1、背景
資訊快速膨脹,國際間的溝通日趨頻繁的今天,快速處理大量的外文資料,已是一種普遍的需求。因此,利用翻譯系統來協助人們快速獲取資訊,已成為必然的趨勢。在這種需求帶動之下,用機器翻譯系統來協助人們快速翻譯,建檔,也就成為無法避免的趨勢,計算機輔助翻譯應運而生。與此同時,網絡的快速發展,提供了大量而豐富的雙語對照電子文獻,這就為機器輔助翻譯提供了堅實的語料基礎。
目前機器翻譯系統不能令人滿意的現狀也不容否認。機器翻譯系統表現不佳的一個很重要的原因在于資源缺乏,無論采用何種機器翻譯方法,都需要大量大規模的知識資源。基于規則的機器翻譯系統需要大量的規則知識、詞典知識。基于統計的方法和基于實例的方法需要大規模的雙語對齊語料,一個好的機器翻譯系統所必備的資源往往需要經年累月的積累,構建雙語語料庫對計算機輔助翻譯是重要的。
2、雙語語料(Bitext)的基本概念
雙語語料(bitext) 是一種生成文檔,它包含給定文本的源語言和目標語言之間的翻譯。雙語語料通過一系列被稱為“對齊工具”(alignment tool)或“雙語語料工具”(bitext tool)的軟件產生,這些工具可以自動對齊同一種文本的源語言和被翻譯的語言。這種工具通常情況下可以逐句(sentence by sentence)匹配這兩種不同語言版本的文章。將這些雙語語料句子對存儲起來就會形成雙語語料數據庫或雙語文集,使用者可以通過搜索引擎來查閱數據庫提取需要的雙語語料。
3、TMX的基本概念
TMX (Translation Memory eXchange) 即翻譯存儲交換,是一種廠商中立的、開放式 XML 標準,用于交換計算機輔助翻譯(CAT)和本地化工具創建的翻譯存儲(TM)數據。TMX 的目的是促進工具和/或翻譯廠商之間的翻譯存儲數據交換,在這一過程中不損失或很少損失重要的數據。
4、本文工作
分析獲取網站對應相同內容的中文、英文網頁,根據HTML標記、標點符號等標志信息確定英文和中文語句的對應關系,組合出雙語語料,并按照TMX(Translation Memory Exchange)格式存放這些雙語語料。并且希望開發的軟件能支持用戶交互管理雙語語料(暫時沒做)。
效果圖
1)提取雙語語料
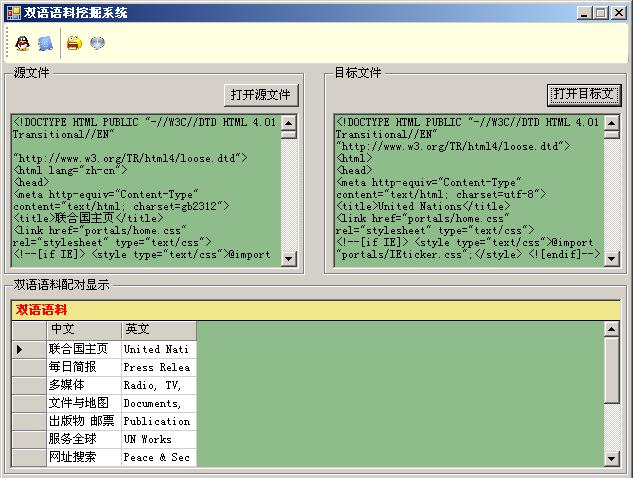
2)生成TMX
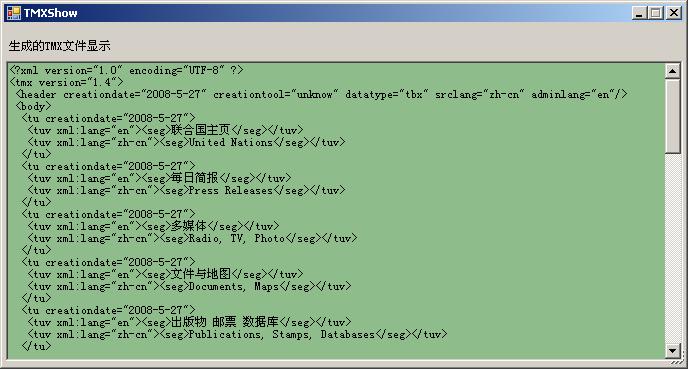
5、總結
原理就是利用.Net平臺的Markup Service實現把中英文網頁解析為DOM樹,這兩棵DOM具有相同的結構。得到DOM樹后,然后遍歷兩個DOM樹,把相同的節點的text等屬性值匹配成雙語語料。 實現的原型系統可以提取中英文網頁中的雙語語料,但系統的容錯能力差,要求中英文網頁必須就有相同的結構(格式)。
posted on 2008-05-27 19:18
何克勤 閱讀(1397)
評論(3) 編輯 收藏