前言
前面啰啰嗦嗦的幾篇文字,各個方面介紹了Fastsocket,盲人摸象一般,能力有限,還得繼續(xù)深入學(xué)習(xí)不是。這不,到了該小結(jié)收尾的時候了。
緣起,內(nèi)核已經(jīng)成為瓶頸
使用Linux作為服務(wù)器,在請求量很小的時候,是不用擔(dān)心其性能。但在海量的數(shù)據(jù)請求下,Linux內(nèi)核在TCP/IP網(wǎng)絡(luò)處理方面,已經(jīng)成為瓶頸。比如新浪在某臺HAProxy服務(wù)器上取樣,90%的CPU時間被內(nèi)核占用,應(yīng)用程序只能夠分配到較少的CPU時鐘周期的資源。
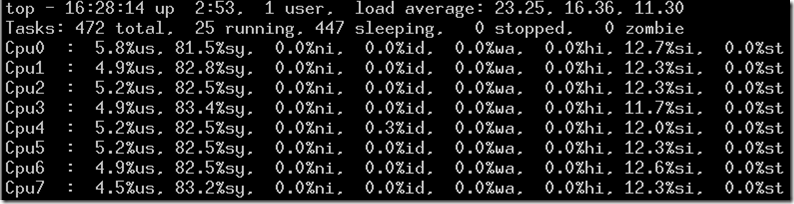
經(jīng)過Haproxy系統(tǒng)詳盡分析后,發(fā)現(xiàn)大部分CPU資源消耗在kernel里,并且在多核平臺下,kernel在網(wǎng)絡(luò)協(xié)議棧處理過程中存在著大量同步開銷。
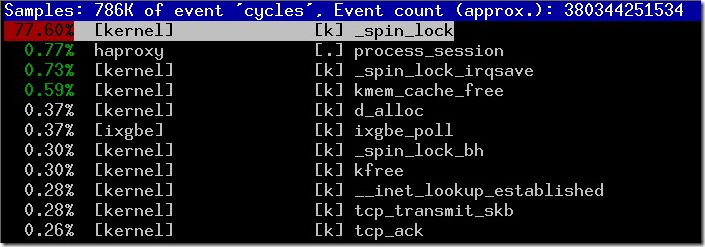
同時在多核上進行測試,HTTP CPS(Connection Per Second)吞吐量并沒有隨著CPU核數(shù)增加呈現(xiàn)線性增長:
")
內(nèi)核3.9之前的Linux TCP調(diào)用
")
- kernel 3.9之前的tcp socket實現(xiàn)
- bind系統(tǒng)調(diào)用會將socket和port進行綁定,并加入全局tcp_hashinfo的bhash鏈表中
- 所有bind調(diào)用都會查詢這個bhash鏈表,如果port被占用,內(nèi)核會導(dǎo)致bind失敗
- listen則是根據(jù)用戶設(shè)置的隊列大小預(yù)先為tcp連接分配內(nèi)存空間
- 一個應(yīng)用在同一個port上只能listen一次,那么也就只有一個隊列來保存已經(jīng)建立的連接
- nginx在listen之后會fork處多個worker,每個worker會繼承l(wèi)isten的socket,每個worker會創(chuàng)建一個epoll fd,并將listen fd和accept的新連接的fd加入epoll fd
- 但是一旦新的連接到來,多個nginx worker只能排隊accept連接進行處理
- 對于大量的短連接,accept顯然成為了一個瓶頸
Linux網(wǎng)絡(luò)堆棧所存在問題
-
TCP處理&多核
- 一個完整的TCP連接,中斷發(fā)生在一個CPU核上,但應(yīng)用數(shù)據(jù)處理可能會在另外一個核上
- 不同CPU核心處理,帶來了鎖競爭和CPU Cache Miss(波動不平衡)
- 多個進程監(jiān)聽一個TCP套接字,共享一個listen queue隊列
- 用于連接管理全局哈希表格,存在資源競爭
- epoll IO模型多進程對accept等待,驚群現(xiàn)象
-
Linux VFS的同步損耗嚴(yán)重
- Socket被VFS管理
- VFS對文件節(jié)點Inode和目錄Dentry有同步需求
- SOCKET只需要在內(nèi)存中存在即可,非嚴(yán)格意義上文件系統(tǒng),不需要Inode和Dentry
- 代碼層面略過不必須的常規(guī)鎖,但又保持了足夠的兼容性
Fastsocket所作改進
- TCP單個連接完整處理做到了CPU本地化,避免了資源競爭
- 保持完整BSD socket API
CPU之間不共享數(shù)據(jù),并行化各自獨立處理TCP連接,也是其高效的主要原因。其架構(gòu)圖可以看出其改進:

Fastsocket架構(gòu)圖可以很清晰說明其大致結(jié)構(gòu),內(nèi)核態(tài)和用戶態(tài)通過ioctl函數(shù)傳輸。記得netmap在重寫網(wǎng)卡驅(qū)動里面通過ioctl函數(shù)直接透傳到用戶態(tài)中,其更為高效,但沒有完整的TCP/IP網(wǎng)絡(luò)堆棧支持嘛。
Fastsocket的TCP調(diào)用圖

- 多個進程可以同時listen在同一個port上
- 動態(tài)鏈接庫libfsocket.so攔截socket、bind、listen等系統(tǒng)調(diào)用并進入這個鏈接庫進行處理
- 對于listen系統(tǒng)調(diào)用,fastsocket會記錄下這個fd,當(dāng)應(yīng)用通過epoll將這個fd加入到epoll fdset中時,libfsocket.so會通過ioctl為該進程clone listen fd關(guān)聯(lián)的socket、sock、file的系統(tǒng)資源
- 內(nèi)核模塊將clone的socket再次調(diào)用bind和listen
- bind系統(tǒng)調(diào)用檢測到另外一個進程綁定到已經(jīng)被綁定的port時,會進行相關(guān)檢查
- 通過檢查sock將會被記錄到port相關(guān)聯(lián)的一個鏈表中,通過該鏈表可以知道所有bind同一個port的sock
- 而sock是關(guān)聯(lián)到fd的,進程則持有fd,那么所有的資源就已經(jīng)關(guān)聯(lián)到一起
- 新的進程再次調(diào)用listen系統(tǒng)調(diào)用的時候,fastsocket內(nèi)核會再次為其關(guān)聯(lián)的sock分配accept隊列
- 結(jié)果是多個進程也就擁有了多個accept隊列,可避免cpu cache miss
- fastsocket提供將每個listen和accept的進程綁定到用戶指定的CPU核
- 如果用戶未指定,fastsocket將會為該進程默認(rèn)綁定一個空閑的CPU核
Fastsocket短連接性能
在新浪測試中,在24核的安裝有Centos 6.5的服務(wù)器上,借助于Fastsocket,Nginx和HAProxy每秒處理連接數(shù)指標(biāo)(connection/second)性能很驚人,分別增加290%和620%。這也證明了,F(xiàn)astsocket帶來了TCP連接快速處理的能力。 除此之外,借助于硬件特性:
- 借助于Intel超級線程,可以獲得另外20%的性能增長
- HAProxy代理服務(wù)器借助于網(wǎng)卡Flow-Director特性支持,吞吐量可增加15%
Fastsocket V1.0正式版從2014年3月份開始已經(jīng)在新浪生產(chǎn)環(huán)境中使用,用作代理服務(wù)器,因此大家可以考慮是否可以采用。針對1.0版本,以下環(huán)境較為收益:
- 服務(wù)器至少不少于8個CPU核心
- 短連接被大量使用
- CPU周期大部分消耗在網(wǎng)絡(luò)軟中斷和套接字系統(tǒng)調(diào)用上
- 應(yīng)用程序使用基于epoll的非阻塞IO
- 應(yīng)用程序使用多個進程單獨接受連接
多線程嘛,就得需要參考示范應(yīng)用所提供實踐建議了。
Nginx測試服務(wù)器配置
- nginx工作進程數(shù)量設(shè)置成CPU核數(shù)個
- http keep-alive特性被禁用
- 測試端http_load從nginx獲取64字節(jié)靜態(tài)文件,并發(fā)量為500*CPU核數(shù)
- 啟用內(nèi)存緩存靜態(tài)文件訪問,用于排除磁盤影響
- 務(wù)必禁用accept_mutex(多核訪問accept產(chǎn)生鎖競爭,另fastsocket內(nèi)核模塊為其去除了鎖競爭)
從下表測試圖片中,可以看到:
- Fastsocket在24核服務(wù)器達(dá)到了475K Connection/Second,獲得了21倍的提升
- Centos 6.5在CPU核數(shù)增長到12核時并沒有呈現(xiàn)線性增長勢頭,反而在24核時下降到159k CPS
- Linux kernel 3.13在24核時獲得了近乎兩倍于Centos 6.5的吞吐量,283K CPS,但在12核后呈現(xiàn)出擴展性瓶頸
HAProxy重要配置
- 工作進程數(shù)量等同于CPU核數(shù)個
- 需要啟用RFD(Receive Flow Deliver)
- http keep-alive需要禁用
- 測試端http_load并發(fā)量為500*CPU核數(shù)
- 后端服務(wù)器響應(yīng)外圍64個字節(jié)的消息
測試結(jié)果中:
- fastsocket呈現(xiàn)出了驚人的擴展性能
- 24核,Linux kernel 3.13成績?yōu)?39K CPS
- 24核,Centos 6.5借助Fastsocket,獲得了370K CPS的吞吐量

實際部署環(huán)境的成績

8核服務(wù)器線上環(huán)境運行了24小時的成績,圖a展示了部署fastsocket之前CPU利用率,圖b為部署了fastsocekt之后的CPU利用率。 Fastsocket帶來的收益:
- 每個CPU核心負(fù)載均衡
- 平均CPU利用率降低10%
- HAProxy處理能力增長85%

其實吧,這一塊期待新浪公布更多的數(shù)據(jù)。
長連接的支持正在開發(fā)中
長連接支持,還是需要等一等的。但是要支持什么類型長連接?百萬級別應(yīng)用服務(wù)器類型,還是redis,可能是后者。雖然目前正做,但目前沒有時間表,但目前所做特性總結(jié)如下:
- 網(wǎng)絡(luò)堆棧的定制
- SKB-Pool,每一CPU核對應(yīng)一個預(yù)分配skb pool,替換內(nèi)核緩沖區(qū)kernel slab
- Percore skb pool
- 合并skb頭部和數(shù)據(jù)
- 本地Pool和重復(fù)循環(huán)使用的Pool(Flow-Director)
- Fast-Epoll
- 多進程之間TCP連接共享變得稀少
- 在file結(jié)構(gòu)體中保存Epoll entry,用以節(jié)省調(diào)用epoll_ctl時紅黑樹查詢的開銷
- 跨層的設(shè)計
- Direct-TCP,數(shù)據(jù)包隸屬于已建立套接字會直接跳過路由過程
- 記錄TCP套接字的輸入路由信息(Record input route information in TCP socket)
- 直接查找網(wǎng)絡(luò)套接字在進入網(wǎng)絡(luò)堆棧之前(Lookup socket directly before network stack)
- 從套接字讀取輸入路由信息(Read input route information from socket)
- 標(biāo)記數(shù)據(jù)包被路有過(Mark the packet as routed)
- Receive-CPU-Selection 類似于RFS,但更輕巧、精準(zhǔn)與快速
- 把當(dāng)前CPU核id編碼到套接字中(Application marks current CPU id in the socket)
- 直接查詢套接字在進入網(wǎng)絡(luò)堆棧之前(Lookup socket directly before network stack)
- 讀取套接字中包含的CPU核,然后發(fā)送給它(Read CPU id from socket and deliver accordingly)
- RPS-Framework 數(shù)據(jù)包在進入網(wǎng)絡(luò)堆棧之前,讓開發(fā)者在內(nèi)核模塊之外定制數(shù)據(jù)包投遞規(guī)則,擴充RPS功能
Redis測試結(jié)果
測試環(huán)境:
- CPU: Intel E5 2640 v2 (6 core) * 2
- NIC: Intel X520
Redis配置選項:
- TCP持久連接
- 8個Redis實例,綁定不同端口
- 使用到8個CPU核心,并且綁定CPU核
測試結(jié)果:
- 僅開啟RSS:20%的吞吐量增加
- 啟用網(wǎng)卡Flow-Director特性:45%吞吐量增加
但需要注意:
- 僅為實驗測試階段
- 為V1.0補充,Nginx和HAProxy同樣會收益
Fastsocket v1.1
V1.1版本要增加長連接的支持,那么類似于Redis的服務(wù)器應(yīng)用程序就很受益了,因為沒有具體的時間表,只能夠慢慢等待了。
以后一些優(yōu)化措施
- 在上下文切換時,避免拷貝操作,Zero-Copy
- 中斷機制完善,減少中斷
- 支持批量提交,降低系統(tǒng)函數(shù)調(diào)用
- 提交到Linux kernel主分支上去
- HugeTLB/HugePage等
Fastsocket和mTCP等簡單對比
說是對比,其實是我從mTCP論文中摘取出來,增加了Fastsocket一欄,可以看出人們一直努力的腳步。
| Types | Accept queue | Conn. Locality | Socket API | Event Handling | Packet I/O | Application Mod- ification | Kernel Modification |
PSIO ,
DPDK ,
PF RING ,
netmap | No TCP stack | Batched | No interface for transport layer | No
(NIC driver) |
| Linux-2.6 | Shared | None | BSD socket | Syscalls | Per packet | Transparent | No |
| Linux-3.9 | Per-core | None | BSD socket | Syscalls | Per packet | Add option SO REUSEPORT | No |
| Affinity-Accept | Per-core | Yes | BSD socket | Syscalls | Per packet | Transparent | Yes |
| MegaPipe | Per-core | Yes | lwsocket | Batched syscalls | Per packet | Event model to completion I/O | Yes |
| FlexSC,VOS | Shared | None | BSD socket | Batched syscalls | Per packet | Change to use new API | Yes |
| mTCP | Per-core | Yes | User-level socket | Batched function calls | Batched | Socket API to mTCP API | No
(NIC driver) |
| Fastsocket | Per-core | Yes | BSD socket | Ioctl + kernel calls | Per packet | Transparent | No |
有一個大致的印象,也方便對比,但這只能是一個暫時的摘要而已,人類對性能的渴求總是朝著更好的方向發(fā)展著。
部署嘗試
怎么說呢,F(xiàn)astsocket是為大家耳熟能詳服務(wù)器程序Nginx,HAProxy等而開發(fā)的。但若應(yīng)用環(huán)境為大量的短連接,并且是小文件類型請求,不需要強制支持Keep-alive特性(短連接要的是快速請求-相應(yīng),然后關(guān)閉),那么管理員可以嘗試一下Fastsocket,至于部署策略,選擇性部署幾臺作為實驗看看結(jié)果。
小結(jié)
本系列到此算是告一段落啦。以后呢,自然是希望Fastsocket盡快發(fā)布對長連接的支持,還有更高性能的提升咯 :))
資源引用