華為宣布開源了CarbonData項目,該項目于6月3日通過Apache社區投票,成功進入Apache孵化器。CarbonData是一種低時延查詢、存儲和計算分離的輕量化文件存儲格式。那么相比SQL on Hadoop方案、傳統NoSQL或相對ElasticSearch等搜索系統,CarbonData具有什么樣的優勢呢?CarbonData的技術架構是什么樣子的?未來有什么樣的規劃?我們采訪了CarbonData項目的技術負責人為大家解惑。
InfoQ:請問CarbonData是什么時候開始進行的項目?為什么現在向Apache孵化器開源呢?開源發展歷程和項目目前狀態是怎么樣的?
CarbonData:CarbonData項目是華為公司從多年數據處理經驗和行業理解中逐步積累起來的,2015年我們對系統進行了一次架構重構,使其演化為HDFS上的一套通用的列式存儲,支持和Spark引擎對接后形成一套分布式OLAP分析的解決方案。
華為一直是面向電信、金融、IT企業等用戶提供大數據平臺解決方案的供應商,從眾多客戶場景中我們不斷提煉數據特征,總結出了一些典型的對大數據分析的訴求,逐步形成了CarbonData這個架構。
因為在IT領域,只有開源開放,才能最終讓更多的客戶和合作伙伴的數據連接在一起,產生更大商業價值。開源是為了構建E2E生態,CarbonData是數據存儲層技術,要發揮價值,需要與計算層、查詢層有效集成在一起,形成完成真正的生態發揮價值。
又因為Apache是目前大數據領域最權威的開源組織,其中的Hadoop,Spark已成為大數據開源的事實標準,我們也非常認可Apache以Community驅動技術進步的理念,所以我們選擇進入Apache,與社區一同構建能力,使CarbonData融入大數據生態。
目前CarbonData開源項目已經在6月3日通過Apache社區投票,成功進入Apache孵化器。github地址:https://github.com/apache/incubator-carbondata。歡迎大家參與到Apache CarbonData社區: https://github.com/apache/incubator-carbondata/blob/master/docs/How-to-contribute-to-Apache-CarbonData.md。
InfoQ:請問是什么原因或機遇促使您們產生做CarbonData這個項目的想法的?之前的項目中遇到什么樣的困難?
CarbonData:我們一直面臨著很多高性能數據分析訴求,在傳統的做法里,一般是使用數據庫加BI工具實現報表、DashBoard和交互式查詢等業務,但隨著企業數據日益增大,業務驅動的分析靈活性要求逐漸增大,也有部分客戶希望有除SQL外更強大的分析功能,所以傳統的方式漸漸滿足不了客戶需求,讓我們產生了做CarbonData這個項目的想法。
需求一般來源于幾方面。
第一,在部署上,區別于以往的單機系統,企業客戶希望有一套分布式方案來應對日益增多的數據,隨時可以通過增加通用服務器的方式scale out橫向擴展。
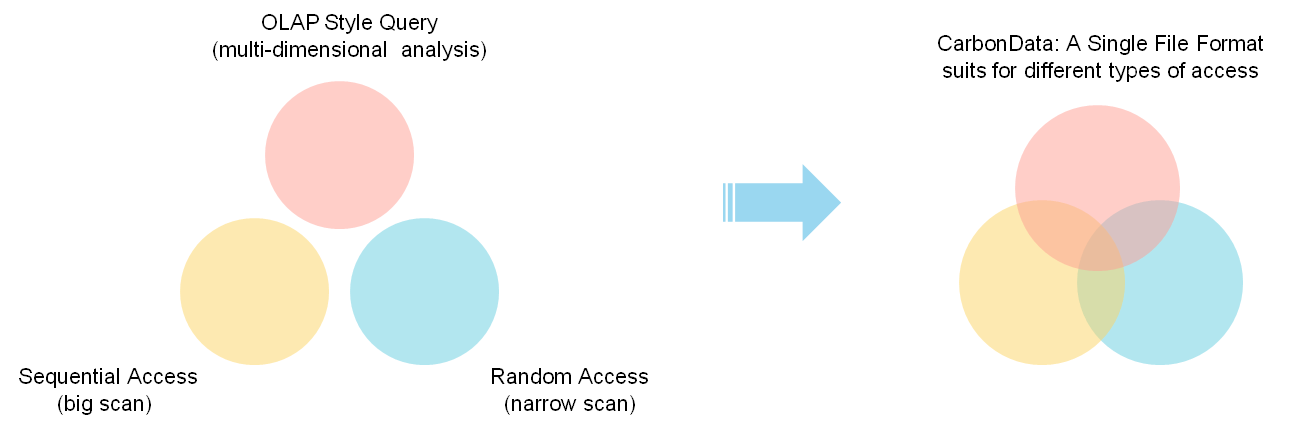
第二,在業務功能上,很多企業的業務都處在從傳統數據庫逐漸轉移到大數據平臺的遷移過程中,這就要求大數據平臺要有較高兼容老業務的能力,這里面主要包含的是對完整的標準SQL支持,以及多種分析場景的支持。同時為了節約成本,企業希望“一份數據支持多種使用場景”,例如大規模掃描和計算的批處理場景,OLAP多維交互式分析場景,明細數據即席查詢,主鍵低時延點查,以及對實時數據的實時查詢等場景,都希望平臺能給予支持,且達到秒級查詢響應。
第三,在易用性上,企業客戶以往使用BI工具,業務分析的OLAP模型是需要在BI工具中建立的,這就會導致有的場景下數據模型的靈活性和分析手段受到限制,而在大數據時代,大數據開源領域已經形成了一個生態系統,社區隨時都在進步,經常會冒出一些新型的分析工具,所以企業客戶都希望能跟隨社區不斷改進自己的系統,在自己的數據里快速用上新型的分析工具,得到更大的商業價值。
要同時達到上訴要求,無疑對大數據平臺是一個很大的挑戰。為了滿足這些要求,我們開始不斷在實際項目中積累經驗,也嘗試了很多不同的解決方案,但都沒有發現能用一套方案解決所有問題。
大家首先會想到的是,在涉及到低時延查詢的分布式存儲中,一般常用的是KV型NoSQL數據庫(如HBase,Cassandra),可以解決主鍵低時延查詢的問題,但如果業務的查詢模式稍作改變,例如對多維度靈活組合的查詢,就會使點查變為全表掃描,使性能急劇下降。有的場景下,這時可以通過加入二級索引來緩解該問題,但這又帶來了二級索引的維護和同步等管理問題,所以KV型存儲并不是解決企業問題的通用方案。
那么,如果要解決通用的多維查詢問題,有時我們會想到用多維時序數據庫的方案(如Linkedin Pinot),他們的特點是數據都以時間序列的方式進入系統并經過數據預聚合和建立索引,因為是預計算,所以應對多維查詢時非常快,數據也非常及時,同時具備多維分析和實時處理的優點,在性能監控、實時指標分析的場景里應用較多。但它在支持的查詢類型上也有一定限制,因為做了數據預計算,所以這種架構一般無法應對明細數據查詢,以及不支持Join多表關聯分析,這無疑給企業使用場景帶來了一定的限制。
另外一類是搜索系統(如Apache Solr,ElasticSearch),搜索系統可以做多維匯總也可以查詢明細數據,它也具備基于倒排索引的快速布爾查詢,并發也較高,似乎正是我們希望尋找的方案。但在實際應用中我們發現兩個問題:一是由于搜索系統一般是針對非結構化數據而設計的,系統的數據膨脹率一般都比較高,在企業關系型數據模型下數據存儲不夠緊湊,造成數據量較大,二是搜索系統的數據組織方式和計算引擎密切相關,這就導致了數據入庫后只能用相應的搜索引擎處理,這又一定程度打破了企業客戶希望應用多種社區分析工具的初衷,所以搜索系統也有他自己的適用場景。
最后一類系統,就是目前社區里大量涌現的SQL on Hadoop方案,以Hive, SparkSQL, Flink為代表,這類系統的特點是計算和存儲相分離,針對存儲在HDFS上的文件提供標準SQL功能,他們在部署性和易用性上可以滿足企業客戶需求,業務場景上也能覆蓋掃描,匯聚,詳單等各類場景,可見可以將他們視為一類通用的解決方案。為了提高性能,Spark,Flink等開源項目通過不斷優化自身架構提升計算性能,但提升重點都放在計算引擎和SQL優化器的增強上,在存儲和數據組織上改進并不是重點。
所以,可以看出當前的很多大數據系統雖然都能支持各類查詢場景,但他們都是偏向某一類場景設計的,在不是其目標場景的情況下要么不支持要么退化為全表掃描,所以導致企業為了應對批處理,多維分析,明細數據查詢等場景,客戶常常需要通過復制多份數據,每種場景要維護一套數據。
CarbonData的設計初衷正是為了打破這種限制,做到只保存一份數據,最優化地支撐多種使用場景。
InfoQ:能否具體談談CarbonData的技術架構?有何特征和優勢呢?
CarbonData:整個大數據時代的開啟,可以說是源自于Google的MapReduce論文,他引發了Hadoop開源項目以及后續一系列的生態發展。他的“偉大”之處在于計算和存儲解耦的架構,使企業的部分業務(主要是批處理)從傳統的垂直方案中解放出來,計算和存儲可以按需擴展極大提升了業務發展的敏捷性,讓眾多企業普及了這一計算模式,從中受益。
雖然MapReduce開啟了大數據時代,但它是通過純粹的暴力掃描+分布式計算來提升批處理性能,所以并不能解決客戶對所有查詢場景的低時延查詢要求。
在目前的生態中,最接近于客戶要求的其實是搜索引擎類方案。通過良好的數據組織和索引,搜索引擎能提供多種快速的查詢功能,但偏偏搜索引擎的存儲層又和計算引擎是緊耦合的,并不符合企業對”一份數據,多種場景”的期望。
這給了我們啟發,我們何不為通用計算引擎打造更一個高效的數據組織來滿足客戶需求呢,做到既利用計算和存儲解耦架構又能提供高性能查詢。抱著這個想法,我們啟動了CarbonData項目。針對更多的業務,使計算和存儲相分離,這也成了CarbonData的架構設計理念。
確立了這個理念后,我們很自然地選擇了基于HDFS+通用計算引擎的架構,因為這個架構可以很好地提供Scale out能力。下一步我們問自己這個架構里還缺什么?這個架構中,HDFS提供文件的復制和讀寫能力,計算引擎負責讀取文件和分布式計算,分工很明確,可以說他們分別定位于解決存儲管理和計算的問題。但不難看出,為了適應更多場景,HDFS做了很大的“犧牲”,它犧牲了對文件內容的理解,正是由于放棄了對文件內容的理解,導致計算只能通過全掃描的方式來進行,可以說最終導致的是存儲和計算都無法很好的利用數據特征來做優化。
所以針對這個問題,我們把CarbonData的發力重點放在對數據組織的優化上,通過數據組織最終是要提升IO性能和計算性能。為此,CarbonData做了如下工作。
CarbonData基礎特性
1. 多維數據聚集:在入庫時對數據按多個維度進行重新組織,使數據在“多維空間上更內聚”,在存儲上獲得更好的壓縮率,在計算上獲得更好的數據過濾效率。
2. 帶索引的列存文件結構:首先,CarbonData為多類場景設計了多個級別的索引,并融入了一些搜索的特性,有跨文件的多維索引,文件內的多維索引,每列的minmax索引,以及列內的倒排索引等。其次,為了適應HDFS的存儲特點,CarbonData的索引和數據文件存放在一起,一部分索引本身就是數據,另一部分索引存放在文件的元數據結構中,他們都能隨HDFS提供本地化的訪問能力。
3. 列組:整體上,CarbonData是一種列存結構,但相對于行存來說,列存結構在應對明細數據查詢時會有數據還原代價高的問題,所以為了提升明顯數據查詢性能,CarbonData支持列組的存儲方式,用戶可以把某些不常作為過濾條件但又需要作為結果集返回的字段作為列組來存儲,經過CarbonData編碼后會將這些字段使用行存的方式來存儲以提升查詢性能。
4. 數據類型:目前CarbonData支持所有數據庫的常用基本類型,以及Array,Struct復雜嵌套類型。同時社區也有人提出支持Map數據類型,我們計劃未來添加Map數據類型。
5. 壓縮:目前CarbonData支持Snappy壓縮,壓縮是針對每列分別進行的,因為列存的特點使得壓縮非常高效。數據壓縮率基于應用場景不同一般在2到8之間。
6. Hadoop集成:通過支持InputFormat/OutputFormat接口,CarbonData可以利用Hadoop的分布式優點,也能在所有以Hadoop為基礎的生態系統中使用。
CarbonData高級特性
1. 可計算的編碼方式:除了常見的Delta,RLE,Dictionary,BitPacking等編碼方式外,CarbonData還支持將多列進行聯合編碼,以及應用了全局字典編碼來實現免解碼的計算,計算框架可以直接使用經過編碼的數據來做聚合,排序等計算,這對需要大量shuffle的查詢來說性能提升非常明顯。
2. 與計算引擎聯合優化:為了高效利用CarbonData經過優化后的數據組織,CarbonData提供了有針對性的優化策略,目前CarbonData社區首先做了和Spark的深度集成,其中基于SparkSQL框架增強了過濾下壓,延遲物化,增量入庫等特性,同時支持所有DataFrame API。相信未來通過社區的努力,會有更多的計算框架與CarbonData集成,發揮數據組織的價值。
目前這些特性都已經合入Apache CarbonData主干,歡迎大家使用。
InfoQ:在哪些場景推薦使用呢?性能測試結果如何?有沒有應用案例,目前在國內的使用情況和用戶規模?
CarbonData:推薦場景:希望一份存儲同時滿足快速掃描,多維分析,明細數據查詢的場景。在華為的客戶使用案例中,對比業界已有的列存方案,CarbonData可以帶來5~30倍性能提升。
性能測試數據及應用案例等更多信息,請關注微信公眾號ApacheCarbonData,及社區https://github.com/apache/incubator-carbondata。
InfoQ:CarbonData能和當前正火的Spark完美結合嗎?還能兼容哪些主流框架呢?
CarbonData:目前CarbonData已與Spark做了深度集成,具體見上述高級特性。
InfoQ:您們的項目在未來有什么樣的發展規劃?還會增加什么功能嗎?如何保證開源之后的項目的持續維護工作呢?
CarbonData:接下來社區重點工作是,提升系統易用性、完善生態集成(如:與Flink,Kafka等集成,實現數據實時導入CarbonData)。
CarbonData開源的第一個月,就有幾百個commits提交,和20多個貢獻者參與,所以后續這個項目會持續的活躍。10多個核心貢獻者也將會持續參與社區建設。
InfoQ:在CarbonData設計研發并進入Apache孵化器的過程中,經歷了哪些階段,經歷過的最大困難是什么?有什么樣的感受或經驗可以和大家分享的嗎?
CarbonData:CarbonData團隊大多數人都有參與Apache Hadoop、Spark等社區開發的經驗,我們對社區流程和工作方式都很熟悉。最大的困難是進入孵化器階段,去說服Apache社區接納大數據生態新的高性能數據格式CarbonData。我們通過5月份在美國奧斯丁的開源盛會OSCON上,做CarbonData技術主題演講和現場DEMO演示,展示了CarbonData優秀的架構和良好的性能效果。
InfoQ:您們是一個團隊嗎?如何保證您們團隊的優秀成長?
CarbonData:CarbonData團隊是一個全球化的(工程師來自中國、美國、印度)團隊,這種全球化工作模式的經驗積累,讓我們能快速的適應Apache開源社區工作模式。
采訪嘉賓:Apache CarbonData的PMC、Committers李昆、陳亮。