
2012年8月16日
js通過ajax傳給后臺一個json數組字符串:
[{'prjcode':'4209222012A00','countyname':'大悟縣','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005A03','countyname':'大悟縣','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'},{'prjcode':'4209222005B00','countyname':'大悟縣','pro_1':'A','pro_2':'A','pro_3':'A','pro_4':'A','pro_5':'A','pro_6':'A','pro_7':'A','pro_8':'A','pro_9':'A','pro_10':'A','pro_11':'A','pro_12':'A','pro_13':'A','pro_14':'A','pro_15':'A'}]
String jsonstr = request.getParameter("jsonstr");
JSONArray json = JSONArray.fromObject(jsonstr);
Object[] obj=json.toArray();
for(int i=0;i<obj.length;i++){
JSONObject object = JSONObject.fromObject(obj[i]);
String prjcode=object.get("prjcode").toString();
String countyname=object.getString("countyname").toString();
String pro_1=object.getString("pro_1").toString();
String pro_2=object.getString("pro_2").toString();
String pro_3=object.getString("pro_3").toString();
String pro_4=object.getString("pro_4").toString();
String pro_5=object.getString("pro_5").toString();
String pro_6=object.getString("pro_6").toString();
String pro_7=object.getString("pro_7").toString();
String pro_8=object.getString("pro_8").toString();
String pro_9=object.getString("pro_9").toString();
String pro_10=object.getString("pro_10").toString();
String pro_11=object.getString("pro_11").toString();
String pro_12=object.getString("pro_12").toString();
String pro_13=object.getString("pro_13").toString();
String pro_14=object.getString("pro_14").toString();
String pro_15=object.getString("pro_15").toString();
}
posted @
2012-08-16 22:36 zhanghu198901 閱讀(2488) |
評論 (0) |
編輯 收藏
CSS之所以會如此流行,是它具備以下的優點
1、符合W3C標準����。保證網站不會因為將來網絡應用的升級而被淘汰����。
2�����、支持瀏覽器的向后兼容����,也就是無論未來的瀏覽器大戰����,勝利的是IE、chrome或者是火狐�����,網站都能很好的兼容����。
3、搜索引擎更加友好��。相對與傳統的table, 采用DIV+CSS技術的網頁����,更加容易被搜索引擎找到。
4�����、樣式的調整更加方便��。內容和樣式的分離�����,使頁面和樣式的調整變得更加方便����,可以一次性修改多個網頁的樣式,只修改樣式不需要重新發布。
5、降低網頁大小��,對于一個大型網站來說�����,可以節省大量帶寬��,大大提高用戶體驗,這是非常重要的一點——用戶至上。
posted @
2012-08-16 22:36 zhanghu198901 閱讀(1121) |
評論 (0) |
編輯 收藏在網上會有很多關于struts2結合autocomplet插件的實例�����,但是不怎么完整�����,讓人感覺不清楚��,剛剛在公司做了一個關于這個的項目,頁面也用到了這個插件,所以把詳細的步驟和注意事項貼出來和大家分享��,廢話不多說����,貼鐵代碼:本文代碼下載地址:http://download.csdn.net/detail/harderxin/4504612
一����、我的資源中有autcomplet的json實例和autocomplet的源代碼�����,也是copy網上的,大家可以免費下載,下載地址:http://download.csdn.net/detail/harderxin/4504288
二��、開始我們的案例旅程
1��、編寫頁面index.jsp
<body>
自動提示:
<!-- autocomplete防止一些瀏覽器的自動提示完成功能 -->
<input type="text" name="content" id="content" autocomplete="off" onkeyup="value=value.replace(/[^\a-\z\A-\Z0-9\u4E00-\u9FA5]/g,'')"/>
<input type="button" id="button" name="button" value="提交" onclick="" />
<br />
<p>
</p>
</body>
顯示效果如下: 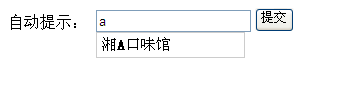
posted @
2012-08-16 22:34 zhanghu198901 閱讀(1267) |
評論 (0) |
編輯 收藏
2012年8月12日
PS:在所有例子中正則表達式匹配結果包含在源文本中的【和】之間����,有的例子會使用java來實現�����,如果是java本身正則表達式的用法��,會在相應的地方說明。所有java例子都在JDK1.6.0_13下測試通過。
一��、對特殊字符進行轉義
元字符是一些在正則表達式里有著特殊含義的字符����。因為元字符在正則表達式里有著特殊的含義,所以這些字符就無法用來代表它們本身�����。在元字符前面加上一個反斜杠就可以對它進行轉義�����,這樣得到的轉義序列將匹配那個字符本身而不是它特殊的元字符含義����。如�����,如果想要匹配[和],就必須對它進行轉義:\[和\]��。
對元字符轉義需要用到斜杠\字符����,這就意味著\字符本向也是一個元字符,要匹配\字符本身��,必須轉義成\\。如匹配windows文件路徑����。
二、匹配空白字符
元字符大致可以分為兩種:一種是用來匹配文本的(如.)�����,另一種是正則表達式的語法所要求的(如[和])��。
在進行正則表達式搜索的時候����,我們經常會遇到需要對原始文本中里的非打印空白字符進行匹配的情況�����。比如說��,我們可能需要把所有的制表符找出來,或者我們需要把換行符找出來��,這類字符很難被直接輸入到一個正則表達式里�����,這時我們可以使用如下列出的特殊元字符來輸入它們:
\b 回退(并刪除)一個字符(Backspace鍵)
\f 換頁符
\n 換行符
\r 回車符
\t 制表符(Tab鍵)
\v 垂直制表符
來看一個例子��,把文件中的空白行去掉:
文本:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 26 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
正則表達式:\r\n\r\n
分析:\r\n匹配一個回車+換行組合,windows操作系統中把它作為文本行的結束標簽�����。使用正則表達式\r\n\r\n進行的搜索將匹配兩個連續的行尾標簽��,而這正好是空白行��。
注意:Unix和Linux操作系統中只使用一個換行符來結束一個文本行,換句話說��,在Unix或Linux系統中匹配空白行只使用\n\n即可�����,不需要加上\r��。同時適用于windows和Unix/Linux的正則表達式應該包括一個可先的\r和一個必須匹配的\n,即\r?\n\r?\n�����,這將會在后面的文章中講到����。
Java代碼如下:
public static void matchBlankLine() throws Exception{
BufferedReader br = new BufferedReader(new FileReader(new File("E:/九宮格.txt")));
StringBuilder sb = new StringBuilder();
char[] cbuf = new char[1024];
int len = 0;
while(br.ready() && (len = br.read(cbuf)) > 0){
br.read(cbuf);
sb.append(cbuf, 0, len);
}
String reg = "\r\n\r\n";
System.out.println("原內容:\n" + sb.toString());
System.out.println("處理后:-----------------------------");
System.out.println(sb.toString().replaceAll(reg, "\r\n"));
}
運行結果如下:原內容:
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
處理后:-----------------------------
8 5 4 1 6 3 2 7 9
7 6 2 9 5 8 3 4 1
9 3 1 4 2 7 8 5 6
6 9 3 8 7 5 1 2 4
5 1 8 3 4 2 6 9 7
2 4 7 6 1 9 5 3 8
3 2 6 7 8 4 9 1 5
4 8 9 5 3 1 7 6 2
1 7 5 2 9 6 4 8 3
三、匹配特定的字符類別
字符集合(匹配多個字符中的某一個)是最常見的匹配形式�����,而一些常用的字符集合可以用特殊元字符來代替�����。這些元字符匹配的是某一類別的字符(類元字符),類元字符并不是必不可少的,因為可以通過逐一列舉有關字符或通過定義一個字符區間來匹配某一類字符����,但是使用它們構造出來的正則表達式簡明易懂��,在實際應用中很常用。
1、匹配數字與非數字
\d 任何一個數字��,等價于[0-9]或[0123456789]
\D 任何一個非數字����,等價于[^0-9]或[^0123456789]
2、匹配字母和數字與非字母和數字
字母(A-Z不區分大小寫)、數字��、下劃線是一種常用的字符集合�����,可用如下類元字符:
\w 任何一個字母(不區分大小寫)��、數字、下劃線����,等價于[0-9a-zA-Z_]
\W 任何一個非字母數字和下劃線����,等價于[^0-9a-zA-Z_]
3�����、匹配空白字符與非空白字符
\s 任何一下空白字符��,等價于[\f\n\r\t\v]
\S 任何一下空白字符,等價于[^\f\n\r\t\v]
注意:退格元字符\b沒有不在\s的范圍之內。
4、匹配十六進制或八進制數值
十六進制:用前綴\x來給出����,如:\x0A對應于ASCII字符10(換行符),其效果等價于\n����。
八進制:用前綴\0來給出����,數值本身可以是兩位或三位數字,如:\011對應于ASCII字符9(制表符)����,其效果等價于\t�����。
四、使用POSIX字符類
POSIX字符類是很多正則表達式實現都支持的一種簡寫形式�����。Java也支持它����,但JavaScript不支持。POSIX字符如下所示:
[:alnum:] 任何一個字母或數字,等價于[a-zA-Z0-9]
[:alpha:] 任何一個字母��,等價于[a-zA-Z]
[:blank:] 空格或制表符�����,等價于[\t]
[:cntrl:] ASCII控制字符(ASCII 0到31�����,再加上ASCII 127)
[:digit:] 任何一個數字����,等價于[0-9]
[:graph:] 任何一個可打印字符,但不包括空格
[:lower:] 任何一個小寫字母����,等價于[a-z]
[:print:] 任何一個可打印字符
[:punct:] 既不屬于[:alnum:]和[:cntrl:]的任何一個字符
[:space:] 任何一個空白字符�����,包括空格,等價于[^\f\n\r\t\v]
[:upper:] 任何一個大寫字母����,等價于[A-Z]
[:xdigit:] 任何一個十六進制數字��,等價于[a-fA-F0-9]
POSIX字符和之前見過的元字符不太一樣,我們來看一個前面利用正則表達式來匹配網頁中的顏色的例子:
文本:<span style="background-color:#3636FF;height:30px;width:60px;">測試</span>
正則表達式:#[[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]] [[:xdigit:]]
結果:<span style="background-color:【#3636FF】;height:30px;width:60px;">測試</span>
注意:這里使用的模式以[[開頭����、以]]結束����,這是使用POSIX字符類所必須的��,POSIX字符必須括在[:和:]之間��,外層[和]字符用來定義一個集合,內層的[和]字符是POSIX字符類本身的組成部分�����。
在java中的POSIX字符表示有所不同�����,不是包括在[:和:]之間,而是以\p開頭,包括在{和}之間,且大小寫有區別�����,同時增加了\p{ASCII}�����,如下所示:
\p{Alnum} 字母數字字符:[\p{Alpha}\p{Digit}]
\p{Alpha} 字母字符:[\p{Lower}\p{Upper}]
\p{ASCII} 所有 ASCII:[\x00-\x7F]
\p{Blank} 空格或制表符:[ \t]
\p{Cntrl} 控制字符:[\x00-\x1F\x7F]
\p{Digit} 十進制數字:[0-9]
\p{Graph} 可見字符:[\p{Alnum}\p{Punct}]
\p{Lower} 小寫字母字符:[a-z]
\p{Print} 可打印字符:[\p{Graph}\x20]
\p{Punct} 標點符號:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Space} 空白字符:[ \t\n\x0B\f\r]
\p{Upper} 大寫字母字符:[A-Z]
\p{XDigit} 十六進制數字:[0-9a-fA-F]
posted @
2012-08-12 23:00 zhanghu198901 閱讀(2100) |
評論 (2) |
編輯 收藏PS:在所有例子中正則表達式匹配結果包含在源文本中的【和】之間����,有的例子會使用java來實現,如果是java本身正則表達式的用法����,會在相應的地方說明�����。所有java例子都在JDK1.6.0_13下測試通過。
一����、有多少個匹配
前面幾篇講的都是匹配一個字符����,但是一個字符或字符集合要匹配多次�����,應該怎么做呢�����?比如要匹配一個電子郵件地址��,用之前說到的方法�����,可能有人會寫出像\w@\w\.\w這樣的正則表達式,但這個只能匹配到像a@b.c這樣的地址,明顯是不正確的�����,接下來就來看看如何匹配電子郵件地址����。
首先要知道電子郵件地址的組成:以字母數字或下劃線開頭的一組字符,后面跟@符號,再后面是域名����,即用戶名@域名地址����。不過這也跟具體的郵箱服務提供商有關��,有的在用戶名中也允許.字符��。
1、匹配一個或多個字符
要想匹配同一個字符(或字符集合)的多次重復�����,只要簡單地給這個字符(或字符集合)加上一個+字符作為后綴就可以了�����。+匹配一個或多個字符(至少一個)。如:a匹配a本身����,a+將匹配一個或多個連續出現的a�����;[0-9]+匹配多個連續的數字。
注意:在給一個字符集合加上+后綴的時候����,必須把+放在字符集合的外面����,否則就不是重復匹配了。如[0-9+]這樣就表示數字或+號了�����,雖然語法上正確��,但不是我們想要的了��。
文本:Hello, mhmyqn@qq.com or mhmyqn@126.com is my email.
正則表達式:\w+@(\w+\.)+\w+
結果:Hello, 【mhmyqn@qq.com】 or 【mhmyqn@126.com】 is my email.
分析:\w+可以匹配一個或多個字符,而子表達式(\w+\.)+可匹配像xxxx.edu.這樣的字符串�����,而最后不會是.字符結尾�����,所以后面還會有一個\w+。像mhmyqn@xxxx.edu.cn這樣的郵件地址也會匹配到����。
2�����、匹配零個或多個字符
匹配零個或多個字符使用元符*,它的用法和+完全一樣�����,只要把它放在一下字符或字符集合的后面����,就可以匹配該字符(或字符集合)連續出現零次或多次。如正則表達式ab*c可以匹配ac��、abc����、abbbbbc等。
3����、匹配零個或一個字符
匹配零個或一個字符使用元字符?����。像上一篇說到的匹配一個空白行使用正則表達式\r\n\r\n����,但在Unix和Linux中不需要\r,就可以使用元字符?,\r?\n\r?\n這樣既可匹配windows中的空白行�����,也可匹配Unix和Linux中的空白行�����。下面來看一個匹配http或https協議的URL的例子:
文本:The URL is http://www.mikan.com, to connect securely use https://www.mikan.cominstead.
正則表達式:https?://(\w+\.)+\w+
結果:The URL is 【http://www.mikan.com】, to connect securely use 【https://www.mikan.com】 instead.
分析:這個模式以https?開頭,表示?之前的一個字符可以有,也可以沒有,所以它能匹配http或https,后面部分和前一個例子一樣。
二、匹配的重復次數
正則表達式里的+、*和?解決了很多問題��,但是:
1)+和*匹配的字符個數沒有上限��。我們無法為它們將匹配的字符個數設定一個最大值����。
2)+��、*和?至少匹配一個或零個字符�����。我們無法為它們將匹配的字符個數另行設定一個最小值。
3)如果只使用*和+,我們無法把它們將匹配的字符個數設定為一個精確的數字����。
正則表達式里提供了一個用來設定重復次數的語法��,重復次數要用{和}字符來給出�����,把數值寫在它們中間。
1、為重復匹配次數設定一個精確值
如果想為重復匹配次數設定一個精確的值�����,把那個數字寫在{和}之間即可����。如{4}表示它前面的那個字符(或字符集合)必須在原始文本中連續重復出現4次才算是一個匹配��,如果只出現了3次�����,也不算是一個匹配。
如前面幾篇中說到的匹配頁面中顏色的例子,就可以用重復次數來匹配:#[[:xdigit:]]{6}或#[0-9a-fA-F]{6}����,POSIX字符在java中是#\\p{XDigit}{6}����。
2��、為重復匹配次數設定一個區間
{}語法還可以用來為重復匹配次數設定一個區間�����,也就是為重復匹配次數設定一個最小值和最大值。這種區間必須以{n, m}這樣的形式給出��,其中n>=m>=0����。如檢查日期格式是否正確(不檢查日期的有效性)的正則表達式(如日期2012-08-12或2012-8-12):\d{4}-\d{1,2}-\d{1,2}。
3、匹配至少重復多少次
{}語法的最后一種用法是給出一個最小的重復次數(但不必給出最大重復次數)��,如{3,}表示至少重復3次��。注意:{3,}中一定要有逗號�����,而且逗號后不能有空格����。否則會出錯。
來看一個例子�����,使用正則表達式把所有金額大于$100的金額找出來:
文本:
$25.36
$125.36
$205.0
$2500.44
$44.30
正則表達式:$\d{3,}\.\d{2}
結果:
$25.36
【$125.36】
【$205.0】
【$2500.44】
$44.30
+�����、*����、?可以表示成重復次數:
+等價于{1,}
*等價于{0,}
?等價于{0,1}
三�����、防止過度匹配
?只能匹配零個或一個字符�����,{n}和{n,m}也有匹配重復次數的上限,但是像*����、+�����、{n,}都沒有上限值��,這樣有時會導致過度匹配的現象����。
來看匹配一個html標簽的例子
文本:
Yesterday is <b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>.
正則表達式:<[Bb]>.*</[Bb]>
結果:
Yesterday is 【<b>history</b>,tomorrow is a <B>mystery</B>, but today is a <b>gift</b>】.
分析:<[Bb]>匹配<b>標簽(不區分大小寫),</[Bb]>匹配</b>標簽(不區分大小寫)����。但結果卻不是預期的那樣有三個����,第一個</b>標簽之后��,一直到最后一個</b>之間的東西全部匹配出來了��。
為什么會這樣呢?因為*和+都是貪婪型的元字符����,它們在匹配時的行為模式是多多益善��,它們會盡可能從一段文本的開頭一直匹配到這段文本的末尾,而不是從這段文本的開頭匹配到碰到第一個匹配時為止。
當不需要這種貪婪行為時,可以使用這些元字符的懶惰型版本��。懶惰意思是匹配盡可能少的字符�����,與貪婪型相反��。懶惰型元字符只需要給貪婪型元字符加上一個?后綴即可。下面是貪婪型元字符的對應懶惰型版本:
* *?
+ +?
{n,} {n,}?
所以上面的例子中�����,正則表達式只需要改成<[Bb]>.*?</[Bb]>即可�����,結果如下:
<b>history</b>
<B>mystery</B>
<b>gift</b>
四、總結
正則表達式的真下威力體現在重復次數匹配方面。這里介紹了+�����、*����、?幾種元字符的用法,如果要精確的確定匹配次數����,使用{}�����。元字符分貪婪型和懶惰型兩種,在需要防止過度匹配的場合下,請使用懶惰型元字符來構造正則表達式
posted @
2012-08-12 23:00 zhanghu198901 閱讀(13336) |
評論 (1) |
編輯 收藏 根據我近些年在IT行業的摸爬滾打,發現作為一個合格的開發經理需要做的第一件事情是:規范�����。
1��、規范代碼
每個公司都有自己的規范文檔����,但是很少有同學按照規范標準來寫自己的代碼��。這樣導致代碼風格多元化����、代碼邏輯可愛化����,更有甚者,會有人連自己的代碼都看不懂��。為什么��?原因很簡單��,雖然寫了規范文檔,做了規范培訓����,但是沒有強制的執行和跟蹤��。
我認為作為一個合格的開發經理,需要做如下三件事情�����。第一步����,寫代碼規范文檔,做培訓。第二步����,按照規范生成開發模版����,規定手下的所有開發人員的開發工具中導入此模版����。第三步,反復核查開發人員的代碼(3-6個月)����,直到規范成為一種習慣。
2�����、規范文檔
文檔在中國IT公司幾乎不受太大的重視����。
在項目型的公司,要么就是沒有文檔�����,要么就是文檔泛濫(要知道��,有很多文檔是做給QA看的��,其實都是垃圾),我有時候就想����,這樣有意義嗎��?文檔的目的是開發人員的輔助工具,尤其對于剛入職公司的新人而言����,不會有幾個“好心腸”的老員工去幫助新員工講解項目架構和原理的����,進來了就是靠自己摸索����,那么文檔對于新人就顯得尤為重要了。所以����,要么就建立一個好的培訓機制,要么就寫好文檔,如果兩者都做的很好為最佳�����。
在互聯網公司�����,對于一些生命周期短暫的小項目不寫文檔我同意�����,畢竟需要時間成本�����。但是這樣的項目代碼規范一定嚴格,盡量精細到數據庫字段的規范�����。因為這種類型的項目開發人員一般為1人����,如果此人離開,后來人員交接時����,能夠更快的看懂對方的代碼����,以節省時間��。此外,對于核心項目��,一定需要一套完整的API文檔����,以供各項目組之間的互通,減少不必要的溝通。
總結:正是因為沒有合理的規范����,某個模塊的開發人員離職�����,會消耗公司的巨大維護成本。如果能夠做到以上兩點規范,相信能夠給公司帶來更多的效能��。
posted @
2012-08-12 22:58 zhanghu198901 閱讀(1894) |
評論 (1) |
編輯 收藏