一 我所知道的集合
我知道的第一個(gè)集合:ArrayList,加入元素非常方便,add(Object elem)。其它的, TreeSet(有序并防止重復(fù)), HashMap(名值對(duì)), LinkedList(為經(jīng)常插入或刪除中間元素所設(shè)計(jì)的高效集合), HashSet(防止重復(fù),可快速找尋符合的元素), LinkedHashMap(類型于HashMap, 但可以記住元素插入的順序,也可以設(shè)定成依照元素上次存取的先后來(lái)排序)。總的來(lái)說(shuō),這些集合可以用“順序”和“重復(fù)”來(lái)區(qū)分。
下面兩圖用來(lái)說(shuō)明3個(gè)主要的接口:List, Set 和 Map.(部分)
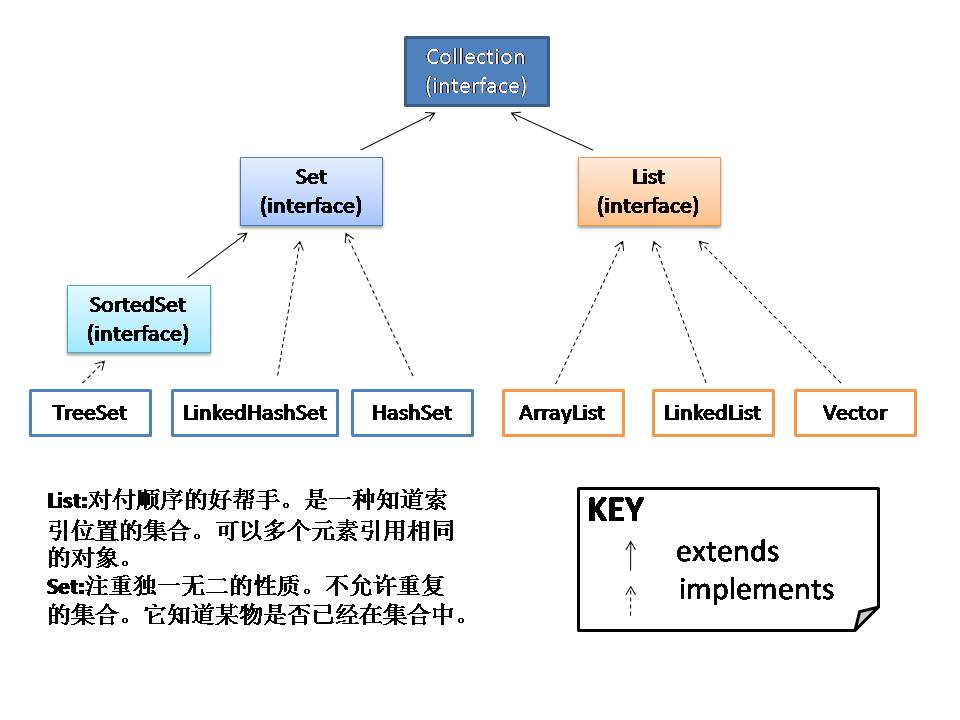
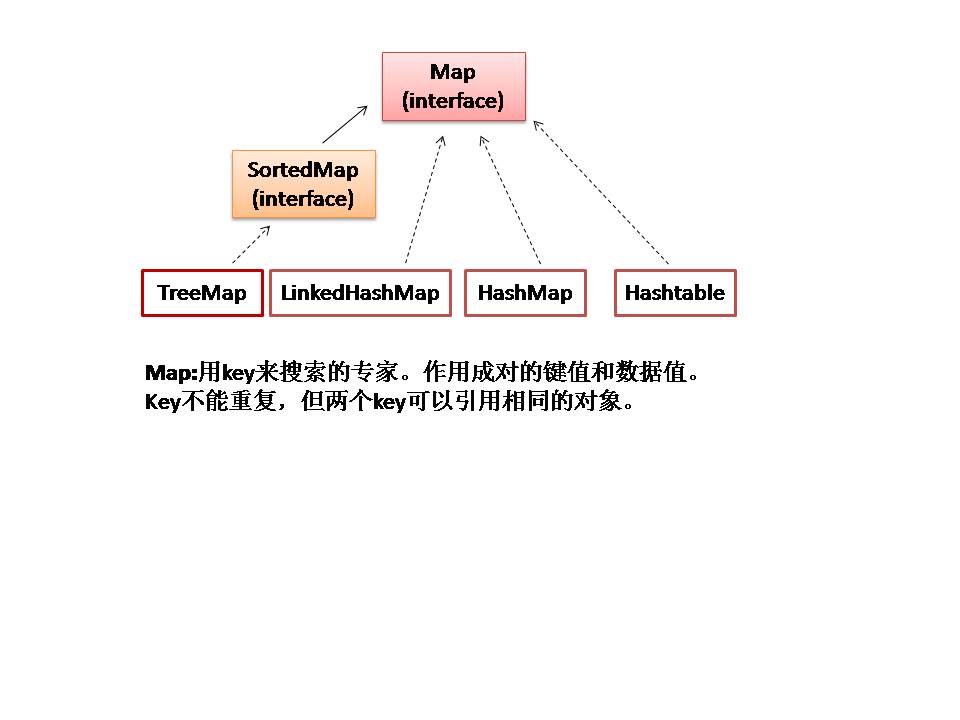
二 順序
順序問(wèn)題,可以用TreeSet或Collections.sort()來(lái)實(shí)現(xiàn)。當(dāng)插入新元素時(shí),TreeSet會(huì)花時(shí)間找到適當(dāng)?shù)奈恢茫韵鄬?duì)要慢了。而ArrayList只要把新加的元素放到最后就好。(當(dāng)然,ArrayList也有重載的add(index, element )可以插到指定位置,也慢,通常不這樣做。)
sort(List<T> list) 方法 /* public static <T extends Comparable<? super T>> void sort(List<T> list) */ :只傳入Comparable 接口的 list 作為參數(shù)。Comparable有一個(gè)方法要實(shí)現(xiàn):compareTo(T o)方法。
或者用重載的sort()方法:sort(List<T> list, Comparator< ? super T> c)方法 。這樣,就用不著compareTo()方法了。而是要實(shí)現(xiàn)Comparator接口,實(shí)現(xiàn)compare()方法。
實(shí)例1-關(guān)于 sort(List<T> list)

 /**//* Class StudyComparable */
/**//* Class StudyComparable */
 package conllection;
package conllection;
import java.util.Collections;
import java.util.LinkedList;
public class StudyComparable  {
{
 LinkedList<Person> psn = new LinkedList<Person>();
LinkedList<Person> psn = new LinkedList<Person>();

 public static void main(String[] args) {
public static void main(String[] args) {
StudyComparable sc = new StudyComparable();
sc.go();
 }
}
private void go() {
psn.add(new Person("one", 3));
psn.add(new Person("two", 2));
psn.add(new Person("three", 5));
psn.add(new Person("five", 6));
psn.add(new Person("eight", 8));
System.out.println(psn);
Collections.sort(psn);
System.out.println(psn);
}
 }
}
/**//* Class Person */
package conllection;
public class Person implements Comparable<Person> {
String name;
int age;
public Person(String n, int a) {
name = n;
age = a;
}
@Override
public int compareTo(Person o) {
return name.compareTo(o.name);
}
@Override
public String toString() {
return name + "/" + age;
}
}
運(yùn)行結(jié)果:
[one/3, two/2, three/5, five/6, eight/8]
[eight/8, five/6, one/3, three/5, two/2]
現(xiàn)在,可以按照name來(lái)排序了,不過(guò)我想用age 來(lái)排序,就要改代碼,用Person類中的compareTo()方法進(jìn)入age的比較。這樣做很不好,所以可以用重載的sort(List<T> list, Comparator<? super T> c)方法。
實(shí)例2-關(guān)于 sort(List <T> list, Comparator <? super T> c)
Class StudyComparator
package conllection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class StudyComparator {
ArrayList<Person> psn = new ArrayList<Person>();
public static void main(String[] args) {
StudyComparator sc = new StudyComparator();
sc.go();
}
class NameComparator implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
return o1.name.compareTo(o2.name);
}
}
class AgeComparator implements Comparator<Person> {
@Override
public int compare(Person o1, Person o2) {
return o1.age - o2.age;
}
}
private void go() {
psn.add(new Person("one", 3));
psn.add(new Person("two", 2));
psn.add(new Person("three", 5));
psn.add(new Person("five", 6));
psn.add(new Person("eight", 8));
System.out.println(psn);
NameComparator nc = new NameComparator();
Collections.sort(psn, nc);
System.out.println("onName:" + psn);
AgeComparator ac = new AgeComparator();
Collections.sort(psn, ac);
System.out.println("onAge:" + psn);
}
}
Class Person:同例1中的Person.Class 。因?yàn)樵赟tudyComparator里面定義了Comparator的實(shí)現(xiàn)類,所以Person類不用動(dòng),也就是說(shuō),在沒(méi)有原代碼的情況下也實(shí)現(xiàn)了sort,而且可按不同的屬性來(lái)進(jìn)行排序,我更喜歡這個(gè)重載的sort()方法。
運(yùn)行結(jié)果:
[one/3, two/2, three/5, five/6, eight/8]
onName:[eight/8, five/6, one/3, three/5, two/2]
onAge:[two/2, one/3, three/5, five/6, eight/8]
三 重復(fù)
1 相等 ==
防止重復(fù),用Set。要解決的第一個(gè)問(wèn)題:兩個(gè)對(duì)象的引用怎樣才算是重復(fù)?答案就是它們是相等的。那么怎樣算‘相等’?顯然不是單純的值相等。‘相等’包括引用相等和對(duì)象相等。
引用相等:引用堆上的同一對(duì)象的兩個(gè)引用是相等的。如果對(duì)兩個(gè)引用調(diào)用hashCode() ,會(huì)得到相同的結(jié)果。hashCode()(默認(rèn)的行為)會(huì)返回對(duì)象在堆上的特有的唯一序號(hào)。顯然,不同對(duì)象的引用的hashCode()的值是不同的。
對(duì)象相等:堆上的兩個(gè)不同對(duì)象,在意義上相同。
因此,
想要兩個(gè)不同的對(duì)象‘相等’,就必須要override hashCode()和equals()方法。
a.equals(b) 的默認(rèn)行為是執(zhí)行‘==’,包括了hashCode()的對(duì)比。如果equals()方法不被override, 那么兩個(gè)對(duì)象永遠(yuǎn)都不會(huì)視為相同。
2 HashSet 檢查重復(fù):hashCode() 與 equals()
當(dāng)把對(duì)象放入HashSet時(shí),它會(huì)先用對(duì)象的hashCode()與已有元素的hashCode()來(lái)比較,(如果沒(méi)有override過(guò)hashCode()方法,那么HashSet 會(huì)認(rèn)為對(duì)象間不重復(fù),我們當(dāng)然要override來(lái)確保對(duì)象有相同的值)。如果hashCode()相同,再調(diào)用其中一個(gè)的equals()來(lái)檢查對(duì)象是否真的相同。如果又相同了,那么加入的操作就不會(huì)發(fā)生。
說(shuō)明:有相同hashCode()的對(duì)象也不一定是相等的,感覺(jué)有點(diǎn)怪,但的確如此。因?yàn)閔ashCode()用的是雜湊算法,也許剛好使多個(gè)對(duì)象有了相同的雜湊值。越爛的雜湊算法越容易碰撞。這個(gè)屬于數(shù)據(jù)結(jié)構(gòu)方面的問(wèn)題了。具體的要問(wèn)專家了。
posted on 2008-07-09 02:47
BlueSunshine 閱讀(1206)
評(píng)論(3) 編輯 收藏 所屬分類:
學(xué)習(xí)心得