執行到./configure --enable-shared一步時提示:
checking host system type... Invalid configuration `x86_64-unknown-linux-gnu ': machine `x86_64-unknown ' not recognized
解決辦法:
cp /usr/share/libtool/config.guess . (覆蓋到相關軟件自帶的config.guess,t1lib在解壓包的ac-tools下)
cp /usr/share/libtool/config.sub . (覆蓋到相關軟件自帶的config.sub)
./configure --enable-shared --enable-static
make libdir=/usr/lib64
make libdir=/usr/lib64 install
使用64位函數庫編譯.
posted @
2010-06-01 17:31 一凡 閱讀(826) |
評論 (0) |
編輯 收藏
linux下用cp更新so后重啟服務會出core原因:
用cp更新so會改變so的inode,服務找不到原來的inode,所以出core
解決辦法:
1、先mv so,再cp so就不會出core了
2、先rm so,再cp so就不會出core了
posted @
2010-05-28 15:35 一凡 閱讀(342) |
評論 (0) |
編輯 收藏
1、安裝jprofiler6 google一下
2、修改~/.bashrc,根據你的安裝路徑配置:
export LD_LIBRARY_PATH='/home/work/jprofiler6/bin/linux-x64'
export JPROFILER_HOME='/home/work/jprofiler6/bin/linux-x64'
3、啟動java應用程序
java -agentlib:jprofilerti=port=8849 -Xbootclasspath/a:/home/work/jprofiler6/bin/agent.jar JavaApp
posted @
2010-05-26 10:12 一凡 閱讀(338) |
評論 (0) |
編輯 收藏
1、查看庫函數原型:
在命令模式下,光標停在要看的函數上 ctrl+w i
2、查看庫函數幫助:
在命令模式下,光標停在要看的函數上 shift+k(K)
posted @
2010-05-21 17:44 一凡 閱讀(235) |
評論 (0) |
編輯 收藏
1、copy /etc/vimrc ~/.vimrc
2、vi ~/.vimrc
添加配置
export TERM=xterm-color
即可語法高亮
.vimrc
 if v:lang =~ "utf8$" || v:lang =~ "UTF-8$"
if v:lang =~ "utf8$" || v:lang =~ "UTF-8$"
set fileencodings=utf-8,latin1
endif
set nocompatible " Use Vim defaults (much better!)
set bs=2 " allow backspacing over everything in insert mode
"set ai " always set autoindenting on
"set backup " keep a backup file
set viminfo='20,\"50 " read/write a .viminfo file, don't store more
" than 50 lines of registers
set history=50 " keep 50 lines of command line history
set ruler " show the cursor position all the time
" Only do this part when compiled with support for autocommands
if has("autocmd")
" In text files, always limit the width of text to 78 characters
autocmd BufRead *.txt set tw=78
" When editing a file, always jump to the last cursor position
autocmd BufReadPost *
\ if line("'\"") > 0 && line ("'\"") <= line("$") |
\ exe "normal! g'\"" |
\ endif
endif
if has("cscope")
set csprg=/usr/bin/cscope
set csto=0
set cst
set nocsverb
" add any database in current directory
if filereadable("cscope.out")
cs add cscope.out
" else add database pointed to by environment
elseif $CSCOPE_DB != ""
cs add $CSCOPE_DB
endif
set csverb
endif
" Switch syntax highlighting on, when the terminal has colors
" Also switch on highlighting the last used search pattern.
if &t_Co > 2 || has("gui_running")
syntax on
set hlsearch
endif
if &term=="xterm"
set t_Co=8
set t_Sb=^[[4%dm
set t_Sf=^[[3%dm
endifposted @
2010-05-11 11:32 一凡 閱讀(1239) |
評論 (0) |
編輯 收藏
摘自:http://dikar.javaeye.com/blog/643436
如題,我這里簡單說下我現在離線分析java內存的方式,所謂離線,就是需要dump出正在運行的java系統中的一些運行時堆棧數據,然后拿到線下來分析,分析可以包括內存,線程,GC等等,同時不會對正在運行的生產環境的機器造成很大的影響,對應著離線分析,當然是在線分析了,這個我在后面會嘗試下,因為離線分析有些場景還是模擬不出來,需要借助LR來模擬壓力,查看在線的java程序運行情況了。
首先一個簡單的問題,如何dump出java運行時堆棧,這個SUN就提供了很好的工具,位于JAVA_HOME/bin目錄下的jmap(java memory map之意),如果需要dump出當前運行的java進程的堆棧數據,則首先需要獲得該java進程的進程ID,在linux下可以使用
- ps -aux
-
- ps -ef | grep java
ps -aux
ps -ef | grep java
或者使用jdk自帶的一個工具jps,例如
/JAVA_HOME/bin/jps
找到了當前運行的java進程的id后,就可以對正在運行的java進程使用jmap工具進行dump了,例如使用以下命令:
- JAVA_HOME/bin/jmap -dump:format=b,file=heap.bin <pid>
JAVA_HOME/bin/jmap -dump:format=b,file=heap.bin <pid>
其中file = heap.bin的意思是dump出的文件名叫heap.bin, 當然你可以選擇你喜歡的名字,我這里選擇叫*.bin是為了后面使用方便,<pid>表示你需要dump的java進程的id。
這里需要注意的是,記住dump的進程是java進程,不會是jboss的進程,weblogic的進程等。dump過程中機器load可能會升高,但是在我這里測試發現load升的不是特別快,同時dump時需要的磁盤空間也比較大,例如我這里測試的幾個系統,分別是500M 800M 1500M 3000M,所以確保你運行jmap命令時所在的目錄中的磁盤空間足夠,當然現在的系統磁盤空間都比較大。
以上是在java進程還存活的時候進行的dump,有的時候我們的java進程crash后,會生成一個core.pid文件,這個core.pid文件還不能直接被我們的java 內存分析工具使用,需要將其轉換為java 內存分析工具可以讀的文件(例如使用jmap工具dump出的heap.bin文件就是很多java 內存分析工具可以讀的文件格式)。將core.pid文件轉換為jmap工具dump出的文件格式還可以繼續使用jmap工具,這個的說明可以見我前幾篇中的一個轉載(Create Java heapdumps with the help of core dumps ),這里我在補充點
- jmap -heap:format=b [java binary] [core dump file]
-
-
- jmap -dump:format=b,file=dump.hprof [java binary] [core dump file]
-
-
- 64位下可以指定使用64位模式
-
- jmap -d64 -dump:format=b,file=dump.hprof [java binary] [core dump file]
jmap -heap:format=b [java binary] [core dump file]
jmap -dump:format=b,file=dump.hprof [java binary] [core dump file]
64位下可以指定使用64位模式
jmap -d64 -dump:format=b,file=dump.hprof [java binary] [core dump file]
需要說明一下,使用jmap轉換core.pid文件時,當文件格式比較大時,可能大于2G的時候就不能執行成功(我轉換3G文件大小的時候沒有成功)而報出
Error attaching to core file: Can't attach to the core file
查過sun的bug庫中,這個bug還沒有被修復,我想還是由于32位下用戶進程尋址大小限制在2G的范圍內引起的,在64位系統和64位jdk版本中,轉換3G文件應該沒有什么大的問題(有機會有環境得需要測試下)。如果有興趣分析jmap轉換不成功的同學,可以使用如下命令來分析跟蹤命令的執行軌跡,例如使用
- strace jmap -heap:format=b [java binary] [core dum
strace jmap -heap:format=b [java binary] [core dum
對于strace的命令的說明,同樣可以參考我前幾篇文章中的一個 strace命令用法
同時對于core.pid文件的調試我也補充一下, 其中>>表示命令提示符
- >>gdb JAVA_HOME/bin/java core.pid
-
- >>bt
>>gdb JAVA_HOME/bin/java core.pid
>>bt
bt后就可以看到生成core.pid文件時,系統正在執行的一個操作,例如是哪個so文件正在執行等。
好了說了這么多,上面都是怎么生成java 運行期DUMP文件的,接下來我們就進入分析階段,為了分析這個dump出的文件,需要將這個文件弄到你的分析程序所在的機器上,例如可以是windows上,linux上,這個和你使用的分析工具以及使用的操作系統有關。不管使用什么系統,總是需要把生產環境下打出的dump文件搞到你的分析機器上,由于dump出的文件經常會比較大,例如達到2G,這么大的文件不是很好的從生產環境拉下來,因此使用FTP的方式把文件拖到分析機器上,同時由于單個文件很大,因此為了快速的將文件下載到分析機器,我們可以使用分而治之的思想,先將文件切割為小文件下載,然后在合并為一個大文件即可,還好linux提供了很方便的工具,例如使用如下命令
- $ split -b 300m heap.bin
-
- $ cat x* > heap.bin
$ split -b 300m heap.bin
$ cat x* > heap.bin
在上面的 split 命令行中的 “300m” 表示分割后的每個文件為 300MB,“heap.bin” 為待分割的dump文件,分割后的文件自動命名為 xaa,xab,xac等
cat 命令可將這些分割后的文件合并為一個文件,例如將所有x開頭的文件合并為heap.bin
如果我們是利用一個中間層的FTP服務器來保存數據的,那么我們還需要連接這個FTP服務器把合并后的文件拉下來,在windows下我推薦使用一個工具,速度很快而且簡單,
winscp http://winscp.net/eng/docs/lang:chs
好了分析的文件終于經過一翻周折到了你的分析機器上,現在我們就可以使用分析工具來分析這個dump出的程序了,這里我主要是分析內存的問題,所以我說下我選擇的內存分析工具,我這里使用的是開源的由SAP 和IBM 支持的一個內存分析工具
Memory Analyzer (MAT)
http://www.eclipse.org/mat/
我建議下載 Stand-alone Eclipse RCP 版本,不要裝成eclipse的插件,因為這個分析起來還是很耗內存。
下載好了,解壓開來就可以直接使用了(基于eclipse的),打開以后,在菜單欄中選擇打開文件,選擇你剛剛的dump文件,然后一路的next就可以了,最后你會看到一個報告,這個報告里會告訴你可能的內存泄露的點,以及內存中對象的一個分布,關于mat的使用請參考官方說明,當然你也可以自己徜徉在學習的海洋中 。
對于dump文件的分析還可以使用jdk中提供的一個jhat工具來查看,不過這個很耗內存,而且默認的內存大小不夠,還需要增加參數設置內存大小才能分析出,不過我看了下分析出的結果不是很滿意,而且這個用起來很慢。還是推薦使用mat 。
posted @
2010-05-07 10:31 一凡 閱讀(2904) |
評論 (0) |
編輯 收藏參考手冊里的9語言結構,9.3用戶變量,9.4系統變量
設置用戶變量的一個途徑是執行SET語句:
SET @var_name = expr [, @var_name = expr] ...
也可以用語句代替SET來為用戶變量分配一個值。在這種情況下,分配符必須為:=而不能用=,因為在非SET語句中=被視為一個比較 操作符,如下所示:
mysql> SET @t1=0, @t2=0, @t3=0;
mysql> SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
對于使用select語句為變量賦值的情況,若返回多條記錄,則變量的值為最后一條記錄的值,不過不建議在這種情況下使用;若返回結果為空,即沒有記錄,此時變量的值為上一次變量賦值時的值,如果沒有對變量賦過值,則為NULL。
一般我們可以這么使用:
set @tmp=0
select @tmp:=tmp from table_test;
set @tmp=@tmp+1
系統變量就直接拷貝吧:
MySQL可以訪問許多系統和連接變量。當服務器運行時許多變量可以動態更改。這樣通常允許你修改服務器操作而不需要停止并重啟服務器。
mysqld服務器維護兩種變量。全局變量影響服務器整體操作。會話變量影響具體客戶端連接的操作。
當服務器啟動時,它將所有全局變量初始化為默認值。這些默認值可以在選項文件中或在命令行中指定的選項進行更改。服務器啟動后,通過連接服務器并執行SET GLOBAL var_name語句,可以動態更改這些全局變量。要想更改全局變量,必須具有SUPER權限。
服務器還為每個連接的客戶端維護一系列會話變量。在連接時使用相應全局變量的當前值對客戶端的會話變量進行初始化。對于動態會話變量,客戶端可以通過SET SESSION var_name語句更改它們。設置會話變量不需要特殊權限,但客戶端只能更改自己的會話變量,而不能更改其它客戶端的會話變量。
對于全局變量的更改可以被訪問該全局變量的任何客戶端看見。然而,它只影響更改后連接的客戶的從該全局變量初始化的相應會話變量。不影響目前已經連接的客戶端的會話變量(即使客戶端執行SET GLOBAL語句也不影響)。
可以使用幾種語法形式來設置或檢索全局或會話變量。下面的例子使用了sort_buffer_sizeas作為示例變量名。
要想設置一個GLOBAL變量的值,使用下面的語法:
mysql> SET GLOBAL sort_buffer_size=value;
mysql> SET @@global.sort_buffer_size=value;
要想設置一個SESSION變量的值,使用下面的語法:
mysql> SET SESSION sort_buffer_size=value;
mysql> SET @@session.sort_buffer_size=value;
mysql> SET sort_buffer_size=value;
LOCAL是SESSION的同義詞。
如果設置變量時不指定GLOBAL、SESSION或者LOCAL,默認使用SESSION。參見13.5.3節,“SET語法”。
要想檢索一個GLOBAL變量的值,使用下面的語法:
mysql> SELECT @@global.sort_buffer_size;
mysql> SHOW GLOBAL VARIABLES like 'sort_buffer_size';
要想檢索一個SESSION變量的值,使用下面的語法:
mysql> SELECT @@sort_buffer_size;
mysql> SELECT @@session.sort_buffer_size;
mysql> SHOW SESSION VARIABLES like 'sort_buffer_size';
這里,LOCAL也是SESSION的同義詞。
當你用SELECT @@var_name搜索一個變量時(也就是說,不指定global.、session.或者local.),MySQL返回SESSION值(如果存在),否則返回GLOBAL值。
對于SHOW VARIABLES,如果不指定GLOBAL、SESSION或者LOCAL,MySQL返回SESSION值。
當設置GLOBAL變量需要GLOBAL關鍵字但檢索時不需要它們的原因是防止將來出現問題。如果我們移除一個與某個GLOBAL變量具有相同名字的SESSION變量,具有SUPER權限的客戶可能會意外地更改GLOBAL變量而不是它自己的連接的SESSION變量。如果我們添加一個與某個GLOBAL變量具有相同名字的SESSION變量,想更改GLOBAL變量的客戶可能會發現只有自己的SESSION變量被更改了。
關于系統啟動選項和系統變量的詳細信息參見5.3.1節,“mysqld命令行選項”和5.3.3節,“服務器系統變量”。在5.3.3.1節,“動態系統變量”中列出了可以在運行時設置的變量。
posted @
2010-05-05 13:43 一凡 閱讀(3116) |
評論 (0) |
編輯 收藏JVM內存模型以及垃圾回收
摘自:http://hi.baidu.com/xuwanbest/blog/item/0587d82f2c44a73d1e30892e.html
JAVA堆的描述如下:
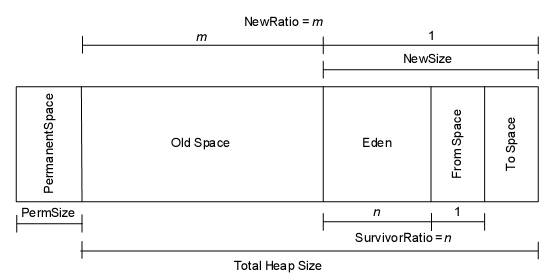
內存由 Perm 和 Heap 組成. 其中
Heap = {Old + NEW = { Eden , from, to } }
JVM內存模型中分兩大塊,一塊是 NEW Generation, 另一塊是Old Generation. 在New Generation中,有一個叫Eden的空間,主要是用來存放新生的對象,還有兩個Survivor Spaces(from,to), 它們用來存放每次垃圾回收后存活下來的對象。在Old Generation中,主要存放應用程序中生命周期長的內存對象,還有個Permanent Generation,主要用來放JVM自己的反射對象,比如類對象和方法對象等。
垃圾回收描述:
在New Generation塊中,垃圾回收一般用Copying的算法,速度快。每次GC的時候,存活下來的對象首先由Eden拷貝到某個Survivor Space, 當Survivor Space空間滿了后, 剩下的live對象就被直接拷貝到Old Generation中去。因此,每次GC后,Eden內存塊會被清空。在Old Generation塊中,垃圾回收一般用mark-compact的算法,速度慢些,但減少內存要求.
垃圾回收分多級,0級為全部(Full)的垃圾回收,會回收OLD段中的垃圾;1級或以上為部分垃圾回收,只會回收NEW中的垃圾,內存溢出通常發生于OLD段或Perm段垃圾回收后,仍然無內存空間容納新的Java對象的情況。
當一個URL被訪問時,內存申請過程如下:
A. JVM會試圖為相關Java對象在Eden中初始化一塊內存區域
B. 當Eden空間足夠時,內存申請結束。否則到下一步
C. JVM試圖釋放在Eden中所有不活躍的對象(這屬于1或更高級的垃圾回收), 釋放后若Eden空間仍然不足以放入新對象,則試圖將部分Eden中活躍對象放入Survivor區
D. Survivor區被用來作為Eden及OLD的中間交換區域,當OLD區空間足夠時,Survivor區的對象會被移到Old區,否則會被保留在Survivor區
E. 當OLD區空間不夠時,JVM會在OLD區進行完全的垃圾收集(0級)
F. 完全垃圾收集后,若Survivor及OLD區仍然無法存放從Eden復制過來的部分對象,導致JVM無法在Eden區為新對象創建內存區域,則出現”out of memory錯誤”
JVM調優建議:
ms/mx:定義YOUNG+OLD段的總尺寸,ms為JVM啟動時YOUNG+OLD的內存大小;mx為最大可占用的YOUNG+OLD內存大小。在用戶生產環境上一般將這兩個值設為相同,以減少運行期間系統在內存申請上所花的開銷。
NewSize/MaxNewSize:定義YOUNG段的尺寸,NewSize為JVM啟動時YOUNG的內存大小;MaxNewSize為最大可占用的YOUNG內存大小。在用戶生產環境上一般將這兩個值設為相同,以減少運行期間系統在內存申請上所花的開銷。
PermSize/MaxPermSize:定義Perm段的尺寸,PermSize為JVM啟動時Perm的內存大小;MaxPermSize為最大可占用的Perm內存大小。在用戶生產環境上一般將這兩個值設為相同,以減少運行期間系統在內存申請上所花的開銷。
SurvivorRatio:設置Survivor空間和Eden空間的比例
內存溢出的可能性
1. OLD段溢出
這種內存溢出是最常見的情況之一,產生的原因可能是:
1) 設置的內存參數過小(ms/mx, NewSize/MaxNewSize)
2) 程序問題
單個程序持續進行消耗內存的處理,如循環幾千次的字符串處理,對字符串處理應建議使用StringBuffer。此時不會報內存溢出錯,卻會使系統持續垃圾收集,無法處理其它請求,相關問題程序可通過Thread Dump獲取(見系統問題診斷一章)單個程序所申請內存過大,有的程序會申請幾十乃至幾百兆內存,此時JVM也會因無法申請到資源而出現內存溢出,對此首先要找到相關功能,然后交予程序員修改,要找到相關程序,必須在Apache日志中尋找。
當Java對象使用完畢后,其所引用的對象卻沒有銷毀,使得JVM認為他還是活躍的對象而不進行回收,這樣累計占用了大量內存而無法釋放。由于目前市面上還沒有對系統影響小的內存分析工具,故此時只能和程序員一起定位。
2. Perm段溢出
通常由于Perm段裝載了大量的Servlet類而導致溢出,目前的解決辦法:
1) 將PermSize擴大,一般256M能夠滿足要求
2) 若別無選擇,則只能將servlet的路徑加到CLASSPATH中,但一般不建議這么處理
3. C Heap溢出
系統對C Heap沒有限制,故C Heap發生問題時,Java進程所占內存會持續增長,直到占用所有可用系統內存
其他:
JVM有2個GC線程。第一個線程負責回收Heap的Young區。第二個線程在Heap不足時,遍歷Heap,將Young 區升級為Older區。Older區的大小等于-Xmx減去-Xmn,不能將-Xms的值設的過大,因為第二個線程被迫運行會降低JVM的性能。
為什么一些程序頻繁發生GC?有如下原因:l 程序內調用了System.gc()或Runtime.gc()。l 一些中間件軟件調用自己的GC方法,此時需要設置參數禁止這些GC。l Java的Heap太小,一般默認的Heap值都很小。l 頻繁實例化對象,Release對象。此時盡量保存并重用對象,例如使用StringBuffer()和String()。如果你發現每次GC后,Heap的剩余空間會是總空間的50%,這表示你的Heap處于健康狀態。許多Server端的Java程序每次GC后最好能有65%的剩余空間。經驗之談:1.Server端JVM最好將-Xms和-Xmx設為相同值。為了優化GC,最好讓-Xmn值約等于-Xmx的1/3[2]。2.一個GUI程序最好是每10到20秒間運行一次GC,每次在半秒之內完成[2]。注意:1.增加Heap的大小雖然會降低GC的頻率,但也增加了每次GC的時間。并且GC運行時,所有的用戶線程將暫停,也就是GC期間,Java應用程序不做任何工作。2.Heap大小并不決定進程的內存使用量。進程的內存使用量要大于-Xmx定義的值,因為Java為其他任務分配內存,例如每個線程的Stack等。2.Stack的設定每個線程都有他自己的Stack。
-Xss 每個線程的Stack大小
Stack的大小限制著線程的數量。如果Stack過大就好導致內存溢漏。-Xss參數決定Stack大小,例如-Xss1024K。如果Stack太小,也會導致Stack溢漏。3.硬件環境硬件環境也影響GC的效率,例如機器的種類,內存,swap空間,和CPU的數量。如果你的程序需要頻繁創建很多transient對象,會導致JVM頻繁GC。這種情況你可以增加機器的內存,來減少Swap空間的使用[2]。4.4種GC第一種為單線程GC,也是默認的GC。,該GC適用于單CPU機器。第二種為Throughput GC,是多線程的GC,適用于多CPU,使用大量線程的程序。第二種GC與第一種GC相似,不同在于GC在收集Young區是多線程的,但在Old區和第一種一樣,仍然采用單線程。-XX:+UseParallelGC參數啟動該GC。第三種為Concurrent Low Pause GC,類似于第一種,適用于多CPU,并要求縮短因GC造成程序停滯的時間。這種GC可以在Old區的回收同時,運行應用程序。-XX:+UseConcMarkSweepGC參數啟動該GC。第四種為Incremental Low Pause GC,適用于要求縮短因GC造成程序停滯的時間。這種GC可以在Young區回收的同時,回收一部分Old區對象。-Xincgc參數啟動該GC。
posted @
2010-05-04 09:29 一凡 閱讀(294) |
評論 (0) |
編輯 收藏一款開源的壓力測試工具,可以根據配置對一個WEB站點進行多用戶的并發訪問,記錄每個用戶所有請求過程的相應時間,并在一定數量的并發訪問下重復進行。
獲取:http://www.joedog.org/
官方提供ftp下載
解壓:
# tar -zxf siege-latest.tar.gz
進入解壓目錄:
# cd siege-2.65/
安裝:
#./configure ; make
#make install
使用
siege -c 200 -r 10 -f example.url
-c是并發量,-r是重復次數。 url文件就是一個文本,每行都是一個url,它會從里面隨機訪問的。
example.url內容:
http://www.taoav.com
http://www.tuhaoduo.com
http://www.tiaonv.com
結果說明
Lifting the server siege… done.
Transactions: 3419263 hits //完成419263次處理
Availability: 100.00 % //100.00 % 成功率
Elapsed time: 5999.69 secs //總共用時
Data transferred: 84273.91 MB //共數據傳輸84273.91 MB
Response time: 0.37 secs //相應用時1.65秒:顯示網絡連接的速度
Transaction rate: 569.91 trans/sec //均每秒完成 569.91 次處理:表示服務器后
Throughput: 14.05 MB/sec //平均每秒傳送數據
Concurrency: 213.42 //實際最高并發數
Successful transactions: 2564081 //成功處理次數
Failed transactions: 11 //失敗處理次數
Longest transaction: 29.04 //每次傳輸所花最長時間
Shortest transaction: 0.00 //每次傳輸所花最短時間
posted @
2010-04-09 23:03 一凡 閱讀(498) |
評論 (0) |
編輯 收藏
mysql8.x:
alter mysql.user 'root'@'%' identified by '123456';
mysql 5.x:
GRANT ALL PRIVILEGES ON *.* TO 'monitor'@'%' IDENTIFIED BY 'monitor' WITH GRANT OPTION;
posted @
2010-03-16 15:38 一凡 閱讀(297) |
評論 (0) |
編輯 收藏