High Availability for the HDFS Namenode
Sanjay Radia, Suresh Srinivas
Yahoo! Inc
(本文為namdnoe HA的設(shè)計(jì)文檔翻譯)
1. 問題闡述
有許多方法可以改善HDFS Namednoe(NN)的可用性,包括減少啟動(dòng)時(shí)間,更新配置而不需要重啟集群,減少升級(jí)時(shí)間與提供一個(gè)手動(dòng)或自動(dòng)的NN故障切換等。本文主要關(guān)注于NN的故障切換以解決NN的單點(diǎn)故障問題。
有許多方法用以解決NN的失敗,其中包括使用共享存儲(chǔ),使用虛擬IP與智能客戶端。 可以使用Zookeeper用于領(lǐng)導(dǎo)者選舉,或者其他架構(gòu)類似Linux HA。 這些不同的解決方法可以共享一些框架部件, 本文的目的是定義這些框架部件并提供一些具體設(shè)計(jì),用以建立一個(gè)機(jī)器故障切換的解決方案,以此提供HDFS Namenode的高可用性并隔離HDFS的服務(wù)。
2. 術(shù)語
1) Active NN - 為客戶端提供讀寫操作的服務(wù)的活動(dòng)NN
2) Standby NN - 這個(gè)NN等待并當(dāng)Active NN死去的時(shí)候成為active
i. BackupNode 在hadoop-0.21中可用于實(shí)現(xiàn)Standby的共享存儲(chǔ)文件系統(tǒng)的名字空間。
3) 為了不導(dǎo)致混淆,我們不會(huì)使用Primary 或者 Secondary來代表Active和Standby,因?yàn)?/span>Secondary在老版本中是checkpoing 節(jié)點(diǎn)。
4) Hot,Warm, Cold 的故障切換,Standby NN 存儲(chǔ)正在運(yùn)行的Active的子狀態(tài) 。
i. Cold Standby:Standby NN沒有狀態(tài)。
ii. Warm Standby:Standby 有部分狀態(tài):
1. 它已加載fsImage和editLog但是沒有收到塊報(bào)告;
2. 它已加載fsImage和roolled logs與所有塊報(bào)告。
5) Hot Standby: Standby已經(jīng)有Active的所有狀態(tài),并立刻啟動(dòng)。
3. 上層應(yīng)用
1) 計(jì)劃停機(jī): 一個(gè)hadoop集群經(jīng)常需要停止以升級(jí)軟件或配置,一個(gè)4000節(jié)點(diǎn)的hadoop集群需要大約兩個(gè)小時(shí)的時(shí)間重啟。
2) 非計(jì)劃停機(jī)或服務(wù)無響應(yīng): Namenode服務(wù)經(jīng)常由于硬件,系統(tǒng),NN進(jìn)程失敗或NN 進(jìn)程程序幾分鐘無響應(yīng)而出現(xiàn)故障, 然而這些有可能出乎意料的影響一些重要的上層應(yīng)用。
以上兩種情況下,一個(gè)warm或hot 故障切換可以減少停機(jī)時(shí)間, 事實(shí)上計(jì)劃升級(jí)是影響HDFS服務(wù)不可用的最大因素, 因?yàn)?/span>HDFS Namenode 失敗是很少的。(根據(jù)Yahoo 和Facebook的經(jīng)驗(yàn))。
4. 不考慮的情況
1) Active-Active NNs -我們的初始設(shè)計(jì)是一個(gè)NN成為Active而另外一個(gè)standby(warm 或hot), 可選方案是可以考慮允許Standby提供讀操作。 我們認(rèn)為Active-Active 需要額外的工作, 也許需要重新設(shè)計(jì)。
2) 一個(gè)名字空間多于兩個(gè)NN
3) 大面積的失敗,這通常叫做BCP。
5. 支持的失敗情況
1) 只要單HW失敗(disks,NICs,links等),兩個(gè)時(shí)不進(jìn)行處理,但這種情況下保證數(shù)據(jù)不會(huì)損壞。
2) 軟件失敗:例如NN進(jìn)程失敗,或者NN 進(jìn)程死鎖。注意系統(tǒng)無法恢復(fù)當(dāng)standby在剛變成Active的時(shí)候出現(xiàn)軟件失敗。
3) NN GC是一個(gè)棘手的問題,如果一個(gè)NN進(jìn)入GC并且不回復(fù),它不能被認(rèn)為死。
6. 需求
1) 只有一個(gè)NN處于Active
i. 只有Active能處理客戶端的請(qǐng)求并答復(fù)。
ii. 只有Active能改變持久化狀態(tài);
iii. 可選: Standby處理讀請(qǐng)求。
2) 第一步支持手動(dòng)故障切換-一些組織希望使用故障切換僅僅在軟件升級(jí)的時(shí)候,這是導(dǎo)致hadoop集群不可用的最大原因。、
3) 無法自動(dòng)回滾,如果舊的Active重啟或變成健康狀態(tài)的時(shí)候。
4) 數(shù)據(jù)比可用性更重要
i. 手動(dòng)或者自動(dòng)故障切換不應(yīng)該導(dǎo)致數(shù)據(jù)損壞
5) 盡量不用特殊硬件
6) HA安裝和失敗管理應(yīng)該簡(jiǎn)單,并得防止數(shù)據(jù)損壞即使在操作失誤的情況下。
7) 短時(shí)間的NN垃圾收集不應(yīng)該被認(rèn)為失敗與觸發(fā)自動(dòng)故障切換。
7. 具體用例
1) 單點(diǎn)NN配置,沒有故障切換
2) Active和Standby手動(dòng)切換
i. Standby可以是cold/warm/hot
3) Active和Standby 自動(dòng)切換
i. 兩個(gè)NN啟動(dòng),一個(gè)自動(dòng)成為Active另外一個(gè)成為Standby
ii. Active 和Standby 運(yùn)行著
iii. Active失敗,或者不健康,Standby接替
iv. Active和Standby運(yùn)行, Active 手動(dòng)停機(jī)
v. Active和Standby運(yùn)行,Standby失敗,Active繼續(xù)
vi. Active運(yùn)行,Standby停機(jī)維修,Active死并無法啟動(dòng),Standby啟動(dòng)并成為Active
vii. 兩個(gè)NN啟動(dòng),只有一個(gè)起來,它成為Active
viii. Active和Standby運(yùn)行,Active狀態(tài)未知,Standby接替。
8. 設(shè)計(jì)方案
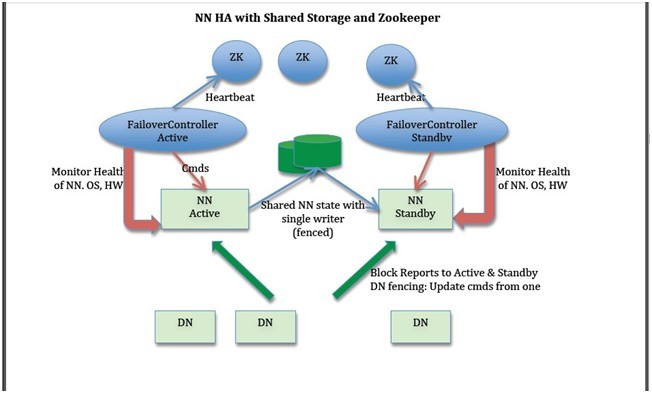
下面我們描述一些設(shè)計(jì)方案。在許多地方都有一些選擇,例如:是否存儲(chǔ)NN的實(shí)時(shí)狀態(tài),如何進(jìn)行領(lǐng)導(dǎo)者選舉(使用zookeeper 或者Linux HA或者其它方法),或者如何實(shí)現(xiàn)隔離技術(shù)。然而其余的部分很簡(jiǎn)單。下面兩個(gè)圖表描述使用zookeeper 和Linux HA做共享存儲(chǔ)的整體方針;設(shè)計(jì)可以擴(kuò)展到BackupNode。
NN HA with Shared Storage and Zookeeper
NN HA with Shared Storage and Linux HA
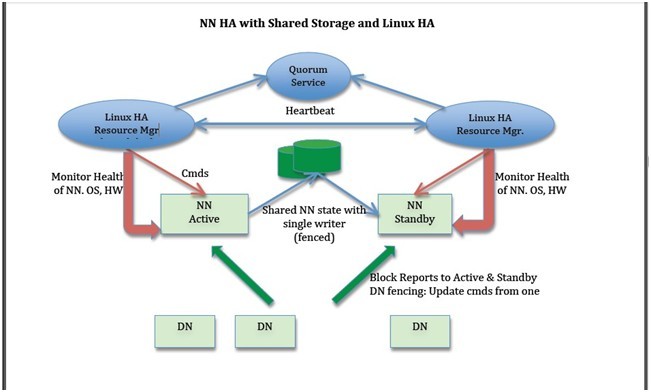
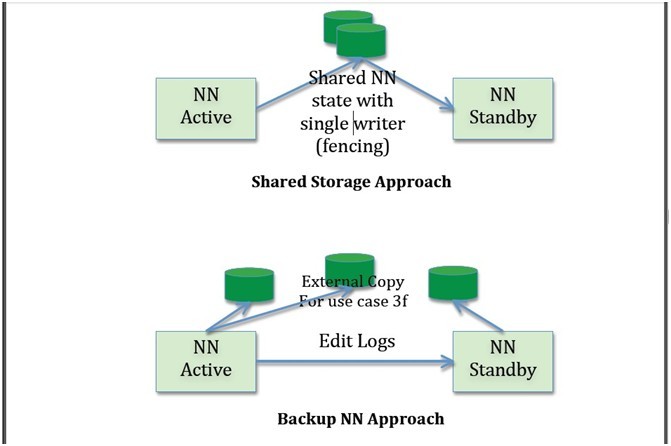
1) NN元數(shù)據(jù)的共享存儲(chǔ)與無共享存儲(chǔ)
Active與Standby既可以共享存儲(chǔ)(例如NFS)或者Active把edits形成流發(fā)給Standby(就像0.21里BackupNode的實(shí)現(xiàn))。其中一些考慮如下:
i. 共享存儲(chǔ)成為單點(diǎn)故障,因此需要其高可用。Bookkeeper 是一個(gè)比較好的解決方法但是在prime time還未準(zhǔn)備好,可以考慮成為長(zhǎng)遠(yuǎn)的方法。使用bookkeeper ,NN不需要在本地磁盤保持狀態(tài),導(dǎo)致NN結(jié)束時(shí)‘無狀態(tài)’。某些組織由于其他原因在其集群中已經(jīng)存在HA NFS。
ii. BackupNode更便宜,因?yàn)樗恍枰褂霉蚕矸?wù)器。然而其不支持用例的第三條。
iii. BackupNode不需要隔離技術(shù),只要不必解決用例的第三條時(shí)。共享存儲(chǔ)需要隔離。然而,如果我們使用Stonith來解決隔離問題,那么就能解決所有隔離需求。
iv. BackupNode不具有對(duì)稱性,因此不能接替除非有Active的完整狀態(tài)。
v. 當(dāng)BackupNode停機(jī)時(shí),還是依賴于remote存儲(chǔ)以存儲(chǔ)Active的額外狀態(tài),這就轉(zhuǎn)回到了共享存儲(chǔ)。
2) 并行塊報(bào)告給Active和Atandby
我們的設(shè)計(jì)中需要并行發(fā)送塊報(bào)告給Active和Standby以保證warm或hot故障切換。塊報(bào)告可以直接由datanode發(fā)送,也可以通過中間層把塊報(bào)告發(fā)給Active和Standby。
3) 客戶端在故障切換時(shí)重定向
當(dāng)Active失敗時(shí),客戶端需要重新連接到新的Active,這叫做客戶端故障切換。有多種方法可以實(shí)現(xiàn)。
i. 更改DNS的綁定:這不是一個(gè)好方法,因?yàn)椴僮飨到y(tǒng)以及許多庫(kù)把DNS緩存著,因此不會(huì)立刻做相應(yīng)的改變。
ii. 智能客戶端:基于服務(wù)器的重定向,重試或者重新查找Active。
1. 注意基于服務(wù)器的重定向需要注意腦裂,無論服務(wù)器是否重定向。這種情況下一個(gè)更好的隔離方法是需要共享存儲(chǔ),因此只有一端可以寫editlog。
2. 是否可以在HTTP或JMX下工作。
3. 故障切換時(shí)間將更長(zhǎng),因?yàn)樵谡业叫翹N的地址前客戶端總是需要與第一個(gè)NN(有可能已經(jīng)死了)交互。
iii. 使用一個(gè)負(fù)載平衡器來發(fā)送客戶端的請(qǐng)求到正確的NN,但這在大規(guī)模的環(huán)境中(例如:10萬客戶端)是很困難的。
iv. IP故障切換-這在生產(chǎn)環(huán)境下經(jīng)常用到。
1. Namenode服務(wù)器使用虛擬IP地址,虛擬IP地址被Active使用。
2. 問題:在跨交換機(jī)的環(huán)境下是否工作,是否只能在VLAN中使用。
4) 客戶端在NN啟動(dòng)時(shí)超時(shí)
NN在某些情況下花很長(zhǎng)時(shí)間啟動(dòng),加載image,應(yīng)用edits恢復(fù)塊位置信息。這有可能導(dǎo)致客戶端超時(shí)并認(rèn)為NN死了。因此,當(dāng)Active啟動(dòng)的時(shí)候,應(yīng)該在客戶端的請(qǐng)求中返回“啟動(dòng)中”以表示客戶端應(yīng)該等待。這種模式是safemode的特殊例子。
5) 故障切換控制使用獨(dú)立于NN進(jìn)程的故障切換控制器(Watchdog)
我們的方法是使用獨(dú)立于NN進(jìn)程的故障切換控制器進(jìn)程。這個(gè)故障切換控制器與Linux HA的資源管理器非常相似。在基于Linux HA的解決方法中,作為其一部分的RM可以直接使用。而zookeeper ,我們可以自己寫一個(gè),或者配置Linux HA的資源管理器使用zookeeper 。
故障切換控制器執(zhí)行以下功能:
i. 監(jiān)控健康的NN,OS和HW,以及其他資源例如網(wǎng)絡(luò)連接。
ii. 使用heartbeat以此選舉領(lǐng)導(dǎo)者。(heartbeat發(fā)送給zookeeper,使用zookeeper 選舉領(lǐng)導(dǎo)者 )
iii. 在領(lǐng)導(dǎo)選舉中Active被選中。Active故障切換控制器指示其監(jiān)控的NN從Standby轉(zhuǎn)換為Active。(注意每個(gè)NN啟動(dòng)的時(shí)候都是Standby,只有在接到故障切換控制器的指示后才成為active)
使用獨(dú)立的故障切換控制器進(jìn)程有以下的優(yōu)點(diǎn):
i. 把這個(gè)功能集成到NN會(huì)導(dǎo)致心跳機(jī)制患上GC的失敗。
ii. 故障切換控制器應(yīng)該是寫成緊湊的代碼,從失敗的應(yīng)用中獨(dú)立出來以增加容錯(cuò)。
iii. 把選舉機(jī)制做成插件形式。
6) 隔離(fencing)
在 故障切換的解決方案中,保證只有一個(gè)Active實(shí)例能更新共享狀態(tài)是很重要的。即使有選舉機(jī)制,舊的Active有可能被隔離,不可能立刻成為 Standby,有可能繼續(xù)共享共享狀態(tài)。Fencing是一種阻止舊Active繼續(xù)寫共享存儲(chǔ)的方法。Fencing需要Active服務(wù)不重試,在 恢復(fù)對(duì)共享存儲(chǔ)設(shè)備的控制時(shí)通過fenced設(shè)備返回IO錯(cuò)誤;在這種情況下舊Active應(yīng)該退出并附帶錯(cuò)誤信息(成為standby不是很好)。
下面的共享資源可以考慮:
i. 作為NN元數(shù)據(jù)的共享存儲(chǔ)器:保證只有Active寫更新到edits logs。
ii. Datanode:保證只有一NN進(jìn)行刪除操做以移動(dòng)/管理在datanode上的副本。
iii. 客戶端:客戶端不嚴(yán)格的需要NN更新的共享狀態(tài),然而客戶端發(fā)送更新命令到兩個(gè)NN之一。需要保證只有Active NN給客戶端回復(fù)。注意如果共享存儲(chǔ)器fencing時(shí),如果非active NN試圖寫將被fenced并且這種情況下不會(huì)返回成功給客戶端。
2) 其他故障切換問題
i. 故障切換時(shí)恢復(fù)租約-具體TBD。
ii. 故障切換時(shí)Pipeline恢復(fù)
2. 具體設(shè)計(jì)
1) Fencing
我們已經(jīng)描述了fencing和需要fenced的共享資源/狀態(tài),以及NN應(yīng)該在由于fencing寫失敗的時(shí)候退出的需求。
2) Fencing 包含NN元數(shù)據(jù)的共享存儲(chǔ)
在HDFS-1073中, fsImage和EditLogs已經(jīng)脫離, 因此只有editlog需要fenced. 注意, 啟動(dòng)一個(gè)新的NN總會(huì)啟動(dòng)一個(gè)新的editlog. 一個(gè)需要防止的事情是防止舊的active 繼續(xù)寫舊的editlog并把這個(gè)結(jié)果告訴客戶端.
i. 使用NFS, fencing的解決方案需要調(diào)查.
ii. 使用Bookeeper, 當(dāng)前正在與bookkeeper團(tuán)隊(duì)討論增加fencing解決方案.
iii. 使用共享磁盤(SCSI 或者 SAN), 共享磁盤提供一個(gè)已經(jīng)解決的 fencing解決方案, 但不適合hadoop環(huán)境.
3) Fencing Datanodes
兩個(gè)解決方案:
1. 在heartbeat的答復(fù)中, NN返回自己狀態(tài): active或standby
如果DN發(fā)現(xiàn)狀態(tài)更改, 則向ZK詢問誰是active.
如果active由A改為B,然后改為A, DN應(yīng)該然后能檢測(cè)到.
一個(gè)更好的解決方案, 故障切換控制器告訴DN, 但是過多的DN難以等待其確認(rèn), 因此需要在協(xié)議中解決.
2.
每個(gè)NN都有一個(gè)序列號(hào), 這個(gè)序列號(hào)在nn狀態(tài)更改時(shí)傳遞給DN.
DN在運(yùn)行時(shí)保持這個(gè)序列號(hào), DN只聽從最后一個(gè)從standby轉(zhuǎn)換到active的NN.
如果一個(gè)此前active的NN重新回來(類似GC), DN將拒絕它, 因?yàn)槠湫蛄刑?hào)已經(jīng)過時(shí), 另外一個(gè)新NN已經(jīng)使用新的序列號(hào)代替了它.
4) Fencing 客戶端
一個(gè)客戶端發(fā)送更新命令到兩個(gè)NN中的一個(gè), 只有active NN回答給客戶端. 這需要更深入的調(diào)查. 注意如果共享存儲(chǔ)已經(jīng)fenncing了, 那么非active NN試圖寫不會(huì)返回成功給客戶端.
5) 使用stonith作為fencing的解決方案.
如果沒有其他好的解決方案時(shí), Stonith (Shoot the other node in the head) 經(jīng)常被用于fencing解決方案, Stonith往往通過電源操作關(guān)閉其它節(jié)點(diǎn).
6) 領(lǐng)導(dǎo)者選舉和故障切換控制器進(jìn)程
我們已經(jīng)概括了把控制進(jìn)程分離出來的好處, 它還有其它優(yōu)勢(shì). 故障切換控制器進(jìn)程在Linux HA中叫做資源管理器, zookeeper沒有類似的看門狗進(jìn)程, 因此建議使用LinuxHA的RM接口:
因?yàn)?/span>LinuxHA使用Linux HA 資源管理器作為故障切換控制進(jìn)程.
為ookeeper寫一個(gè)故障切換控制器作為測(cè)試是否健康, 直接使用Linux HA資源管理器和zookeeper, 這能有效的使用zookeeper 作為領(lǐng)導(dǎo)者選舉器.
7) 故障切換控制器進(jìn)程操作
i. 心跳, 用于保證active存活, 失去heartbeat時(shí)觸發(fā)領(lǐng)導(dǎo)者選舉.
如果是zookeeper , 故障切換控制器定期發(fā)送心跳給ZK.
LinuxHA, 其資源管理器管理發(fā)送Standby心跳的故障切換控制器.
ii. 使用故障切換控制器監(jiān)控是否健康.
處理NN的狀態(tài)(ps命令)
NN簡(jiǎn)單的需求(例如GC)
OS檢測(cè)
Nic檢測(cè)
交換機(jī)檢測(cè)
iii. 故障切換控制器需要處理一系列命令, 無論是NN從Standby‐to‐Active 還是 Active‐to‐Standby. 這些操作需要配置, 例如Linux HA允許每個(gè)其管理的資源配置一系列的命令.
iv. Standby‐to‐Active過程中, 需要以下過程:
Fenced共享存儲(chǔ)和DN(如果沒有其它資源, 可以使用Stonish)
更新共享客戶端地址和/或虛擬IP
告訴NN轉(zhuǎn)換為active
v. Active‐to‐Standby轉(zhuǎn)換中, 需要以下過程
更新客戶端地址或放棄虛擬IP
告訴NN變成standby或退出, 如果NN無回應(yīng), 則kill之.
8) NN啟動(dòng)和Active與standby狀態(tài)更改
在啟動(dòng)NN是進(jìn)入Standby, 只在接到故障切換控制器的命令后才能轉(zhuǎn)為active.
9) Standby的NN
i. 不向客戶端提供服務(wù)
ii. 讀取image并處理edits
iii. 接收BR并處理, 但不回復(fù)”刪除”或”復(fù)制”命令給DN
10) NN變?yōu)?/span>Active
當(dāng)NN變?yōu)?/span>active時(shí): 結(jié)束處理最新的edits; 告訴客戶端它在啟動(dòng)模式.
問題: 如果NN僅僅是從Active轉(zhuǎn)換為Standby或重啟.
11) 客戶端重定向
我們已經(jīng)概括以上兩種可行的方法. TBD
12) 智能客戶端
TBD描述了智能客戶端的方法, 當(dāng)客戶端連接NN失敗時(shí)通過其它服務(wù)(如zookeeper ) 尋找active. 需要討論其利弊.
13) IP故障切換方法
生成領(lǐng)域標(biāo)準(zhǔn)方法, 如何工作: TBD
好處: 適合各種協(xié)議, HDFS, HTTP, JMX等
挑戰(zhàn): 虛擬IP跨網(wǎng)段.
14) 共享存儲(chǔ)方法
Standby從共享存儲(chǔ)器讀取edits, 只有過時(shí)的寫到當(dāng)前未滾動(dòng)的edits, 詳情:TBD
Fencing已經(jīng)在上文敘述
15) 非共享存儲(chǔ)方法:使用Backup NN
描述BackupNN的工作以及這種方法: TBD
3. 附錄
1) 自動(dòng)故障回滾
描述問題以及其產(chǎn)生條件
2) 健忘癥
失去已經(jīng)和客戶端此前的交流過的信息.
3) GC
如何區(qū)別NN不回復(fù)的時(shí)候是否是GC? 需要調(diào)查