下文翻譯自yahoo博客:
http://developer.yahoo.com/blogs/hadoop/posts/2011/02/mapreduce-nextgen/
Hadoop的下一代mapreduce
概述
在大數(shù)據(jù)商業(yè)領(lǐng)域中,運行個數(shù)少但較大的集群比運行多個小集群更劃算,大集群還可以處理更大的數(shù)據(jù)集并支持更多的作業(yè)和用戶.
Apache Hadoop 的MapReduce框架已經(jīng)達到4000臺機器的擴展極限,我們正在發(fā)展下一代MapReduce,使其成為一個通用資源管理,單作業(yè),用戶自定義組件,管理著應(yīng)用程序執(zhí)行的框架. 由于停機成本更大,高可用必需從一開始就得建立,就如安全性和多用戶組,用以支持更多用戶使用更大的集群,新的構(gòu)架在許多地方進行了創(chuàng)新,增加了敏捷性和機器利用率.
背景
當前Apache Hadoop 的MapReduce的接口會顯示其年齡.
由于集群大小和工作負載的變化趨勢, MapReduce的JobTracker需要徹底的改革以解決其可擴展性,內(nèi)存消耗,線程模型,可靠性和性能上的不足. 過去五年,我們做了一些小的修復(fù),然而最近,修改框架的的成本越來越高. 結(jié)構(gòu)的缺陷和糾正措施都很好理解,甚至早在2007年,當我們記錄下修復(fù)建議: https://issues.apache.org/jira/browse/MAPREDUCE-278.
從運營的角度看,目前的Hadoop MapReduce框架面臨系統(tǒng)級別的升級,以解決例如bug修復(fù),性能改善和功能的需求. 更糟糕的是,它迫使每個用戶也需要同時升級,不顧其利益;這使用戶使用新版本的周期變長.
需求
我們考慮改善Hadoop MapReduce框架的方法,重要的是記住最迫切的需求,下一代Hadoop MapReduce框架最迫切的需求是:
- 可靠性
- 可用性
- 可擴展性 - 10000臺機器,200000核,或者更多
- 向后兼容性 - 確保用戶的MapReduce應(yīng)用程序在下一代框架下不需要改變
- 進展 – 客戶端可以控制hadoop軟件堆棧的升級.
- 可預(yù)測的延遲 – 用戶很關(guān)注的一點.
- 集群利用率
第二層次需求:
- 使MapReduce支持備用編程范式
- 支持短時間的服務(wù)
鑒于以上需求,顯然我們需要重新考慮使用hadoop成為數(shù)據(jù)處理的基礎(chǔ)設(shè)施. 事實上,當前MapReduce結(jié)構(gòu)無法滿足我們的需求,因此需要新的創(chuàng)新,這在hadoop社區(qū)這已成為共識,查看2008年一月的一個提議,在jira: https://issues.apache.org/jira/browse/MAPREDUCE-279.
下一代MapReduce
重構(gòu)的基本思想是把jobtracker的兩大功能分開,使資源管理和作業(yè)分配/監(jiān)控成為兩個部件.新的資源管理器管理提供給應(yīng)用(一個或多個)的計算資源,應(yīng)用管理中心管理應(yīng)用程序的調(diào)度和協(xié)調(diào),應(yīng)用程序既是一個經(jīng)典MapReduce作業(yè)也是這類作業(yè)的DAG. 資源管理器和每臺機器的NodeManager服務(wù),管理該機上的用戶進程,形成計算結(jié)構(gòu). 每個應(yīng)用程序的ApplicationMaster是一個具體庫的架構(gòu),負責從資源管理器請求資源,并和NodeManager協(xié)同執(zhí)行和監(jiān)控任務(wù).
資源管理器支持應(yīng)用程序的分組,這些組保證使用一定比例集群資源. 它是純粹的調(diào)度,也就是,它運行時并不監(jiān)控和追蹤應(yīng)用的狀態(tài). 此外,它不保證重新啟動失敗的任務(wù),無論是應(yīng)用程序或硬件導(dǎo)致的失敗.
資源管理器執(zhí)行調(diào)度功能是基于應(yīng)用的資源需求,每個應(yīng)用需要多種資源需求,代表對對容器所需的資源,資源需求包括內(nèi)存,cpu,硬盤,網(wǎng)絡(luò)等,注意這與當前使用slot模型的MapReduce有很大的不同,slot模型導(dǎo)致集群利用率不高,資源管理器有一個調(diào)度策略插件,負責分把集群資源分給各個組,應(yīng)用等.有基礎(chǔ)的調(diào)度插件,例如:當前的CapacityScheduler 和FairScheduler.
NodeManager是每臺機器的框架代理,負責提交應(yīng)用程序的容器,監(jiān)控他們的資源利用率(cpu,內(nèi)存,硬盤,網(wǎng)絡(luò)),并且報告給調(diào)度器.
每個應(yīng)用程序的ApplicationMaster負責與調(diào)度器請求適當?shù)馁Y源容器,提交作業(yè),追蹤其狀態(tài),監(jiān)控進度和處理失敗任務(wù).
結(jié)構(gòu)
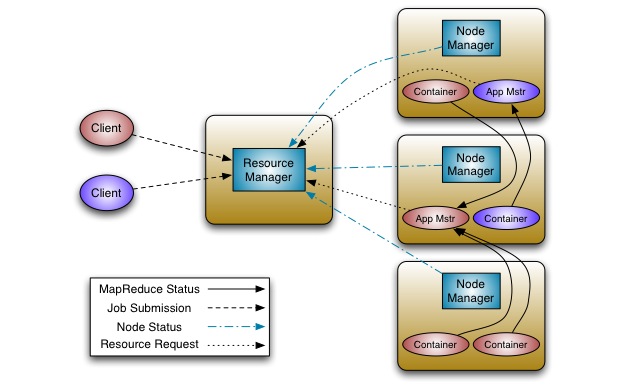
改進當前實現(xiàn)面對面的Hadoop MapReduce
可擴展性
在集群中把資源管理從集群管理器的整個生命周期和他們的部件中分離出來后形成的架構(gòu):擴展性更好并且更優(yōu)雅, Hadoop MapReduce的JobTracker花費很大一部分時間和精力管理應(yīng)用程序的生命周期,這是導(dǎo)致軟件災(zāi)難的原因.把它移到應(yīng)用指定的實體是一個重大的勝利.
可擴展性在當前硬件趨勢下更加重要,當前hadoop的MapReduce已經(jīng)發(fā)展到4000臺機器,然而4000臺機器在2009年(例:8core,16G RAM,4TB硬盤)只有2011年400臺機器的一半(16core,48G RAM, 24TB硬盤). 并且,運營成本的因素有助于迫使和鞏固我們使用更大的集群:6000臺機器或者更多.
可用性
- 資源管理器 – 使用 Apache ZooKeeper 用于故障轉(zhuǎn)移. 當資源管理器發(fā)生故障,另外一個可以迅速恢復(fù),這是由于集群狀態(tài)保存在ZooKeeper中. 資源管理器失敗后,重啟所有組和正在運行的應(yīng)用程序.
- 應(yīng)用中心 - 下一代MapReduce支持應(yīng)用特殊點的檢查功能 ,依靠其把自身狀態(tài)存儲在hdfs上的功能,MapReduce 應(yīng)用中心可以從失敗中恢復(fù),
兼容性
下一代MapReduce使用線兼容協(xié)議以允許不同版本的服務(wù)端和客戶端相互通信,在將來的releases版本,這將使集群滾動升級,一個重要的可操作性便成功了.
創(chuàng)新和敏捷性
提出的構(gòu)架一個主要優(yōu)點是MapReduce將更有效,成為user-land library. 計算框架(資源管理器和節(jié)點管理器)完全通用并在MapReduce看來是透明的.
這使最終客戶在同一個集群使用可用不同版本的MapReduce, 這是微不足道的支持,因為MapReduce的應(yīng)用中心和運行時的多版本可用于不同的應(yīng)用. 這為應(yīng)用提供顯著的靈活性,因為整個集群沒必要升級,如修復(fù)bug,改進和新功能的應(yīng)用. 它也允許終端用戶根據(jù)他們自己的安排升級其應(yīng)用到MapReduce版本,這大大提高了集群的可操作性.
允許用戶自定義的Map-Reduce版本的創(chuàng)新不會影響軟件的穩(wěn)定性. 這是微不足道的,就像hadoop在線原型進入用戶MapReduce版本而不影響其他用戶.( It will be trivial to incorporate features such as the Hadoop Online Prototype into the user’s version of MapReduce without affecting other users.)
集群利用率
下一代MapReduce資源管理器使用通用概念,用于調(diào)度和分配給單獨的個體.
集群中的每個機器資源是概念性的,例如內(nèi)存,cpu,I/O帶寬等. 每個機器都是可替代的,分配給應(yīng)用程序就像基于應(yīng)用指定需求資源的容器.每個容器包括一些處理器,并和其他容器邏輯隔離,提供強有利的多租戶支持.
它刪除了當前hadoop MapReduce中map和reduce slots概念. Slot會影響集群的利用率,因為在任何時候,無論map和reduce都是稀缺的.
支持MapReduce編程范式
下一代MapReduce提供一個完全通用的計算框架以支持MapReduce和其他的范例.
架構(gòu)允許終端用戶實現(xiàn)應(yīng)用指定的框架,通過實現(xiàn)用戶的ApplicationMaster,可以向資源管理器請求資源并利用他們,因為他們通過隔離并保證資源的情況下看起來是適合的.
因此,在同一個hadoop集群下支持多種編程范式,例如MapReduce, MPI, Master-Worker和迭代模型,并允許為每個應(yīng)用使用適當?shù)目蚣?/span>.這對自定義框架順序執(zhí)行一定數(shù)目的MapReduc應(yīng)用程序(例: K-Means, Page-Rank)很重要.
結(jié)論
Apache Hadoop和特定的Hadoop MapReduce,是一個用于處理大數(shù)據(jù)集的成功開源項目. 我們建議Hadoop的 MapReduce重構(gòu)以提供高可用性,增加集群利用率,提供編程范例的支持以加快發(fā)展.
我們認為,在已存在的選項中如Torque, Condor, Mesos 等,沒有一個用于設(shè)計解決MapReduce集群規(guī)模的問題, 某些功能很新且不成熟, 另外一些沒有解決關(guān)鍵問題,如調(diào)度在上十萬個task,規(guī)模的性能,安全和多用戶等.
我們將與Apache Hadoop社區(qū)合作,為實現(xiàn)這以提升Apache Hadoop以適應(yīng)下一代大數(shù)據(jù)空間.
0.23的調(diào)度方法: http://developer.yahoo.com/blogs/hadoop/posts/2011/03/mapreduce-nextgen-scheduler/