原文鏈接:http://drunkmenworkhere.org/219.php
中文翻譯:benhur
持續修正中……歡迎多提意見!
Contents
Introduction
關于搜索引擎的大規模試驗在持續了一年之后于2006-4-13結束。該試驗的目的是分析搜索引擎行為模式,共使用了基于二叉查找樹結構- Binary Search Tree 2 -而組織的20億頁面。在一年的時間內,三個主要搜索引擎向超過十萬個不同的URL提交了超過一百萬次頁面請求。由于顯示在頁面上的訪問記錄和留言的增長,drunkmenworkhere.org的主頁也從最初的1.6kB增長到了4MB。
本文即為這次試驗的結果。
^
Setup
這次試驗共準備了2,147,483,647個頁面,這些頁面(結點)以二叉查找樹的結構組織在一起。對于某一特定結點來說,它自身的值大于其左子樹上任意一結點的值,而小于右子樹上任意一結點的值。在這次試驗中,最左葉結點的值為1,而最右葉結點的值為2,147,483,647。
二叉樹的深度是指從根結點訪問到最遠的葉結點所經歷的結點數量。如果二叉樹的深度是n,那在這棵二叉樹上最多能排列2n+1個結點。在本次試驗中,二叉樹的深度定為30(231= 2,147,483,648),所以根結點的值為1073741824(230)。在持續一年的時間里(從2005-4-13到2006-4-13),我們跟蹤了三大搜索機器人(Yahoo!Slurp、Googlebot和msnbot)在每個頁面上的訪問量。
為了讓搜索引擎對頁面內容更感興趣,每個結點的值都用short scale(短級差制英語表示,billion=“十億”,譯者注)表示,每一次搜索機器人對于任意結點的訪問記錄都會按時間排序顯示在該結點的頁面上。每個頁面上添加了一個留言板(已于被2006-4-13被移除)。上一版二叉查找樹結構- Binary Search Tree - 因為使用了長URL而造成不便,現在這些措施都是對其的進一步改進。
每個結點上首先顯示了三張訪問樹圖。這是被搜索引擎抓取的結點的圖形化表示。圖中的每條線代表一個結點,線的長度代表搜索機器人的訪問次數。下文中所使用的圖片是訪問樹全圖的修改版,除去了擁有最大訪問量的根結點,但沒有連接到根結點的樹枝仍會被表示。
^
Overall results
到目前為止,Yahoo! Slurp是最活躍的搜索機器人。在一年時間里總共請求了超過一百萬次頁面,抓取了超過十萬個不同的結點。這是一個很大的數字,但也只占了總結點數的0.0049%。所有機器人的統計數據如下:
overall statistics by search engine
| |
Yahoo!
|
Google |
MSN |
total number of pageviews
(頁面總請求數) |
1,030,396 |
20,633 |
4,699 |
number of nodes crawled
(抓取結點數) |
105,971 |
7,556 |
1,390 |
percentage of tree crawled
(抓取率) |
0.0049% |
0.00035% |
0.000065% |
number of indexed nodes
(索引結點數) |
120,000 |
554 |
1 |
indexed/crawled ratio
(索引/抓取比) |
113.23% |
7.33% |
0.07% |
頁面總請求數和抓取結點總數在一年內的增長趨勢如圖1和圖2所示。在隨后幾節中將具體分析搜索機器人抓取結點的方式(配有動畫演示)。
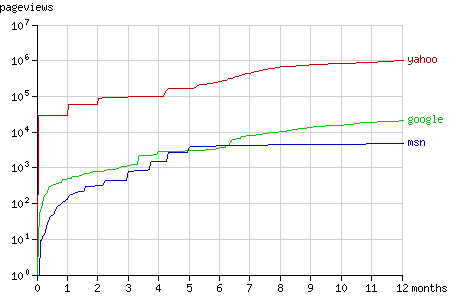
Fig. 1 - The cumulative number of pageviews by the search bots in time.
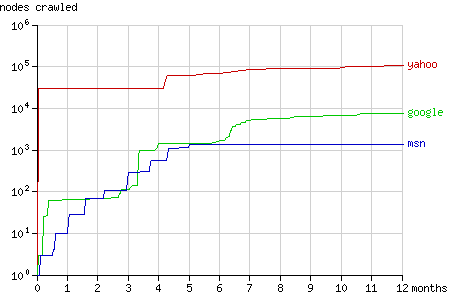
Fig. 2 - The cumulative number of nodes crawled by the search bots in time.
圖3中顯示了二叉樹中的不同層結點被抓取的數據統計(注:縱軸為對數表示)。根結點在level 0,最遠葉結點(如結點1)在level 30。二叉樹的結構決定了在第n層有2n個結點,所以從理論上說,搜索機器人抓取整個二叉樹的行為會在圖中表示為一條單調上升的直線。
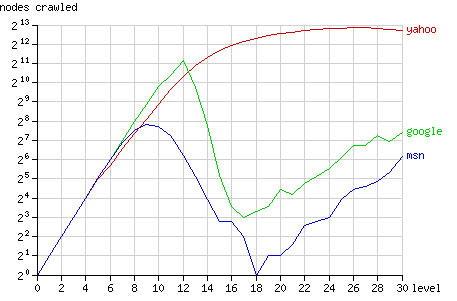
Fig. 3 - The number of nodes crawled after 1 year, grouped by node level.
Googlebot的抓取模式基本上接近于這條直線,直到在第12級發生轉折。它所抓取的大多數結點在第12層或12層以下(8191中的5524個),少有深層的結點被抓取。MSNbot的行為模式與Googlebot類似但拐點出現得更早,在第9級(1023中的656個)。Yahoo沒有發生明顯的轉折,不過在深層抓取新結點的行為逐漸放緩。
與其他搜索機器人相比,Yahoo更頻繁地向其所抓取的深層結點發送請求:在14層到30層的結點平均請求次數為10次。(見圖4)
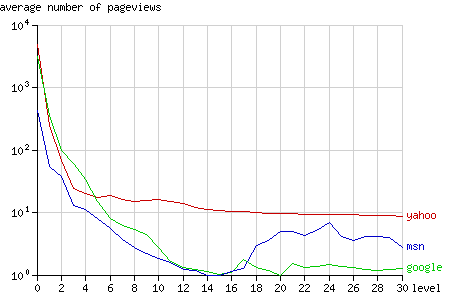
Fig. 4 - The average number of pageviews per node after 1 year, grouped by node level.
^
Yahoo! Slurp

Fig. 5 - The Yahoo! Slurp tree.
Yahoo! Slurp是第一個發現Binary Search Tree 2的引擎。在其后的幾個小時里Yahoo! Slurp每秒2.3個結點(見動畫演示(2 hours ))的速度精力旺盛地抓取著每一個結點。到第一天結束它已經抓取了大約30,000個結點。
在接下來的一個月里Slurp表現得沒有第一天那么活躍,但一個月以后它重新請求了它先前訪問的每一頁。在動畫演示中可以看到:訪問樹在2005-05-14增長了一倍。這一現象在一個月后再次重復:在2005-06-13訪問樹增長到原來規模的三倍。Yahoo! Slurp在請求數已經達到90,000時抓取的結點數仍然維持在30,000。圖6顯示了在最初幾個月里請求數的階梯式增長。
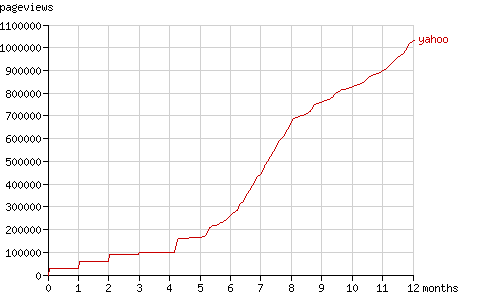
Fig. 6 - The cumulative number of pageviews by Yahoo! Slurp in time.
4個月后,Slurp重復了其第一回合的行為,請求了大量的“新”結點。它請求了所有訪問過的結點。因為已經建立了30000個結點的索引而每一個結點都鏈接到更深一層的兩個子結點,在8月底它請求了60000個頁面(請求數由100,000跳到160,000,見圖6),同時抓取頁面總數也翻了一番。(見圖7)
5個月后Yahoo! Slurp開始顯得更有規律發送請求,從圖7中上仍然可以看到新的“發現期”(例:10個月以后)。
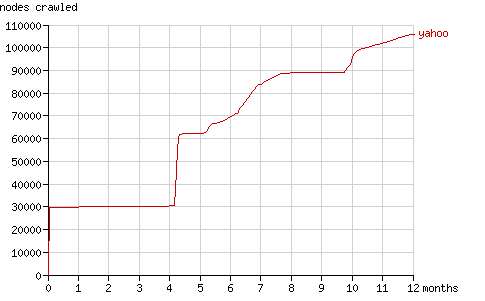
Fig. 7 - The cumulative number of nodes crawled by Yahoo! Slurp in time.
Yahoo在索引中報告了120,000個頁面(current value)。考慮到它只訪問了105,971 個結點,這看起來有點不可思議,但實際上每個結點都有兩個域名:www.drunkmenworkhere.org和drunkmenworkhere.org
Note: 從返回的查詢結果上看,Google和MSN與Yahoo的35,600條記錄相比明顯落于下風。截止到試驗結束為止,Yahoo是唯一一個對上述查詢返回結果的搜索引擎。
^
Googlebot
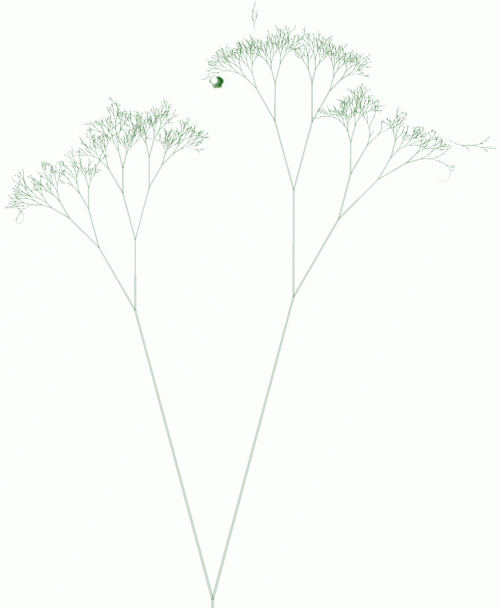
Fig. 8 - The Googlebot tree.
與Yahoo的訪問樹相比,Google的訪問樹更像一棵真實的樹。Google訪問深層結點并不如它們的父結點那么頻繁。Yahoo訪問最頻繁的結點集中在前三層,Google則集中在前12層(見圖4)。
Google訪問樹的形狀取決于PageRank算法,該算法的具體定義如下:
“We assume page A has pages T1…Tn which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. There are more details about d in the next section. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows:
PR(A) = (1-d) + d (PR(T1)/C(T1) + … + PR(Tn)/C(Tn)) “
二叉樹上的絕大多數結點都沒有外部鏈接,所以各結點的PR值計算式可簡化為如下形式(忽略留言上的鏈接):
PR(node) = 0.15 + 0.85 (PR(parent) + PR(left child) + PR(right child))/3
唯一不確定的地方是在迭代計算各結點PR值時我們無法確定根結點的PR值。考慮到根結點作為drunkmenworkhere.org的主頁已經有了一年時間,可以假定它擁有一個高PR值。PageRank樹的特征與Googlebot訪問樹很相似,可以認為Googlebot訪問某一頁面的頻率與這一頁面的PR值直接相關。

Fig. 9 - A binary tree of depth 17 visualising calculated PageRank as length of each line, when the PageRank of the root node is set to 100.
Googlebot訪問樹的動畫顯示了某些不能用PageRank的有趣特征。
- 最遠右子樹
- 一開始Googlebot更多地抓取了二叉樹右支上的結點。在2005-07-04它試圖到達擁有最高值的最右結點。從根結點出發,Googlebot在右子樹深度為20的地方停了下來。訪問樹的右段形成了一段圓弧。

- 搜索結點1
- 在2005-06-30,Googlebot訪問了 結點1——這是二叉樹的最左葉結點。Googlebot并沒有從根結點沿著左子樹一路爬上來,它究竟是如何發現這一結點的呢?是Googlebot猜到了URL還是從某個外部鏈接跟蹤過來?
幾個小時后,Googlebot抓到了結點2——結點1的父結點。這兩個游離于主干之外的結點在動畫演示的2005-06-30顯示為一個小黑點。一周后的2005-07-06 (也就是到達訪問樹最遠右結點的兩天后),Googlebot找到了從根結點訪問結點1的路徑,在20秒之內串聯了24個結點(從06:39:39到06:39:59)。這次大串聯行動從根結點開始,直到連接到結點2,其間沒有一次請求右子結點。在Googlebot訪問樹的全景圖中很容易找到這條訪問路徑。中途的大部分結點沒有第二次被訪問過,在訪問樹上它們被表示短而細的線段,整體的顯示效果為一段極其陡峭的圓弧。

- 類Yahoo子樹
- 在2005-07-23,Google突然間花費幾個小時在結點1073872896周邊抓取了600個新結點。其中絕大多數沒有被再次訪問。
這棵類Yahoo子樹正是圖3中Googlebot在18層到30層抓取的結點數重新上升的原因。

在后六個月里Googlebot一直以一個穩定的速度發送著頁面請求(平均每月260個頁面,見圖11)。與Yahoo! Slurp類似,Googlebot的行為模式也可以分為發現期(periods of discovery)和刷新期(periods of refreshing its cache)。
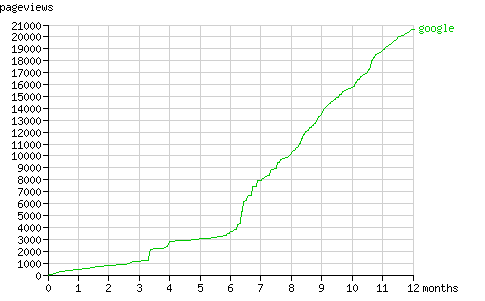
Fig. 10 - The cumulative number of pageviews by Googlebot in time.
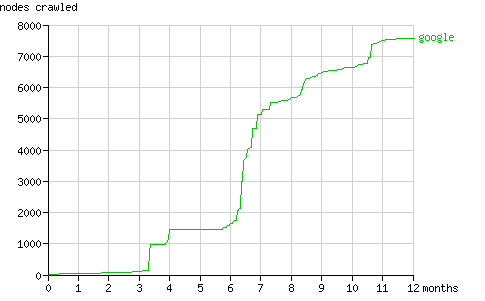
Fig. 11 - The cumulative number of nodes crawled by Googlebot in time.
Google收錄了它所抓取結點中的554個結點。最早收錄的結點是結點1和結點2。它們最早收錄是因為它們的短URL。而Google第一頁的搜索結果的其他結點都位于第4層,這可能是因為前三層結點因為垃圾留言過多而被Google 過濾了。
查看當前的搜索結果請點這里。
^
MSNbot

Fig. 12 - The msnbot tree
Msnbot的訪問樹與Yahoo和Google相比顯得更小,比較有趣的是在訪問樹的右邊有一個大的斷支。這個斷支發生于2005-04-29,msnbot訪問了結點2045877824。這個結點上有一句兩周前的留言:
I hereby claim this name in the name of…well, mine. Paul Pigg.
一周后msnbot請求了這個結點,Googlebot也請求了這個結點。這個看似無奇的24層結點被抓取是因為Paul Pigg的網站masterpigg.com (該站點現在已不存在了, Google cache)為它作了超鏈接。所有這三個搜索引擎都是通過這個鏈接訪問到這個結點,誰也沒能把它同訪問樹的根結點連接上。
查看結點2045877824的留言也能確認這一點。
從這個孤立的結點的上下兩個方向抓取其他結點,從而形成了一顆大的子樹。這顆子樹造成了msnbot在圖3中18層到30層向上趨勢。
第二顆較大的子樹位于頂部中央,是由uu-dot.com的一個超鏈接引起的。這兩個獨立子樹在Googlebot的訪問樹中同樣看得很清楚。搜索結果在上圖中看得不是很清楚。
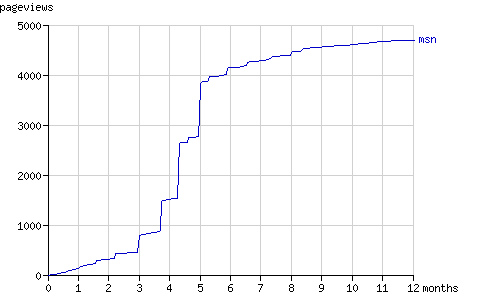
Fig. 13 - The cumulative number of pageviews by msnbot in time.
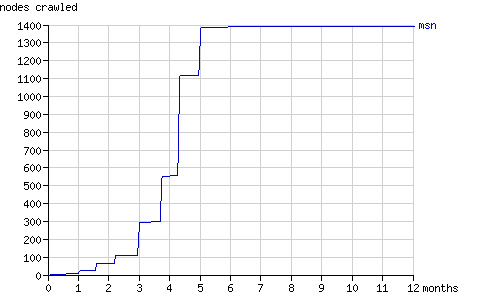
Fig. 14 - The cumulative number of nodes crawled by msnbot in time.
如圖所示,msnbot在5個月后實際上終止了抓取Binary Search Tree 2的行動。MSN Search如何反饋
^
Spam bots
一年之中103個結點上留下了5265條留言。其中有32個結點沒有被任何搜索機器人訪問過。大多數留言(3652)都留在根結點(主頁)上。留言中的最常見的單詞統計如下:
top 50 of most frequently spammed words
| |
count |
word |
| 1 |
32743 |
http |
| 2 |
23264 |
com |
| 3 |
12375 |
url |
| 4 |
8636 |
www |
| 5 |
5541 |
info |
| 6 |
4631 |
viagra |
| 7 |
4570 |
online |
| 8 |
4533 |
phentermine |
| 9 |
4512 |
buy |
| 10 |
4469 |
html |
| 11 |
3531 |
org |
| 12 |
3346 |
blogstudio |
| 13 |
3194 |
drunkmenworkhere |
| 14 |
2801 |
free |
| 15 |
2772 |
cialis |
| 16 |
2371 |
to |
| 17 |
2241 |
u |
| 18 |
2169 |
generic |
| 19 |
2054 |
cheap |
| 20 |
1921 |
ringtones |
| 21 |
1914 |
view |
| 22 |
1835 |
a |
| 23 |
1818 |
net |
| 24 |
1756 |
the |
| 25 |
1658 |
buddy4u |
| 26 |
1633 |
of |
| 27 |
1633 |
lelefa |
| 28 |
1580 |
xanax |
| 29 |
1572 |
blogspot |
| 30 |
1570 |
tramadol |
| 31 |
1488 |
mp3sa |
| 32 |
1390 |
insurance |
| 33 |
1379 |
poker |
| 34 |
1310 |
cgi |
| 35 |
1232 |
sex |
| 36 |
1198 |
teen |
| 37 |
1193 |
in |
| 38 |
1158 |
content |
| 39 |
1105 |
aol |
| 40 |
1099 |
mime |
| 41 |
1095 |
and |
| 42 |
1081 |
home |
| 43 |
1034 |
us |
| 44 |
1022 |
valium |
| 45 |
1020 |
josm |
| 46 |
1012 |
order |
| 47 |
992 |
is |
| 48 |
948 |
de |
| 49 |
908 |
ringtone |
| 50 |
907 |
i |
complete list (360 kB)
從top50可以看出,很多留言都與制藥業有關。下面餅圖就是各種藥物的比例。
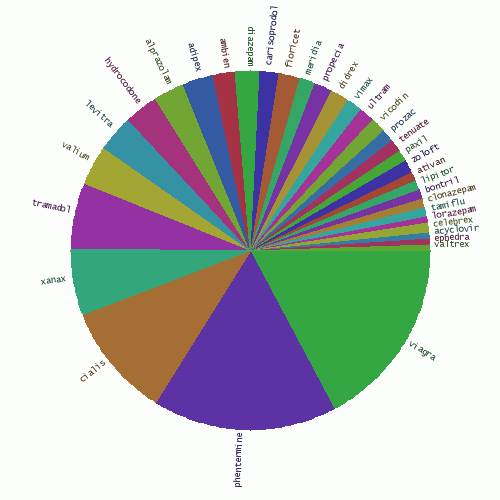
Fig. 15 - The share of various medicines in comment spam.
留言中提交的域名,所有的頂級域名見圖16(按頻度排序)
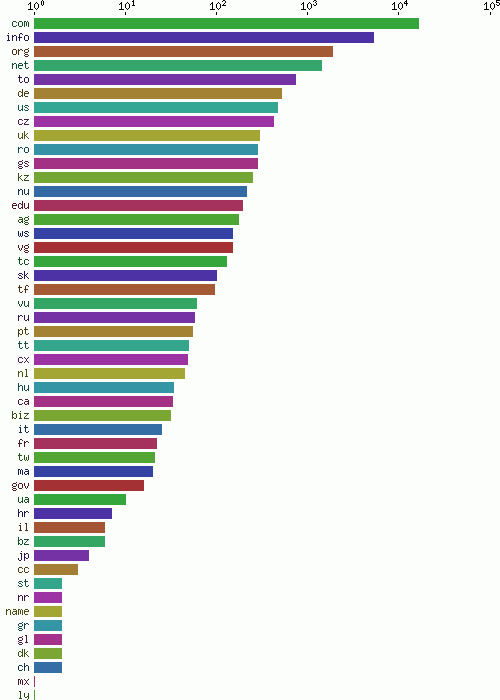
Fig. 16 - Number of spammed domains by top level domain
Spam bots發送的許多郵件都指向一個不存在的地址——@drunkmenworkhere.org,從一個側面也反映出這個域名在“Spam bots最流行域名榜”(the chart of most frequently spammed domains)上的高排名。(見圖17)
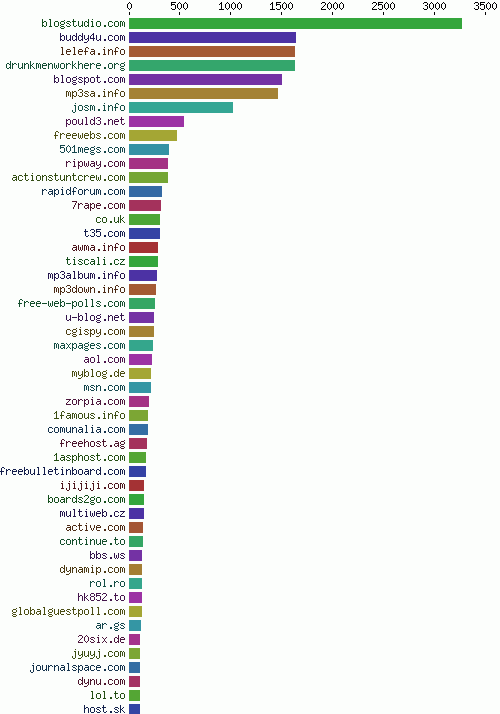
Fig. 17 - Most frequently spammed domains
(全文完)