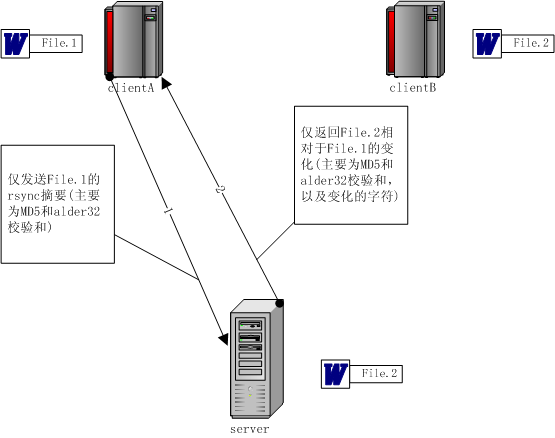
先看下圖中的場景,客戶端A和B,以及服務器server都保存了同一個文件,最初,A、B和server上的文件內容都是相同的(記為File.1)。某一時刻,B修改了文件內容,上傳到SERVER上(記為File.2)。客戶端A這時試圖向服務器SERVER更新文件到最新內容,也就是File.1更新為File.2。

上面這個場景很常見,例如現在流行的網盤。假設我有一個文件a.txt在網盤上,上班時在公司的單位PC上更新了文件a.txt,下班后回到家里,家里PC硬盤上的a.txt就不是最新的內容,這時網盤就試圖從服務器上去拿最新的a.txt了。
那么問題來了,如果在公司電腦上我只是更新了a.txt里很少的一部分內容,例如a.txt共有20M,我只更新了10個字節,難道家里的電腦上,網盤要從服務器上下載20M大小的文件?這明顯很浪費帶寬。
更有用的場景,假設我的手機android上也用了這個網盤(手機上網費貴得多),只改了幾十字節的內容,就要下載20M的文件,得不償失。或者我把這個文件共享給其他朋友,也有同樣的問題:修改少量的內容,卻同步完整的文件!
rsync算法就是用來解決上述問題的。client A發送它所保存的舊文件File.1少量的rsync摘要,server拿到后對比本地的File.2內容,得到File.2相對于File.1的變化,然后通過僅發送這個變化來代替發送完整的File.2內容,這樣大大減少了網絡傳輸數據。client A收到這個變化后,更新本地的File.1到最新的File.2。就是這么簡單。下面詳述rsync算法的步驟。
rsync首先需要客戶端與服務器之間約定一個塊大小,例如1K。然后把File.1等分成多個1K大小的字符串塊,每塊各計算出MD5摘要和Alder32校驗和,如下圖。
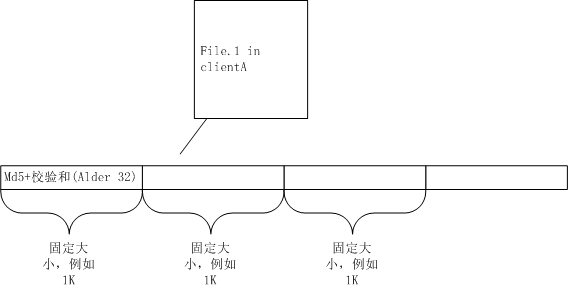
這里簡單介紹下MD5和校驗和。MD5是種哈希算法,用于把任意長度的字符串轉化為固定為128位的定長字符串,這里可以保證,相同的字符串不可能計算出不同的MD5值。MD5的碰撞率是有的,就是說,兩個不同的字符串有可能計算出相同的MD5值,但是這個機率非常小,這里我們忽略不計。例如,在rsync算法里,同一個文件按1K切分成多塊,每塊都有一個MD5值,如果兩塊字符串的MD5值相同,則我們認為這兩塊數據完全相同。
校驗和是把上述1K塊數據映射為32位大小整型數字上,我們采用Alder32算法,這里同樣可以保證,相同的字符串不可能計算出不同的Alder32值。Alder32有兩個優點:1、計算非常快,比MD5快多了,成本小;2、當我們有了從0-1024長度的校驗和后,計算出1-1025或者2-1026等其他校驗和非常方便,只要少量運算即可。當然,它的缺點也很明顯,就是碰撞率比MD5高多了,所以,我們要把每個rynsc塊同時計算出Alder32校驗和與MD5值。Alder32算法我會在本文最后解釋。
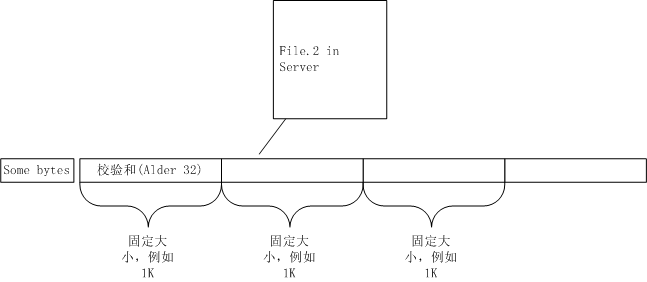
客戶端按1K大小劃分File.1文件為許多塊,并對每塊計算出MD5、Alder32校驗和。最后不滿1K的數據不做計算。之后,客戶端把這些MD5、Alder32校驗和依序通過網絡傳輸給服務器,最后不滿1K的數據直接發給服務器。那么,服務器收到數據后怎么處理呢?看下圖。
首先重申,計算Alder32校驗和非常快!
所以,服務器先把最新文件File.2從0字節開始,按1K切分成許多塊,每塊計算出Alder32校驗和,然后與客戶端發來的File.1切分出來的Alder32校驗和相比,如果alder32值都不一樣,毫無疑問,文件內容是不相同的。接著,把File.2從1字節開始,按1K切分成許多塊,每塊計算出Alder32校驗和,再與客戶端的校驗和比。如此循環下去,直到某個校驗和相同了,那么把這段字符串再計算出MD5值,再與客戶端過來的對應的MD5值相比(還記得吧?客戶端對每個塊既計算出Alder32又計算出MD5值),如果不同,則繼續往后移1字節,繼續比Alder32、MD5值。如果相同,則認為這1K數據,服務器與客戶端保存的一致,忽略這塊數據(例如1K字節),繼續向下看。
全部處理完后,按File.2的文件順序,向客戶端發送以下數據:對于不能夠在客戶端File.1數據塊中找到相同塊的字符串,直接列上發出;如果可以找到,則寫上MD5和Alder32值,代替原來1024字節的數據塊。同樣,最后不足1K大小的部分直接列上發出。
純理論讀起來會有些吃力,我再把它簡化了舉個例子吧。假設客戶端與服務器間約定的字符塊大小不是1K,而是4個字節。客戶端的文件內容是:
taohuiissoman
而服務器的文件內容是:
itaohuiamsoman
現在我們來看看,rsync算法是怎么運作的。
首先,客戶端開始分塊并計算出MD5和Alder32值。

如上圖,像taoh是一塊,對taoh分別計算出MD5和alder32值。以此類推,最后一個n字母不足4位保留。于是,客戶端把計算出的MD5和alder32按順序發出,最后發出字符n。
服務器收到后,先把自己保存的File.2的內容按4字節劃分。
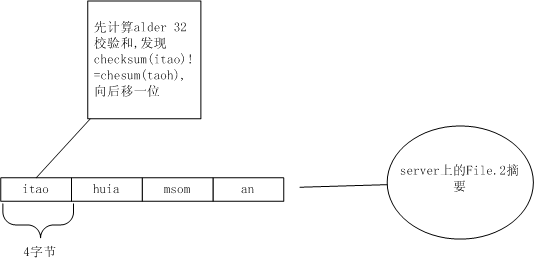
劃分出itao、huia、msom、an,當然,這些串的Alder32值肯定無法從File.1里劃分出的:taoh、uiis、soma、n找出相同的。于是向后移一個字節,從t開始繼續按4字節劃分。
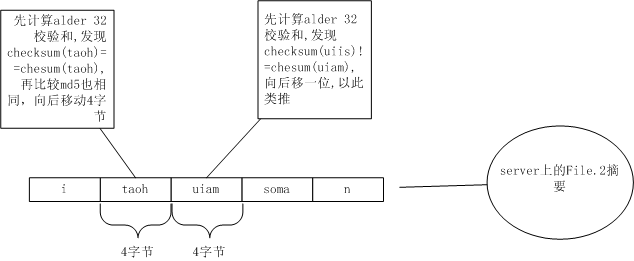
從taoh上找到了alder32相同的塊,接著再比較MD5值,也相同!于是記下來,跳過taoh這4個字符,看uiam,又找不到File.1上相同的塊了。繼續向后跳1個字節從i開始看。還是沒有找到Alder32相同,繼續向后移,以此類推。
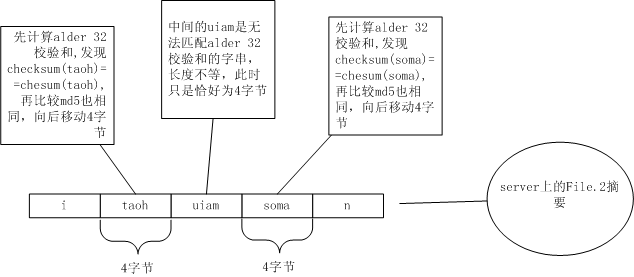
到了soma,又找到相同的塊了。
重復上面的步驟,直到File.2文件結束。
那么,最終客戶端與服務器間傳輸的數據如下圖所示。
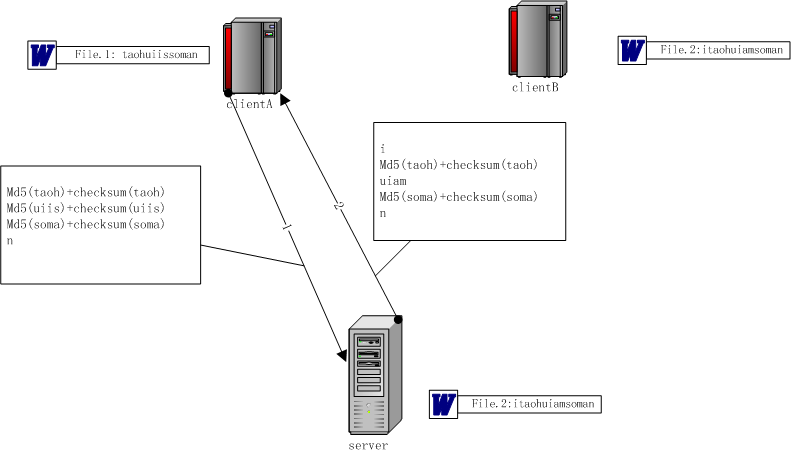
上面這個例子很簡單,可由此推導出復雜的情況,包括File.2對File.1在任意位置上做了增、改、刪,都能夠完成。
如果這是個大文本文件,應用rsync算法就非常有意義,例如20M的文件,實際可能只傳輸1M的數據量!這樣用戶體驗會好很多,特別是網速慢的場景。
同時增加的消耗,就是在PC上計算的MD5值和Alder32校驗和,這只消耗少量的CPU和內存而已。
最后列下Alder32的算法:
- A = 1 + D1 + D2 + ... + Dn (mod 65521)
- B = (1 + D1) + (1 + D1 + D2) + ... + (1 + D1 + D2 + ... + Dn) (mod 65521)
- = n×D1 + (n−1)×D2 + (n−2)×D3 + ... + Dn + n (mod 65521)
-
- Adler-32(D) = B × 65536 + A
D1到Dn就是待計算的字符串塊,所有位上的ASC字符。它的C代碼實現為:
- const int MOD_ADLER = 65521;
-
- unsigned long adler32(unsigned char *data, int len) /* where data is the location of the data in physical memory and
- len is the length of the data in bytes */
- {
- unsigned long a = 1, b = 0;
- int index;
-
- /* Process each byte of the data in order */
- for (index = 0; index < len; ++index)
- {
- a = (a + data[index]) % MOD_ADLER;
- b = (b + a) % MOD_ADLER;
- }
-
- return (b << 16) | a;
- }