Region。
- 將新創建的Region實例mark成已經使用(這個新創建的Region的start和AA樹中某個Region節點的start值一樣,而end大小則不一定一樣)。
因為這個新創建的Region實例是要從AA樹中的某個節點分出部分空間,因而首先要將AA樹中的那個節點從樹中移除,然后如果樹中移除的節點的end值和新創建的Region的end值一樣,則直接移除就可以了,否則,要將樹種移除的節點剩余部分的重新創建一個Region插回樹中。從代碼的角度,首先以新創建的Region的start值找到樹中對應的Region(Region中接收Long作為參數的compare方法的存在以實現這種方式的查找),將其移除并返回移除后的Region(removeAndReturn方法,在RegionSet中重新拷貝一個Region實例是為了防止通過R返回的Region改變樹內部的狀態,因為Region即作為一個Node也作為payload存在,同時也可以給接下來的插入提供新的Region節點),然后把將新創建的Region從原樹中的Region中移除,這里的移除邏輯假設新創建的Region可以是原樹中的Region的前部分、中間部分以及末位部分,作為前部分和末位部分,因為Region是新創建的節點,因而直接更新當前節點即可,而如果是中間部分,則前部分作為當前節點,而后部分作為新節點返回。最后,如果原樹中節點還剩余部分數據作為新的空閑磁盤區添回到空閑磁盤樹中。最后,檢查是否需要增加文件大小,這里只需要更新文件大小的字段即可而不需要實際增加文件的大小,因為文件在寫入時會自動增加大小。Region中移除其中的部分Region代碼如下:
protected Region remove(Region r) throws IllegalArgumentException {
if (r.start < this.start || r.end > this.end) {
throw new IllegalArgumentException("Ranges : Illegal value passed to remove : " + this + " remove called for : " + r);
}
if (this.start == r.start) {
this.start = r.end + 1;
updateContiguous();
return null;
} else if (this.end == r.end) {
this.end = r.start - 1;
updateContiguous();
return null;
} else {
Region newRegion = new Region(r.end + 1, this.end);
this.end = r.start - 1;
updateContiguous();
return newRegion;
}
}
- 最后將分配出來的Region實例返回,并紀錄在DiskMarker中,在以后需要將磁盤中的數據重新讀取到內存中時用于定位該數據在磁盤中的位置,并可以將該Regin回收。
磁盤的回收
磁盤的回收也分幾個步驟來完成:
- 對要回收的Region,查找在當前樹中是否有一個Region節點其start和要回收的Region的(end - 1)值相等,如果有,則刪除樹中的原節點并返回,合并這兩個節點,將合并后的節點重新插入到樹中。Region中合并的代碼邏輯如下:
protected void merge(Region r) throws IllegalArgumentException {
if (this.start == r.end + 1) {
this.start = r.start;
} else if (this.end == r.start - 1) {
this.end = r.end;
} else {
throw new IllegalArgumentException("Ranges : Merge called on non contiguous values : [this]:" + this + " and " + r);
}
updateContiguous();
}
- 對要回收的Region(或合并后的Region),繼續查找當前樹是否有一個Region節點,其end和要回收的(或已合并的)Region的(start - 1)的值相等,如果有,則刪除樹中的原節點并返回,合并這兩個節點,將合并后的節點繼續插入樹中。
- 如果在樹中找不到可以和回收的Region合并的Region節點,則只是將要合并的Region添加到樹中。
- 最后如果回收后數據文件可以減小,更新數據文件大小的字段,并將數據文件的縮小,從而保持數據文件處于盡量小的狀態。
最后我寫了一個簡單的測試程序,對磁盤分配與釋放做了一些隨機的模擬,以增加一些直觀的感受(類似DiskStorageFactory,在創建FileAllocationTree時,給了Long.MAX_VALUE的初始值,我這也給這個值作為初始值,從而保證基本上在所有情況下,都能找到一個合適的Region節點,也就是說FileAllocationTree不用來控制數據文件的大小,數據文件的大小由其他邏輯來控制,這在后面會詳細講解):
public class FileAllocationTreeTest {
public static void main(String[] args) {
final int count = 5;
Random random = new Random();
FileAllocationTree alloc = new FileAllocationTree(Long.MAX_VALUE, null);
List<Region> allocated = Lists.newArrayList();
for(int i = 0; i < count; i++) {
int size = random.nextInt(1000);
Region region = alloc.alloc(size);
System.out.println("new size: " + size + ", " + toString(region) + ", filesize: " + alloc.getFileSize() + ", allocator: " + toString(alloc));
allocated.add(region);
}
for(int i = 0; i < count; i++) {
int size = random.nextInt(1000);
Region region = alloc.alloc(size);
System.out.println("new size: " + size + ", " + toString(region) + ", filesize: " + alloc.getFileSize() + ", allocator: " + toString(alloc));
allocated.add(region);
region = allocated.get(random.nextInt(allocated.size()));
alloc.free(region);
allocated.remove(region);
System.out.println("Freed region: " + toString(region) + ", after file size: " + alloc.getFileSize() + ", allocator: " + toString(alloc));
}
}
private static String toString(FileAllocationTree alloc) {
StringBuilder builder = new StringBuilder("[");
for(Region region : alloc) {
builder.append(toString(region)).append(", ");
}
builder.replace(builder.length() - 2, builder.length() - 1, "]");
return builder.toString();
}
private static String toString(Region region) {
return "Regin(" + region.start() + ", " + region.end() + ")";
}
}
輸出的隨機結果如下:
new size: 397, Regin(0, 396), filesize: 397, allocator: [Regin(397, 9223372036854775806)]
new size: 175, Regin(397, 571), filesize: 572, allocator: [Regin(572, 9223372036854775806)]
new size: 210, Regin(572, 781), filesize: 782, allocator: [Regin(782, 9223372036854775806)]
new size: 11, Regin(782, 792), filesize: 793, allocator: [Regin(793, 9223372036854775806)]
new size: 432, Regin(793, 1224), filesize: 1225, allocator: [Regin(1225, 9223372036854775806)]
new size: 226, Regin(1225, 1450), filesize: 1451, allocator: [Regin(1451, 9223372036854775806)]
Freed region: Regin(572, 781), after file size: 1451, allocator: [Regin(572, 781), Regin(1451, 9223372036854775806)]
new size: 500, Regin(1451, 1950), filesize: 1951, allocator: [Regin(572, 781), Regin(1951, 9223372036854775806)]
Freed region: Regin(793, 1224), after file size: 1951, allocator: [Regin(572, 781), Regin(793, 1224), Regin(1951, 9223372036854775806)]
new size: 681, Regin(1951, 2631), filesize: 2632, allocator: [Regin(572, 781), Regin(793, 1224), Regin(2632, 9223372036854775806)]
Freed region: Regin(1951, 2631), after file size: 1951, allocator: [Regin(572, 781), Regin(793, 1224), Regin(1951, 9223372036854775806)]
new size: 23, Regin(793, 815), filesize: 1951, allocator: [Regin(572, 781), Regin(816, 1224), Regin(1951, 9223372036854775806)]
Freed region: Regin(0, 396), after file size: 1951, allocator: [Regin(0, 396), Regin(572, 781), Regin(816, 1224), Regin(1951, 9223372036854775806)]
new size: 109, Regin(816, 924), filesize: 1951, allocator: [Regin(0, 396), Regin(572, 781), Regin(925, 1224), Regin(1951, 9223372036854775806)]
Freed region: Regin(1225, 1450), after file size: 1951, allocator: [Regin(0, 396), Regin(572, 781), Regin(925, 1450), Regin(1951, 9223372036854775806)]
posted on 2013-10-29 01:59
DLevin 閱讀(3105)
評論(2) 編輯 收藏 所屬分類:
EHCache