|
|
本文轉自 http://trinea.iteye.com/blog/1196400
1、jps的作用 jps類似linux的ps命令,不同的是ps是用來顯示進程,而jps只顯示java進程,準確的說是當前用戶已啟動的部分java進程信息,信息包括進程號和簡短的進程command。 2、某個java進程已經啟動,用jps卻顯示不了該進程進程號 這個問題已經碰到過兩次了,所以在這里總結下。 現象: 用ps -ef|grep java能看到啟動的java進程,但是用jps查看卻不存在該進程的id。待會兒解釋過之后就能知道在該情況下,jconsole、jvisualvm可能無法監控該進程,其他java自帶工具也可能無法使用 分析: java程序啟動后,默認(請注意是默認)會在/tmp/hsperfdata_userName目錄下以該進程的id為文件名新建文件,并在該文件中存儲jvm運行的相關信息,其中的userName為當前的用戶名,/tmp/hsperfdata_userName目錄會存放該用戶所有已經啟動的java進程信息。對于windows機器/tmp用Windows存放臨時文件目錄代替。 而jps、jconsole、jvisualvm等工具的數據來源就是這個文件(/tmp/hsperfdata_userName/pid)。所以當該文件不存在或是無法讀取時就會出現jps無法查看該進程號,jconsole無法監控等問題 原因: (1)、磁盤讀寫、目錄權限問題 若該用戶沒有權限寫/tmp目錄或是磁盤已滿,則無法創建/tmp/hsperfdata_userName/pid文件。或該文件已經生成,但用戶沒有讀權限 (2)、臨時文件丟失,被刪除或是定期清理 對于linux機器,一般都會存在定時任務對臨時文件夾進行清理,導致/tmp目錄被清空。這也是我第一次碰到該現象的原因 這個導致的現象可能會是這樣,用jconsole監控進程,發現在某一時段后進程仍然存在,但是卻沒有監控信息了。 (3)、java進程信息文件存儲地址被設置,不在/tmp目錄下 上面我們在介紹時說默認會在/tmp/hsperfdata_userName目錄保存進程信息,但由于以上1、2所述原因,可能導致該文件無法生成或是丟失,所以java啟動時提供了參數,可以對這個文件的位置進行設置,而jps、jconsole都只會從/tmp目錄讀取,而無法從設置后的目錄讀物信息, 這個問題只會在jdk 6u23和6u24上出現,在6u23和6u24上,進程信息會保存在-Djava.io.tmpdir下, 因此如果它被設置為非/tmp目錄則會導致 jps,jconsole等無法讀取的現象, 但在其他版本的jdk上,即使設置-Djava.io.tmpdir為非/tmp, 也會在/tmp/hsperfdata_userName下保存java進程信息.因此可以說這是6u23和6u24的bug,
以下是jdk對該bug的描述地址:
bug描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7021676
bug的修復描述:
http://bugs.sun.com/bugdatabase/view_bug.do?bug_id=7009828
bug修改代碼:
http://hg.openjdk.java.net/jdk7/hotspot/hotspot/rev/34d64ad817f4
關于設置該文件位置的參數為-Djava.io.tmpdir
1. 根據上一章配好的集群,現為Myhost1配置backupNode和SecondaryNamenode, 由于機器有限,這里就不為Myhost2配置backupNode和SecondaryNamenode,但是方法相同. 2. 我們選定Myhost4為SecondaryNamenode, Myhost5為backupNode. 配置并啟動SecondaryNamenode: 1. 配置:為Myhost1的 hdfs-site.xml 加入如下配置,指定SecondaryNamenode. <property>
<name>dfs.namenode.secondary.http-address</name>
<value> Myhost4:9001</value>
</property> 2. Myhost4的hdfs-site.xml 加入如下配置,指定nn的url和本地的checkpoint.dir. <property>
<name>dfs.federation.nameservice.id</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/home/yuling.sh/checkpoint-data</value>
</property> 3. 啟動SecondaryNamenode. 在Myhost1上運行命令:sbin/star-dfs.sh或者在Myhost4上運行sbin/hadoop-daemo.sh start SecondaryNamenode 即可以啟動SecondaryNamenode. 可以通過log或者網頁Myhost4:50090查看其狀態. 另外在checkpoint.dir下會有元數據信息. 配置并啟動backupNode: 1. 配置Myhost5的hdfs-site.xml, 加入如下配置信息: <property>
<name>dfs.namenode.backup.address</name>
<value> Myhost5:9002</value>
</property>
<property>
<name>dfs.namenode.backup.http-address</name>
<value> Myhost5:9003</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/ backup-data</value>
</property> 2. 啟動backupNode, 在Myhost5上運行bin/hdfs namenode –backup & 3. 在dfs.namenode.name.dir下查看元數據信息.
下一篇博客將講述如何搭建hadoop 0.23 的mapreduce
使用hadoop-0.23 搭建hdfs, namenode + datanode 1. HDFS-1052引入了多namenode, HDFS架構變化較大, 可以參考hortonworks的文章: http://hortonworks.com/an-introduction-to-hdfs-federation/. 我將在接下來的博客里把此文章翻譯一下(另外還有: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/). 所有namenode共享datanode, 各個namenode相互獨立, 互不影響, 每個namenode都有一個backupNode和SecondaryNamenode,提供主備切換功能和備份元數據的功能. 下文的配置信息主要參考HDFS-2471. 2. 環境: a) 五臺機器 ,linux系統, b) 互相添加ssh-key,后應該可以不用密碼互連 c) 編譯好的0.23版本的包: hadoop-0.23.0-SNAPSHOT.tar.gz d) 每臺機器需要安裝java1.6或以上版本.并把JAVA_HOME加到$PATH中. e) 最好加上pssh和pscp工具. 這里把五臺機器命名為: Myhost1 Myhost2 Myhost3 Myhost4 Myhost5 假設我們需要搭建如下集群: Myhost1和Myhost2開啟 namenode, 另外三臺機器啟動datanode服務. 3. 首先把分配到五臺機器上,然后解壓.(推薦使用pscp, pssh命令) 4. 然后在五臺機器上安裝java,并把JAVA_HOME加到$PATH中 5. 進入解壓后的hadoop目錄, 編輯 etc/hadoop/hdfs-site.xml a) Myhost1的配置如下(其中hadoop存放在/home/yuling.sh/目錄下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> b) Myhost2的配置如下(其中hadoop存放在/home/yuling.sh/目錄下): <property>
<name>fs.defaultFS</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/yuling.sh/cluster-data</value>
</property> c) 這里把Myhost1集群起名ns1, Myhost1集群起名ns2, 三臺slava的etc/hadoop/hdfs-site.xml配置如下: <property>
<name>dfs.federation.nameservices</name>
<value>ns1,ns2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1</name>
<value>hdfs:// Myhost1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns2</name>
<value>hdfs:// Myhost2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1</name>
<value> Myhost2:50070</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/yuling.sh/datanode</value>
</property>
d) 解釋:namenode需要指定兩個參數, 用于存放元數據和文件系統的URL. Datanode需指定要連接的namenode 的rpc-address和http-address. 以及數據存放位置dfs.datanode.data.dir. 6. 然后編輯兩臺namenode的hadoop目錄下 etc/hadoop/slaves文件. 加入三臺slave機器名: Myhost3 Myhost4 Myhost5 7. 現在需要格式化namenode, 由于namenode共享datanode, 因此它們的clusterid需要有相同的名字.這里我們把名字設為 yuling .命令如下: bin/hdfs namenode –format –clusterid yuling 兩臺機器格式話之后會在/home/yuling.sh/cluster-data下生成元數據目錄. 8. 啟動Myhost1和Myhost2上的namenode和slave上datanode服務. 命令如下: sbin/start-hdfs.sh 分別在Myhost1和Myhost2下運行. 9. 啟動之后打開瀏覽器, 分別查看兩namenode啟動后狀態. URL為: Myhost1:50070和Myhost2:50070 10. 這期間可能會遇到許多問題, 但是可以根據拋出的異常自己解決, 我這里就不多說了. 下一篇博客將講述如何啟動backupNode和SecondaryNamenode
編譯(環境linux, 需要聯網) 1. 首先下載hadoop 0.23版本 svn checkout http://svn.apache.org/repos/asf/hadoop/common/tags/release-0.23.0-rc0/ 2. 進入release-0.23.0-rc0目錄下能看到INSTALL.TXT文件, 這里有編譯hadoop 0.23的教程. 編譯前的準備:. a) * Unix System b) * JDK 1.6 c) * Maven 3.0 d) * Forrest 0.8 (if generating docs) e) * Findbugs 1.3.9 (if running findbugs) f) * ProtocolBuffer 2.4.1+ (for MapReduce) g) * Autotools (if compiling native code) h) * Internet connection for first build (to fetch all Maven and Hadoop dependencies) 可以根據需要安裝全部或部分的工具,然后把它們加入到$PATH中. 這里介紹一下ProtocolBuffer的安裝方法:下載2.4.1版本后解壓,進入目錄,運行如下命令即可. $ ./configure --prefile=/usr/local $ make $ sudo make install 3. 經過第二步準備之后,由于從hadoop0.23開始使用Maven編譯,因此必需聯網,命令如下: mvn package [-Pdist][-Pdocs][-Psrc][-Pnative][-Dtar] 建議先運行命令: mvn package -Pdist -DskipTests –Dtar (前提Maven 3.0和ProtocolBuffer2.4.1以上), 此命令成功之后會在release-0.23.0-rc0/下生成 hadoop-dist/target/hadoop-0.23.0-SNAPSHOT.tar.gz. 可以使用這個包搭建集群. 使用-Pdocs選項可以生成文檔,當然前提是安裝了Forrest 0.8和Findbugs 1.3.9. 可以參考如下命令手動指定:FORREST_HOME和FINDBUGS_HOME. mvn package -Pdocs -DskipTests -Dtar -Dmaven.test.skip -Denv.FORREST_HOME=/usr/local/apache-forrest-0.9 -Denv.FINDBUGS_HOME=/usr/local/findbugs-1.3.9 生成的文檔在各自的target/site目錄下.
經過以上步驟,我們已經編譯好了hadoop-0.23,現在可以使用hadoop-0.23.0-SNAPSHOT.tar.gz來搭建集群了. 下一篇博客將講述如何使用hadoop-0.23 搭建hdfs集群
本周末學習zookeeper,原理和安裝配置 本文參考: http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ http://zookeeper.apache.org/ Zookeeper 作為一個分布式的服務框架,主要用來解決分布式集群中應用系統的一致性問題,它能提供基于類似于文件系統的目錄節點樹方式的數據存儲,但是 Zookeeper 并不是用來專門存儲數據的,它的作用主要是用來維護和監控你存儲的數據的狀態變化。通過監控這些數據狀態的變化,從而可以達到基于數據的集群管理。 Zookeeper安裝和配置比較簡單,可以參考官網. 數據模型 Zookeeper 會維護一個具有層次關系的數據結構,它非常類似于一個標準的文件系統,如圖 1 所示:
圖 1 Zookeeper 數據結構

Zookeeper 這種數據結構有如下這些特點: - 每個子目錄項如 NameService 都被稱作為 znode,這個 znode 是被它所在的路徑唯一標識,如 Server1 這個 znode 的標識為 /NameService/Server1
- znode 可以有子節點目錄,并且每個 znode 可以存儲數據,注意 EPHEMERAL 類型的目錄節點不能有子節點目錄
- znode 是有版本的,每個 znode 中存儲的數據可以有多個版本,也就是一個訪問路徑中可以存儲多份數據
- znode 可以是臨時節點,一旦創建這個 znode 的客戶端與服務器失去聯系,這個 znode 也將自動刪除,Zookeeper 的客戶端和服務器通信采用長連接方式,每個客戶端和服務器通過心跳來保持連接,這個連接狀態稱為 session,如果 znode 是臨時節點,這個 session 失效,znode 也就刪除了
- znode 的目錄名可以自動編號,如 App1 已經存在,再創建的話,將會自動命名為 App2
- znode 可以被監控,包括這個目錄節點中存儲的數據的修改,子節點目錄的變化等,一旦變化可以通知設置監控的客戶端,這個是 Zookeeper 的核心特性,Zookeeper 的很多功能都是基于這個特性實現的,后面在典型的應用場景中會有實例介紹
ZooKeeper 典型的應用場景 Zookeeper 從設計模式角度來看,是一個基于觀察者模式設計的分布式服務管理框架,它負責存儲和管理大家都關心的數據,然后接受觀察者的注冊,一旦這些數據的狀態發生 變化,Zookeeper 就將負責通知已經在 Zookeeper 上注冊的那些觀察者做出相應的反應,從而實現集群中類似 Master/Slave 管理模式,關于 Zookeeper 的詳細架構等內部細節可以閱讀 Zookeeper 的源碼 下面詳細介紹這些典型的應用場景,也就是 Zookeeper 到底能幫我們解決那些問題?下面將給出答案。 統一命名服務(Name Service) 分布式應用中,通常需要有一套完整的命名規則,既能夠產生唯一的名稱又便于人識別和記住,通常情況下用樹形的名稱結構是一個理想的選擇,樹形 的名稱結構是一個有層次的目錄結構,既對人友好又不會重復。說到這里你可能想到了 JNDI(Java Naming and Directory Interface,Java命名和目錄接口,是一組在Java應用中訪問命名和目錄服務的API),沒錯 Zookeeper 的 Name Service 與 JNDI 能夠完成的功能是差不多的,它們都是將有層次的目錄結構關聯到一定資源上,但是 Zookeeper 的 Name Service 更加是廣泛意義上的關聯,也許你并不需要將名稱關聯到特定資源上,你可能只需要一個不會重復名稱,就像數據庫中產生一個唯一的數字主鍵一樣。 Name Service 已經是 Zookeeper 內置的功能,你只要調用 Zookeeper 的 API 就能實現。如調用 create 接口就可以很容易創建一個目錄節點。 配置管理(Configuration Management) 配置的管理在分布式應用環境中很常見,例如同一個應用系統需要多臺 PC Server 運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那么就必須同時修改每臺運行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。 像這樣的配置信息完全可以交給 Zookeeper 來管理,將配置信息保存在 Zookeeper 的某個目錄節點中,然后將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每臺應用機器就會收到 Zookeeper 的通知,然后從 Zookeeper 獲取新的配置信息應用到系統中。
圖 2. 配置管理結構圖
 集群管理(Group Membership) Zookeeper 能夠很容易的實現集群管理的功能,如有多臺 Server 組成一個服務集群,那么必須要一個“總管”知道當前集群中每臺機器的服務狀態,一旦有機器不能提供服務,集群中其它集群必須知道,從而做出調整重新分配服 務策略。同樣當增加集群的服務能力時,就會增加一臺或多臺 Server,同樣也必須讓“總管”知道。 Zookeeper 不僅能夠幫你維護當前的集群中機器的服務狀態,而且能夠幫你選出一個“總管”,讓這個總管來管理集群,這就是 Zookeeper 的另一個功能 Leader Election。 它們的實現方式都是在 Zookeeper 上創建一個 EPHEMERAL 類型的目錄節點,然后每個 Server 在它們創建目錄節點的父目錄節點上調用 getChildren(String path, boolean watch) 方法并設置 watch 為 true,由于是 EPHEMERAL 目錄節點,當創建它的 Server 死去,這個目錄節點也隨之被刪除,所以 Children 將會變化,這時 getChildren上的 Watch 將會被調用,所以其它 Server 就知道已經有某臺 Server 死去了。新增 Server 也是同樣的原理。 Zookeeper 如何實現 Leader Election,也就是選出一個 Master Server。和前面的一樣每臺 Server 創建一個 EPHEMERAL 目錄節點,不同的是它還是一個 SEQUENTIAL 目錄節點,所以它是個 EPHEMERAL_SEQUENTIAL 目錄節點。之所以它是 EPHEMERAL_SEQUENTIAL 目錄節點,是因為我們可以給每臺 Server 編號,我們可以選擇當前是最小編號的 Server 為 Master,假如這個最小編號的 Server 死去,由于是 EPHEMERAL 節點,死去的 Server 對應的節點也被刪除,所以當前的節點列表中又出現一個最小編號的節點,我們就選擇這個節點為當前 Master。這樣就實現了動態選擇 Master,避免了傳統意義上單 Master 容易出現單點故障的問題。
圖 3. 集群管理結構圖
 這部分的示例代碼如下,完整的代碼請看源代碼:
清單 3. Leader Election 關鍵代碼
void findLeader() throws InterruptedException { byte[] leader = null; try { leader = zk.getData(root + "/leader", true, null); } catch (Exception e) { logger.error(e); } if (leader != null) { following(); } else { String newLeader = null; try { byte[] localhost = InetAddress.getLocalHost().getAddress(); newLeader = zk.create(root + "/leader", localhost, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL); } catch (Exception e) { logger.error(e); } if (newLeader != null) { leading(); } else { mutex.wait(); } } } | 共享鎖(Locks) 共享鎖在同一個進程中很容易實現,但是在跨進程或者在不同 Server 之間就不好實現了。Zookeeper 卻很容易實現這個功能,實現方式也是需要獲得鎖的 Server 創建一個 EPHEMERAL_SEQUENTIAL 目錄節點,然后調用 getChildren方法獲取當前的目錄節點列表中最小的目錄節點是不是就是自己創建的目錄節點,如果正是自己創建的,那么它就獲得了這個鎖,如果不是那么它就調用 exists(String path, boolean watch) 方法并監控 Zookeeper 上目錄節點列表的變化,一直到自己創建的節點是列表中最小編號的目錄節點,從而獲得鎖,釋放鎖很簡單,只要刪除前面它自己所創建的目錄節點就行了。
圖 4. Zookeeper 實現 Locks 的流程圖
 同步鎖的實現代碼如下,完整的代碼請看源代碼:
清單 4. 同步鎖的關鍵代碼
void getLock() throws KeeperException, InterruptedException{ List<String> list = zk.getChildren(root, false); String[] nodes = list.toArray(new String[list.size()]); Arrays.sort(nodes); if(myZnode.equals(root+"/"+nodes[0])){ doAction(); } else{ waitForLock(nodes[0]); } } void waitForLock(String lower) throws InterruptedException, KeeperException { Stat stat = zk.exists(root + "/" + lower,true); if(stat != null){ mutex.wait(); } else{ getLock(); } } | 隊列管理 Zookeeper 可以處理兩種類型的隊列: - 當一個隊列的成員都聚齊時,這個隊列才可用,否則一直等待所有成員到達,這種是同步隊列。
- 隊列按照 FIFO 方式進行入隊和出隊操作,例如實現生產者和消費者模型。
同步隊列用 Zookeeper 實現的實現思路如下: 創建一個父目錄 /synchronizing,每個成員都監控標志(Set Watch)位目錄 /synchronizing/start 是否存在,然后每個成員都加入這個隊列,加入隊列的方式就是創建 /synchronizing/member_i 的臨時目錄節點,然后每個成員獲取 / synchronizing 目錄的所有目錄節點,也就是 member_i。判斷 i 的值是否已經是成員的個數,如果小于成員個數等待 /synchronizing/start 的出現,如果已經相等就創建 /synchronizing/start。 用下面的流程圖更容易理解:
圖 5. 同步隊列流程圖
 同步隊列的關鍵代碼如下,完整的代碼請看附件:
清單 5. 同步隊列
void addQueue() throws KeeperException, InterruptedException{ zk.exists(root + "/start",true); zk.create(root + "/" + name, new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL); synchronized (mutex) { List<String> list = zk.getChildren(root, false); if (list.size() < size) { mutex.wait(); } else { zk.create(root + "/start", new byte[0], Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT); } } } | 當隊列沒滿是進入 wait(),然后會一直等待 Watch 的通知,Watch 的代碼如下: public void process(WatchedEvent event) { if(event.getPath().equals(root + "/start") && event.getType() == Event.EventType.NodeCreated){ System.out.println("得到通知"); super.process(event); doAction(); } } | FIFO 隊列用 Zookeeper 實現思路如下: 實現的思路也非常簡單,就是在特定的目錄下創建 SEQUENTIAL 類型的子目錄 /queue_i,這樣就能保證所有成員加入隊列時都是有編號的,出隊列時通過 getChildren( ) 方法可以返回當前所有的隊列中的元素,然后消費其中最小的一個,這樣就能保證 FIFO。 下面是生產者和消費者這種隊列形式的示例代碼,完整的代碼請看附件:
清單 6. 生產者代碼
boolean produce(int i) throws KeeperException, InterruptedException{ ByteBuffer b = ByteBuffer.allocate(4); byte[] value; b.putInt(i); value = b.array(); zk.create(root + "/element", value, ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT_SEQUENTIAL); return true; } |
清單 7. 消費者代碼
int consume() throws KeeperException, InterruptedException{ int retvalue = -1; Stat stat = null; while (true) { synchronized (mutex) { List<String> list = zk.getChildren(root, true); if (list.size() == 0) { mutex.wait(); } else { Integer min = new Integer(list.get(0).substring(7)); for(String s : list){ Integer tempValue = new Integer(s.substring(7)); if(tempValue < min) min = tempValue; } byte[] b = zk.getData(root + "/element" + min,false, stat); zk.delete(root + "/element" + min, 0); ByteBuffer buffer = ByteBuffer.wrap(b); retvalue = buffer.getInt(); return retvalue; } } } } | 總結 Zookeeper 作為 Hadoop 項目中的一個子項目,是 Hadoop 集群管理的一個必不可少的模塊,它主要用來控制集群中的數據,如它管理 Hadoop 集群中的 NameNode,還有 Hbase 中 Master Election、Server 之間狀態同步等。 本文介紹的 Zookeeper 的基本知識,以及介紹了幾個典型的應用場景。這些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分布式集群管理的機制,就是它這種基于層次型的目錄樹的數據結構,并對樹中的節點進行有效管理,從而可以設計出多種多樣的分布式的數據管 理模型,而不僅僅局限于上面提到的幾個常用應用場景。
使用 Linux 系統總是免不了要接觸包管理工具。比如,Debian/Ubuntu 的 apt、openSUSE 的 zypp、Fedora 的 yum、Mandriva 的 urpmi、Slackware 的 slackpkg、Archlinux 的 pacman、Gentoo 的 emerge、Foresight 的 conary、Pardus 的 pisi,等等。DistroWatch 針對上述包管理器的主要用法進行了總結,對各位 Linux 用戶來說具有很好的參考作用。這個總結還是有一點不足,有空給大家整理一個更全面的版本。 | 任務 | apt
Debian, Ubuntu | zypp
openSUSE | yum
Fedora, CentOS | | 安裝包 | apt-get install <pkg> | zypper install <pkg> | yum install <pkg> | | 移除包 | apt-get remove <pkg> | zypper remove <pkg> | yum erase <pkg> | | 更新包列表 | apt-get update | zypper refresh | yum check-update | | 更新系統 | apt-get upgrade | zypper update | yum update | | 列出源 | cat /etc/apt/sources.list | zypper repos | yum repolist | | 添加源 | (edit /etc/apt/sources.list) | zypper addrepo <path> <name> | (add <repo> to /etc/yum.repos.d/) | | 移除源 | (edit /etc/apt/sources.list) | zypper removerepo <name> | (remove <repo> from /etc/yum.repos.d/) | | 搜索包 | apt-cache search <pkg> | zypper search <pkg> | yum search <pkg> | | 列出已安裝的包 | dpkg -l | rpm -qa | rpm -qa | | 任務 | urpmi
Mandriva | slackpkg
Slackware | pacman
Arch | | 安裝包 | urpmi <pkg> | slackpkg install <pkg> | pacman -S <pkg> | | 移除包 | urpme <pkg> | slackpkg remove <pkg> | pacman -R <pkg> | | 更新包列表 | urpmi.update -a | slackpkg update | pacman -Sy | | 更新系統 | urpmi --auto-select | slackpkg upgrade-all | pacman -Su | | 列出源 | urpmq --list-media | cat /etc/slackpkg/mirrors | cat /etc/pacman.conf | | 添加源 | urpmi.addmedia <name> <path> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 移除源 | urpmi.removemedia <media> | (edit /etc/slackpkg/mirrors) | (edit /etc/pacman.conf) | | 搜索包 | urpmf <pkg> | -- | pacman -Qs <pkg> | | 列出已安裝的包 | rpm -qa | ls /var/log/packages/ | pacman -Qii | | 任務 | conary
rPath, Foresight | pisi
Pardus | emerge
Gentoo | | 安裝包 | conary update <pkg> | pisi install <pkg> | emerge <pkg> | | 移除包 | conary erase <pkg> | pisi remove <pkg> | emerge -C <pkg> | | 更新包列表 | | pisi update-repo | emerge --sync | layman -S [for added repositories] | | 更新系統 | conary updateall | pisi upgrade | emerge -NuDa world | | 列出源 | | pisi list-repo | layman -L | | 添加源 | | pisi add-repo <name> <path> | layman -a | | 移除源 | | pisi remove-repo <name> | layman -d | | 搜索包 | conary query <pkg> | pisi search <pkg> | emerge --search | | 列出已安裝的包 | conary query | pisi list-installed | cat /var/lib/portage | more |
本文轉自 http://linuxtoy.org/archives/linux-package-management-cheatsheet.html
-Xms256m
-Xmx512m
-Xmn128m
-XX:PermSize=96m
-XX:MaxPermSize=96m
-Xverify:none
-Xnoclassgc
-XX:UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=85 加入以上參數能使eclipse啟動速度得到加快.至于各個參數的意義可以在網上查找到,這里不詳細贅述.
Eclipse插件開發 1. 下載并安裝jdk和eclipse
這里強調一下: 需要下載Eclipse for RCP and RAP Developers, 否則無法新建Plug-in Development 項目.
2. 新建項目
安裝好之后打開eclipse, 點擊 File->NewProject。選擇Plug-in Project,點擊Next。新建一個名為com.developer.showtime的項目,所有參數采用默認值. 3. 在com.developer.showtime項目的src下新建一個類: ShowTime,代碼如下:
package com.developer.showtime;
import org.eclipse.jface.dialogs.MessageDialog;
import org.eclipse.swt.widgets.Display;
import org.eclipse.swt.widgets.Shell;
import org.eclipse.ui.IStartup;
public class ShowTime implements IStartup {
public void earlyStartup() {
Display.getDefault().syncExec(new Runnable() {
public void run(){
long eclipseStartTime = Long.parseLong(System.getProperty("eclipse.startTime"));
long costTime = System.currentTimeMillis() - eclipseStartTime;
Shell shell = Display.getDefault().getActiveShell();
String message = "Eclipse start in " + costTime + "ms";
MessageDialog.openInformation(shell, "Information", message);
}
});
}
}
4. 修改plugin.xml文件如下: <?xml version="1.0" encoding="UTF-8"?>
<?eclipse version="3.4"?>
<plugin>
<extension
point="org.eclipse.ui.startup">
<startup class="com.developer.showtime.ShowTime"/>
</extension>
</plugin> 5. 試運行 右鍵點擊Run as -> Eclipse Application. 此時會運行一個eclipse, 啟動之后就能顯示啟動所需時間. 6. 導出插件. 右鍵Export -> Deployable plug-ins and fragments. 在Directory中輸入需要導出的路徑, 點擊finish后會在該目錄下產生一個plugins的目錄, 里面就是插件包: com.developer.showTime_1.0.0.201110161216.jar. 把這個包復制到eclipse目錄下的plugin目錄下. 然后再啟動eclipse 便可以看到eclipse啟動所花的時間.
本周學習了mapreduce-64,對map端的spill有了較為深入的了解. 附件描述了修改前后sort的原理.mapreduce-64前spill原理較為簡單,打上mapreduce-64后主要流程也不難,需要了解各個參數的意義.
下文翻譯自yahoo博客:http://developer.yahoo.com/blogs/hadoop/posts/2011/02/mapreduce-nextgen/
Hadoop的下一代mapreduce 概述 在大數據商業領域中,運行個數少但較大的集群比運行多個小集群更劃算,大集群還可以處理更大的數據集并支持更多的作業和用戶. Apache Hadoop 的MapReduce框架已經達到4000臺機器的擴展極限,我們正在發展下一代MapReduce,使其成為一個通用資源管理,單作業,用戶自定義組件,管理著應用程序執行的框架. 由于停機成本更大,高可用必需從一開始就得建立,就如安全性和多用戶組,用以支持更多用戶使用更大的集群,新的構架在許多地方進行了創新,增加了敏捷性和機器利用率. 背景 當前Apache Hadoop 的MapReduce的接口會顯示其年齡. 由于集群大小和工作負載的變化趨勢, MapReduce的JobTracker需要徹底的改革以解決其可擴展性,內存消耗,線程模型,可靠性和性能上的不足. 過去五年,我們做了一些小的修復,然而最近,修改框架的的成本越來越高. 結構的缺陷和糾正措施都很好理解,甚至早在2007年,當我們記錄下修復建議: https://issues.apache.org/jira/browse/MAPREDUCE-278. 從運營的角度看,目前的Hadoop MapReduce框架面臨系統級別的升級,以解決例如bug修復,性能改善和功能的需求. 更糟糕的是,它迫使每個用戶也需要同時升級,不顧其利益;這使用戶使用新版本的周期變長. 需求 我們考慮改善Hadoop MapReduce框架的方法,重要的是記住最迫切的需求,下一代Hadoop MapReduce框架最迫切的需求是: - 可靠性
- 可用性
- 可擴展性 - 10000臺機器,200000核,或者更多
- 向后兼容性 - 確保用戶的MapReduce應用程序在下一代框架下不需要改變
- 進展 – 客戶端可以控制hadoop軟件堆棧的升級.
- 可預測的延遲 – 用戶很關注的一點.
- 集群利用率
第二層次需求: - 使MapReduce支持備用編程范式
- 支持短時間的服務
鑒于以上需求,顯然我們需要重新考慮使用hadoop成為數據處理的基礎設施. 事實上,當前MapReduce結構無法滿足我們的需求,因此需要新的創新,這在hadoop社區這已成為共識,查看2008年一月的一個提議,在jira: https://issues.apache.org/jira/browse/MAPREDUCE-279. 下一代MapReduce 重構的基本思想是把jobtracker的兩大功能分開,使資源管理和作業分配/監控成為兩個部件.新的資源管理器管理提供給應用(一個或多個)的計算資源,應用管理中心管理應用程序的調度和協調,應用程序既是一個經典MapReduce作業也是這類作業的DAG. 資源管理器和每臺機器的NodeManager服務,管理該機上的用戶進程,形成計算結構. 每個應用程序的ApplicationMaster是一個具體庫的架構,負責從資源管理器請求資源,并和NodeManager協同執行和監控任務. 資源管理器支持應用程序的分組,這些組保證使用一定比例集群資源. 它是純粹的調度,也就是,它運行時并不監控和追蹤應用的狀態. 此外,它不保證重新啟動失敗的任務,無論是應用程序或硬件導致的失敗. 資源管理器執行調度功能是基于應用的資源需求,每個應用需要多種資源需求,代表對對容器所需的資源,資源需求包括內存,cpu,硬盤,網絡等,注意這與當前使用slot模型的MapReduce有很大的不同,slot模型導致集群利用率不高,資源管理器有一個調度策略插件,負責分把集群資源分給各個組,應用等.有基礎的調度插件,例如:當前的CapacityScheduler 和FairScheduler. NodeManager是每臺機器的框架代理,負責提交應用程序的容器,監控他們的資源利用率(cpu,內存,硬盤,網絡),并且報告給調度器. 每個應用程序的ApplicationMaster負責與調度器請求適當的資源容器,提交作業,追蹤其狀態,監控進度和處理失敗任務. 結構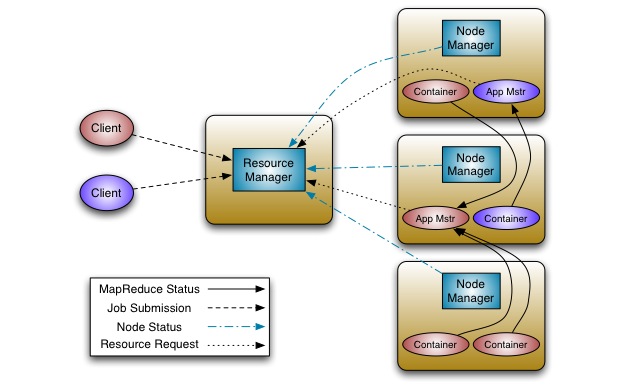 改進當前實現面對面的Hadoop MapReduce 可擴展性 在集群中把資源管理從集群管理器的整個生命周期和他們的部件中分離出來后形成的架構:擴展性更好并且更優雅, Hadoop MapReduce的JobTracker花費很大一部分時間和精力管理應用程序的生命周期,這是導致軟件災難的原因.把它移到應用指定的實體是一個重大的勝利. 可擴展性在當前硬件趨勢下更加重要,當前hadoop的MapReduce已經發展到4000臺機器,然而4000臺機器在2009年(例:8core,16G RAM,4TB硬盤)只有2011年400臺機器的一半(16core,48G RAM, 24TB硬盤). 并且,運營成本的因素有助于迫使和鞏固我們使用更大的集群:6000臺機器或者更多. 可用性 - 資源管理器 – 使用 Apache ZooKeeper 用于故障轉移. 當資源管理器發生故障,另外一個可以迅速恢復,這是由于集群狀態保存在ZooKeeper中. 資源管理器失敗后,重啟所有組和正在運行的應用程序.
- 應用中心 - 下一代MapReduce支持應用特殊點的檢查功能 ,依靠其把自身狀態存儲在hdfs上的功能,MapReduce 應用中心可以從失敗中恢復,
兼容性 下一代MapReduce使用線兼容協議以允許不同版本的服務端和客戶端相互通信,在將來的releases版本,這將使集群滾動升級,一個重要的可操作性便成功了. 創新和敏捷性 提出的構架一個主要優點是MapReduce將更有效,成為user-land library. 計算框架(資源管理器和節點管理器)完全通用并在MapReduce看來是透明的. 這使最終客戶在同一個集群使用可用不同版本的MapReduce, 這是微不足道的支持,因為MapReduce的應用中心和運行時的多版本可用于不同的應用. 這為應用提供顯著的靈活性,因為整個集群沒必要升級,如修復bug,改進和新功能的應用. 它也允許終端用戶根據他們自己的安排升級其應用到MapReduce版本,這大大提高了集群的可操作性. 允許用戶自定義的Map-Reduce版本的創新不會影響軟件的穩定性. 這是微不足道的,就像hadoop在線原型進入用戶MapReduce版本而不影響其他用戶.( It will be trivial to incorporate features such as the Hadoop Online Prototype into the user’s version of MapReduce without affecting other users.) 集群利用率 下一代MapReduce資源管理器使用通用概念,用于調度和分配給單獨的個體. 集群中的每個機器資源是概念性的,例如內存,cpu,I/O帶寬等. 每個機器都是可替代的,分配給應用程序就像基于應用指定需求資源的容器.每個容器包括一些處理器,并和其他容器邏輯隔離,提供強有利的多租戶支持. 它刪除了當前hadoop MapReduce中map和reduce slots概念. Slot會影響集群的利用率,因為在任何時候,無論map和reduce都是稀缺的. 支持MapReduce編程范式 下一代MapReduce提供一個完全通用的計算框架以支持MapReduce和其他的范例. 架構允許終端用戶實現應用指定的框架,通過實現用戶的ApplicationMaster,可以向資源管理器請求資源并利用他們,因為他們通過隔離并保證資源的情況下看起來是適合的. 因此,在同一個hadoop集群下支持多種編程范式,例如MapReduce, MPI, Master-Worker和迭代模型,并允許為每個應用使用適當的框架.這對自定義框架順序執行一定數目的MapReduc應用程序(例: K-Means, Page-Rank)很重要. 結論 Apache Hadoop和特定的Hadoop MapReduce,是一個用于處理大數據集的成功開源項目. 我們建議Hadoop的 MapReduce重構以提供高可用性,增加集群利用率,提供編程范例的支持以加快發展. 我們認為,在已存在的選項中如Torque, Condor, Mesos 等,沒有一個用于設計解決MapReduce集群規模的問題, 某些功能很新且不成熟, 另外一些沒有解決關鍵問題,如調度在上十萬個task,規模的性能,安全和多用戶等. 我們將與Apache Hadoop社區合作,為實現這以提升Apache Hadoop以適應下一代大數據空間.
0.23的調度方法: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/
|